





I. Introduction▲
Cela arrive trop souvent : un programme fonctionne correctement avec les caractères latins, mais il produit des caractères étranges ou illisibles dès qu'il faut utiliser des caractères chinois ou japonais, ou des caractères latins modifiés tels que le « Umlaut » allemand Ä, Ö… ou les caractères scandinaves å et Ø.
II. ASCII▲
Pour comprendre le cœur du problème, il faut comprendre comment les caractères latins « normaux » et les autres caractères (ceux causant les problèmes) sont stockés.
Tout a commencé en 1963, avec le code ASCII, the « American Standard for Information Interchange ».Il couvre 128 caractères de 0 à 127, pouvant être encodés en 7 bits.
Puisqu'un octet contient 8 bits, le bit de poids fort d'un caractère ASCII est toujours à 0.
Le standard définit les caractères latins a à z en majuscules et en minuscules, les chiffres arabes 0 à 9, un espace appelé « blank », le retour chariot, et quelques caractères de contrôle et caractères spéciaux tels que %, $. Les caractères non essentiels à l'usage quotidien des citoyens américains ne sont pas définis dans le codage ASCII, comme les lettres cyrilliques, les caractères latins « décorés », les caractères grecs, et ainsi de suite.
III. Les autres encodages de caractères▲
Quand les gens ont commencé à utiliser des ordinateurs ailleurs qu'aux États-Unis, d'autres caractères ont été nécessaires. Dans les pays européens, l'ASCII fut réutilisé, et les 128 nombres inutilisés (le huitième bit de l'octet) ont été utilisés pour les caractères localement nécessaires.
En Europe de l'Ouest, l'encodage de caractères fut appelé « Latin-1 », puis plus tard standardisé sous le format ISO-8859-1. Latin-2 fut utilisé en Europe centrale, et ainsi de suite.
Dans chaque jeu de caractères Latin-*, les premiers 128 caractères sont identiques à l'ASCII, donc, cela peut être vu comme une extension de l'ASCII. Les autres 128 valeurs sont chacune mappées sur les caractères nécessaires à chaque région, chacun dans leur jeu de caractères utilisés.
Dans d'autres endroits du monde, d'autres encodages de caractères ont été développés, comme l'EUC-CN en Chine et le Shift-JIS au Japon.
Ces jeux de caractères locaux sont vraiment limités. Quand l'euro fut introduit en 2001, beaucoup de pays européens avaient un symbole pour leur monnaie qui ne pouvait pas être exprimé avec l'encodage de caractères traditionnels.
IV. Unicode▲
Les jeux de caractères mentionnés ci-dessus ne peuvent encoder qu'une partie de tous les caractères possibles, ce qui rend quasi impossible la création de documents contenant des lettres de différentes écritures.
Dans une tentative d'unifier toutes les écritures dans une seule norme, le consortium Unicode fut créé, et il commença à collecter tous les caractères connus, et à leur assigner chacun un nombre unique, appelé « point de code ».
Le « point de code » est habituellement écrit comme un nombre hexadécimal de quatre ou six chiffres, comme U+0041. Le nom correspondant à ce caractère est : « LATIN SMALL LETTER A ».
En dehors des lettres et autres « caractères de base », il y a aussi des accents aigus ou graves, des décorations (exemple :¨ ou ~) qui peuvent être ajoutés aux caractères de base.
Si le caractère de base est suivi par un ou plusieurs de ces caractères de marquage, ce composé forme un caractère logique nommé « graphème ».
Il est à noter que beaucoup de graphèmes précomposés existent pour les caractères qui sont définis dans d'autres jeux de caractères, et ceux-ci sont souvent mieux supportés par les logiciels courants que les caractères de base combinés aux caractères de marquage.
V. Formats de transformation Unicode ▲
Le concept des points de code Unicode et des graphèmes est complètement indépendant de l'encodage.
Il y a différentes façons d'encoder ces points de code, et leurs mappings de points de code en octets sont appelés « Unicode Transformation Formats ». Le plus connu est l'UTF-8, qui est un format basé sur des octets qui utilisent les valeurs de 0 à 255. Dans le monde de Perl, il y a aussi une version nommée UTF8 (sans le trait d'union). Le module Perl Encode distingue les deux versions.
Windows utilise principalement l'UTF-16, qui utilise au moins 2 octets par point de code, pour les plus grands points de code, il utilise 4 octets. Il y a plusieurs variantes d'UTF-16, qui sont marquées par LE pour Little-Endian et BE pour Big-Endian (voir Endianness).
UTF-32 encode chaque point de code avec 4 octets. C'est le seul encodage à longueur fixe pouvant implémenter entièrement l'étendue des caractères Unicode.
|
points de code |
Caractères |
ASCII |
UTF-8 |
Latin-1 |
ISO-8859-15 |
UTF-16 |
|---|---|---|---|---|---|---|
|
U+0041 |
A |
0x41 |
0x41 |
0x41 |
0x41 |
0x00 0x41 |
|
U+00c4 |
Ä |
- |
0xc3 0x84 |
0xc4 |
0xc4 |
0x00 0xc4 |
|
U+20AC |
€ |
- |
0xe3 0x82 0xac |
- |
0xa4 |
0x20 0xac |
|
U+c218 |
|
- |
0xec 0x88 0x98 |
- |
- |
0xc2 0x18 |
La lettre dans la dernière ligne est la syllabe Hangeul SU, et votre navigateur ne peut l'afficher correctement que si vous avez les polices asiatiques appropriées installées.
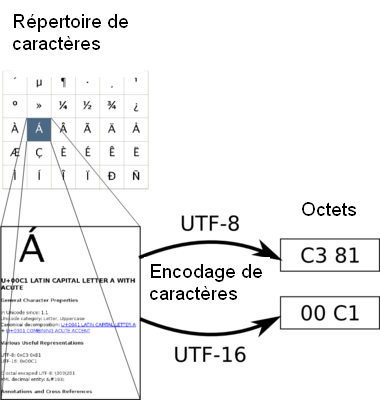
Unicode définit un répertoire de caractères et ses propriétés. Les encodages de caractères UTF-8 et UTF-16 définissent une façon d'écrire ceux-ci en séquence courte d'octets.
VI. Perl 5 et les encodages de caractères▲
Les chaînes Perl peuvent être utilisées pour contenir des chaînes de caractères ou des données binaires. Avec une chaîne donnée, vous n'avez aucun mécanisme permettant de déterminer si elle contient du texte ou des données binaires, vous devez en garder une trace vous-même.
L'interaction avec l'environnement (comme lire un fichier, des données sur STDIN ou les imprimer) traite les chaînes comme des données binaires. La même chose est vraie pour les valeurs de retour de beaucoup de fonctions internes (comme gethostbyname) et les variables spéciales qui gardent les informations pour votre programme (%ENV et @ARGV).
Les autres fonctions internes qui interagissent avec du texte (comme les expressions régulières, uc et lc) traitent les chaînes comme du texte, ou plus exactement comme une liste de points de code.
Avec la fonction decode du module Encode, vous pouvez décoder des chaînes binaires pour être sûr que les fonctions de traitement de texte fonctionnement correctement.
Toutes les opérations devraient fonctionner sur des chaînes qui ont été décodées par Encode::decode (ou avec les façons décrites ci-dessous). Autrement les fonctions de traitement de texte considèrent que les chaînes sont stockées en Latin-1 et donneront un résultat incorrect dans un autre encodage.
Notez que cmp compare uniquement les caractères non ASCII par des numéros de points de code, ce qui peut donner des résultats inattendus. En général, l'ordre est dépendant du langage utilisé et vous devez donc utiliser use locale pour trier des chaînes selon les règles naturelles du langage utilisé. Par exemple, en allemand, l'ordre de tri souhaité sera 'a' lt 'ä' and 'ä' lt 'b', tandis que la comparaison par numéro de points de code donnera 'ä' gt 'b'.
#!/usr/bin/perl
use warnings;
use strict;
use Encode qw(encode decode);
my $enc = 'utf-8'; # Ce programme est encodé et enregistré en UTF-8
my $str = "Ä\n";
# Byte strings:
print lc $str; # affiche 'Ä', lc n'a aucun effet
# Chaîne de caractères
my $text_str = decode( $enc, $byte_str );
$text_str = lc $text_str;
print encode( $enc, $text_str ); # affiche 'ä', lc fonctionneIl est fortement recommandé de convertir toutes les entrées en chaînes texte, de travailler avec ces chaînes texte et les mettre secrètement en chaînes d'octets à la sortie ou sur le support de stockage.
Sinon, vous pouvez très vite être induit en erreur et perdre les traces des chaînes qui sont des chaînes d'octets de celles qui sont des chaînes de texte.
Perl offre des couches d'entrée/sortie (IO Layers) qui ont des mécanismes de conversion automatique, soit globalement, soit par descripteur de fichier.
# IO layer: $handle décode désormais toutes les chaînes lors de la lecture
open my $handle, '<:encoding(UTF-8)', $file;
# same
open my $handle, '<', $datei;
binmode $handle, ':encoding(UTF-8)';
# tout appel à open() utilise automatiquement :encoding(iso-8859-1)
use open ':encoding(iso-8859-1)';
# Toutes les chaînes de caractères du script sont interprétées comme des chaînes de texte:
use utf8;
# considère que le script doit être stocké en UTF-8
# Récupère les paramètres régionaux (les "locales") de l'environnement et
# demande à STDOUT de faire la conversion vers ces paramètres régionaux
use PerlIO::locale;
binmode STDOUT, ':locale';
# Toutes les entrées/sorties avec l'encodage courant
use open ':locale';Une attention particulière doit être portée à : utf8, qui est souvent citée dans les exemples de code et de documentation : cette fonction garantit que l'entrée sera valide en UTF-8, et vous n'avez aucun moyen de savoir dans votre programme si c'est réellement le cas. Si ça ne l'est pas, c'est une source de trou de sécurité subtil, regardez cet article pour plus de détails. Ne l'utilisez jamais comme une couche d'entrée, utilisez encoding(UTF-8) à la place.
Le module et pragma utf8 vous permet également d'utiliser des caractères non ASCII dans des noms de variables ou de modules. Mais attention, ne le faites pas pour les packages et les modules, cela ne fonctionne pas correctement. Considérez également que tout le monde n'a pas de clavier autorisant la saisie simple de caractères non ASCII, donc la maintenance de votre code s'en trouvera compliquée.
VII. Tester votre environnement▲
Vous pouvez utiliser le petit script suivant dans votre terminal. Il est très centré sur l'Europe, mais vous pouvez l'adapter à l'encodage de caractères que vous utilisez où vous vivez.
#!/usr/bin/perl
use warnings;
use strict;
use Encode;
my @charsets = qw(utf-8 latin1 iso-8859-15 utf-16);
# quelques points de code non non-ASCII
my $test = 'Ue: ' . chr(220) . '; Euro: ' . chr(8364) . "\n";
for (@charsets) {
print "$_: " . encode( $_, $test );
}Si vous lancez ce programme dans un terminal, une seule ligne sera affichée correctement, et sa première colonne correspond à l'encodage de votre terminal.
Le signe euro € n'est pas dans la table d'encodage Latin-1, donc si votre terminal est dans cet encodage, le signe euro n'apparaîtra pas correctement.
Les terminaux Windows utilisent principalement les encodages cp*, par exemple cp850 ou cp858 (seulement disponibles dans les nouvelles versions de Encode) pour les installations allemandes. Le reste de l'environnement utilise les encodages Windows-*, par exemple Windows-1252 pour plusieurs localisations de l'Europe de l'Ouest.
Encode->encodings(":all");retourne une liste des encodages disponibles.
VIII. Dépannage▲
VIII-A. « Caractères larges à l'impression »▲
Quelquefois, vous pourriez voir ce message d'avertissement : Wide character in print.
Cela signifie que vous avez essayé d'utiliser des données d'une chaîne décodée dans un contexte où seules des données binaires ont un sens. Vous pouvez supprimer le warning en utilisant une couche de sortie appropriée, ou en encapsulant d'abord la chaîne incriminée avec Encode::encode.
VIII-B. Inspecter des chaînes▲
Quelquefois, vous voulez vérifier si une chaîne de source inconnue a déjà été décodée. Comme Perl n'a pas de types de données séparés pour les chaînes binaires et les chaînes décodées, vous ne pouvez pas faire ceci de façon fiable.
Mais vous pouvez pallier cela en utilisant le module Devel::Peek.
use Devel::Peek;
use Encode;
my $str = "ä";
Dump $str;
$str = decode("utf-8", $str);
Dump $str;
Dump encode('latin1', $str);
__END__
SV = PV(0x814fb00) at 0x814f678
REFCNT = 1
FLAGS = (PADBUSY,PADMY,POK,pPOK)
PV = 0x81654f8 "\303\244"\0
CUR = 2
LEN = 4
SV = PV(0x814fb00) at 0x814f678
REFCNT = 1
FLAGS = (PADBUSY,PADMY,POK,pPOK,UTF8)
PV = 0x817fcf8 "\303\244"\0 [UTF8 "ä"]
CUR = 2
LEN = 4
SV = PV(0x814fb00) at 0x81b7f94
REFCNT = 1
FLAGS = (TEMP,POK,pPOK)
PV = 0x8203868 "\344"\0
CUR = 1
LEN = 4La chaîne UTF8 dans la ligne commençant par FLAGS = montre que la chaîne a déjà été décodée. La ligne commençant par PV = contient les octets et entre parenthèses les points de code.
Mais il y a un gros avertissement. Juste, car le flag UTF8 n'est pas présent et qui ne veut pas dire que la chaîne texte n'a pas été décodée. Perl utilise soit Latin1, soit UTF-8 en interne pour stocker les chaînes, et la présence de ce flag indique que chacun a été utilisé.
Cela implique aussi que votre programme n'est écrit qu'en Perl (et n'a pas de composant XS). Et c'est presque une erreur à coup sûr de compter sur la présence de ce flag. Vous ne devriez pas vous préoccuper de comment Perl stocke ses chaînes.
VIII-C. Modules bogués▲
Une source commune d'erreurs provient de modules bogués. Le Pragma encoding semble très tentant.
# conversion automatique grâce aux paramètres régionaux (locale)
use encoding ':locale';Mais sous l'effet de use encoding, certaines fonctions AUTOLOAD s'arrêtent de fonctionner, et les modules ne sont pas Thread safe.
IX. Encodage de caractères sur l'internet▲
Quand vous écrivez un script CGI, vous devez choisir un encodage de caractères, imprimer toutes vos données dans cet encodage, et l'écrire dans les en-têtes HTTP.
Pour la plupart des applications, l'UTF-8 est un bon choix, puisque vous pouvez arbitrairement coder les points de code Unicode avec. D'autre part, le texte anglais et la plupart des autres langages européens sont encodés vraiment efficacement.
L'HTTP offre l'en-tête Accept-Charset-Header dans lequel le client peut indiquer au serveur quel encodage il peut supporter. Mais si vous vous en tenez aux encodages communs comme l'UTF-8 ou le Latin-1, tous les user agents vont les comprendre, donc il n'est pas vraiment nécessaire de vérifier cet en-tête.
Les en-têtes HTTP eux-mêmes sont strictement en ASCII, donc toutes les informations envoyées dans l'en-tête HTTP (en incluant les URL et les cookies) doivent être encodées en ASCII si des caractères non ASCII sont utilisés.
Pour les fichiers HTML, l'en-tête ressemble typiquement à ceci :
Content-Type: text/html; charset=UTF-8.Si vous envoyez un tel en-tête, vous n'avez qu'à échapper les caractères qui ont une signification particulière en HTML comme : <,>,& et, dans des attributs ".
Un soin particulier doit être porté à la lecture des paramètres POST ou GET avec la fonction param dans le module CGI. Les vieilles versions (antérieures à 3.29) retournent toujours des chaînes d'octets. Les nouvelles versions retournent une chaîne texte si charset("UTF-8") a été appelé avant, et sinon une chaîne d'octets.
CGI.pm ne supporte pas d'encodage de caractères autre que l'UTF-8. Vous ne devez donc pas utiliser de routine de jeu de caractères et vous devez décoder explicitement les paramètres de chaînes vous-même.
Pour vous assurer que le contenu de formulaire du navigateur a été envoyé avec un charset connu, vous pouvez ajouter l'attribut accept-charset dans la balise <FORM>.
<form method="post" accept-charset="utf-8" action="/script.pl">Si vous utilisez un système de templates, vous devez en choisir un qui sait comment gérer les encodages de caractères.
Les Template::Alloy, HTML::Template::Compiled (depuis la version 0.90 avec l'option open_mode), ou le Template Toolkit (avec l'option d'encodage dans le constructeur et un IO layer dans la méthode process) sont de bons exemples.
X. Les modules▲
Il y a pléthore de modules Perl qui peuvent gérer le texte, et il y en a que quelques-uns de notables, et vous devez les rendre « Unicode-aware ».
X-A. LWP::UserAgent et WWW::Mechanize▲
Utilisez $response->decode_content à la place de seulement $response->content. Par ce biais, l'information d'encodage de caractères envoyée dans l'en-tête de réponse HTTP est utilisée pour décoder le corps de la réponse.
X-B. DBI▲
DBI laisse le traitement de l'encodage de caractères aux modules DBD::(driver), ce que vous avez donc à faire dépend de la base de données que vous utilisez en arrière-plan. Pour la plupart de celles-ci, l'UTF-8 est l'encodage le mieux supporté.
- Pour Mysql et DBD::mysql, passez l'option mysql_enable_utf8=>1 à l'appel à DBI->connect.
- Pour PostgresSql et DBD::Pg, positionnez l'attribut pg_enable_utf8 à 1.
- Pour SQLite et DBD::SQLite, positionnez l'attribut sqlite_unicode à 1.
XI. Thèmes avancés▲
Avec le charset de base et la connaissance de Perl, vous pouvez aller assez loin. Par exemple, vous pouvez faire une application web « Unicode safe », c'est-à-dire prendre soin que toutes les entrées possibles soient affichées correctement, dans n'importe quel script que l'utilisateur est amené à utiliser.
Mais ce n'est pas tout ce qu'il faut savoir sur le sujet. Par exemple, le standard Unicode permet différents moyens de composer des caractères, vous devez donc les normaliser avant de comparer deux chaînes. Vous pouvez lire plus à ce propos dans la FAQ Unicode normalization.
Pour implémenter un comportement spécifique à un pays dans des programmes, vous devez jeter un œil sur les locales du système. Par exemple, en Turquie, la minuscule de la lettre capitale I est İ, U+0131 LATIN SMALL LETTER DOTLESS I, quand la majuscule de i est İ, U+0130 LATIN CAPITAL LETTER I WITH DOT ABOVE.
Une bonne lecture pour commencer à propos des locales est la perldoc perllocale.
XII. Philosophie▲
Beaucoup de programmeurs confrontés à des problèmes d'encodage ont comme première réaction : « ça ne devrait pas marcher ? ». Oui, ça devrait marcher, mais beaucoup trop de systèmes sont mal conçus au niveau de l'encodage et des jeux de caractères.
XIII. Mal conçu▲
« mal conçu » signifie la plupart du temps qu'un format de document, qu'une API ou un protocole autorise plusieurs encodages, sans une façon normalisée de transport de conserver cet encodage avec l'information.
Un exemple classique est l'Internet Relay Chat (IRC), lequel spécifie qu'un caractère est un seul octet, mais pas quel encodage est utilisé. Cela marchait bien du temps de l'encodage Latin-1, mais était voué à l'échec aussitôt que des personnes de différents continents allaient commencer à l'utiliser.
Actuellement, beaucoup de clients IRC essayent d'autodétecter l'encodage de caractères et le recodent selon la configuration de l'utilisateur. Cela fonctionne très bien dans certains cas, mais produit un résultat horrible là ou cela ne fonctionne pas.
XIV. Autre exemple : le XML▲
L'Extensible Markup Language, communément connu par son abréviation XML, vous permet de spécifier l'encodage dans le fichier :
<?xml version="1.0" encoding="UTF-8" ?>Il y a deux raisons pour lesquelles c'est suffisant :
- L'information d'encodage est optionnelle. La spécification indique clairement que l'encodage doit être UTF-8 si l'information de celui-ci est absente, mais malheureusement beaucoup d'auteurs d'outils ne semblent pas le savoir et finalement émettent du Latin-1. (C'est bien sûr seulement en partie la faute de la spécification.) ;
- Tout analyseur XML doit d'abord détecter automatiquement l'encodage pour pouvoir parser l'information encodée.
Le second point est vraiment important. Vous supposez que : « Il n'y a pas de problème, le préambule est juste de l'ASCII ».
Mais beaucoup d'encodages sont compatibles ASCII pour les 127 premiers octets (par exemple UTF-7, UCS-2 et UTF-16).
Ainsi, l'information d'encodage est disponible, le parser doit d'abord le deviner pour l'extraire correctement.
L'annexe aux spécifications XML contient un algorithme de détection qui peut gérer tous les cas classiques, mais ne comporte pas le support de l'UTF-7.
XV. Comment faire les choses correctement : la signalisation Out-of-band▲
L'exemple XML au-dessus démontre que le support de l'information d'encodage est inclus dans le format de fichier lui-même, sauf si vous spécifiez un moyen de transporter l'information d'encodage au niveau de l'octet, indépendamment de l'encodage du reste du fichier.
Une solution possible aurait pu être de spécifier que la première ligne d'un fichier XML doit être encodée en ASCII, le reste du fichier étant encodé avec ce qui a été spécifié dans cette première ligne. Mais c'est une solution horrible, un éditeur de texte normal pourrait afficher la première ligne de façon complètement fausse si le fichier est dans un codage incompatible avec l'ASCII. Bien sûr, c'est aussi incompatible avec les spécifications XML actuelles, et exigerait de nouvelles spécifications incompatibles qui casseraient toutes les applications existantes.
Alors, comment bien faire les choses ?
La réponse est assez simple ; tout système fonctionnant avec des données texte doit stocker les métadonnées séparément, ou tout stocker dans un encodage uniforme.
C'est tentant de tout stocker dans le même encodage. Et cela fonctionne très bien sur une machine locale, mais vous ne pouvez pas attendre de tout le monde d'être d'accord sur un seul encodage, donc tous les échanges de données doivent toujours incorporer l'information d'encodage. Et souvent, vous voulez stocker les fichiers originaux (par crainte de perte de données), donc vous devez garder l'information d'encodage quelque part.
Cette observation devrait avoir un énorme impact sur le monde de l'informatique : tous les systèmes de fichiers devraient permettre le stockage de l'information d'encodage comme métadonnée, et la retrouver facilement. Le même principe devrait s'appliquer pour les noms de fichiers, et les langages de programmation (au moins ceux qui veulent ne pas faire souffrir leurs utilisateurs) devraient transporter de façon transparente cette métainformation, et se préoccuper de tous les problèmes d'encodage.
Et là, ça pourrait fonctionner.
XVI. Pour en savoir plus▲
XVII. Outils utiles ▲
- gucharmap, la carte des caractères Unicode de Gnome.
- An UTF-8 dumper vous montre les noms des caractères non ASCII.
- hexdump never lies (sur Debian se trouve dans le package bsdmainutils).
- iconv convertit des fichiers texte d'un encodage vers un autre.
XVIII. Remerciements▲
Cet article est une traduction d'un de mes articles en allemand (http://perlgeek.de/de/artikel/charsets-unicode) écrit pour foo-magazin.de en janvier 2008, un magazine Perl allemand. Il a été amélioré et corrigé depuis.
Merci beaucoup à Juerd Waalboer qui a souligné de nombreuses petites erreurs et des erreurs pas si petites que cela dans les versions précédentes de cet article, et a grandement contribué à ma compréhension de la gestion des chaînes en Perl.
J'aimerais aussi remercier ELISHEVA pour ses suggestions et ses nombreuses améliorations grammaticales et orthographiques.
Je tiens aussi à remercier pour leurs discussions pertinentes :
XIX. Remerciements Developpez▲
Nous remercions Moritz LENZ de nous avoir aimablement autorisés à publier son article. Cet article est une traduction autorisée dont le texte original peut être trouvé sur http://perlgeek.de. Nous remercions aussi Christophe LOUVET pour sa traduction et ClaudeLELOUP pour sa relecture orthographique.
Les commentaires et les suggestions d'amélioration sont les bienvenus, alors, après votre lecture, n'hésitez pas, 2 commentaires ![]() !
!
