


V. Références▲
28. Noms spéciaux▲
Ce chapitre traite des variables qui ont une signification spéciale pour Perl. La plupart des noms à ponctuation ont des mnémoniques raisonnables ou des homologues dans les shells (ou les deux). Néanmoins, s'il faut utiliser les noms longs de variables, il suffit d'écrire :
use English;au début du programme. Ceci crée des alias longs pour les noms courts dans le paquetage courant. Certains d'entre eux ont même des noms moyens, généralement empruntés à awk. La plupart des gens continuent d'utiliser les noms courts, du moins pour les variables les plus courantes. Au long de cet ouvrage, nous employons uniformément les noms courts, mais nous mentionnerons aussi les noms longs (entre parenthèses) pour que vous puissiez facilement les retrouver dans ce chapitre.
La sémantique de ces variables est quelque peu magique (pour créer vos propres sorts, voir le chapitre 24, Variables liées). Certaines de ces variables sont en lecture seule. Si l'on essaie d'y assigner une valeur, une exception sera lancée.
Dans ce qui suit, nous donnerons tout d'abord une liste des variables et fonctions auxquelles Perl attribue une signification spéciale, classées par type ; ainsi vous pourrez retrouver les variables dont vous n'êtes plus tout à fait sûrs du nom exact. Ensuite nous détaillerons toutes les variables par ordre alphabétique, avec leur nom approprié (ou leur nom le moins inapproprié).
28-1. Noms spéciaux classés par type▲
Nous utilisons improprement le mot « type », les sections suivantes regroupent davantage les variables selon leur contexte, c'est-à-dire depuis l'endroit où elles sont visibles.
28-1-a. Variables spéciales des expressions régulières▲
Les variables spéciales suivantes sont associées à la recherche de motifs. Elles sont visibles tout au long du contexte dans lequel la recherche a lieu (hormis $*, qui est dépréciée). Autrement dit, elles se comportent comme si elles étaient déclarées avec local, vous n'avez donc pas besoin de les déclarer ainsi vous-même. Voir le chapitre 5, Reconnaissance de motifs.
$*
$chiffres
@+ (@LAST_MATCH_END)
@-(@LAST_MATCH_START)
$+ ($LAST_PAREN_MATCH)
$^R ($LAST_REGEXP_CODE_RESULT)
$& ($MATCH)
$' ($POSTMATCH)
$' ($PREMATCH)28-1-b. Variables spéciales des handles de fichiers▲
Ces variables spéciales n'ont jamais besoin d'être mentionnées dans un local car elles se réfèrent toujours à des valeurs appartenant au handle de sortie actuellement sélectionné — chaque handle de fichier garde son propre jeu de valeurs. Quand on sélectionne un autre handle de fichier, l'ancien garde ses valeurs et les variables reflètent alors les valeurs du nouveau handle de fichier. Voir aussi le module FileHandle dans le chapitre 32, Modules standards.
$| ($AUTOFLUSH, $OUTPUT_AUTOFLUSH)
$-($FORMAT_LINES_LEFT)
$= ($FORMAT_LINES_PER_PAGE)
$~ ($FORMAT_NAME)
$% ($FORMAT_PAGE_NUMBER)
$^ ($FORMAT_TO_NAME)28-1-c. Variables spéciales par paquetage▲
Ces variables spéciales existent séparément dans chaque paquetage. Il n'est pas besoin de les localiser, puisque sort le fait automatiquement pour $a et $b, et qu'il est probablement préférable de laisser les autres se débrouiller toutes seules (cependant si vous employez use strict, vous devrez les déclarer avec our).
$a
$b
@EXPORT
@EXPORT_OK
%EXPORT_TAGS
%FIELDS @ISA
%OVERLOAD
$VERSION28-1-d. Variables spéciales pour le programme entier▲
Ces variables sont vraiment globales au sens exact du terme — elles signifient la même chose dans chaque paquetage, car elles sont toutes localisées de force dans le paquetage
main lorsqu'elles sont non qualifiées (sauf pour @F, qui est spéciale dans main, mais pas forcée). Si vous voulez une copie temporaire de l'une d'entre elles, vous devez la localiser dans le contexte dynamique courant.
%ENV $< (UID, $REAL_USER_ID)
%INC $> (EUID, $EFFECTIVE_USER_ID)
%SIG $? ($CHILD_ERROR)
%! $@ ($EVAL_ERROR)
%^H $[
$\ ($ORS, $OUTPUT_RECORD_SEPARATOR)
@_ $] ($OLD_PERL_VERSION)
@ARGV $^A ($ACCUMULATOR)
@F $^C ($COMPILING)
@INC $^D ($DEBUGGING)
$^E ($EXTENDED_OS_ERROR)
$_ ($ARG) $^F ($SYSTEM_FD_MAX)
$0 ($PROGRAM_NAME) $^H
$ARGV $^I ($INPLACE_EDIT)
$^L ($FORMA_FORMFEED)
$! ($ERRNO, $OS_ERROR) $^M
$" ($LIST_SEPARATOR) $^O ($OSNAME)
$# $^P ($PERLDB)
$$ ($PID, $PROCESS_ID) $^R ($LAST_REGEXP_DOC_RESULT)
$( ($GID, $REAL_GROUP_ID) $^S ($EXCEPTION_BEING_CAUGHT)
$) ($EGID, $EFFECTIVE_GROUP_ID) $^T ($BASETIME)
$, ($OFS, $OUTPUT_FIELD_SEPARATOR) $^V ($PERL_VERSION)
$. ($NR, $INPUT_LINE_NUMBER) $^W ($WARNING)
$/ ($RS, $INPUT_RECORD_SEPARATOR) ${^WARNING_BITS}
$: ($FORMAT_LINE_BREAK_CHARACTERS) ${^WIDE_SYSTEM_CALLS}
$; ($SUBSEP, $SUBSCRIPT_SEPARATOR) $^X ($EXECUTABLE_NAME)28-1-e. Handles de fichiers spéciaux par paquetage▲
Sauf pour DATA, qui est toujours particulier à un paquetage, les handles de fichiers suivants sont toujours considérés comme étant dans main lorsqu'ils ne sont pas pleinement qualifiés dans un autre paquetage.
28-1-f. Fonctions spéciales par paquetage▲
Les noms des routines suivantes ont une signification spéciale pour Perl. Elles sont toujours appelées implicitement suite à un événement, comme l'accès à une variable liée ou l'appel d'une fonction indéfinie. Nous ne les décrirons pas dans ce chapitre puisqu'elles sont largement couvertes par ailleurs dans cet ouvrage.
Fonction indéfinie appelant une interception (voir le chapitre 10, Paquetages):
- AUTOLOAD
Achèvement des objets moribonds (voir le chapitre 12, Objets):
- DESTROY
Objets d'exception (voir die dans le chapitre suivant) :
- PROPAGATE
Fonctions d'autoinitialisation et d'autonettoyage (voir le chapitre 18, Compilation):
Méthodes de liaison (voir le chapitre 14) :
- BINMODE, CLEAR, CLOSE, DELETE, EOF, EXISTS, EXTEND, FETCH, FETCHIZE, FILENO, FIRSTKEY, GETC, NEXTKEY, OPEN, POP, PRINT, PRINTF, PUSH, READ, READLINE, SEEK, SHIFT, SPLICE, STORE, STORESIZE, TELL, TIEARRAY, TIEHANDLE, TIEHASH, TIESCALAR, UNSHIFT, WRITE
28-2. Variables spéciales dans l'ordre alphabétique▲
Nous avons classé alphabétiquement ces entrées selon le nom long des variables. Si vous ne connaissez pas le nom long d'une variable, vous pouvez le trouver dans la section précédente. (Les variables sans nom alphabétique sont classées au début.)
Pour éviter les répétitions, chaque description de variable débute avec une, ou plusieurs, des annotations suivantes.
|
Annotation |
Signification |
|---|---|
|
XXX |
Dépréciée, ne pas utiliser pour quelque chose de nouveau. |
|
NON |
Non Officiellement Nommée (pour usage interne seulement). |
|
GLO |
Réellement globale, partagée par tous les paquetages. |
|
PKG |
Globale au paquetage ; chaque paquetage peut redéfinir sa propre |
|
AHF |
Attribut de handle de fichier ; un attribut par objet d'entrée/sortie. |
|
DYN |
Automatiquement dans un contexte dynamique (entraîne GLO). |
|
LEX |
Dans un contexte lexicographique à la compilation. |
|
LEC |
En lecture seule ; lève une exception si vous tentez de modifier. |
Quand plus d'un symbole ou plus d'un nom de variable est mentionné, seul le nom court est disponible par défaut. En utilisant le module English, les synonymes plus longs sont disponibles dans le paquetage courant et uniquement dans le paquetage courant, même si la variable est marquée avec [GLO].
Les entrées de la forme méthode HANDLE EXPR montrent l'interface orientée objet des variables pourvues par FileHandle et les différents modules IO::. (Si vous préférez, vous pouvez aussi utiliser la notation HANDLE->méthode(EXPR)). Ceci vous permet d'éviter d'appeler select pour changer le handle de sortie par défaut avant d'examiner ou de modifier la variable en question. Chacune de ces méthodes renvoie l'ancienne valeur de l'attribut du FileHandle ; l'attribut prend une nouvelle valeur si l'on positionne l'argument EXPR. Si cet argument n'est pas fourni, la plupart des méthodes ne modifient pas la valeur courante, excepté pour autoflush, qui suppose que l'argument vaut 1, uniquement pour se distinguer.
_ (souligné)
- [GLO] Il s'agit du handle de fichier spécial utilisé pour garder en cache les informations obtenues lors du dernier
stat,lstatou du dernier opérateur de test de fichier (comme-w$fileou-d$file) ayant réussi.
$chiffres
- [DYN, LEC] Les variables numérotées
$1,$2, etc. (aussi élevé que vous le désirez)(197) contiennent le texte trouvé par le jeu de parenthèses correspondant dans la dernière recherche de motifs du contexte dynamique actif à cet instant. (Mnémonique : comme \chiffres).
$[
- [XXX, LEX] L'index du premier élément d'un tableau et du premier caractère d'une sous-chaîne. 0 par défaut, mais nous utilisons cette variable positionnée à 1 pour que Perl se comporte mieux comme awk (ou FORTRAN) au moment d'indicer et d'évaluer les fonctions
indexetsubstr. Parce qu'on a trouvé cette variable dangereuse, l'affectation de $[ est maintenant traitée comme une directive de compilation dans un contexte lexical et ne peut pas influencer le comportement de tout autre fichier. (Mnémonique : [ précède les indices).
$#
- [XXX, GLO] N'utilisez pas cette variable ; préférez
printf.$#contient le format de sortie des nombres imprimés, dans une tentative peu convaincante d'émulation de la variable OFMT de awk. (Mnémonique :#en anglais signifie numéro, mais si vous êtes pointilleux, mieux vaut oublier tout ceci afin de ne pas trop parasiter votre programme et éviter ainsi un sermon).
$*
- [XXX, GLO] Et bien, trois variables dépréciées à la suite ! Celle-ci peut (mais ne doit pas) être positionnée à vrai pour que Perl assume un
/m sur chaque recherche de motif qui n'a pas explicitement de/s. (Mnémonique :*correspond à de multiples quantités).
$a
- [PKG] Cette variable est utilisée par la fonction
sortpour contenir le premier élément de chaque paire de valeurs à comparer ($best le second élément de chaque paire). Le paquetage pour$aest le même que celui où l'opérateursorta été compilé, qui n'est pas nécessairement celui dans lequel la fonction de comparaison a été compilée. Cette variable est implicitement localisée dans le bloc de comparaison desort. Comme elle est globale, elle est exempte des messages de protestation de use strict. Puisque c'est un alias pour la valeur du tableau concerné, on pourrait penser qu'on peut la modifier, n'en faites rien. Voir la fonctionsort.
$ACCUMULATOR $^A
- [GLO] La valeur courante de l'accumulateur de
writepour les lignes deformat. Un format contient contient des commandesformlinequi émettent leur résultat dans$^A. Après avoir appelé son format,writeaffiche le contenu de$^Aet le vide. On ne voit donc jamais le contenu de$^Aà moins d'appelerformlinesoi-même pour l'examiner. Voir la fonctionformline.
$ARG $_
-
[GLO] L'espace d'entrée et de recherche de motifs par défaut. Ces paires sont équivalentes :
-
Voici les endroits où Perl prend
$_si l'on ne spécifie pas d'opérande aux fonctions et opérateurs :- Des fonctions de listes comme
printetunlinket des fonctions unaires commeord,poset int, ainsi que tous les tests de fichier (sauf pour-t, qui prend STDIN par défaut). Toutes les fonctions qui prennent par défaut$_sont repérées en tant que telles dans le chapitre 29, Fonctions. - Les opérations de recherche de motifs m
//et s///et les opérations de transformation y///et tr///, lorsqu'on les utilise sans l'opérateur=~. - La variable d'itération dans une boucle foreach (même si on l'épelle for ou lorsqu'on l'utilise avec un modificateur d'instruction) si aucune autre variable n'est fournie.
- La variable d'itération implicite dans les fonctions
grepetmap. (Il n'y a aucun moyen de spécifier une variable différente pour ces fonctions.) -
L'endroit par défaut où est placé un enregistrement en entrée quand le résultat d'une opération
<HF>, readline ouglobest testé en tant qu'unique critère d'un while. Cette affectation ne se produit pas en dehors d'un while ou si un quelconque élément additionnel est inclus dans l'expression while.
- Des fonctions de listes comme
- (Mnémonique : le souligné est l'opérande sous-jacent de certaines opérations).
@ARG @_
- [GLO] Dans un sous-programme, ce tableau contient la liste d'arguments passée à ce sous-programme. Voir le chapitre 6, Sous-programmes. Un
splitdans un contexte scalaire s'applique sur ce tableau, mais cet usage est déprécié.
ARGV
- [GLO] Le handle de fichier spécial qui parcourt les noms de fichiers de la ligne de commande et contenus dans
@ARGV. Habituellement, on l'écrit comme le handle de fichier nul dans l'opérateur d'angle<>.
$ARGV
- [GLO] Contient le nom du fichier courant lorsqu'on lit depuis le handle de fichier ARGV en utilisant les opérateurs
<>ou readline.
@ARGV
- [GLO] Le tableau contenant les arguments de la ligne de commande prévus pour le script. Remarquez que
$#ARGVest généralement le nombre d'arguments moins un, puisque$ARGV[0] est le premier argument et non le nom de la commande ; utilisezscalar@ARGVpour le nombre d'arguments du programme. Voir$0pour le nom du programme.
- [GLO] Ce handle de fichier spécial est utilisé lorsqu'on traite le handle de fichier ARGV avec l'option
-i ou la variable$^I. Voir l'option-i dans le chapitre 19, L'interface de ligne de commande.
$b
- [PKG] Cette variable, sœur de
$a, est utilisée dans les comparaisons avecsort. Voir$aet la fonctionsortpour les détails.
$BASETIME $^T
- [GLO] Le moment où le script a commencé à tourner, en secondes depuis l'origine (le début de 1970, pour les systèmes Unix). Les valeurs renvoyées par les tests de fichier
-M,-A et-C sont basées sur ce moment.
$CHILD_ERROR $?
- [GLO] Le statut renvoyé par la dernière fermeture de tube, la dernière commande en apostrophe inverse (``) ou les fonctions
wait,waitpidousystem. Remarquez qu'il ne s'agit pas simplement du code retour, mais le mot entier de 16-bits du statut renvoyé par les appels système sous-jacents wait(2) ou waitpid(2) (ou leurs équivalents). Ainsi, la valeur de retour du sous-programme se trouve dans l'octet de poids fort, c'est-à-dire,$?>>8; dans l'octet de poids faible,$?&127donne quel signal (s'il y en a un) a tué le processus, alors que$?&128rapporte si sa disparition a produit un core dump. (Mnémonique : similaire à$?dans sh et sa progéniture). - À l'intérieur d'un bloc END,
$?contient la valeur qui va être donnée à exit. Vous pouvez modifier$?dans un END pour changer le statut retour du script. Sous VMS, le pragma use vmsish'status'fait que$?reflète le véritable statut de retour de VMS, au lieu de l'émulation par défaut du statut POSIX. - Si la variable h_errno est supportée en C, sa valeur numérique est retournée via
$?si l'une des fonctions gethost*() échoue.
$COMPILING $^C
- [GLO] La valeur courante de l'argument interne associé à l'option -c, principalement utilisé avec -MO et l'outil perlcc(1) pour laisser le code modifier son comportement lorsqu'il est compilé pour la génération de code. Par exemple, vous pouvez avoir envie d'exécuter AUTOLOAD pendant la phase de compilation, au lieu d'utiliser le chargement différé habituel, de sorte que le code sera généré immédiatement. Voir le chapitre 18.
DATA
- [PKG] Ce handle de fichier spécial se réfère à tout ce qui suit soit le token __END__ ou le token __DATA__ dans le fichier courant. Le token __END__ ouvre toujours le handle de fichier main::DATA, ainsi il est utilisé dans le programme principal. Le token __DATA__ ouvre le handle de fichier DATA dans n'importe quel paquetage effectif à ce moment. Ainsi différents modules peuvent posséder leur propre handle de fichier DATA, puisqu'ils ont (on le présume) des noms de paquetage différents.
$DEBUGGING $^D
- [GLO] La valeur courante des arguments internes, positionnés par l'option -D de la ligne de commande ; voir le chapitre 19 pour les valeurs de bit. (Mnémonique : valeur de l'option -D).
$EFFECTIVE_GROUP_ID $EGID $)
-
[GLO] Le gid (group ID) effectif de ce processus. Si vous vous trouvez sur une machine qui accepte que l'on soit membre de plusieurs groupes simultanément,
$) donne une liste des groupes concernés, séparés par des espaces. Le premier nombre est celui qui est renvoyé par getgid(2), et les suivants par getgroups(2), l'un d'entre eux pouvant être identique au premier nombre.
De même, une valeur assignée à$) doit également être une liste de nombres séparés par des espaces. Le premier nombre est utilisé pour positionner le GID effectif, et les autres (s'il y en a) sont passés à l'appel système setgroups(2). Pour obtenir l'effet d'une liste vide pour setgroups, il suffit de répéter le nouveau GID effectif ; par exemple, pour forcer un GID effectif de 5 et une liste vide effective pour setgroups :Sélectionnez$)="5 5"; - (Mnémonique : les parenthèses sont employées pour regrouper les choses. Le GID effectif est le groupe qui est fermement le bon, si votre script est lancé avec setgid. Il faut donc une parenthèse fermante). Remarque :
$<,$>,$( et$) ne peuvent être modifiés que sur des machines qui supportent la routine système set-id correspondante.$( et$) ne peuvent être échangés que sur des machines supportant setregid(2).
$EFFECTIVE_USER_ID $EUID $>
- [GLO] L'UID effectif de ce processus tel que renvoyé par l'appel système geteuid(2). Exemple :
$< = $>; # mettre l'uid réel à l'uid effectif
($<, $>) = ($>, $<); # échanger l'uid réel et l'uid effectif- (Mnémonique : il s'agit de l'UID vers lequel vous êtes parvenus si votre script est lancé avec setuid). Remarque :
$<et$>ne peuvent être échangés que sur des machines qui supportent setreuid(2). Parfois même, cela ne suffit pas.
%ENV
-
[GLO] Le hachage contenant les variables de l'environnement courant. Modifier une valeur dans
%ENVchange l'environnement à la fois pour votre processus et pour les processus fils lancés après l'affectation. (On ne peut modifier l'environnement d'un processus parent sur aucun système ressemblant à Unix).Sélectionnez$ENV{PATH}="/bin:/usr/bin;"$ENV{PAGER}="less";$ENV{LESS}="MQeicsnf";# nos options favorites pour less(1)system"man perl";# récupère les nouveaux paramètres -
Pour supprimer quelque chose dans votre environnement, soyez sûr d'utiliser la fonction
deleteau lieu d'unundefsur la valeur du hachage. - Remarquez que les processus qui sont lancés par une entrée de crontab(5) héritent d'un jeu de variables d'environnement particulièrement appauvri. (Si votre programme fonctionne parfaitement depuis la ligne de commande, mais pas avec cron, c'est probablement la cause). Remarquez également que vous devez modifier
$ENV{PATH},$ENV{SHELL},$ENV{BASH_ENV}, et$ENV{IFS}si votre script est lancé avec setuid. Voir le chapitre 23, Sécurité.
$EVAL_ERROR $@
- [GLO] L'exception courante levée ou le message d'erreur de syntaxe Perl de la dernière opération eval. (Mnémonique : quelle est « l'adresse » de la dernière erreur de syntaxe ?) Contrairement à
$!($OS_ERROR), qui est positionné sur un échec, mais pas nettoyé lors d'un succès, on a la garantie que$@est bien positionné (à une valeur vraie) si le dernier eval a engendré une erreur de compilation ou une exception à l'exécution, mais aussi la garantie que$@est nettoyé (à une valeur fausse) si aucun de ces problèmes ne survient. - Les messages d'avertissement ne sont pas collectés dans cette variable. Cependant, vous pouvez installer une routine destinée à traiter les avertissements en positionnant
$SIG{__WARN__}comme décrit plus loin dans cette section. -
Remarquez que la valeur de
$@peut être un objet exception plutôt qu'une chaîne. Dans ce cas, vous pouvez toujours le traiter comme une chaîne pourvu que l'objet exception ait défini une surcharge de la transformation en chaîne (N.d.T. stringification overload) pour sa classe. Si vous propagez une exception en écrivant : - alors un objet exception appellera
$@->PROPAGATE pour savoir que faire. (Une chaîne exception ajoutera une ligne « propagée à » à la chaîne.)
$EXCEPTIONS_BEING_CAUGHT $^S
- [GLO] Cette variable reflète la situation courante de l'interpréteur, en retournant vrai à l'intérieur d'un eval, faux sinon. Elle est indéfinie si l'analyse de l'unité courante de compilation n'est pas encore finie, ce qui peut être le cas dans les gestionnaires de signaux
$SIG{__DIE__}et$SIG{__WARN__}. (Mnémonique : situation de eval.)
$EXECUTABLE_NAME $^X
- [GLO] Le nom avec lequel le binaire perl lui-même a été exécuté, provient de argv[
0] en C.
@EXPORT
- [PKG] Ce tableau est consulté par la méthode import du module Exporter pour trouver la liste des variables et sous-programmes d'autres paquetages qui doivent être exportés par défaut quand le module est utilisé (avec use) ou lorsqu'on emploie l'option d'importation :DEFAULT. Il n'est pas exempt des complaintes de use strict, ainsi il doit être déclaré avec our ou pleinement qualifié avec le nom du paquetage si vous avez activé ce pragma. De toute façon, toutes les variables qui commencent par « EXPORT » sont exemptes des avertissements comme quoi elles ne sont utilisées qu'une seule fois. Voir le chapitre 11, Modules.
@EXPORT_OK
- [PKG] Ce tableau est consulté par la méthode import du module Exporter pour déterminer si une requête d'importation est légale. Il n'est pas exempt des complaintes de use strict. Voir le chapitre 11.
%EXPORT_TAGS
- [PKG] Ce hachage est consulté par la méthode import du module Exporter lorsqu'on requiert un symbole d'importation débutant par deux points, comme dans use POSIX
":queue". Les clefs sont les tags commençant par deux points, mais sans les deux points (comme sys_wait_h). Les valeurs doivent être des références à des tableaux contenant les symboles à importer lorsqu'on requiert ce tag ; toutes les valeurs du hachage doivent également apparaître soit dans@EXPORT, soit dans@EXPORT_OK. Ce hachage n'est pas exempt des complaintes de use strict. Voir le chapitre 11.
$EXTENDED_OS_ERROR $^E
- [GLO] Information d'erreur spécifique au système d'exploitation courant. Sous Unix,
$^Eest identique à$!($OS_ERROR), mais elle diffère sous OS/2, VMS, les systèmes Microsoft et MacPerl. Consultez les informations sur votre portage pour les spécificités. Les mises en garde mentionnées dans la description de$!s'appliquent aussi à$^Een général . (Mnémonique : explication étendue d'erreur.)
@F
- [PKG] Le tableau dans lequel les lignes d'entrée sont éclatées quand la ligne de commande comporte l'option -a est donnée. Si l'option -a n'est pas utilisée, ce tableau n'a aucune signification particulière (ce tableau n'est en fait que
@main::F et non dans tous les paquetages à la fois).
%FIELDS
- [NON, PKG] Ce hachage est utilisé en interne par le pragma use fields pour déterminer les champs légaux courants dans un objet hachage. Voir use fields, use base et Déclarations de champ avec use fields au chapitre 12.
format_formfeed HANDLE EXPR $FORMAT_FORMFEED $^L
- [GLO] Ce qu'une fonction
writegénère implicitement pour effectuer un saut de page avant d'émettre un en-tête de page."\f"par défaut.
format_lines_left HANDLE EXPR $FORMAT_LINES_LEFT $-
- [AHF] Le nombre de lignes restantes dans la page du canal de sortie actuellement sélectionné, pour une utilisation avec la déclaration
formatet la fonctionwrite. (Mnémonique : lines_on_pages lines_printed.)
format_lines_per_page HANDLE EXPR $FORMAT_LINES_PER_PAGE $=
- [AHF] La longueur de la page courante (lignes imprimables) du canal de sortie actuellement sélectionné, pour une utilisation avec
formatetwrite. 60 par défaut. (Mnémonique : est composé des lignes horizontales.)
format_line_break_characters HANDLE EXPR $FORMAT_LINE_BREAK_CHARACTERS $:
- [GLO] Le jeu de caractères courant d'après lequel une chaîne peut être scindée pour remplir les champs de continuation (commençant par
^) dans un format."\n-"par défaut, pour couper sur l'espace ou le tiret. (Mnémonique : un « deux-points » en poésie fait partie d'une ligne. Maintenant il ne vous reste plus qu'à vous rappeler du procédé mnémonique...)
format_name HANDLE EXPR $FORMAT_NAME $~
- [AHF] Le nom du format de rapport courant pour le canal de sortie actuellement sélectionné. Le nom du handle du fichier par défaut. (Mnémonique : cette variable tourne après
$^.)
format_page_number HANDLE EXPR $FORMAT_PAGE_NUMBER $%
- [AHF] Le numéro de page courant du canal de sortie actuellement sélectionné, pour une utilisation avec
formatetwrite. (Mnémonique : % est le registre de numéro de page dans troff(1). Quoi, vous ne savez pas ce qu'est troff ?)
format_top_name HANDLE EXPR $FORMAT_TOP_NAME $^
- [AHF] Le nom du format d'en-tête de page courant pour le canal de sortie actuellement sélectionné. Le nom du handle de fichier auquel est ajouté _TOP par défaut. (Mnémonique : pointe vers le haut de la page.)
$^H
- [NON, LEX] Cette variable contient les bits de statut du contexte lexical (autrement dit, des indications) pour le parseur Perl. Cette variable est strictement réservée à une utilisation interne. Sa disponibilité, son comportement et son contenu sont sujets à modifications sans préavis. Si vous y touchez, vous périrez indubitablement d'une mort horrible causée par une détestable maladie tropicale inconnue de la science. (Mnémonique : nous ne vous donnerons aucune indication.)
%^H
- [NON, LEX] Le hachage %^H fournit la même sémantique de contexte lexical que $^H, le rendant utile pour l'implémentation des pragmas de contexte lexical. Lisez les affreuses mises en garde énoncées pour $^H, et ajoutez-y le fait que cette variable est encore expérimentale.
%INC
- [GLO] Le hachage contenant les entrées de noms de fichiers pour chaque fichier Perl chargé via do FICHIER, require ou use. La clef est le nom du fichier spécifié, et la valeur est l'endroit où le fichier a été véritablement trouvé. L'opérateur require utilise ce tableau pour déterminer si un fichier donné a déjà été chargé. Par exemple :
% perl -MLWP::Simple -le 'print $INC{LWP/Simple.pm}'
/usr/local/lib/perl/5.6.0/lib/site_perl/LWP/Simple.pm@INC
/usr/local/lib/perl5/5.6.0/i386-linux
/usr/local/lib/perl5/5.6.0
/usr/local/lib/perl5/site_perl/5.6.0/i386-linux /usr/local/lib/perl5/site_perl/5.6.0 /usr/local/lib/perl5/site_perl/5.00552/i386-linux
/usr/local/lib/perl5/site_perl/5.00552 /usr/local/lib/perl5/site_perl/5.005/i386-linux /usr/local/lib/perl5/site_perl/5.005
/usr/local/lib/perl5/site_perl- [GLO] Le tableau contenant la liste des répertoires où les modules Perl peuvent être trouvés par do FICHIER, require ou use. Initialement, il se compose des arguments de n'importe quelle option -I de la ligne de commande et des répertoires de la variable d'environnement PERL5LIB, suivis par les bibliothèques par défaut de Perl, comme :
- suivies par « . », qui représente le répertoire courant. Si vous avez besoin de modifier cette liste depuis votre programme, essayer le pragma use lib, qui non seulement modifie la variable durant la compilation, mais qui fait également des ajouts dans tous les répertoires dépendant de l'architecture (comme ceux qui contiennent les bibliothèques partagées utilisées par les modules XS) :
$INPLACE_EDIT $^I
-
[GLO] La valeur courante de l'extension d'édition sur place. Employez
undefpour désactiver l'édition sur place. Vous pouvez utiliser ceci à l'intérieur de votre programme pour obtenir le même comportement qu'avec l'option -i. Par exemple, pour produire l'équivalent de cette commande :Sélectionnez%perl-i.orig-pe's/machin/truc/g'*.c -
vous pouvez utiliser le code suivant dans votre programme :
- (Mnémonique : la valeur de l'option -i.)
$INPUT_LINE_NUMBER $NR $.
- [GLO] Le numéro de l'enregistrement courant (généralement le numéro de ligne) pour le dernier handle de fichier dans lequel vous avez lu (ou sur lequel vous avez appelé
seekoutell). La valeur peut être différente de la ligne physique actuelle, selon la définition à ce moment de ce qu'est une « ligne » — voir$/($INPUT_RECORD_NUMBER) pour la manière de choisir cette définition). Uncloseexplicite sur un handle de fichier réinitialise à zéro le numéro de ligne. Comme<>n'effectue jamais decloseexplicite, les numéros de ligne augmentent en parcourant les fichiers ARGV (mais voyez les exemples deeof). La mise en local de$.a également pour effet de mettre en local la notion que Perl a du « dernier handle de fichier lu ». (Mnémonique : de nombreux programmes utilisent « . » pour le numéro de ligne courant.)
$INPUT_RECORD_SEPARATOR $RS $/
- [GLO] Le séparateur d'enregistrement en entrée, le caractère « saut de ligne » par défaut, celui qui est consulté par la fonction readline, l'opérateur
<HF>, et la fonctionchomp. Il se comporte comme la variable RS de awk, et, s'il contient la chaîne nulle, traite une ou plusieurs lignes blanches comme des délimiteurs d'enregistrements. (Mais une ligne vide ne doit contenir aucun espace caché ou aucune tabulation). Vous pouvez affecter à cette variable une chaîne de plusieurs caractères pour correspondre à un séparateur sur plusieurs caractères, mais vous ne pouvez pas lui affecter un motif — il faut bien que awk soit meilleur dans un domaine. - Remarquez que le fait d'affecter
"à$/signifie quelque chose de sensiblement différent que de lui affecter"", si le fichier contient des lignes blanches consécutives.""traitera deux lignes blanches consécutives ou plus comme une seule ligne blanche."\n\n"signifie que Perl suppose aveuglément qu'une troisième ligne appartient au paragraphe suivant. -
Si l'on rend carrément
$/indéfini, la prochaine opération de lecture de ligne avalera le reste du fichier dans une seule valeur scalaire :Sélectionnezundef$/;# enclenche le mode "cul-sec"$_=<HF>;# maintenant le fichier entier est icis/\n[ \t]+/ /g;# aplatit les lignes indentées -
Si vous utilisez la construction while (
<>) pour accéder au handle de fichier ARGV alors que$/vautundef, chaque lecture prend le fichier suivant :Sélectionnezundef$/; while (<>){# $_ contient le prochain fichier dans sa totalité...} -
Bien que nous ayons employé
undefci-dessus, il est plus sûr de rendre$/indéfini en utilisant local :Sélectionnez{local$/;$_=<HF>;} -
Affecter à
$/une référence soit à un entier, soit à un scalaire contenant un entier, soit à un scalaire convertible en entier, fera que les opérations readline et<HF>liront des enregistrements de taille fixe (avec la taille maximale d'enregistrement valant l'entier référencé) au lieu d'un enregistrement de taille variable terminé par une chaîne particulière. Ainsi, ceci :Sélectionnez$/=32768;# ou \"32768" ou \$var_scalaire_contenant_32768 open(FICHIER, $monfichier);$enregistrement=<FICHIER>; -
lira un enregistrement d'au plus 32768 octets depuis le handle de FICHIER. Si vous ne lisez pas un fichier structuré par enregistrement (N.d.T. record-oriented file) (ou si votre système d'exploitation ne connaît pas les fichiers structurés par enregistrement), alors vous aurez vraisemblablement un morceau de données à chaque lecture. Si un enregistrement est plus volumineux que la taille que vous avez fixée, vous recevrez l'enregistrement découpé en plusieurs tranches. Le mode par « enregistrement » ne se marie bien avec le mode par ligne que sur les systèmes où les entrées/sorties standards fournissent une fonction read(3) ; VMS est une exception notoire.
- Un appel à
chomplorsque$/est positionnée sur le mode par enregistrement — ou lorsqu'elle n'est pas définie — n'a aucun effet. Voir aussi les options de la ligne de commande -0 (le chiffre) et -l (la lettre) dans le chapitre 19. (Mnémonique : / est utilisé pour séparer les lignes lorsque l'on cite de la poésie.)
@ISA
- [PKG] Ce tableau contient les noms des autres paquetages dans lesquels il faut rechercher une méthode qui n'a pu être trouvée dans le paquetage courant. Autrement dit, il contient les classes de base du paquetage. Le pragma use base positionne ceci implicitement. Il n'est pas exempt des complaintes de use strict. Voir le chapitre 12.
@LAST_MATCH_END @+
- [DYN,LEC] Ce tableau contient les positions des fins des sous-éléments de la dernière recherche de correspondance ayant réussi dans le contexte dynamique actuellement actif.
$-[0] est la position à la fin de la correspondance entière. Il s'agit de la même valeur que celle retournée par la fonctionposlorsqu'on l'appelle avec comme paramètre la variable sur laquelle s'est faite la recherche de correspondance. Lorsque nous parlons de « la position de la fin », nous voulons réellement dire la position du premier caractère qui suit la fin de ce qui a correspondu, ainsi nous pouvons soustraire les positions de début aux positions de fin pour obtenir la longueur. Le nième élément de ce tableau contient la position du nième élément de la correspondance, ainsi$+[1] est la position où finit$1,$+[2] la position où$2finit, etc. Vous pouvez utiliser$#+pour déterminer combien d'éléments ont réussi à correspondre dans la dernière recherche. Voir aussi@-(@LAST_MATCH_START). -
Après une recherche de correspondance réussie sur une variable
$var:$'est identique àsubstr($var,0,$-[0])$&est identique àsubstr($var,$-[0],$+[0]-$-[0])$'est identique àsubstr($var,$+[0])$1est identique àsubstr($var,$-[1],$+[1]-$-[1])$2est identique àsubstr($var,$-[2],$+[2]-$-[2])$3est identique àsubstr($var,$-[3],$+[3]-$-[3]), etc.
@LAST_MATCH_START @-
- [DYN,LEC] Ce tableau contient les positions des débuts des sous-éléments de la dernière recherche de correspondance ayant réussi dans le contexte dynamique actif.
$-[0] est la position au début de la correspondance entière. Le nième élément de ce tableau contient la position du nième élément de la correspondance, ainsi$-[1] est la position où débute$1,$-[2] la position où$2débute, etc. Vous pouvez utiliser$#-pour déterminer combien d'éléments ont réussi à correspondre dans la dernière recherche. Voir aussi@+(@LAST_MATCH_END).
$LAST_PAREN_MATCH $+
- [DYN, LEC] Cette variable renvoie ce qu'a trouvé la dernière recherche de parenthèse dans le contexte dynamique actuellement actif. C'est utile si l'on ne sait pas (ou si l'on ne s'en préoccupe pas) lequel des motifs parmi une alternative a été trouvé. (Mnémonique : Soyez positifs et regardez droit devant.) Exemple :
$rev = $+ if /Version: (.*)|Revision: (.*)/;$LAST_REGEXP_CODE_RESULT $^R
- [DYN] Cette variable contient le résultat du dernier morceau de code exécuté au sein d'une recherche de motifs réussie construite avec (
?{CODE}).$^Rvous donne un moyen d'exécuter du code et d'en retenir le résultat pour l'utiliser plus tard dans le motif, ou même encore après. - Comme le moteur d'expressions régulières de Perl se déplace tout au long du motif, il peut rencontrer de multiples expressions (
?{CODE}). Lorsque cela arrive, il retient chaque valeur de$^Rde manière à ce qu'il puisse restaurer l'ancienne valeur de$^Rsi plus tard il doit reculer avant l'expression. En d'autres termes,$^Rpossède un contexte dynamique au sein du motif, un peu comme$1et ses amis. - Ainsi,
$^Rn'est pas juste le résultat du dernier morceau de code exécuté au sein d'un motif. C'est le résultat du dernier morceau de code qui a conduit au succès de la correspondance. Un corollaire est que si la correspondance a échoué,$^Rreprendra la valeur qu'elle avait avant la correspondance. - Si le motif (
?{CODE}) est employé directement comme la condition d'un sous-motif (?(CONDITION)SI_VRAI|SI_FAUX),$^Rn'est pas valorisée.
$LIST_SEPARATOR $"
- [GLO] Lorsqu'un tableau ou une tranche est interpolé dans une chaîne entre guillemets (ou un équivalent), cette variable indique la chaîne à mettre entre les éléments individuels. Un espace par défaut. (Mnémonique : on peut espérer que c'est évident.)
$^M
-
[GLO] Par défaut, on ne peut pas intercepter un dépassement de mémoire. Toutefois, si votre perl a été compilé pour bénéficier de
$^M, vous pouvez l'utiliser comme un espace mémoire en cas d'urgence. Si votre Perl est compilé avec DPERL_EMERGENCY_SBRK et utilise le malloc de Perl, alors :Sélectionnez$^M='a'x(1<<16); -
allouera un tampon de 64K en cas d'urgence. Voir le fichier INSTALL dans le répertoire du code source de la distribution Perl pour les informations sur la manière d'activer cette option.
- En guise d'effet dissuasif pour l'emploi de cette fonctionnalité avancée, il n'y a pas de nom long avec use English pour cette variable (et nous ne vous dirons pas quel est le procédé mnémonique).
$MATCH $&
- [DYN, LEC] La chaîne trouvée par la dernière recherche de motif dans le contexte dynamique actuellement actif. (Mnémonique : comme
&dans certains éditeurs.)
$OLD_PERL_VERSION $]
-
[GLO] Renvoie la version + niveau_de_patch/1000. On peut l'utiliser pour déterminer au début du script si l'interpréteur Perl qui exécute le script est dans une plage de versions correcte. (Mnémonique : cette version de Perl est-elle dans le bon intervalle ? L'intervalle mathématique étant représenté par un crochet). Exemple :
- Voir aussi la documentation de use VERSION et require VERSION pour un moyen convenable d'échouer si l'interpréteur Perl est trop ancien. Voir
$^Vpour une représentation UTF-8 plus flexible de la version de Perl.
$OSNAME $^O
- [GLO] Cette variable contient le nom de la plate-forme (généralement du système d'exploitation) pour laquelle le binaire Perl courant a été compilé. Elle sert surtout à ne pas appeler le module Config.
$OS_ERROR $ERRNO $!
- [GLO] Dans un contexte numérique, donne la valeur courante de la dernière erreur d'appel système, avec toutes les restrictions d'usage. (Ce qui signifie qu'il vaut mieux ne pas attendre grand-chose de la valeur de
$!à moins qu'une erreur renvoyée n'indique spécifiquement une erreur système). Dans un contexte de chaîne,$!donne la chaîne du message d'erreur correspondant. Vous pouvez assigner un numéro d'erreur à$!si, par exemple, vous voulez que$!renvoie la chaîne correspondant à cette erreur particulière, ou si vous voulez positionner la valeur de sortie de die. Voir aussi le module Errno au chapitre 32. (Mnémonique : j'ai entendu qu'on venait de s'exclamer ?)
%OS_ERROR %ERRNO %!
-
[GLO] Ce hachage n'est défini que si vous avez chargé le module standard Errno décrit au chapitre 32. Une fois ceci fait, vous pouvez accéder à
%!en utilisant une chaîne d'erreur particulière, et sa valeur n'est vraie que s'il s'agit de l'erreur courante. Par exemple,$!{ENOENT}n'est vraie que si la variable C errno vaut à ce moment la valeur de ENOENT dans le#defineen C. C'est un moyen pratique d'accéder aux symboles spécifiques d'un fabricant.Sélectionnezautoflush HANDLE EXPR$OUTPUT_AUTOFLUSH$AUTOFLUSH$| -
[AHF] Si elle est positionnée à vrai, cette variable force un tampon à être vidé après chaque
print,printfetwritesur le handle de sortie actuellement sélectionné. (C'est ce que nous appelons vidage du tampon de commande. Contrairement à la croyance populaire, positionner cette variable ne désactive pas le vidage du tampon.) Elle vaut faux, par défaut, ce qui signifie sur de nombreux systèmes que STDOUT est vidé ligne par ligne si la sortie s'effectue sur terminal, et vidé bloc par bloc si ce n'est pas le cas, même dans les tubes et les sockets. Positionner cette variable est utile lorsque vous envoyez la sortie vers un tube, comme lorsque vous lancez un script Perl sous rsh(1) et que vous voulez en voir la sortie en temps réel. Si vous avez des données en attente d'être vidées dans le tampon du handle de fichier actuellement sélectionné lorsque cette variable est positionnée à vrai, ce tampon sera immédiatement vidé par effet de bord de l'affectation. Voir la forme à un seul argument deselectpour des exemples de contrôle du tampon sur les handles de fichier autres que STDOUT. (Mnémonique : quand vous voulez que vos tubes soient fumants.) - Cette variable n'a aucun effet sur le vidage du tampon d'entrée ; pour ceci, voir
getcdans le chapitre 29 ou l'exemple dans le module POSIX au chapitre 32.
$OUTPUT_FIELD_SEPARATOR $OFS $,
- [GLO] Le séparateur de champs en sortie (le limitateur, en fait) pour
print. Normalement,printaffiche simplement la liste d'éléments que vous spécifiez sans rien entre eux. Affecter cette variable fera spécifier à la variable OFS de awk ce qui doit être affiché entre les champs. (Mnémonique : ce qui est affiché quand il y a une « , » dans l'instructionprint.)
$OUTPUT_RECORD_SEPARATOR $ORS $\
- [GLO] Le séparateur d'enregistrement en sortie (le délimiteur, en fait) pour
print. Normalement,printaffiche simplement les champs séparés par des virgules que vous avez spécifiés, sans saut de ligne final, ni séparateur d'enregistrements. Affectez cette variable, comme vous auriez affecté la variable ORS de awk, pour spécifier ce qui est affiché à la fin duprint. (Mnémonique : vous assignez$\au lieu d'ajouter"\n"à la fin duprint. De même, cette variable ressemble à/, mais pour ce que Perl « retourne ».) Voir aussi l'option de la ligne de commande -l (pour « ligne ») dans le chapitre 19
%OVERLOAD
- [NON, PKG] Ces entrées de hachage sont positionnées en interne grâce au pragma use overload pour implémenter la surcharge d'opérateur pour les objets de la classe du paquetage courant. Voir le chapitre 13, Surcharge.
$PERLDB $^P
- [NON, GLO] La variable interne pour activer le débogueur Perl (perl -d).
$PERL_VERSION $^V
-
[GLO] La révision, la version, et la sous-version de l'interpréteur Perl, représentées comme une « chaîne de version » binaire. Les v-chaînes n'ont généralement pas de valeur numérique, mais cette variable est doublement valuée, et elle a une valeur numérique équivalente à l'ancienne variable
$] ; c'est-à-dire un nombre à virgule valant révision + version/1000 + sous-version/1000000. La valeur de la chaîne est composée des caractères UTF8 :chr($revision) .chr($version) .chr($sous_version). Cela signifie que$^Vn'est pas affichable. Pour l'afficher, vous devez écrire :Sélectionnezprintf"%vd",$^V; -
Dans les bons côtés, cela veut également dire que la comparaison normale de chaînes peut être utilisée pour déterminer si l'interpréteur Perl qui exécute votre script est dans une plage de versions correcte. (Ceci s'applique à n'importe quelle version numérique représentée avec des v-chaînes, pas seulement celles de Perl). Exemple :
- Voir la documentation de use VERSION et require VERSION pour un moyen convenable d'échouer si l'interpréteur Perl est plus ancien que ce que vous espériez. Voir aussi
$] pour la représentation originelle de la version de Perl.
$POSTMATCH $'
-
[DYN, LEC] La chaîne qui suit tout ce qui a été trouvé par la dernière recherche de motif réussie dans le contexte dynamique actuellement actif. (Mnémonique : ' suit souvent une chaîne protégée.) Exemple :
Sélectionnez$_='abcdefghi';/def/;print"$`:$&:$\n";# affiche abc:def:ghi - À cause du contexte dynamique, Perl ne peut pas savoir quel motif aura besoin de sauvegarder ses résultats dans ces variables, ainsi mentionner
$ou$'n'importe où dans le programme entraîne une pénalisation dans les performances pour toutes les recherches de motif tout au long du programme. Ce n'est pas un gros problème dans les programmes courts, mais vous voudrez probablement éviter cette paire de variables si vous écrivez le code d'un module réutilisable. L'exemple ci-dessus peut être réécrit de manière équivalente, mais sans le problème de performances globales, ainsi :
$_ = 'abcdefghi';
/(.*?)(def)(.*)/s # /s au cas où $1 contiendrait des sauts de ligne
print "$1:$2:$3\n"; # affiche abc:def:ghi$PREMATCH $`
- [DYN, LEC] La chaîne qui précède tout ce qui a été trouvé par la dernière recherche de motif réussie dans le contexte dynamique actuellement actif.
- (Mnémonique :
`précède souvent une chaîne protégée.) Voir la remarque sur les performances de$'ci-dessus.
$PROCESS_ID $PID $$
- [GLO] Le numéro de processus (PID) du Perl en train d'exécuter ce script. Cette variable est automatiquement mise à jour dans un
fork. En fait, vous pouvez même modifier$$vous-même ; ceci ne changera pas votre PID de toute façon. Ce serait un joli coup. (Mnémonique : comme pour les shells divers et variés). - Vous devez faire attention de ne pas utiliser la variable
$$n'importe où elle pourrait être malencontreusement interprétée comme une déréférence :$$alphanum. Dans ce cas, écrivez${$}alphanum pour distinguer de${$alphanum}.
$PROGRAM_NAME $0
- [GLO] Contient le nom du fichier contenant le script Perl en train d'être exécuté. L'affectation d'une valeur à
$0est magique : elle tente de modifier la zone d'arguments que voit le programme ps(1). Ceci est plus utile pour indiquer l'état courant du programme que pour cacher le programme en train de tourner. Mais cela ne fonctionne pas sur tous les systèmes. (Mnémonique : pareil que dans sh, ksh, bash, etc.)
$REAL_GROUP_ID $GID $(
- [GLO] Le GID (groupe ID) réel de ce processus. Si vous vous trouvez sur une machine qui accepte que l'on soit membre de plusieurs groupes simultanément,
$( donne une liste des groupes concernés, séparés par des espaces. Le premier nombre est celui qui est renvoyé par getgid(2), et les suivants par getgroups(2), l'un d'entre eux pouvant être identique au premier nombre. - De toute façon, une valeur assignée à
$( doit être un seul et unique nombre utilisé pour positionner le GID. Ainsi la valeur donnée par$( ne doit pas être réaffectée à$( sans la forcer à être numérique, comme en lui ajoutant zéro. Ceci parce que vous ne pouvez avoir qu'un seul groupe réel. Voir plutôt$) ($EFFECTIVE_GROUP_ID), qui vous permet d'affecter plusieurs groupes effectifs. - (Mnémonique : les parenthèses sont employées pour regrouper les choses. Le GID réel est le groupe que vous laissez ouvert derrière vous, si votre script est lancé avec setgid. Il faut donc une parenthèse ouvrante.)
$REAL_USER_ID $UID $<
- [GLO] L'UID réel de ce processus tel que renvoyé par l'appel système geteuid(2). Savoir si vous pouvez le changer et comment le faire est dépendant de la bonne volonté de l'implémentation sur votre système — voir les exemples dans
$>($EFFECTIVE_USER_ID). (Mnémonique : il s'agit de l'UID d'où vous provenez si votre script est lancé avec setuid.)
%SIG
-
[GLO] Le hachage utilisé pour installer les gestionnaires de divers signaux. (Voir la section Signaux dans le chapitre 16, Communication interprocessus). Par exemple :
Sélectionnezsub gestionnaire{my$sig=shift;# le 1er argument est le nom du signalsyswriteSTDERR,"SIG$sigdétecté--on quitte\n";# Évitez les entrées/sorties standards dans les# gestionnaires asynchrones pour supprimer le# core dump). (Même cette concaténation de chaîne# est risquée).closeLOG;# Ceci appelle une entrée/sortie standard, ainsi# il peut y avoir quand même un core dump !exit1;#, Mais puisque l'on quitte le programme,# il n'y a pas de mal à essayer.}$SIG{INT}=\&gestionnaire;$SIG{QUIT)=\&gestionnaire; ...$SIG{INT}='DEFAULT';# rétablir l'action par défaut$SIG{QUIT}='IGNORE';# ignorer SIGQUIT -
Le hachage
%SIGcontient des valeurs indéfinies correspondant aux signaux pour lesquels aucun gestionnaire n'a été affecté. Un gestionnaire peut être spécifié comme une référence de sous-programme ou comme une chaîne. Une chaîne dont la valeur n'est pas l'une des deux actions spéciales « DEFAULT » ou « IGNORE » est le nom d'une fonction, qui, si elle n'est pas qualifiée par un paquetage, est interprétée comme faisant partie du paquetage main. Voici quelques exemples :Sélectionnez$SIG{PIPE}="Plombier";# OK, on suppose qu'il s'agit de# main::plombier$SIG{PIPE}=\&Plombier;# bien, on utilise Plombier dans# le paquetage courant -
Certaines routines internes peuvent également être installées avec le hachage
%SIG. La routine indiquée par$SIG{__WARN__}est appelée quand un message d'avertissement va être affiché. Le message est passé en premier argument. La présence d'une routine __WARN__ provoque la suppression de l'affichage normal des messages d'avertissements vers STDERR. Vous pouvez vous en servir pour sauvegarder ces messages dans une variable ou pour transformer les avertissements en erreurs fatales, comme ceci : -
C'est équivalent à :
-
excepté le fait que le premier code a un contexte dynamique alors que le second a un contexte lexical. La routine indiquée par
$SIG{__DIE__}offre un moyen de changer une exception batracienne en exception princière avec un baiser magique, ce qui souvent ne fonctionne pas. La meilleure utilisation est l'exécution de choses de dernière minute lorsqu'un programme est sur le point de mourir suite à une exception non interceptée. Vous ne sauverez pas votre peau ainsi, mais vous aurez le droit de formuler une dernière volonté. -
Le message d'exception est passé en premier argument. Quand une routine __DIE__ revient, le traitement de l'exception continue comme il l'aurait fait en l'absence de l'interception, à moins que la routine d'interception ne quitte elle-même par un goto, une sortie de boucle ou un die. Le gestionnaire de __DIE__ est explicitement désactivé pendant l'appel, afin que vous puissiez vous-même appeler alors le véritable die depuis un gestionnaire de __DIE__. (Si ce n'était pas le cas, le gestionnaire s'appellerait lui-même indéfiniment.) Le gestionnaire pour
$SIG{__WARN__}procède de la même façon. -
Seul le programme principal doit positionner
$SIG{__DIE__}, pas le module. Ceci, car actuellement, même les exceptions qui sont interceptées continuent de déclencher un gestionnaire de$SIG{__DIE__}. Ceci est fortement déconseillé, car vous pourriez briser d'innocents modules qui ne s'attendaient pas à ce que les exceptions qu'ils prévoyaient soient altérées. Utilisez cette fonctionnalité uniquement en dernier ressort, et si vous le devez, mettez toujours devant un local pour limiter la durée du danger. - N'essayez pas de construire un mécanisme de gestion de signal à partir de cette fonctionnalité. Utilisez plutôt eval
{}pour intercepter les exceptions.
- [GLO] Le handle de fichier spécial pour la sortie d'erreur standard dans n'importe quel paquetage.
- [GLO] Le handle de fichier spécial pour l'entrée standard dans n'importe quel paquetage.
- [GLO] Le handle de fichier spécial pour la sortie standard dans n'importe quel paquetage.
$SUBSCRIPT_SEPARATOR $SUBSEP $;
-
[GLO] Le séparateur d'indices pour l'émulation de hachage multidimensionnels. Si vous vous référez à un élément de hachage comme :
Sélectionnez$machin{$a,$b,$c} -
cela veut vraiment dire :
Sélectionnez$machin{join($;,$a,$b,$c)} -
Mais ne mettez pas :
Sélectionnez@machin{$a,$b,$c}# une tranche de tableau -remarquez le @ -
qui signifie :
Sélectionnez($m{$a},$machin{$b},$machin{$c}) -
La valeur par défaut est
"\034", la même que SUBSEP dans awk. Remarquez que si vos clefs contiennent des données binaires, il ne peut exister de valeur sûre pour$;. -
(Mnémonique : virgule — le séparateur d'indices syntaxique — est un point-virgule. Oui, je sais, c'est un peu faible, mais
$,est déjà prise pour quelque chose de plus important.) - Bien que nous n'ayons pas découragé cette fonctionnalité, vous devez plutôt envisager d'utiliser maintenant de « véritables » hachages multidimensionnels, comme
$machin{$a}{$b}{$c}au lieu de$machin{$a,$b,$c}. Les simulations de hachages multidimensionnels peuvent cependant être plus faciles à trier et sont plus à même d'utiliser les fichiers DBM.
$SYSTEM_FD_MAX $^F
- [GLO] Le descripteur de fichier « système » maximum, généralement 2. Les descripteurs de fichiers systèmes sont passés aux nouveaux programmes durant un
exec, alors que les descripteurs supérieurs ne le sont pas. De plus, pendant unopen, les descripteurs de fichiers systèmes sont préservés même si leopenéchoue. (Les descripteurs de fichiers ordinaires sont fermés avant que l'ouverture ne soit tentée et le restent si elle échoue.) Remarquez que le statut de close-on-exec d'un descripteur de fichier se décide d'après la valeur de$^Fau moment duopen, et non au moment duexec. Évitez ceci en affectant à$^Fune valeur qui explose les compteurs :
$VERSION
- [PKG] Cette variable est accessible à tout moment où une version minimale acceptable d'un module est spécifiée, comme dans use UnModule
2.5. Si$UNMODULE::VERSION est inférieure, une exception est levée. Techniquement, c'est la méthode UNIVERSAL->VERSION qui inspecte cette variable, vous pouvez donc définir votre propre fonction VERSION dans le paquetage courant si vous voulez autre chose que le comportement par défaut. Voir le chapitre 12.
$WARNING $^W
- [GLO] La valeur booléenne courante de l'option globale d'avertissement (à ne pas confondre avec l'option globale d'asservissement, à propos de laquelle nous avons entendu de nombreux avertissements globaux). Voir aussi le pragma use warnings au chapitre 31, Modules de pragma, et les options de la ligne de commande -W et -X pour les avertissements dans un contexte lexical, qui ne sont pas affectés par cette variable. (Mnémonique : la valeur est liée à l'option -w.)
${^WARNING_BITS}
- [NON, GLO] L'ensemble courant des tests d'avertissement activés par le pragma use warnings. Voir use warnings au chapitre 31 pour de plus amples détails.
${^WIDE_SYSTEM_CALLS}
- [GLO} L'argument global qui permet à tous les appels systèmes effectués par Perl d'utiliser les API wide-characters natives du système, si elles sont disponibles. Il peut également être activé depuis la ligne de commande en utilisant l'option -C. La valeur initiale est généralement 0 pour assurer la compatibilité avec les versions de Perl antérieures à la 5.6, mais il peut être automatiquement mis à 1 par Perl si le système fournit une valeur par défaut modifiable par l'utilisateur (comme via
$ENV{LC_TYPE}). Le pragma use bytes annule les effets de cet argument dans le contexte lexical courant.
Et maintenant, attachez vos ceintures pour un grand chapitre...
29. Fonctions▲
Ce chapitre décrit les fonctions intrinsèques de Perl par ordre alphabétique(198) par souci pratique de référence. Chaque description de fonction commence par un bref résumé de la syntaxe pour cette fonction. Les noms de paramètre en CAPITALES OBLIQUES indiquent en fait les emplacements pour des expressions ; le texte qui suit le résumé de la syntaxe décrit ensuite la sémantique de ces arguments lorsqu'on les fournit (ou qu'on les omet).
Vous pouvez considérer que les fonctions sont des termes dans une expression au même titre que les littéraux et les variables. Ou bien, vous pouvez considérer qu'il s'agit d'opérateurs préfixes, qui traitent les arguments qui les suivent. D'ailleurs, nous utilisons le mot opérateur la plupart du temps.
Certains de ces opérateurs, euh, fonctions, prennent comme argument une LISTE. Les éléments de la LISTE doivent être séparés par des virgules (ou par =>, qui est juste une drôle de variété de virgule). Les éléments de la LISTE sont évalués dans un contexte de liste, ainsi chaque élément renvoie, soit un scalaire, soit une valeur de liste, selon sa sensibilité au contexte de liste. Chaque valeur renvoyée, que ce soit un scalaire ou une liste, sera interpolée comme étant un composant de la séquence entière de valeurs scalaires. C'est-à-dire que les listes sont mises à plat dans une seule liste. Du point de vue de la fonction qui reçoit les arguments, l'argument global LISTE est toujours une valeur de liste à une dimension. (Pour interpoler un tableau comme un élément unique, vous devez explicitement créer et interpoler à la place une référence à ce tableau.)
Les fonctions prédéfinies de Perl peuvent être utilisées avec ou sans parenthèses encadrant les arguments ; dans ce chapitre les résumés de syntaxe omettent les parenthèses. Si vous utilisez des parenthèses, la règle simple, mais parfois surprenante est la suivante : si ça ressemble à une fonction, alors c'est une fonction, ainsi la précédence n'a pas d'importance. Sinon, il s'agit d'un opérateur de liste ou d'un opérateur unaire, et la précédence devient importante. Soyez vigilants, car même si vous mettez un espace entre le mot-clef et sa parenthèse ouvrante, cela ne l'empêche pas d'être une fonction :
print 1+2*4; # Affiche 9.
print(1+2) * 4; # Affiche 3 !
print (1+2)*4; # Affiche aussi 3 !
print +(1+2)*4; # Affiche 12.
print ((1+2)*4); # Affiche 12.Perl peut vous avertir de cette situation, si vous le lancez avec l'option -w. Par exemple, la deuxième et la troisième ligne ci-dessus donneront ce type de messages :
print () interpreted as function at -line 2.
Useless use of integer multiplication (*) in void context at -line 2.Avec la simple définition de certaines fonctions, vous avez une latitude considérable dans la manière de passer des arguments. Par exemple, la façon la plus habituelle d'utiliser chmod est de passer les permissions du fichier (le mode) comme argument initial :
chmod 0644, @tableau;mais la définition de chmod indique juste :
chmod LISTEainsi vous pouvez tout aussi bien écrire :
unshift @tableau, 0644;
chmod @tableau;Si le premier argument de la liste n'est pas un mode valide, chmod échouera, mais c'est un problème sémantique à l'exécution sans rapport avec la syntaxe de l'appel. Si la sémantique réclame des arguments spéciaux à donner en premier, le texte décrira ces restrictions.
Au contraire des simples fonctions de LISTE, d'autres fonctions imposent des contraintes syntaxiques supplémentaires. Par exemple, push a un résumé de syntaxe comme ceci :
push TABLEAU, LISTECela veut dire que push demande un tableau correct comme premier argument, mais ne tient pas compte des arguments suivants. C'est ce que signifie le LISTE à la fin. (Les LISTE viennent toujours à la fin, puisqu'elles englobent toutes les valeurs qui restent). Si le résumé de syntaxe contient des arguments avant la LISTE, ces arguments sont distingués syntaxiquement par le compilateur, et non seulement distingués sémantiquement par l'interpréteur lorsqu'on le lancera plus tard. De tels arguments ne sont jamais évalués dans un contexte de liste. Ils peuvent être évalués soit dans un contexte scalaire, soit ce sont des références spéciales comme le tableau dans push. (La description vous dira qui est qui.)
Pour les opérations qui sont directement basées sur les fonctions de la bibliothèque C, nous n'essayerons pas de dupliquer la documentation de votre système. Lorsque la description d'une fonction demande de voir fonction(2), cela signifie que vous devez vous référer à la version correspondante en C de cette fonction pour en savoir plus sur sa sémantique. Le nombre entre parenthèses indique la section du manuel de programmation système dans laquelle vous trouverez la page man, si vous avez installé les pages man. (Et dans laquelle vous ne trouverez rien, si vous n'avez rien installé.)
Ces pages de manuel peuvent documenter des comportements spécifiques de votre système, comme les mots de passe shadow, les listes de contrôle d'accès et ainsi de suite. De nombreuses fonctions Perl dérivent de la bibliothèque C sous Unix, mais sont émulées même sur les autres plates-formes. Par exemple, même si votre système d'exploitation ne connaît pas les appels système flock(2) et fork(2), Perl fait de son mieux pour les émuler avec les ressources natives de votre plate-forme.
Parfois, vous constaterez que, dans la documentation, la fonction C reçoit plus d'arguments que la fonction Perl correspondante. En général, les arguments supplémentaires sont déjà connus par Perl, comme la longueur d'un autre argument. Les autres différences viennent de la façon dont Perl et C spécifient les handles de fichiers, ainsi que les valeurs de succès et d'échec.
En général, les fonctions en Perl qui servent de sur-couches aux appels système du même nom (comme chown(2), fork(2), closedir(2), etc.) renvoient toutes une valeur vraie lorsqu'elles réussissent, sinon undef comme indiqué dans les descriptions qui suivent. Ceci est différent des interfaces C à ces opérations, lesquelles retournent toutes -1 en cas d'échec. Les exceptions à cette règle sont wait, waitpid et syscall. Les appels système positionnent aussi la variable spéciale $! ($OS_ERROR). Les autres fonctions ne le font pas, excepté accidentellement.
Pour les fonctions qui peuvent être utilisées aussi bien dans un contexte scalaire que dans un contexte de liste, un échec est généralement indiqué dans un contexte scalaire en retournant une valeur fausse (en général undef) et dans un contexte de liste en retournant une liste vide. La réussite de l'opération est généralement indiquée en renvoyant une valeur qui sera évaluée comme vraie (dans le contexte).
Retenez la règle suivante : il n'y a pas de règle qui relie le comportement d'une fonction dans un contexte de liste à son comportement dans un contexte scalaire, ou vice versa. Il peut s'agir de deux choses totalement différentes.
Chaque fonction connaît le contexte dans lequel elle a été appelée. La même fonction, qui renvoie une liste lorsqu'on l'appelle dans un contexte de liste, retournera, lorsqu'on l'appelle dans un contexte scalaire, la valeur qui lui semble la plus appropriée. Certaines fonctions renvoient la longueur de la liste qui aurait été retournée dans un contexte de liste. D'autres fonctions retournent « l'autre » valeur, lorsque quelque chose peut être manipulé, soit par un nombre, soit par son nom. D'autres encore renvoient un compteur des opérations qui ont réussi. En général, les fonctions de Perl font exactement ce que vous voulez faire, à moins que vous ne vouliez de la cohérence.
Une dernière Remarque : nous avons essayé d'être très cohérents dans notre emploi des termes octets et caractères. Historiquement, ces termes ont été confondus l'un avec l'autre (et avec eux-mêmes). Mais lorsque nous disons octet, nous désignons toujours un octet de 8 bits. Lorsque nous disons caractère, nous voulons dire un caractère dans son abstraction, généralement un caractère Unicode, lequel peut être représenté dans vos chaînes par un ou plusieurs octets.
Mais notez que nous avons dit « généralement ». Perl confond à dessein les octets avec les caractères dans le contexte d'une déclaration use bytes, ainsi à chaque fois que nous parlons de caractère, vous devez comprendre un octet dans un contexte use bytes, sinon un caractère Unicode. En d'autres termes, use bytes reprend la définition d'un caractère telle qu'on la concevait dans les précédentes versions de Perl. Par exemple, si nous disons qu'un reverse scalaire, inverse une chaîne caractère par caractère, ne nous demandez pas si cela veut vraiment dire caractères ou alors octets, car la réponse est : « Oui».
29-1. Fonctions Perl par catégorie▲
Voici les fonctions de Perl et les mots-clefs assimilés, classés par catégorie. Certaines fonctions apparaissent sous plusieurs en-têtes.
Manipulation de scalaires
chomp,chop,chr,crypt,hex,index,lc,lcfirst,length,oct,ord,pack,q//,qq//,reverse,rindex,sprintf,substr, tr///,uc,ucfirst, y///
Expressions rationnelles et recherche de motifs
- m
//,pos,qr//,quotemeta, s///,split,study
Fonctions numériques
abs,atan2,cos,exp,hex, int,log,oct,rand,sin,sqrt,srand
Traitement des tableaux
pop,push,shift,splice,unshift
Traitement des listes
grep,join,map,qw//,reverse,sort,unpack
Traitement des hachages
delete,each,exists,keys,values
Entrées et sorties
binmode,close,closedir,dbmclose,dbmopen, die,eof,fileno,flock,format,getc,print,printf,read,readdir, readpipe,rewinddir,seek,seekdir,select(descripteurs de fichiers prêts),syscall,sysread,sysseek,syswrite,tell,telldir,truncate,warn,write
Données et enregistrements de longueur fixe
pack,read,syscall,sysread,sysseek,syswrite,unpack,vec
Handles de fichiers, fichiers et répertoires
chdir,chmod,chown,chroot,fcntl,glob,ioctl,link,lstat,mkdir,open,opendir,readlink,rename,rmdir,select(descripteurs de fichiers prêts),select(handle du fichier de sortie),stat,symlink, sysopen,umask,unlink,utime
Contrôle de flux des programmes
Potée
Divers
Processus et groupes de processus
alarm,exec,fork,getpgrp,getppid,getpriority,kill,pipe,qx//,setpgrp,setpriority,sleep,system,times,wait,waitpid
Modules de bibliothèques
Classes et objets
Accès aux sockets de bas niveau
accept,bind,connect,getpeername,getsockname,getsockopt,listen,recv,send,setsockopt,shutdown,socket,socketpair
Communications interprocessus System V
msgctl,msgget,msgrcv,msgsnd,semctl,semget,semop,shmctl,shmget,shmread,shmwrite
Recherches d'informations sur les groupes et les utilisateurs
endgrent,endhostent,endnetent,endpwent,getgrent,getgrgid,getgrnam,getlogin,getpwent,getpwnam,getpwuid,setgrent,setpwent
Recherches d'informations réseaux
endprotoent,endservent,gethostbyaddr,gethostbyname,gethostent,getnetbyaddr,getnetbyname,getnetent,getprotobyname,getprotobynumber,getprotoent,getservbyname,getservbyport,getservent,sethostent,setnetent,setprotoent,setservent
Date et heure
gmtime,localtime,time,times
29-2. Fonctions Perl par ordre alphabétique▲
La plupart des fonctions suivantes sont annotées avec, euh, des annotations. Voici leur signification :
![]() Utilise
Utilise $_ ($ARG) comme variable par défaut.
![]() Modifie
Modifie $! ($OS_ERROR) pour les erreurs dans les appels système.
![]() Lève des exceptions ; utilisez eval pour intercepter
Lève des exceptions ; utilisez eval pour intercepter $@ ($EVAL_ERROR).
![]() Modifie
Modifie $? ($CHILD_ERROR) lorsque le processus fils se termine.
![]() Marque la donnée retournée.
Marque la donnée retournée.
![]() Marque la donnée retournée dans certains systèmes, localement, ou configurée manuellement.
Marque la donnée retournée dans certains systèmes, localement, ou configurée manuellement.
![]() Lève une exception si un argument d'un type inapproprié est donné.
Lève une exception si un argument d'un type inapproprié est donné.
![]() Lève une exception si on modifie une cible en lecture seule.
Lève une exception si on modifie une cible en lecture seule.
![]() Lève une exception si on l'alimente avec une donnée marquée.
Lève une exception si on l'alimente avec une donnée marquée.
![]() Lève une exception s'il n'existe pas d'implémentation sur la plate-forme courante.
Lève une exception s'il n'existe pas d'implémentation sur la plate-forme courante.
Les fonctions qui retournent une donnée marquée lorsqu'elles sont alimentées avec une donnée marquée ne sont elles-mêmes pas marquées, puisque c'est le cas de la plupart des fonctions. En particulier, si vous utilisez n'importe quelle fonction avec %ENV ou @ARGV, vous obtiendrez une donnée marquée.
Les fonctions annotées avec ![]() lèvent une exception lorsqu'elles attendent, mais ne reçoivent pas, un argument d'un type précis (comme des handles de fichiers pour les opérations d'entrée/sortie, des références pour
lèvent une exception lorsqu'elles attendent, mais ne reçoivent pas, un argument d'un type précis (comme des handles de fichiers pour les opérations d'entrée/sortie, des références pour bless, etc.).
Les fonctions annotées avec ![]() ont parfois besoin de modifier leurs arguments. Si elles ne peuvent pas modifier l'argument, car il est marqué en lecture seule, elles lèvent une exception. Des exemples de variables en lecture seule sont les variables spéciales contenant une donnée capturée durant une recherche de motif et les variables qui sont en fait des alias de constantes.
ont parfois besoin de modifier leurs arguments. Si elles ne peuvent pas modifier l'argument, car il est marqué en lecture seule, elles lèvent une exception. Des exemples de variables en lecture seule sont les variables spéciales contenant une donnée capturée durant une recherche de motif et les variables qui sont en fait des alias de constantes.
Les fonctions annotées avec ![]() peuvent ne pas être implémentées sur toutes les plates-formes. Bien que la plupart d'entre elles soient nommées d'après les fonctions de la bibliothèque C sous Unix, ne croyez pas que vous ne pouvez en appeler aucune, seulement parce que vous n'êtes pas sous Unix. Beaucoup sont émulées, même celles que vous n'espériez jamais voir — comme
peuvent ne pas être implémentées sur toutes les plates-formes. Bien que la plupart d'entre elles soient nommées d'après les fonctions de la bibliothèque C sous Unix, ne croyez pas que vous ne pouvez en appeler aucune, seulement parce que vous n'êtes pas sous Unix. Beaucoup sont émulées, même celles que vous n'espériez jamais voir — comme fork sur les systèmes Win32, qui est en place depuis la version 5.6 de Perl. Pour plus d'informations sur la portabilité et le comportement de fonctions spécifiques à un système, voir la page de man perlport, plus quelques documentations spécifiques à la plate-forme fournie par votre portage de Perl.
Les fonctions qui lèvent d'autres exceptions diverses et variées sont annotées avec ![]() , y compris les fonctions mathématiques qui émettent des erreurs d'intervalle, comme
, y compris les fonctions mathématiques qui émettent des erreurs d'intervalle, comme sqrt(-1).
abs ![]()
abs VALEUR
absCette fonction renvoie la valeur absolue de son argument.
$diff = abs($premier -$second);Remarque : ici et dans les exemples suivants, un bon style (et le pragma use strict) exigerait que vous ajoutiez un modificateur my pour déclarer une nouvelle variable de portée lexicale, comme ceci :
my $diff = abs($premier -$second);Toutefois, nous avons omis my de la plupart de nos exemples pour plus de clarté. Vous n'avez qu'à supposer qu'une telle variable a été déclarée plus tôt, si cela vous démange.
accept ![]()
![]()
![]()
accept SOCKET, SOCKET_PROTOCette fonction est utilisée par les processus serveurs qui désirent se mettre en attente de connexion de clients sur une socket. SOCKET_PROTO doit être un handle de fichier déjà ouvert via l'opérateur socket et attaché à l'une des adresses réseau du serveur ou à INADDR_ANY. L'exécution est suspendue jusqu'à ce qu'une connexion soit établie, un handle de fichier SOCKET étant alors ouvert et attaché à la nouvelle connexion. Le handle original SOCKET_PROTO reste inchangé ; son seul but est d'être clôné dans une véritable socket. La fonction renvoie l'adresse de la connexion si l'appel réussit, une valeur fausse sinon. Par exemple :
unless ($interlocuteur = accept(SOCK, SOCK_PROTO)) {
die "Ne peut accepter la connexion : $!\n";
}Sur les systèmes qui l'acceptent, le flag close-on-exec sera positionné pour le nouveau descripteur de fichier ouvert, comme le veut la valeur de $^F ($SYSTEM_FD_MAX).
Voir accept(2). Voir aussi l'exemple dans la section Sockets au chapitre 16, Communication interprocessus.
alarm ![]()
![]()
alarm EXPR
alarmCette fonction envoie un signal SIGALRM au processus courant après EXPR secondes.
Un seul minuteur (timer) peut être actif à un moment donné. Chaque appel désactive le précédent minuteur et un argument EXPR valant 0 peut être fourni pour annuler le minuteur précédent sans en lancer un de nouveau.
print "Répondez en une minute ou allez en enfer : ";
alarm(60); # tue le programme dans une minute
$reponse = <STDIN>;
$temps_restant = alarm(0) # efface l'alarme
print "Il vous reste $temps_restant secondes\n";Une erreur courante est de mélanger les appels à alarm et sleep, car nombre de systèmes utilisent le mécanisme de l'appel système à alarm(2) pour implémenter sleep(3). Sur des machines plus anciennes, le temps écoulé peut être jusqu'à une seconde inférieur à celui que vous avez spécifié, selon la manière dont sont comptées les secondes. De plus, un système surchargé peut ne pas être prêt à lancer votre processus immédiatement. Voir le chapitre 16 pour plus d'informations sur l'interception de signaux.
Pour des alarmes d'une granularité plus fine que la seconde, vous pouvez utiliser la fonction syscall pour accéder à setitimer(2) si votre système le supporte. Le module CPAN, Timer::HiRes offre aussi des fonctions dans cet objectif.
atan2
atan2 Y, XCette fonction renvoie la valeur principale de l'arctangente de Y/X dans l'intervalle de -π à π. Un moyen rapide d'obtenir une valeur approchée de ! est d'écrire :
$pi = atan2(1, 1) * 4;Pour la tangente, vous pouvez utiliser la fonction tan provenant soit du module Math::Trig, soit du module POSIX, ou employer la relation bien connue :
sub tan { sin($_[0] / cos($_[0]) }bind ![]()
![]()
![]()
![]()
bind SOCKET, NOMCette fonction attache une adresse (un nom) à une socket déjà ouverte, spécifiée par le handle de fichier SOCKET. La fonction renvoie vrai si elle a réussi, sinon faux. NOM doit être une adresse empaquetée de la socket avec le type approprié.
use Socket;
$numero_port = 80; # prétend que nous voulons être un serveur web
$adresse_socket = sockaddr_in($numero_port, INADDR_ANY);
bind SOCK, $adresse_socket
or die "Impossible d'attacher $numero_port : $!\n";Voir bind(2). Voir aussi les exemples de la section Sockets au chapitre 16.
binmode ![]()
binmode HANDLE_FICHIER, DISCIPLINES
binmode HANDLE_FICHIERCette fonction s'arrange pour que le HANDLE_FICHIER ait la sémantique spécifiée par l'argument DISCIPLINES. Si l'on omet DISCIPLINES, des sémantiques binaires (ou « raw ») sont appliquées au handle de fichier. Si HANDLE_FICHIER est une expression, la valeur est prise de manière appropriée, comme le nom du handle de fichier ou comme une référence à un handle de fichier.
La fonction binmode doit être appelée après l'open mais avant qu'une quelconque opération d'entrée/sortie sur le handle de fichier n'ait été effectuée. Le seul moyen de réinitialiser le mode d'un handle de fichier est de rouvrir le fichier, puisque les diverses disciplines ont pu conserver divers bits et segments de données dans diverses mémoires tampons. Cette restriction est susceptible d'être levée à l'avenir.
Autrefois, binmode était principalement utilisé sur les systèmes d'exploitation dont les bibliothèques d'exécution distinguaient les fichiers textes des fichiers binaires. Sur ces systèmes, l'objectif de binmode était de désactiver la sémantique de texte par défaut. De toute façon, depuis l'avènement d'Unicode, tous les programmes sur tous les systèmes doivent connaître la distinction, même sur les systèmes Unix ou Mac. De nos jours, il n'existe qu'un type de fichiers binaire (du moins pour Perl), mais une multitude de types de fichiers texte. Ainsi, Perl ne connaît qu'un seul format interne pour les textes Unicode, UTF-8. Puisqu'il existe une variété de fichiers texte, ceux-ci doivent souvent être convertis en entrée vers UTF-8 et en sortie vers le jeu de caractères d'origine ou vers une autre représentation d'Unicode. Vous pouvez utiliser les disciplines pour indiquer à Perl comment réaliser exactement (ou inexactement) ces conversions.(199)
Par exemple, une discipline de ":text" dira à Perl de traiter les textes de façon générique sans préciser quel type de texte traiter. Mais des disciplines comme ":utf8" ou ":latin1" disent à Perl quel format de texte lire et écrire. D'un autre côté, la discipline ":raw" prévient Perl de garder ses sales mains en dehors des données. Pour en savoir plus sur le fonctionnement (éventuellement futur) des disciplines, voir la fonction open. La suite de cette discussion décrit ce que binmode fait sans l'argument DISCIPLINES, c'est-à-dire la signification historique de binmode, qui est équivalente à :
binmode HANDLE_FICHIER, ":raw";Sauf indication contraire, Perl suppose que votre fichier fraîchement ouvert doit être lu ou écrit en mode texte. Le mode texte signifie que \n (newline) est votre caractère fin de ligne interne. Tous les systèmes utilisent \n comme leur caractère de fin de ligne interne, mais ce qu'il représente réellement varie d'un système à l'autre, d'un périphérique à un autre et même d'un fichier à un autre, selon la façon dont vous accédez au fichier. Sur de tels systèmes (comprenant MS-DOS et VMS), ce que votre programme voit comme un \n peut ne pas être ce qui est stocké physiquement sur le disque. Le système d'exploitation peut, par exemple, stocker des fichiers textes avec les séquences \cM\cJ qui sont converties en entrée pour apparaître comme \n dans votre programme et inversement convertir \n depuis votre programme vers \cM\cJ en sortie dans un fichier. La fonction binmode désactive cette conversion automatique sur de tels systèmes.
En l'absence d'un argument DISCIPLINES, binmode n'a aucun effet sous Unix ou MAC OS, tous deux utilisant \n pour terminer chaque fin de ligne et représentant ceci avec un seul caractère. (Il peut s'agir toutefois d'un autre caractère : Unix utilise \cJ et les anciens Macs \cM. Mais cela ne porte pas à conséquence.)
Les exemples suivants montrent comment un script Perl doit lire une image GIF depuis un fichier et l'afficher sur la sortie standard. Sur les systèmes qui autrement altéreraient les données littérales en quelque chose d'autre que leur exacte représentation physique, vous devez préparer les deux handles de fichiers. Alors que vous pourriez directement utiliser une discipline ":raw" pour ouvrir le fichier GIF, vous ne pouvez pas si facilement faire de même avec les handles de fichiers déjà ouverts, tels que STDOUT :
binmode STDOUT;
open(GIF, "vim-power.gif") or die "Impossible d'ouvrir vim-power.gif : $!\n";
binmode GIF;
while (read(GIF, $buf, 1024)) {
print STDOUT $buf;
}bless ![]()
bless REF, NOM_DE_CLASSE
bless REFCette fonction indique à l'objet sur lequel pointe REF qu'il est maintenant un objet du paquetage NOM_DE_CLASSE — ou du paquetage courant si aucun NOM_DE_CLASSE n'est spécifié. Si REF n'est pas une référence valide, une exception est levée. Pour des raisons pratiques, bless retourne la référence, puisque c'est souvent la dernière fonction d'un constructeur. Par exemple :
dromadaire = Animal->nouveau(TYPE => "Chameau", NOM => "amelia");
# puis dans Amimal.pm :
sub nouveau {
my $classe = shift;
my %attrs = @_;
my $obj = { %attrs };
return bless($obj, $classe);
}Vous devez généralement consacrer les objets avec bless dans des NOMS_DE_CLASSE en majuscules et minuscules mélangées. Les espaces de noms tout entiers en minuscules sont réservés pour des besoins internes, comme les pragmas (directives de compilation) de Perl. Les types prédéfinis (tels que « SCALAR », « ARRAY », « HASH », etc., pour ne pas mentionner la classe de base de toutes les classes, « UNIVERSAL ») sont tous en majuscules, alors peut-être vaut-il mieux que vous évitiez des noms de paquetages écrits ainsi.
Assurez-vous que NOM_DE_CLASSE ne soit pas à une valeur fausse, la consécration dans des paquetages faux n'est pas supportée et peut conduire à des résultats imprévisibles.
Ce n'est pas un bogue qu'il n'y ait pas d'opérateur curse correspondant. (Mais il existe un opérateur sin, jeu de mots intraduisible, l'opérateur sin s'occupant de la fonction sinus et non d'un quelconque blasphème.) Voir aussi le chapitre 12, Objet, pour en savoir plus sur la bénédiction (et les consécrations) des objets.
caller
Cette fonction renvoie des informations concernant la pile d'appels en cours de sous-programmes et assimilés. Sans argument, elle renvoie le nom du paquetage, le nom du fichier et le numéro de ligne d'où la routine en cours d'exécution a été appelée :
($paquetage, $fichier, $ligne) = caller;Voici un exemple d'une fonction extrêmement fastidieuse, qui utilise les tokens spéciaux __PACKAGE__ et __FILE__ décrit au chapitre 2, Composants de Perl :
sub attention {
my ($paquetage, $fichier) = caller;
unless ($paquetage eq __PACKAGE__ && $file eq __FILE__) {
die "Vous n'êtes pas supposé m'appeller, $paquetage !\n";
}
print "Appelez-moi en toute tranquillité\n";
}
sub appel_tranquille {
attention();
}Appelée avec un argument, caller interprète EXPR comme étant le nombre de groupes d'éléments dans la pile (stack frames) à remonter avant la routine courante. Par exemple, un argument de 0 signifie l'élément courant dans la pile ; 1, la routine appelante ; 2, la routine appelante de la routine appelante ; et ainsi de suite. La fonction renvoie également des informations supplémentaires, comme le montre l'exemple suivant :
$i= 0;
while (($paquetage, $fichier, $ligne, $routine,
$args_presents, $tableau_demande, $texte_eval, $est_requis,
$indications, $masque_de_bits) = caller($i++))
{
...
}Si l'élément est un appel de sous-programme, $args_presents est vrai s'il possède son propre tableau @_ (et non un qui soit emprunté à la routine qui l'a appelé). Sinon, $routine peut valoir « (eval) » si l'élément n'est pas un appel de sous-programme, mais un eval. Si c'est le cas, les informations supplémentaires $texte_eval et $est_requis sont positionnées : $est_requis est vrai si l'élément est créé par une instruction require ou un use, et $texte_eval contient le texte de l'instruction eval EXPR. Plus particulièrement, pour une instruction eval BLOCK, $fichier vaut « (eval) », mais $texte_eval est indéfini. (Remarquez également que chaque instruction use crée un élément require dans un élément eval EXPR.) $indications et $masque_de_bits sont des valeurs internes ; vous êtes priés de les ignorer à moins que vous ne soyez membre de la thaumatocratie.
Dans un esprit de magie encore plus poussée, caller positionne également le tableau @DB::args avec les arguments passés à l'élément donné de la pile — mais seulement lorsqu'on l'appelle depuis le paquetage DB. Voir le chapitre 20, Le débogueur Perl.
chdir ![]()
![]()
chdir EXPR
chdirCette fonction change le répertoire de travail du processus courant en EXPR, si cela est possible. Si EXPR est omise, on utilise le répertoire de base de l'utilisateur. La fonction renvoie vraie si elle réussit, sinon faux.
chdir "$prefixe/lib" or die "Impossible de faire un cd dans $prefixe/lib\n";Voir aussi le module Cwd, décrit au chapitre 32, Modules standard, qui vous permet de garder automatiquement une trace de votre répertoire courant.
chmod ![]()
![]()
chmod LISTECette fonction modifie les permissions d'une liste de fichiers. Le premier élément de la liste doit être le mode numérique, comme dans l'appel système chmod(2). La fonction renvoie le nombre de fichiers modifiés avec succès. Par exemple :
$compt = chmod 0755, 'fichier1', 'fichier2';affectera 0, 1 ou 2 à $compt, selon le nombre de fichiers modifiés. L'opération est jugée réussie par l'absence d'erreur et non par un véritable changement, car un fichier peut avoir le même mode qu'avant l'opération. Une erreur signifie vraisemblablement que vous manquez de privilèges suffisants pour changer le mode du fichier, car vous n'êtes ni son propriétaire ni le super-utilisateur. Vérifiez $! pour découvrir la cause réelle de l'échec.
Voici une utilisation plus typique :
chmod(0755, @executables) == @executables
or die "Modification impossible de certains éléments de @executables : $!";Si vous devez connaître quels fichiers n'ont pas pu être changés, écrivez quelque chose comme ceci :
@immuables = grep {not chmod 0755, $_} 'fichier1', 'fichier2', 'fichier3';
die "$0 : impossible d'exécuter chmod @immuables\n" if @immuables;Cet idiome utilise la fonction grep pour ne sélectionner que les éléments de la liste pour lesquels la fonction chmod a échoué.
Lorsque des données non littérales sont utilisées pour le mode, vous pouvez avoir besoin de convertir une chaîne octale en un nombre décimal en utilisant la fonction oct. Ceci, car Perl ne devine pas automatiquement qu'une chaîne contient un nombre octal seulement parce qu'elle commence par un « 0 ».
$MODE_DEFAUT = 0644; # On ne peut pas utiliser de guillemets ici !
PROMPT: {
print "Nouveau mode ? ";
$chaine_mode = <STDIN>;
exit unless defined $chaine_mode; # test de fin de fichier
if ($chaine_mode =~ /^\s*$/ { # test de ligne à blanc
$mode = $MODE_DEFAUT;
}
elsif ($chaine_mode !~ /^\d+$/) {
print "Demande un mode numérique, $chaine_mode invalide\n";
redo PROMPT;
}
else {
$mode = oct($chaine_mode); # convertit "755" en 0755
}
chmod $mode, @fichiers;
}Cette fonction marche avec des modes numériques comme dans l'appel système Unix chmod(2). Si vous voulez une interface symbolique comme celle fournie par la commande chmod(1), voir le module File::chmod de CPAN.
Vous pouvez aussi importer les constantes symboliques S_I* du module Fcntl :
use Fcntl ':mode';
chmod S_IRWXU|S_IRGRP|S_IXGRP|S_IROTH|S_IXOTH, @executables;Certains considèrent que ceci est plus lisible qu'avec 0755. Maintenant, c'est à vous de voir.
chomp ![]()
![]()
chomp VARIABLE
chomp LISTE
chompCette fonction supprime (normalement) un saut de ligne à la fin d'une chaîne contenue dans une variable. Il s'agit d'une fonction légèrement plus sûre que chop (décrite ci-dessous) en ce qu'elle n'a pas d'effet sur une chaîne ne se terminant pas par un saut de ligne. Plus précisément, elle supprime la fin d'une chaîne correspondant à la valeur courante de $/, et non n'importe quel caractère de fin.
À l'inverse de chop, chomp renvoie le nombre de caractères supprimés. Si $/ vaut "" (en mode paragraphe), chomp enlève tous les caractères de fin de ligne à la fin de la chaîne sélectionnée (ou des chaînes si l'on « chompe » une LISTE). Vous ne pouvez pas « chomp er » un littéral, seulement une variable.
Par exemple :
while (<PASSWD>) {
chomp; # évite d'avoir \n dans le dernier champ
@tableau = split /:/;
...
}Avec la version 5.6, la signification de chomp change légèrement en ce que les disciplines en entrée peuvent prendre le dessus sur la valeur de la variable $/ et affecter la manière dont les chaînes doivent être « chompées ». Ceci a l'avantage qu'une discipline en entrée peut reconnaître plus d'une variété de délimiteurs de ligne (comme un paragraphe Unicode et les séparateurs de ligne), mais « chomp e » encore en toute sécurité tout ce qui termine la ligne courante.
chop ![]()
![]()
chop VARIABLE
chop LISTE
chopCette fonction coupe le dernier caractère d'une chaîne et renvoie le caractère coupé. L'opérateur chop est utilisé en premier lieu pour couper le caractère fin de ligne à la fin d'un enregistrement en entrée, mais est plus efficace qu'une substitution. Si c'est tout ce que vous en faites, alors il est plus sûr d'utiliser chomp, puisque chop tronque toujours la chaîne d'un caractère quel qu'il soit, alors que chomp est plus sélectif.
Vous ne pouvez pas « choper » un littéral, seulement une variable.
Si vous « chopez » une LISTE de variables, chacune des chaînes de la liste est coupée :
@lignes = 'cat mon_fichier';
chop @lignes;Vous pouvez « choper » tout ce qui est une lvalue, y compris une affectation :
chop($rep_courant = 'pwd');
chop($reponse = <STDIN>);Ce qui est différent de :
$reponse = chop($tmp = <STDIN>); # MAUVAISqui met un caractère fin de ligne dans $reponse puisque chop renvoie le caractère éliminé et non la chaîne résultante (qui se trouve dans $tmp). Une manière d'obtenir le résultat voulu est d'utiliser substr :
$reponse = substr <STDIN>, 0, -1;Mais on l'écrit plus fréquemment :
chop($reponse = <STDIN>);La plupart du temps, on peut exprimer chop en termes de substr :
$dernier_caractere = chop($var);
$dernier_caractere = substr($var, -1, 1, ""); # la même choseUne fois que vous aurez compris cette équivalence, vous pourrez l'utiliser pour faire des coupes plus évoluées. Pour couper plus d'un caractère, utilisez substr comme une lvalue, en assignant une chaîne vide. Ce qui suit enlève les cinq derniers caractères de $caravane :
substr($caravane, -5) = "";Le paramètre négatif fait partir substr de la fin de la chaîne au lieu du début. Si vous voulez récupérer les caractères ainsi enlevés, vous pouvez employer la forme à quatre arguments de substr, créant ainsi quelque chose comme un quintuple « chop » :
$queue = substr($caravane, -5, 5, "");chown![]()
![]()
![]()
chown LISTECette fonction change le propriétaire et le groupe d'une liste de fichiers. Les deux premiers éléments de la liste doivent être les UID et GID numériques, dans cet ordre. Une valeur de -1, dans l'une ou l'autre position, est interprétée par la plupart des systèmes en conservant la valeur inchangée. La fonction renvoie le nombre de fichiers modifiés avec succès. Par exemple :
($compt = chown($uidnum, $gidnum, 'fichier1', 'fichier2')) == 2
or die "chown impossible pour fichier1 ou fichier2 : $!";mettra $compt à 0, 1 ou 2, selon le nombre de fichiers modifiés (dans le sens où l'opération s'est déroulée avec succès, et non selon que le propriétaire est différent après coup). Voici une utilisation plus typique :
chown($uidnum, $gidnum, @fichiers) == @fichiers
or die "Modification impossible de @fichiers avec chown : $!";Voilà un sous-programme qui accepte un nom d'utilisateur, vérifie les UID et GID pour vous, puis effectue le chown :
sub chown_avec_le_nom {
my ($utilisateur, @fichiers) = @_;
chown((getpwnam($utilisateur))[2,3], @fichiers) == @fichiers
or die "chown impossible pour @fichiers : $!";
}
chown_avec_le_nom("larry", glob("*.c"));Cependant, il se peut que vous ne vouliez pas modifier le groupe ainsi que le fait la fonction précédente, car le fichier /etc/passwd associe à chaque utilisateur, un groupe unique même si cet utilisateur peut être membre de plusieurs groupes secondaires dans /etc/groups. Dans ce cas, vous pouvez passer -1 pour le GID, ce qui laisse inchangé le groupe du fichier. Si vous passez -1 comme UID et un GID valide, vous pouvez affecter le groupe sans changer l'utilisateur.
Sur la plupart des systèmes, vous n'avez la permission de changer le propriétaire du fichier que si vous êtes le super-utilisateur, bien que vous puissiez changer le groupe en n'importe lequel de vos groupes secondaires. Sur des systèmes peu sûrs, ces restrictions peuvent être assouplies, mais cette supposition n'est pas généralisable. Sur les systèmes POSIX, vous pouvez détecter quelle règle s'applique ainsi :
use POSIX qw(sysconf _PC_CHOWN_RESTRICTED);
# essayez seulement si vous êtes le super-utilisateur
# ou sur un système permissif
if ($> == 0 || !sysconf(_PC_CHOWN_RESTRICTED)) {
chown($uidnum, -1, $fichier)
or die "chown de $fichier à $uidnum impossible : $!";chr ![]()
chr NOMBRE
chrCette fonction renvoie le caractère représenté par ce NOMBRE dans le jeu de caractères. Par exemple, chr(65) vaut « A » en ASCII comme en Unicode, et chr(0x263a) est un smiley Unicode. Pour obtenir l'inverse de chr, utilisez ord.
Si vous préférez spécifier votre caractère par son nom plutôt que par un nombre (par exemple, "\N{WHITE SMILING FACE}" pour un smiley Unicode), voir charname au chapitre 31, Modules de pragmas.
chroot ![]()
![]()
![]()
![]()
chroot FICHIER
chrootEn cas de succès, FICHIER devient le nouveau répertoire racine pour le processus courant, le point de départ des noms de chemin commençant par « / ». Ce répertoire est hérité par appels à exec et par tous les sous-processus forkés après l'appel à chroot. Il n'y a aucun moyen de revenir à l'état précédent un chroot. Pour des raisons de sécurité, seul le super-utilisateur peut utiliser cette fonction. Voici un morceau de code ressemblant approximativement à ce que font de nombreux serveurs FTP :
chroot((getpwnam('ftp'))[7]
or die "Ftp anonyme impossible : $!\n";Il est improbable que cette fonction marche sur des systèmes non Unix. Voir chroot(2).
close ![]()
![]()
![]()
close HANDLE
closeCette fonction ferme le fichier, la socket ou le pipe associé au HANDLE. (Elle ferme le handle de fichier actuellement sélectionné si l'argument est omis.) Elle renvoie vrai si la fermeture se déroule avec succès, sinon faux. Vous n'avez pas besoin de fermer HANDLE si vous le rouvrez immédiatement, puisque le open suivant le ferme automatiquement pour vous. (Voir open.) Cependant, un close explicite sur un fichier en entrée remet à zéro le compteur de lignes ($.), ce qui n'est pas le cas de la fermeture implicite effectuée par open.
HANDLE peut être une expression dont la valeur peut être employée en tant que handle de fichier indirect (soit le non réel du handle de fichier, soit une référence à tout ce qui peut être interprété comme un objet handle de fichier.)
Si le handle de fichier vient d'une ouverture de pipe, close renverra faux si un appel système sous-jacent échoue ou si le programme à l'autre extrémité du pipe se termine avec un statut non nul. Dans ce dernier cas, le close force la variable $! ($OS_ERROR)à zéro. Donc, si un close sur un pipe renvoie un statut non nul, vérifiez $! pour déterminer si le problème vient du pipe lui-même (valeur non nulle) ou du programme à l'autre bout du pipe (valeur nulle). Dans tous les cas, $? ($CHILD_ERROR) contient la valeur de statut d'attente (N.d.T. : wait status ; voir son interprétation à la fonction system) de la commande associée à l'autre extrémité du pipe. Par exemple :
open(SORTIE, '| sort -rn | lpr -p') # pipe pour sort et lpr
or die "Impossible de démarrer le pipe sortlpr : $!";
print SORTIE @lignes; # imprime des choses sur la sortie
close SORTIE # attend que le sort finisse
or warn $! ? "Erreur système lors de la fermeture du pipe sortlpr : $!"
: "Statut d'attente du pipe sortlpr $?";Un handle de fichier produit, en dupliquant (2) un pipe, est traité comme un handle de fichier ordinaire, ainsi close n'attendra pas le fils pour ce handle de fichier. Vous devez attendre le fils en fermant le handle de fichier d'origine. Par exemple :
open(NESTSTAT, "netstat -rn |")
or die "Impossible de lancer netstat : $!";
open (STDIN, "<&NETSTAT")
or die "Impossible de dupliquer vers stdin : $!";Si vous fermez le STDIN ci-dessus, il n'y aura pas d'attente ; par contre, il y en aura si vous fermez NETSTAT.
Si vous vous débrouillez d'une manière ou d'une autre pour récolter vous-même un pipe fils qui s'est terminé, le close échouera. Ceci peut arriver si vous avez votre propre gestionnaire pour $SIG{CHLD} qui se déclenche lorsque le pipe fils se termine, ou si vous appelez intentionnellement waitpid avec l'identifiant de processus renvoyé par l'appel de open.
closedir ![]()
![]()
![]()
closedir HANDLE_REPCette fonction ferme un répertoire ouvert par opendir et renvoie la réussite de l'opération. Voir les exemples de readdir. HANDLE_REP peut être une expression dont la valeur peut être employée en tant que handle de répertoire indirect, généralement le non réel du handle du répertoire.
connect ![]()
![]()
![]()
![]()
connect SOCKET, NOMCette fonction démarre une connexion avec un autre processus qui attend par un accept. La fonction renvoie vrai si elle réussit, faux sinon. NOM doit être une adresse réseau binaire du type correspondant à celui de la socket. Par exemple, en supposant que SOCK soit une socket créée préalablement :
use Socket;
my ($distant, $port) = ("www.perl.com", 80);
my $adr_dest = sockaddr_in($port, inet_aton($distant));
connect SOCK, $adr_dest
or die "Connexion impossible vers $distant sur le port $port : $!";Pour déconnecter une socket, utilisez soit close, soit shutdown. Voir aussi les exemples de la section Sockets au chapitre 16. Voir connect(2).
cos ![]()
cos EXPR
cosCette fonction renvoie le cosinus de EXPR (exprimée en radians). Par exemple, le script suivant affiche une table des cosinus d'angles mesurés en degrés :
# Voici la manière de ne pas se fatiguer pour convertir de degrés en radians
$pi = atan2(1,1) * 4;
$pi_apres_180 = $pi/180;
# Affiche la table
for ($deg = 0; $deg <= 90; $deg++) {
printf "%3d %7.5f\n", $deg, cos($deg * $pi_apres_180);
}Pour l'opération cosinus inverse, vous pouvez utilisez la fonction acos() des modules Math::Trig ou POSIX, ou encore utiliser cette relation :
sub acos { atan2( sqrt(1 -$_[0] * $_[0]), $_[0] ) }crypt ![]()
crypt TEXTE_EN_CLAIR, PERTURBATIONCette fonction calcule le hachage non bijectif d'une chaîne exactement comme le fait crypt(3). Ceci s'avère très utile pur vérifier que le fichier de mots de passe n'en contient pas qui soient trop faibles(200), bien que ce que vous vouliez réellement faire est d'empêcher les gens de commencer à en ajouter de mauvais.
crypt se veut une fonction non bijective, un peu comme casser des œufs pour faire une omelette. Il n'existe aucun moyen (connu) de décrypter un mot de passe chiffré, à moins d'essayer de deviner toutes les combinaisons de manière exhaustive.
Lorsque vous vérifiez une chaîne cryptée existante, vous devez utiliser le texte chiffré en tant que PERTURBATION (comme crypt($texte_en_clair, $crypte) eq $crypte). Ceci permet à votre code de fonctionner avec le crypt standard ainsi qu'avec d'autres implémentations plus exotiques.
Lorsque vous choisissez une nouvelle PERTURBATION, vous avez au moins besoin de créer une chaîne de deux caractères aléatoires appartenant à l'ensemble [./0-9A-Za-z] (comme join '', ('.', '/', 0..9, 'A'..'Z', 'a'..'z')[rand 64, rand 64]). Les anciennes implémentations de crypt avaient seulement besoin des deux premiers caractères de PERTURBATION, mais le code qui donnait seulement les deux premiers caractères est maintenant considéré comme non portable. Voir votre page de manuel locale de crypt(3) pour des détails intéressants.
Voici un exemple qui s'assure que quiconque lançant ce programme connaît son propre mot de passe :
$mot_de_passe = (getpwuid ($<))[1] # Suppose que l'on soit sur Unix.
system "stty -echo"; # ou regarder Term::Readkey dans CPAN
print "Mot de passe : ";
chomp($mot = <STDIN>);
print "\n";
system "stty echo";
if (crypt($mot, $mot_de_passe) ne $mot_de_passe) {
print "Désolé\n";
} else {
print "ok\n";
}Il est bien sûr déconseillé de donner votre mot de passe à quiconque le demande, car c'est imprudent.
Les mots de passe cachés sont légèrement plus sûrs que les fichiers de mots de passe traditionnels et vous devez être le super-utilisateur pour y accéder. Comme peu de programmes doivent tourner avec des privilèges si puissants, il se peut que le programme maintienne son propre système d'authentification indépendant en stockant les chaînes crypt ées dans un fichier autre que /etc/passwd ou /etc/shadow.
La fonction crypt n'est pas adaptée au chiffrement de grandes quantités de données, au moins parce que vous ne pouvez pas retrouver en sens inverse l'information en clair. Regardez dans les répertoires by-module/Crypt et by-module/PGP de votre miroir favori de CPAN pour trouver un grand nombre de modules potentiellement utiles.
dbmclose ![]()
![]()
dbmclose HACHAGECette fonction brise le lien entre un fichier DBM (DataBase Management, gestion de base de données) et un hachage. dbmclose n'est en fait qu'un appel à untie avec les bons arguments, mais est fournie pour des raisons de compatibilité avec les anciennes versions de Perl.
dbmopen ![]()
![]()
dbmopen HACHAGE, NOMDB, MODERelie un fichier DBM à un hachage. (DBM signifie DataBase Management, gestion de base de données, et consiste en un ensemble de routines de bibliothèque C qui permettent un accès direct à des enregistrements via un algorithme de hachage.) HACHAGE est le nom de la base de données (sans l'extension .dir ou .pg). Si la base de données n'existe pas et qu'un MODE valide est spécifié, la base de données est créée avec les protections spécifiées par MODE, modifié par le umask. Pour empêcher la création de la base de données au cas où elle n'existe pas, il est possible de spécifier un mode valant undef, et la fonction renverra faux si elle ne peut trouver de base existante. Les valeurs associées au hachage avant le dbmopen ne sont plus accessibles.
La fonction dbmopen n'est en fait qu'un appel à tie avec les arguments appropriés, mais elle est fournie pour des raisons de compatibilité avec les anciennes versions de Perl. Vous pouvez contrôler quelle est bibliothèque DBM à utiliser en employant directement l'interface tie ou en chargeant le module approprié avant d'appeler open. Voici un exemple qui fonctionne sur certains systèmes pour les versions de DB_file similaires à celle de votre navigateur Netscape :
use Db_file;
dbmopen(%NS_hist, "$ENV{HOME}/.netscape/history.dat", undef)
or die "Impossible d'ouvrir le fichier d'historique de netscape : $!";
while (($url, $quand) = each %NS_hist) {
next unless defined($quand);
chop ($url, $quand); # supprime les octets nuls à fin
printf "Dernière visite de %s le %s.\n", $url,
scalar(localtime(unpack("V", $quand)));
}Si vous n'avez pas d'accès au fichier DBM en écriture, vous pourrez seulement lire les variables du hachage sans les modifier. Pour tester si vous pouvez écrire, utilisez soit un test de fichier comme -w, soit essayez de modifier une entrée dans un hachage bidon à l'intérieur d'un eval {}, ce qui interceptera l'exception.
Les fonctions comme keys et values peuvent renvoyer une importante liste de valeurs lorsqu'on les utilise avec de grands fichiers DBM. Vous préférerez sans doute utiliser la fonction each pour les parcourir itérativement et ne pas tout charger d'un bloc en mémoire.
Les hachages liés à des fichiers DBM ont les mêmes limitations que le type de paquetage DBM que vous utilisez, notamment pour ce qui concerne la dimension de ce qu'on peut mettre dans une cellule (bucket). Si vous vous restreignez à des clefs et des valeurs courtes, cela ne constitue que rarement un problème. Voir aussi le module DB_file au chapitre 32.
Une autre chose dont il faut tenir compte est que de nombreuses bases de données DBM existantes contiennent des clefs et des valeurs terminées par un caractère nul, car elles ont été conçues pour être exploitées par des programmes C. Le fichier d'historique de Netscape et le fichier d'alias des anciens sendmail en sont des exemples. Il vous suffit d'utiliser "$key\0" lorsque vous extrayez une valeur, puis de supprimer le caractère nul dans cette dernière.
$alias = $les_alias{"postmaster\0"};
chop $alias; # supprime le caractère nulIl n'existe à l'heure actuelle aucun moyen intégré de verrouiller un fichier DBM générique. Certains pourraient considérer qu'il s'agit d'un bogue. Le module GDBM_file permet lui de verrouiller l'ensemble du fichier. En cas de doute, il vaut mieux utiliser un fichier verrou séparé.
defined ![]()
defined EXPR
definedCette fonction renvoie une valeur booléenne selon que EXPR contient une valeur définie ou non. La plupart des données que vous manipulez sont définies, mais un scalaire qui ne contient ni de chaîne valide, ni valeur numérique, ni de référence est considéré contenir la valeur indéfinie, ou pour abréger undef. Initialiser une variable scalaire à une valeur particulière la rendra définie et elle restera définie jusqu'à ce que vous lui assigniez une valeur indéfinie ou que vous appeliez explicitement undef avec cette variable comme paramètre.
De nombreuses opérations renvoient undef dans des conditions exceptionnelles, comme une fin de fichier, une variable non initialisée, une erreur système, etc. Puisque undef n'est qu'un type de valeur fausse, un simple test booléen ne fait pas de distinction entre undef, le chiffre zéro, la chaîne vide et la chaîne d'un seul caractère, « 0 » — toutes ces valeurs sont fausses de la même manière. La fonction defined vous permet de distinguer entre une chaîne vide indéfinie et une chaîne vide définie lorsque vous employez des opérateurs susceptibles de renvoyer une véritable chaîne vide.
Voici un morceau de code qui teste une valeur scalaire d'un hachage :
print if defined $option{D};Lorsqu'on l'utilise sur un élément de hachage comme ceci, defined ne fait qu'indiquer si la valeur est définie, et non si la clef possède une entrée dans le hachage. Il est possible d'avoir une clef dont la valeur est indéfinie ; cependant la clef elle-même existe. Utilisez exist pour déterminer si une clef de hachage existe.
Dans l'exemple suivant, nous exploitons la convention qui fait que certaines opérations renvoient une valeur indéfinie lorsqu'il n'y a plus de données.
print "$val\n" while defined($val = pop(@tableau));Et dans celui-ci, nous faisons la même chose avec la fonction getpwent pour obtenir des informations à propos des utilisateurs du système :
setpwent(); while (defined($nom = getpwent())) {
print "< <$nom> >\n";
}
endpwent();Il en va de même pour les erreurs renvoyées par les appels système qui peuvent légitimement renvoyer une valeur fausse :
Vous pouvez également utiliser defined pour déterminer si un sous-programme a d'ores et déjà été défini. Ceci évite de se surcharger avec des sous-programmes inexistants (ou des sous-programmes qui ont été déclarés, mais jamais définis) :
indirect("nom_fonction", @liste_args);
sub indirect {
my $nom_routine = shift;
no strict 'refs'; # ainsi nous pouvons utiliser
# nom_routine indirectement
if (defined &$nom_routine) {
&$nom_routine(@_); # ou $nom_routine->(@_);
} else {
warn "Appel ignoré à une fonction invalide $nom_routine";
}
}L'utilisation de defined sur les agrégats (hachages et tableaux) est dépréciée. (On l'utilisait pour savoir si la mémoire pour cet agrégat avait jamais été allouée.) À la place, employez un simple test booléen pour voir si le tableau ou le hachage possède des éléments :
if (@un_tableau) { print "tableau possédant des éléments\n";
if (%un_hachage) { print "hachage possédant des éléments\n";Voir aussi undef et exists.
delete
delete EXPRCette fonction supprime un élément (ou une tranche d'éléments) dans le hachage ou le tableau spécifié. (Voir unlink si vous voulez supprimer un fichier.) Les éléments supprimés sont renvoyés dans l'ordre spécifié, bien que ce comportement ne soit pas garanti dans le cas de variables liées comme les fichiers DBM. Après la suppression, la fonction exists renverra faux pour toute clef ou indice supprimé. (À l'opposé, après la fonction undef, la fonction exists continue de renvoyer vrai, car la fonction undef ne fait que rendre indéfinie la valeur d'un élément, mais ne supprime pas l'élément lui-même.)
Supprimer dans le hachage %ENV modifie l'environnement. Les supprimer dans un hachage qui est lié à un fichier DBM (dans lequel on a les droits en écriture) supprime l'entrée dans ce fichier DBM.
Historiquement, vous pouviez seulement supprimer dans un hachage, mais avec Perl version 5.6 vous pouvez également supprimer dans un tableau. Une suppression dans un tableau a pour conséquence que l'élément à la position spécifiée retourne dans un état non initialisé, mais sans combler le vide, puisque ceci modifierait les positions de toutes les entrées suivantes. Utilisez un splice pour cela. (Toutefois, si vous supprimez le dernier élément d'un tableau, la taille de celui-ci diminuera de un — ou plus, selon la position de l'élément existant précédent s'il y en a.)
EXPR peut être arbitrairement complexe, pourvu que l'opération ultime soit une consultation de hachage ou de tableau :
# installation d'un tableau de tableau de hachage
$donjon[$x][$y] = \%proprietes;
# supprimer une propriété dans le hachage
delete $donjon[$x][$y]{OCCUPE}
# supprimer trois propriétés dans le hachage d'un seul coup
delete @{ $donjon[$x][$y] }{ "OCCUPE", "HUMIDE", "ECLAIRE" };
# supprimer la référence à %proprietes dans le tableau
delete $donjon[$x][$y];L'exemple naïf qui suit supprime toutes les valeurs d'un %hachage de manière inefficace :
foreach $clef (keys %hachage) {
delete $hachage{$clef};
}De même que celui-ci :
delete @hachage{keys %hachage};Mais ces deux exemples sont plus lents que si l'on assigne simplement au hachage la liste vide ou qu'on le rend indéfini :
%hachage = (); # vide entièrement %hachage
undef %hachage; # oublie que %hachage a jamais existéIl en va de même pour les tableaux :
foreach $indice (0.. $#tableau) {
delete $tableau[$indice];
}et :
delete @tableau[0 .. $#tableau];sont moins efficaces que :
@tableau = (); # vide entièrement @tableau
undef @tableau; # oublie que @tableau a jamais existédie ![]()
Hors d'un eval, cette fonction affiche la valeur concaténée de LISTE sur STDERR et sort avec la valeur courante de $! (la variable errno de la bibliothèque C). Si $! vaut 0, elle sort avec la valeur de $? >> 8 (qui est le statut du dernier fils récolté depuis un system, un wait, un close sur un pipe, ou une `commande`). Si $? >> 8 vaut 0, elle sort avec 255.
À l'intérieur d'un eval, la fonction met le message d'erreur qui aurait autrement été produit dans la variable $@, puis elle interrompt le eval, qui renvoie undef. La fonction die peut ainsi être utilisée pour lever des exceptions nommées susceptibles d'être exploitées à un plus haut niveau dans le programme. Voir eval plus loin dans ce chapitre.
Si LISTE est une référence vers un objet unique, cet objet est supposé être un objet exception et il est renvoyé sans modification comme l'exception dans $@.
Si LISTE est vide et que $@ contient déjà une chaîne (provenant généralement d'un précédent eval), cette chaîne est réutilisée en lui ajoutant "\t...propagated". Ceci est utile pour propager (lever à nouveau) des exceptions :
Si LISTE est vide et que $@ contient déjà un objet exception, la méthode $@->PROPAGATE est appelée pour déterminer comment l'exception doit être propagée.
Si LISTE est vide ainsi que $@, la chaîne "Died" est utilisée.
Si la valeur finale de LISTE ne se termine pas par un saut de ligne (et que vous ne passez pas d'objet exception), le nom du script courant, le numéro de ligne et le numéro de ligne du fichier d'entrée (s'il existe) sont ajoutés au message, ainsi qu'un saut de ligne. Astuce : quelquefois, le fait d'ajouter ", stopped" à votre message le rendra plus explicite quand la chaîne "at nom_de_script line 123" lui sera ajoutée. Supposons que vous lanciez le script canasta ; considérez la différence entre les deux manières suivantes de mourir :
qui produisent respectivement :
/usr/games ne vaut rien at canasta line 123.
/usr/games ne vaut rien, stopped at canasta line 123.Si vous désirez que vos propres messages donnent le nom de fichier et le numéro de ligne, employez les tokens spéciaux __FILE__ et __LINE__ :
die '"', __FILE__, '", ligne ', __LINE__, ", hou la honte !\n";La sortie ressemblera alors à :
"canasta", ligne 38, hou la honte !Une autre question de style — considérez les exemples équivalents suivants :
die "Impossible de faire un cd vers le spool : $!\n"
unless chdir '/usr/spool/news';
chdir '/usr/spool/news'
or die "Impossible de faire un cd vers le spool : $!\n";Comme la partie importante est le chdir, on préfère généralement la seconde forme. Voir également exit, warm, %SIG et le module Carp.
do (bloc)
do BLOCLa forme do BLOC exécute la séquence de commandes indiquée par BLOC et renvoie la valeur de la dernière expression évaluée dans le bloc. Lorsqu'elle est modifiée par une instruction while ou until, Perl exécute le BLOC une fois avant de tester la condition de sortie. (Pour d'autres instructions, les modificateurs de boucle testent la condition en premier.) Le do BLOC lui-même ne compte pas comme une boucle, ainsi les instructions de contrôle de boucle next, last ou redo ne peuvent pas être utilisées pour quitter ou recommencer le bloc. Voir la section Blocs simples au chapitre 4, Instruction et déclaration, pour contourner ce problème.
do (fichier) ![]()
do FICHIERLa forme do FICHIER utilise la valeur de FICHIER comme nom de fichier et exécute son contenu comme un script Perl. Son usage premier est (ou plutôt était) d'inclure des sous-programmes depuis une bibliothèque Perl, de sorte que :
do 'stat.pl';est identique à :
scalar eval 'cat stat.pl'; #'type stat.pl' sur Windowssauf que la première forme est plus efficace, plus concise, elle garde la trace du nom de fichier courant pour les messages d'erreur, cherche dans tous les répertoires du tableau @INC et met à jour %INC si le fichier est trouvé. (Voir au chapitre 28, Noms spéciaux.) Elle diffère également dans le fait que le code évalué avec do FICHIER ne peut pas voir les variables lexicales dans la portée qui l'englobe, à l'inverse du code dans eval FICHIER. Mais elle est pourtant similaire à la seconde en ce qu'elle rescrute le fichier à chaque appel, et il vaut mieux ne pas l'employer dans une boucle à moins que le nom du fichier lui-même change à chaque itération.
Si do ne peut pas lire le fichier, elle renvoie undef et met l'erreur dans $!. Si do peut lire le fichier, mais pas le compiler, elle retourne undef et met un message d'erreur dans $@. Si le fichier est compilé avec succès, do renvoie la valeur de la dernière expression évaluée.
L'inclusion de modules de bibliothèques (qui ont obligatoirement un suffixe .pm) est mieux gérée par les opérateurs use et require, qui contrôlent les erreurs et génèrent une exception s'il y a un problème. Ils ont également d'autres avantages : ils évitent de dupliquer le chargement, facilitent la programmation orientée objet et fournissent des indications au compilateur sur les prototypes de fonctions.
Mais do FICHIER est toujours utile pour des choses comme la lecture de fichiers de configuration. On peut faire un contrôle d'erreur manuel comme ceci :
# lit dans les fichiers de configuration : système d'abord,
# ensuite utilisateur
for $fichier ("/usr/share/projet/defaut.rc",
"$ENV{HOME}/.programmerc")
{
unless ($retour = do $fichier) {
warn "Impossible de scruter $fichier : $@" if $@;
warn "Impossible de faire do $fichier : $!" unless defined $retour;
warn "Impossible de lancer $fichier" unless $retour;
}
}Un démon qui doit tourner longtemps peut périodiquement examiner la date de son fichier de configuration, et si le fichier a été modifié depuis sa dernière lecture, le démon peut utiliser do pour recharger le fichier. Il est plus propre de le faire avec do qu'avec require ou use.
do (sous-programme) ![]()
do SOUS-PROGRAMME(LISTE)La forme do SOUS-PROGRAMME(LISTE) est une forme dépréciée d'appel d'un sous-programme. Une exception est levée si le SOUS-PROGRAMME n'est pas défini. Voir le chapitre 6, Sous-programmes.
dump
Cette fonction provoque un core dump immédiat. En premier lieu, ceci vous permet d'utiliser le programme undump(1) (non fourni) pour transformer le fichier de copie résultant en un binaire exécutable après avoir initialisé toutes les variables au début du programme. Quand le nouveau binaire sera exécuté, il commencera par un goto LABEL (avec toutes les restrictions inhérentes à goto). On peut voir le processus complet comme un saut inconditionnel avec un core dump, suivi d'une réincarnation. Si LABEL est omis, le programme repart du début. Attention : tout fichier ouvert au moment de la copie avec dump, ne le sera plus au moment de la réincarnation du programme, d'où une possible confusion de la part de Perl. Voyez également l'option de ligne de commande -u au chapitre 19, Interface de la ligne de commande.
Cette fonction est maintenant tout à fait obsolète, en partie parce qu'il est extrêmement difficile de convertir un core dump en un binaire dans le cas général, et parce que les divers compilateurs générant du bytecode portable ou du C compilable l'ont surpassé.
Si vous désirez utiliser dump pour accélérer vos programmes, allez voir la discussion concernant les questions d'efficacité au chapitre 24, Usage courant, ainsi que le compilateur en code natif au chapitre 18, Compilation. L'autochargement peut également présenter un certain intérêt, en ce qu'il semble accélérer l'exécution.
each
each HACHAGECette fonction parcourt pas à pas un hachage à raison d'une paire clef/valeur à la fois. Appelée dans un contexte de liste, each renvoie une liste à deux éléments composée de la clef et de la valeur de l'entrée suivante d'un hachage, il vous est ainsi possible de circuler dans la liste toute entière. Appelée dans un contexte scalaire, each renvoie seulement la clef de l'entrée suivante du hachage. Quand le hachage est entièrement lu, elle renvoie la liste vide, qui produit une valeur fausse lorsqu'elle est assignée dans un contexte scalaire, comme un test de boucle. L'appel suivant à each redémarrera une nouvelle itération. On l'utilise généralement comme dans l'exemple suivant qui utilise le hachage prédéfini %ENV :
while (($clef, $valeur) = each %ENV) {
print "$clef=$valeur\n";
}En interne, un hachage conserve ses entrées dans un ordre apparemment aléatoire. La fonction each boucle le long de cette séquence, car chaque hachage se souvient de l'entrée renvoyée en dernier. L'ordre réel de cette séquence est susceptible de changer dans les prochaines versions de Perl, mais il est garanti qu'il sera identique à celui que renverrait la fonction keys (ou values) avec le même hachage (sans modification).
Il existe un itérateur unique pour chaque hachage, partagé par tous les appels aux fonctions each, keys et values du programme ; on peut le remettre à zéro en lisant tous les éléments du hachage, ou en évaluant keys %hachage ou values %hachage. Si vous ajoutez ou supprimez des éléments d'un hachage pendant qu'il y a une itération sur celui-ci, les conséquences ne sont pas bien définies : des entrées peuvent être passées ou dupliquées.
Voir aussi keys, values et sort.
eof ![]()
eof HANDLE_FICHIER
eof()
eofCette fonction renvoie vrai si la lecture suivante sur HANDLE_FICHIER renverra une fin de fichier, ou si HANDLE_FICHIER n'est pas ouvert. HANDLE_FICHIER peut être une expression dont la valeur donne le vrai nom du handle de fichier. Un eof sans argument renvoie le statut de fin de fichier pour le dernier fichier lu. Un eof() avec des parenthèses vides teste le handle de fichier ARGV (plus généralement rencontré en tant que handle de fichier nul dans <>). Ainsi, à l'intérieur d'une boucle while (<>), un eof() avec parenthèses ne détectera la fin que du dernier d'un groupe de fichiers. Utilisez eof (sans parenthèses) pour tester chacun des fichiers dans une boucle while (<>). Par exemple le code suivant insère des tirets juste avant la dernière ligne du dernier fichier :
Pour sa part, ce script remet à zéro la numérotation des lignes pour chaque fichier d'entrée :
# remet à zéro la numérotation des lignes pour chaque fichier d'entrée
while (<>) {
next if /^\s*#/; # passe les commentaires
print "$.\t$_";
} continue {
close ARGV if eof; # Et non eof() !
}De même que « $ » dans un programme sed, eof brille particulièrement dans les numérotations de lignes par zones. Voici un script qui affiche les lignes de /motif/ à la fin de chaque fichier d'entrée :
Ici, l'opérateur de bascule (..) évalue la correspondance du motif à chaque ligne. Jusqu'à ce que le motif corresponde, l'opérateur renvoie faux. Quand la correspondance est enfin trouvée, l'opérateur commence par renvoyer vrai, provoquant ainsi l'affichage des lignes. Quand l'opérateur eof renvoie finalement vrai (à la fin du fichier examiné), l'opérateur de bascule se remet à zéro et renvoie de nouveau faux pour le prochain fichier dans @ARGV.
Attention : la fonction eof lisant un octet puis le remettant dans le flux d'entrée avec ungetc(3), elle n'est pas très utile dans un contexte interactif. En fait, les programmeurs Perl expérimentés utilisent rarement eof, puisque les divers opérateurs d'entrée se comportent plutôt bien dans les expressions conditionnelles des boucles while. Reportez-vous à l'exemple de la description de foreach au chapitre 4.
eval ![]()
![]()
Le mot-clef eval dessert en Perl deux buts différents, mais néanmoins liés. Ces buts sont représentés par deux formes de syntaxe, eval BLOC et eval EXPR. La première forme intercepte les exceptions à l'exécution (erreurs) qui auraient sinon provoqué une erreur fatale, de la même manière qu'un « bloc try » en C++ ou en Java. La seconde forme compile et exécute de petits morceaux de code à la volée et intercepte également (et c'est bien commode) les exceptions exactement comme la première forme. Mais la seconde forme s'exécute beaucoup plus lentement que la première, puisqu'elle doit analyser la chaîne à chaque fois. D'un autre côté, elle est aussi plus générique. Quelle que soit la forme que vous utilisez, eval est la manière standard d'intercepter les exceptions en Perl.
Pour chacune des formes, la valeur renvoyée par eval est celle de la dernière expression évaluée, tout comme dans un sous-programme. Vous pouvez de même utiliser l'opérateur return pour renvoyer une valeur au beau milieu de l'eval. L'expression générant la valeur de retour est évaluée dans un contexte vide, scalaire ou de liste, selon le contexte de l'eval lui-même. Voir wantarray pour plus d'informations sur la manière de déterminer un contexte.
S'il se produit une erreur interceptable (y compris une erreur engendrée par l'opérateur die), eval renvoie undef et met le message d'erreur (ou l'objet) dans $@. S'il n'y a pas d'erreur, $@ est garantie contenir la chaîne vide, vous pouvez ainsi détecter les erreurs après coup de manière fiable. Un simple test booléen suffit.
La forme eval BLOC est vérifiée syntaxiquement durant la compilation, ce qui la rend assez performante. (Cela trouble de temps à autre les personnes habituées à la forme lente eval EXPR.) Puisque le code du BLOC est évalué à la compilation en même temps que le code qui l'entoure, cette forme d'eval ne peut pas intercepter les erreurs de syntaxe.
La forme eval EXPR peut quant à elle intercepter les erreurs syntaxiques, car elle analyse le code durant l'exécution. (Si l'analyse échoue, elle met l'erreur analysée dans $@, comme d'habitude.) Sinon, elle exécute la valeur de EXPR comme si c'était un petit programme Perl. Le code est exécuté dans le contexte courant du programme Perl, ce qui signifie qu'il peut voir toutes les variables lexicales de la portée qui l'englobe, tout comme les définitions de sous-programmes ou de formats. Le code de l'eval est traité en tant que bloc, toute variable de portée locale déclarée à l'intérieur de l'eval n'existe donc que le temps de l'eval. (Voir my et local.) Comme dans tout code à l'intérieur d'un bloc, il n'y a pas besoin de point-virgule à la fin.
Voici un simple script Perl. Il demande à l'utilisateur d'entrer une chaîne arbitraire de code Perl, la compile, l'exécute et affiche les éventuelles erreurs qui se sont produites :
print "\nEntrer du code Perl : ";
while (<STDIN>) {
eval;
print $@;
print "\nEntrer à nouveau du code Perl : ";
}Voici un programme rename pour changer le nom d'une quantité de fichiers en utilisant une expression Perl :
#!/usr/bin/perl
# rename -change les noms des fichiers
$op = shift;
for (@ARGV) {
$ancien = $_;
eval $op;
die if $@;
# la prochaine ligne appelle la fonction interne Perl,
# non le script du même nom
rename($ancien, $_) unless $ancien eq $_;
}Vous pouvez utiliser ce programme comme ceci :
$ rename 's/\.orig$//' *.orig
$ rename 'y/A-Z/a-z/ unless /^Make/' *
$ rename '$_ .= ".bad"' *.fPuisqu'eval intercepte des erreurs qui sinon seraient fatales, il est très utile pour déterminer si une fonctionnalité donnée (comme fork ou symlink) est implémentée.
Comme un eval BLOC est vérifié syntaxiquement à la compilation, toute erreur de syntaxe est reportée en amont. Ainsi, si votre code est invariant et qu'à la fois un eval EXPR et un eval BLOC vous conviennent, la dernière forme est la meilleure. Par exemple :
# rend la division par zéro non fatale
eval { $reponse = $a / $b; }; warn $@ if $@;
# idem, mais moins performant si on l'exécute plusieurs fois
eval '$reponse = $a / $b'; warn $@ if $@;
# une erreur de syntaxe à la compilation (non interceptée)
eval { $reponse = }; # MAUVAIS
# une erreur de syntaxe à l'exécution
eval '$reponse ='; # positionne $@Ici, le code du BLOC doit être un code Perl valide pour passer la phase de compilation. Le code de l'EXPR n'est pas examiné avant l'exécution, il ne produit donc pas d'erreur avant d'être exécuté.
Le bloc d'un evalBLOCK ne compte pas comme une boucle, ainsi les instructions de contrôle de boucle next, last et redo ne peuvent pas être employées pour sortir ou recommencer le bloc.
exec ![]()
![]()
exec CHEMIN LISTE
exec LISTELa fonction exec termine le programme courant, exécute une commande externe et n'en revient jamais !!! Utilisez system au lieu de exec si vous voulez reprendre le contrôle après la la fin de la commande. La fonction exec échoue et renvoie faux seulement si la commande n'existe pas et si elle est exécutée directement et non par l'intermédiaire d'une commande shell de votre système (nous en discuterons plus loin).
S'il n'y a qu'un seul argument scalaire, celui-ci est inspecté pour y chercher des métacaractères du shell. S'il y en a, l'argument est tout entier passé à l'interpréteur de commandes standard du shell (/bin/sh sous Unix). Sinon, l'argument est décomposé en mots et exécuté directement dans un souci d'efficacité, puisqu'on économise ainsi la surcharge due au traitement du shell. Cela vous donne également plus de contrôle sur la reprise d'erreur si jamais le programme n'existait pas.
S'il y a plus d'un argument dans la LISTE, ou si LISTE est un tableau avec plus d'une valeur, le shell du système ne sera jamais utilisé. Ceci évite également tout traitement de la commande par le shell. La présence ou l'absence de métacaractères dans les arguments n'affecte pas ce comportement déclenché par la liste, ce qui en fait la forme idéale pour des programmes soucieux de la sécurité, ne voulant pas s'exposer à des fuites potentielles dans le shell.
Cet exemple entraîne le remplacement du programme Perl en train de tourner par le programme echo, qui affiche la liste d'arguments courante :
exec 'echo', 'Vos arguments sont :', @ARGV;Cet autre exemple montre que vous pouvez executer un pipeline et non uniquement un seul programme :
exec "sort $fichier_sortie | uniq"
or die "Impossible de faire un sort/uniq : $!\n";exec ne revient généralement jamais — si c'est le cas, il retourne toujours faux et vous devez vérifier $! pour savoir ce qui s'est mal passé. Remarquez que dans les anciennes versions de Perl, exec (et system) ne vidaient pas votre tampon de sortie, vous deviez donc activer le vidage du tampon de commande en positionnant $| sur un ou plusieurs handles de fichier pour éviter la perte de la sortie dans le cas d'exec, ou une sortie désordonnée dans le cas de system. La version 5.6 de Perl remédie largement à cette situation.
Lorsque vous demandez au système d'exploitation d'exécuter un nouveau programme à l'intérieur d'un processus existant (comme le fait la fonction exec de Perl), vous indiquez au système où se trouve le nouveau programme à exécuter, mais vous donnez aussi au nouveau programme (à travers son premier argument) le nom sous lequel il a été invoqué. Habituellement, le nom que vous donnez est juste une copie de l'endroit où se trouve le programme, mais vous n'y êtes pas nécessairement obligés, puisqu'il y a deux arguments distincts au niveau du langage C. Lorsqu'il ne s'agit pas d'une copie, vous obtenez comme curieux résultat que le nouveau programme croit qu'il est lancé sous un nom qui peut être complètement différent du véritable chemin dans lequel il réside. Cela n'a souvent pas de conséquences pour le programme en question, mais certains programmes y font attention et adoptent une personnalité différente selon ce qu'ils pensent être leur nom. Par exemple, l'éditeur vi regarde s'il a été appelé avec « vi » ou avec « view ». S'il a été invoqué avec « view », il se met automatiquement en mode lecture seule, exactement comme s'il avait été appelé avec l'option de la ligne de commande -R.
Voilà où le paramètre optionnel CHEMIN de exec entre en jeu. Syntaxiquement, il vient se brancher sur la position d'un objet indirect comme le handle de fichier pour print ou printf. Ainsi, il n'y a pas de virgule après lui, car il ne fait pas exactement partie de la liste d'arguments. (En un sens, Perl adopte l'approche opposée du système d'exploitation en ce qu'il suppose que le premier argument est le plus important et qu'il vous laisse modifier le chemin s'il diffère.) Par exemple :
$editeur = "/usr/bin/vi";
exec $editeur "view", @fichiers # active le mode lecture seule
or die "Impossible d'exécuter $editeur : $!\n";Comme avec tout objet indirect, vous pouvez également remplacer le simple scalaire contenant le nom du programme avec un bloc contenant du code arbitraire, ce qui simplifie l'exemple précédent en donnant :
exec { "/usr/bin/vi" } "view" @fichiers # active le mode lecture seule
or die "Impossible d'exécuter /usr/bin/vi : $!\n";Comme nous l'avons déjà évoqué, exec traite une liste discrète d'arguments comme une indication qu'il doit éviter le traitement du shell. Toutefois, il y a un endroit où vous pourriez être déroutés. L'appel exec (et également system) ne distingue pas un unique argument scalaire d'un tableau ne contenant qu'un seul élément.
@args = ("echo surprise"); # une liste à un seul élément
exec @args # toujours sujet aux fuites du shell
or die "exec : $!\n"; #, car @args == 1Pour éviter ceci, vous pouvez utiliser la syntaxe avec CHEMIN, en dupliquant exactement le premier argument dans le chemin, ce qui force l'interprétation du reste des arguments à être une liste, même s'il n'y en a qu'un seul :
exec { args[0] } @args # sécurisé même si la liste n'a qu'un argument
or die "exec @args impossible : $!";La première version, celle avec les parenthèses, lance le programme echo en lui passant « surprise » comme argument. La seconde version ne fait pas la même chose — elle tente de lancer un programme appelé littéralement echo surprise, ne le trouve pas (du moins on l'espère) et positionne $! à une valeur non nulle indiquant l'échec.
Comme la fonction exec est le plus souvent utilisée peu après un fork, on suppose que l'on doit passer outre tout ce qui survient normalement lorsqu'un processus Perl se termine. Sous un exec, Perl n'appellera pas les blocs END, ni les méthodes DESTROY associées aux objets. Sinon, vos processus fils se termineraient en faisant le nettoyage alors que vous vous attendiez à ce que ce soit le processus parent qui le fasse. (Nous aimerions que ce soit le cas dans la vie réelle.)
Comme c'est une erreur courante d'utiliser exec au lieu de system, Perl vous en avertit si la prochaine instruction n'est pas die, warn ou exit, lorsqu'il est lancé avec l'option populaire de la ligne de commande -w, ou si vous employez le pragma use warnings qw(exec syntax). Si vous voulez vraiment faire suivre un exec d'une autre instruction, vous pouvez utiliser l'un ou l'autre de ces styles pour éviter l'avertissement :
exec ('machin') or print STDERR "exec machin impossible : $!";
{ exec ('machin') }; print STDERR "exec machin impossible : $!";Comme dans la seconde ligne ci-dessus, un appel à exec qui est la dernière instruction dans un bloc est exempt de cet avertissement.
Voir aussi system.
exists
exists EXPRCette fonction renvoie vrai si la clef de hachage ou l'indice de tableau spécifié existe dans le hachage ou le tableau. Peu importe que la valeur correspondante soit vraie ou fausse, ou même qu'elle soit définie.
print "Vraie\n" if $hachage{$clef};
print "Définie\n" if defined $hachage{$clef};
print "Existe\n" if exists $hachage{$clef};
print "Vrai\n" if $tableau[$indice];
print "Défini\n" if defined $tableau[$indice];
print "Existe\n" if exists $tableau[$indice];Un élément ne peut être vrai que s'il est défini, et ne peut être défini que s'il existe, mais l'inverse n'est pas forcément valable.
EXPR peut être arbitrairement complexe, tant que l'opération finale est une consultation de clef de hachage ou d'indice de tableau.
if (exists $hachage{A}{B}{$clef}) { ... }Bien que le dernier élément ne vienne pas à exister spontanément seulement parce qu'on a testé son existence, c'est le cas de ceux que l'on fait intervenir. Ainsi, $$hachage{"A"} et $hachage{"A"}->{"B"} se mettent tous deux à exister. Ce n'est pas une fonctionnalité de exists en soi ; cela se produit partout où l'opérateur flèche est utilisé (explicitement ou implicitement) :
undef $ref if (exists $ref->"Une clef"}) { }
print $ref; # affiche HASH(0x80d3d5c)Même si l'élément "Une clef" ne se met pas à exister, la variable $ref, indéfinie auparavant, vient tout à coup contenir un hachage anonyme. C'est une instance surprise d'autovivification de ce qui n'apparaissait pas au premier — ou même au second — coup d'œil comme un contexte lvalue. Ce comportement sera agréablement corrigé dans une prochaine version. Autrement, vous pouvez emboîter vos appels :
if ($ref and exists $ref->[$x] and
exists $ref->[$x][$y] and
exists $ref->[$x][$y]{$clef} and
exists $ref->[$X][$y]{$clef}[2] ) { }Si EXPR est le nom d'un sous-programme, la fonction exists renverra vrai si celui-ci est a été déclaré, même s'il n'a pas encore été défini. L'exemple suivant affiche seulement « Existe » :
L'utilisation d'exists avec le nom d'un sous-programme peut être utile pour un sous-programme AUTOLOAD qui a besoin de savoir si un paquetage particulier veut qu'un sous-programme particulier soit défini. Le paquetage peut indiquer ceci en déclarant un entête de sub comme couic.
exit
Cette fonction évalue EXPR comme un entier et sort immédiatement avec cette valeur comme statut d'erreur final du programme. Si EXPR est omise, la fonction sort avec le statut 0 (signifiant « aucune erreur »). Voici un fragment qui permet à un utilisateur de sortir du programme en entrant x ou X.
Vous ne devriez pas utiliser exit pour quitter un sous-programme s'il y a la moindre chance que quelqu'un veuille intercepter l'erreur qui s'est produite. Utilisez plutôt die, qui peut être intercepté par un eval. Ou alors, utilisez l'une des sur-couches de die du module Carp, comme croak ou confess.
Nous avons dit que la fonction exit sortait immédiatement, mais c'était un mensonge d'arracheur de dents. Elle sort aussitôt que possible, mais elle appelle tout d'abord les routines END définies afin les gérer les événements de fin (N.d.T. : at-exit). Ces routines ne peuvent pas annuler la terminaison, bien qu'elles puissent changer la valeur de retour éventuelle en positionnant la variable $?. De la même manière, toute classe qui définit une méthode DESTROY peut invoquer cette méthode au nom de tous ses objets avant que le programme réel ne finisse. Si vous avez vraiment besoin d'outrepasser le traitement avant la terminaison, vous pouvez appeler les fonctions _exit du module POSIX pour éviter toutes les opérations de END et des destructeurs. Et si POSIX n'est pas disponible, vous pouvez faire un exec "/bin/false" ou quelque chose de ce genre.
exp ![]()
exp EXPR
expCette fonction renvoie e à la puissance EXPR. Pour obtenir la valeur de e, utilisez juste exp(1). Pour effectuer une exponentiation générale de différentes bases, utilisez l'opérateur ** que nous avons emprunté au FORTRAN :
use Math::Complex;
print -exp(1) ** (i * pi); # affiche 1fcntl ![]()
![]()
![]()
![]()
![]()
fcntl HANDLE_FICHIER, FONCTION, SCALAIRECette fonction appelle les fonctions de contrôle de fichier de votre système d'exploitation, documentées dans la page de man de fnctl(2). Avant d'appeler fcntl, vous devrez probablement tout d'abord écrire :
use Fcntl;pour charger les définitions correctes des constantes.
SCALAIRE sera lu ou écrit (ou les deux) selon la FONCTION. Un pointeur sur la valeur de chaîne de SCALAIRE sera passé comme troisième argument de l'appel véritable à fcntl. (Si SCALAIRE n'a pas de valeur chaîne, mais une valeur numérique, celle-ci sera passée directement au lieu d'un pointeur sur la valeur chaîne.) Voir le module Fcntl pour une description des valeurs les plus communes qu'il est possible d'employer pour FONCTION.
La fonction fcntl lèvera une exception si elle est utilisée sur un système qui n'implémente pas fcntl(2). Sur les systèmes qui au contraire l'implémentent, vous pouvez faire des choses comme modifier les flags close-on-exec (si vous ne désirez pas jouer avec la variable $^F ($SYSTEM_FD_MAX)), modifier les flags d'entrées/sorties non bloquantes, émuler la fonction lockf (3) ou s'arranger pour recevoir un signal SIGIO lorsqu'il y a des entrées/sorties en attente.
Voici un exemple où l'on rend non bloquant au niveau du système, un handle de fichier nommé DISTANT. Ceci fait que toute opération d'entrée revient immédiatement si rien n'est disponible lors d'une lecture dans un pipe, une socket ou une ligne série qui autrement aurait bloqué. De même, les opérations de sortie qui bloqueraient normalement, renvoient un statut d'échec à la place. (Pour celles-ci, vous feriez mieux de négocier également $|.)
use Fcntl qw(F_GETFL F_SETFL O_NONBLOCK);
$flags = fcntl(DISTANT, F_GETFL, 0)
or die "Impossible de lire les flags pour la socket : $!\n";
$flags = fcntl(DISTANT, F_SETFL, $flags | O_NONBLOCK)
or die "Impossible de modifier les flags de la sockets : $!\n";La valeur de retour de fcntl (et de ioctl) se comporte comme ceci :
|
L'appel système renvoie |
Perl renvoie |
|---|---|
|
-1 |
|
|
0 |
La chaîne « |
|
autre chose |
Le même nombre. |
Perl rend donc vrai pour un succès et faux pour un échec, tout en vous laissant facilement déterminer la véritable valeur renvoyée par le système d'exploitation :
$valret = fcntl() || -1;
printf "fcntl a vraiment renvoyé %d\n", $valret;Ici, même la chaîne « 0 but true » affiche 0, grâce au format %d. Cette chaîne est vraie dans un contexte booléen et 0 dans un contexte numérique. (Par bonheur, elle est également exempte des avertissements habituels pour les conversions numériques inadaptées.)
fileno ![]()
fileno HANDLE_FICHIERCette fonction renvoie le descripteur de fichier sous-jacent d'un handle de fichier. Si ce handle de fichier n'est pas ouvert, fileno renvoie undef. Un descripteur de fichier est un petit entier positif comme 0 ou 1, alors que les handles de fichiers comme STDIN ou STDOUT sont des symboles. Malheureusement, le système d'exploitation ne connaît pas vos sympathiques symboles. Il ne pense aux fichiers ouverts qu'en terme de ces petits numéros de fichiers et bien que Perl fasse automatiquement la traduction pour vous, vous devrez parfois connaître le véritable descripteur de fichier.
Par exemple, la fonction fileno est utile pour construire des masques de bits pour select et pour passer certains appels système obscurs si syscall(2) est implémenté. Elle sert également à vérifier que la fonction open vous a donné le descripteur de fichier que vous vouliez et également à déterminer si deux handles de fichiers utilisent le même descripteur de fichier système.
if (fileno(CECI) == fileno(CELA)) {
print "CECI et CELA sont des duplicata\n";
}Si HANDLE_FICHIER est une expression, sa valeur est prise comme un handle de fichier indirect, généralement son nom ou une référence à quelque chose qui ressemble à un objet handle de fichier.
Attention : ne comptez pas sur une association entre un handle de fichier Perl et un descripteur de fichier numérique qui soit permanente tout au long de la vie du programme. Si un fichier a été fermé et rouvert, le descripteur de fichier peut changer. Perl s'efforce d'assurer que certains descripteurs de fichiers ne sont pas perdus si un open sur eux échoue, mais il ne fait cela que pour les descripteurs de fichiers qui ne dépassent pas la valeur courante de la variable spéciale $^F ($SYSTEM_MAX_FD) (par défaut, 2). Bien que les handles de fichiers STDIN, STDOUT et STDERR démarrent avec les descripteurs de fichiers 0, 1 et 2 (la convention standard Unix), même ceux-ci peuvent changer si vous commencez à les fermer et les ouvrir sans prendre garde. Ceci dit, vous ne pouvez pas avoir d'ennuis avec 0, 1 et 2 aussi longtemps que vous les rouvrez toujours immédiatement après les avoir fermés. La règle de base sur les systèmes Unix est de prendre le descripteur disponible le plus bas possible, et ce sera celui que vous venez juste de fermer.
flock ![]()
![]()
![]()
flock HANDLE_FICHIER, OPÉRATIONLa fonction flock est l'interface portable de Perl pour le verrouillage de fichiers, bien qu'elle ne verrouille un fichier que dans son intégralité et non des enregistrements. La fonction gère les verrous sur le fichier associé à HANDLE_FICHIER, en renvoyant vrai pour un succès et faux sinon. Pour éviter la possibilité de perdre des données, Perl vide le tampon de votre HANDLE_FICHIER avant de le verrouiller ou de le déverrouiller. Perl peut implémenter son flock avec flock(2), fcntl(2), lockf (3) ou des mécanismes de verrouillage spécifiques à d'autres plates-formes, mais si aucun d'entre eux n'est disponible, appeler flock lève une exception. Voir la section Verrouillage de fichier au chapitre 16.
OPÉRATION peut valoir LOCK_SH, LOCK_EX ou LOCK_UN, combinés éventuellement par un OU avec LOCK_NB. Ces constantes valent généralement 1, 2, 8 et 4, mais vous pouvez employer les noms symboliques si vous les importez depuis le module Fcntl, soit individuellement, soit par groupe en utilisant le tag :flock.
LOCK_SH demande un verrou partagé, il est donc généralement utilisé pour les lectures. LOCK_EX demande un verrou exclusif, il est donc généralement utilisé pour les écritures. LOCK_UN relâche un verrou demandé auparavant ; fermer le fichier relâche également ses verrous. Si le bit LOCK_NB est employé avec LOCK_SH ou LOCK_EX, flock rend la main immédiatement au lieu d'attendre un verrou indisponible. Vérifiez le statut de retour pour voir si vous avez obtenu le verrou que vous avez demandé. SI vous n'utilisez pas LOCK_NB, vous pouvez attendre indéfiniment l'accès au verrou.
Un autre aspect difficile, mais général, de flock est que ses verrous sont simplement consultatifs. Les verrous discrets sont plus flexibles, mais offrent moins de garanties que les verrous obligatoires. Cela signifie que les fichiers verrouillés avec flock peuvent être modifiés par les programmes qui n'utilisent pas flock. Les voitures qui s'arrêtent aux feux rouges s'entendent bien entre elles, mais pas avec celles qui ne s'arrêtent pas aux feux rouges. Conduisez sur la défensive.
Certaines implémentations de flock ne peuvent pas verrouiller quoique ce soit à travers un réseau. Bien qu'en théorie vous puissiez utiliser fcntl, plus spécifique au système, pour cela, le jury (ayant délibéré sur le cas pendant à peu près une décennie) est toujours indécis pour déterminer si c'est une chose digne de confiance ou non.
Voici un exemple qui ajoute un message à la fin d'une boîte aux lettres sur les systèmes Unix qui utilisent flock(2) pour verrouiller les boîtes aux lettres :
use Fcntl qw/:flock/ # importer les constantes FLOCK_*
sub mon_verrou {
flock(MBOX, LOCK_EX)
or die "Impossible de verrouiller la boîte aux lettres : $!";
# dans le cas ou quelqu'un ajoutait quelque chose alors que
#nous étions en train d'attendre et que notre tampon stdio ne
# soit pas synchronisé
seek(MBOX, 0, 2)
or die "Impossible de se positionner à la fin de la boîte aux
lettres : $!";
}
open(MBOX, "> >/usr/spool/mail/$ENV{'USER'}")
or die "Impossible d'ouvrir la boîte aux lettres : $!";
mon_verrou();
print MBOX $msg, "\n\n";
close MBOX
or die "Impossible de fermer la boîte aux lettres : $!";Sur les systèmes qui supportent un appel système flock(2) réel, les verrous sont hérités à travers les appels à fork. Les autres implémentations ne sont pas aussi chanceuses et sont susceptibles de perdre les verrous à travers les forks. Voir également le module DB_File au chapitre 32 pour d'autres exemples de flock.
fork ![]()
![]()
forkCette fonction crée deux processus à partir d'un seul en invoquant l'appel système fork(2). En cas de réussite, la fonction renvoie l'ID du nouveau processus fils au processus parent et 0 au processus fils. Si le système ne dispose pas des ressources suffisantes pour allouer un nouveau processus, l'appel échoue et retourne undef. Les descripteurs de fichiers (et parfois les verrous sur ces descripteurs) sont partagés, alors que tout le reste est copié — ou moins paraît l'être.
Dans les versions de Perl antérieures à 5.6, les tampons non vidés le restent dans les deux processus, ce qui veut dire qu'il vous faut parfois positionner $| sur un ou plusieurs handles de fichiers à l'avance pour éviter des sorties dupliquées.
Voici une façon de blinder presque totalement le lancement d'un processus fils tout en testant les erreurs de type « fork impossible » :
use Errno qw(EAGAIN);
FORK: {
if ($pid = fork) {
# on est ici dans le père
# le pid du processus fils est accessible par $pid
}
elsif (defined $pid) { # $pid vaut ici 0 s'il défini
# on est ici dans le fils
# le pid du processus père est accessible par getppid
}
elsif ($! == EAGAIN) {
# EAGAIN est l'erreur de fork susceptible d'être corrigée
sleep 5;
redo FORK;
}
else {
# erreur de fork étrange
die "fork impossible :$!\n";
}
}Ces précautions ne sont pas nécessaires pour des opérations qui font un fork(2) implicite, comme system, les apostrophes inverses ou l'ouverture d'un processus comme un handle de fichier, car Perl réessaye automatiquement un fork en cas d'échec dans ces cas. Faites très attention à terminer le code du fils par un exit, faute de quoi le fils pourrait quitter par inadvertance le bloc conditionnel et commencer à exécuter du code prévu pour le seul processus père.
Si vous fork ez sans même attendre vos enfants, vous accumulerez les zombies (les processus terminés qui n'ont toujours pas de parents qui les attendent). Sur certains systèmes, vous pouvez éviter ceci en positionnant $SIG{CHLD} à "IGNORE" ; sur la plupart, vous devrez attendre avec wait vos enfants moribonds. Vous en trouverez des exemples dans la description de la fonction wait, ou dans la section Signaux du chapitre 16.
Si un fils fork é hérite des descripteurs fichiers systèmes comme STDIN ou STDOUT qui sont connectés à un pipe distant ou à une socket, il se peut que vous deviez les redirigez vers /dev/null dans le fils. Ceci, car même lorsque le processus père se termine, le fils vivra avec ses copies de ces handles de fichiers. Le serveur distant (mettons comme un script CGI ou une tâche lancée en arrière-plan par un shell distant) semblera bloquer, car il attendra que toutes les copies soient fermées. Rouvrir les handles de fichiers systèmes en les dirigeant vers autre chose corrige ceci.
Sur la plupart des systèmes supportant fork(2), on a porté une attention toute particulière à ce que la fonction soit performante (par exemple, utilisant une technologie de copie en écriture sur les pages de données), ce qui en fait le paradigme dominant de ces dernières décennies pour le multitâche. La fonction fork est susceptible de ne pas être implémentée efficacement, voire de ne pas être implémentée du tout, sur les systèmes qui ne ressemblent pas à Unix. Par exemple, Perl 5.6 émule un fork approprié sur les systèmes de Microsoft, mais sans assurance sur les performances à ce jour. Vous pouvez avoir plus de chances ici avec le module Win32::Process.
format
format NOM =
ligne d'image
liste de valeurs
...
.Cette fonction déclare une séquence nommée de lignes d'images (avec les valeurs associées) à l'usage de la fonction write. Si NOM est omis, le nom par défaut est STDOUT, qui est celui du format par défaut pour le handle de fichier STDOUT. Puisque, comme pour une déclaration de sub, il s'agit d'une déclaration globale au paquetage se produisant à la compilation, toutes les variables utilisées dans la liste de valeurs doivent être visibles au point de la déclaration du format. C'est-à-dire que les variables à portée lexicale doivent être auparavant déclarées dans le fichier, alors que les variables à portée dynamique peuvent n'être initialisées qu'au moment où l'on appelle write. En voici un exemple (qui suppose que nous avons déjà calculé $cout et $quantite :
my $chn = "widget"; # Une variable de portée lexicale.
format Jolie_Sortie =
Test: @<<<<<<<< @||||| @>>>>>
$chn, $%, '$' . int($num)
.
local $~ = "Jolie_Sortie"; # Sélection du format.
local $num = $cout * $quantite; # Variable de portée dynamique.
write;Tout comme les handles de fichier, les noms de format sont de simples identificateurs qui existent dans une table de symboles (paquetage) et peuvent être pleinement qualifiés par le nom du paquetage. Dans les typeglobs des entrées d'une table de symboles, les formats résident dans leur propre espace de noms, qui est distinct des handles de fichiers et de répertoires, des scalaires, des tableaux, des hachages ou des sous-programmes. Cependant, comme pour ces six autres types, un format nommé Nimportequoi serait aussi affecté par un local sur le typeglob *Nimportequoi. En d'autres termes, un format n'est qu'un machin de plus, contenu dans un typeglob, indépendant des autres machins.
La section Variables de format du chapitre 7, Formats contient de nombreux détails et des exemples d'utilisation. Le chapitre 28 décrit les variables internes spécifiques aux formats, et les modules English et FileHandle y fournissent un accès aisé.
formline
formline IMAGE, LISTEIl s'agit d'une fonction interne utilisée par les format s, bien que vous puissiez également l'appeler vous-même. Elle formate une liste de valeurs d'après le contenu d'IMAGE, en plaçant la sortie dans l'accumulateur de sortie, $^A (ou $ACCUMULATOR si vous utilisez le module English). Finalement, au moment d'un write, le contenu de $^A est écrit vers un handle de fichier, mais vous pouvez aussi bien lire $^A par vous-même pour ensuite le remettre à "". Typiquement, un format lance un formline par ligne de format, mais la fonction formline elle-même ne fait pas attention au nombre de sauts de ligne inclus dans l'IMAGE. Cela veut dire que les tokens ~ et ~~ traitent IMAGE comme une seule ligne. Il peut donc être nécessaire d'employer plusieurs formline s pour implémenter un unique format d'enregistrement, comme le compilateur de format le fait en interne.
Attention si vous mettez des doubles apostrophes autour de l'image, car un caractère @ peut être confondu avec le début d'un nom de tableau. Voir le chapitre 7, Formats, pour des exemples d'utilisation.
getc ![]()
![]()
getc HANDLE_FICHIER
getcCette fonction renvoie le caractère suivant depuis le fichier d'entrée attaché à HANDLE_FICHIER. Elle renvoie undef à la fin du fichier ou si une erreur d'entrée/sortie se produit. Si HANDLE_FICHIER est omis, la fonction lit depuis STDIN.
Cette fonction est quelque peu lente, mais se révèle parfois utile pour les entrées d'un seul caractère (octet, réellement) au clavier — pourvu que vous vous arrangiez pour que les entrées depuis le clavier ne passent pas par un tampon. Cette fonction demande une entrée non tamponnée depuis la bibliothèque standard d'entrée/sortie. Malheureusement, la bibliothèque standard d'entrée/sortie n'est pas assez standard pour fournir une manière portable de dire au système d'exploitation sous-jacent de donner au système d'entrée/sortie des entrées non tamponnées depuis le clavier. Pour accomplir ceci, vous devez être un peu plus habile et utiliser un style dépendant du système d'exploitation. Sous Unix, vous pourriez dire ceci :
if ($BSD_STYLE) {
system "stty cbreak </dev/tty >/dev/tty 2>&1";
} else {
system "stty", "-icanon", "eol", "\001";
}
$clef = getc;
if ($BSD_STYLE) {
system "stty -cbreak </dev/tty >/dev/tty 2&1";
} else {
system "stty", "icanon", "eol", "^@"; # ASCII NUL
}
print "\n";Ce code met le prochain caractère (octet) frappé sur le terminal dans la chaîne $clef. Si votre programme stty possède des options comme cbreak, vous devrez utiliser le code où $BSD_STYLE est vrai. Sinon, vous devrez utiliser le code où il est faux. Déterminer les options de stty(1) est laissé comme exercice au lecteur.
Le module POSIX en fournit une version plus portable grâce à la fonction POSIX::getattr. Voir aussi le module Term::ReadKey dans votre site CPAN le plus proche pour une approche plus portable et plus flexible.
getgrent ![]()
getgrent
setgrent
endgrentCes routines parcourent votre fichier /etc/group (ou peut-être le fichier /etc/group de quelqu'un d'autre, s'il provient d'un serveur quelque part). La valeur renvoyée par getgrent dans un contexte de liste est :
($nom, $mot_de_passe, $gid, $membres)où $membres contient une liste des noms de login des membres du groupe séparés par des espaces. Pour mettre en œuvre un hachage traduisant les noms de groupes en GID, écrivez ceci :
while (($nom, $mot_de_passe, $gid) = getgrent) {
$gid{$nom} = $gid;
}Dans un contexte scalaire, getgrent renvoie seulement le nom du groupe. Le module standard User::grent supporte une interface orientée par nom pour cette fonction. Voir getgrent(3).
getgrid ![]()
getgrid GIDCette fonction recherche une entrée de fichier de groupe par le numéro du groupe. La valeur renvoyée dans un contexte de liste est :
($nom, $mot_de_passe, $gid, $membres)où $membres contient une liste des noms de login des membres du groupe séparés par des espaces. Si vous voulez faire cela de façon répétitive, il vaut mieux utiliser un hachage comme cache en utilisant getgrent.
Dans un contexte scalaire, getgrid renvoie seulement le nom du groupe. Le module standard User::grent supporte une interface orientée par nom pour cette fonction. Voir getgrid(3).
getgrnam ![]()
getgrid NOMCette fonction recherche une entrée de fichier de groupe par le nom du groupe. La valeur renvoyée dans un contexte de liste est :
($nom, $mot_de_passe, $gid, $membres)où $membres contient une liste des noms de login des membres du groupe séparés par des espaces. Si vous voulez faire cela de façon répétitive, il vaut mieux utiliser un hachage comme cache en utilisant getgrent.
Dans un contexte scalaire, getgrnam renvoie seulement le nom du groupe. Le module standard User::grent supporte une interface orientée « par nom » pour cette fonction. Voir getgrnam(3).
gethostbyaddr ![]()
gethostbyaddr ADR, TYPE_ADRCette fonction convertit des adresses en noms (et en adresses alternatives). ADR doit être une adresse réseau binaire empaquetée et TYPE_ADR en pratique doit être normalement AF_INET (du module Socket). La valeur de retour dans un contexte de liste est :
($nom, $alias, $type_adr, $longueur, @adrs) =
gethostbyaddr($adresse_binaire_empaquetée, $type_adr);où @adrs est une liste d'adresses brutes. Dans le domaine de l'Internet, chaque adresse est (historiquement) longue de 4 octets et peut être découpée en écrivant quelque chose comme ceci :
($a, $b, $c, $d) = unpack('C4', $adrs[0]);Ou alors, vous pouvez directement la convertir dans la notation de vecteur pointé avec le modificateur v de sprintf :
$points = sprintf "%vd", $adrs[0];La fonction inet_ntoa du module Socket est très utile pour produire une version affichable. Cette approche deviendra importante si et quand nous parviendrons à passer à IPv6.
Dans un contexte scalaire, gethostbyaddr renvoie seulement le nom de l'hôte. Pour obtenir une ADR à partir d'un vecteur pointé, écrivez ceci :
use Socket;
$adr_ip = inet_aton("127.0.0.1"); # localhost
$nom_officiel = gethostbyaddr($adr_ip, AF_INET);De manière intéressante, vous pouvez avec la version 5.6 de Perl vous passer de inet_aton et employer la nouvelle notation v-chaîne, qui a été inventée pour les numéros de versions, mais il est apparu qu'elle fonctionnait aussi bien pour les adresses IP :
$adr_ip = v127.0.0.1;Voir la section Sockets au chapitre 16 pour plus d'exemples. Le module Net::hostent supporte une interface orientée « par nom » pour cette fonction. Voir gethostbyaddr(3).
gethostbyname ![]()
gethostbyname NOMCette fonction convertit un nom d'hôte réseau en son adresse correspondante (et en d'autres noms). La valeur de retour dans un contexte de liste est :
($nom, $alias, $type_adr, $longueur, @adrs) =
gethostbyname($nom_hote_distant);où @adrs est une liste d'adresses brutes. Dans le domaine de l'Internet, chaque adresse est (historiquement) longue de 4 octets et peut être découpée en écrivant quelque chose comme ceci :
($a, $b, $c, $d) = unpack('C4', $adrs[0]);Vous pouvez directement la convertir dans la notation de vecteur avec le modificateur v de sprintf :
$points = sprintf "%vd", $adrs[0];Dans un contexte scalaire, gethostbyname renvoie uniquement l'adresse de l'hôte :
use Socket;
$adr_ip = gethostbyname($hote_distant);
printf "%s a comme adresse %s\n",
$hote_distant, inet_ntoa($adr_ip);Voir la section Sockets au chapitre 16 pour une autre approche. Le module Net::hostent supporte une interface orientée par nom pour cette fonction. Voir également gethostbyname(3).
gethostent ![]()
gethostent
sethostent RESTE_OUVERT
endhostentCes fonctions parcourent votre fichier /etc/hosts et renvoient chaque entrée une par une. La valeur de retour de gethostent dans un contexte de liste est :
($nom, $alias, $longueur, @adrs)où @adrs est une liste d'adresses brutes. Dans le domaine Internet, chaque adresse est longue de 4 octets et peut être découpée en écrivant quelque chose comme ceci :
($a, $b, $c, $d) = unpack('C4', $adrs[0]);Les scripts qui utilisent gethostent ne doivent pas être considérés comme portables. Si une machine utilise un serveur de noms, elle interrogera la quasi-totalité de l'Internet pour tenter de satisfaire une requête portant sur toutes les adresses de toutes les machines de la planète. Voir gethostent(3) pour d'autres détails.
Le module Net::hostent supporte une interface orientée par nom pour cette fonction.
getlogin ![]()
getloginCette fonction renvoie le nom de login courant s'il est trouvé. Sur les systèmes Unix, il est lu à partir du fichier utmp(5). Si la fonction renvoie faux, utilisez getpwuid à la place. Par exemple :
$login = getlogin() || (getpwuid($<))[0]) || "Intrus !!";getnetbyaddr ![]()
getnetbyaddr ADR, TYPE_ADRCette fonction convertit une adresse réseau vers le nom ou les noms de réseau correspondants. La valeur renvoyée dans un contexte de liste est :
Dans un contexte scalaire, getnetbyaddr renvoie seulement le nom du réseau. Le module Net::netent supporte une interface orientée par nom pour cette fonction. Voir getnetbyaddr(3).
getnetbyname ![]()
getnetbyname NOMCette fonction convertit un nom de réseau vers son adresse réseau correspondante. La valeur de retour dans un contexte de liste est :
($nom, $alias, $type_adr, $reseau) = getnetbyname("loopback");Dans un contexte scalaire, getnetbyname renvoie seulement l'adresse du réseau. Le module Net::netent supporte une interface orientée par nom pour cette fonction. Voir getnetbyname(3).
getnetent ![]()
getnetent
setnetent RESTE_OUVERT
endnetentCes fonctions parcourent votre fichier /etc/networks. La valeur renvoyée dans un contexte de liste est :
($nom, $alias, $type_adr, $reseau) = getnetent();Dans un contexte scalaire, getnetent renvoie seulement le nom du réseau. Le module Net::netent supporte une interface orientée par nom pour cette fonction. Voir getnetent(3).
Le concept de nom de réseau semble un peu désuet de nos jours ; la plupart des adresses IP étant sur des sous-réseaux innommés (et innommables).
getpeername ![]()
![]()
![]()
getpeername SOCKETCette fonction l'adresse socket empaquetée de l'autre extrémité de la connexion SOCKET. Par exemple :
use Socket;
$son_adr_sock = getpeername SOCK;
($port, $son_adr) = sockaddr_in($son_adr_sock);
$son_nom_hote = gethostbyaddr($son_adr, AF_INET);
$son_adr_chaine = inet_ntoa($son_adr);getpgrp ![]()
getpgrp PIDCette fonction renvoie l'identifiant du groupe de processus courant pour le PID spécifié (employez un PID égal à 0 pour le processus courant). L'invocation de getpgrp lèvera une exception sur une machine n'implémentant pas getpgrp(2). Si PID est omis, la fonction renvoie le groupe de processus du processus courant (ce qui est identique à un PID de 0). Sur les systèmes qui implémentent cet opérateur avec l'appel système POSIX getpgrp(2), PID doit être omis ou, s'il est fourni, doit être égal à 0.
getppid ![]()
getppidCette fonction renvoie l'identifiant du processus parent. Sur un système UNIX typique, si l'ID du processus père se change en 1, c'est que ce dernier est mort et que le processus courant a été adopté par le programme init(8).
getpriority ![]()
![]()
getpriority QUOI, QUICette fonction renvoie la priorité courante d'un processus, d'un groupe de processus ou d'un utilisateur. Voir getpriority(2). Son invocation lèvera une exception sur une machine où getpriority(2) n'est pas implémentée.
Le module BSD::Resource de CPAN fournit une interface plus pratique, comprenant les constantes symboliques PRIO_PROCESS, PRIO_PGRP et PRIO_USER qu'il faut fournir pour l'argument QUOI. Bien qu'elles soient généralement égales à 0, 1 et 2 respectivement, vous ne savez vraiment pas ce qui peut se passer aux sombres confins des fichiers #include du C.
Une valeur de 0 pour QUI signifie le processus, le groupe de processus ou l'utilisateur courant, ainsi pour obtenir la priorité du processus en cours, utilisez :
$prio_cour = getpriority(0, 0);getprotobyname ![]()
getprotobyname NOMCette fonction convertit un nom de protocole vers son numéro correspondant. La valeur renvoyée dans un contexte de liste est :
($nom, $alias, $numero_protocole) = getprotobyname("tcp");Lorsqu'on l'appelle dans un contexte scalaire, getprotobyname renvoie seulement le numéro de protocole. Le module Net::proto supporte une interface orientée par nom pour cette fonction. Voir getprotobyname(3).
getprotobynumber ![]()
getprotobynumber NUMEROCette fonction convertit un numéro de protocole vers son nom correspondant. La valeur renvoyée dans un contexte de liste est :
($nom, $alias, $numero_protocole) = getprotobynumber(6);Lorsqu'on l'appelle dans un contexte scalaire, getprotobynumber renvoie seulement le nom de protocole. Le module Net::proto supporte une interface orientée par nom pour cette fonction. Voir getprotobynumber(3).
getprotoent ![]()
getprotoent
setprotoent RESTE_OUVERT
endprotoentCes fonctions parcourent votre fichier /etc/protocols. Dans un contexte de liste, la valeur renvoyée par getprotoent est :
($nom, $alias, $numero_protocole) = getprotoent();Lorsqu'on l'appelle dans un contexte scalaire, getprotoent renvoie seulement le numéro du protocole. Le module Net::protoent supporte une interface orientée par nom pour cette fonction. Voir getprotent(3).
getpwent ![]()
![]()
getpwent
setpwent
endpwentCes fonctions parcourent conceptuellement votre fichier /etc/passwd, bien que ceci puisse impliquer le fichier /etc/shadow si vous êtes le super-utilisateur et que vous utilisez les mots de passe « shadow », NIS (ex-Pages Jaunes, Yellow Pages, YP) ou NIS+. La valeur renvoyée dans un contexte de liste est :
($nom,$mot_de_passe,$uid,$gid,$quota,$commentaire,$nom_reel,$rep,$shell)= getpwent();Certaines machines peuvent utiliser les champs quota et commentaire à d'autres fins que leurs noms ne le laissent supposer, mais les champs restants seront toujours les mêmes. Pour mettre en œuvre un hachage de traduction des noms de login en UID, écrivez ceci :
while (($nom, $mot_de_passe, $uid) = getpwent()) {
$uid{$nom} = $uid;
}Dans un contexte scalaire, getpwent renvoie seulement le nom d'utilisateur. Le module User::pwent supporte une interface orientée par nom pour cette fonction. Voir getpwent(3).
getpwnam ![]()
![]()
getpwnam NOMCette fonction convertit un nom d'utilisateur vers l'entrée correspondante du fichier /etc/passwd. La valeur renvoyée dans un contexte de liste :
($nom,$mot_de_passe,$uid,$gid,$quota,$commentaire,$nom_reel,$rep,$shell)= getpwnam("daemon");Sur les systèmes qui supportent les mots de passe « shadow », vous devrez être le super-utilisateur pour récupérer le véritable mot de passe. Votre bibliothèque C doit remarquer que vous avez les permissions suffisantes et ouvre votre fichier /etc/shadow (ou n'importe quel endroit où le fichier shadow est conservé). Du moins, c'est censé fonctionner ainsi. Perl essayera de faire ceci si votre bibliothèque C est trop stupide pour le remarquer.
Pour faire des recherches répétitives, mieux vaut utiliser un hachage comme cache avec getpwent.
Dans un contexte scalaire, getpwnam renvoie seulement l'UID numérique. Le module User::pwent supporte une interface orientée par nom pour cette fonction. Voir getpwnam(3) et passwd(5).
getpwuid ![]()
![]()
getpwuid UIDCette fonction convertit un UID numérique vers l'entrée correspondante du fichier /etc/passwd. La valeur renvoyée dans un contexte de liste :
($nom,$mot_de_passe,$uid,$gid,$quota,$commentaire,$nom_reel,$rep,$shell)= getpwuid(2);Pour faire des recherches répétitives, mieux vaut utiliser un hachage comme cache avec getpwent.
Dans un contexte scalaire, getpwuid renvoie seulement le nom de l'utilisateur. Le module User::pwent supporte une interface orientée « par nom » pour cette fonction. Voir getpwnam(3) et passwd(5).
getservbyname ![]()
getservbyname NOM, PROTOCette fonction convertit un nom de service (port) vers son numéro de port correspondant. PROTO est un nom de protocole comme "tcp". La valeur renvoyée dans un contexte de liste est :
($nom, $alias, $numero_port, $nom_protocole) = getservbyname("www", "tcp");Dans un contexte scalaire, getservbyname renvoie seulement le numéro du port de service. Le module Net::servent supporte une interface orientée par nom pour cette fonction. Voir getservbyname(3).
getservbyport ![]()
getservbyport PORT, PROTOCette fonction convertit un numéro de service (port) vers les noms correspondants. PROTO est un nom de protocole comme "tcp". La valeur renvoyée dans un contexte de liste est :
($nom, $alias, $numero_port, $nom_protocole) = getservbyport(80, "tcp");Dans un contexte scalaire, getservbyport renvoie seulement le nom du service. Le module Net::servent supporte une interface orientée par nom pour cette fonction. Voir getservbyport(3).
getservent ![]()
getservent
setservent RESTE_OUVERT
endserventCette fonction parcourt votre fichier /etc/services ou son équivalent. La valeur renvoyée dans un contexte de liste est :
($nom, $alias, $numero_port, $nom_protocole) = getservent();Dans un contexte scalaire, getservent renvoie seulement le nom du port de service. Le module Net::servent supporte une interface orientée par nom pour cette fonction. Voir getservent(3).
getsockname ![]()
![]()
![]()
getsockname SOCKETCette fonction renvoie l'adresse socket empaquetée de cette extrémité de la connexion SOCKET. (Et pourquoi ne connaîtriez-vous plus votre propre adresse ? Peut-être parce que vous avez attaché une adresse contenant des jokers (wildcards) à la socket serveur avant de faire un accept et que maintenant vous avez besoin de savoir à travers quelle interface quelqu'un est connecté avec vous. Ou la socket vous a été passée par votre processus père — inetd, par exemple.)
use Socket;
$mon_adr_sock = getsockname SOCK;
($port, $mon_adr) = sockaddr_in($mon_adr_sock);
$mon_nom = gethostbyaddr($mon_adr, AF_INET);
printf "Je suis %s [%vd]\n", $mon_nom, $mon_adr;getsockopt ![]()
![]()
![]()
getsockopt SOCKET, NIVEAU, NOM_OPTIONCette fonction renvoie l'option de socket requise ou undef en cas d'erreur. Voir setsockopt pour plus d'informations.
glob ![]()
![]()
![]()
![]()
glob EXPR
globCette fonction renvoie la valeur de EXPR avec expansion des noms de fichiers, exactement comme un shell le ferait. Il s'agit de la fonction interne implémentant l'opérateur <*>.
Pour des raisons historiques, l'algorithme correspond au style d'expansion de csh(1) et pas à celui du Bourne Shell. Les versions de Perl antérieures à 5.6 utilisaient un processus externe, mais la 5.6 et les suivantes exécutent les globs en interne. Les fichiers dont le premier caractère est un point (« . ») sont ignorés sauf si ce caractère correspond explicitement. Un astérisque (« * ») correspond à n'importe quelle séquence de n'importe quels caractères (y compris aucun). Un point d'interrogation (« ? ») correspond à un unique caractère, quel qu'il soit. Une séquence entre crochets (« [...] ») spécifie une simple classe de caractères, comme « [chy0-9] ». Les classes de caractères peuvent être niées avec un accent circonflexe, comme dans « *.[^oa] », qui correspond à tous les fichiers ne commençant pas par un point et dont les noms contiennent un point suivi par un seul caractère qui ne soit ni un « a », ni un « o » à la fin du nom. Un tilde (« ~ ») se développe en un répertoire maison, comme dans « ~/.*rc » pour les fichiers « rc » de l'utilisateur courant, ou « ~caro/Mail/* » pour tous les fichiers mails de Caro. On peut employer des accolades pour les alternatives, comme dans « ~/.{mail,ex,csh,twm,}rc » pour obtenir ces fichiers rc particuliers.
Si vous voulez glober sur des noms de fichiers qui peuvent contenir des espaces, vous devrez utilisez le module File::Glob directement, puisque les grands-pères de glob utilisaient les espaces pour séparer plusieurs motifs comme <*.c *.h>. Pour plus de détail, voir File::Glob au chapitre 32. L'appel de glob (ou de l'opérateur <*>) fait automatiquement un use sur ce module, donc si se module s'évapore mystérieusement de votre bibliothèque, une exception est levée.
Lorsque vous appelez open, Perl ne développe pas les jokers, y compris les tildes. Vous devez d'abord glober les résultats.
open(MAILRC, "~/.mailrc") # FAUX : le tilde est un truc du shell
or die "Impossible d'ouvrir ~/.mailrc : $!";
open(MAILRC, (glob("~/.mailrc"))[0]) # développe d'abord le tilde
or die "Impossible d'ouvrir ~/.mailrc : $!";La fonction glob n'a aucun rapport avec la notion Perl de typeglobs, sinon qu'elles utilisent toutes deux un * pour représenter plusieurs éléments.
Voir aussi la section Opérateur de globalisation des noms de fichier au chapitre 2.
gmtime
gmtime EXPR
gmtimeCette fonction convertit une heure renvoyée par la fonction time en un tableau de neuf éléments dont l'heure est en phase avec le méridien de Greenwich (alias GMT ou UTC, ou même Zoulou dans certaines cultures, dont ne fait bizarrement pas partie la culture Zoulou). Elle est généralement employée comme suit :
# 0 1 2 3 4 5 6 7 8
($sec,$min,$heure,$mjour,$mois,$annee,$sjour,$ajour,$est_dst) = gmtime();Si, comme dans ce cas, EXPR est omise, la fonction effectue gmtime(time()). Le module Time::Local de la bibliothèque Perl contient un sous-programme, timegm, qui peut à l'inverse convertir la liste vers une valeur de time.
Tous les éléments sont numériques et proviennent directement d'une struct tm (une structure de programmation C ; pas d'affolement). Cela signifie en particulier que $mois se situe dans l'intervalle 0..11 avec janvier comme le mois 0 et que $sjour est dans 0..6 avec dimanche comme jour 0. Vous pouvez vous rappeler de ceux qui commencent par zéro, car ce sont ceux que vous utilisez toujours comme indices dans les tableaux débutant par zéro contenant les noms des mois et des jours.
Par exemple, pour afficher le mois courant à Londres, vous pouvez écrire :
$mois_londres = (qw((Jan Fev Mar Avr Mai Jun
Jui Aou Sep Oct Nov Dec))[(gmtime)[4]];$annee est le nombre d'années depuis 1900 ; c'est-à-dire qu'en 2023, $annee vaudra 123, et pas simplement 23. Pour obtenir l'année sur 4 chiffres, il suffit d'écrire $annee+1900. Pour l'avoir sur 2 chiffres (par exemple « 01 » en 2001), utilisez sprintf("%02d", $annee % 100).
Dans un contexte scalaire, gmtime renvoie une chaîne ressemblant à ctime(3) basée sur la valeur de l'heure GMT. Le module Time::gmtime supporte une interface orientée « par nom » pour cette fonction. Voir aussi POSIX::strftime pour une approche permettant de formater des dates avec une granularité plus fine.
Cette valeur scalaire n'est pas dépendante des « locales », mais plutôt interne à Perl. Voir aussi le module Time::Local et les fonctions strftime(3) et mktime(3) disponibles via le module POSIX. Pour obtenir des chaînes pour la date qui soient similaires, mais locales, positionnez vos variables d'environnement locales de manière appropriée (merci de voir la page de man pour perllocale) et essayez :
Les caractères d'échappement %a et %b, qui représentent la forme abrégée pour le jour de la semaine et le mois de l'année, peuvent ne pas être nécessairement de trois caractères dans toutes les « locales ».
goto ![]()
goto ETIQUETTE trouve l'instruction étiquetée par ETIQUETTE et continue l'exécution à partir de là. Si l'ETIQUETTE est impossible à trouver, une exception est levée. Elle ne peut pas être utilisée pour aller dans une construction demandant une initialisation, comme un sous-programme ou une boucle foreach. De même, elle ne peut être employée pour rentrer dans une construction optimisée. Elle peut être utilisée pour aller quasiment partout ailleurs dans l'espace de portée d'adressage dynamique,(201) y compris pour sortir des sous-programmes, mais il vaut alors mieux employer une autre instruction comme last ou die. L'auteur de Perl n'a jamais ressenti le besoin d'utiliser cette forme de goto (en Perl — en C, c'est une autre histoire).
Pour aller plus loin dans l'orthogonalité (et plus profond dans la stupidité), Perl autorise gotoEXPR qui s'attend à ce que EXPR donne un nom d'étiquette, dont l'emplacement ne peut jamais être résolu avant l'exécution puisque l'étiquette est inconnue lorsqu'on compile l'instruction. Cela permet des goto s calculés comme en FORTRAN, mais ce n'est pas vraiment recommandé(202) lorsqu'on cherche à optimiser la maintenabilité :
goto +("TRUC", "MACHIN", "CHOUETTE")[$i];Sans aucun rapport, le goto &NOM fait de la grande magie en substituant un appel au sous-programme nommé en lieu et place du sous-programme actuellement en cours. Cette construction est utilisée sans scrupule par les sous-programmes AUTOLOAD qui veulent en charger un autre pour ensuite prétendre que celui-ci — et non l'original — a été appelé en premier lieu (sauf que toute modification de @_ dans le sous-programme d'origine est propagée dans le sous-programme de remplacement). Après le goto, même caller ne pourra pas dire que la routine AUTOLOAD originelle avait été appelée en premier lieu.
grep
grep EXPR, LISTE
grep BLOC LISTECette fonction évalue EXPR ou BLOC dans un contexte booléen pour chaque élément de LISTE, en positionnant temporairement $_ avec chaque élément tout à tour, un peu comme la construction foreach. Dans un contexte de liste, elle renvoie la liste des éléments pour lesquels l'expression est vraie. (L'opérateur a été nommé d'après le bien-aimé programme UNIX qui extrait les lignes d'un fichier qui correspondent à un motif particulier. En Perl, l'expression est souvent un motif, mais ce n'est pas obligatoire.) Dans un contexte scalaire, grep renvoie le nombre d'occurrences où l'expression est vraie.
À supposer que @toutes_les_lignes contienne des lignes de code, cet exemple élimine les lignes de commentaires :
@lignes_de_code = grep !/^\s*#/, @toutes_les_lignes;$_ étant un alias implicite à chaque valeur de la liste, l'altération de $_ modifiera les éléments de la liste originelle. Bien que ceci soit utile et supporté, les résultats peuvent devenir bizarres si l'on ne s'y attend pas. Par exemple,
@liste = qw(barney fred dino wilma);
@liste_grep = grep { s/^[bfd]// } @liste;@liste_grep contient maintenant « arney », « red », « ino », mais @liste est devenu « arney », « red », « ino », « wilma » ! Danger de bourde de programmeur.
Voir également map. Les deux instructions suivantes sont fonctionnellement équivalentes :
@sortie = grep { EXPR } @entree;
@sortie = map { EXPR ? $_ : () } @entreehex ![]()
hex EXPR
hexCette fonction interprète EXPR comme une chaîne hexadécimale et renvoie la valeur décimale équivalente. S'il y un « 0x » au début, il est ignoré. Pour interpréter des chaînes commençant soit par 0, soit par 0b, ou par 0x, voir oct. Le code suivant met $nombre à 4 294 906 560 :
$nombre = hex("ffff12c0");Pour la fonction inverse, employez sprintf :
sprintf "%lx", $nombre; # (la lettre L en minuscule, pas le chiffre un.)Les chaînes hexadécimales ne peuvent représenter que des entiers. Les chaînes qui causeraient un débordement de la limite pour les entiers déclenchent un avertissement.
import
Il n'existe pas de fonction import intégrée. Il s'agit essentiellement d'une méthode de classe ordinaire définie (ou héritée) par les modules qui désirent exporter des noms vers un autre module par l'intermédiaire de l'opérateur use. Voir use pour plus de détails.
index
index CHAINE, SOUS_CHAINE, DECALAGE
index CHAINE, SOUS_CHAINECette fonction recherche une chaîne à l'intérieur d'une autre. Elle renvoie la position de la première occurrence de SOUS_CHAINE dans CHAINE. Le DECALAGE, s'il est spécifié, indique à partir de combien de caractère débute la recherche. Les positions partent de 0 (ou de là où vous avez positionné la variable de base des indices $[, mais ne faites pas ça). Si la sous-chaîne n'est pas trouvée, la fonction renvoie un de moins que la base, généralement -1. Pour balayer une chaîne, on peut écrire :
$pos = -1;
while (($pos = index($chaine, $chaine_recherchee, $pos)) > -1) {
print "Trouvé en $pos\n";
$pos++;
}int ![]()
int EXPR
intCette fonction renvoie la partie entière de EXPR. Si vous êtes un programmeur C, vous êtes susceptible d'oublier fréquemment d'utiliser int en conjonction avec la division, qui est une opération en virgule flottante en Perl :
$age_moyen = 939/16; # donne 58.6875 (58 en C)
$age_moyen = int 939/16; # donne 58Vous ne devez pas employer cette fonction pour arrondir dans tous les cas, car elle tronque vers 0 et parce que la représentation pour la machine des nombres en virgule flottante peut quelquefois produire des résultats qui ne sont pas intuitifs. Par exemple, int(-6.725/0.025) donnera -268 au lieu de la valeur correcte -269 ; ceci, car la valeur est plus proche de -268.99999999999994315658. Généralement, les fonctions sprintf, printf ou POSIX::floor ou encore POSIX::ceil vous serviront plus que ne le ferait int.
$n = sprintf("%.0f", $f); # arrondit (et ne tronque pas)
# vers l'entier le plus procheIoctl ![]()
![]()
![]()
![]()
![]()
ioctl HANDLE_FICHIER, FONCTION, SCALAIRECette fonction implémente l'appel système ioctl(2) qui contrôle les entrées/sorties. Il vous faudra peut-être d'abord écrire pour obtenir les définitions de fonctions correctes :
require "sys/ioctl.ph"; # probablement /usr/local/lib/perl/sys/ioctl.phSi sys/ioctl.ph n'existe pas ou ne comporte pas les définitions correctes, vous devrez écrire les vôtres, en vous basant sur vos en-têtes de fichiers C comme sys/ioctl.h. (La distribution Perl contient un script appelé h2ph pour vous y aider, mais cela reste complexe.) SCALAIRE sera lu ou écrit (ou les deux) selon la FONCTION — un pointeur sur la valeur chaîne de SCALAIRE sera passé comme troisième argument de l'appel réel à ioctl(2). (Si SCALAIRE n'a pas de valeur chaîne, mais une valeur numérique, c'est cette dernière qui sera passée directement au lieu d'un pointeur sur la valeur chaîne.) Les fonctions pack et unpack servent notamment à manipuler les valeurs des structures utilisées par ioctl. L'exemple suivant détermine combien d'octets sont disponibles pour être lus en utilisant un FIONREAD :
require 'sys/ioctl.ph';
$taille = pack("L", 0);
ioctl(HF, FIONREAD(), $taille)
or die "Impossible d'appeler ioctl : $!\n";
$taille = unpack("L", $taille);Si h2ph n'a pas été installé ou ne fonctionne pas dans votre cas, vous pouvez faire un grep à la main sur les fichiers d'en-têtes ou écrire un petit programme C pour afficher la valeur.
La valeur de retour d'ioctl (et de fcntl) est comme suit :
|
L'appel système renvoie |
Perl renvoie |
|---|---|
|
-1 |
|
|
0 |
La chaîne « |
|
autre chose |
Le même nombre. |
Perl renvoie donc vrai pour un succès et faux pour un échec, tout en vous laissant facilement déterminer la valeur renvoyée par le système d'exploitation :
$val_ret = ioctl(...) || -1;
printf "ioctl a en fait renvoyé %d\n", $val_ret;La chaîne spéciale « 0 but true » (N.d.T. : 0, mais vrai) est exempte des avertissements de -w à propos des conversions numériques inadaptées.
Les appels à ioctl ne doivent pas être considérés comme portables. Si, par exemple, vous voulez simplement désactiver l'écho une seule fois pour le script tout entier, il est beaucoup plus portable d'écrire :
system "stty -echo"; # Fonctionne sur la plupart des UnixCe n'est pas parce qu'il est possible de faire quelque chose en Perl qu'il faut le faire. Pour citer l'apôtre Saint Paul : « Tout est acceptable — mais tout n'est pas bénéfique. »
Pour une meilleure portabilité, vous devriez regarder le module de CPAN Term::Read-Key.
join
join EXPR, LISTECette fonction joint les chaînes séparées de LISTE en une chaîne unique dont les champs sont séparés par la valeur de EXPR, et renvoie la chaîne résultante. Par exemple :
$enreg = join ':', $login,$mot_de_passe,$uid,$gid,$nom_reel,$rep,$shell;Pour faire l'inverse, voir split. Pour joindre des éléments dans des champs à position fixe, voir pack. La manière la plus efficace de concaténer des chaînes consiste à les joindre avec la chaîne vide :
$chaine = join "", @tableau;Au contraire de split, join ne prend pas un motif comme premier argument, et elle produit un avertissement si vous tentez de le faire.
keys
keys HACHAGECette fonction renvoie une liste constituée de toutes les clefs du HACHAGE indiqué. Les clefs sont renvoyées dans un ordre apparemment aléatoire, mais c'est le même que celui produit par les fonctions values ou each (à supposer que le hachage n'a pas été modifié entre les appels). Comme effet de bord, elle réinitialise l'itérateur de HACHAGE. Voici une manière (un peu tordue) d'afficher votre environnement :
@clefs = keys %ENV; # les clefs sont dans le même ordre que
@valeurs = values %ENV; # les valeurs, comme ceci le démontre
while (@clefs) {
print pop(@clefs), '=', pop(@valeurs), "\n";
}Vous préférez peut-être plus voir votre environnement affiché dans l'ordre des clefs :
foreach $clef (sort keys %ENV) {
print $clef, '=', $ENV{$clef}, "\n";
}Vous pouvez trier les valeurs d'un hachage directement, mais c'est plutôt inutile en l'absence d'une solution pour retrouver les clefs à partir des valeurs. Pour trier un hachage par ses valeurs, vous avez généralement besoin de trier le résultat de keys en fournissant une fonction de comparaison qui accède aux valeurs en fonction des clefs. Voici un tri numérique décroissant d'un hachage par ses valeurs :
foreach $clef (sort { $hachage{$b} <=> $hachage{$a} } keys %hachage) {
printf "%4d %s\n", $hachage{$clef}, $clef;
}L'utilisation de keys sur un hachage lié à un gros fichier DBM produirait une liste volumineuse, et donc un processus volumineux. Il vaut mieux que vous utilisiez dans ce cas la fonction each, qui parcourt les entrées du hachage une à une sans les absorber toutes dans une seule liste gargantuesque.
Dans un contexte scalaire, keys renvoie le nombre d'éléments du hachage (et réinitialise l'itérateur de each). Cependant, pour obtenir cette information à partir d'un hachage lié, y compris à un fichier DBM, Perl doit le parcourir en entier, ce qui n'est pas très efficace dans ce cas. L'appel de keys dans un contexte vide facilite ceci.
Utilisée en tant que lvalue, keys augmente le nombre de cellules de hachage (N.d.T. : hash buckets) allouées pour le hachage donné. (C'est la même chose que d'étendre a priori un tableau en assignant un nombre élevé pour $#tableau.) Étendre a priori un hachage peut se traduire par un gain de performance, s'il vous arrive de savoir si le hachage va être gros, et quelle grosseur il atteindra. Si vous écrivez :
keys %hachage = 1000;le %hachage aura alors au moins 1000 cellules allouées pour lui (vous aurez en fait 1024 cellules, puisqu'on arrondit à la prochaine puissance de deux). Vous pouvez diminuer le nombre de cellules allouées pour un hachage en utilisant keys de cette manière (mais vous n'aurez pas à vous inquiéter de faire cela par accident, puisqu'essayer est sans effet). Les cellules seront conservées même si vous faites %hachage = (). Utilisez undef %hachage si vous voulez libérer de la place en mémoire alors que %hachage est toujours dans la portée courante.
Voir également each, value et sort.
kill ![]()
![]()
![]()
![]()
kill SIGNAL, LISTECette fonction envoie un signal à une liste de processus. Pour le SIGNAL, vous pouvez utiliser soit un entier, soit le nom d'un signal entre apostrophes (sans le « SIG » au début). Une tentative d'employer un SIGNAL non reconnu lève une exception. La fonction renvoie le nombre de processus qui ont réussi à recevoir le signal. Si SIGNAL est négatif, la fonction touchera des groupes de processus au lieu des processus. (Sur System V, un numéro de processus négatif touchera également des groupes de processus, mais ce n'est pas portable.) Un PID égal à zéro enverra le signal à tous les processus du même groupe que celui de l'émetteur. Par exemple :
$compt = kill 1, $fils1, $fils2;
kill 9, @mourants;
kill 'STOP', getppid # Peut suspendre *ainsi* le shell de login
unless getppid == -1; # (Mais ne titillez pas init(8).)Un SIGNAL valant 0 teste si un processus est toujours en vie et que vous avez toujours les permissions pour lui envoyer un signal. Aucun signal n'est envoyé. Vous pouvez de cette manière détecter si un processus est toujours en vie et s'il n'a pas changé d'UID.
use Errno qw(ESRCH EPERM);
if (kill 0 => $larbin) {
print "$larbin est en vie !\n";
} elsif ($! == EPERM) { # UID changé
print "$larbin a échappé à mon contrôle !\n";
} elsif ($! == ESRCH) { # ou zombie
print "$larbin est décédé.\n";
} else {
warn "Bizarre : je n'ai pas pu vérifier l'état de $larbin : $!\n";
}Voir la section Signaux au chapitre 16.
last ![]()
L'opérateur last sort immédiatement de la boucle en question, exactement comme l'instruction break en C ou en Java (lorsqu'elle est utilisée dans les boucles). Si l'ETIQUETTE est omise, l'opérateur se réfère à la boucle la plus intérieure qui l'encadre. Le bloc continue, s'il existe, n'est pas exécuté.
LIGNE: while (<MSG_MAIL>) {
last LIGNE if /^$/; # sort lorsqu'on en a fini avec les en-têtes
# suite de la boucle ici
}last ne peut pas être employé pour sortir d'un bloc qui renvoie une valeur, comme eval {}, sub {} ou do {}, et ne doit pas être utilisé pour sortir d'une opération grep ou map. Si les avertissements sont actifs, Perl vous préviendra si vous faites un last pour sortir d'une boucle qui est hors de votre portée lexicale, comme une boucle dans une sous-routine appelante.
Un bloc en soi-même est sémantiquement identique à une boucle qui ne s'exécute qu'une seule fois. Ainsi last peut être employé pour effectuer une sortie anticipée d'un tel bloc.
Voir aussi le chapitre 4 pour des illustrations du fonctionnement de last, next, redo et continue.
lc ![]()
![]()
lc EXPR
lcCette fonction renvoie une version en minuscules de EXPR. Il s'agit de la fonction interne implémentant l'échappement \L dans les chaînes entre guillemets. La valeur de votre locale LC_CTYPE est respectée si use locale est actif, bien que la manière dont les locales interagissent avec Unicode est toujours un sujet à l'étude, comme ils disent. Voir la page de man perllocale pour les résultats les plus à jour.
lcfirst ![]()
![]()
lcfirst EXPR
lcfirstCette fonction renvoie une version de EXPR avec le premier caractère en minuscule. Il s'agit de la fonction interne implémentant l'échappement \l dans les chaînes entre guillemets. La valeur de votre locale LC_CTYPE est respectée si vous employez use locale et nous tâchons de comprendre le rapport avec Unicode.
length ![]()
length EXPR
lengthCette fonction renvoie la longueur en caractères de la valeur scalaire de EXPR. Si EXPR est omise, la fonction renvoie la longueur de $_ (mais prenez garde que ce qui suit ne ressemble pas au début d'une EXPRression, faute de quoi le moteur lexical de Perl sera perturbé. Par exemple, length < 10 ne compilera pas. En cas de doute, mettez des parenthèses.)
N'essayez pas d'utiliser length pour trouver la taille d'un tableau ou d'un liste. scalar @tableau donne la taille d'un tableau et scalar keys %hachage celle des couples clef/valeur d'un hachage. (Le scalar est habituellement omis lorsqu'il est redondant.)
Pour trouver la taille d'une chaîne en octets plutôt qu'en caractères, écrivez :
ou
$oct_long = bytes::length $chaine; # doit d'abord faire un use byteslink ![]()
![]()
![]()
link ANCIEN_FICHIER, NOUVEAU_FICHIERCette fonction crée un nouveau nom de fichier lié à l'ancien. La fonction renvoie vrai en cas de succès, faux sinon. Voir également symlink plus loin dans ce chapitre. Il est peu probable que cette fonction soit implémentée sur les systèmes de fichiers non Unix.
listen ![]()
![]()
![]()
listen SOCKET, TAILLE_FILECette fonction informe le système que vous allez accepter des connexions sur cette SOCKET et que le système peut mettre en file d'attente le nombre de connexions spécifiées par TAILLE_FILE. Imaginez un signal d'appel sur votre téléphone, avec la possibilité de mettre 17 appels en file d'attente. (Encore faut-il le vouloir !) La fonction renvoie vrai si elle a réussi, sinon faux.
use Socket;
listen(SOCK_PROTO, SOMAXCONN)
or die "Impossible de mettre une file d'attente avec listen sur SOCK_PROTO : $!";Voir accept. Voir également la section Sockets au chapitre 16. Voir listen(2).
local
local EXPRCet opérateur ne crée pas de variable locale ; utilisez my pour le faire. À la place, il rend locales des variables existantes ; c'est-à-dire qu'il donne à une ou plusieurs variables globales une portée locale à l'intérieur du bloc, de l'eval ou du fichier le plus intérieur les encadrant. Si plus d'une valeur est listée, la liste doit être placée entre parenthèses, car la priorité de l'opérateur est plus élevée que celle des virgules. Tous les éléments listés doivent être des lvalues légales, c'est-à-dire quelque chose auquel vous pouvez assigner une valeur ; ceci peut comprendre les éléments individuels de tableaux ou de hachages.
Cet opérateur fonctionne en sauvegardant les valeurs courantes des variables spécifiées dans une pile cachée et en les restaurant au moment de sortir du bloc, du sous-programme, de l'eval ou du fichier. Après que le local a été exécuté, mais avant de sortir de sa portée, tout sous-programme ou tout format exécuté verra les valeurs locales internes et non les valeurs externes précédentes, car la variable reste globale, bien que sa valeur soit localisée. Le terme technique est « portée dynamique ». Voir la section Déclarations avec portée au chapitre 4.
On peut assigner une valeur à EXPR si besoin, ce qui permet d'initialiser vos variables au moment où vous les rendez locales. Si aucune initialisation explicite n'est effectuée, tous les scalaires sont initialisés à undef et tous les tableaux et hachages à (). Comme pour les affectations ordinaires, si l'on utilise des parenthèses autour des variables à gauche (ou si la variable est un tableau ou un hachage), l'expression de droite est évaluée dans un contexte de liste. Sinon, l'expression de droite est évaluée dans un contexte scalaire.
Dans tous les cas, l'expression de droite est évaluée avant de rendre les variables locales, mais l'initialisation est effectuée après, vous permettant ainsi d'initialiser une variable rendue locale avec la valeur qu'elle contenait avant de l'être. Par exemple, ce code démontre comment modifier temporairement un tableau global :
if ($op eq '-v') {
# initialiser le tableau local avec le tableau global
local @ARGV = @ARGV;
unshift @ARGV, 'echo';
system @ARGV;
}
# @ARGV restauréVous pouvez aussi modifier temporairement des hachages globaux :
# ajoute temporairement quelques entrées au hachage %chiffres
if ($base12) \{
# (NB : ce n'est pas forcément efficace !)
local(%chiffres) = (%chiffres, T => 10, E => 11);
&parcours_nombres();
}Vous pouvez utiliser local pour donner des valeurs temporaires aux éléments individuels de tableaux ou de hachages, même s'ils ont une portée lexicale :
if ($protege) {
local $SIG{INT} = 'IGNORE';
precieux(); # pas d'interruption durant cette fonction
} # le gestionnaire précédent (s'il y en a) est restauréVous pouvez utiliser local avec les typeglobs pour créer des handles de fichiers locaux sans charger des modules objets encombrants :
local *MOTD; # protège tout handle MOTD global
my $hf = do { local *HF }; # crée un nouveau handle de fichier indirect(Depuis la version 5.6 de Perl, un my $hf; ordinaire suffit, car il vous donne une variable indéfinie là où un handle de fichier est attendu, comme le premier argument de open ou socket, Perl donne maintenant la vie à un tout nouveau handle de fichier pour vous.)
Mais en général, préférez my au lieu de local, car local n'est pas vraiment ce que la plupart des gens définit comme « local », ni même « local ». Voir my.
localtime
localtime EXPR
localtimeCette fonction convertit une heure renvoyée par la fonction time en un tableau de neuf éléments dont l'heure est en phase avec le méridien local. Elle est généralement employée comme suit :
# 0 1 2 3 4 5 6 7 8
($sec,$min,$heure,$mjour,$mois,$annee,$sjour,$ajour,$est_dst) = localtime;Si, comme dans ce cas, EXPR est omise, la fonction effectue localtime(time()).
Tous les éléments sont numériques et proviennent directement d'une struct tm (un jargon de programmation C — pas d'affolement). Cela signifie en particulier que $mois se situe dans l'intervalle 0..11 avec janvier comme le mois 0 et que $sjour est dans 0..6 avec dimanche comme jour 0. Vous pouvez vous rappeler de ceux qui commencent par zéro, car ce sont ceux que vous utilisez toujours comme indices dans les tableaux débutant par zéro contenant les noms des mois et des jours.
Par exemple, pour obtenir le jour actuel de la semaine :
$ce_jour = (qw((Dim Lun Mar Mer Jeu Ven Sam))[(localtime)[6]];$annee est le nombre d'années depuis 1900 ; c'est-à-dire qu'en 2023, $annee vaudra 123, et pas simplement 23. Pour obtenir l'année sur 4 chiffres, il suffit d'écrire $annee+1900. Pour l'avoir sur 2 chiffres (par exemple « 01 » en 2001), utilisez sprintf("%02d", $annee % 100).
Le module Time::Local de la bibliothèque Perl contient un sous-programme, timelocal, qui peut faire la conversion dans le sens l'inverse.
Dans un contexte scalaire, localtime renvoie une chaîne ressemblant à ctime(3). Par exemple, la commande date(1) peut (presque(203)) être émulée par :
perl -le 'print scalar localtime';Voir aussi la fonction strftime du le module standard POSIX pour une approche permettant de formater des dates avec une granularité plus fine. Le module Time::localtime supporte une interface orientée « par nom » pour cette fonction.
lock
lock CHOSELa fonction lock place un verrou sur une variable, un sous-programme ou un objet référencé par CHOSE jusqu'à ce que le verrou sorte de la portée courante. Pour assurer une compatibilité antérieure, cette fonction n'est interne que si Perl a été compilé en autorisant les threads et si vous avez écrit use Threads. Sinon, Perl supposera qu'il s'agit d'une fonction définie par l'utilisateur. Voir le chapitre 17, Threads.
log ![]()
![]()
log EXPR
logCette fonction renvoie le logarithme naturel (c'est-à-dire en base e) de EXPR. Si EXPR est négative, une exception est générée. Pour obtenir le log dans une autre base, utilisez l'algèbre de base : le log en base-N d'un nombre est égal au log de ce nombre divisé par le log naturel de N. Par exemple :
Pour l'inverse du log, voir exp.
lstat ![]()
![]()
![]()
lstat EXPR
lstatCette fonction est similaire à la fonction stat de Perl (y compris en positionnant le handle de fichier spécial _), mais si le dernier composant du nom de fichier est un lien symbolique, elle agit sur le lien symbolique lui-même au lieu du fichier sur lequel pointe le lien en question. (Si les liens symboliques ne sont pas implémentés, c'est un stat normal qui est lancé en lieu et place.)
m// ![]()
![]()
/MOTIF/
m/MOTIF/Il s'agit de l'opérateur de correspondance, qui interprète MOTIF comme une expression régulière. L'opérateur est évalué comme une chaîne entre guillemets plutôt que comme une fonction. Voir le chapitre 5, Recherche de motif.
map
map BLOC LISTE
map EXPR, LISTECette fonction évalue le BLOC ou l'EXPR pour chaque élément de LISTE (en affectant localement $_ à chaque élément) et renvoie la liste composée des résultats de chacune de ces évaluations. Elle évalue BLOC ou EXPR dans un contexte de liste, ce qui fait que chaque élément de LISTE peut produire zéro, un ou plusieurs éléments dans la valeur renvoyée. Ces éléments sont tous rassemblés en une seule liste plate. Par exemple :
@mots = map { split ' ' } @lignes;éclate une ligne en une liste de mots. Mais on observe souvent une correspondance bijective entre les valeurs de sortie et d'entrée :
@caracteres = map chr, @nombres;convertit une liste de nombres vers leurs caractères correspondants. Voici un exemple de correspondance un-vers-deux :
%hachage = map { gen_clef($_) => $_ } @tableau;qui n'est qu'une façon amusante et fonctionnelle d'écrire ceci :
%hachage = ();
foreach $_ (@tableau) {
$hachage{gen_clef($_)} = $_;
}Comme $_ est un alias (une référence implicite) pour les valeurs de la liste, on peut utiliser cette variable pour modifier les éléments dans le tableau. C'est utile et supporté bien que cela puisse générer d'étranges résultats si la LISTE n'est pas un tableau nommé. L'utilisation d'une boucle foreach habituelle dans cet objectif peut paraître plus clair. Voir également grep ; map diffère de grep en ce que map renvoie une liste composée des résultats de chaque évaluation successive de EXPR, alors que grep renvoie une liste composée de chaque valeur de LISTE pour laquelle EXPR est évaluée à vrai.
mkdir ![]()
![]()
mkdir REPERTOIRE, MASQUE
mkdir REPERTOIRECette fonction crée le répertoire spécifié par REPERTOIRE en lui donnant les permissions spécifiées par le MASQUE numérique, modifié par le umask courant. Si l'opération réussie, elle renvoie vrai, sinon faux.
Si MASQUE est omis, on suppose un masque de 0777, qui de toute façon est ce que vous voulez dans la plupart des cas. En général, créer des répertoires avec un MASQUE permissif (comme 0777) et laisser l'utilisateur modifier cela avec son umask est une meilleure habitude plutôt que de fournir un MASQUE restrictif sans donner à l'utilisateur un moyen d'être plus permissif. L'exception à cette règle est le cas où le fichier ou le répertoire doit rester privé (les fichiers mail, par exemple). Voir umask.
Si l'appel système mkdir(2) n'est pas intégré à votre bibliothèque C, Perl l'émule en appelant le programme mkdir(1). Pour créer une longue liste de répertoires sur ce genre de système, il sera plus efficace d'appeler vous-mêmes le programme mkdir avec la liste des répertoires pour éviter de créer des palanquées de sous-processus.
msgctl ![]()
![]()
msgctl ID, CMD, ARGCette fonction invoque l'appel system msgctl(2) des IPC System V ; voir msgctl(2) pour plus de détails. Il se peut que vous deviez faire un use IPC::SysV pour obtenir les définitions de constante correctes. Si CMD vaut IPC_STAT, ARG doit alors être une variable qui contiendra la structure C msqid_ds renvoyée. Les valeurs de retour fonctionnent comme celles de ioctl et fcntl : undef pour une erreur, « 0 but true » (N.d.T. : 0, mais vrai) pour zéro ou la valeur réelle dans les autres cas.
Cette fonction n'est disponible que sur les machines qui supportent les IPC System V, ce qui s'avère bien plus rare que celles qui supportent les sockets.
msgget ![]()
![]()
msgget CLEF, FLAGSCette fonction invoque l'appel système msgget(2) des IPC System V. Voir msgget(2) pour plus de détails. La fonction renvoie l'ID de file de messages ou undef s'il y a une erreur. Avant d'appeler, vous devez écrire use IPC::SysV.
Cette fonction n'est disponible que sur les machines qui supportent les IPC System V.
msgrcv ![]()
![]()
msgrcv ID, VAR, TAILLE, TYPE, FLAGSCette fonction invoque l'appel système msgrcv(2) des IPC System V pour recevoir un message depuis la file de messages ID dans la variable VAR avec une taille maximum TAILLE. Voir msgrcv(2) pour plus de détails. Lorsqu'un message est reçu, le type de message sera la première chose dans VAR et la longueur maximale de VAR sera TAILLE plus la taille du type de message. La fonction renvoie vrai si elle réussit ou undef s'il y a une erreur. Avant d'appeler, vous devez écrire use IPC::SysV.
Cette fonction n'est disponible que sur les machines qui supportent les IPC System V.
msgsnd ![]()
![]()
msgsnd ID, MSG, FLAGSCette fonction invoque l'appel système msgsnd(2) des IPC System V pour envoyer le message MSG dans la file de messages ID. Voir msgsnd(2) pour plus de détails. MSG doit commencer par l'entier long représentant le type de message. Vous pouvez créer un message comme ceci :
$msg = pack "L a*", $type, $texte_du_message;La fonction renvoie vrai si elle réussit ou undef s'il y a une erreur. Avant d'appeler, vous devez écrire use IPC::SysV.
Cette fonction n'est disponible que sur les machines qui supportent les IPC System V.
my
Cet opérateur déclare une ou plusieurs variables privées comme n'existant que dans le bloc, le sous-programme, l'eval ou le fichier le plus intérieur les encadrant. Si plus d'une valeur est listée, la liste doit être placée entre parenthèses, car l'opérateur lie plus fortement que la virgule. Seuls les scalaires simples ou les tableaux et les hachages complets peuvent être déclarés de cette façon.
Le nom de la variable ne peut pas être qualifié par un paquetage, car les variables de paquetage sont toutes globalement accessibles par le biais de leur table de symboles correspondante tandis que les variables lexicales sont sans rapport avec une quelconque table de symboles. À l'inverse de local, cet opérateur n'a rien à voir avec les variables globales, sinon masquer une autre variable du même nom dans sa portée (c'est-à-dire, là où la variable privée existe). Cependant, une variable globale peut toujours être atteinte sous sa forme qualifiée par paquetage ou par le biais d'une référence symbolique.
La portée d'une variable privée ne commence pas avant l'instruction qui suit sa déclaration. Elle s'étend à n'importe quel bloc contenu ensuite, jusqu'à la fin de la portée de la variable elle-même.
Cela signifie cependant que tout sous-programme que vous appelez dans la portée d'une variable privée ne peut pas la voir, à moins que le bloc qui définit le sous-programme lui-même ne fasse textuellement partie de la portée de cette variable. Le terme technique consacré est portée lexicale, nous les appelons donc souvent variables lexicales. Dans la culture C, elles sont appelées variables auto, car elles sont automatiquement allouées et désallouées respectivement à l'entrée et à la sortie de la portée.
Vous pouvez si besoin assigner une valeur à EXPR, ce qui vous permet d'initialiser les variables locales. (Si aucune initialisation explicite n'est effectuée, tous les scalaires sont initialisés à la valeur indéfinie et tous les tableaux et hachages à la liste vide). Comme pour les affectations ordinaires, si l'on utilise des parenthèses autour des variables à gauche (ou si la variable est un tableau ou un hachage), l'expression de droite est évaluée dans un contexte de liste. Sinon, l'expression de droite est évaluée dans un contexte scalaire. Par exemple, les paramètres formels de sous-programme peuvent être nommés par une affectation de liste, comme ceci :
my ($amis, $romains, $paysans) = @_;Mais prenez garde à ne pas oublier les parenthèses indiquant une affectation de liste, comme ceci :
my $pays = @_; # Est-ce correct ou pas ?Ici, c'est la longueur du tableau (c'est-à-dire le nombre d'arguments du sous-programme) qui est assignée à la variable, car le tableau est évalué dans un contexte scalaire. Vous pouvez cependant employer l'affectation scalaire pour un paramètre formel, tant que vous utilisez l'opérateur shift. En fait, comme les méthodes sont passées aux objets dans le premier argument, de nombreux sous-programmes méthodes commencent comme ceci :
sub simple_comme {
my $obj = shift; # affectation scalaire
my ($a,$b,$c) = @_; # affectation de liste
...
}Si vous tentez de déclarer un sous-programme de portée lexicale avec my su b, Perl mourra avec le message que cette fonctionnalité n'a pas encore été implémentée. (Sauf si bien sûr, cette fonctionnalité a déjà été implémentée.)
Les TYPE et ATTRIBUTS sont optionnels, ce qui se justifie puisqu'ils doivent tous deux être considérés comme expérimentaux. Voici à quoi ressemble une déclaration qui les utilise :
my Chien $medor :oreilles(courtes) :queue(longue);Le TYPE, s'il est spécifié, indique quelle sorte de scalaire ou de scalaires sont déclarés dans EXPR, soit directement comme une ou plusieurs variables scalaires, soit indirectement par le biais d'un tableau ou d'un hachage. Si TYPE est le nom d'une classe, on supposera que les scalaires contiennent des références à des objets de ce type, ou à des objets compatibles avec ce type. En particulier, les classes dérivées sont considérées comme compatibles. C'est-à-dire, en supposant que Colley soit dérivée de Chien, vous pouvez déclarer :
Votre déclaration affiche que vous désirez utiliser l'objet $lassie en accord avec son appartenance à un objet Chien. Le fait que ce soit vraiment un objet Colley ne doit pas avoir d'influence tant que vous vous lui faites faire des choses de Chien. Malgré la magie des méthodes virtuelles, l'implémentation de ces méthodes de Chien peuvent très bien être dans la classe Colley, mais la déclaration ci-dessus ne parle que de l'interface et pas de l'implémentation. En théorie.
De manière intéressante, dans la version 5.6.0, la seule fois où Perl accorde une attention à la déclaration de TYPE est lorsque la classe correspondante a déclaré des champs avec le pragma use fields. Prises ensembles, ces déclarations permettent à l'implémentation d'une classe en tant que pseudohachage de « s'exhiber » au code qui se trouve à l'extérieur de la classe, permettant ainsi aux recherches dans le hachage d'être optimisées par le compilateur comme étant des recherches dans un tableau. En un sens, le pseudohachage est l'interface pour une telle classe, notre théorie reste donc intacte, si ce n'est un peu cabossée. Pour plus d'informations sur les pseudohachages, voir la section Pseudohachages au chapitre 8, Références.
À l'avenir, d'autres types de classes pourront interpréter le TYPE différemment. La déclaration de TYPE doit être perçue comme une interface de type générique qui pourra un jour être instanciée de différentes manières selon la classe. En fait, le TYPE pourra même ne pas être un nom de classe officiel. Nous réservons les noms de types en minuscules pour Perl, car l'une des manières que nous préférons pour étendre le type d'interface est d'autoriser les déclarations de type de bas niveau comme int, num, str et ref. Ces déclarations ne seront pas destinées à un typage fort ; elles seront plutôt des indications pour le compilateur, en lui disant d'optimiser le stockage de la variable en supposant que cette variable sera le plus souvent utilisée comme elle a été déclarée. La sémantique des scalaires restera à peu près la même — vous serez toujours capables d'additionner deux scalaires str (N.d.T. : chaînes) ou d'afficher un scalaire int (N.d.T. : entier), exactement comme s'ils étaient les scalaires polymorphes auxquels vous êtes familiers. Mais avec une déclaration int, Perl pourra décider de ne stocker que la valeur entière et d'oublier de sauver dans le cache la chaîne résultante comme il le fait actuellement. Les boucles avec des variables de boucle int pourront tourner plus rapidement, spécialement dans le code compilé en C. Les tableaux de nombres pourront en particulier être stockés de manière plus compacte. Comme cas limite, la fonction interne vec deviendra même obsolète alors que nous pourrons écrire des déclarations comme :
my bit @chaine_de_bits;La déclaration ATTRIBUTS est encore plus expérimentale. Nous n'avons pas fait grand-chose de plus que réserver la syntaxe et prototyper l'interface interne ; voir le pragma use attributes au chapitre 31 pour plus d'informations à ce sujet. Le premier attribut que nous implémenterons est susceptible d'être constant :
Mais il y a beaucoup d'autres possibilités, comme établir des valeurs par défaut pour les tableaux et les hachages ou laisser les variables partagées entre des interpréteurs coopérants. Comme l'interface de type, l'interface d'attribut doit être perçue comme une interface générique, une sorte de cadre de travail pour inventer de nouvelles syntaxes et sémantiques. Nous ne savons pas comment Perl évoluera dans les dix prochaines années. Nous savons seulement que nous pouvons le rendre plus simple pour nous-mêmes en planifiant cela à l'avance.
Voir également local, our et la section Déclarations avec portée au chapitre 4.
new
Il n'existe pas de fonction interne new. Il s'agit plutôt d'un constructeur de méthode ordinaire (c'est-à-dire un sous-programme défini par l'utilisateur) qui est défini ou hérité par la classe NOM_CLASSE (c'est-à-dire le paquetage) pour vous laisser construire des objets de type NOM_CLASSE. Beaucoup de constructeurs sont appelés « new », mais seulement par convention, juste pour jouer un tour aux programmeurs C++ en leur faisant croire qu'ils savent ce qu'il se passe. Lisez toujours la documentation de la classe en question pour savoir comment appeler ses constructeurs ; par exemple, le constructeur qui crée une « list box » dans le widget Tk est juste appelé Listbox(). Voir le chapitre 12.
next ![]()
L'opérateur next est semblable à l'instruction continue en C ; il démarre l'itération suivante de la boucle désignée par ETIQUETTE :
S'il y avait un bloc continue dans cet exemple, il s'exécuterait immédiatement après l'invocation de next. Lorsqu'ETIQUETTE est omise, la commande se réfère à la boucle la plus intérieure l'encadrant.
Un bloc en soi-même est sémantiquement identique à une boucle qui ne s'exécute qu'une seule fois. Ainsi next peut quitter de manière anticipée un tel bloc (via le bloc continue, s'il y en a un).
next ne peut pas être employé pour sortir d'un bloc qui renvoie une valeur, comme eval {}, sub {} ou do {}, et ne doit pas être utilisé pour sortir d'une opération grep ou map. Si les avertissements sont actifs, Perl vous préviendra si vous faites un next pour sortir d'une boucle qui est hors de votre portée lexicale, comme une boucle dans une sous-routine appelante. Voir la section Instructions de boucle au chapitre 4.
no ![]()
no MODULE LISTEVoir l'opérateur use, qui est l'inverse de no, plus ou moins. La plupart des modules standard ne « non-importent » rien, faisant de no une « non-opération ». Les modules pragmatiques ont tendance ici à être plus serviables. Si le MODULE n'est pas trouvé, une exception est levée.
oct ![]()
oct EXPR
octCette fonction interprète EXPR comme une chaîne octale et renvoie la valeur décimale équivalente. S'il se trouve que EXPR commence par « 0x », on l'interprète comme une chaîne hexadécimale à la place. Si EXPR débute par « 0b », on l'interprète comme une chaîne de chiffres binaires. Ce qui suit convertit proprement en nombres n'importe quelle chaîne en base décimale, binaire, octale ou hexadécimale dans la notation standard C ou C++ :
$val = oct $val id $val =~ /^0/;Pour exécuter la fonction inverse, utilisez sprintf avec le format approprié :
$perms = (stat("nom_fichier"))[2] & 07777;
$perms_oct = sprintf "%lo", $perms;La fonction oct est habituellement employée lorsqu'une donnée sous forme de chaîne, comme « 644 » doit être convertie vers un mode de fichier, par exemple. Bien que Perl convertisse automatiquement les chaînes en nombres si besoin est, cette conversion automatique suppose que l'on soit en base 10.
open ![]()
![]()
![]()
![]()
open HANDLE_FICHIER, MODE, LISTE
open HANDLE_FICHIER, EXPR
open HANDLE_FICHIERLa fonction open associe un HANDLE_FICHIER interne à la spécification d'un fichier externe donnée par EXPR ou LISTE. Elle peut être appelée avec un, deux ou trois arguments (ou plus si le troisième argument est une commande et que vous lancez au moins la version 5.6.1 de Perl). Si trois arguments ou plus sont présents, le deuxième argument spécifie le MODE d'accès avec lequel le fichier doit être ouvert, et le troisième argument (LISTE) fournit le véritable nom de fichier ou la commande à exécuter, en fonction du MODE. Dans le cas d'une commande, des arguments supplémentaires peuvent être fournis si vous désirez invoquer la commande directement sans impliquer un shell, un peu comme system ou exec. Sinon, la commande peut être fournie comme un seul argument (le troisième), auquel cas la décision d'invoquer le shell dépend du fait que la commande contienne ou non des métacaractères du shell. (N'utilisez pas plus de trois arguments si les arguments sont des fichiers ordinaires ; cela ne fonctionnera pas.) Si le MODE n'est pas reconnu, open lève une exception.
Si seulement deux arguments sont présents, on suppose que le mode et le nom de fichier ou de commande sont assemblés dans le second argument. (Et si vous ne spécifiez aucun mode dans le second argument, mais uniquement un nom de fichier, le fichier est alors ouvert en lecture seule pour raison de sécurité.)
Avec un seul argument, la variable scalaire de paquetage qui porte le même nom (la variable, pas le paquetage !) que le HANDLE_FICHIER, doit contenir le nom du fichier et le mode optionnel :
$LOG = ">fichier_journal"; # $LOG ne doit pas être déclarée avec my !
open LOG or die "Impossible d'ouvrir le fichier journal : $!";Mais ne faites pas cela ! Ça manque de style. Oubliez que nous en avons parlé.
La fonction open renvoie vrai si elle réussit, sinon undef. Si le open commence par un pipe sur un processus fils, la valeur de retour sera le PID de ce nouveau processus. Comme avec tout appel système, vérifiez toujours la valeur de retour de open pour être sûr qu'il a marché. Mais ce n'est pas du C ou du Java, alors n'employez pas d'instruction if alors que l'opérateur or fait très bien l'affaire. Vous pouvez également employer ||, mais dans ce cas, utilisez des parenthèses autour du open. Si vous choisissez d'omettre les parenthèses autour de l'appel de fonction pour le changer en opérateur de liste, prenez garde à bien utiliser « or die » après la liste plutôt que « || die », car la préséance de || est supérieure à celle des opérateurs de liste comme open, et le || serait lié à votre dernier argument et non à l'open tout entier :
open LOG, ">fichier_journal"
|| die "Impossible de créer le fichier journal : $!"; # FAUX
open LOG, ">fichier_journal"
or die "Impossible de créer le fichier journal : $!"; # okCela semble plutôt exagéré, mais généralement vous devriez insérer un quelconque caractère d'espacement pour que la fin de l'opérateur de liste vous saute aux yeux :
open LOG, ">fichier_journal"
or die "Impossible de créer le fichier journal : $!";Comme le montre cet exemple, l'argument HANDLE_FICHIER n'est souvent qu'un simple identificateur (normalement en majuscules), mais il peut aussi être une expression dont la valeur donne une référence vers le véritable handle de fichier. (La référence peut être soit une référence symbolique vers le nom du handle de fichier, soit une référence en dur vers tout objet qui puisse être interprété comme un handle de fichier.) On appelle ceci un handle de fichier indirect, et toute fonction qui prend comme premier argument un HANDLE_FICHIER accepte les handles de fichiers aussi bien indirects que directs. Mais open est spécial, car si vous lui donnez une variable indéfinie comme handle de fichier indirect, Perl définira automatiquement cette variable pour vous, c'est-à-dire qu'elle sera autovivifiée pour contenir la référence de handle de fichier adéquat. Ceci a l'avantage de fermer automatiquement le handle de fichier lorsqu'il n'y a plus de référence sur lui, généralement lorsque la variable quitte la portée courante :
{
my $hf; # (non initialisée)
open($hf, ">fichier_journal") # $hf est autovivifié
or die "Impossible de créer le fichier journal : $!";
... # faites ce que vous voulez avec $hf
} # fermeture de $hf iciOn peut lisiblement incorporer la déclaration my $hf à l'intérieur de l'open :
Le symbole > que vous venez de voir devant le nom de fichier est un exemple de mode. Historiquement, la forme avec deux arguments de open est apparue en premier. Le récent ajout de la forme avec trois arguments vous permet de séparer le mode du nom de fichier, qui a l'avantage d'éviter toute confusion possible entre les deux. Dans l'exemple suivant, nous savons que l'utilisateur n'essaie pas d'ouvrir un nom de fichier commençant par « > ». Nous pouvons être sûrs qu'il spécifie un MODE valant « > », ce qui ouvre en écriture le fichier indiqué par EXPR, en le créant s'il n'existait pas et en l'effaçant s'il existait déjà :
open(LOG, ">", "fichier_journal")
or die "Impossible de créer le fichier journal : $!";Dans les formes plus courtes, le nom de fichier et le mode se trouvent dans la même chaîne. La chaîne est analysée un peu comme un shell typique traite les redirections de fichiers et de pipes. La chaîne est alors examinée, par n'importe quelle extrémité si besoin, pour trouver les caractères spécifiant comment le fichier doit être ouvert. Un espace est autorisé entre le mode et le nom de fichier.
Les modes qui indiquent comment ouvrir un fichier ressemblent aux symboles de redirection du shell. Le tableau 29-1 donne une liste de ces symboles. (Pour accéder à un fichier en combinant des modes d'ouvertures non présentés dans cette table, voir la fonction de bas niveau sysopen.)
|
Mode |
Accès en lecture |
Accès en écriture |
Ajout uniquement |
Créer si inexistant |
Vidage de l'existant |
|---|---|---|---|---|---|
|
< CHEMIN |
O |
N |
N |
N |
N |
|
> CHEMIN |
N |
O |
N |
O |
O |
|
>> CHEMIN |
N |
O |
O |
O |
N |
|
+< CHEMIN |
O |
O |
N |
N |
N |
|
+> CHEMIN |
O |
O |
N |
O |
O |
|
+>> CHEMIN |
O |
O |
O |
O |
N |
|
| COMMANDE |
N |
O |
aucun |
aucun |
aucun |
|
COMMANDE | |
O |
N |
aucun |
aucun |
aucun |
Si le mode est « < » ou rien du tout, un fichier existant est ouvert en lecture. Si le mode est « > », le fichier est ouvert en écriture, ce qui tronque les fichiers existants et crée ceux qui n'existent pas. Si le mode est « >> », le fichier est créé si besoin et ouvert en ajout, et toutes les écritures sont automatiquement placées à la fin du fichier. Si un nouveau fichier est créé parce que vous avez utilisé « > » ou « >> » et que le fichier n'existait pas auparavant, les permissions d'accès dépendront de l'umask actuel du processus avec les règles décrites pour cette fonction. Voici quelques exemples courants :
open(INFO, "fichier_de_donnees")
|| die("Impossible d'ouvrir le fichier de données : $!");
open(INFO, "< fichier_de_donnees")
|| die("Impossible d'ouvrir le fichier de données : $!");
open(RESULTATS, "> stats_en_cours")
|| die("Impossible d'ouvrir les stats en cours : $!");
open(LOG, ">> fichier_journal")
|| die("Impossible d'ouvrir le fichier journal : $!");Si vous préférez la version avec moins de ponctuation, vous pouvez écrire :
open INFO, "fichier_de_donnees"
or die("Impossible d'ouvrir le fichier de données : $!");
open INFO, "< fichier_de_donnees"
or die("Impossible d'ouvrir le fichier de données : $!");
open RESULTATS, "> stats_en_cours"
or die("Impossible d'ouvrir les stats en cours : $!");
open LOG, ">> fichier_journal"
or die("Impossible d'ouvrir le fichier journal : $!");Lors d'une ouverture en lecture, le nom de fichier spécial « - » se réfère à STDIN. lors qu'il est ouvert en écriture, ce même nom de fichier spécial se réfère à STDOUT. Normalement, on les spécifie respectivement avec « <- » et « -> ».
open(ENTREE, "-" ) or die; # rouvre l'entrée standard en lecture
open(ENTREE, "<-") or die; # idem, mais explicitement
open(SORTIE, "->") or die; # rouvre la sortie standard en écritureDe cette façon, l'utilisateur peut fournir à un programme un nom de fichier qui utilisera l'entrée ou la sortie standard, mais l'auteur du programme n'a pas besoin d'écrire de code particulier pour connaître ceci.
Vous pouvez également placer un « + » devant n'importe lequel de ces trois modes pour demander un accès en lecture/écriture simultané. Cependant, le fait que le fichier soit vidé ou créé et qu'il doit déjà exister est toujours déterminé par votre choix du signe inférieur ou supérieur. Cela signifie que « +< » est toujours un meilleur choix pour des mises à jour en lecture/écriture, plutôt que le mode douteux « +> » qui viderait tout d'abord le fichier avant que vous puissiez y lire quoi que ce soit. (N'utilisez ce mode que si vous ne voulez relire que ce que vous venez d'écrire.)
open(DBASE, "+<base_de_donnees")
or die "Impossible d'ouvrir la base de données en mise à jour : $!";Vous pouvez traiter un fichier ouvert en mise à jour comme une base de données en accès direct et utiliser seek pour vous déplacer vers un nombre d'octets particulier, mais les enregistrements de longueur variable rendent généralement irréalisables l'emploi du mode lecture/écriture pour mettre à jour de tels fichiers. Voir l'option de la ligne de commande -i au chapitre 19 pour une approche différente des mises à jour.
Si le premier caractère dans EXPR est un symbole pipe, open déclenche un nouveau processus et connecte un handle de fichier en écriture seule avec la commande. De cette façon, vous pouvez écrire dans ce handle et ce que vous y écrivez sera passé à l'entrée standard de cette commande. Par exemple :
open(IMPRIMANTE, "| lpr -Plp1") or die "Impossible de forker : $!";
print IMPRIMANTE "truc\n";
close(IMPRIMANTE) or die "Échec de la fermeture de lpr : $?/$!";Si le dernier caractère de EXPR est un symbole pipe, open lancera ici aussi un nouveau processus, mais cette fois connecté à un handle de fichier en lecture seule. Ceci permet à tout ce que la commande écrit sur sa sortie standard d'être passé dans votre handle pour être lu. Par exemple :
open(RESEAU, "netstat -i -n |") or die "Impossible de forker : $!";
while (<RESEAU>) { ... }
close RESEAU or die "Impossible de fermer netstat : $!/$?";La fermeture explicite de tout handle de fichier pipé entraîne l'attente du processus père de la terminaison du processus fils et le retour d'un code de statut dans $? ($CHILD_ERROR). Il est également possible que close positionne $! ($OS_ERROR). Voir les exemples dans les descriptions de close et de system pour savoir comment interpréter ces codes d'erreur.
Toute commande pipée contenant des métacaractères shell comme des jokers (N.d.T. : wildcards) ou des redirections d'entrée/sortie est passée à votre shell canonique (/bin/sh sur Unix), ces constructions spécifiques au shell sont donc analysées en premier lieu. Si aucun métacaractère n'est trouvé, Perl lance le nouveau processus lui-même sans appeler le shell.
Vous pouvez également utiliser la forme à trois arguments pour démarrer des pipes. En utilisant ce style, l'équivalent des ouvertures de pipe précédentes serait :
open(IMPRIMANTE, "|-", "lpr -Plp1") or die "Impossible de forker : $!";
open(RESEAU, "-|", "netstat -i -n") or die "Impossible de forker : $!";Ici le caractère moins dans le deuxième argument représente la commande du troisième argument. Ces commandes n'invoquent pas le shell, mais si vous souhaitez qu'aucun traitement du shell ne survienne, les nouvelles versions de Perl vous permettent d'écrire :
open(IMPRIMANTE, "|-", "lpr", "-Plp1")
or die "Impossible de forker : $!";
open(RESEAU, "-|", "netstat", "-i", "-n")
or die "Impossible de forker : $!";Si vous utilisez la forme à deux arguments pour ouvrir un pipe ou la commande spéciale « - »(204), un fork implicite est réalisé en premier lieu. (Sur les systèmes qui ne savent pas fork er, ceci génère une exception. Les systèmes Microsoft ne supportaient pas le fork avant la version 5.6 de Perl.) Dans ce cas, le caractère moins représente votre nouveau processus fils, qui est une copie du père. La valeur de retour de cet open forkant est l'ID du processus fils lorsqu'elle est examinée par le père, 0 lorsque c'est par le fils et la valeur indéfinie undef si le fork échoue — auquel cas, il n'y a pas de fils. Par exemple :
defined($pid = open(DEPUIS_LE_FILS, "-|"))
or die "Impossible de forker : $!";
if ($pid) {
@lignes_pere = <DEPUIS_LE_FILS>; # code du père
} else {
print STDOUT @lignes_fils; # code du fils
}Le handle de fichier se comporte normalement pour le père, mais pour le processus fils, l'entrée (ou la sortie) du père est pipée depuis (ou vers) le STDOUT (ou le STDIN) du fils. Le processus fils ne voit pas le handle de fichier du père comme étant ouvert. (Ceci est utilement indiqué par le PID de 0.)
Généralement vous devriez utiliser cette construction à la place d'un open pipé classique lorsque vous voulez exercer plus de contrôle sur la manière dont la commande pipée s'exécute (comme lorsque vous exécutez setuid) et que vous ne désirez pas examiner si les commandes shells contiennent des métacaractères. Les open pipés suivants sont fortement équivalents :
open HF, "| tr 'a-z' 'A-Z'"; # pipe vers une commande shell
open HF, "|-", 'tr', 'a-z', 'A-Z'; # pipe vers une commande nue
open HF, "|-" or exec 'tr', 'a-z', 'A-Z' or die; # pipe vers un filstout comme celles-ci :
open HF, " cat -n 'fichier' |"; # pipe vers une commande shell
open HF, "-|", 'cat', '-n' 'fichier'; # pipe vers une commande nue
open HF, "-|" or exec 'cat', '-n', 'fichier' or die; # pipe vers un filsPour des utilisations plus élaborées de open forké, voir la section Soliloque au chapitre 16 et Nettoyage de votre environnement au chapitre 23, Sécurité.
Lorsque vous démarrez une commande avec open, vous devez choisir soit l'entrée soit la sortie : « cmd| » pour la lecture ou « |cmd » pour l'écriture. Vous ne pouvez pas utiliser open pour démarrer une commande qui possède des pipes à la fois en entrée et en sortie, comme la notation illégale (pour le moment) « |cmd| » semblerait l'indiquer. Cependant, les routines standard de la bibliothèque IPC::Open2 et IPC::Open3 vous donne une équivalence relativement proche. Pour plus de détail sur les pipes à double sens, voir la section Communication bidirectionnelle au chapitre 16.
Vous pouvez également spécifier, dans la plus pure tradition du Bourne Shell, une EXPR commençant par >&, auquel cas le reste de la chaîne est interprété comme le nom d'un handle de fichier (ou un descripteur de fichier, s'il est numérique) que l'on doit dupliquer en utilisant l'appel système dup2(2).(205) Vous pouvez utiliser & après >, >>, +>, +>> et +<. (Le mode spécifié doit correspondre au mode du handle de fichier originel.)
Une raison pour laquelle vous pourriez vouloir faire cela serait le cas où vous disposiez d'ores et déjà un handle de fichier ouvert et que vous vouliez obtenir un autre handle de fichier qui soit réellement un duplicata du premier.
open(SORTIE_SAUVEE, ">&ERREUR_SAUVEE")
or die "Impossible de dupliquer ERREUR_SAUVEE : $!";
open(MON_CONTEXTE, "<&4")
or die "Impossible de dupliquer le descfic4 : $!";Cela signifie que si une fonction attend un nom de fichier, mais si vous ne voulez pas lui en donner parce que vous disposez déjà d'un fichier ouvert, vous n'avez qu'à passer le handle de fichier préfixé par une esperluette. Il vaut mieux tout de même utiliser un handle pleinement qualifié, pour le cas où la fonction se trouve dans un autre paquetage :
une_fonction("&main::FICHIER_JOURNAL");Une autre raison de dupliquer un handle de fichier est de rediriger temporairement un handle de fichier existant sans perdre la trace de la destination d'origine. Voici un script qui sauvegarde, redirige et restaure STDOUT et STDERR :
#!/usr/bin/perl
open SORTIE_SAUVEE, ">&STDOUT";
open ERREUR_SAUVEE, ">&STDERR";
open STDOUT, ">truc.out" or die "Impossible de rediriger stdout";
open STDERR, ">&STDOUT" or die "Impossible de dupliquer stdout";
select STDERR; $| = 1; # active le vidage de tampon automatique
select STDOUT; $| = 1; # active le vidage de tampon automatique
print STDOUT "stdout 1\n"; # ces flux d'entrée/sortie se propagent
print STDERR "stderr 1\n"; # également aux sous-processus
system ("une commande"); # utilise les nouveaux stdout/stderr
close STDOUT;
close STDERR;
open STDOUT, ">&SORTIE_SAUVEE";
open STDERR, ">&ERREUR_SAUVEE";
print STDOUT "stdout 2\n";
print STDERR "stderr 2\n";Si le handle ou le descripteur de fichier est précédé par une combinaison &= au lieu d'un simple &, alors au lieu de créé un descripteur de fichier complètement neuf, Perl fait de HANDLE_FICHIER un alias du descripteur existant en utilisant l'appel fdopen(3) de la bibliothèque C. Ceci est quelque peu plus parcimonieux en terme de ressources système, bien que ce ne soit plus un gros problème de nos jours.
$df = $ENV{"DF_MON_CONTEXTE"};
open(MON_CONTEXTE, "<&=$num_df"
or die "fdopen sur le descripteur $num_fd impossible : $!\";Les handles de fichiers STDIN, STDOUT et STDERR restent toujours ouvert à travers un exec. Les autres handles de fichiers ne le restent pas, par défaut. Sur les systèmes qui supportent la fonction fcntl, vous pouvez modifier le flag close-on-exec (N.d.T. : indicateur de fermeture lors d'un exec) pour un handle de fichier :
use Fcntl qw(F_GETFD F_SETFD);
$flags = fcntl(HF, F_SETFD, 0)
or die "Impossible de nettoyer le flag close-on-exec pour HF : $!\n";Voir aussi la variable spéciale $^F ($SYSTEM_MAX_FD) au chapitre 28.
Avec les formes à un ou à deux arguments de open, vous devez faire attention lorsque vous utilisez une variable chaîne comme nom de fichier, puisque la variable peut contenir arbitrairement des caractères étranges (particulièrement lorsque le nom du fichier a été obtenu à partir d'étranges caractères depuis Internet). Si vous n'y prenez pas garde, certaines parties du nom de fichier peuvent être interprétées comme une chaîne de MODE , des espaces à ignorer, une spécification de duplication ou un signe moins. Voici une manière historiquement intéressante de vous isoler :
$chemin =~ s#^(\s)#./$1#;
open (HF, "< $chemin\0") or die "Impossible d'ouvrir $chemin : $!";Mais vous êtes toujours vulnérables de plusieurs manières. À la place, utilisez la forme à trois arguments de open pour ouvrir proprement tout nom fichier arbitraire et sans aucun risque (supplémentaire) concernant la sécurité :
open(HF, "<", $chemin) or die "Impossible d'ouvrir $chemin : $!";D'un autre côté, si ce que vous recherchez est un véritable appel système dans le style de open(2) en C, avec les cloches et sirènes d'arrêt qui s'en suivent, alors investissez sur sysopen :
Si vous êtes sur un système qui fait la distinction entre les fichiers textes et binaires, vous pouvez avoir besoin de placer votre handle de fichier en mode binaire — ou oubliez de faire cela, comme cela peut s'avérer — pour éviter de mutiler vos fichiers. Sur de tels systèmes, si vous utilisez le mode texte avec des fichiers binaires, ou l'inverse, vous n'apprécierez certainement pas les résultats.
Les systèmes qui ont besoin de la fonction binmode se distinguent des autres par le format employé pour les fichiers textes. Ceux qui s'en passent finissent chaque ligne avec un seul caractère correspondant à ce que le C pense être un saut de ligne, \n. Unix et Mac OS tombent dans cette catégorie. Les systèmes d'exploitation des autres variétés VMS, MVS, MS-biduletrucmachinchouette et S&M traitent différemment les entrées/sorties dans les fichiers textes et binaires, ils ont donc besoin de binmode.
Ou de son équivalent. Depuis la version 5.6 de Perl, vous pouvez spécifier le mode binaire dans la fonction open sans un appel séparé à binmode. En tant que composantes de l'argument MODE (mais uniquement dans la forme à trois arguments), vous pouvez spécifier diverses disciplines d'entrées/sorties. Pour obtenir l'équivalent d'un binmode, employez la forme à trois arguments de open et donnez une discipline valant :raw après les autres caractères de MODE :
open(HF, "<:raw", $chemin) or die "Impossible d'ouvrir $chemin : $!";Puisqu'il s'agit d'une toute nouvelle fonctionnalité, il existera certainement plus de disciplines au moment où vous lirez ceci que lorsque nous l'avons écrit. Cependant, nous pouvons raisonnablement prédire qu'il y aura en toute vraisemblance des disciplines qui ressembleront pour toutes ou partie à celles du tableau 29-2.
|
Discipline |
Signification |
|---|---|
|
:raw |
Mode binaire ; ne pas traiter. |
|
:text |
Traitement par défaut de texte. |
|
:def |
Défaut déclaré par « use |
|
:latin1 |
Le fichier doit être en ISO |
|
:ctype |
Le fichier doit être en LC_TYPE. |
|
:utf8 |
Le fichier doit être en UTF |
|
:utf16 |
Le fichier doit être en UTF |
|
:utf32 |
Le fichier doit être en UTF |
|
:uni |
Pressent de l'Unicode (UTF |
|
:any |
Pressent de l'Unicode/Latin1/LC |
|
:xml |
Utilise l'encodage spécifié dans le fichier. |
|
:crlf |
Pressent des sauts de lignes. |
|
:para |
Mode paragraphe. |
|
:slurp |
Mode par avalement tout rond. |
Vous serez capables d'empiler les disciplines susceptibles d'être empilées, ainsi, vous pourrez écrire par exemple :
open(HF, "<:para:crlf:uni", $chemin)
or die "Impossible d'ouvrir $chemin : $!";
while ($para ) <HF>) { ... }Ceci positionnera les disciplines :
- en lisant certaines formes d'Unicode et en les convertissant vers le format interne de Perl UTF-8 si le fichier n'est pas d'ores et déjà en UTF-8 ;
- en cherchant les variantes des séquences de fin de ligne et en les convertissant toutes vers \n, et ;
- en traitant le fichier paragraphe par paragraphe, un peu comme le fait
$/="".
Si vous voulez positionner le mode d'ouverture par défaut (:def) à autre chose que :, vous pouvez déclarer ceci au tout début de votre fichier avec le pragma open :
use open IN => ":any", OUT => ":utf8";En fait, ce serait vraiment beau si un jour ou l'autre c'était la discipline : par défaut. Ceci reflète bien l'esprit du dicton : « Soyez tolérant avec ce que vous acceptez et strict avec ce que vous produisez.
opendir ![]()
![]()
![]()
![]()
opendir HANDLE_REPERTOIRE, EXPRCette fonction ouvre un répertoire nommé EXPR pour le traiter par readdir, telldir, seekdir, rewinddir et closedir. La fonction renvoie vrai en cas de réussite. Les handles de répertoires possèdent leur propre espace de nommage, séparé de celui des handles de fichiers.
ord ![]()
ord EXPR
ordCette fonction renvoie la valeur numérique (ASCII, Latin-1 ou Unicode) du premier caractère de EXPR. La valeur de retour est toujours non signée. Si vous désirez une valeur signée, utilisez unpack('c',EXPR). Si vous voulez convertir tous les caractères de la chaîne en une liste de nombres, utilisez unpack('U*', EXPR) à la place.
our
Un our déclare une ou plusieurs variables comme étant des variables globales valides à l'intérieur du bloc, du fichier ou de l'eval l'encadrant. C'est-à-dire que l'on détermine la visibilité de our avec les mêmes règles qu'une déclaration my. Mais our ne crée pas de variable privée ; il permet simplement l'accès sans entraves à la variable de paquetage globale existante. Si plus d'une valeur est listée, la liste doit être placée entre parenthèses.
L'utilisation principale d'un our est de cacher la variable des effets d'une déclaration use strict "vars" ; puisque la variable est masquée comme une variable my, vous avez la permission d'utiliser la variable déclarée globale sans la qualifier avec son paquetage. Cependant, tout comme une variable my, cela ne marche que dans la portée lexicale de la déclaration our. En regard de ceci, our diffère de use vars, qui affecte le paquetage dans son entier et qui n'a pas de portée lexicale.
our est également semblable à my en ce que vous êtes autorisé à déclarer une variable avec un TYPE et des ATTRIBUTS. Voici la syntaxe :
our Chien $medor :oreilles(courtes) :queue(longue);Au moment où nous écrivons ceci, sa signification n'est pas tout à fait claire. Les attributs peuvent affecter soit la variable globale, soit l'interprétation locale de $medor. D'un côté, cela ressemblerait fort aux variables my pour les attributs que l'on protège d'un voile dans la vue locale actuelle de $medor, sans interférer avec les autres vues de la variable globale à d'autres endroits. De l'autre côté, si un module déclare $medor comme étant un Chien et qu'un autre déclare $medor en tant que Chat, vous pouvez finir avec des chiens miaulant et des chats aboyant. C'est un sujet de recherche active, ce qui est une manière polie de dire que nous ne savons pas de quoi nous parlons à l'heure actuelle. (Excepté que nous savons quoi faire avec une déclaration de TYPE lorsque la variable se réfère à un pseudohachage — voir Gestion des données d'instance au chapitre 12.)
Une autre similitude entre our et my réside dans sa visibilité. Une déclaration our déclare une variable globale qui sera visible tout au long de sa portée lexicale, même au-delà des frontières de paquetages. Le paquetage dans lequel la variable est située est déterminé à l'endroit de la déclaration, pas à l'endroit où on l'utilise. Cela signifie que le comportement suivant est valide et qu'il est jugé être une fonctionnalité :
package Truc;
our $machin; # $machin est $Truc::machin pour le reste de la
# portée lexicale
$machin = 582;
package Machin
print $machin; # $affiche 582, comme si 'our' avait été 'my'Toutefois, la distinction entre my qui crée une nouvelle variable privée et our qui expose une variable globale existante est importante, particulièrement pour les affectations. Si vous combinez une affectation à l'exécution avec une déclaration our, la valeur de la variable globale ne disparaîtra pas une fois que le our sortira de la portée. Pour cela, vous avez besoin de local :
($x, $y) = ("un", "deux");
print "avant le bloc, x vaut $x, y vaut $y\n";
{
our $x = 10;
local our $y = 20;
print "dans le bloc, x vaut $x, y vaut $y\n";
}
print "après le bloc, x vaut $x, y vaut $y\n";Cela affiche :
avant le bloc, x vaut un, y vaut deux
dans le bloc, x vaut 10, y vaut 20
après le bloc, x vaut 10, y vaut deuxDe multiples déclarations our dans la même portée sont autorisées si elles se trouvent dans des paquetages différents. Si elles se produisent dans le même paquetage, Perl émettra des avertissements, si vous lui demandez de le faire.
use warnings;
package Truc;
our $machin; # déclare $Truc::machin pour le reste de la
# portée lexicale
$machin = 20;
package Machin;
our $machin = 30; # déclare $Machin::machin pour le reste de la
# portée lexicale
print $machin; # affiche 30
our $machin; # émet un avertissementVoir aussi local, my et la section Déclarations avec portée au chapitre 4.
pack ![]()
pack CANEVAS, LISTECette fonction prend une LISTE de valeurs ordinaires Perl, les convertit en une chaîne d'octets en fonction du CANEVAS et renvoie cette chaîne. La liste d'arguments est complétée ou tronquée selon les besoins. C'est-à-dire que si vous fournissez moins d'arguments que n'en requiert le CANEVAS, pack suppose que les arguments additionnels sont nuls. À l'inverse, si vous fournissez plus d'arguments que n'en requiert le CANEVAS, les arguments supplémentaires sont ignorés. Les formats inconnus du CANEVAS génèreront des exceptions.
Le CANEVAS décrit une structure de chaîne en tant que séquence de champs. Chaque champ est représenté par un seul caractère qui décrit le type de la valeur et son encodage. Par exemple, un caractère de format valant N spécifie un entier non signé de quatre octets dans l'ordre de la notation gros-boutiste (N.d.T. : big-endian).
Les champs sont empaquetés dans l'ordre donné par le CANEVAS. Par exemple, pour empaqueter un entier signé d'un octet et un nombre en virgule flottante avec une simple précision dans une chaîne, vous devez écrire :
$chaine = pack("Cf", 244, 3.14);Le premier octet de la chaîne renvoyée a la valeur 244. Les octets restants représentent l'encodage de 3.14 en tant que nombre flottant en simple précision. L'encodage particulier du nombre à virgule flottante dépend du matériel de votre ordinateur.
Les points importants à considérer lorsque vous utilisez pack sont :
- le type de donnée (comme un entier, un nombre à virgule flottante ou une chaîne) ;
- l'intervalle de valeurs (comme lorsque vos entiers occupent un, deux, quatre ou peut-être même huit octets ; ou si vous empaquetez des caractères 8-bits ou Unicode) ;
- si vos entiers sont signés ou non ;
- l'encodage à employer (comme un empaquetage de bits ou d'octets en natif, en petit-boutiste ou en gros-boutiste.
Le tableau 29-3 liste les caractères de format et leurs significations. (D'autres caractères peuvent apparaître dans les formats ; ils seront décrits plus tard.)
|
Caractère |
Signification |
|---|---|
|
a |
Une chaîne d'octets, complétée par des nuls. |
|
A |
Une chaîne d'octets, complétée par des blancs. |
|
b |
Une chaîne de bits, dans l'ordre croissant des bits à l'intérieur de chaque octet (comme |
|
B |
Une chaîne de bits, dans l'ordre décroissant des bits à l'intérieur de chaque octet. |
|
c |
Une valeur caractère signée (entier 8-bits). |
|
C |
Une valeur caractère non signé (entier 8-bits) ; voir U pour Unicode. |
|
d |
Un nombre à virgule flottante en double précision au format natif. |
|
f |
Un nombre à virgule flottante en simple précision au format natif. |
|
h |
Une chaîne hexadécimale, quartet de poids faible d'abord. |
|
H |
Une chaîne hexadécimale, quartet de poids fort d'abord. |
|
i |
Une valeur entière signée au format natif. |
|
I |
Une valeur entière non signée au format natif. |
|
l |
Une valeur entière longue signée, toujours de 32 bits. |
|
L |
Une valeur entière longue non signée, toujours de 32 bits. |
|
n |
Un court de 16 bits, dans l'ordre « réseau » (gros-boutiste). |
|
N |
Un long de 32 bits, dans l'ordre « réseau » (gros-boutiste). |
|
p |
Un pointeur sur une chaîne terminée par un caractère nul. |
|
P |
Un pointeur sur une chaîne de longueur fixe. |
|
q |
Une valeur quad (entier de 64 bits) signée. |
|
Q |
Une valeur quad (entier de 64 bits) non signé. |
|
s |
Une valeur entière courte signée, toujours de 16 bits. |
|
S |
Une valeur entière courte non signée, toujours de 16 bits. |
|
u |
Une chaîne uuencodée. |
|
U |
Un nombre en caractère Unicode. |
|
v |
Un court de 16 bits dans l'ordre « VAX » (petit-boutiste). |
|
V |
Un long de 32 bits dans l'ordre « VAX » (petit-boutiste). |
|
w |
Un entier compressé au format BER. |
|
x |
Un octet nul (avance d'un octet). |
|
X |
Recule d'un octet. |
|
Z |
Une chaîne d'octets terminée par un caractère nul (et complétée par des nuls). |
|
@ |
Remplissage avec un caractère nul à la position absolue. |
Vous pouvez librement placer des espaces et des commentaires dans vos CANEVAS. Les commentaires commencent par le symbole # habituel et se prolongent jusqu'à la première fin de ligne (s'il y en a) dans le CANEVAS. Chaque lettre peut être suivie par un nombre indiquant le compteur, que l'on interprète comme le compteur de répétitions ou la longueur en quelque sorte, selon le format. Avec tous les formats exceptés a, A, b, B, h, H, P et Z, compteur est un compteur de répétition, pack engloutit autant de valeurs dans la LISTE. Un * pour le compteur signifie autant d'entités qu'il en reste.
Les formats a, A et Z n'engloutissent qu'une seule valeur, mais l'empaquettent comme une chaîne d'octets de longueur compteur, en la complétant avec des caractères nuls ou des espaces si besoin. Lorsqu'on dépaquette, A dépouille les espaces et les caractères nuls qui traînent, Z dépouille tout ce qui se trouve après le premier caractère nul et a renvoie la donnée littérale indemne. Lorsqu'on empaquette, a et Z sont équivalents.
De même, les formats b et B empaquettent une chaîne longue de compteur bits. Chaque octet du champ d'entrée génère 1 bit dans le résultat basé sur le bit le moins significatif de chaque octet d'entrée (c'est-à-dire, sur ord($octet) % 2). Commodément, cela signifie que les octets 0 et 1 génèrent les bits 0 et 1. En partant du début de la chaîne d'entrée, chaque 8-tuple d'octets est converti vers un unique octet en sortie. Si la longueur de la chaîne d'entrée n'est pas divisible par 8, le reste est empaqueté comme s'il était complété par des 0s. De même, durant le dépaquetage avec unpack les bits supplémentaires sont ignorés. Si la chaîne d'entrée est plus longue que nécessaire, les octets supplémentaires sont ignorés. Un * comme compteur signifie l'utilisation de tous les octets du champ d'entrée. Durant le dépaquetage avec unpack, les bits sont convertis vers une chaîne de 0 s et de 1 s.
Les formats h et H empaquettent une chaîne de compteur quartets (groupes de 4 bits souvent représentés comme des chiffres hexadécimaux).
Le format p empaquette un pointeur sur une chaîne terminée par un caractère null. Il vous incombe de vous assurer que la chaîne n'est pas une valeur temporaire (qui est susceptible d'être désallouée avant que vous n'ayez fini d'utiliser le résultat empaqueté) Le format P empaquette un pointeur vers une structure dont la taille est indiquée par compteur. Un pointeur nul est créé si la valeur correspondante pour p ou P est undef.
Le caractère / permet d'empaqueter et de dépaqueter des chaînes dans lesquelles la structure empaquetée contient un compteur sur un octet suivi par la chaîne elle-même. On écrit entité-longueur/entité-chaîne. L'entité-longueur peut être n'importe quelle lettre canevas de pack et décrit comment la valeur représentant la longueur est empaquetée. Les canevas les plus susceptibles d'être utilisés sont ceux empaquetant des entiers comme n (pour les chaînes Java), w (pour de l'ASN.1 ou du SNMP) et N (pour du XDR de Sun). L'entité-chaîne doit, à présent, être A*, a* ou Z*. Pour unpack, la longueur de la chaîne est obtenue à partir de l'entité-longueur, mais si vous avez mis un *, elle sera ignorée.
unpack 'C/a', "\04Gurusamy"; # donne 'Guru'
unpack 'a3/A* A*', '007 Bond J '; # donne ('Bond','J')
pack 'n/a* w/a*','bonjour,','le monde'; # donne "bonjour, le monde"unpack ne renvoie pas explicitement l'entité-longueur. L'ajout d'un compteur à la lettre de l'entité-longueur n'est pas susceptible d'être utile à quoi que ce soit, sauf si cette lettre est A, a ou Z. L'empaquetage avec une entité-longueur de a ou Z introduit des caractères nuls (\0), que Perl ne considère pas comme légaux dans les chaînes numériques.
Les formats d'entiers s, S, l et L peuvent être immédiatement suivis par un ! pour signifier des entiers courts ou longs natifs à la place de mesurer exactement 16 et 32 bits, respectivement. À ce jour, c'est un problème principalement pour les plates-formes 64 bits, où les entiers cours et longs natifs tel que les voit le compilateur local C peuvent être complètement différents de ces valeurs. (i! et I! fonctionnent, mais seulement à cause de la complétude ; ils sont identiques à i et I.)
La taille réelle (en octets) des entiers, des courts, des longs et des « longs longs » natifs sur la plate-forme où Perl a été compilé est également disponible via le module Config :
use Config;
print $Config{shortsize}, "\n";
print $Config{intsize}, "\n";
print $Config{longsize}, "\n";
print $Config{longlongsize}, "\n";Le simple fait que Configure connaisse la taille d'un « long long », n'implique pas forcément que vous disposiez des formats q et Q. (Certains systèmes en disposent, mais vous n'en possédez certainement pas. Du moins pas encore.)
Les formats d'entiers d'une longueur plus grande qu'un seul bit (s, S, i, I, l et L) sont intrinsèquement non portables entre processeurs différents, car ils obéissent à l'ordre des octets natifs et au paradigme petit-boutiste/gros-boutiste. Si vous voulez des entiers portables, utilisez les formats n, N, v et V ; l'ordre de leurs bits et leur taille sont connus.
Les nombres à virgules flottantes ne se trouvent que dans le format natif de la machine. À cause de la variété des formats des flottants et de l'absence d'une représentation « réseau » standard, il n'existe pas d'interéchanges facilités. Cela signifie que si l'on écrit des données à virgule flottante empaquetées sur une machine, elles pourront ne pas être lisibles sur une autre. Ceci est un problème même lorsque les deux machines utilisent l'arithmétique flottante IEEE, car l'ordre (petit-boutiste/gros-boutiste) de la représentation en mémoire ne fait pas partie de la spécification IEEE.
Perl utilise en interne des doubles pour tous les calculs en virgule flottante, donc la conversion depuis un double vers un float, puis la conversion inverse perdra de la précision. Cela signifie que unpack("f", pack("f", $truc)) ne sera généralement pas égal à $truc.
Vous êtes responsable de toute considération concernant les alignements ou les remplissages exigés par d'autres programmes, particulièrement par ces programmes créés par un compilateur C avec sa propre idiosyncrasie en matière de présentation d'une struct C sur l'architecture particulière en question. Vous devrez ajouter suffisamment de x durant l'empaquetage pour compenser ceci. Par exemple, une déclaration C de :
struct machin {
unsigned char c;
float f;
}pourrait être écrite dans un format « Cxf », ou « C x3 f », ou encore « fC » — pour n'en citer que quelques-uns. Les fonctions pack et unpack gèrent leurs entrées et leurs sorties comme des séquences plates d'octets, car il n'y a aucun moyen pour elles de savoir où vont les octets, n d'où ils viennent.
Regardons quelques exemples. Cette première paire empaquette des valeurs numériques dans des octets :
$sortie = pack "CCCC", 65, 66, 67, 68; # $sortie eq "ABCD"
$sortie = pack "C4", 65, 66, 67, 68; # idemCelui-ci fait la même chose avec des lettres Unicode :
$machin = pack("U4",0x24b6,0x24b7,0x24b8,0x24b9);Celui-là est similaire, avec une paire de caractères nuls rentrant en jeu :
$sortie = pack "CCxxCC", 65, 66, 67, 68 # $sortie eq "AB\0\0CD"Empaqueter vos entiers courts n'implique pas que vous soyez portable :
$sortie = pack "s2", 1, 2; # "\1\0\2\0" en petit-boutiste
# "\0\1\0\2" en gros-boutisteDans les paquets binaires et hexadécimaux, le compteur se réfère au nombre de bits ou de quartets, pas au nombre d'octets produits :
$sortie = pack "B32", "01010000011001010111001001101100";
$sortie = pack "H8", "5065726c"; # les deux donnent "Perl"La longueur dans un champ a ne s'applique qu'à une seule chaîne :
$sortie = pack "a4", "abcd", "x", "y", "z"; # "abcd"Pour contourner cette limitation, utilisez plusieurs spécificateurs :
$sortie = pack "aaaa", "abcd", "x", "y", "z"; # "axyz"
$sortie = pack "a" x 4, "abcd", "x", "y", "z"; # "axyz"Le format a rempli avec des caractères nuls
$sortie = pack "a14", "abcdefg"; # "abcdefg\0\0\0\0\0\0\0"Ce canevas empaquette un enregistrement de struct tm C (du moins sur certains systèmes) :
$sortie = pack "i9pl", gmtime(), $tz, $toff;Généralement, le même canevas peut également être utilisé dans la fonction unpack, bien que certains formats se comportent différemment, notamment a, A et Z. Si vous voulez joindre des champs de texte de taille fixe, utilisez pack avec un CANEVAS
de format A ou a :
$chaine = pack("A10" x 10, @data);Si vous voulez joindre des champs de texte de taille variable avec un séparateur, utilisez plutôt la fonction join :
$chaine = join(" and ", @donnee);
$chaine = join("", @donnee); # séparateur nulBien que tous nos exemples utilisent des chaînes littérales comme canevas, il n'y a rien qui vous interdise d'aller chercher vos données dans un fichier sur disque. Vous pouvez construire une base de données relationnelle complète autour de cette fonction. (Nous ne nous étendrons pas sur ce que cela prouverait sur votre nature.)
package
Il ne s'agit pas vraiment d'une fonction, mais d'une déclaration qui affirme que le reste de la portée la plus intérieure l'encadrant appartient à la table de symboles ou l'espace de nom, indiqué. (La portée d'une déclaration package est ainsi la même que la portée d'une déclaration my ou our.) À l'intérieur de cette portée, la déclaration force le compilateur à résoudre tous les identificateurs non qualifiés en les recherchant dans la table de symboles du paquetage déclaré.
Une déclaration package n'affecte que les variables globales — y compris celles sur lesquelles vous avez employé local — et pas les variables lexicales déclarées avec my. Elle affecte seulement les variables globales non qualifiées ; celles qui sont qualifiées avec leur propre nom de paquetage ignorent le paquetage actuellement déclaré. Les variables globales déclarées avec our ne sont pas qualifiées et respectent par conséquent le paquetage courant, mais seulement à l'endroit de leur déclaration, après quoi elles se comportent comme des variables my. C'est-à-dire que pour le reste de leur portée lexicale, les variables our sont « clouées » au paquetage courant au moment de leur déclaration, même si une déclaration de paquetage ultérieure intervient.
La déclaration package est généralement la première d'un fichier à inclure avec un opérateur require ou use, bien qu'elle puisse se trouver en tout endroit légal pour une instruction. Lorsqu'on crée un fichier de module traditionnel ou orienté objet, il est courant d'appeler le paquetage avec le même nom que le fichier pour éviter toute confusion. (Il est également courant de mettre la première lettre du nom du paquetage en majuscule, car les modules en minuscules sont interprétés par convention comme étant des pragmas.)
Vous pouvez passer dans un paquetage donné par plus d'un endroit ; cela influence le choix de la table des symboles utilisée par le compilateur pour le reste de ce bloc. (Si le compilateur rencontre un autre paquetage déclaré au même niveau, la nouvelle déclaration écrase l'ancienne.) Votre programme principal est censé commencer par une déclaration package main.
Vous pouvez vous référer à des variables, des sous-programmes, des handles de fichier et des formats appartenant à d'autres paquetages en préfixant l'identificateur avec le nom du paquetage et un double deux-points : $Paquetage::Variable. Si le nom du paquetage est nul, le paquetage principal est pris par défaut. C'est-à-dire que $::heureuse est équivalente à $main::heureuse, tout comme à $main'heureuse, que l'on rencontre encore parfois dans d'anciens codes.
Voici un exemple :
package main; $heureuse = "un poker de dames";
package Donne; $heureuse = "truquée";
package Nimporte;
print "Ma main heureuse est $main::heureuse.\n";
print "La donne heureuse est $Donne::heureuse.\n";Ce qui affiche :
Ma main heureuse est un poker de dames.
Ma donne heureuse est truquée.La table de symboles d'un paquetage est stockée dans un hachage avec un nom se terminant par un double deux-points. La table de symboles du paquetage principal est par exemple appelée %main::. On peut donc aussi accéder au symbole *main::heureuse par $main::{"heureuse"}.
Si ESPACE_DE_NOM est omis, il n'y aura alors aucun paquetage courant et tous les identifiants devront être pleinement qualifiés ou déclarés comme lexicaux. C'est encore plus strict qu'un use strict, puisque cela s'étend également aux noms de fonctions.
Voir le chapitre 10, Paquetages, pour plus d'informations sur les paquetages. Voir my plus haut dans ce chapitre pour d'autres considérations sur les portées.
pipe ![]()
![]()
![]()
pipe HANDLE_LECTURE, HANDLE_ECRITUREComme l'appel système correspondant, cette fonction ouvre deux pipes connectés, voir pipe(2). Cet appel est presque toujours employé avant un fork, après lequel le lecteur du pipe doit fermer HANDLE_ECRITURE et celui qui écrit doit fermer HANDLE_LECTURE. (Sinon le pipe n'indiquera pas la fin de fichier à celui qui lit quand celui qui écrit le fermera.) Si vous lancez une boucle de processus par des pipes, un verrou mortel peut se produire à moins d'être très prudent. Notez de plus que les pipes de Perl utilisent des tampons d'entrées/sorties standard et qu'il vous faut donc positionner $| ($OUTPUT_AUTOFLUSH) sur votre HANDLE_ECRITURE pour vider les tampons après chaque opération de sortie, selon l'application - voir select (handle de fichier de sortie).
(Comme avec open, si l'un des handle de fichier est indéfini, il sera autovivifié.)
Voici un petit exemple :
pipe(LISEZ_MOI, ECRIVEZ_MOI);
unless ($pid = fork) { # fils
defined $pid or die "Impossible de forker : $!";
close(LISEZ_MOI);
for $i (1..5) { print ECRIVEZ_MOI "ligne $i\n" }
exit;
}
$SIG{CHLD} = sub { waitpid($pid, 0) };
close(ECRIVEZ_MOI);
@chaines = <LISEZ_MOI>;
close(LISEZ_MOI);
print "Reçu: \n", @chaines;Remarquez comment l'écrivain ferme l'extrémité de lecture et comment à l'inverse le lecteur ferme l'extrémité d'écriture. Vous ne pouvez pas utiliser un seul pipe pour une communication à double sens. Utilisez pour cela soit deux pipes différents, soit l'appel système socketpair. Voir la section Pipes au chapitre 16.
pop
pop TABLEAU
popCette fonction traite un tableau comme une pile — elle dépile (enlève) et renvoie la dernière valeur du tableau en le raccourcissant d'un élément. Si TABLEAU est omis, la fonction dépile @_ dans la portée lexicale des sous-programmes et formats ; elle dépile @ARGV dans la portée des fichiers (généralement le programme principal) ou à l'intérieur de la portée lexicale établie par les constructions eval CHAINE, BEGIN {}, CHECK {}, INIT {} et END {}. Elle entraîne les mêmes effets que :
$tmp = $TABLEAU{$#TABLEAU--};ou que :
$tmp = splice @TABLEAU, -1;S'il n'y a pas d'élément dans le tableau, pop renvoie undef. (Mais ne vous basez pas sur ceci pour vous dir que le tableau est vide si votre tableau continent des valeurs undef !) Voir également push et shift. Pour dépiler plus d'un élément, utilisez splice.
Le premier argument de pop doit être un tableau et non une liste. Pour obtenir le dernier élément d'une liste, utilisez ceci :
( LISTE )[-1]pos ![]()
pos SCALAIRE
posCette fonction renvoie l'endroit de SCALAIRE où la dernière recherche m//g s'est arrêtée. Elle renvoie le décalage du caractère suivant celui qui correspondait. (C'est-à-dire que c'est équivalent à length($`) + length($&).) Il s'agit du décalage où la prochaine recherche m//g sur cette chaîne démarrera. Rappelez-vous que le décalage début de la chaîne est 0. Par exemple :
$grafitto = "fee fie foe foo";
while ($grafitto =~ m/e/g) {
print pos $grafitto, "\n";
}affiche 2, 3, 7 et 11, les décalages de chacun des caractères suivant un « e » . On peut assigner à pos une valeur pour indiquer à m//g d'où partir :
$grafitto = "fee fie foe foo";
pos $grafitto = 4; # Sauter le fee, commencer à fie
while ($grafitto =~ m/e/g) {
print pos $grafitto, "\n";
}Cela n'affiche que 7 et 11. L'assertion \G ne recherche de correspondance qu'à l'endroit spécifié par pos à ce moment dans la chaîne dans laquelle on recherche. Voir la section Positions au chapitre 5.
print ![]()
![]()
![]()
print HANDLE _FICHIER LISTE
print LISTE
printCette fonction affiche une chaîne ou une liste de chaînes séparées par des virgules. Si la variable $\ ($OUTPUT_RECORD_SEPARATOR) est positionnée, son contenu sera affiché implicitement à la fin de la liste. La fonction renvoie vrai en cas de réussite, sinon faux. HANDLE_FICHIER peut être un nom de variable scalaire (non indicée), auquel cas la variable contient le nom du véritable handle de fichier ou une référence à un objet handle de fichier d'une quelconque sorte. HANDLE_FICHIER peut également être un bloc qui renvoie une telle valeur :
print { $OK ? "STDOUT" : "STDERR" } "$truc\n";
print { $handle_entrees_sorties[$i] } "$truc\n";Si HANDLE_FICHIER est une variable et que le token suivant est un terme, elle peut être prise à tort pour un opérateur à moins que vous n'interposiez un + ou ne mettiez des parenthèses autour des arguments. Par exemple :
print $a - 2; # envoie $a - 2 sur le handle par défaut (en général STDOUT)
print $a (- 2); # envoie -2 sur le handle de fichier spécifié par $a
print $a -2; # idem (règles d'analyse bizarres :-)Si HANDLE_FICHIER est omis, la fonction affiche sur le handle de fichier de sortie actuellement sélectionné, initialement STDOUT. Pour mettre le handle de fichier de sortie par défaut à autre chose que STDOUT, utilisez l'opération select HANDLE_FICHIER.(206) Si LISTE est également omise, la fonction affiche $_. Comme print prend une LISTE en argument, tout élément de cette LISTE est évalué dans un contexte de liste. Ainsi quand vous écrivez :
print SORTIE <STDIN>;ce n'est pas la ligne suivante de l'entrée standard qui va être affichée, mais toutes les lignes de l'entrée standard jusqu'à la fin du fichier, puisque c'est ce que <STDIN> renvoie dans un contexte de liste. Si vous voulez autre chose, écrivez :
print SORTIE scalar <STDIN>;De même, en se souvenant de la règle si-ça-ressemble-à-une-fonction-c'est-une-fonction, faites attention à ne pas faire suivre le mot-clé print d'une parenthèse gauche à moins que la parenthèse droite correspondante ne termine les arguments du print-interposez un + ou mettez des parenthèses à tous les arguments :
print (1+2)*3, "\n"; # mauvais
print +(1+2)*3, "\n"; # ok
print ((1+2)*3, "\n"); # okprintf ![]()
![]()
![]()
printf HANDLE_FICHIER FORMAT, LISTE
printf FORMAT, LISTECette fonction affiche une chaîne formatée sur HANDLE_FICHIER ou, s'il est omis, sur le handle de fichier de sortie courant, initialement STDOUT. Le premier élément de LISTE doit être une chaîne qui indique comme formater les éléments suivants. La fonction est similaire à printf (3) et fprintf (3). La fonction est exactement équivalente à :
print HANDLE_FICHIER sprintf FORMAT, LISTEsauf que $\ ($OUTPUT_RECORD_SEPARATOR) n'est pas ajouté à la fin. Si use locale est actif, le caractère utilisé comme séparateur de la partie décimale dans les nombres à virgule flottante est affecté par la locale LC_NUMERIC.
Une exception n'est levée que si un type de référence invalide est employé pour l'argument HANDLE_FICHIER. Les formats inconnus sont sautés sans modification. Ces deux situations déclenchent des avertissements si ceux-ci sont activés.
Voir les fonctions print et sprintf ailleurs dans ce chapitre. La description de sprintf inclut la liste des spécifications des formats. Nous l'aurions volontiers reproduite ici, mais ce livre est d'ores et déjà un désastre écologique.
Si vous omettez à la fois le FORMAT et la LISTE, $_ est utilisé — mais dans ce cas, vous auriez dû utiliser print. Ne tombez pas dans le piège d'utiliser un printf lorsqu'un simple print aurait très bien fait l'affaire. La fonction print est bien plus efficace et bien moins sujette à erreurs.
prototype ![]()
prototype FONCTIONRenvoie le prototype d'une fonction dans une chaîne (ou undef si la fonction n'a pas de prototype). FONCTION est une référence vers, ou le nom de, la fonction pour laquelle vous désirez trouver le prototype.
Si FONCTION est une chaîne commençant par CORE::, la suite est prise en tant que nom pour les fonctions internes de Perl, et une exception est levée s'il n'existe pas de telle fonction interne. Si la fonction interne n'est pas surchargeable (comme qw//) ou si ses arguments ne peuvent pas être exprimés par un prototype (comme system), la fonction renvoie, undef car la fonction interne ne se comporte pas véritablement comme une fonction Perl. Sinon, la chaîne décrivant le prototype équivalent est renvoyée.
push
push TABLEAU
pushCette fonction traite TABLEAU comme une pile et empile les valeurs de LISTE à la fin du tableau. La taille de TABLEAU est allongée de la longueur de LISTE. La fonction renvoie cette nouvelle taille. La fonction push entraîne les mêmes effets que :
foreach $valeur (fonction_liste()) {
$tableau[++$#tableau] = $valeur;
}ou que :
splice @tableau, @tableau, 0, fonction_liste();mais est beaucoup plus performante (à la fois pour vous et pour votre ordinateur). Vous pouvez utilisez push associée avec shift pour construire une file ou un registre à décalage assez efficace :
for (;;) {
push @tableau, shift @tableau;
...
}Voir également pop et unshift.
q/CHAINE/
q/CHAINE/
qq/CHAINE/
qr/CHAINE/
qw/CHAINE/
qx/CHAINE/Protections généralisées. Voir la section Choisissez vos délimiteurs au chapitre 2. Pour les annotations de statut pour qx//, voir readpipe. Pour les annotations de statut pour qr//, voir m//. Voir également Garder le contrôle au chapitre 5.
quotemeta ![]()
quotemeta EXPR
quotemetaCette fonction renvoie la valeur de EXPR avec tous les caractères non alphanumériques précédés d'un backslash (\). (C'est-à-dire que tous les caractères ne correspondant pas à /[A-Za-z_0-9]/ seront précédés d'un backslash dans la chaîne renvoyée, sans tenir compte des valeurs des locales.) Il s'agit de la fonction interne implémentant l'échappement \Q dans les contextes d'interpolation (comprenant les chaînes entre guillemets, entre apostrophes inverses ou les motifs).
rand
rand EXPR
randCette fonction renvoie un nombre à virgule flottante pseudoaléatoire supérieur ou égal à 0 et inférieur à la valeur de EXPR.(EXPR doit être positif.) Si EXPR est omise, la fonction renvoie un nombre à virgule flottante entre 0 et 1 (comprenant 0, mais excluant 1). rand appelle automatiquement srand sauf si la fonction srand a déjà été appelée. Voir également srand.
Pour obtenir une valeur entière, comme pour un lancer de dé, combinez ceci avec int, comme dans :
$lancer = int(rand 6) +1; # $lancer est maintenant un entier
# compris entre 1 et 6Comme Perl utilise la fonction pseudoaléatoire de votre propre bibliothèque C, comme random(3) ou drand48(3), la qualité de la distribution n'est pas garantie. Si vous avez besoin d'aléatoire plus fort, comme pour de la cryptographie, vous devriez plutôt consulter la documentation de random(4) (si votre système possède un périphérique /dev/random ou /dev/urandom), le module Math::TrulyRandom de CPAN, ou un bon bouquin sur la génération de nombres pseudoaléatoires en informatique, comme le second volume de Knuth.(207)
read ![]()
![]()
![]()
![]()
read HANDLE_FICHIER, SCALAIRE, LONGUEUR, DECALAGE
read HANDLE_FICHIER, SCALAIRE, LONGUEURCette fonction essaye de lire LONGUEUR octets de données dans la variable SCALAIRE depuis le HANDLE_FICHIER spécifié. La fonction renvoie le nombre d'octets réellement lus ou 0 en fin de fichier. undef est renvoyée en cas d'erreur. SCALAIRE est ajusté à la taille réellement lue. Le DECALAGE, s'il est spécifié, indique l'endroit de la variable à partie duquel commencer à écrire des octets, vous pouvez ainsi lire au milieu d'une chaîne.
Pour copier des données du handle de fichier DEPUIS dans le handle VERS, vous pouvez écrire :
while (read DEPUIS, $tampon, 16384) {
print VERS $tampon;
}L'inverse d'un read est simplement print, qui connaît déjà la longueur de la chaîne à écrire, et qui peut écrire une chaîne de n'importe quelle longueur. Ne faites pas l'erreur d'employer write, qui est uniquement utilisé dans les formats.
La fonction read de Perl est en fait implémentée par la fonction d'entrée/sortie standard fread(3), ce qui fait que le véritable appel système read(2) peut lire plus que LONGUEUR octets pour remplir le tampon d'entrée et que fread(3) peut faire plus d'un appel système à read(2) pour remplir ce tampon. Vous pouvez spécifier l'appel système réel par sysread pour mieux contrôler les entrées/sorties. Les appels à read et à sysread ne doivent pas être mélangés à moins d'être adepte des sciences occultes (ou des soirées cuir et chaînes). Quelle que soit celle que vous employez, faites attention : lorsque vous lisez depuis un fichier contenant un encodage Unicode ou n'importe quel encodage sur plusieurs octets, les limites du tampon peuvent tomber au milieu d'un caractère.
readdir ![]()
![]()
![]()
![]()
readdir HANDLE_REPERTOIRECette fonction lit les entrées de répertoire (qui ne sont que de simples noms de fichiers) depuis un handle de répertoire ouvert par opendir. Dans un contexte scalaire, cette fonction renvoie l'entrée de répertoire suivante si elle existe, undef sinon. Dans un contexte de liste, elle renvoie le reste des entrées du répertoire, ce qui donnera bien sûr une liste nulle s'il n'y en a plus. Par exemple :
opendir(CE_REP, "." or die "sérieusement endommagé : $!";
@tous_les_fichiers = readdir CE_REP;
closedir CE_REP;
print "@tous_les_fichiers\n";Ceci affiche tous les fichiers du répertoire courant sur une seule ligne. Pour éviter les entrées . et .., employez l'une de ces incantations (quelle que soit celle à laquelle vous pensez, elle sera moins illisible) :
@tous_les_fichiers = grep { $_ ne '.' and $_ ne '..' } readdir CE_REP;
@tous_les_fichiers = grep { not /^[.][.]?\z/ } readdir CE_REP;
@tous_les_fichiers = grep { not /^\.{1,2}\z/ } readdir CE_REP;
@tous_les_fichiers = grep !/^\.\.?\z/, readdir CE_REP;Et pour éviter tous les fichiers .*, écrivez ceci :
@tous_les_fichiers = grep !/^\./, readdir CE_REP;Pour ne lister que les fichiers texte, écrivez :
@fichiers_texte = grep -T, readdir CE_REP;Mais attention à ce dernier exemple, car le répertoire doit être recollé au résultat de readdir si ce n'est pas le répertoire courant — comme ceci :
opendir(CE_REP, $chemin); or die "opendir $chemin impossible : $!" ;
@fichiers_points = grep { /^\./ && -f } map { "$chemin/$_" }
readdir(CE_REP);
closedir CE_REP;readline ![]()
![]()
![]()
readline HANDLE_FICHIERIl s'agit de la fonction interne implémentant l'opérateur <HANDLE_FICHIER>, mais vous pouvez l'utiliser directement. La fonction lit l'enregistrement suivant depuis HANDLE_FICHIER, qui peut être un nom de handle de fichier ou une expression de handle de fichier indirect renvoyant soit le nom d'un véritable handle de fichier, soit une référence à quoi que ce soit ressemblant à une objet handle de fichier, comme un typeglob. (Les versions de Perl antérieures à la 5.6 acceptent seulement un typeglob.) Dans un contexte scalaire, chaque appel lit et renvoie le prochain enregistrement jusqu'à ce que l'on atteigne la fin de fichier, avec laquelle l'appel suivant renvoie undef. Dans un contexte de liste, readline lit tous les enregistrements jusqu'à atteindre la fin de fichier et renvoie alors une liste d'enregistrements. Par « enregistrements », il faut normalement entendre une ligne de texte, mais si la variable spéciale $/ ($INPUT_RECORD_SEPARATOR) est différente de sa valeur par défaut, l'opérateur « avalera » le texte différemment. De même, certaines disciplines en entrée, comme :para (mode paragraphe) renverront des enregistrements par morceaux, autres que des lignes. Le positionnement de la discipline :slurp (ou $/ = undef) entraînera l'avalement du fichier entier.
Lorsqu'on avale des fichiers tout rond dans un contexte scalaire, s'il vous arrive de gober un fichier vide, readline renvoie "" la première fois et undef toutes les fois suivantes. Si l'on avale tout rond en partant du handle de fichier magique ARGV, chaque fichier renvoie une seule bouchée (encore une fois, les fichiers vides renvoient ""), suivi par un seul undef lorsque tous les fichiers on été digérés.
De plus amples détails sur l'opérateur <HANDLE_FICHIER> sont donnés dans la section Opérateurs d'entrée au chapitre 2.
$ligne = <STDIN>;
$ligne = readline(STDIN); # idem
$ligne = readline(*STDIN); # idem
$ligne = readline(\*STDIN); # idem
open my $hf, "<&=STDIN" or die;
bless $hf => 'UneVieilleClasse';
$ligne = readline($hf); # idemreadlink ![]()
![]()
![]()
![]()
readlink EXPR
readlinkCette fonction renvoie le nom d'un fichier pointé par un lien symbolique. EXPR doit donner le nom d'un fichier dont la dernière composante est un lien symbolique. S'il ne s'agit pas d'un lien symbolique, ou si les liens symboliques ne sont pas implémentés dans le système de fichier, ou encore si une erreur se produit, la fonction renvoie la undef et vous devrez vérifier le code d'erreur dans $!.
Prenez garde, car le lien symbolique renvoyé peut être relatif à l'endroit spécifié. Par exemple, vous pouvez écrire :
readlink "/usr/local/src/exprimez/vous.h"et readlink pourrait renvoyer :
../exprimez.1.23/includes/vous.hce qui n'est pas franchement utile à moins que le répertoire courant ne soit justement /usr/local/src/exprimez.
readpipe ![]()
![]()
![]()
![]()
![]()
readpipe scalar EXPR
readpipe LIST (à l'étude)Il s'agit de la fonction interne implémentant la construction protégée qx// (connue également en tant qu'opérateur apostrophes inverses). Elle est parfois commode lorsque vous avez besoin de spécifier votre EXPR d'une manière qui ne serait pas pratique avec les apostrophes. Prenez garde, car nous pourrions modifier à l'avenir cette interface pour supporter un argument LISTE qui la ferait plus ressembler à la fonction exec, n'imaginez donc pas qu'elle continuera à fournir un contexte scalaire pour EXPR. Indiquez vous-même scalar ou utilisez la forme avec LISTE. Qui sait, peut-être cela fonctionnera-t-il au moment où vous lirez ceci.
recv ![]()
![]()
![]()
![]()
![]()
recv SOCKET, SCALAIRE, LONGUEUR, FLAGSCette fonction reçoit un message sur une socket. Elle s'attend à recevoir LONGUEUR octets de données dans la variable SCALAIRE depuis le handle de fichier SOCKET. La fonction renvoie l'adresse de l'expéditeur, ou undef s'il y a une erreur. SCALAIRE est ajusté à la longueur effectivement lue. Les FLAGS de la fonction sont les mêmes que ceux de recv(2). Voir la section Sockets au chapitre 16.
redo ![]()
L'opérateur redo recommence le bloc d'une boucle sans réévaluer la condition. Le bloc continue, s'il existe, n'est pas exécuté. Si l'ETIQUETTE est omise, l'opérateur se réfère à la boucle la plus interne l'encadrant. Cet opérateur est normalement utilisé par les programmes qui souhaitent dissimuler à eux-mêmes ce qui vient d'être entré :
# Une boucle qui joint les lignes coupées par un antislash.
while (<STDIN>) {
if (s/\\\n$// && defined($ligne_suivante = <STDIN>)) {
$_ .= $ligne_suivante;
redo LIGNE;
}
print; # ou ce que vous voulez
}On ne peut pas utiliser redo pour sortir d'un bloc qui renvoie une valeur comme eval {}, sub {} ou do {}, ni d'une opération grep ou map. Si les avertissements sont actifs, Perl vous avertira si vous faites un redo dans une boucle qui ne se trouve pas dans votre portée lexicale courante.
Un bloc en soi-même est sémantiquement identique à une boucle qui ne s'exécute qu'une seule fois. Ainsi redo à l'intérieur un tel bloc le changera en une construction de boucle. Voir la section Contrôle de boucle au chapitre 4.
ref ![]()
ref EXPR
refL'opérateur ref renvoie une valeur vraie si EXPR est une référence, sinon faux. La valeur renvoyée dépend du type d'objet auquel il est fait référence. Les types intégrés comprennent :
SCALAR
ARRAY
HASH
CODE
GLOB
REF
LVALUE
IO::HandleSi l'objet référencé a été consacré (avec bless) dans un paquetage, c'est le nom du paquetage qui est renvoyé. Vous pouvez voir ref comme une sorte d'opérateur « typeof ».
if (ref($r) eq "HASH") {
print "r est une référence à un hachage.\n";
} elsif (ref($r) eq "Bosse") { # Vilain, voir ci-dessous.
print "r est une référence à un objet Bosse.\n";
} elsif (not ref ($r)) {
print "r n'est pas du tout une référence.\n";
}On considère que tester l'égalité de votre classe d'objet avec une classe particulière est une erreur de style OO (orienté objet), puisqu'une classe dérivée aura un nom différent, mais devra permettre l'accès aux méthodes de la classe de base. Il vaut mieux utiliser la méthode isa de la classe UNIVERSAL comme ceci :
if ($r->isa("Bosse")) {
print "r est une référence à un objet Bosse, ou à une sous-classe.\n";
}Il vaut mieux normalement ne rien tester du tout, puisque le mécanisme OO n'enverra pas l'objet à votre méthode sauf s'il pense qu'elle est la plus appropriée. Voir les chapitres 8 et 12 pour plus de détails. Voir aussi la fonction reftype dans le pragma use attributes au chapitre 31.
rename ![]()
rename ANCIEN_NOM, NOUVEAU_NOMCette fonction change le nom d'un fichier. Elle renvoie vrai en cas de succès et faux sinon. Elle ne fonctionnera pas (normalement) à travers les frontières des systèmes de fichiers, bien que sur un système Unix, la commande mv puisse parfois être utilisée pour compenser cela. Si un fichier nommé NOUVEAU_NOM existe déjà, il sera détruit. Les systèmes non Unix peuvent comporter des restrictions supplémentaires.
Voire le module standard File::Copy pour renommer les fichiers d'un système de fichiers à l'autre.
require ![]()
![]()
![]()
![]()
Cette fonction exprime une sorte de dépendance envers son argument.
Si l'argument est une chaîne, require charge et exécute le code Perl trouvé dans le fichier séparé dont le nom est donné par la chaîne. Ceci est similaire à l'exécution d'un do, mis à part que require vérifie si le fichier de bibliothèque a déjà été chargé et lève une exception si un quelconque problème est rencontré. (On peut donc l'utiliser pour exprimer des dépendances de fichiers sans se soucier d'une duplication de la compilation.) Comme ses cousines do et use, require sait comment rechercher le chemin d'inclusion, stocké dans le tableau @INC et sait également mettre à jour %INC en cas de succès. Voir le chapitre 28.
Le fichier doit renvoyer vrai comme dernière valeur pour indiquer l'exécution réussie du code d'initialisation, il est donc habituel de terminer ce genre de fichier par un 1;, à moins que vous ne soyez sûrs qu'il renverra vrai de toute façon.
Si l'argument de require est un numéro de version de la forme 5.6.2, require exige que la version de Perl en train d'être exécuté soit égale ou supérieure à ce numéro de version. (Perl accepte également un nombre à virgule flottante comme 5.005_03 pour une compatibilité avec les anciennes versions de Perl, mais cette forme est maintenant fortement déconseillée, car les foules venant d'autres cultures ne la comprennent pas.) Ainsi, un script qui requiert Perl version 5.6 peut commencer par :
require 5.6.0 # ou require v5.6.0et les versions plus anciennes de Perl échoueront. Cependant, comme tous les require, la vérification est réalisée lors de l'exécution. Vous pouvez préférer écrire use 5.6.0 pour un test à la compilation. Voir aussi $PERL_VERSION au chapitre 28.
Si l'argument de require est le nom dénudé d'un paquetage (voir package), require suppose que le suffixe est automatiquement .pm, facilitant ainsi le chargement de modules standard. Cela ressemble à use, mis à part le fait que cela se produit à l'exécution et non à la compilation et que la méthode d'import n'est pas appelée. Par exemple, pour charger Socket.pm sans introduire aucun symbole dans le package courant, écrivez ceci :
Mais on peut toutefois obtenir le même effet avec ce qui suit, qui procure l'avantage de donner des avertissements à la compilation si Socket.pm ne peut être trouvé :
L'utilisation de require sur un nom dénudé de paquetage remplace également tout :: dans le nom d'un paquetage par le séparateur de répertoires de votre système, généralement /. En d'autres termes, si vous essayez ceci :
require Machin::Truc; # un formidable nom dénudéla fonction require cherchera le fichier Machin/Truc.pm dans les répertoires spécifiés par le tableau @INC. Mais si vous essayez cela :
$classe = 'Machin::Truc';
require $classe; # $classe n'est pas un nom dénudéou encore cela :
require "Machin::Truc"; # un littéral entre guillemets n'est pas un
#nom dénudéla fonction require recherchera le fichier Machin::Truc dans le tableau @INC et se plaindra de ne pas y trouver Machin::Truc. Si cela arrive, vous pouvez faire ceci :
eval "require $classe";Voir également les commandes do FICHIER, use, le pragma use lib et le module standard FindBin.
reset
reset EXPR
resetOn use (ou on abuse) de cette fonction généralement au début d'une boucle ou dans un bloc continue à la fin d'une boucle, pour nettoyer les variables globales ou réinitialiser les recherches ?? pour qu'elles puissent à nouveau fonctionner. L'EXPR est interprétée comme une liste de caractères uniques (les tirets sont autorisés pour les intervalles). Toutes les variables scalaires et tous les tableaux et hachages commençant par l'une de ces lettres sont remises dans leur état d'origine. Si l'EXPR est omise, les recherches de correspondance unique (?MOTIF?) sont réinitialisées pour correspondre à nouveau. La fonction réinitialise les variables ou les recherches uniquement pour le package courant. Elle renvoie toujours vrai. Pour réinitialiser toutes les variables en « X » , écrivez ceci :
reset 'X';Pour réinitialiser toutes les variables en minuscules, écrivez cela :
reset 'a-z';Enfin, pour ne réinitialiser que les recherches en ??, écrivez :
reset;La réinitialisation de « A-Z » dans le package principal main n'est pas recommandée, car les tableaux et hachages ARGV, INC, ENV et SIG seront probablement balayés.
Les variables lexicales (créées par my) ne sont pas affectées. L'emploi de reset est vaguement déprécié, car il efface un peu trop facilement des espaces de noms entiers et parce que l'opérateur ?? est lui-même vaguement déprécié.
Voir également la fonction delete_package() du module standard Symbol et la discussion entière sur les compartiments sécurisés dans la section Compartiments sécurisés au chapitre 23.
return ![]()
Cet opérateur entraîne le retour immédiat de la sous-routine courante (ou de l'eval ou du do FICHIER) avec la valeur spécifiée. Toute tentative d'utiliser return en dehors de ces trois endroits lève une exception. Remarquez également qu'un eval ne peut pas faire un return pour le compte de la sous-routine qui a appelé l'eval.
EXPR peut être évaluée dans un contexte de liste, scalaire ou vide, selon la manière dont la valeur de retour sera utilisé, ce qui peut varier d'une exécution à l'autre. C'est-à-dire que l'expression fournie sera évaluée dans le contexte de l'invocation du sous-programme. Si le sous-programme a été appelé dans un contexte scalaire, EXPR est également évaluée dans un contexte scalaire. Si le sous-programme a été appelé dans un contexte de liste, EXPR est également évaluée dans un contexte de liste. Un return sans argument renvoie la valeur scalaire undef dans un contexte scalaire et une liste vide () dans un contexte de liste, et (naturellement) rien du tout dans un contexte vide. Le contexte de l'appel au sous-programme peut être déterminé de l'intérieur du sous-programme par la fonction (mal nommée) wantarray.
reverse
reverse LISTEDans un contexte de liste, cette fonction renvoie une valeur liste composée des éléments de LISTE dans l'ordre inverse. La fonction peut être utilisée pour créer des séquences décroissantes :
for (reverse 1 .. 10) { ... }Comme les hachages se transforment en listes quand ils sont passés en tant que LISTE, reverse peut également être employée pour inverser un hachage, à supposer que les valeurs soient uniques :
%machintruc = reverse %trucmachin;Dans un contexte scalaire, la fonction concatène tous les caractères de LISTE et renvoie alors l'inverse, caractère par caractère, de la chaîne résultante.
Petite astuce : l'inversion d'une liste triée par une fonction définie par l'utilisateur peut parfois être plus facilement accomplie en triant d'abord la liste dans le sens opposé.
rewinddir ![]()
![]()
![]()
rewinddir HANDLE_REPERTOIRECette fonction se positionne au début du répertoire pour la routine readdir sur HANDLE_REPERTOIRE. La fonction peut ne pas être disponible sur toutes les machines supportant readdir — rewindir meurt si elle n'est pas implémentée. Elle renvoie vrai en cas de succès, faux sinon.
rindex
rindex CHAINE, SOUS_CHAINE, POSITION
rindex CHAINE, SOUS_CHAINECette fonction agit exactement comme index mis à part le fait qu'elle renvoie la position de la dernière occurrence de SOUS_CHAINE dans CHAINE (un index inverse). La fonction renvoie $[-1 si aucune SOUS_CHAINE n'a été trouvée. Comme $[ est le plus souvent à 0 de nos jours, la fonction renvoie presque toujours -1. POSITION, si elle est spécifiée, est la position la plus à droite qui puisse être renvoyée. Pour scruter une chaîne à l'envers, écrivez :
$pos = length $chaine;
while (($pos = rindex $chaine, $a_chercher, $pos) >= 0) {
print "Trouvé en $pos\n";
$pos--;
}rmdir ![]()
![]()
![]()
rmdir REPERTOIRE
rmdirCette fonction supprime le répertoire spécifié par REPERTOIRE si ce répertoire est vide. Si la fonction réussit, elle renvoie vrai ; sinon, elle renvoie faux. Voir également le module File::Path si vous voulez d'abord supprimer le contenu du répertoire et si vous n'envisagez pas d'appeler le shell avec rm -r, pour une raison ou une autre. (Si par exemple vous ne disposez pas de shell ou de commande rm, parce que vous n'avez pas encore PPT(208))
s/// ![]()
![]()
![]()
s///L'opérateur de substitution. Voir la section Opérateurs de correspondance de motif au chapitre 5.
scalar
scalar EXPRCette pseudofonction peut être utilisée dans une LISTE pour forcer EXPR à être évaluée dans un contexte scalaire quand l'évaluation dans un contexte de tableau produirait un résultat différent. Par exemple :
my ($var_suivante) = scalar <STDIN>;empêche <STDIN> de lire toutes les lignes depuis l'entrée standard avant d'effectuer l'affectation, puisqu'une affectation à une liste (même à une my liste) donne un contexte de liste. (Sans l'utilisation de scalar dans cet exemple, la première ligne de <STDIN> serait toujours assignée à $var_suivante, mais les lignes suivantes seraient lues et poubellisées, puisque la liste à laquelle nous sommes en train d'assigner ne peut recevoir qu'une seule valeur scalaire.)
Bien sûr, il serait plus simple et moins encombrant d'enlever les parenthèses, transformant ainsi le contexte de liste en un contexte scalaire :
my $var_suivante = <STDIN>;Puisqu'une fonction print est un opérateur de LISTE, il vous faudrait écrire :
print "La longueur est ", scalar(@TABLEAU), "\n";pour afficher la longueur de @TABLEAU.
Il n'existe aucune fonction « list » correspondant à scalar, puisqu'en pratique, on n'a jamais besoin de forcer l'évaluation dans un contexte de liste. Car toute opération demandant une LISTE fournit déjà un contexte de liste à ses arguments de liste, et ceci gratuitement.
Comme scalar est un opérateur unaire, si vous utilisez accidentellement une liste entre parenthèses pour l'EXPR, cette dernière se comportera comme une expression scalaire avec des virgules, en évaluant tous les éléments sauf le dernier dans un contexte vide et renvoyant l'élément final évalué dans un contexte scalaire. C'est rarement ce que vous voulez. La seule instruction suivante :
print uc(scalar(&machin,$truc)),$bidule;est l'équivalent (im)moral de ces deux instructions :
&machin; print(uc($truc),$bidule);Voir le chapitre 2 pour plus de détails sur le séparateur virgule. Voir la section Prototypes au chapitre 6 pour plus d'informations sur les opérateurs unaires.
seek ![]()
![]()
seek HANDLE_FICHIER, DECALAGE, DEPARTCette fonction positionne le pointeur de fichier pour HANDLE_FICHIER, exactement comme l'appel d'entrée/sortie standard fseek(3). La première position dans un fichier correspond à un décalage de 0, et non de 1. Les décalages se réfèrent à des positions en octets, et non des numéros de ligne. En général, comme les longueurs de ligne varient, il n'est pas possible d'accéder à un numéro de ligne précis sans lire tout le fichier jusqu'à cet endroit, à moins que toutes vos lignes ne soient d'une longueur fixe ou que vous ayez construit un index convertissant les numéros de lignes en décalages d'octets. (Les mêmes restrictions s'appliquent aux positions des caractères dans un fichier avec des encodages de caractères de longueur variable : le système d'exploitation ne sait pas ce que sont les caractères, il ne connaît que des octets.)
HANDLE_FICHIER peut être une expression dont la valeur donne un véritable nom de handle de fichier ou une référence vers quoi que ce soit ressemblant à un objet handle de fichier. La fonction renvoie vrai en cas de succès, faux sinon. Pour des raisons pratiques, la fonction peut calculer pour vous des décalages depuis diverses positions dans le fichier. La valeur de DEPART indique la position à partir de laquelle votre DECALAGE commencera : 0, pour le début du fichier ; 1, pour la position courante dans le fichier ; ou 2, pour la fin du fichier. Le DECALAGE peut être négatif pour un DEPART de 1 ou de 2. Si vous désirez employer des valeurs symboliques pour DEPART, vous pouvez utiliser SEEK_SET, SEEK_CUR et SEEK_END importée depuis les modules IO::Seekable ou POSIX, ou depuis la version 5.6 de Perl, depuis le module Fcntl.
Si vous voulez connaître la position dans le fichier pour sysread ou syswrite, n'employez pas seek ; les conséquences des tampons des entrées/sorties standards rendent la position système dans un fichier imprévisible et non portable. Utilisez sysseek à la place.
À cause des règles rigoureuses du C ANSI, vous devez sur certains systèmes faire un seek à chaque fois que vous basculez entre une lecture et une écriture. Parmi d'autres effets, ceci peut avoir comme conséquence d'appeler la fonction clearerr(3) de la bibliothèque standard d'entrée/sortie. Un DEPART de 1 (SEEK_CUR) avec un DECALAGE de 0 est utile pour ne pas bouger de la position courante dans le fichier :
seek(TEST,0,1);Cette fonction s'avère intéressante notamment pour suivre la croissance d'un fichier, comme ceci :
for (;;) {
while (<JOURNAL>) {
gnoquer($_) # Traiter la ligne courante
}
sleep 15;
seek LOG,0,1; # RAZ erreur de fin de fichier
}Le seek final réinitialise l'erreur de fin de fichier sans bouger le pointeur. Si cela ne fonctionne pas, selon l'implémentation de la bibliothèque C d'entrées/sorties standards, alors il vous faut plutôt ce genre de code :
for (;;) {
for ($pos_cour = tell FILE; <FILE>; $pos_cour = tell FILE) {
gnoquer($_) # Traiter la ligne courante
}
sleep $un_moment;
seek FILE, $pos_cour, 0; # RAZ erreur de fin de fichier
}Des stratégies similaires peuvent être employées pour conserver les adresses de seek pour chaque ligne dans tableau.
seekdir ![]()
![]()
![]()
seekdir HANDLE_REPERTOIRE, POSITIONCette fonction fixe la position courante pour le prochain appel à readdir sur HANDLE_REPERTOIRE. POSITION doit être une valeur renvoyée par telldir. Cette fonction comporte les mêmes dangers relatifs à un possible compactage du répertoire que la routine de la bibliothèque système correspondante. La fonction peut ne pas être implémentée partout où l'est readdir. Elle ne l'est certainement pas si readdir est absente.
select (handle de fichier de sortie) ![]()
select HANDLE_FICHIER
selectPour des raisons historiques, il existe deux opérateurs select totalement distincts l'un de l'autre. La section suivante décrit l'autre. Cette version de l'opérateur select renvoie le handle de fichier de sortie actuellement sélectionné et, si HANDLE_FICHIER est fourni, fixe le handle par défaut courant pour la sortie. Cela a deux conséquences : d'abord, un write ou un print sans handle de fichier s'adressera à ce handle par défaut. Ensuite, les variables spéciales relatives à la sortie se référeront à ce handle de fichier de sortie. Par exemple, s'il faut fixer un format d'en-tête identique pour plus d'un handle de fichier de sortie, il vous faudrait faire ceci :
select RAPPORT1;
$^ = 'mon_en_tete';
select RAPPORT2;
$^ = 'mon_en_tete';Mais remarquez que cela laisse RAPPORT2 comme handle de fichier actuellement sélectionné. Ce qui est un comportement antisocial condamnable puisque cela peut réellement démolir les routines print ou write de quelqu'un d'autre. Les routines de bibliothèque bien écrites laissent le handle de fichier sélectionné courant dans l'état où elles l'ont trouvé en entrant. À cet effet, HANDLE_FICHIER peut être une expression dont la valeur donne le nom du véritable handle de fichier. Il vous est donc possible de sauvegarder et de restaurer le handle de fichier actuellement sélectionné :
ou de manière idiomatique (mais nettement plus absconse) :
select((select(STDERR), $| = 1)[0])Cet exemple fonctionne en construisant une liste composée de la valeur renvoyée par select(STDERR) (qui sélectionne STDERR par effet de bord) et $| = 1 (qui est toujours 1), mais vide le tampon de STDERR, maintenant sélectionné, par effet de bord. Le premier élément de cette liste (le handle de fichier précédemment sélectionné) est maintenant utilisé comme un argument vers le select extérieur. Étrange, n'est-ce pas ? C'est ce que vous obtenez quand vous connaissez juste assez de Lisp pour être dangereux.
Vous pouvez également utiliser le module standard SelectSaver pour restaurer automatiquement le select précédent à la sortie de la portée.
Maintenant que nous avons expliqué tout cela, nous devons souligner que vous n'aurez que rarement besoin d'utiliser cette forme de select, car la plupart des variables spéciales auxquelles vous pouvez vouloir accéder possèdent des méthodes d'enrobage orientées objet. Donc, au lieu d'accéder directement à $|, vous pouvez écrire :
Et l'exemple précédent de format peut être codé comme suit :
use IO::Handle;
RAPPORT1->format_top_name("mon_en_tete");
RAPPORT2->format_top_name("mon_en_tete");select (descripteurs de fichiers prêts) ![]()
![]()
select BITS_LEC, BITS_ECR, BITS_ERR, MINUTEURLa forme à quatre arguments de select est totalement indépendante de l'opérateur select précédemment décrit. Celui-ci sert à découvrir lesquels (s'il en existe) de vos descripteurs de fichiers sont prêts à effectuer une entrée ou une sortie, ou à informer d'une condition d'exception. (Ce qui vous évite une scrutation.) Elle appelle l'appel système select(2) avec les masques de bits que vous avez spécifiés, qui peuvent être construits grâce à fileno et vec, comme ceci :
$lec_entree = $ecr_entree = $err_entree = ";
vec($lec_entree, fileno(STDIN), 1) = 1;
vec($ecr_entree, fileno(STDOUT), 1) = 1;
$err_entree = $lec_entree | $ecr_entree;Si vous voulez faire un select sur plusieurs handles de fichier, il peut être préférable d'écrire une routine :
sub bits_hf {
my @liste_hf = @_;
my $bits;
for (@liste_hf) {
vec($bits, fileno($_), 1) = 1;
}
return $bits;
}
$lec_entree = bits_hf(qw(STDIN TTY MA_SOCK));Si vous désirez utiliser les mêmes masques de bits de façon répétitive (et c'est plus efficace), la manière la plus courante est :
($nb_trouves, $temps_restant) =
select( $lec_sortie=$lec_entree, $ecr_sortie=$ecr_entree,
$err_sortie=$err_entree, $minuteur);Ou pour bloquer jusqu'à ce qu'un descripteur de fichiers soit prêt :
$nb_trouves = select( $lec_sortie=$lec_entree, $ecr_sortie=$ecr_entree,
$err_sortie=$err_entree, undef);Comme vous pouvez le constater, l'appel de select dans un contexte scalaire renvoie seulement $nb_trouves, soit le nombre de descripteurs de fichiers prêts trouvés.
L'astuce $ecr_sortie=$ecr_entree fonctionne, car la valeur d'une affectation est le côté gauche, ce qui fait que $ecr_sortie est d'abord modifié par l'affectation, puis par le select, alors que $ecr_entree reste inchangé.
Chaque argument peut également valoir undef. Le MINUTEUR, s'il est spécifié, est en secondes(209), et peut éventuellement comporter une virgule. (Un délai de 0 effectue une scrutation.) Toutes les implémentations ne sont pas capables de renvoyer le $temps_restant. Dans ce cas, elles renverront toujours un $temps_restant égal au $minuteur fourni.
Le module standard IO::Select fournit une interface plus amicale à select, surtout parce qu'il effectue pour vous toutes les opérations sur les masques de bits.
Un des emplois possibles de select consiste à endormir un processus avec une résolution plus fine que ce qu'admet sleep, ceci en spécifiant undef pour tous les masques de bits. Ainsi pour vous endormir pendant (au moins) 4,75 secondes, utilisez :
select undef, undef, undef, 4.75;(Le triple undef peut ne pas fonctionner sur certains systèmes non UNIX, et il vous faut alors mettre fallacieusement au moins un masque de bits à un descripteur de fichier qui ne sera jamais prêt.)
Il est dangereux de mélanger des entrées/sorties bufferisées (comme read ou <HANDLE>) avec select, à l'exception de ce que permet POSIX, et même dans ce cas, uniquement sur les systèmes réellement POSIX. Employez plutôt sysread.
semctl ![]()
![]()
semctl CLEF, NUM_SEM, CMD, ARGCette fonction invoque l'appel système semctl(2) des IPC System V. Vous devrez probablement d'abord faire use IPC::SysV pour obtenir les définitions de constantes correctes. Si CMD vaut IPC_STAT ou GETALL, ARG doit alors être une variable qui contiendra la structure semid_ds ou le tableau des valeurs de sémaphore qui sont renvoyés. Comme pour ioctl et fcntl, les valeurs renvoyées sont undef en cas d'erreur, « 0 but true » (N.d.T. : 0, mais vrai) pour zéro ou sinon la valeur réellement renvoyée.
Voir également le module IPC::Semaphore. Cette fonction n'est disponible que sur les systèmes supportant les IPC System V.
semget ![]()
![]()
semget CLEF, NB_SEM S, TAILLE, FLAGSCette fonction invoque l'appel système semget(2) des IPC System V. Vous devrez probablement d'abord faire use IPC::SysV pour obtenir les définitions de constantes correctes. La fonction renvoie l'ID du sémaphore ou undef en cas d'erreur.
Voir également le module IPC::Semaphore. Cette fonction n'est disponible que sur les systèmes supportant les IPC System V.
semop ![]()
![]()
semop CLEF, CHAINE_OPCette fonction invoque l'appel système semop(2) des IPC System V pour réaliser des opérations sur les sémaphores, comme signaler ou attendre la libération. Vous devrez probablement d'abord faire use IPC::SysV pour obtenir les définitions de constantes correctes.
CHAINE_OP doit être un tableau empaqueté de structures semop. Vous pouvez construire chaque structure semop en écrivant pack("s*", $num_sem, $op_sem, $flags_sem). Le nombre d'opérations de sémaphores est donné par la longueur de CHAINE_OP. La fonction renvoie vrai si elle a réussi, faux en cas d'erreur.
Le code qui suit attend sur le sémaphore $num_sem de l'ensemble de sémaphores identifié par $id_sem :
$op_sem = pack "s*", $semnum, -1, 0;
semop $id_sem, $op_sem or die "Problème de sémaphore : $!\n";Pour envoyer un signal au sémaphore, il vous suffit de remplacer -1 par 1.
Voir également le module IPC::Semaphore. Cette fonction n'est disponible que sur les systèmes supportant les IPC System V.
send ![]()
![]()
![]()
send SOCKET, MSG, FLAGS, VERS
send SOCKET, MSG, FLAGSCette fonction envoie un message sur une socket. Elle prend les mêmes flags que l'appel système du même nom — voir send(2). Sur des sockets non connectées, vous devez spécifier une destination VERS laquelle envoyer les données, ce qui fait que le send de Perl fonctionne comme sendto(2). La fonction send renvoie le nombre d'octets envoyés, ou undef en cas d'erreur.
(Certains systèmes traitent improprement les sockets comme des objets différents de simples descripteurs de fichiers, ce qui vous oblige à toujours utiliser send et recv sur les sockets au lieu des opérateurs d'entrée/sortie standards.)
Une erreur qu'au moins l'un de nous fait fréquemment est de confondre le send de Perl avec le send de C en écrivant :
send SOCK, $tampon, $length $tampon # FAUXCeci échouera mystérieusement selon le rapport exigé par le système entre la longueur de la chaîne et les bits de FLAGS. Voir la section Passage de message au chapitre 16 pour plus d'exemples.
setpgrp ![]()
![]()
![]()
setpgrp PID, GRP_PCette fonction modifie le groupe de processus courant (GRP_P) pour le PID spécifié (employez un PID égal à 0 pour le processus courant). L'invocation de setpgrp lèvera une exception sur une machine n'implémentant pas setpgrp(2). Attention : certains systèmes ignoreront les arguments fournis et feront toujours setpgrp(0, $$). Ce sont heureusement les arguments que l'on fournit généralement. Si les arguments sont omis, ils vaudront 0,0 par défaut. La version BSD 4.2 de setpgrp n'acceptait aucun argument, mais pour BSD 4.4, c'est un synonyme de la fonction setpgid. Pour une meilleure portabilité (du moins théorique), utilisez directement la fonction setpgid du module POSIX. Ou, si vous voulez changer votre script en démon, la fonction POSIX::setsid() peut aussi bien faire l'affaire. Remarquez que la version POSIX de setpgrp n'accepte pas d'arguments, seul setpgrp(0,0) est donc portable.
setpriority ![]()
![]()
![]()
setpriority QUOI, QUI, PRIORITECette fonction modifie la PRIORITE courante d'un processus, d'un groupe de processus ou d'un utilisateur, tel que spécifiés par QUOI et QUI. Voir setpriority(2). Son invocation lèvera une exception sur une machine où setpriority(2) n'est pas implémentée. Pour faire un nice sur votre processus de quatre unités vers le bas (la même chose que d'exécuter votre programme avec nice(1)), essayez :
setpriority 0, 0, getpriority(0, 0) + 4;L'interprétation d'une priorité donnée peut varier d'un système d'exploitation à l'autre. Certaines priorités ne sont pas accessibles aux utilisateurs sans privilèges.
Voir également le module BSD::Resource de CPAN.
setsockopt ![]()
![]()
![]()
setsockopt SOCKET, NIVEAU, NOM_OPTION, VALEUR_OPTIONCette fonction applique l'option de socket requise. La fonction renvoie undef en cas d'échec. NIVEAU spécifie quelle couche de protocole est visée par l'appel, ou SOL_SOCKET pour la socket elle-même qui se trouve au sommet de toutes les couches. VALEUR_OPTION peut être undef si vous ne voulez pas passer d'argument. Il est courant d'appliquer l'option SO_REUSEADDR, pour contourner le fait que l'on ne peut pas faire de bind vers une adresse donnée alors que la connexion TCP précédente sur ce port est toujours en train de se demander s'il faut en finir. Cela peut ressembler à ceci :
use Socket; socket(SOCK, ...)
or die "Impossible de créer une socket : $!\n";
setsockopt(SOCK, SOL_SOCKET, SO_REUSEADDR, 1)
or warn "setsockopt impossible : $!\n";Voir setsockopt(2) pour les autres valeurs possibles.
shift
shift TABLEAU
shiftCette fonction enlève la première valeur du tableau et la renvoie, réduisant ainsi le tableau d'un élément et déplaçant toutes les autres d'une unité vers le bas. (Ou vers le haut, ou vers la gauche, selon votre vision du tableau. Nous aimons bien vers la gauche.) S'il n'y a pas d'éléments dans le tableau, la fonction renvoie undef.
Si TABLEAU est omis, la fonction décale @_ dans la portée lexicale des sous-programmes et des formats ; elle décale @ARGV dans les portées de fichiers (généralement, le programme principal) ou à l'intérieur de la portée lexicale établie par les constructions eval CHAINE, BEGIN {}, CHECK {}, INIT {} et END {}.
Les sous-programmes commencent souvent par recopier leurs arguments dans des variables lexicales et peuvent utiliser shift pour ce faire :(210)
sub marine {
my $brasse = shift; # profondeur
my $poissons = shift; # nombre de poissons
my $o2 = shift; # concentration en oxygène
# ...
}shift est également employé pour traiter les arguments au début de votre programme :
while (defined($_ = shift)) {
/^[^-]/ && do { unshift @ARGV, $_; last };
/^-w/ && do { $AVERTISSEMENTS = 1; next };
/^-r/ && do { $RECURSION = 1; last };
die "Argument inconnu $_\n";
}Vous pouvez également considérer les modules Getopt::Std et GetOpt::Long pour traiter les arguments de votre programme.
Voir également unshift, push, pop et splice. Les fonctions shift et unshift font la même chose à l'extrémité gauche d'un tableau que push et pop à l'extrémité droite.
shmctl ![]()
![]()
shmctl ID, CMD, ARGCette fonction invoque l'appel système shmctl(2) des IPC System V. Vous devrez probablement d'abord faire use IPC::SysV pour obtenir les définitions de constantes correctes.
Si CMD vaut IPC_STAT, ARG doit alors être une variable qui contiendra la structure shmid_ds renvoyée. Comme pour ioctl et fcntl, les valeurs renvoyées sont undef en cas d'erreur, « 0 but true » (N.d.T. : 0, mais vrai) pour zéro ou sinon la valeur réellement renvoyée.
Cette fonction n'est disponible que sur les systèmes supportant les IPC System V.
shmget ![]()
![]()
shmget CLEF, TAILLE, FLAGSCette fonction invoque l'appel système shmget(2) des IPC System V. La fonction renvoie l'ID du segment de mémoire partagée ou undef en cas d'erreur. Avant l'appel, faites use IPC::SysV.
Cette fonction n'est disponible que sur les systèmes supportant les IPC System V.
shmread ![]()
![]()
shmread ID, VAR, POS, TAILLECette fonction lit depuis l'ID de segment de mémoire partagée en commençant à la position POS sur la longueur TAILLE (en s'y attachant, puis en copiant les données qui s'y trouvent et enfin en s'en détachant). VAR doit être une variable qui contiendra les données lues. La fonction renvoie vrai en cas de réussite et faux en cas d'erreur.
Cette fonction n'est disponible que sur les systèmes supportant les IPC System V.
shmwrite ![]()
![]()
shmwrite ID, CHAINE, POS, TAILLECette fonction écrit sur l'ID de segment de mémoire partagée en commençant à la position POS sur la longueur TAILLE (en s'y attachant, puis en y copiant des données et enfin en s'en détachant). Si CHAINE est trop longue, seulement TAILLE octets seront utilisés ; si TAILLE est trop courte, des caractères nuls sont écrits pour remplir TAILLE octets. La fonction renvoie vrai en cas de réussite et faux en cas d'erreur.
Cette fonction n'est disponible que sur les systèmes supportant les IPC System V. (Vous êtes certainement fatigués de lire ceci — nous commençons à être fatigués de l'écrire.)
shutdown ![]()
![]()
![]()
shutdown SOCKET, COMMENTCette fonction arrête une connexion socket de la manière indiquée par COMMENT. Si COMMENT vaut 0, toute réception ultérieure est interdite. Si COMMENT vaut 1, toute émission ultérieure est interdite. Si COMMENT vaut 2, tout est interdit.
shutdown(SOCK, 0); # plus de lectures
shutdown(SOCK, 1); # plus d'écritures
shutdown(SOCK, 2); # plus du tout d'entrées/sortiesCeci est utile avec les sockets lorsque vous voulez prévenir l'autre côté que vous avez fini d'écrire, mais pas de lire, ou vice versa. C'est également une forme plus déterminée de fermeture, car elle empêche toute copie de ces descripteurs détenus par des processus forkés.
Imaginez un serveur qui veut lire la requête de son client jusqu'à la fin de fichier, puis envoyer une réponse. Si le client appelle close, cette socket n'est maintenant plus valide pour les entrées/sorties, aucune réponse ne pourra donc être renvoyée. À la place, le client doit utiliser shutdown pour fermer la moitié de la connexion :
print SERVEUR, "ma requete\n"; # envoi de données
shutdown(SERVEUR, 1); # envoi de fin de ligne; plus d'écritures
$reponse = <SERVEUR>; #, mais vous pouvez encore lire(Si vous êtes arrivé ici pour savoir comment arrêter un système, vous devrez exécuter un programme externe à cet effet. Voir system.)
sin ![]()
sin EXPR
sinDésolé, même si cet opérateur évoque des choses malicieuses aux anglophones(211), il ne fait que renvoyer le sinus de EXPR (exprimée en radians).
Pour l'opération inverse, vous pouvez utiliser la fonction asin des modules Math::Trig ou POSIX, ou utiliser cette relation :
sub asin { atan2($_[0], sqrt(1 -$_[0] * $_[0])) }sleep
sleep EXPR
sleepCette fonction endort le script pendant EXPR secondes, ou éternellement si EXPR est omise. Elle renvoie le nombre de secondes réellement passées à dormir. Elle peut être interrompue en envoyant un signal SIGALRM au processus. Sur certains systèmes anciens, le repos peut durer jusqu'à une seconde de moins que ce que demandiez, selon la manière de compter les secondes. La plupart des systèmes modernes dorment toujours durant la période entière. Ils peuvent cependant sembler dormir plus que cela, car l'ordonnanceur d'un système multitâche peut ne pas donner tout de suite la main à votre processus. S'il est disponible, l'appel select (descripteurs de fichiers prêts) peut vous donner une meilleure résolution. Vous pouvez également employer syscall pour appeler les routines getitimer(2) et setitimer(2) supportée par certains systèmes Unix. Vous ne pouvez probablement pas mélanger des appels à alarm avec ceux à sleep, car sleep est souvent implémenté en utilisant alarm.
Voir également la fonction sigpause du module POSIX.
socket ![]()
![]()
![]()
![]()
socket SOCKET, DOMAINE, TYPE, PROTOCOLECette fonction ouvre une socket du type spécifié et l'attache au handle de fichier SOCKET. DOMAIN, TYPE et PROTOCOLE sont spécifiés comme pour socket(2). Si le handle de fichier SOCKET est indéfini, il sera autovivifié. Avant d'utiliser cette fonction, votre programme doit contenir la ligne :
Cela vous donne accès aux constantes appropriées. La fonction renvoie vrai en cas de réussite. Voir les exemples dans la section « Sockets » au chapitre 16.
Sur les systèmes qui supportent le flag close-on-exec pour les fichiers, ce flag sera positionné pour le nouveau descripteur de fichier ouvert, comme le détermine la valeur de $^F. Voir la variable $^F ($SYSTEM_FD_MAX) au chapitre 28.
socketpair ![]()
![]()
![]()
![]()
socketpair SOCKET1, SOCKET2, DOMAINE, TYPE, PROTOCOLECette fonction crée une paire de sockets non nommées dans le domaine spécifié, d'un type spécifié. DOMAINE, TYPE et PROTOCOLE sont spécifiés de la même manière que pour socketpair(2). Si l'un des arguments sockets (SOCKET1 ou SOCKET2) est indéfini, il sera autovivifié. La fonction renvoie vrai en cas de succès, sinon faux. Sur un système où socketpair(2) n'est pas implémenté, l'appel à cette fonction lève une exception.
Cette fonction est généralement utilisée juste avant un fork. L'un des processus résultants doit fermer SOCKET1 et l'autre SOCKET2. Vous pouvez utiliser ces sockets de manière bidirectionnelle, au contraire des handles de fichiers créés par la fonction pipe. Certains systèmes définissent pipe en termes de socketpair, auquel cas un appel à pipe(Lec, Ecr) est équivalent pour l'essentiel à :
use Socket;
socketpair(Lec, Ecr, AF_UNIX, SOCK_STREAM, PF_UNSPEC);
shutdown(Lec, 1); # plus d'écritures pour le lecteur
shutdown(Ecr, 0); # plus de lectures pour l'écrivainSur les systèmes qui supportent le flag close-on-exec pour les fichiers, ce flag sera positionné pour le nouveau descripteur de fichier ouvert, comme le détermine la valeur de $^F. Voir la variable $^F ($SYSTEM_FD_MAX) au chapitre 28. Voir également l'exemple à la fin de la section Communication bidirectionnelle au chapitre 16.
sort ![]()
sort SUB_UTILISATEUR LISTE
sort BLOC LISTE
sort LISTECette fonction trie la LISTE et renvoie la valeur liste triée. Elle trie par défaut dans le sens de comparaison standard des chaînes (les valeurs indéfinies étant triées avant les chaînes vides définies, qui sont triées avant tout le reste). Lorsque le pragma use locale est actif, sort LISTE trie LISTE selon la locale courante LC_COLLATE.
SUB_UTILISATEUR, s'il est spécifié, est le nom d'un sous-programme qui renvoie un entier inférieur, égal ou supérieur à 0, selon la manière dont les éléments du tableau doivent être ordonnés. (Les opérateurs <=> et cmp peuvent être utilisés pour effectuer facilement des comparaisons de nombres et de chaînes pouvant donner trois résultats.) Si un SUB_UTILISATEUR est donné, mais que cette fonction est indéfinie, sort génère une exception.
Pour des raisons d'efficacité, le code d'appel normal des sous-programmes est court-circuité, ce qui a pour conséquences que : le sous-programme ne peut pas être récursif (ni contenir d'opérateur de contrôle de boucle qui vous ferait sortir du bloc ou de la routine) et que les deux éléments à comparer lui sont passés non via @_, mais en positionnant temporairement les variables globales par $a et $b dans le paquetage où sort a été compilé (voir les exemples ci-dessous). Les variables $a et $b étant passées en tant qu'alias des valeurs réelles, ne les modifiez pas dans le sous-programme.
Le sous-programme de comparaison doit bien se comporter. S'il renvoie des résultats inconsistants (en disant un jour que $x[1] est inférieur à $x[2] et en prétendant le contraire le lendemain), les conséquences sont aléatoires. (C'est une autre raison de ne pas modifier $a et $b.)
SUB_UTILISATEUR peut être un nom de variable scalaire (non indicée), dont la valeur fournit le nom du sous-programme à utiliser. (Un nom symbolique plutôt qu'une référence en dur est autorisé même lorsque le pragma use strict 'refs' est actif.) En lieu et place de SUB_UTILISATEUR, on peut fournir un BLOC, sorte de sous-programme anonyme en ligne.
Pour un tri numérique ordinaire, écrivez ceci :
sub numerique { $a <=> $b }
@tri_par_nombre = sort numerique 53,29,11,32,7;Pour trier dans l'ordre décroissant, il vous suffit d'appliquer reverse après le sort, ou d'inverser l'ordre de $a et $b dans le sous-programme de tri :
@decroissant = reverse sort numerique 53,29,11,32,7;
sub inverse_numerique { $b <=> $a }
@decroissant = sort inverse_numerique 53,29,11,32,7;Pour trier des chaînes sans tenir compte de la casse (majuscules/minuscules), passez $a et $b à lc avant la comparaison :
@desordonnee = qw/moineau Autruche ALOUETTE moqueurchat geaiBLEU/;
@ordonnee = sort { lc($a) cmp lc($b) } @desordonnee;(Avec Unicode, l'emploi de lc pour la canonisation de la casse est plus ou moins préférable à l'utilisation de, uc car certaines langues différencient les majuscules pour les titres des majuscules ordinaires. Mais cela ne compte pas pour un tri ASCII basique, et si vous voulez trier convenablement de l'Unicode, vos routines de canonisation seront bien plus imaginatives que lc.)
Le tri des valeurs d'un hachage est une utilisation courante de la fonction sort. Par exemple, si un hachage %montant_ventes enregistre les ventes de différents services, une recherche dans le hachage à l'intérieur de la routine de tri permet aux clefs du hachage d'être triées selon leurs valeurs correspondantes :
# tri dans l'ordre décroissant des ventes par service
sub par_vente { $montant_ventes{$b} <=> $montant_ventes{$a} }
for $serv (sort par_vente keys %montant_ventes) {
print "$serv => $montant_ventes{$serv}\n";
}Vous pouvez effectuer des niveaux supplémentaires de tri en faisant des comparaisons en cascade à l'aide des opérateurs || ou or. Cela marche parfaitement, car les opérateurs de comparaison renvoient convenablement 0 pour une équivalence, ce qui les fait entrer dans la comparaison suivante. Ici les clefs de hachage sont triées tout d'abord selon les montants des ventes associées puis selon les clefs elles-mêmes (dans le cas où deux départements ou plus auraient le même montant de ventes) :
sub par_vente_puis_serv {
$montant_ventes{$b} <=> $montant_ventes{$a}
||
$a cmp $b
}
for $serv (sort par_vente_puis_serv keys %montant_ventes) {
print "$serv => $montant_ventes{$serv}\n";
}En supposant que @enregs est un tableau de références sur des hachages, dans lequel chaque hachage comporte des champs comme PRENOM, NOM, AGE, TAILLE et SALAIRE, la routine suivante met au début de la liste triée les enregistrements pour les personnes les plus riches, puis les plus grandes, ensuite les plus jeunes et enfin les premières dans l'ordre alphabétique :
sub prospecte {
$b->{SALAIRE} <=> $a->{SALAIRE}
||
$b->{TAILLE} <=> $a->{TAILLE}
||
$a->{AGE} <=> $b->{AGE}
||
$a->{NOM} cmp $b->{NOM}
||
$a->{PRENOM} cmp $b->{PRENOM}
}
@triee = sort prospecte @enregs;Toute information utile qui dérive de $a et de $b peut servir de base à une comparaison dans une routine de tri. Par exemple, si les lignes d'un texte doivent être triées selon des champs particuliers, split peut être utilisé dans la routine de tri pour dériver les champs :
@lignes_triees = sort {
@champs_a = split /:/, $a; # champs séparés par deux points
@champs_b = split /:/, $b;
$champs_a[3] <=> $champs_b[3] # tri numérique sur le 4e champ, puis
||
$champs_a[0] cmp $champs_b[0] # tri de chaînes sur le 1er champ, puis
||
$champs_b[2] <=> $champs_a[2] # tri numérique décroissant sur le 3e
|| # champ
... # etc.
} @lignes;Toutefois, puisque sort exécute la routine de tri plusieurs fois en utilisant différentes paires de valeurs pour $a et $b, l'exemple précédent redécoupera chaque ligne avec split plus souvent que nécessaire.
Pour éviter le coût de dérivations répétées comme l'éclatement de lignes pour comparer leurs champs, exécutez la dérivation une seule fois par valeur avant le tri et sauvegardez l'information dérivée. Ici, on crée des tableaux anonymes pour encapsuler chaque ligne ainsi que le résultat de son éclatement :
@temp = map { [$_, split /:/] } @lignes;Puis, on trie les références du tableau :
@temp = sort {
@champs_a = @$a[1..$#$a];
@champs_b = @$b[1..$#$b];
$champs_a[3] <=> $champs_b[3] # tri numérique sur le 4e champ, puis
||
$champs_a[0] cmp $champs_b[0] # tri de chaînes sur le 1er champ, puis
||
$champs_b[2] <=> $champs_a[2] # tri numérique décroissant sur le 3e
|| # champ
... # etc.
} @temp;Maintenant que les références du tableau sont triées, on peut récupérer les lignes d'origine à partir des tableaux anonymes :
@lignes_triees = map { $_->[0] } @temp;Si l'on rassemble tout cela, cette technique map-sort-map, souvent appelée transformation schwartzienne(212), peut être accomplie en une seule instruction :
@lignes_triees = map { $_->[0] }
sort {
@champs_a = @$a[1..$#$a];
@champs_b = @$b[1..$#$b];
$champs_a[3] <=> $champs_b[3]
||
$champs_a[0] cmp $champs_b[0]
||
$champs_b[2] <=> $champs_a[2]
||
...
}
map { [$_, split /:/] } @lignes;Ne déclarez pas $a et $b en tant que variables lexicales (avec my). Elles sont globales au paquetage (bien qu'exemptes des restrictions habituelles concernant les variables globales lorsque vous employez use strict). Vous devez cependant vous assurer que la routine de tri se trouve bien dans le même package, ou sinon qualifier $a et $b avec le nom du paquetage de l'appelant (voir la fonction caller).
Ceci étant dit, dans la version 5.6, vous pouvez écrire des sous-programmes de tri avec la méthode standard de passage d'arguments (et , sans coïncidence aucune, utiliser des sous-programmes XS comme routines de tri), pourvu que vous déclariez le sous-programme de tri avec un prototype valant ($$). Et dans ce cas, vous pouvez en fait déclarer $a et $b comme variables lexicales :
Et un jour ou l'autre, lorsque des prototypes complets auront été implémentés, vous écrirez seulement :
sub numerique ($a, $b) { $a <=> $b }et nous serons alors plus ou moins revenus à notre point de départ.
splice ![]()
splice TABLEAU, DECALAGE, LONGUEUR, LISTE
splice TABLEAU, DECALAGE, LONGUEUR
splice TABLEAU, DECALAGE
splice TABLEAUCette fonction enlève les éléments désignés par DECALAGE et LONGUEUR dans un TABLEAU, et les remplace par les éléments de LISTE, s'il en existe. Si DECALAGE est négatif, la fonction compte à rebours depuis la fin du tableau, mais si cela vous faisait atterrir avant le début du tableau, une exception est levée. Dans un contexte de liste, splice renvoie les éléments supprimés du tableau. Dans un contexte scalaire, elle renvoie le dernier élément enlevé ou undef s'il n'y en a pas. Si le nombre de nouveaux éléments n'est pas égal au nombre d'anciens éléments, le tableau augmente ou diminue en taille selon les besoins, et la position des éléments qui suivent cette tranche ajoutée ou enlevée est décalée en conséquence. Si LONGUEUR est omise, la fonction enlève tout à partir de DECALAGE. Si DECALAGE est omis, le tableau est vidé au fur et à mesure qu'il est lu. Les colonnes suivantes sont équivalentes (à supposer que $[ vaille 0) :
|
Méthode directe |
Équivalent splice |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
( |
|
La fonction splice peut également servir à découper la liste d'arguments passée à un sous-programme. En supposant par exemple que les longueurs de liste sont passées avant les listes elles-mêmes :
sub eq_liste { # compare deux valeurs de liste
my @a = splice(@_, 0, shift);
my @b = splice(@_, 0, shift);
return 0 unless @a == @b; # même longueur ?
while (@a) {
return 0 if pop(@a) ne pop(@b);
}
return 1;
}
if (eq_liste($long, @machin[1..$long], scalar(@truc), @truc)) { }Toutefois, il serait probablement plus propre de se contenter d'utiliser des références sur des tableaux pour faire cela.
split ![]()
![]()
split /MOTIF/, EXPR, LIMITE split /MOTIF/, EXPR
split /MOTIF/
splitCette fonction recherche des délimiteurs dans une chaîne EXPR et l'éclate en une liste de sous-chaînes, en renvoyant la valeur liste résultante dans un contexte de liste, ou le nombre de sous-chaînes dans un contexte scalaire.(213) Les délimiteurs sont déterminés par la correspondance répétée d'un motif, en utilisant l'expression régulière donnée dans MOTIF. Les délimiteurs peuvent donc être de n'importe quelle taille et ne sont pas forcément la même chaîne à chaque recherche. (Les délimiteurs ne sont généralement pas renvoyés, mais voyez les exceptions ci-dessous.) Si le MOTIF ne correspond à rien, split renvoie la chaîne d'origine comme une sous-chaîne unique. S'il trouve une occurrence, vous obtenez deux sous-chaînes, et ainsi de suite. Vous pouvez donner au MOTIF des modificateurs d'expressions régulières, comme /MOTIF/i, /MOTIF/x, etc. Lorsque vous éclatez avec un motif valant /^/, le modificateur //m est implicite.
Si LIMITE est spécifiée et positive, la fonction éclate la chaîne en, au plus, ce nombre de champs (bien qu'elle puisse l'éclater en moins si elle ne trouve pas assez de délimiteurs). Si LIMITE est négative, elle est traitée comme si une LIMITE arbitrairement grande avait été spécifiée. Si LIMITE est omise, les champs nuls qui restent sont éliminés du résultat (ce dont les utilisateurs potentiels de pop feraient bien de se souvenir). Si EXPR est omise, la fonction éclate la chaîne $_. Si MOTIF est également omis ou s'il s'agit d'un espace littéral, " ", la fonction éclate sur les caractères d'espacement, /s+/, après avoir éliminé tout espacement en début de chaîne.
On peut éclater des chaînes de n'importe quelle longueur :
@cars = split //, $mot;
@champs = split /:/, $ligne;
@mots = split " ", $paragraphe;
@lignes = split /^/, $tampon;Un motif capable de correspondre soit à la chaîne vide, soit à quelque chose de plus long que la chaîne vide (par exemple, un motif composé d'un seul caractère modifié par un * ou un ?) éclatera la valeur de EXPR en caractères séparés partout où il correspond à la chaîne vide entre les caractères ; les correspondances non nulles passeront outre les occurrences du délimiteur comme habituellement. (En d'autres termes, un motif ne trouvera pas de correspondance en plus d'un endroit, même avec une longueur de zéro.) Par exemple :
print join ':', split / */, 'à la vôtre';produira « à:l:a:v:o:t:r:e ». Les espaces ont disparu, car ils ont provoqué une correspondance non nulle. Dans un cas trivial, le motif nul // se contente d'éclater la chaîne en caractères séparés, et les espaces ne disparaissent pas. (Pour une correspondance de motif normale, un motif // répéterait le dernier motif de correspondance réussie, mais le motif de split ne tombe pas dans cette crevasse.)
Le paramètre LIMITE peut être utilisé pour n'éclater qu'une partie d'une chaîne :
($login, $mot_de_passe, $reste) = split /:/, $_, 3;Nous vous encourageons à éclater des listes de noms comme ceci afin d'autodocumenter votre code. (Pour des raisons de vérification d'erreurs, remarquez que $reste serait indéfini s'il y avait moins de 3 champs.) Quand une liste se voit assigner une valeur, si LIMITE est omise, Perl fournit une LIMITE supérieure de 1 au nombre de variables de la liste pour éviter un travail inutile. Pour la liste ci-dessus, LIMITE aurait été de 4 par défaut, et $reste n'aurait reçu que le troisième champ et non le reste de la ligne. Dans des applications où le temps compte, il vaut mieux ne pas éclater en plus de champs que ce dont vous avez vraiment besoin. (Le problème avec les langages puissants, c'est qu'ils vous laissent parfois être des idiots en puissance.)
Nous avons dit plus haut que les délimiteurs n'étaient pas renvoyés, mais si le MOTIF contient des parenthèses, les champs habituellement renvoyés viennent s'intercaler entre chaque occurrence des délimiteurs entre parenthèses qui est également incluse dans la liste résultante. Voici un exemple simple :
split /([-,])/, "1-10,20";produit la valeur de liste :
(1, '-', 10, ',', 20)S'il y a plus de parenthèses, un champ est renvoyé pour chaque paire, même si certaines ne donnent pas de correspondances, auquel cas des valeurs indéfinies sont renvoyées à ces positions. Ainsi, si vous écrivez :
split /(-)|(,)/, "1-10,20";vous obtiendrez la valeur :
(1, '-', undef, 10, undef, ',', 20)L'argument /MOTIF/ peut être remplacé par une expression spécifiant les motifs qui varient à l'exécution. Comme pour les motifs ordinaires, pour ne compiler à l'exécution qu'une seule fois, utilisez /$variable/o.
Il existe un cas spécial où la spécification d'un espace unique ("") éclate sur les caractères d'espacement tout comme split sans argument. split(" ") peut donc être utilisé pour émuler le comportement de awk par défaut. Alors qu'au contraire split(/ /) vous donnera autant de champs nuls initiaux qu'il existe d'espaces en en-tête. (Par ailleurs, si l'on fournit une chaîne au lieu d'une expression rationnelle, elle sera de toute façon interprétée comme une expression rationnelle.) Vous pouvez utiliser cette propriété pour supprimer les espaces au début et à la fin d'une chaîne et pour rassembler les séquences de caractères d'espacement consécutifs en un seul espace :
$chaine = join(' ', split(' ', $chaine));L'exemple suivant éclate un en-tête de message RFC-822 en un hachage contenant $tete{$Date}, $tete{Subject}, et ainsi de suite. Il utilise l'astuce d'assigner une liste de paire à un hachage, en se basant sur le fait que les délimiteurs alternent avec des champs délimités. Il emploie les parenthèses pour renvoyer les parties de chaque délimiteur comme faisant partie de la valeur de liste renvoyée. Comme le motif de split garantit le renvoi des éléments en paires par la vertu de contenir un seul jeu de parenthèses, l'affectation du hachage est sure de recevoir une liste composée de paires clef/valeur, où chaque clef est le nom d'un champ d'en-tête. (Cette technique fait malheureusement perdre des informations sur plusieurs lignes avec le même champ de clef, comme les lignes Received-By. Ah, et puis zut…)
$entete =~ s/\n\s+/ /g; # Réunit les lignes de continuation.
%tete = ('PREAMBULE', split /^(\S*?):\s*/m, $entete);L'exemple suivant traite les entrées d'un fichier Unix passwd(5). Vous pourriez éviter le chomp, auquel cas $shell se terminerait par un saut de ligne.
open MOT_DE_PASSE, '/etc/passwd';
while (<MOT_DE_PASSE>) {
chomp; # supprime le saut de ligne final
($login, $mot_de_passe, $uid, $gid, $nom_reel, $rep, $shell) =
split /:/;
...
}Voici comment traiter chaque mot de chaque ligne de chaque fichier d'entrée pour créer un hachage des fréquences de mots :
L'inverse de split est effectué par join (sauf que join ne peut joindre qu'avec le même délimiteur entre tous les champs). Pour éclater une chaîne sur des champs de longueur fixe, employez unpack.
sprintf
sprintf FORMAT, LISTECette fonction renvoie une chaîne formatée suivant les conventions habituelles de printf gouvernées par la fonction sprintf de la bibliothèque C. Voir sprintf (3) ou printf (3) sur votre système pour une explication des principes généraux. La chaîne FORMAT contient du texte comprenant des spécificateurs de champs auxquels les éléments de LISTE sont substitués, à raison d'un élément par champ.
Perl réalise son propre formatage pour sprintf — il émule la fonction C sprintf, mais il ne l'utilise pas.(214) Il en résulte que toutes les extensions non standards dans votre fonction sprintf (3) locale ne sont pas accessibles depuis Perl.
Le sprintf de Perl permet d'utiliser les conversions universellement connues qui sont montrées dans le tableau 29-4.
|
Champ |
Signification |
|---|---|
|
|
Un signe pourcent. |
|
|
Un caractère avec le nombre donné. |
|
|
Une chaîne. |
|
|
Un entier signé, en décimal. |
|
|
Un entier non signé, en décimal. |
|
|
Un entier non signé, en octal. |
|
|
Un entier non signé, en hexadécimal. |
|
|
Un nombre à virgule flottante, en notation scientifique. |
|
|
Un nombre à virgule flottante, en notation décimale fixe. |
|
|
Un nombre à virgule flottante, en notation |
De plus, Perl permet d'utiliser les conversions suivantes, largement supportées :
|
Champ |
Signification |
|---|---|
|
|
Comme |
|
|
Comme |
|
|
Comme |
|
|
Un entier non signé, en binaire. |
|
|
Un pointeur (affiche l'adresse de la valeur Perl en hexadécimal). |
|
|
Spécial : sauvegarde le nombre de caractères de sortie jusque là dans la prochaine variable de la liste d'arguments. |
Enfin, pour une compatibilité antérieure (et nous voulons vraiment dire « antérieure »), Perl permet d'utiliser ces conversions inutiles, mais largement supportées :
|
Champ |
Signification |
|---|---|
|
|
Un synonyme pour |
|
|
Un synonyme pour |
|
|
Un synonyme pour |
|
|
Un synonyme pour |
|
|
Un synonyme pour |
Perl permet d'utiliser les flags suivants universellement connus entre le % et le caractère de conversion :
|
Flag |
Signification |
|---|---|
|
espace |
Préfixe un nombre positif par un espace. |
|
+ |
Préfixe un nombre positif par un signe plus. |
|
- |
Justifie le champ vers la gauche. |
|
0 |
Utilise des zéros, et non des espaces, pour justifier vers la droite. |
|
# |
Préfixe un octal non nul par |
|
nombre |
Largeur minimale du champ. |
|
.nombre |
« Précision » : chiffres après la virgule pour les nombres à virgule flottante, longueur maximale pour les chaînes, longueur minimale pour les entiers. |
|
l |
Interprète l'entier comme un type C long ou unsigned long. |
|
h |
Interprète l'entier comme un type C short ou unsigned short (si aucun flag n'est fourni, l'entier est interprété comme un type C int ou unsigned). |
Il existe également ces deux flags spécifiques à Perl :
|
Flag |
Signification |
|---|---|
|
V |
Interprète l'entier comme le type entier standard de Perl. |
|
v |
Interprète la chaîne comme un vecteur d'entiers, affichés comme des nombres séparés soit par des points, soit par une chaîne arbitraire reçue depuis la liste d'arguments lorsque le flag est précédé par *. |
Si votre Perl connaît les « quads » (entiers de 64 bits) soit parce que la plate-forme les supporte nativement, soir parce que Perl a été spécialement compilé avec cette possibilité, alors les caractères duoxXb iDUO affichent des quads et ils peuvent optionnellement être précédés par ll, L ou q. Par exemple, %lld %16LX %qo. Si Perl connaît les « longs doubles » (ceci requiert que la plate-forme supporte les longs doubles), les flags efgEFG peuvent optionnellement être précédé par ll ou L. Par exemple, %llf %Lf.
Là où un nombre pourrait apparaître dans les flags, un astérisque (« * ») peut être utilisé en lieu et place, auquel cas Perl utilise la prochaine entité dans la liste d'arguments comme le nombre donné (c'est-à-dire, comme le champ de largeur ou de précision). Si un champ de largeur, obtenu avec « * » est négatif, il entraîne les mêmes effets qu'un flag « - » : une justification vers la gauche.
Le flag v est utilisé pour afficher les valeurs ordinales de caractères dans des chaînes arbitraires :
sprintf "la version est v%vd\n", $^V; # version de Perl
sprintf "l'adresse est %vd\n", $adr; # adresse IPv4
sprintf "l'adresse est %*vX\n", $adr; # adresse IPv6
sprintf "les bits sont %*vb\n", " ", $bits; # chaînes de bits aléatoiressqrt ![]()
![]()
sqrt EXPR
sqrtCette fonction renvoie la racine carrée de EXPR. Pour les autres racines, comme la racine cubique, vous pouvez utiliser l'opérateur ** pour élever quelque chose à une puissance fractionnaire. N'essayez par l'une de ces approches avec des nombres négatifs, car cela devient un problème légèrement plus complexe (et lève une exception). Mais il existe un module standard pour s'occuper de cela aussi :
use Math::Complex;
print sqrt(-2); # affiche 1.4142135623731isrand
srand EXPR
srandCette fonction positionne la « graine » aléatoire pour l'opérateur rand. Si EXPR est omise, elle utilise une valeur semi-aléatoire fournie par le noyau (si il supporte le périphérique /dev/urandom) ou basée sur l'heure et la date courante et le PID, entre autres choses. Il n'est généralement pas du tout nécessaire d'appeler srand, car si on ne l'appelle pas explicitement, l'opérateur rand l'invoque implicitement. Toutefois, ce n'était pas vrai dans les versions de Perl antérieures à 5.004, donc si votre script a besoin de tourner avec des versions de Perl plus anciennes, il doit appeler srand.
Les programmes appelés fréquemment (comme les scripts CGI) qui n'utilisent que time ^ $$ pour générer une graine aléatoire peuvent les deux tiers du temps être victimes de la propriété mathématique a^b == (a+1)^(b+1). Alors, ne faites pas cela. À la place, utilisez :
srand( time() ^ ($$ + ($$ << 15)) );Vous aurez besoin de plus d'une graine plus aléatoire que celle par défaut pour faire de la cryptographie. Sur certains systèmes le périphérique /dev/urandom est approprié. Sinon, la méthode habituelle est de faire une somme de contrôle (N.d.T. : checksum) sur la sortie compressée d'un ou plusieurs programmes donnant l'état du système d'exploitation en tenant compte du changement rapide de ces états. Par exemple :
srand (time ^ $$ ^ unpack "%L*", 'ps wwaxl | gzip');Si vous êtes particulièrement concernés par ce problème, regardez le module Math::TrulyRandom dans CPAN.
N'appelez pas srand plusieurs fois dans un programme à moins de savoir exactement ce que vous faites et pourquoi vous le faites. Le but de cette fonction est d'initialiser une « graine » pour la fonction rand pour qu'elle puisse produire un résultat différent à chaque lancement du programme. Ne l'appelez qu'une seule fois au début, faute de quoi rand ne générera pas de nombres aléatoires !
stat ![]()
![]()
![]()
stat HANDLE_FICHIER
stat EXPR
statDans un contexte scalaire, cette fonction renvoie un booléen indiquant si l'appel a réussi. Dans un contexte de liste, elle renvoie une liste de 13 éléments donnant l'état d'un fichier, qu'il soit ouvert via HANDLE_FICHIER ou nommé par EXPR. Elle est généralement utilisée comme suit :
($periph,$inode,$mode,$nb_liens,$uid,$gid,$type_periph,$taille,
$date_a,$date_m,$date_c, $taille_bloc,$blocs)
= stat $nom_fichier;Tous les champs ne sont pas supportés par tous les systèmes d'exploitation, les champs non supportés renvoient 0. Voici les significations des champs :
|
Index |
Champ |
Signification |
|---|---|---|
|
0 |
|
Numéro de périphérique du système de fichier. |
|
1 |
|
Numéro d'inode. |
|
2 |
|
Mode du fichier (type et permissions). |
|
3 |
|
Nombre de liens (en dur) vers le fichier. |
|
4 |
|
UID numérique du propriétaire du fichier. |
|
5 |
|
GID numérique du groupe désigné du fichier. |
|
6 |
|
Identificateur du périphérique (pour les fichiers spéciaux seulement). |
|
7 |
|
Taille totale du fichier, en octets. |
|
8 |
|
Dernière date d'accès au fichier en secondes depuis l'origine. |
|
9 |
|
Dernière date de modification du fichier en secondes depuis l'origine. |
|
10 |
|
Date de changement de l'inode (et non de création !) en secondes depuis l'origine. |
|
11 |
|
Taille de bloc préféré pour les entrées/sorties sur le système de fichier. |
|
12 |
|
Nombre de blocs réellement alloués. |
$periph et $inode, pris ensemble, identifient un fichier de manière unique. Les $taille_bloc et $blocs ne sont définis que sur les systèmes de fichiers dérivés de BSD. Le champ $blocs (s'il est défini) est donné en blocs de 512 octets. La valeur de $blocs*512 peut énormément différer de $taille pour des fichiers contenant des blocs non alloués, ou « trous », qui ne sont pas comptés dans $blocs. Si on passe à stat le handle de fichier spécial composé d'un souligné, aucune collection d'informations n'a lieu, mais le contenu actuel de la structure datant du dernier stat, lstat ou du dernier test de fichier en dépendant (comme -r, -w ou -x) sont renvoyés.
Comme le mode comprend à la fois le type du fichier et ses permissions, vous devez masquer la partie du type et faire printf ou sprintf avec "%o" si vous voulez voir les permissions réelles :
$mode = (stat($nom_fichier))[2];
printf "Les permissions sont %04o\n", $mode & 07777;Le module File::stat fournit un mécanisme d'accès simplifié, orienté « par nom » :
use File::stat; $sb = stat($nom_fichier);
printf "Le fichier est %s, sa taille %s, ses permissions %04o, date_m %s\n",
$nom_fichier, $sb->size, $sb->mode & 07777,
scalar localtime $sb->mtime;Vous pouvez également importer les définitions symboliques des divers bits de mode depuis le module Fcntl. Voir la documentation en ligne pour plus de détail.
Astuce : si vous n'avez seulement besoin que de la taille du fichier, essayez l'opérateur de test de fichier -s, qui renvoie directement la taille en octets. Il existe également des tests de fichiers qui renvoient l'âge du fichier en nombre de jours.
study ![]()
study SCALAIRE
studyCette fonction prend du temps supplémentaire pour étudier SCALAIRE afin d'anticiper de nombreuses recherches de motifs sur la chaîne avant qu'elle ne soit ensuite modifiée. Ceci peut ou non faire gagner du temps, selon la nature et le nombre de motifs de vos recherches, et selon la distribution des fréquences de caractères dans la chaîne recherchée — il vaut mieux que vous compariez les temps d'exécution avec et sans study pour voir ce qui tourne le plus vite. Les boucles qui cherchent de nombreuses chaînes courtes et constantes (y compris les parties constantes de motifs plus complexes) sont celles qui bénéficieront le plus de study. Si tous vos motifs sont des chaînes constantes, ancrées au début, study ne vous sera d'aucun secours, car aucune scrutation ne sera effectuée. Vous ne pouvez avoir qu'un seul study (N.d.T. : étude) actif à la fois ; si vous étudiez un scalaire différent, le premier est « dé-étudié ».
study fonctionne de la manière suivante : une liste chaînée de chacun des caractères de la chaîne est construite de façon à savoir, par exemple, où se trouvent tous les caractères « k ». Pour chaque chaîne, le caractère le plus rare est sélectionné, en se fondant sur des tables de fréquence statiques construites par des programmes C sur du texte anglais. Seuls les endroits contenant ce caractère rare sont examinés.
Par exemple, voici une boucle qui insère des entrées d'index avant toute ligne contenant un certain motif :
while (<>) {
study;
print ".IX machin\n" if /\bmachin\b/;
print ".IX truc\n" if /\btruc\b/;
print ".IX bidule\n" if /\bbidule\b/;
...
print;
}Pendant cette recherche sur /\bmachin\b/, seuls les endroits de $_ contenant « h » seront examinés, car « h » est plus rare que les autres lettres. En général, le gain est indiscutable, sauf dans des cas pathologiques. La seule question est de savoir si cela fait gagner plus de temps que de construire d'abord la liste chaînée.
Si vous devez rechercher des chaînes que vous ne connaissez qu'au moment de l'exécution, vous pouvez construire une boucle complète sous forme de chaîne et l'eval uer pour éviter la recompilation systématique de tous vos motifs. Ceci, associé à $/ pour entrer des fichiers complets en un seul enregistrement, peut être extrêmement rapide, souvent plus rapide que des programmes spécialisés comme fgrep(1). La routine suivante scrute une liste de fichiers (@fichiers) pour trouver une liste de mots @mots), et affiche les noms des fichiers contenant une correspondance sans tenir compte de la casse :
$recherche = 'while (<>) { study;';
foreach $mot (@mots) {
$recherche .= "++\$vu{\$ARGV} if /\\b$mot\\b/i;\n";
}
$recherche .= "}";
@ARGV = @fichiers;
undef $/; # gobe chaque fichier en entier
eval $recherche; # pied au plancher
die $@ if $@ # en cas d'échec de eval
$/ = "\n"; # remet le délimiteur d'entrée normal
foreach $fichier (sort keys(%vu)) {
print $fichier, "\n";
}Maintenant que nous avons l'opérateur qr//, les eval s compliqués à l'exécution comme celui ci-dessus sont moins indispensables. Ceci fait la même chose :
@motifs = ();
foreach $mot (@mots) {
push @motifs, qr/\b$mot\b/i;
}
@ARGV = @fichiers;
undef $/; # gobe chaque fichier en entier
while (<>) {
for $motif (@motifs) {
$vu{$ARGV}++ if /$motif/;
}
}
$/ = "\n"; # remet le délimiteur d'entrée normal
foreach $fichier (sort keys(%vu)) {
print $fichier, "\n";
}sub
Déclarations nommées :
Définitions nommées :
Définitions anonymes :
La syntaxe des déclarations et définitions de sous-programmes paraît compliquée, mais elle est vraiment assez simple en pratique. Tout est basé sur la syntaxe :
sub NOM PROTO ATTRS BLOCLes quatre arguments sont tous optionnels ; la seule restriction est que les champs présents doivent être présents dans cet ordre ; et que vous devez utiliser au moins un des champs NOM ou BLOC. Pour le moment nous ignorerons les champs PROTO et ATTRS ; ce sont seulement des modificateurs de la syntaxe de base. Les champs NOM et BLOC sont les parties importantes pour faire court :
- Si vous n'avez qu'un NOM mais pas de BLOC, il s'agit d'une déclaration de ce nom (et si jamais vous voulez appelez le sous-programme, vous devrez fournir plus tard une définition avec à la fois NOM et BLOC). Les déclarations nommées sont spécialement utiles pour que l'analyseur syntaxique traite un nom de manière spéciale s'il sait qu'il s'agit d'un sous-programme défini par l'utilisateur. Vous pouvez appeler ceci un sous-programme ou une fonction ou encore un opérateur, exactement comme les fonctions internes. Ces déclarations sont parfois appelées déclarations anticipées.
- Si vous avez à la fois un NOM et un BLOC, il s'agit d'une définition standard d'un sous-programme nommé (et également une déclaration, si vous n'avez pas déclaré le nom précédemment). Les définitions nommées sont spécialement utiles, car le BLOC associe un véritable sens (le corps du sous-programme) à la déclaration. C'est exactement ce que cela signifie lorsque nous disons qu'elle définit le sous-programme au lieu de simplement le déclarer. La définition ressemble toutefois à la déclaration, en ce que le code l'encadrant ne la voit pas, et qu'elle ne renvoie pas de valeur en ligne avec laquelle vous pourriez référencer le sous-programme.
- Si vous n'avez qu'un BLOC mais pas de NOM, il s'agit d'une définition sans nom, c'est-à-dire, un sous-programme anonyme. Puisqu'elle n'a pas de nom, ce n'est absolument pas une déclaration, mais un opérateur réel qui renvoie à l'exécution une référence vers le corps du sous-programme anonyme. C'est extrêmement utile pour traiter du code en tant que donnée. Cela vous permet de passer de menus morceaux de code en tant que fonctions de rappel (N.d.T. : callbacks), ou peut-être même en tant que fermetures si l'opérateur de définition sub se réfère à des variables lexicales qui se trouvent à l'extérieur de son propre code. Cela signifie que différents appels au même opérateur sub feront la comptabilité nécessaire pour conserver la visibilité de la « version » correcte de chacune de ces variables lexicales le temps où la fermeture existe, même si la portée d'origine des variables lexicales a été détruite.
Dans chacun de ces trois cas, soit l'un, soit les deux arguments PROTO et ATTRS peuvent apparaître après le NOM et avant le BLOC. Un prototype est une liste de caractères entre parenthèses qui indique à l'analyseur syntaxique comment traiter les arguments d'une fonction. Les attributs sont introduits par un deux-points et fournissent des informations supplémentaires à l'analyseur concernant la fonction. Voici une définition typique qui inclut tous les quatre champs :
pour plus de détails sur les listes d'attributs et leur manipulation, voir le pragma attributes au chapitre 31. Voir également le chapitre 6 et la section Sous-programmes anonymes au chapitre 8.
substr ![]()
![]()
![]()
subtsr EXPR, DECALAGE, LONGUEUR, REMPLACEMENT
subtsr EXPR, DECALAGE, LONGUEUR
subtsr EXPR, DECALAGECette fonction extrait une sous-chaîne de la chaîne donnée par EXPR et la renvoie. La sous-chaîne est extraite en commençant à DECALAGE caractères depuis le premier. (Remarque : si vous avez fait le malin avec $[, le début de la chaîne n'est pas à 0, mais comme vous avez été sage (n'est-ce pas ?) il n'y a pas de problème). Si DECALAGE est négatif, la sous-chaîne démarre à cette distance de la fin de la chaîne. Si LONGUEUR est omise, toute la fin de la chaîne est renvoyée. Si LONGUEUR est négative, la longueur est calculée pour laisser ce nombre de caractères depuis la fin de la chaîne. Sinon, LONGUEUR indique la longueur de la sous-chaîne à extraire, ce à quoi vous pouviez vous attendre.
Vous pouvez utiliser substr comme une lvalue (quelque chose à laquelle on peut assigner une valeur), auquel cas EXPR doit aussi en être une. Si l'on assigne une valeur d'une longueur inférieure à LONGUEUR, la chaîne sera raccourcie et si l'on assigne une valeur d'une longueur supérieure à LONGUEUR, la chaîne s'allongera pour s'en accommoder. Il vous faudra peut-être compléter ou couper la valeur avec sprintf ou l'opérateur x pour conserver une chaîne de même longueur. Si vous tentez une affectation dans une zone non allouée après la fin la chaîne, substr lève une exception.
Pour préfixer la valeur courante de $var par la chaîne "Achille" , écrivez :
substr($var, 0, 0) = "Achille";Pour remplacer le premier caractère de $var par "Talon" , écrivez :
substr($var, 0, 1) = "Talon";Et enfin, pour remplacer le dernier caractère de $var par "Lefuneste" , écrivez :
substr($var, -1, 1) = "Lefuneste";Une alternative à l'utilisation de substr en tant que lvalue est l'emploi de la chaîne REMPLACEMENT comme quatrième argument. Ceci vous permet de remplacer des parties de l'EXPR et de renvoyer ce qu'il y avait avant en une seule opération, exactement comme vous pouvez le faire avec splice. Le prochain exemple remplace également le dernier caractère de $var par "Lefuneste" et met la chaîne remplacée dans $avant :
$avant = substr($var, -1, 1, "Lefuneste");substr en tant que lvalue n'est pas réservée seulement aux affectations. Cet exemple remplace les espaces par des points, mais seulement dans les 10 derniers caractères de la chaîne :
substr($var, -10) =~ s/ /./g;symlink ![]()
![]()
![]()
symlink ANCIEN_NOM, NOUVEAU_NOMCette fonction crée un nouveau nom de fichier lié symboliquement à l'ancien nom de fichier. La fonction renvoie vrai en cas de succès, sinon faux. Sur les systèmes ne supportant pas les liens symboliques, elle lève une exception à l'exécution. Pour éviter cela, utilisez eval pour intercepter l'erreur potentielle :
$symlink_existe = eval { symlink("", ""); 1 };Ou utilisez le module Config. Soyez prudent si vous fournissez un lien symbolique relatif, car cela sera interprété relativement à la position du lien symbolique lui-même, et non à votre répertoire de travail courant.
Voir également link et readlink plus haut dans ce chapitre.
syscall ![]()
![]()
![]()
![]()
syscall LISTECette fonction invoque l'appel système (nous voulons dire un appel système, et pas une commande shell) spécifié dans le premier argument de la liste en passant les éléments restants comme arguments à l'appel système. (Beaucoup d'entre eux sont maintenant plus directement disponibles par le biais de modules comme POSIX). La fonction lève une exception si syscall(2) n'est pas implémenté.
Les arguments sont interprétés comme suit : si un argument donné est numérique, l'argument est passé comme un entier C. Sinon, c'est un pointeur sur la valeur chaîne qui est passé. Vous devez vous assurer que la chaîne est assez longue pour recevoir tout résultat pouvant y être écrit ; sinon vous chercher la copie du cœur du programme (core dump). Vous ne pouvez pas utiliser une chaîne littérale (ou toute autre chaîne en lecture seule) comme argument de syscall car Perl doit prévoir que l'on puisse écrire dans tout pointeur de chaîne. Si vos arguments entiers ne sont pas des littéraux et n'ont jamais été interprétés dans un contexte numérique, vous devrez peut-être leur ajouter 0 pour les forcer à ressembler à des nombres.
syscall renvoie toute valeur retournée par l'appel système invoqué. D'après les conventions de codage C, si l'appel système échoue, syscall renvoie -1 et positionne $! (errno). Certains appels système renvoient légitimement -1 en cas de réussite. La manière appropriée de gérer de tels appels système et d'assigner $!=0; avant l'appel et de vérifier la valeur de $! si syscall renvoie -1.
Tous les appels système ne sont pas accessibles de cette manière. Par exemple, Perl peut passer jusqu'à 14 arguments à votre appel système, ce qui doit normalement suffire en pratique. Il existe cependant un problème avec les appels système qui renvoient des valeurs multiples. Prenez syscall(&SYS_pipe) : il renvoie le numéro de fichier de l'extrémité de lecture du pipe qu'il crée. Il n'y a aucun de moyen de récupérer le numéro de fichier de l'autre extrémité. Vous pouvez éviter ce type de problème en utilisant pipe à la place. Pour résoudre le problème générique, écrivez des XSUB (modules de sous-programmes externes, un dialecte de C) pour accéder aux appels système directement. Puis mettez votre nouveau module sur CPAN et devenez mondialement populaire.
Le sous-programme suivant renvoie l'heure courante en tant que nombre à virgule flottante plutôt que le nombre entier de secondes renvoyé par time. (Il ne fonctionne que sur les machines qui supporte l'appel système gettimeofday(2).)
sub heure_precise() {
package main; # pour le prochain require
require 'syscall.ph';
# prépare le tampon pour qu'il soit de la taille de deux entiers
# longs de 32-bits
my $tv = pack("LL", ());
syscall(&SYS_gettimeofday, $tv, undef) >=0
or die "gettimeofday : $!";
my ($secondes, $microsecondes) = unpack("LL", $tv);
return $secondes + ($microsecondes /1_000_000);
}Imaginez que Perl ne supporte pas l'appel système setgroups(2)(215), mais que votre noyau l'implémente. Vous pourriez toujours l'atteindre de cette manière :
require 'syscall.ph';
syscall(&SYS_setgroups; scalar @nouveaux_gids, pack("i*", @nouveaux_gids))
or die "setgroups : $!";Vous devrez peut-être lancer h2ph, comme l'indiquent les instructions d'installations de Perl, pour créer syscall.ph. Certains systèmes peuvent nécessiter à la place un canevas pour pack de "II". Encore plus perturbant, la fonction syscall suppose une équivalence de taille entre les types C int, long et char*. Essayez de ne pas considérer syscall comme le parangon de la portabilité.
Voir le module Time::HiRes de CPAN pour une approche plus rigoureuse des problèmes de dates et d'heures d'une granularité plus fine.
sysopen ![]()
![]()
sysopen HANDLE_FICHIER, NOM_FICHIER, MODE, MASQUE
sysopen HANDLE_FICHIER, NOM_FICHIER, MODELa fonction sysopen ouvre le fichier dont le nom est donné par NOM_FICHIER et l'associe avec HANDLE_FICHIER. Si HANDLE_FICHIER est une expression, sa valeur est employée comme le nom du handle de fichier ou comme une référence sur ce dernier. Si HANDLE_FICHIER est une variable dont la valeur est indéfinie, une valeur sera créée pour vous. La valeur de retour est vrai si l'appel réussit, sinon faux.
Cette fonction est une interface directe à l'appel open(2) de votre système d'exploitation suivi par un appel de bibliothèque fdopen(3). En tant que tel, vous devrez ici prétendre être un peu un programmeur C. Les valeurs possibles et les flags de bits du paramètre MODE sont disponibles via le module Fcntl. Puisque des systèmes différents supportent des flags différents, ne comptez pas sur la disponibilité de tous les flags sur votre système. Consultez votre page de manuel open(2) ou son équivalent local pour plus de détails. Néanmoins, les flags suivants devraient être présents sur tout système disposant d'une bibliothèque C raisonnable :
|
Flag |
Signification |
|---|---|
|
O_RDONLY |
Lecture seule. |
|
O_WRONLY |
Écriture seule. |
|
O_RDWR |
Lecture et écriture. |
|
O_CREAT |
Crée le fichier s'il n'existe pas. |
|
O_EXCL |
Échoue si le fichier existe déjà. |
|
O_APPEND |
Ajoute à la fin du fichier. |
|
O_TRUNC |
Tronque le fichier. |
|
O_NONBLOCK |
Accès non bloquant. |
Beaucoup d'autres options sont toutefois possibles. Voici quelques flags moins communs :
|
Flag |
Signification |
|---|---|
|
O_NDELAY |
Ancien synonyme pour O_NONBLOCK |
|
O_SYNC |
Écrit un bloc jusqu'à ce que la donnée soit physiquement écrite vers le matériel sous-jacent. On peut également voir ici O_ASYNC, O_DSYNC et O_RSYNC. |
|
O_EXLOCK |
|
|
O_SHLOCK |
|
|
O_DIRECTOR |
Échoue si le fichier n'est pas un répertoire. |
|
O_NOFOLLOW |
Échoue si le dernier composant du chemin est un lien symbolique. |
|
O_BINARY |
Effectue un |
|
O_LARGEFILE |
Certains systèmes en ont besoin pour les fichiers de plus de 2 GO. |
|
O_NOCTTY |
L'ouverture d'un fichier de terminal ne le fera pas devenir le terminal de contrôle du processus si vous n'en aviez pas encore. Habituellement ce flag n'est plus nécessaire. |
Le flag O_EXCL ne sert pas pour les verrous : ici, l'exclusivité signifie que si le fichier existe déjà, sysopen échoue. Si le fichier nommé par NOM_FICHIER n'existe pas et que le MODE inclut le flag O_CREAT, alors sysopen crée le fichier avec les permissions initiales déterminées par l'argument MASQUE (ou 0666 s'il est omis) et modifié par le umask courant de votre processus. Cette valeur par défaut est raisonnable : voir la définition de umask pour une explication.
Les handles de fichiers ouverts avec open et sysopen peuvent être utilisés de manière interchangeable. Vous n'avez pas besoin d'utiliser sysread et ses amis simplement parce que vous avez ouvert le fichier avec sysopen, et rien ne vous en empêche si vous l'avez ouvert avec open. Les deux sont capables de choses que l'autre ne peut pas faire. Un open traditionnel peut ouvrir des pipes, forker des processus, positionner des disciplines, dupliquer des handles de fichiers et convertir un numéro descripteur de fichier vers un handle de fichier. De plus, il ignore les caractères d'espacement au début ou à la fin du nom de fichier et respecte la particularité de « - » en tant que nom de fichier spécial. Mais lorsqu'il s'agit d'ouvrir de véritables fichiers, sysopen peut faire tout ce qu'open fait.
Les exemples suivants montrent les appels équivalents à ces deux fonctions. Nous avons omis les vérifications or die $! pour plus de clarté, mais assurez-vous de toujours vérifier les valeurs de retour dans vos programmes. Nous nous restreindrons à n'employer que les flags disponibles sur virtuellement tous les systèmes d'exploitation. Il s'agit simplement d'un moyen de contrôler les valeurs que vous rassemblez par un OU en utilisant l'opérateur de bit | pour les passer dans l'argument MODE .
- Ouvrir un fichier en lecture :
open(HF, "<", $chemin);
sysopen(HF, $chemin, O_RDONLY);- Ouvrir un fichier en écriture, en créant un nouveau fichier si besoin ou en tronquant un fichier existant :
open(HF, ">", $chemin);
sysopen(HF, $chemin, O_WRONLY | O_TRUNC | O_CREAT);- Ouvrir un fichier en ajout, en le créant si besoin :
open(HF, ">>", $chemin);
sysopen(HF, $chemin, O_WRONLY | O_APPEND | O_CREAT);- • Ouvrir un fichier en mise à jour, le fichier devant déjà exister :
open(HF, "+<", $chemin);
sysopen(HF, $chemin, O_RDWR);Et voici ce que vous pouvez faire avec, sysopen mais pas avec un open traditionnel :
- Ouvrir et créer un fichier en écriture, le fichier ne devant pas déjà exister :
sysopen(HF, $chemin, O_WRONLY | O_EXCL | O_CREAT);- Ouvrir un fichier en ajout, le fichier devant déjà exister :
sysopen(HF, $chemin, O_WRONLY | O_APPEND);- Ouvrir un fichier en mise à jour, en créant un nouveau fichier si besoin :
sysopen(HF, $chemin, O_RDWR | O_CREAT);- Ouvrir un fichier en mise à jour, le fichier ne devant pas déjà exister :
sysopen(HF, $chemin, O_RDWR | O_EXCL | O_CREAT);- Ouvrir un fichier en écriture seule sans bloquer, mais sans créer le fichier s'il n'existe pas :
sysopen(HF, $chemin, O_WRONLY | O_NONBLOCK);Le module FileHandle, décrit au chapitre 32, offre un ensemble de synonymes orientés objet (plus quelques nouvelles fonctionnalités) pour ouvrir des fichiers. Vous êtes cordialement invités à utiliser les méthodes appropriées de FileHandle(216) sur tout handle créé avec open, sysopen, pipe, socket ou accept, même si vous n'avez pas employé le module pour initialiser ces handles.
sysread ![]()
![]()
![]()
![]()
![]()
sysread HANDLE_FICHIER, SCALAIRE, LONGUEUR, DECALAGE
sysread HANDLE_FICHIER, SCALAIRE, LONGUEURCette fonction tente de lire LONGUEUR octets de données dans la variable SCALAIRE depuis le HANDLE_FICHIER spécifié en utilisant l'appel système de bas niveau read(2). La fonction renvoie le nombre d'octets réellement lus, ou 0 en fin de fichier. Elle renvoie undef en cas d'erreur. La taille de SCALAIRE sera ajustée à la longueur effectivement lue. Le DECALAGE, s'il est spécifié, indique à partir d'où lire dans la chaîne, afin de pouvoir lire au milieu d'une chaîne utilisée comme tampon. Voir syswrite pour un exemple d'utilisation de DECALAGE. Une exception est levée si LONGUEUR est négative ou si DECALAGE pointe à l'extérieur de la chaîne.
Préparez-vous à gérer vous-même les problèmes (comme les appels système interrompus) que les entrées/sorties standards gèrent habituellement pour vous. Comme sysread passe outre les entrées/sorties standards, ne mélangez pas sysread avec d'autres types de lectures, ni avec print, printf, write, seek, tell ou eof à moins d'être adepte des sciences occultes (ou des soirées cuir et chaînes). De même, soyez s'il vous plaît prévenus que lors de la lecture dans un fichier contenant de l'Unicode ou tout autre encodage sur plusieurs octets, les frontières du tampon peuvent tomber au milieu d'un caractère.
sysseek ![]()
![]()
sysseek HANDLE_FICHIER, POSITION, DEPARTCette fonction affecte la position système du HANDLE_FICHIER en utilisant l'appel système lseek(2). Elle passe outre les entrées/sorties standard, ainsi les mélanges avec des lectures (autres que par sysread), ou avec print, printf, write, seek, tell ou eof peuvent semer la confusion. HANDLE_FICHIER peut être une expression dont la valeur donne le nom du handle de fichier. Les valeurs de DEPART sont 0 pour mettre se positionner exactement à POSITION, 1 pour se positionner à la position courante plus POSITION et 2 pour se positionner à EOF plus POSITION (en général, négative). Pour DEPART, vous pouvez utiliser les constantes SEEK_SET, SEEK_CUR et SEEK_END des modules standards IO::Seekable et POSIX — ou, depuis la version 5.6 de Perl, du module Fcntl qui est plus portable et plus pratique.
La fonction renvoie la nouvelle position ou undef en cas d'échec. Une position de zéro est renvoyée comme étant la chaîne spéciale « 0 but true » (N.d.T. : 0, mais vrai), qui peut être utilisée numériquement sans produire d'avertissements.
system ![]()
![]()
![]()
system CHEMIN LISTE
system CHEMINCette fonction exécute pour vous tout programme existant sur le système et renvoie le code de retour de ce programme — et non sa sortie. Pour capturer la sortie d'une commande, utilisez les apostrophes inverses ou qx// à la place. La fonction system fonctionne exactement comme exec, hormis le fait qu'elle effectue d'abord un fork puis, qu'après l'exec, elle attende que le programme exécuté se termine. C'est-à-dire qu'elle lance le programme et revient quand ce dernier a fini, au contraire d'exec, qui remplace le programme en train de tourner par le nouveau et qui donc ne revient jamais si le remplacement réussit.
Le traitement des paramètres varie selon le nombre d'arguments, comme dans la description d'exec, y compris le fait de déterminer si le shell sera appelé et si vous avez menti au programme à propos de son nom en spécifiant un CHEMIN séparé.
Étant donné que system et les apostrophes inverses bloquent les signaux SIGINT et SIGQUIT, l'envoi de l'un de ces signaux (provenant par exemple d'un Control-C) au programme en train de tourner n'interrompt pas votre programme principal. Mais l'autre programme qui est en train de tourner reçoit bien le signal. Vérifiez la valeur de retour de system pour voir si le programme que vous avez lancé s'est terminé proprement ou pas.
@args = ("commande", "arg1", "arg2");
system(@args) == 0
or die "system @args a échoué : $?";La valeur de retour est le statut de sortie du programme tel que renvoyé par l'appel système wait(2). Avec les sémantiques traditionnelles, pour obtenir la véritable valeur de sortie, divisez par 256 ou faites un décalage de 8 bits vers la gauche. Ceci, car l'octet de poids faible contient quelque chose d'autre. (Deux choses en fait.) Les sept bits de poids faible indiquent le numéro du signal qui a tué le processus (s'il y en a un) et le huitième bit indique si le processus a fait une copie du cœur du programme (core dump). Vous pouvez vérifier toutes les possibilités d'échec, y compris les signaux et les core dumps, en inspectant $? ($CHILD_ERROR) :
$valeur_sortie = $? >> 8;
$num_signal = $? & 127; # ou 0x7f, ou 0177, ou 0b0111_1111
$coeur_copie = $? & 128; # ou 0x80, ou 0200, ou 0b1000_0000Lorsque le programme a été lancé à travers un shell(217) car vous aviez un seul argument et que cet argument contenait des métacaractères du shell, les codes de retours normaux sont sujets aux caprices et aptitudes supplémentaires du shell. En d'autres termes, dans ces circonstances, vous pouvez être incapable de retrouver l'information détaillée décrite précédemment.
syswrite ![]()
![]()
![]()
syswrite HANDLE_FICHIER, SCALAIRE, LONGUEUR, DECALAGE
syswrite HANDLE_FICHIER, SCALAIRE, LONGUEUR
syswrite HANDLE_FICHIER, SCALAIRECette fonction tente d'écrire LONGUEUR octets de données depuis la variable SCALAIRE vers le HANDLE_FICHIER spécifié en utilisant l'appel système write(2). La fonction renvoie le nombre d'octets réellement écrits, ou undef en cas d'erreur. Le DECALAGE, s'il est spécifié, indique à partir de quel endroit de la chaîne il faut commencer à écrire. (Si par exemple la chaîne vous sert par exemple de tampon, ou qu'il vous faut reprendre une écriture partielle.) Un DECALAGE négatif spécifie que l'écriture doit partir de ce nombre d'octets depuis la fin de la chaîne. Si SCALAIRE est vide, le seul DECALAGE permis est 0. Une exception est levée si LONGUEUR est négative ou si DECALAGE pointe à l'extérieur de la chaîne.
Pour copier des données du handle de fichier DEPUIS vers le handle de fichier VERS, vous pouvez utiliser quelque chose comme :
use Errno qw/EINTR/;
$taille_bloc = (stat FROM)[11] ||16384; # taille de bloc préférée ?
while ($lng = sysread DEPUIS, $tamp, $taille_bloc) {
if (!defined $lng) {
next if $! == EINTR;
die "Erreur système sur read : $!\n";
}
$decalage = 0;
while ($lng) { # Gère les écritures partielles.
$ecrit = syswrite VERS, $tamp, $lng, $decalage;
die "Erreur système sur write : $!\n" unless defined $ecrit;
$decalage += $ecrit;
$lng -= $ecrit;
}
}Préparez-vous à gérer par vous-même les problèmes que les entrées/sorties standards traitent habituellement pour vous, telles que les écritures partielles. Comme syswrite passe outre les entrées/sorties standards de la bibliothèque C, ne mélangez pas d'appels à syswrite avec des lectures (autres que sysread), des écritures (comme print, printf ou write) ou d'autres opérations d'entrées/sorties comme seek, tell ou eof à moins d'être adepte des sciences occultes.(218)
tell ![]()
tell HANDLE_FICHIER
tellCette fonction renvoie la position actuelle dans le fichier (en octets, sur une base de zéro) pour HANDLE_FICHIER. Généralement, cette valeur est passée à la fonction seek à un moment ultérieur pour revenir à la position courante. HANDLE_FICHIER peut être une expression donnant le nom du handle de fichier réel ou une référence sur un objet handle de fichier. Si HANDLE_FICHIER est omis, la fonction renvoie la position dans le dernier fichier lu. Les positions ne sont significatives que sur les fichiers ordinaires. Les périphériques, les pipes et les sockets ne connaissent pas les positions.
Il n'existe pas de fonction systell. Utilisez sysseek(HF, 0, 1) pour cela. Voir seek pour un exemple expliquant comment utiliser tell.
telldir ![]()
![]()
telldir HANDLE_REPERTOIRECette fonction renvoie la position courante des routines readdir sur HANDLE_REPERTOIRE. Cette valeur peut être fournie à seekdir pour accéder à un endroit particulier d'un répertoire. La fonction comporte les mêmes dangers relatifs à un possible compactage du répertoire que la routine de la bibliothèque système correspondante. Cette fonction peut ne pas être implémentée partout où l'est readdir. Même si c'est le cas, aucun calcul ne peut être fait avec la valeur de retour. Il s'agit seulement d'une valeur opaque, qui n'a de signification que pour seekdir.
tie ![]()
tie VARIABLE, NOM_CLASSE, LISTECette fonction relie une variable à une classe de paquetage qui fournit l'implémentation de la variable. VARIABLE est la variable (scalaire, tableau ou hachage) ou le type glob (représentant un handle de fichier) qui doit être relié. NOM_CLASSE est le nom d'une classe implémentant des objets du type approprié.
Tous les arguments additionnels sont passés à la méthode constructeur appropriée, soit l'un des constructeurs parmi TIESCALAR, TIEARRAY ou TIEHASH. (Si la méthode appropriée n'est pas trouvée, une exception est levée.) Ces arguments sont généralement similaires à ceux que l'on enverrait à la fonction dbm_open(3) du C, mais leur signification dépend du paquetage. L'objet renvoyé par le constructeur est à son tour renvoyé par la fonction tie, ce qui s'avère utile si vous voulez accéder à d'autres méthodes de NOM_CLASSE. (On peut aussi accéder à l'objet par le biais de la fonction tied). Ainsi, une classe reliant un hachage à une implémentation ISAM peut fournir une méthode supplémentaire pour traverser séquentiellement un ensemble de clefs (le « S » de ISAM), puisque vos implémentations habituelles de DBM ne peuvent pas le faire.
Les fonctions comme keys et values peuvent renvoyer d'énormes valeurs de listes quand elles sont appliquées à de grands objets comme des fichiers DBM. Vous pouvez préférer utiliser la fonction each pour parcourir ces derniers. Par exemple :
use NDBM_File;
tie %ALIAS, "NDBM_File", "/etc/aliases", 1, 0
or die "Impossible d'ouvrir les alias : $!\n";
while (($clef,$val) = each %ALIAS) {
print $clef, ' = ', $val, "\n";
}
untie %ALIAS;Une classe implémentant un hachage doit comprendre les méthodes suivantes :
TIEHASH CLASSE, LISTE
FETCH SOI, CLEF
STORE SOI, CLEF, VALEUR
DELETE SOI, CLEF
CLEAR SOI
EXISTS SOI, CLEF
FIRSTKEY SOI
NEXTKEY SOI, CLEF_PRECEDENTE
DESTROY SOIUne classe implémentant un tableau ordinaire doit comprendre les méthodes suivantes :
TIEARRAY CLASSE, LISTE
FETCH SOI, INDICE
STORE SOI, INDICE, VALEUR
FETCHSIZE SOI
STORESIZE SOI, COMPTEUR
CLEAR SOI
PUSH SOI, LISTE
POP SOI
SHIFT SOI
UNSHIFT SOI LISTE
SPLICE SOI, DECALAGE, LONGUEUR, LISTE
EXTEND SOI, COMPTEUR
DESTROY SOIUne classe implémentant un scalaire doit comprendre les méthodes suivantes :
TIESCALAR CLASSE, LISTE
FETCH SOI
STORE SOI, VALEUR
DESTROY SOIUne classe implémentant un handle de fichier doit comprendre les méthodes suivantes :
TIEHANDLE CLASSE, LISTE
READ SOI, SCALAIRE, LONGUEUR, DECALAGE
READLINE SOI
GETC SOI
WRITE SOI, SCALAIRE, LONGUEUR, DECALAGE
PRINT SOI, LISTE
PRINTF SOI, FORMAT, LISTE
CLOSE SOI
DESTROY SOILes méthodes indiquées ci-dessus n'ont pas toutes besoin d'être implémentées : Les modules Tie::Hash, Tie::Array, Tie::Scalar et Tie::Handle fournissent des classes de base qui ont des méthodes par défaut raisonnables. Voir chapitre 14, Variables attachées, pour un commentaire détaillé de ces méthodes. À l'inverse de dbmopen, la fonction tie ne fera pas automatiquement un use ou un require — vous devez le faire vous-même explicitement. Voir les modules DB_File et Config qui fournissent des implémentations intéressantes de tie.
tied
tied VARIABLECette fonction renvoie une référence vers l'objet qui sous-tend le scalaire, le tableau, le hachage ou le typeglob contenu dans VARIABLE (la même valeur qui a été renvoyée à l'origine par l'appel à tie, qui a lié la variable au paquetage). Elle renvoie la valeur indéfinie si VARIABLE n'est pas attachée à un paquetage. Vous pouvez par exemple utiliser :
ref tied %hachagepour savoir à quel paquetage votre hachage est attaché. (À supposer que vous l'ayez oublié).
time
timeCette fonction renvoie le nombre de secondes écoulées depuis le 1er janvier 1970, UTC, à 00::00::00.(219) La valeur renvoyée est acceptée par gmtime et localtime pour servir aux comparaisons avec les dates de modification et d'accès renvoyées par stat et pour être passée à utime.
$debut = time(); system("une commande lente");
$fin = time();
if ($fin - $debut > 1) {
print "Le programme a commencé à : ", scalar localtime($debut), "\n";
print "Le programme a fini à : ", scalar localtime($fin), "\n";
}times ![]()
timesDans un contexte de liste, cette fonction renvoie un tableau à quatre éléments donnant les temps utilisateur et système, en secondes (probablement fractionnaires), pour ce processus et pour les fils de ce processus qui sont terminés.
($utilisateur, $systeme, $cutilisateur, $csysteme) = times();
printf "Ce pid et ses fils ont consommé %.3f secondes\n",
$utilisateur + $systeme + $cutilisateur + $csysteme;Dans un contexte scalaire, elle ne renvoie que le temps utilisateur. Par exemple, pour mesurer la vitesse d'exécution d'une section de code Perl :
$debut = times();
...
$fin = times();
printf "Nous avons mis %.2f secondes CPU en temps utilisateur\n",
$fin - $debut;tr/// ![]()
tr///
y///Il s'agit de l'opérateur de traduction (appelé aussi translation), qui ressemble à l'opérateur y/// du programme sed d'UNIX, en mieux, selon l'humble opinion de tout le monde. Voir le chapitre 5.
truncate ![]()
![]()
![]()
![]()
truncate HANDLE_FICHIER, LONGUEUR
truncate EXPR, LONGUEURCette fonction tronque le fichier ouvert sur HANDLE_FICHIER, ou nommé par EXPR, à la longueur spécifiée. La fonction lève une exception si truncate(2) ou un équivalent n'est pas implémenté sur le système. (Il est toujours possible de tronquer un fichier en n'en recopiant que le début, si vous disposez de l'espace disque nécessaire.) La fonction renvoie vrai en cas de succès, undef sinon.
uc ![]()
![]()
uc EXPR
ucCette fonction renvoie une version en majuscules de EXPR. Il s'agit de la fonction interne implémentant l'échappement \U dans les chaînes entre guillemets. Perl essayera de faire de qu'il faut pour respecter les valeurs actuelles de votre locale, mais nous travaillons toujours sur les interactions avec Unicode. Voir la page de manuel perllocale pour les dernières avancées. Dans tous les cas, lorsque Perl utilise les tables Unicode, uc convertit en majuscules plutôt qu'en capitales de titres. Voir ucfirst pour les conversions en capitales de titres.
ucfirst ![]()
![]()
ucfirst EXPR
ucfirstCette fonction renvoie une version de EXPR avec la première lettre en majuscule (titlecased, mise en capitale de titre dans le jargon Unicode). Il s'agit de la fonction interne implémentant l'échappement \u dans les chaînes entre guillemets. Votre locale LC_CTYPE actuelle peut être respectée si vous faites un use locale et si vos données ne ressemblent pas à de l'Unicode, mais nous ne garantissons rien pour le moment.
Pour forcer la première lettre en capitale et tout le reste en minuscules, utilisez :
ucfirst lc $motce qui est équivalent à "\u\L$mot".
umask ![]()
![]()
umask EXPR
umaskCette fonction fixe le umask (masque utilisateur) du processus et renvoie l'ancien en utilisant l'appel système umask(2). Votre umask indique au système d'exploitation quels bits de permissions désactiver au moment de créer un nouveau fichier, y compris les fichiers qui sont des répertoires. Si EXPR est omise, la fonction se contente de renvoyer le umask courant. Par exemple, pour s'assurer que les bits « utilisateur » sont activés et que les bits « autres » sont désactivés, essayez quelque chose comme :
umask((umask() & 077) | 7); # ne change pas les bits "groupe"Rappelez-vous qu'un umask est un nombre, habituellement donné en octal ; ce n'est pas une chaîne de chiffres octaux. Voir aussi oct, si tout ce que vous avez est une chaîne. Rappelez-vous également que les bits d'umask sont le complément des permissions ordinaires.
Les permissions Unix rwxr-x--- sont représentées comme trois ensembles de trois bits, ou trois chiffres octaux : 0750 (le 0 du début indique un octal et ne compte pas comme un des chiffres). Puisque les bits d'umask sont complémentaires, ils représentent des bits de permissions désactivées. Les valeurs de permission (ou « mode ») que vous fournissez à mkdir ou sysopen sont modifiés par votre umask, ainsi même si vous dites à sysopen de créer un fichier avec les permissions 0777, si votre umask vaut 0022, le fichier est créé avec les permissions 0755. Si votre umask valait 0027 (le groupe ne peut pas écrire, les autres ne peuvent ni lire, ni écrire, ni exécuter), alors passer à sysopen un MASQUE de 0666 créerait un fichier avec un mode de 0640 (puisque 0666 & ~0027 vaut 0640).
Voici quelques conseils : donnez un mode de création valant 0666 pour les fichiers normaux (pour sysopen) et un de 0777 à la fois pour les répertoires (pour mkdir) et pour les fichiers exécutables. Cela donne aux utilisateurs la liberté de choisir : s'ils veulent des fichiers protégés, ils choisiront des umasks de processus de 022, 027 ou même le masque particulièrement antisocial de 077. Les programmes ne doivent que rarement, si ce n'est jamais, prendre des décisions stratégiques qu'il vaut mieux laisser à l'utilisateur. Les exceptions à cette règle sont les programmes qui écrivent des fichiers qui doivent rester privés : fichiers mails, cookies de navigateurs web, fichiers .rhosts, et ainsi de suite.
Si umask(2) n'est pas implémenté sur votre système et que vous essayez de restreindre votre propre accès (c'est-à-dire, si (EXPR & 0700) > 0), vous déclencherez une exception à l'exécution. Si umask(2) n'est pas implémenté sur votre système et que vous n'essayez pas de restreindre votre propre accès, la fonction renverra simplement undef.
undef ![]()
undef EXPR
undefundef est le nom sous lequel nous nous référons à l'abstraction connue sous le nom de la valeur indéfinie. Il se trouve aussi qu'il s'agit d'une fonction bien nommée qui renvoie toujours la valeur indéfinie. Nous mélangeons les deux avec joie.
Par coïncidence, la fonction undef rend explicitement indéfinie une entité si vous passez son nom comme argument. L'argument EXPR, s'il est spécifié, soit être une lvalue. À partir de là, vous ne pouvez utiliser qu'une valeur scalaire, un tableau complet, un hachage complet, un nom de sous-programme (en utilisant le préfixe &) ou un typeglob. Toute la mémoire associée à l'objet sera récupérée (mais pas renvoyée au système, pour la plupart des systèmes d'exploitation). La fonction undef ne fera probablement pas ce que vous attendez d'elle sur la plupart des variables spéciales. L'utiliser sur des variables en lecture seule, comme $1, lève une exception.
La fonction undef est un opérateur unaire, non un opérateur de liste, vous ne pouvez donc rendre indéfini qu'une seule chose à la fois. Voici quelques exemples d'utilisation d'undef en tant qu'opérateur unaire :
undef $bidule;
undef $machin{'truc'}; # Différent de delete $machin{'truc'};
undef @tableau
undef %hachage;
undef &monsp;
undef *xyz # Détruit $xyz, @xyz, %xyz, &xyz, etc.Sans son argument, undef n'est utilisé que pour sa valeur :
select(undef, undef, undef, $sieste);
return (wantarray ? () : undef) if $dans_les_choux;
return if $dans_les_choux; # même choseVous pouvez utiliser undef comme un emplacement dans la partie gauche d'une affectation de liste, auquel cas la valeur correspondante de la partie droite est simplement rejetée. À part cela, vous ne pouvez pas utiliser undef en tant que lvalue.
($a, $b, undef, $c) = &truc; # Ignore la troisième valeur renvoyéeDe plus, n'essayez pas de comparer quoi que ce soit avec undef — ça ne fait pas ce que vous pensez. Tout ce que ça fait, c'est comparer avec 0 ou la chaîne vide. Utilisez la fonction defined pour déterminer si une valeur est définie.
unlink ![]()
![]()
![]()
unlink LISTE
unlinkCette fonction supprime une liste de fichiers.(220) La fonction renvoie le nombre de fichiers effectivement supprimés. Quelques exemples simples :
$cpt = unlink 'a', 'b', 'c';
unlink @partants;
unlink glob("*.orig");La fonction unlink ne supprime pas les répertoires à moins d'être super-utilisateur et que l'option de la ligne de commande -U soit donnée à Perl. Même dans ces conditions, vous êtes prévenus que l'effacement d'un répertoire est susceptible d'infliger des dommages sévères dans votre système de fichiers. Employez plutôt rmdir.
Voici une commande rm très simple avec une vérification d'erreurs qui ne l'est pas moins :
#!/usr/bin/perl
@impossible = grep {not unlink}, @ARGV;
die "$0: unlink de @impossible impossible\n" if @impossible;unpack ![]()
unpack CANEVAS, EXPRCette fonction fait l'inverse de pack : elle développe une chaîne (EXPR) représentant une structure de données et l'éclate selon le CANEVAS en une liste de valeurs qu'elle renvoie. Dans un contexte scalaire, elle peut être employée pour dépaqueter une seule valeur. Le CANEVAS est ici à peu près du même format que pour la fonction pack -il spécifie l'ordre et le type des valeurs à dépaqueter. Voir pack pour une description plus détaillée de CANEVAS. Un élément invalide dans le CANEVAS ou une tentative déplacement à l'extérieur de la chaîne avec les formats x, X ou @, lève une exception.
La chaîne est découpée en morceaux décrits dans le CANEVAS. Chaque morceau est converti séparément en une valeur. Généralement, les octets de la chaîne sont le résultat d'un pack ou ils représentent une structure C d'un certain type.
Si le compteur de répétitions d'un champ est plus grand que ce que le reste dans la chaîne en entrée le permet, le compteur de répétitions est décrémenté en douce. (Normalement, vous devriez de toute façon utiliser un compteur de répétitions valant ici *.) Si la chaîne en entrée est plus grande que ce que décrit le CANEVAS, le reste de la chaîne est ignoré.
La fonction unpack est également très utile pour les données de texte brut, pas seulement pour les données binaires. Supposez que vous ayez un fichier de données qui contiendrait des enregistrements ressemblant à ceci :
2000 Ingrid Caven Jean-Jacques Schuhl
1999 Première ligne Jean-Marie Laclavetine
1998 Confidence pour confidence Paule Constant
1997 La bataille Patrick Rambaud
1996 Le chasseur Zéro Roze Pascale
1995 Le testament français André Makine
1994 Un aller simple Didier Van Cauwelaert
1993 Le rocher de Tanios Amin Maalouf
1992 Texaco Patrick Chamoiseauvous ne pouvez pas utiliser split pour décomposer les champs, car ils n'ont pas de séparateur distinct. À la place, les champs sont déterminés par leur décalage d'octets dans l'enregistrement. Ainsi même s'il s'agit d'un enregistrement de texte ordinaire, puisqu'il est composé dans un format fixe, vous pouvez utiliser unpack pour le décomposer :
while (<>) {
($annee, $titre, $auteur) = unpack("A4 x A26 A*", $_);
print "$auteur a gagné le prix Goncourt $annee pour $titre\n";
}Voici un programme uudecode complet :
#!/usr/bin/perl
$_ = <>
until ($mode,$fichier) = /^begin\s*(\d*)\s*(\S*)/;
open(SORTIE,"> $fichier") if $fichier ne "";
while (<>) {
last if /^end/;
next if /[a-z]/;
next unless int((((ord() - 32) & 077) + 2) / 3) ==
int(length() / 4);
print SORTIE unpack "u", $_;
}
chmod oct $mode, $fichier;En plus des champs autorisés dans pack, vous pouvez préfixer un champ par %nombre pour produire une somme de contrôle des entités sur nombre bits au lieu des entités elles-mêmes. La valeur par défaut est une somme de contrôle de 16 bits. La somme de contrôle est calculée en additionnant les valeurs numériques des valeurs développées (pour les champs de chaînes, on additionne ord($,car) et pour les champs de bits, on additionne les zéros et les uns). Par exemple, ce qui suit calcule le même nombre que le programme sum(1) de System V :
undef $/;
$somme_controle = unpack ("%32C*", <>) % 65536;L'exemple suivant compte de façon efficace le nombre de bits positionnés dans un vecteur de bits :
$bits_a_1 = unpack "%32b*", $masque_de_select;Voici un décodeur simple MIME (BASE 64) :
while (<>) {
tr#A-Za-z0-9+/##cd; # enlever les caractères non-base 64
tr#A-Za-z0-9+/# -_#; # convertir au format uuencodé
$lng = pack("c", 32 + 0.75*length); # calculer l'octet de longueur
print unpack("u", $len . $_); # uudécoder et afficher
}unshift
unshift TABLEAU, LISTECette fonction fait l'inverse de shift. (Ou l'inverse de push, selon le point de vue.) Elle ajoute une LISTE au début du tableau et renvoie le nombre actualisé d'éléments dans le tableau :
unshift @ARGV, '-e', $cmd unless $ARGV[0] =~ /^-/;Remarquez que la LISTE est ajoutée en entier au début, et non un élément à la fois, les éléments ajoutés au début restent donc dans le même ordre. Utilisez reverse pour les inverser.
untie
untie VARIABLEBrise le lien existant entre une variable ou un typeglob contenu dans VARIABLE et le paquetage auquel elle était liée. Voir tie et l'intégralité du chapitre 14, mais tout particulièrement la section Un piège subtil du déliement.
use ![]()
![]()
use MODULE VERSION LISTE
use MODULE VERSION ()
use MODULE VERSION
use MODULE LISTE
use MODULE ()
use MODULE
use VERSIONLa déclaration use charge un module, s'il n'a pas déjà été chargé auparavant, et importe depuis ce module des sous-programmes et des variables dans le paquetage courant. (En langage technique, elle importe depuis le module donné des sémantiques dans votre paquetage.) La plupart des déclarations use ressemblent à :
use MODULE LISTE;Ce qui est exactement équivalent à :
Le BEGIN force le require et le import à se produire au moment de la compilation. Le require s'assure que le module est chargé en mémoire s'il ne l'est pas déjà. L'import n'est pas une fonction interne — c'est simplement un appel ordinaire de méthode dans le package nommé par MODULE pour demander à ce module de mettre la liste des fonctionnalités dans le package courant. Le module peut implémenter sa méthode d'importation de la manière qui lui plaît, bien que la plupart choisissent simplement de dériver leur méthode d'importation par héritage de la classe Exporter qui est définie dans le module Exporter. Voir le chapitre 11, Modules et le module Exporter pour plus d'informations. Si aucune méthode import ne peut être trouvée, l'appel est abandonné sans un mot.
Si vous ne voulez pas altérer votre espace de nom, fournissez explicitement une liste vide :
use MODULE ();Ce qui est exactement équivalent à :
Si le premier argument de use est un numéro de version comme 5.6.2, la version courante de Perl en train de s'exécuter doit être au moins aussi récente que la version spécifiée. Si la version actuelle de Perl est inférieur à VERSION, un message d'erreur est affiché et l'interpréteur Perl se termine immédiatement. Ceci est très utile pour vérifier la version courante de Perl avant de charger des modules de bibliothèque qui dépendent des nouvelles versions, puisque de temps en temps, nous avons besoin de « casser » les mauvaises fonctionnalités des anciennes versions de Perl. (Nous n'essayons pas de casser plus de choses que nécessaire. En fait nous essayons souvent de casser moins de choses que nécessaire.)
Et puisque nous parlons de ne pas casser certaines choses, Perl accepte encore les anciens numéros de versions de la forme :
use 5.005_03;Toutefois, pour mieux s'aligner avec les standards de l'industrie, Perl 5.6 accepte désormais (et nous préférons voir) la syntaxe sous forme d'un triplet :
use 5.6.0; # Soit, version 5, sous-version 6, correctif 0.Si l'argument VERSION est présent après MODULE, alors le use appellera la méthode VER-SION de la classe MODULE avec la VERSION donnée comme argument. Remarquez qu'il n'y a pas de virgule après VERSION ! La méthode VERSION par défaut, qui est héritée de la classe UNIVERSAL, meurt en gémissant si la version donnée est plus élevée que la valeur de la variable $Module::VERSION.
Voir le chapitre 32 pour une liste des modules standards.
Comme use fournit une interface largement ouverte, les pragmas (directives de compilation) sont également implémentés via des modules. Les pragmas actuellement implémentées comprennent :
use autouse 'Carp' => qw(carp croak);
use bytes;
use constant PI => 4 * atan2(1,1);
use diagnostics;
use integer;
use lib '/opt/projets/spectre/lib';
use locale;
use sigtrap qw (die INT QUIT);
use strict qw(subs vars refs);
use warnings "deprecated";La plupart de ces modules pragmatiques importent des définitions dans la portée lexicale courante. (Au contraire des modules ordinaires, qui n'importent des symboles que dans le paquetage courant, qui a un rapport minime avec la portée lexicale courante autre que le fait que la portée lexicale est compilée avec ce paquetage à l'esprit. Ceci pour dire que. . . oh et puis zut, voyez le chapitre 11.)
Il existe une déclaration correspondante, no, qui « désimporte » toutes les significations importées à l'origine avec use qui sont devenues depuis, heu, sans importance :
Voir le chapitre 31 pour une liste des pragmas standards.
utime ![]()
![]()
![]()
utime LISTECette fonction change les dates d'accès et de modification sur chacun des fichiers de la liste. Les deux premiers éléments de la liste doivent être les dates d'accès et de modification en numérique, dans cet ordre. La fonction renvoie le nombre de fichiers changés avec succès. La date de modification d'inode de chaque fichier est fixée à la date courante. Voici un exemple d'une commande touch qui met la date de modification du fichier (en supposant que vous en êtes le propriétaire) à environ un mois dans le futur :
#!/usr/bin/perl
# touch_mois -antidate les fichiers à maintenant + 1 mois
$jour = 24 * 60 * 60; # 24 heures en secondes
$plus_tard = time() + 30 * $jour; # 30 jours, c'est environ un mois
utime $plus_tard, $plus_tard, @ARGV;et voici un exemple un peu plus sophistiqué d'une commande qui fait un touch avec quelques notions de contrôle d'erreurs :
#!/usr/bin/perl
# touch_mois -antidate les fichiers à maintenant + 1 mois
$plus_tard = time() + 30 * 24 * 60 * 60;
@impossibles = grep {not utime $plus_tard, $plus_tard, $_} @ARGV;
die "touch impossible de @impossibles.\n" if @impossibles;Pour lire les dates de fichiers existants, utilisez stat et passez les champs appropriés à localtime ou gmtime pour l'affichage.
values
values HACHAGECette fonction renvoie une liste constituée de toutes les valeurs du HACHAGE indiqué. Les valeurs sont renvoyées dans un ordre apparemment aléatoire, mais c'est le même que celui produit par les fonctions keys ou each pour le même hachage. Curieusement, pour trier un hachage par ses valeurs, vous aurez besoin habituellement de la fonction keys, regardez donc l'exemple dans la description de keys.
Vous pouvez modifier les valeurs d'un hachage en utilisant cette fonction, car la liste renvoyée contient des alias des valeurs et pas simplement des copies. (Dans les versions précédentes, vous aviez besoin d'utiliser pour ce faire une portion de hachage.)
for (@hachage{keys %hachage}) { s/machin/truc/g } # ancienne manière
for (values %hachage) { s/machin/truc/g } # modifie maintenant
# les valeursL'emploi de values sur un hachage lié à un fichier DBM important est voué à produire une liste tout aussi volumineuse, ce qui vous donnera un processus important. Il peut être préférable pour vous d'utiliser dans ce cas la fonction each, qui parcourra les entrées de hachage une à une, sans les absorber en une liste gargantuesque.
vec ![]()
vec EXPR, DECALAGE, BITSLa fonction vec fournit un stockage compact de listes d'entiers non signés. Ces entiers sont empaquetés et compressés autant que possible dans une chaîne Perl ordinaire. La chaîne dans EXPR est traitée comme une chaîne de bits construite à partir d'un nombre arbitraire d'éléments selon la longueur de la chaîne.
DECALAGE spécifie l'indice de l'élément particulier qui vous intéresse. Les syntaxes pour lire et écrire l'élément sont les mêmes, puisque vec stocke la valeur de l'élément selon que vous utilisiez un contexte lvalue ou rvalue.
BITS spécifie l'étendue d'un élément en bits, ce qui doit être exprimé en puissance de 2 : 1, 2, 4, 8, 16 ou 32 (et également 64 sur certaines plates-formes). (Une exception est levée si une quelconque autre valeur est utilisée.) Chaque élément peut ainsi contenir un entier compris dans l'intervalle 0..(2**BITS)-1. Pour les plus petites tailles, on empaquète dans chaque octet autant d'éléments que possible. Lorsque BITS vaut 1, il y a huit éléments par octets. Lorsque BITS vaut 2, il y a quatre éléments par octets. Lorsque BITS vaut 4, il y a deux éléments (habituellement appelés des quartets) par octets. Et ainsi de suite. Les entiers plus grands qu'un octet sont stockés dans l'ordre gros-boutise (N.d.T. : big-endian).
Une liste d'entiers non signés peut être stockée dans une simple variable scalaire en les assignant individuellement à la fonction vec. (Si EXPR n'est pas une lvalue valide, une exception est levée.) Dans l'exemple suivant, les éléments font tous 4 bits de large :
$chaine_bits = "";
$decalage = 0;
foreach $nb (0, 5, 5, 6, 2, 7, 12, 6) {
vec($chaine_bits, $decalage++, 4) = $num;
}Si un élément est écrit après la fin de la chaîne, Perl étendra d'abord la chaîne avec suffisamment d'octets à zéro.
Les vecteurs stockés dans la variable scalaire peuvent par la suite être atteints en spécifiant le DECALAGE correct :
$nb_elements = length($chaine_bits)*2; # 2 éléments par octet
foreach $decalage (0 .. nb_elements-1) {
print vec($chaine_bits, $decalage, 4), "\n";
}Si l'élément sélectionné se situe après la fin de la chaîne, une valeur de 0 est renvoyée.
Les chaînes créées avec vec peuvent également être manipulées avec les opérateurs logiques |, &, ^ et ~. Ces opérateurs postulent qu'une opération de vecteurs de bits est désirée quand les deux opérandes sont des chaînes.Voir des exemples de ceci au chapitre 3, Opérateurs unaires et binaires, dans la section Opérateurs sur les bits.
Si BITS == 1, une chaîne de bits peut être créée pour stocker une série de bits dans un seul scalaire. L'ordre est tel que l'on garantit que vec($chaine_bits,0,1) part du bit le plus faible du premier octet de la chaîne.
@bits = (0,0,1,0, 1,0,1,0, 1,1,0,0, 0,0,1,0);
$chaine_bits = "";
$decalage = 0;
foreach $bit (@bits) {
vec($chaine_bits, $decalage++, 1) = $bit;
}
print "$chaine_bit\n"; # "TC", i.e. '0x54', '0x43'Une chaîne de bits peut être convertie vers ou depuis une chaîne de 1 et de 0 en donnant un canevas de « b* » à pack ou unpack. Dans l'autre sens, pack peut être utilisé avec un canevas de « b* » pour créer la chaîne de bits depuis une chaîne de 1 et de 0. L'ordre est compatible avec celui que vec attend.
chaine_bits = pack "b*", join(", @bits);
print "$chaine_bits\n"; # "TC" comme précédemmentunpack peut être utilisé pour extraire la liste de 0 et de 1 de la chaîne de bits.
@bits = split (//, unpack("b*", $chaine_bits));
print"@bits\n"; # 0 0 1 010 101 1 0 0 0 0 1 0Si vous connaissez la longueur exacte en bits, celle-ci peut être utilisée en lieu et place de « * ».
Voir select pour des exemples supplémentaires d'utilisations de bitmaps générées avec vec. Voir pack et unpack pour des manipulations de données binaires à un niveau supérieur.
wait ![]()
![]()
![]()
waitCette fonction attend qu'un processus fils se termine et renvoie le PID du processus décédé, ou -1 s'il n'y a pas de processus fils (ou sur certains systèmes, si les processus fils sont automatiquement enterrés). Le statut est renvoyé dans $? comme nous l'avons décrit pour la fonction system. Si vous obtenez des processus fils zombies, vous devrez appeler cette fonction, ou waitpid.
S'il n'y a pas de fils, contrairement à votre attente, il s'est probablement produit un appel à system, une fermeture de pipe ou des apostrophes inverses entre le fork et le wait. Ces constructions provoquent également une attente avec wait(2) et peuvent avoir récolté votre processus fils. Utilisez waitpid pour éviter ce problème.
waitpid ![]()
![]()
![]()
waitpid PID, FLAGSCette fonction attend qu'un certain processus fils se termine et renvoie le PID quand le processus est mort, -1 s'il n'y a pas de fils, ou 0 si les FLAGS spécifient un appel non bloquant et que le processus n'est pas encore mort. Le statut du processus mort est renvoyé dans $? comme nous l'avons décrit pour la fonction system. Pour obtenir les valeurs valides des flags, vous devrez importer le tag de groupe d'importation ":sys_wait.h" depuis le module POSIX. Voici un exemple qui réalise une attente non bloquante des processus zombies :
Sur les systèmes qui n'implémentent pas les appels système waitpid(2) et wait4(2), les FLAGS ne peuvent être spécifiés qu'à 0. En d'autres termes, vous pouvez attendre là un PID spécifique, mais vous ne pouvez le faire en mode non bloquant.
Sur certains systèmes, une valeur de retour de -1 peut signifier que les processus fils sont automatiquement enterrés, car vous avez fait $SIG{CHLD} = 'IGNORE'.
wantarray
wantarrayCette fonction renvoie vrai si le contexte du sous-programme actuellement en train de s'exécuter demande une valeur tableau et faux sinon. La fonction renvoie une valeur définie fausse ("") si le contexte appelant demande un scalaire et la valeur indéfinie fausse (undef) si le contexte appelant ne demande rien de particulier, c'est-à-dire s'il s'agit d'un contexte vide.
Voici quelques exemples d'usages typiques :
return unless defined wantarray; # ne se préoccupe pas d'en faire plus
my @a = calcul_complique();
return wantarray ? @a : \@a;Voir également caller. Cette fonction aurait vraiment dû s'appeler « wantlist », mais nous l'avons baptisée alors que les contextes de listes s'appelaient encore contextes de tableaux.
warn ![]()
warn LISTE
warnCette fonction produit un message d'erreur en affichant LISTE sur STDERR exactement comme die, mais sans essayer de sortir ou de lancer une exception. Par exemple :
warn "Débogage actif" if $debug;Si LISTE est vide et que $@ contient déjà une valeur (généralement issue d'un eval précédent), la chaîne "\t...caught" est ajoutée à la fin de $@ sur STDERR. (De manière similaire à celle dont die propage les erreurs, excepté le fait que warn ne propage (lève à nouveau) pas l'exception.) Si la chaîne de message fournie est vide, le message « Warning: Something's wrong »(221) est utilisé.
Si la chaîne de message fournie ne se termine pas par un saut de ligne, les informations concernant le fichier et le numéro de ligne sont automatiquement ajoutées à la fin. La fonction warn n'a aucun rapport avec l'option de la ligne de commande de Perl -w, mais elle peut être utilisée en conjonction avec cette dernière, comme lorsque vous voulez émuler le comportement interne :
warn "Quelque chose de foncièrement mauvais\n" if $^W;Aucun message n'est affiché si un gestionnaire pour $SIG{__WARN__} est installé. Il appartient au gestionnaire d'en décider si le message lui semble approprié. Une chose que vous pourriez vouloir faire est de promouvoir un simple avertissement en exception :
local $SIG{__WARN__} = sub {
my $msg = shift;
die $msg if $msg =~ /n'est pas numérique/;
}La plupart des gestionnaires doivent donc faire prendre leurs dispositions pour afficher les avertissements qu'ils n'ont pas prévu de gérer, en appelant à nouveau warn dans le gestionnaire. Ceci est tout à fait sûr ; il n'y aura pas de boucles sans fin, car les routines __WARN__ ne sont pas appelées depuis des routines __WARN__. Ce comportement diffère un peu de celui des gestionnaires de $SIG{__DIE__} (qui ne suppriment pas le texte d'erreur, mais qui peuvent à la place appeler une nouvelle fois die pour le changer).
L'emploi d'un gestionnaire __WARN__ donne un moyen particulièrement puissant de taire tous les avertissements, même ceux qui sont pourtant qualifiés d'obligatoires. Parfois, vos aurez besoin d'encapsuler cela dans un bloc BEGIN{} pour que ce soit pris en compte dès la compilation :
# nettoie *tous* les avertissements à la compilation
BEGIN { $SIG{__WARN__} = sub { warn $_[0] if $AVERTISSEMENTS_ACTIFS } }
my $truc = 10;
my $truc = 20; # pas d'avertissement à propos des my $truc
# dupliqués, mais, bon, vous l'avez voulu !
# pas d'avertissements à la compilation ou à l'exécution jusqu'ici;
$AVERTISSEMENTS_ACTIFS = 1; # avertissements à l'exécution activés
#à partir d'ici
warn "\$truc est vivant et vaut $truc !"; # dénonce toutVoir le pragma use warnings pour le contrôle de la portée lexicale des avertissements. Voir les fonctions carp et cluck du module Carp pour d'autres moyens de produire des messages d'avertissement.
write ![]()
![]()
![]()
write HANDLE_FICHIER
writeCette fonction écrit un enregistrement formaté (qui peut être multiligne) vers le handle de fichier spécifié, en utilisant le format associé à ce handle de fichier — voir la section Variables de format au chapitre 7. Par défaut, le format d'un fichier est celui qui a le même nom que le handle de fichier. Toutefois, le format d'un handle de fichier peut être modifié en changeant la variable $~ après avoir fait un select sur ce handle :
$ancien_hf = select(HANDLE);
$~ = "NOUVEAU_NOM";
select($ancien_hf);ou en écrivant :
use IO::Handle;
HANDLE->format_name("NOUVEAU_NOM");Puisque les formats sont mis dans l'espace de nom d'un paquetage, il se peut que vous deviez qualifier le nom du format si le format a été déclaré dans un paquetage différent :
$~ = "Autre_Paquetage::NOUVEAU_NOM";Le traitement de l'en-tête de formulaire est automatiquement géré : s'il n'y a plus assez de place sur la page courante pour l'enregistrement formaté, la page est avancée en écrivant un saut de page, un format de haut de page spécial est utilisé pour formater le nouvel en-tête de page, et l'enregistrement est enfin écrit. Le nombre de lignes restant sur la page courante se trouve dans la variable $-, qui peut être mise à 0 pour forcer qu'une nouvelle page soit prise au prochain write. (Vous devrez peut-être selectionner d'abord le handle de fichier.) Par défaut, le nom du format de haut de page est celui du handle de fichier auquel est ajouté « _TOP », mais il peut être modifié en changeant la variable $^ après avoir fait un select sur ce handle ou en écrivant :
use IO::Handle;
HANDLE->format_top_name("NOUVEAU_NOM_TOP");Si HANDLE_FICHIER n'est pas spécifié, ce qui est écrit sort sur le handle de fichier de sortie par défaut, qui est STDOUT au départ, mais peut être changé par la forme à un seul argument de l'opérateur select. Si HANDLE_FICHIER est une expression, celle-ci est évaluée pour déterminer le véritable HANDLE_FICHIER à l'exécution.
Si un format spécifié ou le format de l'en-tête de page courant n'existe pas, une exception est levée.
La fonction write n'est pas l'inverse de read. Utilisez print pour une simple écriture de chaîne. Si vous avez consulté cette entrée parce que vous voulez court-circuiter les entrées/sorties standard, regardez syswrite.
y/// ![]()
y///Il s'agit de l'opérateur de traduction (appelé aussi translation), également connu sous le nom de tr///. Voir le chapitre 5.
30. La bibliothèque standard Perl▲
La distribution standard de Perl contient bien plus que l'exécutable perl qui exécute vos scripts. Elle inclut également des centaines de modules remplis de code réutilisable. Comme les modules standards sont disponibles partout, si vous utilisez l'un d'entre eux dans votre programme, vous pouvez faire tourner votre programme partout où Perl est installé, sans étapes d'installation supplémentaires.
30-1. Bibliothèquologie▲
Avant d'énumérer ces modules dans les prochains chapitres, passons quelque peu en revue la terminologie dans laquelle nous nageons jusqu'au cou.
espace de noms
- Les noms sont conservés dans un espace de noms afin de ne pas les confondre avec des noms identiques dans des espaces différents. Ainsi reste à ne pas confondre les espaces de noms entre eux. Il existe deux manières d'éviter cela : leur donner des noms uniques ou leur attribuer des emplacements uniques. Perl vous laisse faire les deux : les espaces de noms nommés s'appellent des paquetages et les espaces de noms anonymes sont appelés portées lexicales. Puisque les portées lexicales ne peuvent pas s'étendre au-delà d'un fichier et puisque les modules standards sont (au minimum) de la taille d'un fichier, il s'ensuit que toutes les interfaces de modules doivent employer des espaces de noms nommés (des paquetages) si quelqu'un doit les utiliser depuis l'extérieur du fichier.
paquetage
- Un paquetage est un mécanisme standard de Perl pour déclarer un espace de noms nommé. Il s'agit d'un mécanisme très simple pour rassembler des fonctions et des variables qui ont des points communs. Tout comme deux répertoires peuvent contenir tous deux un fichier (différent) s'appelant fred, deux parties d'un programme Perl peuvent, chacune de leur côté, avoir leur propre variable
$fredou leur propre fonction&fred. Même si ces variables ou ces fonctions semblent avoir le même nom, ces noms résident dans des espaces de noms distincts gérés par la déclaration package. Les noms de paquetages sont utilisés pour identifier à la fois des modules et des classes, comme nous l'avons décrit au chapitre 11, Modules et au chapitre 12, Objets.
bibliothèque
- Le terme bibliothèque (library) est malheureusement suremployé dans la culture Perl. De nos jours, nous utilisons normalement le terme pour désigner l'ensemble des modules Perl installés sur votre système.
- Historiquement, une bibliothèque Perl était également un simple fichier contenant une collection de sous-programmes partageant un objectif commun. Un tel fichier est souvent suffixé par .pl, pour « perl library ». Nous employons toujours cette extension pour des morceaux variés de code Perl que vous incorporez avec do FICHIER ou require. Bien qu'il ne s'agisse pas d'un module à part entière, un fichier de bibliothèque se déclare généralement lui-même comme étant dans un paquetage distinct, ainsi les variables et les sous-programmes qu'il contient peuvent être rassemblés et n'interfèrent pas accidentellement avec d'autres variables dans votre programme. Il n'y a pas d'extension de fichier obligatoire ; en outre, on rencontre souvent d'autres .pl comme nous le verrons plus loin dans ce chapitre. Ces fichiers de bibliothèques simples et sans structure ont été largement supplantés par les modules.
module
- Un module Perl est un fichier de bibliothèque conforme à certaines conventions spécifiques qui autorisent un ou plusieurs fichiers implémentant ce module à être rentrés avec une seule déclaration use à la compilation. Les noms de fichier des modules doivent toujours se terminer par .pm, car la déclaration use le présuppose. La déclaration use convertira également le séparateur de paquetage :: vers votre séparateur de répertoire quel qu'il soit afin que la structure des répertoires dans votre bibliothèque Perl puisse refléter la structure de votre paquetage. Le chapitre 11 décrit comment créer vos propres modules Perl.
classe
- Une classe est juste un module qui implémente des méthodes pour les objets associés au nom du paquetage du module. Si les modules orientés objet vous intéressent, voyez le chapitre 12.
pragma
- Un pragma est juste un module spécial qui fait joujou avec les boutons internes de Perl. Voir le chapitre 31, Modules de pragmas.
extension
- Une extension est un module Perl qui, en plus de charger un fichier .pm, charge également une bibliothèque partagée implémentant en C ou en C++ la sémantique du module.
programme
- Un programme Perl est un code conçu pour tourner en tant qu'entité indépendante ; il est également connu sous le nom de script lorsque vous ne voulez pas que quiconque en attende un peu trop, sous le nom d'application lorsqu'il est volumineux et compliqué, sous le nom d'exécutable lorsque celui qui l'appelle ne se soucie pas du langage dans lequel il a été écrit, ou encore sous le nom de solution industrielle lorsqu'il coûte une fortune. Les programmes Perl existent en tant que code source, bytecode ou code machine natif. S'il s'agit de quelque chose que vous pouvez lancer depuis la ligne de commande, nous l'appellerons un programme.
30-2. Visite guidée de la bibliothèque Perl▲
Vous gagnerez énormément de temps si vous faites l'effort de vous familiariser avec la bibliothèque Perl standard, car il n'y a aucune raison de réinventer la roue. Nous devons toutefois vous avertir que cette collection contient un vaste champ de matières premières. Bien que certaines bibliothèques soient extrêmement utiles, d'autres peuvent être sans aucun rapport avec vos besoins. Par exemple, si vous n'écrivez que du code Perl pur à 100 %, les modules qui supportent le chargement dynamique d'extensions C et C++ ne vont pas beaucoup vous aider.
Perl s'attend à trouver les modules de bibliothèque quelque part dans son chemin d'inclusion (N.d.T. :« include ») de bibliothèque, @INC. Ce tableau spécifie la liste ordonnée des répertoires où Perl cherche lorsque vous chargez du code de bibliothèque en utilisant les mots clefs do, require ou use. Vous pouvez facilement afficher la liste de ces répertoires en appelant Perl avec l'option -V, pour Version Vraiment Verbeuse, ou avec ce simple code :
% perl -le "print foreach @INC"
/usr/libdata/perl5/sparc-openbsd/5.00503
/usr/local/libdata/perl5/sparc-openbsd/5.00503
/usr/libdata/perl5
/usr/local/libdata/perl5
/usr/local/libdata/perl5/site_perl/sparc-openbsd
/usr/libdata/perl5/site_perl/sparc-openbsd
/usr/local/libdata/perl5/site_perl
/usr/libdata/perl5/site_perl
.Il ne s'agit que d'un exemple d'affichage possible. Chaque installation de Perl utilise ses propres chemins. Le point important est que, malgré la variation des contenus selon la politique de votre constructeur et de celle de l'installation sur votre site, vous pouvez compter sur toutes les bibliothèques standards qui sont installées avec Perl. Si vous voulez retrouver l'endroit depuis lequel un fichier a été réellement chargé, consultez la variable %INC. Pour un fichier de module, vous pouvez trouver exactement où Perl l'a trouvé avec cette commande :
% perldoc -l MODULESi vous regardez les répertoires de @INC et leurs sous-répertoires, vous trouverez différentes sortes de fichiers installés. La plupart ont des noms se terminant par .pm, mais certains se finissent par .pl, .ph, .al ou .so. Ceux qui vous intéressent le plus sont dans la première catégorie, car un suffixe .pm indique que le fichier est un module Perl authentique. Nous en dirons plus sur ceux-là dans un instant.
Le peu de fichiers que vous verrez là finissant par .pl sont ces vieilles bibliothèques Perl que nous avons mentionnées plus haut. Ils sont inclus pour garder une compatibilité avec d'anciennes versions de Perl datant des années 80 et du début des années 90. Ainsi, le code Perl qui marchait, disons en 1990, doit continuer à bien se comporter sans histoires même si vous avez installé une version moderne de Perl. Lorsque vous êtes en train d'écrire du code nouveau, vous devez toujours préférer, lorsque c'est possible, utiliser la version avec .pm plutôt que celle avec .pl. Ainsi, les modules ne pollueront pas votre espace de noms comme beaucoup des vieux fichiers .pl le font.
Une remarque à propos de l'emploi de l'extension .pl : elle signifie Perl library (bibliothèque Perl), et non pas programme Perl. Bien que l'extension .pl soit utilisée pour identifier les programmes Perl sur les serveurs web qui ont besoin de distinguer, dans le même répertoire, les programmes exécutables des contenus statiques, nous vous suggérons d'employer un suffixe de .plx à la place pour indiquer un programme Perl exécutable. (Le même conseil vaut pour les systèmes d'exploitation qui choisissent les interpréteurs en se basant sur les extensions des noms de fichiers.)
Les fichiers avec des extensions .al sont de petits morceaux de modules plus grands qui sont automatiquement chargés lorsque vous utiliser leur fichier parent .pm. Si vous construisez le plan de votre module en utilisant l'outil standard h2xs qui est fourni avec Perl (et si vous n'avez pas employé le flag Perl -A), la procédure make install utilisera le module Autoloader pour créer pour vous ces petits fichiers .al.
Les fichiers .ph sont construits par le programme h2ph, un outil quelque peu vieillissant, mais parfois toujours utile pour convertir des directives de préprocesseur C vers du Perl. Les fichiers .ph résultants contiennent des constantes parfois nécessaires aux fonctions de bas niveau comme ioctl, fnctl ou syscall. (De nos jours la plupart de ces valeurs sont disponibles, plus facilement et de manière plus portable, dans des modules standards comme POSIX, Errno, Fcntl ou Sockets.) Voir perlinstall pour savoir comment installer ces composants optionnels, mais parfois importants.
La dernière extension que vous pourriez rencontrer en errant ici et là est .so (ou ce que votre système emploie pour les bibliothèques partagées). Ces fichiers .so sont des portions de modules d'extension qui sont dépendantes de la plate-forme. Elles sont écrites en C ou en C++ et il faut les compiler pour obtenir le code objet relogeable dynamiquement. L'utilisateur final n'a de toute façon pas besoin d'être au courant de leur existence, car elles sont masquées par l'interface du module. Lorsque le code de l'utilisateur dit require Module ou use Module, Perl charge Module.pm et l'exécute, ce qui laisse le module attirer à lui toute autre partie nécessaire, comme Module.so ou tous les composants .al autochargés. En fait, le module peut charger tout ce qui lui plaît, y compris 582 autres modules. Il peut télécharger l'intégralité de CPAN s'il le veut et pourquoi pas les archives des deux dernières années de freshmeat.net.
Un module n'est pas simplement un morceau de code statique en Perl. C'est un agent actif qui arrive à comprendre comment implémenter pour vous une interface. Il peut suivre toutes les conventions standards, ou pas. Il lui est permis de tout faire pour pervertir la signification du reste de votre programme, y compris jusqu'à convertir le reste de votre programme en SPITBOL. Ce genre de canular est considéré comme étant parfaitement loyal pour autant qu'il soit bien documenté. Lorsque vous utilisez un tel module Perl, vous acceptez son contrat, non un contrat standard écrit par Perl.
Vous feriez donc mieux de lire les petits caractères de la notice.
31. Modules de pragmas▲
Un pragma est un type particulier de module qui affecte la phase de compilation de votre programme. Certains modules de pragmas (ou pragmata, pour faire court, ou pragmas, pour faire encore plus court) peuvent également affecter la phase d'exécution de votre programme. Voyez-les comme des indications données au compilateur. Comme ils ont besoin d'être visibles à la compilation, ils ne fonctionnent que lorsqu'ils sont invoqués par un use ou un no, car lorsqu'un require ou un do s'exécute, la compilation est finie depuis longtemps.
Par convention, les noms de pragmas sont écrits en minuscules, car les noms de modules en minuscules sont réservés pour la distribution Perl elle-même. Lorsque vous écrivez vos propres modules, utilisez au moins une lettre majuscule pour éviter d'entrer en conflit avec les noms de pragmas.
Au contraire des modules ordinaires, la plupart des pragmas limitent leurs effets au reste du bloc le plus interne encadrant l'endroit d'où ils ont été appelés. En d'autres termes, ils sont limités à une portée lexicale, exactement comme les variables my. Habituellement, la portée lexicale d'un bloc extérieur couvre tout bloc intérieur inclus dans le premier, mais un bloc intérieur peut contredire un pragma de portée lexicale provenant d'un bloc extérieur avec l'instruction no :
use strict;
use integer;
{
no strict 'refs'; # permet les références symboliques
no integer; # reprend l'arithmétique en virgule flottante
# ...
}Plus encore que les autres modules inclus dans la distribution Perl, les pragmas forment une partie intégrale et essentielle de l'environnement de compilation en Perl. Il est difficile de bien utiliser le compilateur si vous ne savez pas comment lui passer des indications, nous produirons donc un effort supplémentaire à décrire les pragmas.
Un autre point auquel il faut prêter attention est le fait que nous utilisons souvent les pragmas pour prototyper des fonctionnalités qui seront plus tard encodées dans une syntaxe « réelle ». Ainsi vous verrez dans quelques programmes des pragmas dépréciés comme use attrs dont la fonctionnalité est maintenant directement supportée par la syntaxe de déclaration des sous-programmes. De même, use vars est en cours de remplacement par les déclarations our. Et use subs peut un jour être remplacé par un attribut override dans les déclarations de sous-programmes ordinaires. Nous ne sommes pas extrêmement pressés de casser les anciennes pratiques, mais nous pensons assurément que les nouvelles pratiques sont plus jolies.
31-1. use attributes▲
sub une_fonct : method;
my $fermeture = sub : method { };
use attributes;
@liste_attrs = attributes::get(\&une_fonct);Le pragma attributes a deux objectifs. Le premier est de fournir un mécanisme interne pour déclarer des listes d'attributs, qui sont des propriétés optionnelles associées aux déclarations de sous-programmes et (dans un futur proche) aux déclarations de variables. (Puisqu'il s'agit d'un mécanisme interne, vous ne devriez pas en général utiliser ce pragma directement.) Le second objectif est de fournir un moyen de récupérer ces listes d'attributs à l'exécution en appelant la fonction attribute::get. Dans cette fonctionnalité, attributes est juste un module standard et non un pragma.
Perl ne gère actuellement qu'un petit nombre d'attributs en interne. Les attributs spécifiques à un paquetage sont autorisés par le biais d'un mécanisme d'extension expérimental décrit dans la section Package-specific Attribute Handling (N.d.T. : gestion d'attributs spécifiques à un paquetage) de la page de man attributes(3).
Le positionnement des attributs intervient à la compilation ; la tentative de positionner un attribut inconnu provoque une erreur de compilation. (L'erreur peut être interceptée avec eval, mais elle continuera d'arrêter la compilation à l'intérieur du bloc eval.)
Il n'existe actuellement que trois attributs internes implémentés pour les sous-programmes : locked, method et lvalue. Voir le chapitre 6, Sous-programmes et le chapitre 7, Threads, pour une discussion approfondie sur ces attributs. Il n'existe pas actuellement d'attributs internes pour les variables comme il y en a pour les sous-programmes, mais nous en avons plusieurs en tête que nous aimons bien, comme constant.
Le pragma attributes fournit deux sous-programmes pour un usage générique. Ils peuvent être importés si vous les demandez :
get
- Cette fonction renvoie une liste (qui peut être vide) des attributs lorsqu'on lui donne un seul paramètre en entrée, lequel est une référence à un sous-programme ou à une variable. La fonction lève une exception en invoquant Carp::croak si on lui passe des arguments invalides.
reftype
- Cette fonction se comporte plus ou moins comme la fonction interne,
refmais elle renvoie toujours le type de donnée sous-jacent intrinsèque à Perl ou la valeur référencée, en ignorant tout paquetage dans lequel elle pourrait avoir été consacrée.
Des détails plus précis sur la gestion des attributs sont toujours en cours de discussion, vous feriez donc mieux de consulter la documentation en ligne de votre distribution de Perl pour savoir quel est l'état en cours.
31-2. use autouse▲
use autouse 'Carp' => qw(carp croak);
carp "Cet appel à carp a été prédéclaré avec autouse\n";Ce pragma fournit un mécanisme pour une demande de chargement à l'exécution d'un module particulier si et seulement si une fonction de ce module est réellement appelée. Il accomplit ceci en donnant une souche (stub) de fonction qui est remplacée par l'appel réel lorsqu'on la déclenche. Dans l'esprit, ce mécanisme est similaire au comportement des modules standards AutoLoader et SelfLoader. Pour faire court, c'est une astuce de performance qui facilite le démarrage plus rapide (en moyenne) de votre programme Perl en évitant la compilation de modules qui pourraient ne jamais être appelés durant une exécution donnée du programme.
Le comportement de autouse est lié au fait que le module soit déjà chargé ou non. Par exemple, si le module Module est déjà chargé, alors la déclaration :
use autouse 'Module' => qw(fonc1 fonc2($;$) Module::fonc3);est équivalente à la simple importation de deux fonctions :
use Module qw(fonc1 fonc2);Cela suppose que Module définisse fonc2 avec le prototype ($;$) et que fonc1() et fonc3() n'aient pas de prototype. (Plus généralement, cela suppose également que Module utilise la méthode import du module standard Exporter; sinon, une exception est levée.) Dans tous les cas, la déclaration Module::fonc3 est ignorée puisqu'elle est certainement déjà déclarée.
Si, d'un autre côté, Module n'a pas encore été chargé lorsque le pragma autouse est analysé, ce dernier déclare les fonctions fonc1 et fonc2 dans le paquetage courant. Il déclare également une fonction Module::fonc3 (ce que l'on pourrait analyser comme étant légèrement antisocial, si ce n'est que l'absence du module Module aurait des conséquences encore plus antisociales). Lorsque ces fonctions sont appelées, elles s'assurent que le Module en question est chargé et elles sont alors remplacées par les appels aux fonctions réelles qui viennent d'être chargées.
Puisque le pragma autouse déplace des portions de votre programme depuis la compilation vers l'exécution, cela peut avoir des ramifications déplaisantes. Par exemple, si le module sur lequel vous avez appliqué autouse possède une phase d'initialisation qui s'attend à être passée au plus tôt, celle-ci pourra ne pas arriver assez tôt. L'emploi de autouse peut également masquer des bogues dans votre code lorsque d'importantes vérifications sont déplacées de la compilation vers l'exécution.
En particulier, si le prototype que vous avez spécifié dans la ligne autouse est faux, vous ne le découvrirez pas avant que la fonction correspondante soit exécutée (ce qui peut se produire des mois ou des années plus tard, pour une fonction rarement appelée). Pour résoudre partiellement ce problème, vous pouvez écrire votre code ainsi durant votre phase de développement :
use Chasse;
use autouse Chasse => qw(tolle($) clameur($&));
clameur "Cette clameur a été prédéclarée avec autouse\n";La première ligne s'assure que les erreurs dans votre spécification des arguments soient trouvées assez tôt. Lorsque votre programme passe de la phase de développement à la phase de production, vous pouvez mettre en commentaire le chargement ordinaire du module Chasse et laisser seulement l'appel à autouse. De cette manière, vous obtenez de la sécurité pendant le développement et des performances durant la production.
31-3. use base▲
Ce pragma permet à un programmeur de déclarer aisément une classe dérivée basée sur les classes parentes listées. La déclaration ci-dessus est à peu près équivalente à :
Le pragma use base s'occupe de chaque require nécessaire. Lorsque vous êtes dans la portée du pragma strict 'vars', use base vous laisse faire (effectivement) un assigne-ment de @ISA sans avoir à déclarer d'abord our @ISA. (Puisque le pragma use base intervient lors de la compilation, il vaut mieux éviter de titiller @ISA dans votre coin lors de l'exécution.)
Mais au-delà de ceci, use base possède une autre propriété. Si l'une des classes de base nommées utilise les facilités de use fields décrites plus loin dans ce chapitre, alors le pragma initialise les attributs spéciaux de champs du paquetage depuis la classe de base. (L'héritage multiple des classes de champs n'est pas supporté. Le pragma use base lève une exception si plus d'une des classes de base nommées possède des champs.)
Toute classe de base qui n'a pas encore été chargée l'est automatiquement via require. Toutefois, le fait que l'on doive ou non charger un paquetage d'une classe de base avec require est déterminé, non pas par l'inspection habituelle de %INC, mais par l'absence d'une variable globale $VERSION dans le paquetage de base. Cette astuce évite à Perl d'essayer en boucle (et d'échouer) de charger une classe de base qui ne se trouve pas dans le fichier que l'on appelle par require (car, par exemple, elle est chargée en tant que faisant partie du fichier d'un autre module). Si $VERSION n'est pas détectée après avoir réussi à charger le fichier, use base définira $VERSION dans le paquetage de base, en la positionnant à la chaîne « -1, defined by base.pm».
31-4. use blib▲
Depuis la ligne de commande :
% perl -Mblib programme [args...]
% perl -Mblib=REP programme [args...]Depuis votre programme Perl :
Ce pragma est en premier lieu un moyen de tester arbitrairement les programmes Perl pour découvrir une version non installée d'un paquetage grâce à l'option de la ligne de commande de Perl -M. Il suppose que la structure de vos répertoires a été produite par le module standard ExtUtils::MakeMaker.
Le pragma cherche une structure de répertoire blib commençant depuis un répertoire nommé REP (ou le répertoire courant si l'on n'en a spécifié aucun) et s'il n'y trouve pas de répertoire blib, il revient en arrière à travers vos répertoires « .. », en remontant jusqu'au cinquième niveau dans les répertoires parents.
31-5. use bytes▲
Le pragma use bytes désactive la sémantique des caractères pour le reste de la portée lexicale dans lequel il apparaît. Le pragma no bytes peut être employé pour inverser les effets de use bytes à l'intérieur de la portée lexicale courante.
Perl présume normalement une sémantique de caractères en présence d'une donnée sous forme de caractères (c'est-à-dire, une donnée notée comme étant dans un encodage de caractère particulier).
Pour comprendre les implications et les différences entre les sémantiques de caractères et les sémantiques d'octets, voir le chapitre 15, Unicode. Une visite à Tokyo peut également être utile.
31-6. use charnames▲
use charnames COMMENT;
print "\N{SPEC_CAR} est un drôle de caractère";Ce pragma de portée lexicale permet aux caractères nommés d'être interpolés vers des chaînes en utilisant la notation \N{SPEC_CAR} :
use charnames ':full';
print "\N{GREEK SMALL LETTER SIGMA} est appelée sigma.\n";
use charnames ':short';
print "\N{greek:Sigma} est appelée sigma.\n";
use charnames qw(cyrillic greek); print "\N{sigma} est sigma en grec et \N{be} est b en cyrillique.\n";Le pragma supporte les valeurs :full et :short pour le paramètre COMMENT, ainsi que des noms de scripts spécifiques.(222) L'argument COMMENT détermine comment rechercher le caractère spécifié par SPEC_CAR dans \N{SPEC_CAR}. Si :full est présent, SPEC_CAR est d'abord cherché dans les tables de caractères Unicode en tant que nom complet de caractère Unicode. Si :short est présent et que SPEC_CAR est de la forme NOM_SCRIPT:NOM_CAR, NOM_CAR est recherché en tant que lettre dans le script NOM_SCRIPT. Si COMMENT contient des noms de scripts spécifiques, SPEC_CAR est recherché en tant que NOM_CAR dans chacun des scripts donnés et dans l'ordre spécifié.
Pour la recherche de NOM_CAR dans un script NOM_SCRIPT donné, le pragma regarde dans la table des noms standards Unicode s'il peut trouver des motifs ayant la forme de :
NOM_SCRIPT CAPITAL LETTER NOM_CAR
NOM_SCRIPT SMALL LETTER NOM_CAR
NOM_SCRIPT LETTER NOM_CARSi NOM_CAR est entièrement en minuscules (comme dans \N{sigma}), la variante CAPITAL est ignorée.
Vous pouvez écrire votre propre module fonctionnant comme le pragma, charnames mais définissant différemment les noms de caractères. Toutefois, l'interface pour cela est toujours expérimentale, consultez donc son état courant dans la page de man.
31-7. use constant▲
use constant TAILLE_TAMPON => 4096;
use constant UNE_ANNEE => 365.2425 * 24 * 60 * 60;
use constant PI => 4 * atan2 1, 1;
use constant DEBOGAGE => 0;
use constant ORACLE => 'oracle@cs.indiana.edu';
use constant NOM_UTILISATEUR => scalar getpwuid($<);
use constant INFOS_UTILISATEUR => getpwuid($<);
sub deg_rad { PI * $_[0] / 180 }
print "Cette ligne ne fait rien" unless DEBOGAGE;
# Les références peuvent être déclarées en tant que constantes
use constant C_HACHAGE => { truc => 42 };
use constant C_TABLEAU => [ 1,2,3,4 ];
use constant C_PSEUDO_HACH => [ { truc => 1 }, 42];
use constant C_CODE => sub { "mord $_[0]\n" };
print C_HACHAGE->{truc};
print C_TABLEAU->{$i];
print C_PSEUDO_HACH->{truc};
print C_CODE->{"moi"};
print C_HACHAGE->[10]; # erreur à la compilationCe pragma déclare le symbole nommé comme étant une constante immuable(223) avec la valeur scalaire ou de liste donnée. Vous devez faire une déclaration séparée pour chaque symbole. Les valeurs sont évaluées dans un contexte de liste. Vous pouvez outrepasser cela avec scalar comme nous l'avons fait ci-dessus.
Puisque les constantes ne commencent pas par un $, vous ne pouvez pas les interpoler directement dans les chaînes entre guillemets, bien que ce soit possible indirectement :
print "La valeur de PI est @{[ PI ]}.\n";Comme les constantes de liste sont renvoyées en tant que listes, et non en tant que tableaux, vous devez indicer une constante représentant une valeur de liste en utilisant des parenthèses supplémentaires comme vous le feriez avec toute autre expression de liste :
$rep_maison = INFO_UTILISATEUR[7]; # FAUX
$rep_maison = (INFO_UTILISATEUR)[7]; # OKBien que l'on recommande d'écrire les constantes entièrement en majuscules pour les faire ressortir et pour aider à éviter les collisions potentielles avec d'autres mots-clefs et noms de sous-programmes, il ne s'agit que d'une convention. Les noms de constantes doivent commencer par une lettre, mais celle-ci n'a pas besoin d'être en majuscule.
Les constantes ne sont pas privées dans la portée lexicale dans laquelle elles apparaissent. Elles sont plutôt de simples sous-programmes sans argument dans la table de symboles du paquetage où a lieu la déclaration. Vous pouvez vous référer à une constante CONST depuis un paquetage Autre en écrivant Autre::CONST. Approfondissez la notion d'insertion en ligne (N.d.T. : inlining) de tels sous-programmes à la compilation en lisant la section Substitution en ligne de fonctions constantes au chapitre 6.
Comme dans toutes les directives use, use constant intervient à la compilation. Ainsi, placer une déclaration de constante à l'intérieur d'une instruction conditionnelle comme if ($truc) { use constant ... } est une incompréhension totale.
Si l'on omet la valeur pour un symbole, ce dernier prendra la valeur undef dans un contexte scalaire ou la liste vide dans un contexte de liste. Mais il vaut probablement mieux déclarer ceux-ci explicitement :
31-7-a. Restrictions de use constant▲
Les listes constantes ne sont pas actuellement insérées en ligne de la même manière que les scalaires. Et il n'est pas possible d'avoir un sous-programme ou un mot clef du même nom qu'une constante. C'est probablement une Bonne Chose.
Vous ne pouvez pas déclarer plus d'une constante nommée à la fois :
Ceci définit une constante nommée TRUC qui renvoie une liste (4, "MACHIN", 5). Vous devez plutôt écrire :
Vous allez au-devant des problèmes si vous utilisez une constante dans un contexte qui met automatiquement les mots bruts entre guillemets. (Ceci est vrai pour tout appel de sous-programme, pas seulement pour les constantes.) Par exemple vous ne pouvez pas écrire, $hachage{CONSTANTE} car CONSTANTE serait interprétée comme une chaîne. Utilisez $hachage{CONSTANTE()} ou $hachage{+CONSTANTE} pour empêcher le mécanisme de mise entre guillemets de se mettre en branle. De même, puisque l'opérateur => met entre guillemets son opérande de gauche si cette dernière est un nom brut, vous devez écrire CONSTANTE() => 'valeur' au lieu de CONSTANTE => 'valeur'.
Un jour, vous serez capables d'utiliser un attribut constant dans les déclarations de variables :
Ceci possède tous les avantages d'être une variable plutôt qu'un sous-programme, mais tous les inconvénients de ne pas être encore implémenté.
31-8. use diagnostics▲
use diagnostics; # activé à la compilation
use diagnostics -verbose;
enable diagnostics; # activé à l'exécution
disable diagnostics; # désactivé à l'exécutionCe pragma étend les diagnostics ordinaires, laconiques et supprime les avertissements dupliqués. Il augmente les versions abrégées avec les descriptions plus explicites et plus agréables que l'on peut trouver au chapitre 33, Messages de diagnostic. Comme les autres pragmas, celui-ci affecte également la phase de compilation de votre programme, pas seulement la phase d'exécution.
Lorsque vous utilisez use diagnostics au début de votre programme, l'option Perl -w de la ligne de commande est automatiquement activée en mettant $^W à 1. La suite de votre entière compilation sera alors sujette à des diagnostics améliorés. Ces derniers sont toujours envoyés vers STDERR.
En raison des interactions entre les résultats d'exécution et de compilation, et parce que ce n'est souvent pas une très bonne idée, vous ne devriez pas utiliser no diagnostics pour désactiver les diagnostics à la compilation. Vous pouvez néanmoins contrôler leur comportement à l'exécution en utilisant les méthodes enable et disable, pour respectivement les activer et les désactiver. (Assurez-vous d'avoir d'abord fait le use ou sinon vous serez incapables d'accéder aux méthodes.)
Le flag -verbose affiche d'abord l'introduction de la page man de perldiag avant tout autre diagnostic. La variable $diagnostics::PRETTY peut être positionnée (avant le use) pour générer de meilleures séquences d'échappement pour les pagineurs comme less(1) ou more(1) :
Les avertissements envoyés par Perl et détectés par ce pragma ne sont affichés qu'une seule fois chacun. Ceci est utile lorsque vous êtes pris dans une boucle qui génère encore et toujours le même avertissement (comme une valeur non initialisée). Les avertissements générés manuellement, comme ceux découlant des appels à warn ou carp, ne sont pas affectés par ce mécanisme de détection des duplications.
Voici quelques exemples d'utilisation du pragma diagnostics. Le fichier suivant déclenche à coup sûr quelques erreurs tant à la compilation qu'à l'exécution :
use diagnostics;
print NULLE_PART "rien\n";
print STDERR "\n\nCe message devrait rester tel quel.\n";
warn "\tAvertissement utilisateur";
print "\nTESTEUR DE DIAGNOSTIC : Entrez un <RETOUR_CHARIOT> ici : ";
my $a, $b = scalar <STDIN>;
print "\n";
print $x/$y;ce qui affiche :
Parenthesis missing around "my" list at diagtest line 6 (#1)
(W parenthesis) You said something like
my $foo, $bar = @_;
when you meant
my ($foo, $bar) = @_;
Remember that "my", "our", and "local" bind tighter than comma.
Name "main::NULLE_PART" used only once: possible typo at diagtest line 2 (#2)
(W once) Typographical errors often show up as unique variable
names. If you had a good reason for having a unique name,
then just mention it again somehow to suppress the message.
The our declaration is provided for this purpose.
Name "main::b" used only once: possible typo at diagtest line 6 (#2) Name "main::x" used only once: possible typo at diagtest line 8 (#2) Name "main::y" used only once: possible typo at diagtest line 8 (#2)
Filehandle main::NULLE_PART never opened at diagtest line 2 (#3)
(W unopened) An I/O operation was attempted on a filehandle that
was never initialized. You need to do an open() or a socket()
call, or call a constructor from the FileHandle package.
Ce message devrait rester tel quel.
Avertissement utilisateur at diagtest line 4.
TESTEUR DE DIAGNOSTIC : Entrez un <RETOUR_CHARIOT> ICI : Use of uninitialized value in division (/) at diagtest line 8 (#4)
(W uninitialized) An undefined value was used as if it were
already defined. It was interpreted as a "" or a 0, but maybe
it was a mistake. To suppress this warning assign a defined
value to your variables.
Illegal division by zero at diagtest line 8 (#5)
(F) You tried to divide a number by 0. Either something was
wrong in your logic, or you need to put a conditional in to
guard against meaningless input.
Uncaught exception from user code:
Illegal division by zero at diagtest line 8.Les messages de diagnostic sont tirés du fichier perldiag.pod. Si un gestionnaire $SIG{__WARN__} existant est détecté, il sera toujours respecté, mais seulement après que la fonction diagnostics::splainthis (l'intercepteur de $SIG{__WARN__} pour le pragma) aura fait son travail pour vos avertissements. Perl ne supporte pas à l'heure actuelle les empilements de gestionnaires, c'est donc le mieux que nous puissions faire pour l'instant. Il existe une variable $diagnostics::DEBUG que vous pouvez positionner si vous êtes d'incurables curieux à propos des genres de choses qui sont interceptées.
31-9. use fields▲
Dans le module Animal :
package Animal;
use strict;
use fields qw(nom poids _Animal_id);
my $ID = 0;
sub new {
my Animal $obj = shift;
unless (ref $obj) {
$obj = fields::new($obj);
$obj->{_Animal_id} = "ceci est l'ID secret de l'Animal";
}
$obj->{nom} = "Hé, toi !";
$obj->{poids} = 20;
return $obj;
}
1;Dans un programme séparé, demo_animal :
use Animal;
my Animal $rock = new Animal; # lexicalement typé
$rock->{nom} = "quartz";
$rock->{poids} = "2kg";
$rock->{_Animal_id} = 1233; # attribut privé
$rock->{couleur} = "bleu"; # génère une erreur de compilationDans le module Chien :
package Chien;
use strict;
use base 'Animal'; # hérite les champs et méthodes d'Animal
use fields qw(nom pedigree); # surcharge l'attribut nom d'Animal
# et ajoute un nouvel attribut pedigree
use fields qw(remue _Chien_prive) # non-partagé avec Animal
sub new {
my $classe = shift;
my $obj = fields::new{$classe};
$obj_>SUPER::new(); # initialise les champs de base
$obj->{pedigree} = "aucun"; # initialise ses propres champs
return $obj;
}Dans un programme séparé, demo_chien :
use Chien;
my Chien $medor = new Chien # lexicalement typé
$medor->{nom} = "Theloneus" # non-hérité
$medor->{poids} = "30lbs"; # hérité
$medor->{pedigree} = "bâtard"; # non-hérité
$medor->{couleur} = 'brun'; # génère une erreur de compilation
$medor->{_Animal_pid} = 3324; # génère une erreur de compilationLe pragma fields fournit une méthode pour déclarer les champs de classe dont le type peut être vérifié à la compilation. Ceci repose sur une fonctionnalité connue sous le nom de pseudohachages : si une variable lexicale typée (my Animal $rock) contient une référence (l'objet Animal) et est utilisée pour accéder à un élément de hachage ($rock>{nom}), s'il existe un paquetage du même nom que le type déclaré, et si ce paquetage a positionné des champs de classe en utilisant le pragma fields, alors l'opération se change en accès à un tableau lors de la compilation, pourvu que le champ spécifié soit valide.
Le pragma base apparenté combinera les champs des classes de base et ceux déclarés avec le pragma fields. Ceci rend permet à l'héritage de champ de bien fonctionner.
Les noms de champ qui commencent par un caractère souligné sont rendus privés pour la classe et invisibles dans les sous-classes. Les champs hérités peuvent être surchargés, mais généreront un avertissement si les avertissements sont activés.
La conséquence de tout ceci est que vous pouvez avoir des objets avec des champs nommés qui soient aussi compacts que des tableaux avec un accès aussi rapide. Cependant, ceci ne fonctionne que tant que l'on accède aux objets à travers des variables convenablement typées. Si les variables ne sont pas typées, l'accès est uniquement vérifié à l'exécution, votre programme tourne donc plus lentement, car il doit accéder à la fois à un hachage et à un tableau. En plus des déclarations de champs, les fonctions suivantes sont supportées :
new
- La fonction fields::new crée et consacre un pseudohachage dans la classe spécifiée (qui peut également être spécifiée en passant un objet de cette classe). L'objet est créé avec les champs déclarés auparavant pour cette classe avec le pragma fields. Ceci autorise l'écriture d'un constructeur comme ceci :
package Creature::Sons;
use fields qw(chat chien oiseau);
sub new {
my Creature:Sons $obj = shift;
$obj = fields::new($obj) unless ref $obj;
$obj->{chat} = 'miaule'; # élément scalaire
@$obj{'chien', 'oiseau'} = ('aboie','siffle'); # tranche
return $obj;
}phash
- La fonction fields::phash crée et initialise un pseudohachage brut (non consacré). Vous devriez toujours utiliser cette fonction pour créer des pseudohachages au lieu de le faire directement, au cas où nous décidions de changer l'implémentation.
Si le premier argument de phash est une référence à un tableau, le pseudohachage sera créé avec des clefs provenant de ce tableau. Si le second argument est fourni, ce doit être également une référence à un tableau dont les éléments seront utilisés comme valeurs. Si le second tableau contient moins d'éléments que le premier, les éléments restants du pseudohachage ne seront pas initialisés. Ceci est particulièrement utile pour créer un pseudohachage à partir des arguments d'un sous-programme :
Vous pouvez aussi passer une liste de paires clef/valeur qui sera utilisée pour construire le pseudohachage :
my $option = fields::phash(nom => "Joe",
grade => "capitaine",
matricule => 42);
my $pseudo_hachage = fields::phash(%args);Pour plus d'information sur les pseudohachages, voir la section « Pseudohachages » au chapitre 8, Références.
L'implémentation actuelle conserve les champs déclarés dans le hachage %FIELDS du paquetage appelant, mais cela peut changer dans les prochaines versions, il vaut donc mieux vous fier à l'interface de ce pragma pour gérer vos champs.
31-10. use filetest▲
$lecture_peut_etre_possible = -r "fichier" # utilise les bits de mode
{
use filetest 'access';
$lecture_vraiment_possible = -r "fichier" # dépiste plus sérieusement
}
$lecture_peut_etre_possible = -r "fichier"; # utilise à nouveau les
#bits de modeCe pragma de portée lexicale indique au compilateur de changer le comportement des opérateurs unaires de test de fichier -r, -w, -x, -R, -W et -X, documentés au chapitre 3, Opérateurs unaires et binaires. Le comportement par défaut de ces tests de fichiers est d'utiliser les bits de mode renvoyés par les appels de la famille de stat. Toutefois, ce n'est peut-être pas toujours la façon correcte de faire, comme lorsqu'un système de fichiers comprend les ACL (Access Control Lists, listes de contrôle d'accès). Dans les environnements où cela compte, comme AFS, le pragma use filetest peut aider les opérateurs de permissions à renvoyer des résultats plus cohérents avec d'autres outils.
Il peut y avoir une légère baisse de performance pour les opérateurs de test de fichier affectés lorsqu'on les utilise avec use filetest, car sur certains systèmes les fonctionnalités étendues ont besoin d'être émulées.
Attention : toute notion d'utilisation de tests de fichiers dans des objectifs de sécurité est une cause perdue d'avance. La porte est grande ouverte pour des situations de concurrence (race conditions), car il n'y a aucun moyen de garantir que les permissions ne changeront pas entre le test et l'opération effective. Si vous êtes ne serait-ce qu'un peu sérieux avec la sécurité, vous n'utiliserez pas d'opérateurs de test de fichier pour décider si quelque chose va marcher ou pas. À la place, essayez de lancer l'opération réelle puis testez si l'opération a réussi ou non. (Vous devriez de toute façon faire cela.) Voir la section Gestion des problèmes de synchronisation au chapitre 23, Sécurité.
31-10-a. use filetest 'access'▲
Actuellement une seule importation, access, est implémentée. L'appel de use file-test 'access' active l'emploi d'access(2) ou d'appels systèmes équivalents lorsqu'on lance des tests de fichier ; symétriquement, no filetest 'access' le désactive. Cette fonctionnalité étendue de test de fichier n'est utilisée que lorsque l'opérande de l'opérateur (ou, si vous préférez, l'argument de la fonction unaire) est un véritable nom de fichier, et non un handle de fichier.
31-11. use integer▲
use integer;
$x=10 / 3;
# $x vaut maintenant 3, et non 3.33333333333333333Ce pragma de portée lexicale indique au compilateur d'utiliser des opérations entières à partir de ce point et jusqu'à la fin du bloc l'encadrant. Sur la plupart des machines, cela influence peu la majorité des calculs, mais sur celles qui ne disposent pas de coprocesseur arithmétique, cela peut entraîner une différence de performance dramatique.
Remarquez que ce pragma affecte certaines opérations numériques, pas les nombres eux-mêmes. Par exemple, si vous lancez ce code :
use integer;
$x = 1.8;
$y=$x + 1;
$z = -1.8;vous vous retrouverez avec $x == 1.8, $y== 2 et $z == -1. Le cas de $z s'explique par le fait qu'un - unaire compte comme une opération, ainsi la valeur 1.8 est tronquée à un avant que son bit de signe soit inversé. De même, les fonctions qui attendent des nombres à virgule flottante, comme sqrt ou les fonctions trigonométriques, recevront et renverront toujours des nombres à virgule même sous use integer. Ainsi sqrt(1.44) vaut 1.2 mais 0 + sqrt(1.44) vaut maintenant seulement 1.
L'arithmétique entière native, telle qu'elle est fournie par votre compilateur C, est utilisée. Cela signifie que la propre sémantique de Perl pour les opérations arithmétiques peut ne pas être préservée. Une source d'ennuis fréquente est le modulo des nombres négatifs. Perl le calcule d'une façon, mais votre matériel peut le faire d'une autre manière :
% perl -le 'print (4 % -3)'
-2
% perl -Minteger -le 'print (4 % -3)'
131-12. use less▲
use less; # AUCUN N'EST IMPLÉMENTÉ
use less 'CPU';
use less 'memory';
use less 'time';
use less 'disk';
use less 'fat'; # géant avec "use locale";Actuellement non implémenté, ce pragma est destiné à donner un jour des indications au compilateur, au générateur de code ou à l'interpréteur pour activer certains équilibrages.
Il n'y a aucun mal à demander à utiliser moins (use less) de quelque chose alors que Perl ne sait pas comment réduire ce quelque chose à l'heure actuelle.
31-13. use lib▲
Ce pragma simplifie la manipulation de @INC à la compilation. Il est généralement utilisé pour ajouter des répertoires supplémentaires dans le chemin de recherche de Perl pour qu'ensuite les instructions do, require et use trouvent les fichiers de bibliothèque qui ne se situent pas dans le chemin de recherche par défaut de Perl. Il est particulièrement important avec use, puisque ce dernier intervient également à la compilation et que l'affectation ordinaire de @INC (c'est-à-dire à l'exécution) arriverait trop tard.
Les paramètres de use lib sont ajoutés au début du chemin de recherche de Perl. Écrire use lib LISTE revient à peu près au même qu'écrire BEGIN { unshift(@INC, LISTE)}, mais use libLISTE inclut le support des répertoires spécifiques à une plate-forme. Pour chaque répertoire $rep donné dans sa liste d'arguments, le pragma list vérifie également si un répertoire nommé $rep/$nom_architecture/auto existe ou non. Si c'est le cas, le répertoire $rep/$nom_architecture/auto est supposé correspondre à un répertoire spécifique à la plate-forme et il est donc ajouté à @INC (devant $rep).
Pour éviter les ajouts redondants qui ralentissent les temps d'accès et gaspillent une petite quantité de mémoire, les entrées dupliquées qui restent dans @INC sont supprimées lorsque des entrées sont ajoutées.
Normalement, vous ne devez qu'ajouter des répertoires dans @INC. Si vous avez vraiment besoin d'enlever des répertoires de @INC, prenez garde à ne supprimer que ceux que vous avez vous-même ajoutés ou ceux dont vous êtes certains qu'ils ne sont pas nécessaires à d'autres modules dans votre programme. D'autres modules peuvent avoir ajouté dans votre tableau @INC des répertoires dont ils avaient besoin pour que leurs opérations soient correctement effectuées.
Le pragma no lib supprime de @INC toutes les instances de chaque répertoire nommé. Il détruit également tous les répertoires correspondants spécifiques à la plate-forme, tels que nous les avons décrits plus haut.
Lorsque le pragma lib est chargé, il sauvegarde la valeur courante de @INC dans le tableau @lib::ORIG_INC, afin de copier ce tableau dans le véritable @INC pour restaurer la valeur originale.
Même si @INC inclut généralement le répertoire courant, point (« . »), Ce n'est vraiment pas aussi utile que vous pouvez le penser. Premièrement, l'entrée point vient à la fin, pas au début. Ainsi les modules installés dans le répertoire courant ne prennent pas soudainement le dessus sur les versions globales au système. Vous pouvez écrire use lib "." si c'est ce que vous voulez vraiment. Plus ennuyeux, il s'agit du répertoire courant du processus Perl, et non du répertoire où le script a été installé, ce qui enlève toute fiabilité à cet ajout de « . ». Si vous créez un programme, plus quelques modules utilisés par ce programme, il marchera tant que vous développez, mais cela cessera lorsque vous ne le lancerez pas depuis le répertoire où se trouvent les fichiers.
Une solution pour cela est d'utiliser le module standard FindBin :
use FindBin; # où le script a-t-il été installé ?
use lib $FindBin::Bin; # utilise également ce répertoire pour libLe module FindBin essaie de deviner le chemin complet vers le répertoire où a été installé le programme du processus en train de tourner. N'utilisez pas ceci dans des objectifs de sécurité, car les programmes malveillants peuvent d'ordinaire le détourner en essayant suffisamment énergiquement. Mais à moins que vous n'essayiez intentionnellement de casser le module, il devrait marcher comme prévu. Le module procure une variable $Findbin::Bin (que vous pouvez importer) qui contient l'emplacement où le programme a été installé, tel que le module l'a deviné. Vous pouvez alors utiliser le pragma lib pour ajouter ce répertoire à votre tableau @INC, produisant ainsi un chemin relatif à l'exécutable.
Certains programmes s'attendent à être installés dans un répertoire bin et trouvent alors leurs modules de bibliothèque dans les fichiers « cousins » installés dans un répertoire lib au même niveau que bin. Par exemple, des programmes peuvent se trouver dans /usr/ local/apache/bin ou /opt/perl/bin et les bibliothèques dans /usr/local/apache/lib et /opt/perl/ lib. Ce code en tient soigneusement compte :
Si vous vous retrouvez à spécifier le même use lib dans plusieurs programmes sans rapport les uns avec les autres, vous pouvez envisager de positionner à la place la variable d'environnement PERL5LIB. Voir la description de la variable d'environnement PERL5LIB au chapitre 19, L'interface de la ligne de commande.
# syntaxe pour sh, bash, ksh ou zsh
$ PERLLIB=$HOME/libperl; export PERL5LIB
# syntaxe pour csh ou tcsh
$ setenv PERL5LIB ~/libperlSi vous voulez utiliser des répertoires optionnels uniquement pour ce programme sans changer son code source, regardez du côté de l'option de la ligne de commande -I :
% perl -I ~/libperl chemin-programme argsVoir le chapitre 19 pour plus d'informations sur l'emploi de -I dans la ligne de commande.
31-14. use locale▲
@x = sort @y; # tri dans l'ordre ASCII
{
use locale;
@x = sort @y; # tri dans l'ordre défini par les locales
}
@x = sort @y; # à nouveau tri dans l'ordre ASCIICe pragma de portée lexicale indique au compilateur d'activer (ou de désactiver, avec no locale) l'emploi des locales POSIX pour les opérations intrinsèques. L'activation des locales indique aux fonctions de conversions de casse (majuscule/minuscule) de Perl et au moteur de recherche de motifs de respecter l'environnement de votre langue, en autorisant les signes diacritiques(224), etc. Si ce pragma est actif et que votre bibliothèque C connaît les locales POSIX, Perl recherche la valeur de votre variable d'environnement LC_CTYPE pour les expressions régulières et LC_COLLATE pour les comparaisons de chaînes comme celles de sort.
Comme les locales sont plus une forme de nationalisation que d'internationalisation, l'emploi des locales peut interférer avec Unicode. Voir le chapitre 15 pour plus d'informations sur l'internationalisation.
31-15. use open▲
use open IN => ":crlf", OUT => ":raw";Le pragma open déclare une ou plusieurs disciplines par défaut pour les opérations d'entrées/sorties. Chaque opérateur open et readpipe (c'est-à-dire qx// ou les apostrophes inverses) découvert à l'intérieur de la portée lexicale de ce pragma et qui ne spécifie pas ses propres disciplines utilisera celles déclarées par défaut. Ni open avec un ensemble explicite de disciplines, ni sysopen en toute circonstance, ne sont influencés par ce pragma.
Seules les deux disciplines :raw et :crlf sont actuellement implémentées (cependant au moment où nous écrivons cela, nous espérons qu'une discipline :utf8 le soit également bientôt). Sur les systèmes ancestraux qui font la distinction entre ces deux modes de conversions lors de l'ouverture de fichiers, la discipline :raw correspond au « mode binaire » et :crlf au « mode texte ». (Ces deux disciplines n'ont actuellement aucun effet sur les plates-formes où binmode n'en a pas non plus, mais seulement pour le moment ; voir la fonction open au chapitre 29, Fonctions, pour une description plus détaillée des sémantiques que nous espérons en ce qui concerne les diverses disciplines.)
Le support exhaustif des disciplines d'entrées/sorties n'est pas encore implémenté à ce jour. Lorsqu'elles seront enfin supportées, ce pragma servira comme l'une des interfaces pour déclarer les disciplines par défaut pour toutes les entrées/sorties. À ce moment-là, les disciplines par défaut déclarées avec ce pragma seront accessibles par le biais de la discipline spéciale nommée « :DEFAULT » et exploitables à l'intérieur des constructeurs de handles qui autorisent la spécification de disciplines. Cela rendra possible l'empilement de nouvelles disciplines par-dessus celles par défaut.
open (HF, "<:para :DEFAULT", $fichier)
or die "impossible d'ouvrir $fichier : $!";Lorsqu'il sera complet, le support des disciplines d'entrées/sorties permettra à toutes les disciplines supportées de fonctionner sur toutes les plates-formes.
31-16. use overload▲
Dans le module Nombre :
package Nombre;
use overload "+" => \&mon_addition;
"-" => \&ma_soustraction;
"*=" => \&mon_produit_par;Dans votre programme :
Les opérateurs internes fonctionnent bien avec des chaînes et des nombres, mais n'ont que peu de sens lorsqu'on les applique à des références d'objets (puisque, contrairement à C ou à C++, Perl ne permet pas de faire de l'arithmétique de pointeur). Le pragma overload vous laisse redéfinir les significations de ces opérations internes lorsque vous les appliquez à des objets de votre cru. Dans l'exemple précédent, l'appel au pragma redéfinit trois opérations sur des objets Nombre : l'addition appellera la fonction Nom-bre::mon_addition, la soustraction appellera la fonction Nombre::ma_soustraction et l'opérateur d'assignement accompagné d'une multiplication appellera la méthode mon_produit_par de la classe Nombre (ou de l'une de ses classes de base). Nous disons que ces opérateurs sont surchargés (overloaded), car des significations supplémentaires les recouvrent (et non parce qu'ils ont trop de significations -quoique cela peut également être le cas).
Pour plus d'informations sur la surcharge, voir le chapitre 13, Surcharge.
31-17. use re▲
Ce pragma contrôle l'utilisation des expressions régulières. On peut l'invoquer de quatre façons : « taint » et « eval », qui ont une portée lexicale, plus « debug » et « debugcolor » qui n'en ont pas.
use re 'taint';
# Le contenu de $corresp est marqué si $gribouille était aussi marqué.
($corresp) = ($gribouille =~ /(.*)$/s);
# Permet l'interpolation de code :
use re 'eval';
$motif = '(?{ $var = 1 })'; # exécution de code inséré
/alpha${motif}omega/; # n'échouera pas à moins d'être lancé
# avec -T et que $motif soit marqué
use re 'debug'; # comme "perl -Dr"
/^(.*)$/s; # affichage d'informations de débogage
# durant la compilation et l'exécution
use re 'debugcolor' # comme 'debug', mais avec un affichage
# en couleurLorsque use re 'taint' est actif et qu'une chaîne marquée est la cible de l'expression régulière, les variables numérotées de l'expression régulière et les valeurs renvoyées par l'opérateur m// dans un contexte de liste sont également marquées. Ceci est très utile lorsque les opérations d'expressions régulières sur des données marquées ne sont pas vouées à extraire des sous-chaînes sécurisées, mais à effectuer d'autres transformations. Voir la discussion sur le marquage au chapitre 23.
Lorsque use re 'eval' est actif, une expression régulière a le droit de contenir des assertions exécutant du code Perl, qui sont de la forme (?{...}), même si l'expression régulière contient des variables interpolées. L'exécution des segments de code résultant de l'interpolation de variables à l'intérieur des expressions régulières n'est pas habituellement permise pour des raisons de sécurité : vous ne voulez pas que des programmes qui lisent des motifs depuis des fichiers de configuration, des arguments de la ligne de commande ou des champs de formulaires CGI, se mettent subitement à exécuter un code arbitraire s'ils ne sont pas conçus pour s'attendre à cela. Cet emploi du pragma permet uniquement aux chaînes non marquées d'être interpolées ; les données marquées causeront toujours la levée d'une exception (si vous activez la vérification des marquages).
Voir également le chapitre 5, Correspondance de motifs et le chapitre 23.
À l'intention de ce pragma, l'interpolation d'expressions régulières précompilées (produites par l'opérateur qr//) n'est pas considérée comme une interpolation de variable. Néanmoins, lorsque vous construisez le motif qr//, use re 'eval' doit être actif si l'une de ses chaînes interpolées contient des assertions de code. Par exemple :
$code = '(?{ $n++ })'; # assertion de code
$chaine = '\b\w+\b' . $code; # construit la chaîne à interpoler
$ligne =~ /$chaine/; # ceci a besoin de use re 'eval'
$motif = qr/$chaine/; # ceci également
$ligne =~ /$motif/; #, mais pas ceciAvec use re 'debug', Perl émet des messages de débogage à la compilation et à l'exécution d'expressions régulières. L'affichage est identique à celui obtenu en lançant un « débogueur Perl » (l'un de ceux compilés en passant -DDEBUGGING au compilateur C) et en exécutant alors votre programme Perl avec l'option de la ligne de commande de Perl -Dr. Selon la complexité de votre motif, l'affichage résultant peut vous noyer. L'appel de use re 'debugcolor' permet un affichage plus coloré qui peut s'avérer utile, pourvu que votre terminal comprenne les séquences de couleurs. Positionner votre variable d'environnement PERL_RE_TC avec une liste de propriétés termcap(5) pertinentes, séparées par des virgules, pour faire ressortir l'affichage. Pour plus de détails, voir le chapitre 20, Le débogueur Perl.
31-18. use sigtrap▲
use sigtrap;
use sigtrap qw(stack-trace old-interface-signals); # idem
use sigtrap qw(BUS SEGV PIPE ABRT);
use sigtrap qw(die INT QUIT);
use sigtrap qw(die normal-signals);
use sigtrap qw(die untrapped normal-signals);
use sigtrap qw(die untrapped normal-signals stack-trace any error-signals);Le pragma sigtrap installe pour vous quelques gestionnaires de signaux simples pour vous éviter de vous en inquiéter. Ceci est très utile dans les situations où les signaux non interceptés causeraient des dysfonctionnements dans votre programme; comme lorsque vous avez des blocs END {}, des destructeurs d'objets ou d'autres traitements à lancer à la fin de votre programme, quelle que soit la façon dont il se termine.
Le pragma sigtrap fournit deux gestionnaires de signaux simples que vous pouvez utiliser. L'un apporte à Perl une trace de la pile et l'autre lance une exception ordinaire via die. Vous pouvez aussi fournir votre propre gestionnaire au pragma pour qu'il l'installe. Vous pouvez spécifier des ensembles de signaux prédéfinis à intercepter ; vous pouvez également donner votre propre liste explicite de signaux. Le pragma peut optionnellement installer des gestionnaires uniquement pour les signaux qui n'auraient sinon pas été gérés.
Les arguments passés à use sigtrap sont traités dans l'ordre. Lorsqu'un nom de signal fourni par l'utilisateur ou le nom d'un des ensembles de signaux prédéfinis de sigtrap est rencontré, un gestionnaire est immédiatement installé. Lorsqu'il y a une option, celle-ci n'affecte que les gestionnaires installés ensuite en traitant la liste d'arguments.
31-18-a. Gestionnaires de signaux▲
Ces options ont pour effet de décider quel gestionnaire sera utilisé pour les signaux installés ensuite :
stack-trace
- Ce gestionnaire fourni par le pragma affiche une trace de la pile d'exécution Perl vers STDERR et tente alors de faire une copie du cœur du programme (core dump). Il s'agit du gestionnaire de signaux par défaut.
die
- Ce gestionnaire fourni par le pragma appelle die via Carp::croak avec un message indiquant le signal reçu.
handler VOTRE_GESTIONNAIRE
- VOTRE_GESTIONNAIRE sera utilisé comme gestionnaire pour les signaux installés ensuite. VOTRE_GESTIONNAIRE peut être n'importe quelle valeur valide pour un assignement de
%SIG. Souvenez-vous que le fonctionnement correct de beaucoup d'appels de la bibliothèque C (en particulier les appels d'entrées/sorties standards) n'est pas garanti à l'intérieur d'un gestionnaire de signaux. Pis encore, il est difficile de deviner quels morceaux du code de la bibliothèque C sont appelés depuis tel ou tel morceau du code Perl. (D'un autre côté, nombre de signaux que sigtrap intercepte sont un peu vicieux — ils vous feront tourner en bourrique de toute façon, alors ça ne coûte pas grand-chose d'essayer de faire quelque chose, n'est-ce pas?)
31-18-b. Listes prédéfinies de signaux▲
Le pragma sigtrap inclut quelques listes prédéfinies de signaux à intercepter :
normal-signals
- Il s'agit des signaux qu'un programme peut normalement s'attendre à rencontrer et qui le font, par défaut, se terminer. Ce sont les signaux HUP, INT, PIPE et TERM.
error-signals
- Il s'agit des signaux qui d'ordinaire indiquent un sérieux problème avec l'interpréteur Perl ou avec votre programme. Ce sont les signaux ABRT, BUS, EMT, FPE, KILL, QUIT, SEGV, SYS et TRAP.
old-interface-signals
- Il s'agit des signaux qui sont interceptés par défaut sous une ancienne version de l'interface de sigtrap. Ce sont les signaux ABRT, BUS, EMT, FPE, KILL, PIPE, QUIT, SEGV, SYS, TERM et TRAP. Si aucun signal ou aucune liste de signaux n'est passé à use sigtrap, on utilise cette liste.
Si votre plate-forme n'implémente pas un signal particulier cité dans les listes prédéfinies, le nom de ce signal sera discrètement ignoré. (Le signal lui-même ne peut pas être ignoré, car il n'existe pas.)
31-18-c. Autres arguments de sigtrap▲
untrapped
- Ce token supprime les gestionnaires pour tous les signaux listés ultérieurement s'ils ont déjà été interceptés ou ignorés.
any
- Ce token installe des gestionnaires pour tous les signaux listés ultérieurement. Il s'agit du comportement par défaut.
signal
- Tout argument qui ressemble à un nom de signal (c'est-à-dire qui correspond au motif
/^[A-Z][A-Z0-9]*$/enjoint à sigtrap de gérer ce signal.
nombre
- Un argument numérique requiert que le numéro de version du pragma sigtrap soit au moins nombre. Ceci fonctionne exactement comme la plupart des modules ordinaires qui ont une variable de paquetage
$VERSION.
% perl -Msigtrap -le 'print $sigtrap::VERSION'
1.0231-18-d. Exemples de sigtrap▲
Fournit une trace de la pile pour les signaux utilisant l'ancienne interface :
use sigtrap;Idem, mais plus explicite :
use sigtrap qw(stack-trace old-interface-signals);Fournit une trace de la pile uniquement pour les quatre signaux listés :
use sigtrap qw(BUS SEGV PIPE ABRT);Meurt (via die) sur réception du signal INT ou QUIT :
use sigtrap qw(die INT QUIT);Meurt (via die) sur réception de l'un des signaux HUP, INT, PIPE ou TERM : use
sigtrap qw(die normal-signals);Meurt (via die) sur réception de HUP, INT, PIPE ou TERM — à cela près qu'on ne change pas le comportement pour les signaux qui ont déjà été interceptés ou ignorés ailleurs dans le programme :
use sigtrap qw(die untrapped normal-signals);Meurt (via die) sur réception de n'importe quel signal « normal-signals » non intercepté actuellement ; de plus, fournit une trace arrière de la pile d'exécution sur réception de l'un des signaux « error-signals » :
use sigtrap qw(die untrapped normal-signals stack-trace any error-signals);Installe la routine mon_gestionnaire comme gestionnaire pour les signaux « normalsignals » :
use sigtrap 'handler' => \&mon_gestionnaire, 'normal-signals';Installe la routine mon_gestionnaire comme gestionnaire pour les signaux « normalsignals » ; de plus, fournit une trace arrière de la pile d'exécution sur réception de l'un des signaux « error-signals » :
use sigtrap qw(handler mon_gestionnaire normal-signals stack-trace
error-signals);31-19. use strict▲
use strict; # Installe les trois restrictions.
use strict "vars"; # Les variables doivent être prédéclarées.
use strict "refs"; # Les références symboliques sont interdites.
use strict "subs"; # Les chaînes brutes doivent être entre guillemets.
use strict; # Installe toutes les restrictions
no strict "vars"; # puis renonce à l'une d'entre elles.Ce pragma de portée lexicale modifie quelques règles basiques à propos de ce que Perl considère comme étant du code légal. Quelquefois, ces restrictions semblent trop strictes pour de la programmation occasionnelle, comme lorsque vous ne faites qu'essayer de programmer à la hâte un filtre de cinq lignes. Plus votre programme est gros, plus vous devez être strict avec lui.
Actuellement, vous devez être strict avec trois choses : subs, vars et refs. Si aucune liste d'importation n'est fournie, les trois restrictions sont prises en compte.
31-19-a. strict 'refs'▲
Cet exemple génère une erreur à l'exécution si vous utilisez des références symboliques, intentionnellement ou pas. Voir le chapitre 8, Références pour plus d'informations.
use strict 'refs';
$ref = \$truc; # Enregistre une référence "réelle" (en dur).
print $$ref; # Déréférencement OK.
$ref = "truc"; # Enregistre le nom d'une variable globale (de paquetage).
print $$ref; # FAUX, erreur à l'exécution avec strict refs.Les références symboliques sont suspectes pour diverses raisons. Il est étonnamment aisé, même pour des programmeurs bien intentionnés, de les invoquer accidentellement ; strict 'refs' l'empêche. Au contraire des références réelles, les références symboliques ne peuvent se référer qu'à des variables globales. Elles ne possèdent pas de compteur de références. Il existe souvent un meilleur moyen d'accomplir ce que vous faites : au lieu de référencer un symbole dans une table de symboles globale, utilisez un hachage pour sa propre minitable de symboles. C'est plus efficace, plus lisible et moins sujet à engendrer des erreurs.
Néanmoins, certains types de manipulations valides nécessitent vraiment un accès direct à la table de symboles globale du paquetage pour les noms de variables et de fonctions. Par exemple, il se peut que vous vouliez examiner la liste @EXPORT de la super-classe @ISA d'un paquetage donné dont vous ne connaissez pas le nom à l'avance. Ou vous pourriez vouloir installer toute une kyrielle d'appels de fonctions qui seraient toutes des alias de la même fermeture. C'est seulement là que les références symboliques sont les plus utiles, mais pour les utiliser alors que use strict est actif, vous devez d'abord annuler la restriction « ref » :
31-20. strict 'vars'▲
Dans cette restriction, une erreur de compilation est déclenchée si vous essayez d'accéder à une variable qui n'est pas conforme à au moins un de ces critères :
- Prédéfinie par Perl, comme
@ARGV,%ENVet toutes les variables globales avec des signes de ponctuation comme$.ou$_. - Déclarée avec our (pour une variable globale) ou my (pour une variable lexicale).
- Importée depuis un autre paquetage. (Le pragma use vars simule une importation, mais utilisez our à la place.)
- Pleinement qualifiée en utilisant le nom de son paquetage et le double deux-points séparateur de paquetage.
L'emploi seul d'un opérateur local n'est pas suffisant pour rendre heureux, use strict 'vars' car, malgré son nom, cet opérateur ne change pas le fait qu'une variable nommée soit globale ou non. Il donne seulement à la variable une nouvelle valeur temporaire durant un bloc lors de l'exécution. Vous devrez toujours employer our pour déclarer une variable globale ou my pour déclarer une variable lexicale. Vous pouvez toutefois localiser un our :
Les variables globales prédéfinies par Perl sont dispensées de ces exigences. Ceci s'applique aux variables globales de tout le programme (celles forcées dans le paquetage main comme @ARGV ou $_) et aux variables par paquetage comme $a ou $b, qui sont normalement utilisée par la fonction sort. Les variables par paquetage utilisées par les modules comme Exporter ont toujours besoin d'être déclarées en utilisant our :
our @EXPORT_OK = qw(nom grade matricule);31-21. strict 'subs'▲
Cette restriction oblige Perl à traiter les mots simples comme des erreurs de syntaxe. Un mot simple (bareword ou bearword dans certains dialectes) est un nom simple ou un identificateur qui n'a aucune autre interprétation forcée par le contexte. (Le contexte est souvent forcé par la proximité d'un mot clef ou d'un token ou par la prédéclaration du mot en question.) Historiquement, les mots simples étaient interprétés comme des chaînes sans guillemets ou apostrophes. Cette restriction rend cette interprétation illégale. Si vous avez l'intention de l'utiliser en tant que chaîne, mettez-la entre guillemets ou entre apostrophes. Si vous avez l'intention de l'utiliser en tant que fonction, prédéclarez-la ou employez des parenthèses.
Comme cas particulier de contexte forcé, souvenez-vous qu'un mot qui apparaît entre des accolades ou du côté gauche de l'opérateur => compte comme s'il était entre apostrophes et n'est donc pas sujet à cette restriction.
use strict 'subs';
$x = n_importe_quoi; # FAUX : erreur de mot simple !
$x = n_importe_quoi(); # Par contre, cela marche toujours.
sub n_importe_quoi; # Prédéclaration de fonction.
$x = n_importe_quoi; # Maintenant OK.
# Ces utilisations sont permises, car => met entre apostrophes :
%hachage = (rouge => 1, vert => 2, bleu => 3);
$num_rouge = $hachage{rouge}; # Ok, les accolades mettent entre
# apostrophes ici.
#, Mais pas celles-ci :
@nums = @hachage{bleu, vert}; # Faux : erreur de mot simple.
@nums * @hachage{"bleu", "vert"}; # Ok, les mots sont maintenant entre
# guillemets.
@nums = @hachage{qw/bleu vert/}; # Idem.31-22. use subs▲
use subs qw/am stram gram/;
@x = am 3..10;
@x = gram stram @x;Ce pragma prédéclare tous les noms de la liste d'arguments comme étant des sous-programmes standards. L'avantage ici est que vous pouvez maintenant utiliser ces fonctions sans parenthèses en tant qu'opérateurs de listes, exactement comme si vous les aviez déclarées vous-mêmes. Ce n'est pas forcément aussi utile que des déclarations complètes, car cela ne permet pas d'utiliser des prototypes ou des attributs comme dans :
Puisqu'il est basé sur le mécanisme d'importation standard, le pragma use subs n'a pas de portée lexicale, mais une portée de paquetage. C'est-à-dire que les déclarations sont effectives pour la totalité du fichier dans lequel elles apparaissent, mais seulement pour le paquetage courant. Vous ne pouvez pas annuler de telles déclarations avec no subs.
31-23. use vars▲
use vars qw($bricole @refait %vu);Ce pragma, autrefois utilisé pour déclarer une variable globale, est maintenant quelque peu déprécié en faveur du modificateur our. La déclaration précédente s'effectue mieux en utilisant :
our($bricole, @refait, %vu};ou même :
Peu importe que vous utilisiez l'une ou l'autre de ces possibilités, rappelez-vous qu'elles portent toutes sur des variables globales de paquetage, et non sur des variables lexicales ayant la portée du fichier.
31-24. use warnings▲
use warnings; # Revient à importer "all".
no warnings; # Revient à annuler l'importation de "all".
use warnings::register;
if (warnings::enabled()) {
warnings::warn("un avertissement");
}
if (warnings::enabled("void")) {
warnings::warn("void", "un avertissement");
}Ce pragma de portée lexicale permet un contrôle souple sur les avertissements internes de Perl, à la fois ceux émis par le compilateur et ceux provenant du système d'exécution.
Autrefois, le seul contrôle que vous aviez sur le traitement des avertissements de votre programme se faisait par le biais de l'option de la ligne de commande -w ou de la variable $^W. Bien qu'utile, ces solutions tendaient à faire du tout-ou-rien. L'option -w active des avertissements dans des morceaux de code que vous pouvez ne pas avoir écrits, ce qui est parfois problématique pour vous et embarrassant pour l'auteur original. L'emploi de $^W, soit pour activer, soit pour désactiver des blocs de code, peut s'avérer moins qu'optionnel, car il ne fonctionne que durant l'exécution et non pendant la compilation.(225) Un autre problème est que cette variable globale à tout le programme possède une portée dynamique et non lexicale. Cela signifie que si vous l'activez dans un bloc et qu'ensuite vous appelez à partir de là un autre code, vous risquez ici encore d'activer des avertissements dans du code qui n'est pas développé avec exactement de tels standards à l'esprit.
Le pragma warnings contourne ces limitations en possédant une portée lexicale, des mécanismes durant la compilation qui permettent un contrôle plus fin sur l'endroit où les avertissements peuvent ou ne peuvent pas être déclenchés. Une hiérarchie de catégories d'avertissements (voir la figure 31-1) a été définie pour permettre aux groupes d'avertissements d'être activés ou désactivés séparément les uns des autres. (La catégorisation exacte est expérimentale et sujette à modifications.) Ces catégories peuvent être combinées en passant des arguments multiples à use ou no :
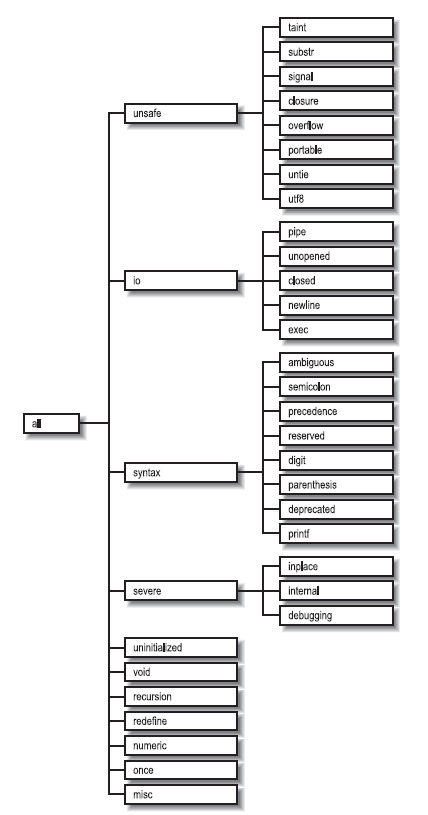
Si des instances multiples du pragma warnings sont actives pour un groupe donné, leurs effets se cumulent :
use warnings "void"; # Seuls les avertissements "void" sont actifs.
...
use warnings "io"; # Les avertissements "void" et "io" sont
# maintenant tous deux actifs.
...
no warnings "void"; # Seuls les avertissements "io" sont maintenant
# actifs.Pour donner des erreurs fatales pour tous les avertissements activés par un pragma warnings particulier, utilisez le mot FATAL devant la liste d'importation. Ceci est très utile lorsque vous aimez mieux qu'une certaine condition, qui d'ordinaire n'aurait causé qu'un avertissement, arrête votre programme. Supposez par exemple que vous considériez l'emploi d'une chaîne invalide en tant que nombre (qui normalement aurait donné une valeur de 0) si incorrect que vous vouliez que cet acte effronté tue votre programme. Pendant que vous y êtes, vous décidez que l'utilisation de valeurs non initialisées en lieu et place de chaînes réelles ou de valeurs numériques doit également être la cause d'un suicide immédiat :
Maintenant, si $y ou $z ne sont pas initialisées (c'est-à-dire, contiennent la valeur scalaire spéciale undef) ou si elles contiennent des chaînes qui ne se convertissent pas proprement en valeurs numériques, au lieu de continuer gentiment son chemin ou tout au plus d'émettre une petite complainte si vous aviez activé -w, votre programme lèvera maintenant une exception. (Pensez à cela comme du Perl tournant en mode Python.) Si vous n'interceptez pas les exceptions, elles causeront une erreur fatale. Le texte de l'exception est le même que celui qui serait normalement apparu dans le message d'avertissement.
Le pragma warnings ignore l'option de la ligne de commande -w et la valeur de la variable $^W ; les configurations du pragma sont prioritaires. Toutefois, le drapeau -W de la ligne de commande passe outre le pragma, en activant totalement les avertissements dans tous le code à l'intérieur de votre programme, y compris le code chargé avec do, require ou use. En d'autres termes, avec -W, Perl prétend que chaque bloc de votre programme possède un pragma use warnings 'all'. Pensez-y comme un lint(1) pour les programmes Perl. (Mais voyez également la documentation en ligne du module B::Lint.) Le drapeau -X de la ligne de commande fonctionne à l'inverse. Il prétend que chaque bloc a un no warnings 'all' activé.
Plusieurs fonctions sont fournies pour assister les auteurs de modules qui veulent que les fonctions de leur module se comportent comme les fonctions internes en respectant la portée lexicale de l'appelant (c'est-à-dire, de manière à ce que les utilisateurs du module puissent lexicalement activer ou désactiver les avertissements que le module pourrait émettre) :
warnings::register
- Enregistre le nom du module courant comme une nouvelle catégorie d'avertissements, afin que les utilisateurs du module puissent en stopper les avertissements.
warnings::enabled(CATEGORIE)
- Renvoie vrai si la catégorie CATEGORIE est activée dans la portée lexicale du module appelant. Sinon, renvoie faux. Si CATEGORIE n'est pas fournie, le nom du paquetage courant est utilisé.
warnings::warn(CATEGORIE, MESSAGE)
32. Modules standards▲
L'édition précédente de ce livre couvrait de manière très complète et définitive tous les modules faisant partie de la distribution standard de Perl. Si nous avions refait la même chose ici, vous auriez payé de livre le double, sans parler de ce que vous auriez dû payer au chiropracteur après avoir essayé de porter le livre jusqu'à chez vous. Ces dernières années, de plus en plus de modules ont été inclus dans la distribution standard ; nous en sommes à ce jour à environ deux cents. Certains d'entre eux, comme CGI, proposent eux-mêmes une documentation remarquablement approfondie. Et si vous utilisez la distribution de Perl ActiveState, votre bibliothèque standard est encore plus raffinée.
Ainsi, nous vous offrons à la place une énumération complète des modules standards, classés par type, accompagnés d'une brève description. Puis, cerise sur le gâteau, nous avons sélectionné quelques-uns de nos modules favoris, vous en donnant des exemples d'utilisation classique, suivis d'une courte description de leur fonctionnement, juste pour que vous y goûtiez un peu. Les descriptions sont suggestives plutôt que complètes et quasiment tous les modules ont d'autres fonctionnalités que celles que nous montrons. Toutefois, une documentation complète de tous les modules standards est incluse dans chaque distribution de Perl, vous n'avez donc qu'à rechercher les détails sur votre propre système en utilisant le programme perldoc, la commande man(1) de votre système ou votre navigateur préféré. Voir la section Documentation en ligne de la préface. Demandez à votre expert maison si vous ne trouvez pas les documents, car ils sont quasi certainement quelque part sur votre système. Et même si ils n'y sont pas, vous pouvez toujours les lire au format pod directement dans les modules eux-mêmes, car toute la documentation des modules est insérée dans le fichier de module (.pm) lui correspondant et le format pod a été conçu pour être assez lisible. (Pas comme, disons, HTML.)
32-1. Listes par type▲
Le nom des modules ordinaires commence par une majuscule. Des noms en minuscules indiquent des pragmas dont vous trouverez la documentation au chapitre 31, Modules de pragmas, plutôt que dans le présent chapitre.
32-1-a. Types de données▲
Ces modules étendent le système de typage de Perl (ou plutôt ses lacunes) de diverses manières.
|
Module |
Description |
|---|---|
|
Class::Struct |
Crée des classes d'objets Perl ressemblant à struct. |
|
constant |
Déclare des scalaires et des listes constantes. |
|
integer |
Force Perl à faire de l'arithmétique avec des entiers au lieu de nombres à virgule flottante. |
|
Math::BigFloat |
Calcule avec des nombres à virgule flottante d'une longueur arbitraire. |
|
Math::BigInt |
Calcule avec des entiers de longueur arbitraire. |
|
Math::Complex |
Calcule avec des nombres complexes et les fonctions mathématiques associées. |
|
Math::Trig. |
Charge beaucoup de fonctions trigonométriques |
|
overload |
Surcharge les opérateurs Perl sur des objets. |
|
Symbol |
Manipule les tables de symboles de Perl et génère des types globs anonymes. |
|
Time:Local |
Calcule efficacement la date et l'heure origine selon locatime ou |
32-1-b. Traitement des chaînes, traitement de textes linguistiques, analyse et recherche▲
Ces modules agissent avec (ou sur) des textes.
|
Module |
Description |
|---|---|
|
Search::Dict |
Effectue une recherche binaire d'une chaîne dans un fichier texte trié. |
|
Text::Abbrev |
Crée une table d'abréviations à partir d'une liste. |
|
Text::ParseWords |
Analyse du texte dans une liste de tokens ou dans un tableau de tableaux. |
|
Text::Soundex |
Utilise l'algorithme Soundex de Knuth. |
|
Text::Tabs |
Développe ou réduit les tabulations comme expand(1) ou unexpand(1). |
|
Text::Wrap |
Équilibre des lignes pour former des paragraphes simples. |
32-1-c. Traitement des options, arguments, paramètres et fichiers de configurations▲
Ces modules traitent votre ligne de commande.
|
Module |
Description |
|---|---|
|
Getopt::Long |
Traite des options étendues de la ligne de commande dans une forme longue ( |
|
Getopt::Std |
Traite des options d'un seul caractère avec regroupement d'options. |
32-1-d. Noms de fichier, systèmes de fichiers et verrouillage de fichiers▲
Ces modules fournissent des méthodes d'accès aux fichiers sur plusieurs plates-formes.
|
Module |
Description |
|---|---|
|
Cwd |
Obtient le chemin du répertoire de travail courant. |
|
File::Basename |
Décompose de manière portable le nom d'un chemin en ses composants : répertoire, nom de base et extension. |
|
File::CheckTree |
Lance plusieurs tests de fichiers sur un ensemble d'arborescences de répertoires. |
|
File::Compare |
Compare de manière portable les contenus de fichiers ou de handles de fichiers. |
|
File::Copy |
Copie de manière portable des fichiers ou des handles de fichiers ou déplace des fichiers. |
|
File::DosGlob |
Réalise des globs dans le style Microsoft. |
|
File::Find |
Parcourt une arborescence de fichiers comme find(1). |
|
File::Glob |
Utilise des globs dans le style Unix. |
|
File::Path |
Crée ou supprime de manière portable une série de répertoires. |
|
File::Spec |
Utilise des opérations portables sur les fichiers (interface orientée objet). |
|
File::Spec::Functions |
Utilise des opérations portables sur les fichiers (interface orientée objet). |
|
File::Spec::Mac |
Utilise des opérations sur les fichiers pour Mac OS. |
|
File::Spec::OS2 |
Utilise des opérations sur les fichiers pour OS/2. |
|
File::Spec::Unix |
Utilise des opérations sur les fichiers pour Unix. |
|
File::Spec::VMS |
Utilise des opérations sur les fichiers pour VMS. |
|
File::Spec::Win32 |
Utilise des opérations sur les fichiers pour Microsoft. |
|
File::stat |
Supplante les fonctions |
32-1-e. Utilitaires pour les handles de fichiers, les handles de répertoires et les flux d'entrées/sorties▲
Ces modules fournissent un accès orienté objet aux fichiers, aux répertoires et aux IPC.
|
Module |
Description |
|---|---|
|
DirHandle |
Utilise des méthodes objets pour les handles de répertoires. |
|
FileCache |
Garde plus de fichiers ouverts simultanément en écriture que votre système ne le permet. |
|
FileHandle |
Utilise des méthodes objets pour les handles de fichiers. |
|
IO |
Fournit un frontal pour charger tous les modules IO::Dir, IO::File, IO::Handle, IO::Pipe, IO::Seekable et IO::Socket. |
|
IO::Dir |
Utilise des méthodes objets pour les handles de répertoires. |
|
IO::File |
Utilise des méthodes objets en rapport avec les fichiers pour les handles de fichiers. |
|
IO::Handle |
Utilise des méthodes objets génériques pour les handles de fichiers/ |
|
IO::Pipe |
Utilise des méthodes objets pour les pipes. |
|
IO::Poll |
Fournit une interface orientée objet à l'appel système poll(2). |
|
IO::Seekable |
Utilise des méthodes objets pour les objets d'entrées/sorties dans lesquels on peut faire des recherches (avec |
|
IO::Select |
Utilise une interface orientée objet facilitant l'appel système select(2). |
|
SelectSaver |
Sauvegarde et restaure les handles de fichiers sélectionnés. |
32-1-f. Internationalisation et locales▲
Ces modules vous aident dans vos activités extra-américaines.
|
Module |
Description |
|---|---|
|
bytes |
Force l'ancienne sémantique orientée octets. |
|
charnames |
Définit les noms de caractères utilisés dans les séquences d'échappements \N |
|
I18N::Collate |
Compare des données scalaires de 8 bits selon la locale courante (déprécié). |
|
locale |
Utilise ou évite les locales POSIX pour les opérations internes. |
|
utf8 |
Bascule explicitement sur le support UTF-8 et Unicode. |
32-1-g. Interfaces au système d'exploitation▲
Ces modules ajustent votre interface au système d'exploitation.
|
Module |
Description |
|---|---|
|
Fcntl |
Charge les définitions de fcntl.h de la bibliothèque C en tant que constantes Perl. |
|
filetest |
Contrôle les opérateurs de tests de fichiers ( |
|
open |
Positionne les disciplines par défaut pour les appels à la fonction |
|
POSIX |
Utilise l'interface Perl à POSIX 1003.1. |
|
Shell |
Lance des commandes shells de manière transparente à l'intérieur de Perl. |
|
sigtrap |
Active une gestion simple des signaux. |
|
Sys::Hostname |
Essaye de manière portable tous les moyens imaginables pour déterminer le nom de l'hôte courant. |
|
Sys::Syslog |
Utilise les fonctions syslog(3) de la bibliothèque C. |
|
Time::gmtime |
Supplante la fonction interne |
|
Time::localtime |
Supplante la fonction interne |
|
Time::tm |
Fournit l'objet interne utilisé par Time::gmtime et Time::localtime. |
|
User::grent |
Supplante les fonctions internes getgr |
|
User::pwent |
Supplante les fonctions internes getpw |
32-1-h. Communication réseau et interprocessus▲
Ces modules fournissent des interfaces abstraites à côté des interfaces basiques que nous avons décrites au chapitre 16, Communication interprocessus.
|
Module |
Description |
|---|---|
|
IO::Socket |
Utilise une interface orientée objet générique pour les communications sur des sockets. |
|
IO::Socket::INET |
Utilise une interface orientée objet pour les sockets du domaine Internet. |
|
IO::Socket::UNIX |
Utilise une interface orientée objet pour les sockets du domaine Unix (locales). |
|
IPC::Msg |
Utilise des méthodes objets pour travailler avec les messages System V (classe objet SysV Msg IPC). |
|
IPC::Open2 |
Ouvre un processus en lecture et écriture simultanées. |
|
IPC::Open3 |
Ouvre un processus pour lire, écrire et gérer les erreurs. |
|
IPC::Semaphore |
Utilise des méthodes objets pour les sémaphores System V. |
|
IPC::SysV |
Définit des constantes pour tous les mécanismes des IPC System V. |
|
Net::hostent |
Supplante les fonctions internes gethost |
|
Net::netent |
Supplante les fonctions internes getnet |
|
Net::Ping |
Vérifie si un hôte distant est joignable. |
|
Net::protoent |
Supplante les fonctions internes getproto |
|
Net::servent |
Supplante les fonctions internes getserv |
|
Socket |
Charge les définitions et les fonctions manipulant des structures de socket.h de la bibliothèque C. |
32-1-i. World Wide Web▲
Ces modules interfacent le WWW. Vous devez en avoir entendu parler.
|
Module |
Description |
|---|---|
|
CGI |
Accède aux formulaires CGI et à la génération performante et automatique de HTML. |
|
CGI::Apache |
Fait fonctionner vos scripts CGI sous l'API Perl-Apache. |
|
CGI::Carp |
Écrit dans le journal d'erreurs CGI de httpd(8) (ou d'autres). |
|
CGI::Cookie |
Lit et écrit des cookies HTTP. |
|
CGI::Fast |
Utilise le protocol Fast CGI. |
|
CGI::Pretty |
Produit du code HTML agréablement formaté. |
|
CGI::Push |
Réalise des scripts CGI server-push (N.d.T. : sollicités par le serveur). |
32-1-j. Interfaces DBM▲
Ces modules chargent diverses bibliothèques de gestion de bases de données.
|
Module |
Description |
|---|---|
|
AnyDBM_File |
Fournit une infrastructure pour de multiples bibliothèques DBM. |
|
DB_File |
Fournit un accès lié avec |
|
GDBM_File |
Fournit un accès lié avec |
|
NDBM_File |
Fournit un accès lié avec |
|
SDBM_File |
Fournit un accès lié avec |
32-1-k. Interfaces utilisateurs▲
Ces modules fournissent une API décente pour les entrées/sorties de l'interface en ligne de commande.
|
Module |
Description |
|---|---|
|
Term::Cap |
Utilise la bibliothèque termcap(3). |
|
Term::Complete |
Réalise une complétion programmable par des commandes sur des listes de mots. |
|
Term::Readline |
Utilise l'un des nombreux paquetages readline. |
32-1-l. Authentification, sécurité et encryptage▲
Ces modules fonctionnent avec les espaces mémoire protégés dans lesquels s'exécutent les programmes.
|
Module |
Description |
|---|---|
|
Opcode |
Active ou désactive les lors codes d'opérations (opcodes) de la compilation de code Perl en vue d'une utilisation avec le module Safe. |
|
ops |
Restreint les opérations non sûres lors de la compilation. |
|
Safe |
Compile et exécute du code dans des compartiments restreints. |
32-1-m. Langage Perl, extensions et mécanismes internes.▲
(À ne pas confondre avec les intentions et les mécanismes externes.)
|
Module |
Description |
|---|---|
|
attributes |
Consulte ou positionne les attributs d'un sous-programme ou d'une variable. |
|
attrs |
Consulte ou positionne les attributs d'un sous-programme ou d'une variable (obsolète). |
|
base |
Établit l'héritage des classes de base à la compilation. |
|
Data::Dumper |
Sérialise des structures de données Perl. |
|
DB |
Accède à l'API expérimentale du débogueur Perl. |
|
Devel::Dprof |
Profile l'exécution d'un programme Perl. |
|
Devel::Peek |
Charge des outils de débogage de données pour les programmeurs XS. |
|
diagnostics |
Force des avertissements verbeux et élimine les duplications. |
|
Dumpvalue |
Affiche à l'écran des valeurs de données. |
|
English |
Utilise des noms de variables plus longs pour les variables internes avec une ponctuation. |
|
Env |
Accède aux variables d'environnement dans |
|
Errno |
Charge les définitions de errno.h de la bibliothèque C et lie la variable |
|
Fatal |
Remplace les fonctions internes avec des versions levant des exceptions lors d'un échec. |
|
fields |
Lors de la compilation, déclare les données attributs d'une classe et vérifie les accès à ces données. |
|
less |
Demande moins de quelque chose de la part de Perl (non implémenté). |
|
re |
Altère le comportement par défaut des expressions régulières. |
|
strict |
Restreint les constructions bâclées. |
|
subs |
Prédéclare les noms de sous-programmes dans le paquetage courant. |
|
vars |
Prédéclare des variables globales (obsolète voir our au chapitre 29. |
32-1-n. Classes commodes▲
Ces modules fournissent des classes de base et d'autres facilités.
|
Module |
Description |
|---|---|
|
Tie::Array |
Fournit une classe de base pour les tableaux liés avec |
|
Tie::Handle |
Fournit une classe de base pour les handles liés avec |
|
Tie::Hash |
Fournit une classe de base pour les hachages liés avec |
|
Tie::RefHash |
Fournit des références comme clefs de hachage. |
|
Tie::Scalar |
Fournit une classe de base pour les scalaires liés avec |
|
Tie::SubstrHash |
Fournit une interface similaire aux hachages pour une table de taille fixe avec des clefs de longueur fixe. |
|
UNIVERSAL |
Fournit une classe de base pour toutes les classes (références consacrées). |
32-1-o. Avertissements et exceptions▲
Que faire lorsque les choses se passent mal.
|
Module |
Description |
|---|---|
|
Carp |
Fournit des routines qui font des |
|
warnings |
Contrôle les avertissements à l'intérieur de la portée lexicale. |
32-1-p. Support de documentation▲
Il existe une quantité de documentation à supporter.
|
Module |
Description |
|---|---|
|
Pod::Checker |
Vérifie les erreurs de syntaxes des documents pod (utilisé par podchecker(1)) . |
|
Pod::Functions |
Liste les fonctions internes par type. |
|
Pod::Html |
Convertit les fichiers pod en HTML (utilisé par pod2html(1)). |
|
Pod::InputObjects |
Gère le support de documentation. |
|
Pod::Man |
Convertit du pod en format troff(1) pour le système man(1) (utilisé par pod2man(1)). |
|
Pod::Parser |
Fournit une classe de base pour créer des filtres et des traducteurs de pod. |
|
Pod::Select |
Extrait des sections de pod depuis l'entrée (utilisé par podselect(1)). |
|
Pod::Text |
Convertit des données pod en texte formaté en ASCII (utilisé par pod2text(1)). |
|
Pod::Text::Color |
Convertit des données pod en texte formaté en ASCII avec les séquences d'échappement ANSI pour les couleurs. |
|
Pod::Text::Termcap |
Convertit des données pod en texte ASCII avec les séquences d'échappement spécifiques du terminal. |
|
Pod::Usage |
Affiche un message d'utilisation dérivé de la documentation pod incluse dans le source. |
32-1-q. Support d'installation de module▲
Ces modules aident d'autres modules à sauter à travers différents cerceaux.
|
Module |
Description |
|---|---|
|
AutoLoader |
Charge des sous-programmes à la demande. |
|
AutoSplit |
Éclate un paquetage pour l'autochargement. |
|
autouse |
Diffère le chargement d'un module jusqu'à ce qu'une fonction de ce module soit utilisée. |
|
blib |
Utilise la bibliothèque depuis la version non installée d'une extension par Makemaker. |
|
Config |
Accède aux informations de configuration de Perl. |
|
CPAN |
Interroge, rapatrie et construit des modules Perl depuis des sites CPAN. |
|
Devel::SelfStubber |
Génère des souches (N.d.T. : stubs) pour un module en utilisant le module SelfLoader. |
|
DynaLoader |
Charge dynamiquement des bibliothèques C ou C++ en tant qu'extensions Perl. |
|
Exporter |
Implémente une méthode d'importation par défaut pour les modules traditionnels. |
|
ExtUtils::Command |
Fournit des utilitaires pour remplacer les commandes externes populaires dans un Makefile. |
|
ExtUtils::Embed |
Fournit des utilitaires pour inclure du Perl dans des programmes C ou C++. |
|
ExtUtils::Install |
Installe des fichiers dans la bibliothèque Perl du système. |
|
ExtUtils::Installed |
Gère l'inventaire des modules installés. |
|
ExtUtils::Liblist |
Détermine quelles bibliothèques utiliser et comment les utiliser. |
|
ExtUtils::MakeMaker |
Crée un Makefile pour une extension Perl. |
|
ExtUtils::Manifest |
Charge des outils pour écrire et vérifier un fichier MANIFEST. |
|
ExtUtils::Miniperl |
Écrit du code C pour perlmain.c. |
|
ExtUtils::Mkbootstrap |
Crée un fichier d'amorçage (bootstrap) pour être utilisé par DynaLoader. |
|
ExtUtils::Mksymlists |
Écrit des fichiers d'options de l'éditeur de liens pour les extensions dynamiques. |
|
ExtUtils::MM_Cygwin |
Supplante les méthodes se comportant à la manière d'Unix dans ExtUtils::MakeMaker. |
|
ExtUtils::MM_OS2 |
Supplante les méthodes se comportant à la manière d'Unix dans ExtUtils::MakeMaker. |
|
ExtUtils::MM_Unix |
Fournit des méthodes utilisées par ExtUtils::MakeMaker. |
|
ExtUtils::MM_VMS |
Supplante les méthodes se comportant à la manière d'Unix dans ExtUtils::MakeMaker. |
|
ExtUtils::MM_Win32 |
Supplante les méthodes se comportant à la manière d'Unix dans ExtUtils::MakeMaker. |
|
ExtUtils::Packlist |
Gère les fichiers .packlist. |
|
ExtUtils::testlib |
Ajoute des répertoires blib/* à |
|
FindBin |
Localise le répertoire d'installation pour le programme Perl en train de tourner. |
|
lib |
Manipule |
|
SelfLoader |
Charge des fonctions uniquement à la demande. |
|
XSLoader |
Charge dynamiquement des bibliothèques C ou C++ en tant qu'extensions Perl. |
32-1-r. Support de développement▲
Ces modules s'occupent des mesures de temps et des tests, pour voir dans quelles proportions votre code ne tourne ni plus rapidement ni plus proprement.
|
Module |
Description |
|---|---|
|
Benchmark |
Compare les temps d'exécution de différentes versions de code. |
|
Test |
Utilise une infrastructure simple pour écrire des scripts de test. |
|
Test::Harness |
Lance des scripts de test standards avec des statistiques. |
32-1-s. Compilateur Perl et générateur de code▲
Ces modules supportent des générateurs de code vers des sorties (N.d.T. : backends) diverses et variées pour Perl.
|
Module |
Description |
|---|---|
|
B |
Charge des générateurs de code Perl (alias le « compilateur Perl »). |
|
B::Asmdata |
Fournit une donnée autogénérée sur les opérations atomiques Perl pour produire du bytecode. |
|
B::Assembler |
Assemble du bytecode Perl. |
|
B::Bblock |
Parcours les blocs basiques dans l'arbre syntaxique. |
|
B::Bytecode |
Utilise la sortie en bytecode du compilateur Perl. |
|
B::C |
Utilise la sortie de traduction en C du compilateur Perl. |
|
B::CC |
Utilise la sortie traduction optimisée en C du compilateur Perl. |
|
B::Debug |
Parcours l'arbre syntaxique Perl en affichant les infos de débogage à propos des opérations atomiques. |
|
B::Deparse |
Utilise la sortie du compilateur Perl pour reproduire du code Perl. |
|
B::Disassembler |
Désassemble du bytecode Perl. |
|
B::Lint |
Décèle les constructions douteuses. |
|
B::Showlex |
Montre les variables lexicales utilisées dans des fonctions ou des fichiers. |
|
B::Stash |
Montre quelles tables de symboles sont chargées. |
|
B::Terse |
Parcours l'arbre syntaxique Perl en affichant des infos laconiques à propos des opérations atomiques. |
|
B::Xref |
Génère des rapports avec des références croisées pour les programmes Perl. |
|
ByteLoader |
Charge du code Perl compilé en bytecode. |
|
O |
Fournit une interface générique aux sorties (backends) du compilateur Perl. |
32-1-t. Modules relatifs à Microsoft▲
Si vous possédez la distribution Perl pour les systèmes Microsoft provenant d'ActiveState, les modules suivants, qui sont uniquement pour Microsoft, sont d'ores et déjà inclus pour vous. Si vous avez juste été chercher les sources de la distribution standard (en voulant peut-être la compiler avec l'émulateur d'environnement Unix de Cygwin), mais que vous tournez sur Wintel, vous pouvez obtenir tous ces modules depuis CPAN.
|
Module |
Description |
|---|---|
|
Win32::ChangeNotify |
Surveille les événements relatifs aux fichiers et aux répertoires. |
|
Win32::Console |
Utilise la console Win32 et les fonctions du mode caractère. |
|
Win32::Event |
Utilise les objets événements Win32 depuis Perl. |
|
Win32::EventLog |
Traite les journaux d'événements Win32 depuis Perl. |
|
Win32::File |
Gère les attributs de fichier en Perl. |
|
Win32::FileSecurity |
Gère les FileSecurity Discretion Access Control Lists (Listes de contrôle d'accès discret aux fichiers sécurisés) en Perl. |
|
Win32::IPC |
Charge la classe de base pour les objets de synchronisation Win32. |
|
Win32::Internet |
Accède aux fonctions de WININET.DLL. |
|
Win32::Mutex |
Utilise les objets mutex Win32 en Perl. |
|
Win32::NetAdmin |
Gère les groupes et utilisateurs réseau en Perl. |
|
Win32::NetResource |
Gère les ressources réseau en Perl. |
|
Win32::ODBC |
Utilise les extensions ODBC pour Win32. |
|
Win32::OLE |
Utilise les extensions d'automatisation OLE. |
|
Win32::OLE::Const |
Extrait les définitions de constantes depuis TypeLib. |
|
Win32::OLE::Enum |
Utilise OLE Automation Collection Objects (objets collections d'automatisation OLE). |
|
Win32::OLE::NLS |
Utilise OLE National Langage Support (support de langages nationaux OLE). |
|
Win32::OLE::Variant |
Crée et modifie les variables OLE VARIANT. |
|
Win32::PerfLib |
Accède au compteur de performance de Windows NT. |
|
Win32::Process |
Crée et manipule des processus. |
|
Win32::Semaphore |
Utilise les objets sémaphores Win32. |
|
Win32::Service |
Gère les services du système. |
|
Win32::Sound |
Joue avec les sons Windows. |
|
Win32::TieRegistry |
Trifouille la base de registres |
|
Win32API::File |
Accède aux appels bas niveau de l'API système Win32 pour les fichiers et les répertoires. |
|
Win32API::Net |
Gère les comptes LanManager de Windows NT. |
|
Win32API::Registry |
Accède aux appels bas niveau de l'API système Win32 depuis WINREG.H. |
32-2. Benchmark▲
use Benchmark qw(timethese cmpthese timeit countit timestr);
# Vous pouvez toujours passer du code sous forme de chaînes :
timethese $compteur, {
'Nom1' => '...code1...',
'Nom2' => '...code2...',
};
# Ou sous forme de références à des sous-programmes :
timethese $compteur, {
'Nom1' => sub { ...code1... },
'Nom2' => sub { ...code2... },
};
cmpthese $compteur, {
'Nom1' => '...code1...',
'Nom2' => '...code2...',
};
$t = timeit $compteur, ' code';
print "$compteur boucles de code ont pris : ", timestr($t), "\n";
$t = countit $temps, ' code';
$compteur = $t->iters;
print "$compteur boucles de code ont pris : ", timestr($t), "\n";Le module Benchmark peut vous aider à déterminer lequel parmi plusieurs choix possibles s'exécute le plus rapidement. La fonction timethese lance les segments de codes spécifiés le nombre de fois demandé et rapporte combien de temps a pris chaque segment. Vous pouvez obtenir un joli diagramme trié si vous appelez cmpthese de la même façon.
Les segments de codes peuvent être passés sous forme de références de fonctions au lieu de chaînes (en fait, il faut que ce soit des références de fonctions si vous utilisez des variables lexicales provenant de la portée de l'appelant), mais la surcharge engendrée par l'appel peut influencer les mesures de temps. Si vous ne demandez pas assez d'itérations pour avoir une bonne mesure, la fonction émet un avertissement.
Des interfaces de bas niveau sont disponibles pour lancer un seul morceau de code soit un certain nombre de fois (timeit), soit un certain nombre de secondes (countit). Ces fonctions renvoient des objets Benchmark (voir une description dans la documentation en ligne). Avec countit, vous savez que cela a tourné pendant assez longtemps pour éviter les avertissements, car vous aviez spécifié un temps d'exécution minimum.
Pour tirer le meilleur profit du module Benchmark, vous aurez besoin d'un peu d'entraînement. En général, il n'est pas suffisant de lancer deux ou trois algorithmes sur le même jeu de données, car les mesures de temps ne reflètent que la manière dont ces algorithmes se sont bien comportés sur ce jeu de données précis. Pour obtenir une meilleure impression sur le cas général, vous aurez besoin de lancer plusieurs ensembles de benchmarks en faisant varier les jeux de données utilisés.
Par exemple, imaginez que vous vouliez savoir le meilleur moyen d'obtenir la copie d'une chaîne sans ses deux derniers caractères. Vous pensez à quatre façons de faire cela (il y en a d'autres bien sûr) : chop deux fois, copier et substituer, ou utiliser substr soit sur la partie gauche, soit sur la partie droite d'un assignement. Vous testez ces algorithmes sur des chaînes de longueur 2, 200 et 20_000 :
use Benchmark qw/countit cmpthese/;
sub lancer($) { countit(5, @_) }
for $taille (2, 200, 20_000) {
$c = "." x $taille;
print "\nTAILLE_DONNEES = $taille\n";
cmpthese {
chop2 => lancer q{
$t = $c; chop $t; chop $t;
},
subs => lancer q{
($t = $c) =~ s/..\Z//s;
},
substr_g => lancer q{
$t = $c; substr($t, -2) = ";
},
substr_d => lancer q{
$t = substr($c, 0, length($c) -2);
},
};
}ce qui affiche :
TAILLE_DONNEES = 2
Rate substr_g subs chop2 substr_d
substr_g 579109/s -- -2% -36% -37%
subs 593574/s 2% -- -34% -36%
chop2 903371/s 56% 52% -- -2%
substr_d 920343/s 59% 55% 2% --
TAILLE_DONNEES = 200
Rate subs substr_g substr_d chop2
subs 561402/s -- -2% -8% -24%
substr_g 574852/s 2% -- -6% -22%
substr_d 610907/s 9% 6% -- -17%
chop2 737478/s 31% 28% 20% --
TAILLE_DONNEES = 20000
Rate substr_d subs substr_g chop2
substr_d 35885/s -- -45% -45% -46%
subs 65113/s 81% -- -1% -3%
substr_g 65472/s 82% 1% -- -2%
chop2 66837/s 86% 3% 2% --Avec de petits jeux de données, l'algorithme « substr_d » tourne 2 % plus rapidement que l'algorithme « chop2 », mais sur de grands jeux de données, il tourne 46 % plus lentement.
Sur des jeux de données vides (aucun de montré ici), le mécanisme de substitution est le plus rapide. Il n'y a donc pas de solution meilleure que les autres dans tous les cas possibles et même ces mesures ne racontent pas toute l'histoire, puisque vous êtes toujours à la merci de votre système d'exploitation et de la bibliothèque C avec laquelle Perl a été compilé. Ce qui est bon pour vous peut devenir mauvais pour quelqu'un d'autre. Cela prend un certain temps pour être adroit avec les benchmarks. Entretemps, cela facilite les choses d'être un bon menteur.
32-3. Carp▲
use Carp;
croak "Nous en sommes là !";
use Carp qw(:DEFAULT cluck);
cluck "Voilà comment nous sommes arrivés là !";Le module Carp vous permet d'écrire des modules dont les fonctions rapportent les erreurs de la même façon que les opérateurs internes du point de vue de l'utilisateur du module. Le module Carp fournit des routines que vous utilisez pratiquement comme les fonctions internes standard warn et die, mais qui changent le nom de fichier et le numéro de ligne de façon à ce que l'erreur ait l'air de provenir du code utilisateur plutôt que de votre code. En bref, Carp est un moyen formidable de renvoyer la faute sur quelqu'un d'autre que soi.
Il existe en fait quatre fonctions. La fonction carp marche comme l'opérateur warn,mais avec les informations sur le nom de fichier et le numéro de ligne relatives à l'appelant. La fonction croak marche comme die en levant une exception, mais en donnant là encore des informations relatives à l'appelant. Si vous préférez une longue complainte, utilisez cluck et confess au lieu de carp et croak respectivement, et vous obtiendrez une trace complète de la pile rapportant qui a appelé qui et armé de quels arguments (sans aucun doute le colonel Moutarde, dans la bibliothèque avec une clef anglaise). Vous devez importer cluck explicitement, car il n'est pas exporté normalement. Les gens ne veulent pas en général des traces complètes de la pile pour de simples avertissements, pour une raison ou pour une autre.
32-4. CGI▲
use CGI qw(:standard);
$qui = param("Nom");
$tel = param("Telephone");
@choix = param("Choix");Le module CGI vous aide à gérer des formulaires HTML, spécialement les formulaires en plusieurs étapes où il est critique de passer d'une étape à une autre. L'exemple extrêmement simple ci-dessus s'attend à traiter un formulaire avec deux paramètres prenant des valeurs scalaires, comme des champs de texte ou des boutons radio et un autre prenant une valeur multiple, comme des listes déroulantes spécifiées avec « MULTIPLE ». Le module est encore plus sympathique que cela à plusieurs niveaux, en supportant des fonctionnalités comme le traitement des cookies, les valeurs persistantes pour les caddies multiécrans et la génération automatique de listes HTML et de tables que vous pouvez extraire d'une base de données pour n'en citer que quelques-unes. Le support de l'exécution à grande vitesse de scripts Perl précompilés via les services de mod_perl d'Apache est également fourni. Le livre de chez O'Reilly & Associates Writing Apache Modules with Perl and C, de Lincoln Stein et Doug MacEachern, vous dira tout sur ce sujet.
32-5. CGI::Carp▲
use CGI::Carp;
warn "Celle-ci est une complainte"; # Estampille avec le nom du
# programme et la date
die "Mais celle-là est sérieuse"; #, Mais ne cause pas d'erreur
# serveur 500
use CGI::Carp qw(carpout); # Importe cette fonction
open(LOG, "> >/var/tmp/mon_cgi-log"
or die "Impossible d'ajouter à mon_cgi-log : $!\n";
carpout(*LOG); # Utilise maintenant le journal
# d'erreurs spécifiques au programme
use CGI::Carp qw(fatalsToBrowser);
die "Les messages d'erreurs fatales sont maintenant envoyés aussi au navigateur";Le module CGI::Carp fournit des versions des fonctions internes Perl warn et die, plus les fonctions carp, cluck, confess et croak du module Carp qui sont plus parlantes et plus sûres également. Elles sont plus parlantes, car chaque message inclut la date et l'heure avec le nom du programme qui a émis les messages, ce qui est une aide précieuse lorsque vous utilisez un fichier journal partagé par une centaine de programmes différents qui le polluent tous en même temps avec un millier de messages différents.
Le module est également agréable pour les surfeurs du Web, puisque la mort prématurée d'un script CGI a tendance à causer des erreurs absconses « Server 500 » lorsque l'en-tête HTTP correct ne part pas du serveur avant que votre programme ne trépasse, et ce module s'assure que cela ne se produit pas. La fonction carpout redirige tous les avertissements et toutes les erreurs vers le handle de fichier spécifié. La directive fatalsToBrowser envoie également une copie de tels messages au navigateur de l'utilisateur. Ces services facilitent le débogage des problèmes dans les scripts CGI.
32-6. Class::Struct▲
use Class::Struct;
struct Chef => { # Crée un constructeur Chef->new().
nom => '$', # La méthode nom() accède maintenant à une
# valeur scalaire.
salaire => '$', # Ainsi que salaire().
debut => '$', # Ainsi que debut().
};
struct Boutique => { # Crée un constructeur Boutique->new().
proprio => '$', # La méthode proprio() accède maintenant à
# un scalaire.
adrs => '@', # Et la méthode adresse() accède à un tableau.
stock => '%', # Et la méthode stock() accède à un hachage.
patron => 'Chef' # Initialise avec Chef->new().
};
$magasin = Boutique->new();
$magasin->proprio('Abdul Alhazred');
$magasin->adrs(0, 'Miskatonic University');
$magasin->adrs(1, 'Innsmouth, Mass.');
$magasin->stock("livres", 208);
$magasin->stock("charmes", 3);
$magasin->stock("potions", "aucune");
$magasin->patron->nom('Dr. L. P. Hache');
$magasin->patron->salaire('folie');
$magasin->patron->debut(scalar localtime)Le module Class:Struct fournit un moyen de « déclarer » une classe ayant des objets dont les champs sont d'un certain type. La fonction qui fait cela est appelée struct. Comme les structures d'enregistrements ne sont pas des types de base en Perl, chaque fois que vous désirez créer une classe pour fournir un objet ressemblant à une donnée d'enregistrement, vous devez définir une méthode constructeur ainsi que des méthodes accesseurs pour chaque donnée de champ, quelquefois appelées méthodes « wrapper ». La fonction struct du module Class::Struct vous soulage de cette tâche en créant une classe à la volée. Vous n'avez qu'à lui communiquer qu'elles doivent être les données membres, ainsi que leur type. La fonction crée une méthode constructeur appelée new dans le paquetage spécifié par le premier argument, plus une méthode accesseur d'attribut pour chaque membre, comme spécifié par le second argument, qui doit être une référence de hachage.
Les types de champ sont spécifiés, soit en tant que types internes en utilisant les symboles habituels « $ », « @ », « % » et « & », soit en tant qu'une autre classe en employant le nom de la classe. Le type de chaque champ sera forcé lorsque vous essayerez de modifier la valeur.
Beaucoup de modules standards utilisent Class:Struct pour créer leurs objets et accesseurs, y compris Net::hostent et User::pwent, dont vous pouvez regardez les sources et vous en servir comme modèles. Voir également les modules CPAN Tie::SecureHash et Class::Multimethods pour des approches plus élaborées de l'autogénération de classes et de méthodes accesseurs. Voir la section Gestion des données d'instance au chapitre 12, Objets.
32-7. Config▲
use Config;
if ($Config{cc} =~ /gcc/) {
print "Ce perl a été compilé avec GNU C.\n";
}
use Config qw(myconfig config_sh config_vars);
print myconfig(); # comme perl -V sans aucun motif
print config_sh(); # donne absolument tout
config_vars qw/osname osvers archname/;Le mécanisme de configuration utilisé pour compiler et installer Perl rassemble une profusion d'informations sur votre système. Le module Config exporte par défaut une variable de hachage liée avec tie, nommée %Config, qui donne accès à environ 900 valeurs de configuration différentes. (Ces valeurs sont également accessibles à travers l'option -V:MOTIF de la ligne de commande de Perl.) Config fournit également trois fonctions qui donnent un accès à ces valeurs dans le style du shell, comme montré ci-dessus. Par exemple, le dernier appel pourrait afficher :
osname='linux';
osvers='2.4.2';
archname='i386-linux';La documentation en ligne du module décrit les variables de configuration et leurs valeurs possibles. Prenez garde si vous déplacez votre exécutable perl vers un système autre que celui sur lequel il a été compilé, ces valeurs peuvent ne pas refléter la réalité actuelle ; par exemple, si vous faites tourner un binaire Linux ou Solaris sur un système BSD.
32-8. CPAN▲
# Obtient un shell CPAN interactif.
%perl -MCPAN -e shell
# S'enquiert juste des recommandations de mise à niveau.
% perl -MCPAN -e 'CPAN::Shell->r'
# Installe le module indiqué en mode batch.
% perl -MCPAN -e "install Class::Multimethods"Le module CPAN est une interface automatisée et conviviale au Comprehensive Perl Archive Network, décrit au chapitre 22, CPAN. Au contraire de la plupart des modules que vous pouvez rencontrer, il est destiné à être invoqué depuis la ligne de commande, exactement comme un petit programme. La première fois que vous l'appelez, le module vous demande le site miroir CPAN par défaut et d'autres renseignements dont il a besoin. Après cela, vous pouvez lancer son shell interactif pour faire des requêtes et sélectionner des modules à installer, demander au module des recommandations sur les modules devant être remis à niveau ou simplement lui faire installer un module particulier.
32-9. Cwd▲
use Cwd;
$rep = getcwd(); # Où suis-je ?
use Cwd 'chdir';
chdir "/tmp"; # Met à jour $ENV{PWD}.
use Cwd 'realpath';
print realpath("/usr////spool//mqueue/../"); # affiche /var/spoolLe module Cwd fournit des fonctions indépendantes de la plate-forme pour déterminer le répertoire de travail courant de votre processus. C'est mieux que de lancer un shell exécutant pwd(1), car les systèmes non conformes à POSIX ne garantissent pas qu'ils connaissent une telle commande et Perl ne se limite pas uniquement à tourner sur les plates-formes POSIX. La fonction getcwd, laquelle est exportée par défaut, renvoie le répertoire de travail courant en utilisant le mécanisme réputé pour être le plus sûr sur la plate-forme courante. Si vous importez la fonction chdir, elle supplante l'opérateur interne avec celui du module, lequel met à jour la variable d'environnement $ENV{PWD} ; les commandes que vous pourriez lancer ensuite et qui tiendraient compte de cette variable auraient alors une vision cohérente de leur univers. La fonction realpath résout dans son argument représentant un nom de chemin tous les liens symboliques et tous les composants de chemin relatif afin de renvoyer un chemin complet de répertoire sous une forme canonique, exactement comme realpath(3).
32-10. Data::Dumper▲
use Data::Dumper;
print Dumper($magasin);Lorsqu'on l'utilise sur l'exemple tiré de la définition de Class::Struct, ceci affiche :
$VAR1 = bless( {
'Boutique::patron' => bless( {
'Chef::salaire' => 'folie',
'Chef::nom' => 'Dr. L. P. Hache',
'Chef::debut' => 'Fri Apr 13 19:33:04 2001'
}, 'Chef' ),
'Boutique::stock' => {
'livres' => 208,
'charmes' => 3,
'potions' => 'aucune'
},
'Boutique::proprio' => 'Abdul Alhazred',
'Boutique::adrs' => [
'Miskatonic University',
'Innsmouth, Mass.'
]
}, 'Boutique' );La fonction Dumper du module Data::Dumper prend une liste de scalaires (incluant des références, qui peuvent même se référer à des objets) et renvoie une chaîne affichable ou evaluable qui reproduit précisément une copie fidèle de l'original. Vous pouvez utiliser ceci pour écrire une version de sauvegarde d'une structure de donnée dans un fichier ordinaire sur disque ou dans un fichier DBM, ou encore la passer à un autre processus via un pipe ou une connexion socket. Ce module peut être utilisé avec les modules MLDBM de CPAN et DB_File pour implémenter un fichier DBM à même de stocker de manière transparente des valeurs de données complexes, et non seulement des chaînes à plat. D'autres modules de transformation en chaînes (stringification) (ou sérialisation, ou formatage de présentation, marshalling) incluent Storable et FreezeThaw, tous deux disponibles depuis CPAN.
32-11. DB_File▲
use DB_File;Lie avec tie un hachage à un fichier dans le style de DBM :
tie(%hachage, "DB_File", $fichier) # Ouvre une base de données.
or die "Impossible d'ouvrir $fichier : $!";
$v = $hachage{"clef"}; # Extrait depuis la base de données.
$hachage{"clef"} = "valeur"; # Positionne une valeur dans la base.
untie %hachage;Lie avec tie un hachage à un fichier B-tree (arbre balancé ou équilibré), mais continue d'y accéder en tant que hachage DBM ordinaire :
tie(%hachage, "DB_File", "mon_arbre", O_RDWR|O_CREAT, 0666, $DB_BTREE)
or die "Impossible d'ouvrir le fichier 'mon_arbre' : $!";
while (($c, $v) = each %hachage) { # Parcourt dans l'ordre
print "$c => $v\n";
}Lie avec tie un tableau à un fichier texte brut :
tie(@lignes, "DB_File", $fic_texte, O_RDWR|O_CREAT, 0666, $DB_NUM_ENREG)
or die "Impossible d'ouvrir le fichier texte $fic_texte : $!";
# Écrit quelques lignes dans le fichier, en écrasant les anciennes.
$lignes[0] = "première ligne";
$lignes[1] = "deuxième ligne";
$lignes[2] = "troisième ligne";
push @lignes, "pénultième", "dernière"; # Met deux lignes à la fin
# du fichier
$wc = scalar @lignes; # Compte le nombre de lignes
$derniere = pop @lignes; # Supprime et extrait la dernière
# ligneLe module DB_File donne un accès lié avec tie à une DB Berkeley.(226) La fonction tie vous donne par défaut une base de données standard dans le style de DBM, avec certaines fonctionnalités que l'on ne retrouve dans aucune bibliothèque DBM : il n'existe pas de limites de taille ni pour les clefs ni pour les valeurs et vos données sont stockées dans un format indépendant de l'ordre des octets.
Le deuxième mécanisme de tie utilise des B-trees (arbres balancés ou équilibrés) pour vous donner un véritable fichier ISAM (Indexed Sequential Access Method, méthode d'accès séquentiel indexé), c'est-à-dire un hachage dont les clefs sont automatiquement triées dans l'ordre alphabétique par défaut, mais configurable par l'utilisateur.
Le troisième mécanisme de tie lie un tableau à un fichier d'enregistrements (des lignes de texte par défaut) de façon à ce que les modifications dans le tableau se répercutent automatiquement sur le disque. Ceci simule un accès aléatoire par numéro de ligne dans un fichier texte ordinaire. L'interface standard est conforme à la version 1.x de Berkeley DB ; si vous souhaitez employer les nouvelles fonctionnalités disponibles dans Berkeley 2.x ou 3.x, utilisez plutôt le module BerkeleyDB de CPAN.
À partir de la version 2.x, Berkeley DB supporte intrinsèquement le verrouillage, ce qui n'était pas le cas dans les versions précédentes. Voir la section Verrouillage de fichier du chapitre 16 pour une description de la manière sûre dont vous pouvez verrouillez n'importe quel type de fichier de base de données en utilisant flock sur un fichier sémaphore.
32-12. Dumpvalue▲
Lorsqu'on l'utilise sur l'exemple tiré de la définition de Class::Struct, ceci affiche :
'Boutique::adrs' => ARRAY(0x816d548)
0 'Miskatonic University'
1 'Innsmouth, Mass.'
'Boutique::patron' => Chef=HASH(0x80f1538)
'Chef::debut' => 'Fri Apr 13 19:33:04 2001'
'Chef::nom' => 'Dr. L. P. Hache'
'Chef::salaire' => 'folie'
'Boutique::proprio' => 'Abdul Alhazred'
'Boutique::stock' => HASH(0x81976d0)
'charmes' => 3
'livres' => 208
'potions' => 'aucune'Il s'agit d'un autre module facilitant l'affichage de données complexes. Il n'est pas tant destiné au formatage de présentation (marshalling) qu'à un affichage agréable. Il est utilisé par la commande x du débogueur Perl. En tant que tel, il offre une quantité impressionnante d'options pour contrôler le format de sortie. Il donne également accès aux tables de symboles de paquetages de Perl pour vider le contenu d'un paquetage entier.
32-13. English▲
use English;
# Utilise des noms dans le style de awk
$RS = ''; # au lieu de $/
while (<>) {
next id $NR < 10; # au lieu de $.
...
}
# Idem, mais encore plus long à la Cobol
$INPUT_RECORD_SEPARATOR = ";
while (<>) {
next if $INPUT_LINE_NUMBER < 10;
...
}Le module English fournit des alias encombrants pour les variables internes à destination des prodigieux dactylos qui ont une haine viscérale des identificateurs non-alphabétiques (et un amour viscéral pour la touche Blocage Majuscules, ou Caps Lock). Comme avec toutes les importations, ces alias ne sont disponibles que dans le paquetage courant. Les variables sont toujours accessibles sous leur véritable nom. Par exemple, un fois que vous avez fait un use de ce module, vous pouvez utiliser $PID si $$ vous dérange ou $PROGRAM_NAME si $0 vous donne mal au cœur. Certaines variables ont plus d'un alias. Voir le chapitre 28, Noms spéciaux pour une description complète de toutes les variables internes et de leur alias en anglais tirés du module English.
32-14. Errno▲
use Errno;
unless (open(HF, $chemin)) {
if ($!{ENOENT}) { # Nous n'avons pas besoin d'importer ceci !
warn "$chemin n'existe pas\n";
else {
warn "Échec de l'ouverture de $chemin : $!";
}
}
use Errno qw(EINTR EIO :POSIX)
if ($! == ENOENT) { ... }Le module Errno rend accessibles les noms symboliques pour l'ensemble des valeurs de statut d'erreur lorsqu'un appel système échoue, mais il ne les exporte pas toutes par défaut. Le module n'a qu'un seul tag d'exportation, « :POSIX », qui n'exporte que les symboles définis dans le standard POSIX 1003.1. Le module rend également magique la variable globale %! en utilisant tie. Vous pouvez indicer le hachage %! en employant n'importe quelle valeur valide d'errno sur votre système, pas seulement les valeurs POSIX, et sa valeur n'est vraie que s'il s'agit de l'erreur actuelle.
32-15. Exporter▲
Dans votre fichier Mon_Module.pm :
package Mon_Module;
use strict;
use Exporter;
our $VERSION = 1.00; # Ou supérieure...
our @ISA = qw(Exporter);
our @EXPORT = qw(f1 %h); # Symboles importés par défaut.
our @EXPORT_OK = qw(f2 f3); # Symboles importés seulement sur demande.
our %EXPORT_TAGS = ( # Mappage pour :raccourcis.
a => [qw(f1 f2 f3)],
b => [qw(f2 %h)],
);
# Votre code ici.
1;Depuis un programme ou un autre module qui fait un use du vôtre :
use Mon_Module; # Importe tout ce qu'il a dans @Export.
use Mon_Module (); # Charge le module sans rien importer.
use Mon_Module "f1", "f2", "%h"; # Deux fonctions et une variable.
use Mon_Module qw(:DEFAULT f3); # Tout ce qu'il y a dans @Export +
# une fonction.
use Mon_Module "f4"; # Erreur fatale, car f4 n'est pas exportée.Dès que quelqu'un invoque une déclaration use pour charger votre module, il appelle la méthode import depuis votre module pour rapatrier tous les symboles dont il a besoin dans le paquetage de l'appelant. Votre module (celui qui fait les exportations) peut définir la méthode import comme il le souhaite, mais la manière standard est d'en hériter à partir du module de classe Exporter. C'est ce que fait le code ci-dessus.
Le module Exporter sert de classe de base pour les modules qui souhaitent établir leurs propres exportations. Curieusement, les modules orientés objet n'utilisent généralement pas Exporter, puisqu'ils n'exportent normalement rien (les appels de méthodes n'ont pas besoin d'être exportés). Toutefois, le module Exporter lui-même est accessible de manière orientée objet à cause du tableau @ISA que vous avez installé, comme dans notre exemple. Lorsqu'un autre programme ou qu'un autre module fait un use de votre module, vous utiliserez automatiquement la méthode Exporter::import par le biais de l'héritage.
Le tableau @EXPORT du module contient une liste de symboles (des fonctions et même des variables) que le code appelant importe automatiquement avec une instruction use sans rien d'autre. Le tableau @EXPORT_OK est composé des symboles qui peuvent être importés si on les demande nommément. Le numéro $VERSION est consulté si l'instruction use demande une version particulière (ou plus récente) du module. Beaucoup, beaucoup d'autres fonctionnalités sont disponibles. Voir le chapitre 11, Modules, ainsi que la page de man en ligne du module Exporter.
32-16. Fatal▲
Le module Fatal fait échouer les fonctions plus spectaculairement. Il remplace les fonctions qui normalement retournent faux en cas d'échec avec des sur-couches qui lèvent une exception si la véritable fonction renvoie faux. Ainsi, vous pouvez utiliser en toute sûreté ces fonctions sans tester explicitement leur valeur de retour à chaque appel.
Les fonctions définies par l'utilisateur et les fonctions internes peuvent toutes être enrobées, sauf les fonctions internes qui ne peuvent pas être exprimées par des prototypes. Une tentative de supplanter une fonction interne non enrobable lève une exception. Ceci inclut system, print, printf, exec, split, grep et map ou plus génériquement, toute FONC pour laquelle prototype "CORE::FONC" renvoie faux, y compris la fonction prototype elle-même.
Si le symbole :void apparaît dans la liste d'importation, les fonctions citées ensuite dans la liste se limitent à lever une exception lorsque la fonction est appelée dans un contexte void c'est-à-dire, lorsque la valeur renvoyée est ignorée. (Faites attention à la dernière instruction dans un sous-programme.) Par exemple :
32-17. Fcntl▲
use Fcntl; # Importe les constantes standard de fcntl.h.
use Fcntl ":flock"; # Importe les constantes LOCK_*.
use Fcntl ":seek"; # Importe SEEK_CUR, SEEK_SET et SEEK_END.
use Fcntl ":mode"; # Importe les constantes de test de stat S_*.
use Fcntl ":Fcompat"; # Importe les constantes F*.Le module Fcntl fournit des constantes à employer avec diverses fonctions internes de Perl. L'ensemble importé par défaut inclut des constantes comme F_GETFL et F_SETFL pour fcntl, SEEK_SET et SEEK_END pour seek et sysseek et O_CREAT et O_EXCL pour sysopen. Les tags d'importation supportés incluent « :flock » pour accéder aux constantes LOCK_EX, LOCK_NB, LOCK_SH et LOCK_UN pour flock ; « :mode » pour aller chercher les constantes de sys/stat.h comme S_IRUSR et S_ISFIFO ; « :seek » pour obtenir les trois arguments de seek et sysseek ; et « :Fcompa t » pour avoir les symboles désuets commençant par un « F », mais pas par« F_ », comme FAPPEND, FASYNC et FNONBLOCK. Voir la documentation en ligne du module Fcntl et la documentation de votre système d'exploitation pour les appels systèmes concernés, comme fcntl(2), lseek(2), open(2) et stat(2).
32-18. File::Basename▲
use File::Basename;
$nom_complet = "/usr/local/src/perl-5.6.1.tar.gz";
$fichier = basename($nom_complet);
# fichier= "perl-5.6.1.tar.gz"
$rep = dirname($nom_complet);
rep="/usr/local/src"
($fichier,$rep,$ext) = fileparse($nom_complet, qr/\..*/);
# rep="/usr/local/src/" fichier="perl-5" ext=".6.1.tar.gz"
($fichier,$rep,$ext) = fileparse($nom_complet, qr/\.[^.]*/);
# rep="/usr/local/src/" fichier="perl-5.6.1.tar" ext=".gz"
($fichier,$rep,$ext) = fileparse($nom_complet, qr/\.\D.*/);
# rep="/usr/local/src/" fichier="perl-5.6.1" ext=".tar.gz"
($fichier,$rep,$bak) = fileparse("/tmp/fichier.bak",
qr/~+$/, qr/\.(bak|orig|save)/)
# rep="/tmp/" fichier="fichier" bak=".bak";
($fichier,$rep,$bak) = fileparse("/tmp/fichier~",
qr/~+$/, qr/\.(bak|orig|save)/)
# rep="/tmp/" fichier="fichier" bak="~";Le module File::Basename fournit des fonctions pour décomposer les noms de chemin en leurs composants individuels. La fonction dirname sort la portion représentant le répertoire et basename la portion ne représentant pas le répertoire. La fonction plus élaborée fileparse distingue dans le nom du chemin complet, le nom du répertoire, le nom du fichier et le suffixe ; vous devez fournir une liste d'expressions régulières décrivant les suffixes qui vous intéressent. Les exemples ci-dessus illustrent comment le choix de motifs pour le suffixe affecte le résultat. Par défaut, ces fonctions analysent des noms de chemin selon les conventions natives de votre plate-forme. La fonction fileparse_set_fstype sélectionne les règles d'analyse pour une plate-forme différente, comme fileparse_set_fstype("VMS") pour analyser les noms utilisant les règles de VMS, même lorsque l'on tourne sur des systèmes non VMS.
32-19. File::Compare▲
use File::Compare;
printf "fichier_A et fichier_B sont %s.\n",
compare("fichier_A","fichier_B") ? "différents" : "identiques";
use File::Compare 'cmp';
sub arranger($) {
my $ligne = $_[0];
for ($ligne) {
s/\^s+//; # Coupe les espaces au début.
s/\s+$//; # Coupe les espaces à la fin.
}
return uc($ligne);
}
if (not cmp("fichier_A", "fichier_B",
sub {arranger $_[0] eq arranger $_[1]} ) {
print "fichier_A et fichier_B sont à peu près pareils.\n";
}Le module File::Compare fournit une fonction, compare, qui compare le contenu des deux fichiers qu'on lui passe. Elle renvoie 0 si les fichiers contiennent les mêmes données, 1 s'ils contiennent des données différentes et -1 si l'on a rencontré une erreur en accédant les fichiers cités. Si vous passez comme troisième argument une référence de sous-programme, cette fonction est appelée répétitivement pour déterminer si deux lignes sont équivalentes. Pour assurer la compatibilité avec le programme cmp(1), vous pouvez explicitement importer la fonction en tant que cmp. (Ceci n'affecte pas l'opérateur binaire cmp.)
32-20. File::Copy▲
use File::Copy;
copy("/tmp/fichier_A", "/tmp/fichier_A.orig") or die "copie échouée : $!";
copy("/etc/motd", *STDOUT) or die "copie échouée : $!";
move("/tmp/fichier_A", "/tmp/fichier_A.orig") or die "déplacement échoué : $!";
use File::Copy qw/cp mv/; # Importe les noms Unix habituels.
cp("/tmp/fichier_A", "/tmp/fichier_A.orig") or die "copie échouée : $!";
mv("/tmp/fichier_A", "/tmp/fichier_A.orig") or die "déplacement échoué : $!";Le module File::Copy exporte deux fonctions, copy et move, qui respectivement copie ou renomme leur premier argument vers leur second, de la même manière qu'un appel aux commandes Unix cp(1) et mv(1) (noms que vous pouvez utiliser si vous les importez explicitement). La fonction copy accepte également comme arguments des handles de fichiers. Ces fonctions renvoient vrai lorsqu'elles fonctionnent et faux lorsqu'elles échouent, en positionnant $! ($OS_ERROR) de manière appropriée. (Malheureusement, vous ne pouvez pas dire si quelque chose comme « Permission denied » s'applique au premier fichier ou au second.) Ces fonctions sont en quelque sorte un compromis entre le confort et la précision. Elles ne supportent pas les nombreuses options et optimisations de cp(1) et mv(1), comme la copie récursive, la copie de sauvegarde automatique, la conservation des dates et heures originales et des informations sur les propriétaires des fichiers, ou la confirmation interactive. Si vous avez besoin de ces fonctionnalités, il vaut certainement mieux appeler les versions de votre plate-forme pour ces commandes.(227) Gardez bien à l'esprit que tous les systèmes ne supportent pas les mêmes commandes ou n'emploient pas les mêmes options pour ces commandes.
system("cp -R -pi /tmp/rep1 /tmp/rep2") == 0
or die "le statut de la commande externe cp est $?";32-21. File::Find▲
use File::Find;
# Affiche tous les répertoires en dessous du répertoire courant.
find sub { print "$File::Find::name\n" if -d }, ".";
# Calcule l'espace total utilisé par les fichiers des répertoires listés.
@reps = @ARGV ? @ARGV : ('.');
my $tot = 0;
find sub { $tot += -s }, @reps;
print "@reps contiennent $tot octets\n";
# Modifie le comportement par défaut pour traverser les liens
# symboliques et visiter les sous-répertoires en premier
find { wanted => \&ma_fonction, follow => 1, bydepth=>1 }, ".";La fonction find du module File::Find descend récursivement dans des répertoires. Son premier argument doit être une référence à une fonction et tous les arguments suivants doivent être des répertoires. La fonction est appelée pour chaque fichier des répertoires listés. À l'intérieur de cette fonction, la variable $_ est positionnée avec le nom de base du fichier actuellement visité et le répertoire de travail courant du processus est par défaut mis à ce répertoire. La variable de paquetage $File::Find::name est le nom de chemin complet du fichier visité. Une autre convention d'appel prend comme premier argument une référence à un hachage contenant des spécifications d'options, incluant « wanted », « bydepth », « follow », « follow_fast », « follow_skip », « no_chdir », « untaint », « untaint_pattern » et« untaint_skip », comme le détaille complètement la documentation en ligne. Ce module est également utilisé par le programme de conversion standard find2perl(1) qui vient avec la distribution Perl.
32-22. File::Glob▲
use File::Glob ':glob'; # Supplante le glob interne.
@liste = <*.[Cchy]>; # Utilise maintenant le glob POSIX, pas le
# glob csh.
use File::Glob qw(:glob csh_glob);
@sources = bsd_glob("*.{C,c,h,y,pm,xs}", GLOB_CSH);
@sources = csh_glob("*.{C,c,h,y,pm,xs}"); # (idem)
use File::Glob ':glob';
# appelle glob avec des arguments supplémentaires
$rep_maison = bsd_glob('~hackerjr', GLOB_TILDE | GLOB_ERR);
if (GLOB_ERROR) {
# Une erreur s'est produite en développant le répertoire maison
}La fonction bsd_glob du module File::Glob implémente la routine glob(3) de la librairie C. Un second argument facultatif contient des options gouvernant des propriétés supplémentaires de correspondances. Le tag d'importation :glob importe à la fois la fonction et les options nécessaires.
Le module implémente également une fonction csh_glob. C'est elle que l'opérateur interne de Perl glob et l'opérateur de globalisation de fichiers GLOBPAT appellent réellement. Appeler csh_glob revient (en grande partie) à appeler bsd_glob de cette manière :
bsd_glob(@_ ? $_[0] : $_,
GLOB_BRACE | GLOB_NOMAGIC | GLOB_QUOTE | GLOB_TILDE);Si vous importez le tag :glob, tous les appels aux opérateurs internes de globalisation de fichiers dans le paquetage courant appelleront alors réellement la fonction du module bsd_glob à la place de la fonction csh_glob. Une raison pour laquelle vous voudriez faire cela, bien que bsd_glob s'occupe de motifs comprenant des espaces, est que csh_glob s'en occupe d'une manière, heu, historique. Les anciens scripts écriraient <*.c *.h> pour globaliser les deux motifs. De toute façon, aucune des fonctions n'est gênée par des espaces dans les véritables noms de fichiers.
La fonction bsd_glob prend un argument contenant le motif de globalisation de fichiers (et pas un motif d'expression régulière) plus un argument facultatif pour les options. Les noms de fichiers commençant par un point ne correspondent pas à moins de le demander spécifiquement. La valeur de retour est influencée par les options du second argument, qui doivent être des bits joints entre eux par des OU :(228)
GLOB_BRACE
- Traite en amont la chaîne pour développer les chaînes
{motif,motif,...}comme csh(1) le ferait. Le motif{}n'est pas développé pour des raisons historiques, surtout pour faciliter la saisie des motifs de find(1).
GLOB_CSH
- Synonyme de GLOB_BRACE
|GLOB_NOMAGIC|GLOB_QUOTE|GLOB_TILDE.
GLOB_ERR
- Renvoie une erreur lorsque la fonction bsd_glob rencontre un répertoire qu'elle ne peut ouvrir ou lire. D'ordinaire, bsd_glob saute les erreurs pour rechercher d'autres correspondances.
GLOB_MARK
- Ajoute un slash à la fin des répertoires.
GLOB_NOCASE
- Par défaut, les noms de fichiers sont sensibles à la casse (majuscules/minuscules) ; cette option fait que bsd_glob ignore les différences de casse. (Mais voir ci-dessous les exceptions sur les systèmes à la MS-DOS).
GLOB_NOCHECK
- Si le motif ne correspond à aucun nom de chemin, alors bsd_glob renvoie une liste uniquement constituée du motif, comme le fait /bin/sh. Si l'option GLOB_QUOTE est positionnée, les conséquences qu'elle entraîne sont présentes dans le motif renvoyé.
GLOB_NOMAGIC
- Idem que, GLOB_NOCHECK mais le motif n'est renvoyé que s'il ne contient aucun des caractères spéciaux
*,?ou [. NOMAGIC est là pour simplifier l'implémentation du comportement historique de globalisation de csh(1) et ne devrait probablement pas être utilisé ailleurs.
GLOB_NOSORT
- Par défaut, les noms de chemins sont triés dans un ordre croissant (en utilisant les comparaisons de caractères habituelles, sans respecter les valeurs des locales). Cette option évite ce tri avec comme résultat une légère amélioration de la vitesse.
GLOB_QUOTE
- Utilise le caractère antislash \ pour les protections : chaque occurrence dans le motif d'un antislash suivi par un caractère est remplacée par ce caractère, évitant les interprétations spéciales du caractère en question. (Mais voir ci-dessous les exceptions sur les systèmes à la MS-DOS).
GLOB_TILDE
- Autorise l'emploi de motifs dont le premier composant du chemin est
~UTILISATEUR. Si UTILISATEUR est omis, le tilde lui-même (ou suivi par un slash) représente le répertoire maison de l'utilisateur courant.
La fonction bsd_glob renvoie une liste (qui peut être vide) des chemins correspondants, cette liste pouvant devenir marquée si cela importe à votre programme. En cas d'erreur, GLOB_ERROR sera vrai et $! ($OS_ERROR) sera positionnée avec l'erreur système standard. Il est garanti que GLOB_ERROR sera faux s'il ne se passe aucune erreur, et de valoir soit GLOB_ABEND, sinon GLOB_NOSPACE.(GLOB_ABEND signifie que la fonction bsd_glob s'est arrêtée à cause d'une erreur et GLOB_NOSPACE à cause d'un manque de mémoire.) Si bsd_glob a déjà trouvé des chemins correspondant lorsque l'erreur se produit, elle renvoie la liste des noms de fichiers trouvés jusque là, mais positionne aussi GLOB_ERROR. Remarquez que cette implémentation de bsd_glob diffère de la plupart des autres en ce qu'elle ne considère pas ENOENT et ENOTDIR comme des conditions d'arrêt sur erreur. À la place, elle poursuit son traitement malgré ces erreurs, sauf si l'option GLOB_ERR est positionnée.
Si aucune option n'est donnée, les comportements par défaut de votre système sont respectés, c'est-à-dire que les noms de fichiers qui différent seulement par leur casse seront confondus sur VMS, OS/2, les vieux Mac OS (mais pas Mac OS X) et les systèmes Microsoft (mais pas lorsque Perl a été compilé avec Cygwin). Si vous ne donnez aucune option et que vous voulez toujours que ce comportement s'applique, vous devez alors inclure GLOB_NOCASE dans les options. Quel que soit le système sur lequel vous êtes, vous pouvez modifier votre comportement par défaut en important à l'avance les options :case ou :nocase.
Sur les systèmes à la MS-DOS, l'antislash est un caractère séparateur de répertoires valide.(229) Dans ce cas, l'emploi d'un antislash comme caractère de protection (via GLOB_QUOTE) interfère avec l'emploi de l'antislash en tant que séparateur de répertoires. La meilleure solution (la plus simple et la plus portable) est d'utiliser des slashs comme séparateurs de répertoires, des antislashs pour les protections. De toute façon, cela n'a rien à voir avec les attentes de certains utilisateurs, ainsi les antislashs (sous GLOB_QUOTE) ne protègent que les métacaractères de globalisation [, ], {, }, -, ~ et \ lui-même.Tous les autres antislashs sont passés inchangés, si vous parvenez à en avoir avec le propre mécanisme de Perl pour la protection par antislashs dans les chaînes. Cela peut prendre jusqu'à quatre antislashs pour finalement correspondre à un seul dans le système de fichier. Ceci est tellement complètement délirant que même les utilisateurs des systèmes à la MS-DOS devraient sérieusement penser à employer des slashs. Si vous voulez vraiment utiliser des antislashs, jetez un œil au module standard File::DosGlob qui est plus susceptible de correspondre à vos goûts que la globalisation de fichiers à la mode Unix.
32-23. File::Spec▲
use File::Spec; # style orienté objet
$chemin = File::Spec->catfile("sous_rep", "fichier");
# 'sous_rep/fichier' sur Unix, OS2 ou Mac OS X
# 'sous_rep:fichier' sur les (vieux) Macs d'Apple
# 'sous_rep\fichier' sur Microsoft
$chemin = File::Spec->catfile("", "rep1", "rep2", "fichier");
# '/rep1/rep2/fichier' sur Unix, OS2 ou Mac OS X
# ':rep1:rep2:fichier' sur les (vieux) Macs d'Apple
# '\rep1\rep2\fichier' sur Microsoft
use File::Spec::Unix;
$chemin = File::Spec->catfile("sous_rep", "fichier");
# 'sous_rep/fichier' (même si exécuté sur des systèmes non-Unix)
use File::Spec::Mac;
$chemin = File::Spec->catfile("sous_rep", "fichier");
# 'sous_rep:fichier'
use File::Spec::Win32;
$chemin = File::Spec->catfile("sous_rep", "fichier");
# 'sous_rep\fichier'
# Utilise plutôt l'interface fonctionnelle.
use File::Spec::Functions;
$chemin = catfile("sous_rep", "fichier");La famille de modules File::Spec vous permet de construire des chemins utilisant des répertoires et des noms de fichiers sans coder en dur les séparateurs de répertoires spécifiques aux plates-formes. Les systèmes supportés incluent Unix, VMS, Mac et Win32. Ces modules offrent tous une méthode de classe catfile qui concatène chaque composant de chemin en utilisant le séparateur de chemin spécifique à la plate-forme. Le module File::Spec renvoie des résultats différents selon votre plate-forme courante. Les autres renvoient des résultats spécifiques à la plate-forme en question. Le module File::Spec::Functions fournit une interface fonctionnelle.
32-24. File::stat▲
use File::stat;
$st = stat($fichier) or die "stat de $fichier impossible : $!";
if ($st->mode & 0111 and $st->nlink > 1) {
print "$fichier est exécutable et possède plusieurs liens\n";
}
use File::stat ":FIELDS";
stat($fichier) or die "stat de $fichier impossible : $!";
if ($st_mode & 0111 and $st_nlink > 1) {
print "$fichier est exécutable et possède plusieurs liens\n";
}
@infos_stat = CORE::stat($fichier); # Utilise la fonction interne,
# même si elle est supplantéeLe module File::stat fournit une interface méthode aux fonctions internes Perl stat et lstat en les remplaçant par des versions renvoyant un objet File::stat (ou undef en cas d'échec). Cet objet possède des méthodes nommées de manière à renvoyer le champ de la structure du même nom depuis l'appel système habituel stat(2) ; il s'agit de dev, ino, mode, nlink, uid, gid, rdev, size, atime, mtime, ctime, blksize et blocks. Vous pouvez également importer les champs de la structure dans votre propre espace de noms en tant que variables ordinaires en utilisant le tag d'importation « :FIELDS ». (Les opérateurs internes stat et lstat continuent à être supplantés.) Ces champs se présentent comme des variables scalaires avec un « st_ » au début du nom du champ. C'est-à-dire que la variable $st_dev correspond à la méthode $st->dev.
32-25. File::Temp▲
use File::Temp qw(tempfile tempdir);
$rep = tempdir(CLEANUP => 1);
($hf, $fichier) = tempfile(DIR => $rep);
($hf, $fichier) = tempfile($exemple, DIR => $rep);
($hf, $fichier) = tempfile($exemple, SUFFIX => ".data");
$hf = tempfile();
use File::Temp ':mktemp';
($hf, $fichier) = mkstemp("fic_tmpXXXXX");
($hf, $fichier) = mkstemps("fic_tmpXXXXX", $suffixe);
$rep_tmp = mkdtemp($exemple);
$fichier_non_ouvert = mktemp($exemple);Nouveauté dans la version 5.6.1 de Perl, le module File::Temp fournit des fonctions pratiques pour créer et ouvrir de manière sûre des fichiers temporaires. Il vaut mieux utiliser ce module qu'essayer de choisir vous-même un fichier temporaire. Sinon, vous tomberez dans les mêmes pièges que tout le monde avant vous. Ce module vous protège aussi bien des situations de concurrence (race conditions) que du danger d'employer des répertoires où d'autres peuvent écrire ; voir le chapitre 23, Sécurité. La fonction tempfile renvoie à la fois un handle de fichier et un nom de fichier. Le plus sûr est d'utiliser ce qui est déjà ouvert et d'ignorer complètement le nom de fichier (excepté peut-être pour les messages d'erreurs). Une fois que le fichier est fermé, il est automatiquement supprimé. Pour assurer une compatibilité avec la bibliothèque C, le tag d'importation :mktemp donne un accès aux fonctions dont les noms sont familiers aux programmeurs C, mais s'il vous plaît, souvenez-vous que les noms de fichiers sont toujours moins sûrs que les handles de fichiers.
32-26. FileHandle▲
use FileHandle;
$hf = new FileHandle;
if ($hf->open("< fichier")) {
print $ligne while defined($ligne = $hf->getline);
$hf->close;
}
$pos = $hf->getpos; # comme tell()
$hf->setpos($pos); # comme seek()
($hf_lec, $hf_ecr) = FileHandle::pipe();
autoflush STDOUT, 1;Le module FileHandle sert surtout de mécanisme pour dissimuler les variables de Perl contenant des ponctuations sous des appellations plus longues, davantage dans le style orienté objet. Il est fourni pour assurer une compatibilité avec des versions antérieures, mais maintenant il s'agit véritablement d'un frontal vers plusieurs modules plus spécifiques, comme IO::Handle et IO::File.(230) Sa meilleure propriété est l'accès de bas niveau qu'il fournit vers certaines fonctions rares de la bibliothèque C (clearerr(3), fgetpos(3), fsetpos(3) et setvbuf (3)).
|
Variable |
Méthode |
|---|---|
|
|
autoflush |
|
|
output_field_separator |
|
|
output_record_separator |
|
|
input_record_separator |
|
|
input_line_number |
|
|
format_page_number |
|
|
format_lines_per_page |
|
|
format_lines_left |
|
|
format_name |
|
|
format_top_name |
|
|
format_line_break_characters |
|
|
format_formfeed |
Au lieu d'écrire :
$hfs = select(HANDLE );
$~ = 'UnFormat';
$|= 1;
select($hfs);vous pouvez juste écrire :
use FileHandle;
Handle->format_name('UnFormat');
Handle->autoflush(1);Actuellement, trois méthodes (output_field_separator, output_record_separator et input_record_separator) ne font que prétendre être des méthodes par handle : les positionner sur un handle affecte tous les handles de fichiers. Elles sont ainsi seulement supportées en tant que méthodes de classes, pas en tant que méthodes par handle de fichier. Cette restriction sera peut-être abandonnée un jour.
Pour obtenir un handle de fichier de portée lexicale, au lieu d'utiliser l'autovivifiation de handle de fichier :
on peut écrire :
use FileHandle;
my $hf = FileHandle->new("< un_fichier")
or die "impossible d'ouvrir un_fichier : $!";FileHandle hérite de IO::File, qui lui-même hérite de IO::Handle et IO::Seekable. Les fonctionnalités du module sont virtuellement toutes accessibles plus efficacement via les appels purs et basiques de Perl, sauf pour les suivants, qui peuvent ne pas tous être implémentés sur les plates-formes non Unix :
HANDLE->blocking(EXPR)
- Appelé avec un argument, active les entrées/sorties non bloquantes si l'argument est faux et désactive les entrées/sorties non bloquantes (c'est-à-dire active les entrées/sorties bloquantes) s'il est vrai. La méthode renvoie la précédente valeur positionnée (ce qui est toujours le comportement actuel si aucun argument n'est donné). En cas d'erreur, blocking positionne
$!et renvoieundef. Ceci pourrait être accompli avecfcntldirectement, mais l'interface FileHandle est plus simple à utiliser.
HANDLE->clearerr
- Appelle la fonction clearerr(3) de la bibliothèque C pour efface les indicateurs internes du handle pour la fin de fichier et le statut d'erreur.
HANDLE->error
- Appelle la fonction ferror(3) de la bibliothèque C pour tester l'indicateur d'erreur pour le handle donné, en renvoyant si cet indicateur interne est positionné ou non. L'indicateur d'erreur ne peut être réinitialisé fiablement que via la méthode clearerr. (Certains systèmes le réinitialisent également en appelant l'opérateur
seek.)
HANDLE->formline(IMAGE, LISTE)
- Cela revient au même que de sauvegarder l'ancienne variable d'accumulateur (
$^A), d'appeler la fonctionformlineavec l'IMAGE et la LISTE données, d'afficher le contenu résultant de l'accumulateur vers le handle donné et enfin de restaurer l'accumulateur original. Par exemple, voici comment afficher une variable représentant un texte long en allant à la ligne à la colonne 72 :
HANDLE->getpos
- Appelle la fonction getpos(3) de la bibliothèque C, offrant ainsi une interface alternative à
tell. Sur certains systèmes (non Unix), la valeur renvoyée peut être un objet complexe et getpos et setpos peuvent être la seule manière de repositionner de manière portable un flux de texte.
HANDLE->new_tmpfile
- Appelle la fonction tmpfile(3) de la bibliothèque C pour créer un nouveau fichier temporaire ouvert en mode lecture-écriture et renvoie un handle sur ce flux. Sur les systèmes où c'est possible, le fichier temporaire est anonyme, c'est-à-dire qu'il est supprimé avec
unlinkaprès sa création tout en restant ouvert. Vous devez utiliser cette fonction ou POSIX::tmpnam comme décrit dans le module POSIX pour créer de manière sûre un fichier temporaire sans vous exposer aux problèmes de sécurités annexes, mais néanmoins sérieux avec les situations de concurrence (N.d.T. : race conditions). Depuis la version 5.6.1 de Perl, le module File::Temp est maintenant l'interface recommandée.
HANDLE->setbuf(TAMPON)
- Appelle la fonction setbuf (3) de la bibliothèque C avec la variable TAMPON donnée. La méthode passe
undefpour indiquer une sortie qui n'utilise pas le mécanisme de tampon. Une variable utilisée comme tampon par setbuf ou setvbuf ne doit pas être modifiée d'aucune manière jusqu'à ce que le handle soit fermé ou jusqu'à ce que la fonction setbuf ou setvbuf soit appelée à nouveau. Sinon il peut en résulter une corruption de mémoire qui vous ferait de la peine.
HANDLE->setpos(EXPR)
- Appelle la fonction fsetpos(3) de la bibliothèque C, offrant ainsi une autre interface à
seek. L'argument ne doit être qu'une valeur correcte renvoyée par getpos, comme décrit précédemment.
HANDLE->setvbuf(TAMPON, TYPE, TAILLE)
- Appelle la fonction setvbuf (3) de la bibliothèque C avec le TAMPON donné. Les constantes standards de la bibliothèque C _IONBF (sans utilisation d'un tampon), _IOLBF (tampon vidé ligne par ligne) et _IOFBF (mécanisme complet de tampon) sont disponibles pour le champ TYPE si elles sont explicitement importées. Voir la mise en garde dans setbuf.
HANDLE->sync
- Appelle la fonction fsync(3) de la bibliothèque C pour synchroniser un fichier dans un état en mémoire vers le support physique. Remarquez que sync n'agit pas sur le handle mais sur le descripteur de fichier, toute donnée conservée dans les tampons ne sera donc pas synchronisée à moins que le tampon ne soit tout d'abord vidé (N.d.T. : flushed).
HANDLE->untaint
- Marque le handle de fichier ou de répertoire en lui fournissant une donnée non marquée. Lorsque l'on tourne en mode marqué (voir le chapitre 23), les données lues depuis des fichiers externes sont considérées comme étant indignes de confiance. N'invoquez pas cette méthode aveuglément : vous court-circuiteriez les meilleures tentatives de Perl pour vous protéger de vous-même.
32-27. Getopt::Long▲
Si votre programme fait :
use Getopt::Long;
GetOptions("verbeux" => \$verbeux,
"debogage" => \$debogage,
"sortie=s" => \$sortie);il peut être appelé ainsi depuis la ligne de commande :
% prog --verbeux autres arguments ici
% prog --debogage autres arguments ici
% prog -v -d autres arguments ici
% prog --sortie=un_fichier autres arguments ici
% prog -s un_fichier autres arguments iciLe module Getopt::Long fournit une fonction GetOptions pour traiter les options de la ligne de commande avec des noms assez longs. Il inclut un support pour des choses comme les options en abrégé, les arguments typés comme booléen, chaîne, entier ou à virgule flottante, les variables de tableaux pour les options répétées, les routines de validation définies par l'utilisateur, le traitement conforme à POSIX ou conforme au style FSF, les options insensibles à la casse et le regroupement traditionnel des options courtes pour ne citer qu'un échantillon de la corne d'abondance de ses fonctionnalités. Si ce module en fait trop, pensez au module plus ordinaire Getopt::Std décrit plus loin. Si ce module n'en fait pas assez, regardez le module de CPAN Getopt::Declare qui offre une syntaxe plus déclarative pour spécifier les options.
32-28. Getopt::Std▲
use Getopt::Std;Vous pouvez utiliser getopt et getopts avec des variables globales :
out ($opt_o, $opt_i, $opt_f);
getopt('oif'); # -o, -i et -f prennent tous des arguments.
# Positionne les variables globales $opt_*.
getopts('oif:'); # Maintenant -o et -i sont booléens ; -f prend un arg.
# Positionne toujours les variables globales $opt_*
# comme effet de bord.Ou vous pouvez les utiliser avec un hachage privé pour les options :
my %opts; # Nous placerons les résultats ici.
getopt('oif', \%opts); # Tous les trois prennent toujours un argument.
getopts('oif:', \%opts); # Maintenant -o et -i sont des booléens
# et seul -f prend un argument.Le module Getopt::Std fournit deux fonctions, getopt et getopts, pour vous aider à analyser les arguments de la ligne de commande dans le cas d'options sur un seul caractère. Des deux fonctions, getopts est la plus utile, car elle vous laisse spécifier que certaines options prennent un argument ; sinon, on s'attend à trouver une option booléenne. Le regroupement d'options standards est supporté. L'ordre ne compte pas, ainsi les options ne prenant pas d'arguments peuvent être regroupées ensemble. Les options qui prennent un argument doivent être les dernières d'un groupe ou être spécifiées à part et leur argument doit venir soit immédiatement après l'option dans la même chaîne, soit comme l'argument suivant du programme. Étant donné l'exemple d'utilisation de getopts ci-dessus, voici des appels équivalents :
% prog -o -i -f FIC_TEMP autres arguments ici
% prog -o -if FIC_TEMP autres arguments ici
% prog -io -fFIC_TEMP autres arguments ici
% prog -iofFIC_TEMP autres arguments ici
% prog -oifFIC_TEMP autres arguments ici32-29. IO::Socket▲
use IO::Socket;En tant que client :
$socket = new IO::Socket::INET (PeerAddr => $hote_distant,
PeerPort => $port_distant,
Proto => "tcp",
Type => SOCK_STREAM)
or die "Connexion impossible vers $hote_distant:port_distant : $!\n";
# Ou utilisez l'interface plus simple à un seul argument.
$socket = IO::Socket::INET->new("$hote_distant:$port_distant,");
# "localhost:80", par exemple.
print $socket "donnée\n";
$ligne = <$socket>;En tant que serveur :
$serveur = IO::Socket::INET->new(LocalPort => port_serveur,
Type => SOCK_STREAM,
Reuse => 1,
Listen => 10) # ou SOMAXCONN
or die "Impossible d'être un serveur TCP sur le port
$port_serveur : $!\n";
while ($client = $serveur->accept()) {
# $client est la nouvelle connexion
$requete = <$client>;
print $client "reponse\n";
close $client;
}
# Simple fonction de connexion TCP renvoyant un handle de fichier
# pour utiliser dans les programmes clients simples.
sub connex_tcp {
my ($hote, $service) = @_;
require IO::Socket;
return IO::Socket::INET->new(join ":", $hote, $service);
}
my $hf = connex_tcp("localhost", "smtp"); # avec un scalaire
local *HF = connex_tcp("localhost", "smtp"); # avec un handleLe module IO::Socket fournit une approche de plus haut niveau pour la gestion des sockets que le module de base Socket. Vous pouvez l'utiliser dans un style orienté objet, bien que ce ne soit pas obligatoire, car les valeurs renvoyées sont des handles de fichiers réguliers et peuvent être utilisées en tant que telles, comme le montre la fonction connex_tcp dans l'exemple ci-dessus. Ce module hérite ses méthodes de IO::Handle et fait lui-même un require de IO::Socket::INET et IO::Socket::UNIX. Voir la description du module FileHandle pour d'autres fonctionnalités intéressantes. Voir le chapitre 16 pour une description de l'utilisation des sockets.
32-30. IPC::Open2▲
use IPC::Open2;
local(*SA_SORTIE, *SON_ENTREE); # Crée les handles locaux si besoin.
$pid_fils = open2(*SA_SORTIE, *SON_ENTREE, $programme, @args)
or die "Impossible d'ouvrir un pipe vers $programme : $!";
print SON_ENTREE "Voici votre entrée\n";
$sa_sortie = <SA_SORTIE>;
close(SA_SORTIE);
close(SON_ENTREE);
waitpid($pid_fils, 0);La seule fonction exportée, open2, du module IPC::Open2 démarre un autre programme et offre un accès à la fois en lecture et en écriture à cette commande. Les deux premiers arguments doivent être des handles de fichiers valides (ou alors des variables vides dans lesquelles seront placés les handles de fichiers autogénérés). Les arguments restants sont le programme plus ses arguments, qui, s'ils sont passés séparément, ne seront pas interprétés par le shell. Ce module ne récolte pas le processus fils après sa mort. À part les programmes courts où il reste acceptable de laisser le système d'exploitation gérer cela, vous aurez besoin de le faire vous-mêmes. Cela se résume normalement à appeler waitpid $pid, 0 lorsque vous en avez fini avec ce processus fils. Ne pas faire ceci entraîne l'accumulation de processus défunts (« zombies »).
En pratique, ce module ne fonctionne pas bien avec beaucoup de programmes à cause de la manière dont marche le vidage de tampon dans la bibliothèque d'entrées/sorties standard en C. Si vous contrôlez le code source des deux programmes, vous pouvez toutefois contourner facilement cette restriction en forçant le vidage ( flushing) de vos tampons de sortie plus fréquemment que par défaut. Si ce n'est pas le cas, les programmes peuvent être ennuyeusement avares dans leur accumulation de données en sortie. Un autre piège potentiel est le verrou mortel (deadlock) : si les deux processus sont en train de lire au même moment et qu'aucun n'écrit, alors votre programme se bloquera. Voir le chapitre 16 pour une discussion approfondie.
32-31. IPC::Open3▲
use IPC::Open3;
local(*SON_ENTREE, *SA_SORTIE, *SON_ERREUR);
$pid_fils = open3(*SON_ENTREE, *SA_SORTIE, *SON_ERREUR, $cmd, @args);
print SON_ENTREE "trucs\n";
close(SON_ENTREE); # Donne une fin de fichier au fils.
@lignes_sortie = <SA_SORTIE>; # Lit jusqu'à EOF.
@lignes_erreur = <SON_ERREUR>; # XXX : blocage potentiel si énorme
print "STDOUT:\n", @lignes_sortie, "\n";
print "STDERR:\n", @lignes_erreur, "\n";
close SA_SORTIE;
close SON_ERREUR;
waitpid($pid_fils, 0);
if ($?) {
print "Ce fils s'est terminé avec comme statut d'attente $?_n";
}Le module IPC::Open3 fonctionne comme IPC::Open2 (ce dernier est implémenté dans les termes du premier), excepté que open3 donne accès aux handles d'entrée standard, de sortie standard et de sortie d'erreurs standard du programme que vous lancez. Les mêmes précautions qu'avec open2 (voir l'entrée précédente) s'appliquent, plus quelques autres. Au lieu de passer le handle pour la lecture en premier et celui pour l'écriture en second, cette fois-ci c'est l'inverse. De plus, avec open3, le danger de verrous mortels (deadlocks) est encore plus grand qu'avant. Si vous essayez de lire après la fin de fichier sur l'un des handles de sortie du fils, mais que pendant ce temps il y a beaucoup de trafic en sortie sur l'autre handle, le processus pair semble se bloquer. Utilisez soit la forme à quatre arguments de select, soit le module IO::Select pour contourner cela. Voir le chapitre 16 pour plus de détails.
32-32. Math::BigInt▲
use Math::BigInt;
$i = Math::BigInt->new($chaine);
use Math::BigInt ':constant';
print 2**200;Ceci affiche :
+1606938044258990275541962092341162602522202993782792835301376Le module Math::BigInt fournit des objets qui représentent des entiers avec une précision arbitraire et des opérateurs arithmétiques surchargés. Créez ces objets en utilisant le constructeur new ou, dans une portée lexicale, en important la valeur spéciale « :constant », après laquelle tous les littéraux numériques jusqu'à la fin de cette portée lexicale seront traités comme des objets Math::BigInt. Tous les opérateurs standards sur les entiers sont implémentés, y compris (depuis la version 5.6 de Perl) les opérateurs logiques de bits. Dans l'implémentation actuelle, ce module n'est pas ce que vous pouvez appeler d'une rapidité fulgurante, mais cela pourrait être le cas dans l'avenir. (Nous aimerions voir à quelle vitesse vous calculez de tête 2**200.)
32-33. Math::Complex▲
use Math::Complex;
$z = Math::Complex->make(5, 6);
$z = cplx(5, 6); # idem, mais plus court.
$t = 4 - 3*i + $z; # effectue des opérations complexes standard
print "$t\n"; # affiche 9+3i
print sqrt(-9), "\n"; # affiche 3iLe module Math::Complex fournit des objets représentant des nombres complexes avec des opérateurs surchargés. Ce sont des nombres avec une partie réelle et une partie imaginaire comme ceux qui satisfont les racines paires de nombres négatifs, comme montré ci-dessus. À côté des opérateurs arithmétiques, nombre de fonctions internes mathématiques sont également supplantées par des versions qui connaissent les nombres complexes, incluant abs, log, sqrt, sin, cos et atan2. D'autres fonctions fournies sont Re et Im pour donner les parties réelles et imaginaires des arguments complexes, plus une batterie complète de fonctions trigonométriques étendues, comme tan, asin, acos, sinh, cosh et tanh. Le module exporte également la constante i, qui, comme vous pouvez l'imaginer, contient la valeur de i ; c'est-à-dire, la racine carrée de -1.
32-34. Math::Trig▲
use Math::Trig;
$x = tan(0.9);
$y = acos(3.7);
$z = asin(2.4);
$pi_sur_deux = pi/2;
$rad = deg2rad(120);Perl ne définit lui-même que trois fonctions trigonométriques : sin, cos et atan2. Le module Math::Trig les supplante avec des versions plus agréables et fournit toutes les autres fonctions trigos, incluant tan, csc, cosec, sec, cot, cotan, asin, acos, atan, sinh, cosh, tanh et beaucoup d'autres. De plus, la constante pi est définie, tout comme les fonctions de conversion comme deg2rad et grad2rad. Un support est fourni pour les systèmes de coordonnées cartésiennes, cylindriques ou sphériques. Ce module fait un usage implicite de Math::Complex si besoin est (et vice-versa) pour les calculs nécessitant des nombres imaginaires.
32-35. Net::hostent▲
use Socket;
use Net::hostent;
print inet_ntoa(gethost("www.perl.com")->addr); # affiche 208.201.239.50
printf "%vd", gethost("www.perl.com")->addr; # idem
print gethost("127.0.0.1")->name; # affiche localhost
use Net::hostent ':FIELDS';
if (gethost($nom_ou_nombre)) {
print "le nom est $h_name\n";
print "les alias sont $h_aliases\n";
print "les adresses sont ",
join ", " => map { inet_ntoa($_) } @h_addr_list;
}Les exportations par défaut de ce module supplantent les fonctions intrinsèques gethostbyname et gethostbyaddr, en les remplaçant avec des versions qui renvoient un objet Net::hostent (ou undef en cas d'échec). Cet objet possède des méthodes accesseurs d'attributs qui renvoient des champs nommés comme ceux de la structure struct hostent de la bibliothèque C définie dans netdb.h : name, aliases, addrtype, length ou addr_list. Les méthodes aliases et addr_list renvoient des références de tableaux ; les autres renvoient des scalaires. La fonction gethost est un frontal qui fait suivre un argument numérique à gethostbyaddr par le biais de la fonction Socket::inet_aton et le reste à gethostbyname. Comme avec les autres modules semi-pragmatiques qui supplantent des fonctions internes renvoyant des listes, si vous importez le tag « :FIELDS », vous pouvez accéder à des variables de paquetages scalaires ou tabulaires par le même nom que les appels de méthodes préfixés par « h_ ». Les fonctions intrinsèques sont quand même supplantées.
32-36. POSIX▲
use POSIX;
# Arrondit des nombres à virgule flottante à l'entier supérieur
# ou inférieur le plus proche.
$n = ceil($n); # arrondi supérieur
$n = floor($n); # arrondi inférieur
# Produit "20-04-2001" pour aujourd'hui.
$ch_date = strftime("%d-%m-%Y"), localtime);
# Produit "vendredi 04/20/01" pour la même date.
$ch_date = strftime("%A %D"), localtime);
# Essaie de nouveaux noms de fichiers temporaires jusqu'à en trouver un qui
# n'existe pas déjà; voir également File::Temp sur CPAN ou dans la v5.6.1.
do {
$nom = tmpnam();
} until sysopen(HF, $nom, O_CREAT|O_EXCL|O_RDWR, 0666);
# Vérifie si le système a un opérateur chown peu sûr le trahissant.
if (sysconf(_PC_CHOWN_RESTRICTED)) {
print "Hourra -- seul le super-utilisateur peut appeler chown\n";
}
# Trouve les informations par uname du système courant.
my ($noyau, $hote, $release, $version, $materiel) = uname();
use POSIX ":queue";
while (($pid_mort = waitpid(-1, &WNOHANG)) > 0) {
# Faites quelque chose avec $pid_mort si vous le voulez.
}
# Devient le leader d'une nouvelle session/nouveau groupe de processus
# (nécessaire pour créer des démons non affectés par les signaux
# du clavier ou les shells de connexion se terminant).
setsid(0) or die "échec de setsid : $!";Le module POSIX de Perl vous permet d'accéder à tous (ou presque tous) les identificateurs du standard POSIX 1003.1, plus quelques-uns du C ANSI que nous ne savions pas où mettre. Ce module fournit plus de fonctions qu'aucun autre. Voir sa documentation en ligne pour une séance de dissection ou le POSIX Programmer's Guide de Donald Lewine (O'Reilly, 1991).
Les identificateurs qui sont des #defines sans paramètres en C, comme EINTR ou O_NDELAY sont automatiquement exporter dans votre espace de noms en tant que fonctions constantes. Les fonctions qui ne sont normalement pas disponibles en Perl (comme floor, ceil, strftime, uname, setsid, setlocale et sysconf) sont exportées par défaut. Les fonctions du même nom que les opérateurs internes de Perl, comme open, ne sont pas exportées à moins de le demander explicitement, mais la plupart de gens sont susceptibles de préférer des noms de fonctions pleinement qualifiés pour distinguer POSIX::open de CORE::open.
Quelques fonctions ne sont pas implémentées, car elles sont spécifiques au C. Si vous tentez de les appeler, elles affichent un message vous disant qu'elles ne sont pas implémentées et vous suggèrent d'utiliser un équivalent Perl s'il en existe. Par exemple, une tentative d'accéder à la fonction setjmp affiche le message « setjmp() is C-specific: use eval {} instead » et tmpfile vous dit « Use method IO::File::new_tmp_file() ». (Mais depuis la version 5.6.1, vous devriez plutôt utilisez File::Temp.)
Le module POSIX vous emmène aussi près du système d'exploitation (ou tout du moins aux parties adressées par le standard POSIX) que ne le ferait n'importe quel programmeur C. Ceci vous donne accès à un pouvoir phénoménal et à des choses très utiles, comme bloquer les signaux et contrôler les options des entrées/sorties du terminal. Toutefois, cela signifie également que votre code finira par ressembler quasiment à du C. Comme démonstration utile de la manière d'éviter les vidages de tampons en entrée, voici un exemple d'un programme complet pour obtenir un seul caractère en entrée sans tampon, sur un système POSIX :
#!/usr/bin/perl -w
use strict;
$| = 1;
for (1..4) {
my $lu;
print "donnez-moi : ";
$lu = lire_un();
print "--> $lu\n";
}
exit;
BEGIN {
use POSIX qw(:termios_h);
my ($term, $oterm, $echo, $noecho, $df_entree);
$df_entree = fileno(STDIN);
$term = POSIX::Termios->new();
$term->getattr($df_entree);
$oterm = $term->getlflag();
$echo = ECHO | ECHOK | ICANON;
$noecho = $oterm & ~$echo;
sub cbreak {
$term->setlflag($noecho);
$term->setcc(VTIME, 1);
$term->setattr($df_entree, TCSANOW);
}
sub cuisine {
$term->setflag($oterm);
$term->setcc(VTIME, 0);
$term->setattr($df_entree, TCSANOW);
}
sub lire_un {
my $clef = "";
cbreak();
sysread(STDIN, $clef, 1);
cuisine();
return $clef;
}
}
END { cuisine() }La page de man du module POSIX donne un inventaire complet des fonctions et constantes qu'il exporte. Il y en a tant que vous finirez souvent par n'en importer qu'un sous-ensemble, comme « :queue », « :sys_stat_h » ou « :termios_h ». Un exemple de blocage de signaux avec le module POSIX est donné au chapitre 16.
32-37. Safe▲
use Safe;
$mem_proteg = Safe->new(); # espace mémoire protégé anonyme
$mem_proteg = Safe->new("Nom_Paquetage"); # dans cette table de symboles
# Active ou désactive les codes d'opération par groupe ou par nom
$mem_proteg->permit(qw(:base_core));
$mem_proteg->permit_only(qw(:base_core :base_loop :base_mem));
$mem_proteg->deny("die");
# comme do(), mais dans l'espace mémoire protégé
$ok = $mem_proteg->rdo($fichier);
# comme eval(), mais dans l'espace mémoire protégé
$ok = $mem_proteg->reval($code); # sans 'use strict'
$ok = $mem_proteg->reval($code, 1); # avec 'use strict'Le module Safe tente de fournir un environnement restreint pour protéger le reste du programme des opérations dangereuses. Il utilise deux stratégies différentes pour accomplir ceci. Un peu comme l'utilisation de chroot(2) par les démons FTP anonymes altère la vue que l'on a de la racine du système de fichier, la création d'un objet compartiment avec Safe->new("Nom_Paquetage") altère la vue que ce compartiment a de son propre espace de noms. Le compartiment voit maintenant comme sa table de symboles racine (main::), la table de symboles que le reste du programme voit comme Nom_Paquetage::. Ce qui ressemble à Bidule:: à l'intérieur du compartiment est en réalité Nom_Paquetage::Bidule:: à l'extérieur. Si vous ne donnez pas d'argument au constructeur, un nouveau nom de paquetage aléatoire est sélectionné pour vous. Le second et le plus important service fourni par un compartiment Safe est une manière de limiter le code considéré comme légal à l'intérieur d'un eval. Vous pouvez ajuster l'ensemble des codes d'opérations (opcodes) autorisés en utilisant des appels de méthodes sur votre objet Safe. Deux méthodes sont disponibles pour compiler du code dans un compartiment Safe : rdo (« restriction du do ») pour les fichiers et reval (« restriction de l'eval ») pour les chaînes. Ils fonctionnent comme do sur un nom de fichier et comme eval sur une chaîne, mais ils s'exécutent dans un espace de noms restreint avec des codes d'opérations limités. Le premier argument est le nom du fichier ou la chaîne à compiler et le second, qui est optionnel, indique si le code doit être compilé sous use strict ou pas.
Il est prévu de réécrire ce module (nous avons l'intention d'isoler l'espace mémoire protégé dans une tâche (thread) d'interpréteur différente pour une sécurité supplémentaire), assurez-vous donc de vérifier la page de man de Safe pour les mises à niveau. Voir également le chapitre 23.
32-38. Socket▲
use Socket;
$proto = getprotobyname('udp');
socket(SOCK , PF_INET, SOCK_DGRAM, $proto)
or die "socket : $!";
$iadr = gethostbyname('hishost.com');
$port = getservbyname('time', 'udp');
$sin = sockaddr_in($port, $iadr);
send(SOCK, 0, 0, $sin)
or die "send : $!";
$proto = getprotobyname('tcp');
socket(SOCK, PF_INET, SOCK_STREAM, $proto)
or die "socket : $!";
$port = getservbyname('smtp', 'tcp');
$sin = sockaddr_in($port, inet_aton("127.1"));
$sin = sockaddr_in(7, inet_aton("localhost"));
$sin = sockaddr_in(7, INADDR_LOOPBACK);
connect(SOCK, $sin)
or die "connect : $!";
($port, $iadr) = sockaddr_in(getpeerbyname(SOCK ));
$hote_pair = gethostbyaddr($iadr, AF_INET);
$adr_pair = inet_ntoa($iadr);
$proto = getprotobyname('tcp');
socket(SOCK, PF_UNIX, SOCK_STREAM, $proto)
or die "socket : $!";
unlink('/tmp/usock'); # XXX : l'échec est ignoré intentionnellement
$sun = sockaddr_un('tmp/usock');
connect(SOCK, $sun)
or die "connect : $!";
use Socket qw(:DEFAULT :crlf);
# Maintenant vous pouvez utiliser CR(), LF() et CRLF() ou
# $CR, $LF et $CRLF pour les fins de lignes.Le module Socket donne accès aux constantes du fichier #include sys/socket.h de la bibliothèque C pour qu'on les utilise dans les fonctions de bas niveau de Perl concernant les sockets. Il fournit également deux fonctions, inet_aton et inet_ntoa, pour convertir les adresses IP entres leurs représentations ASCII (comme « 127.0.0.1 ») et leur empaquetage réseau, ainsi que deux fonctions spéciales d'empaquetage/dépaquetage, sockaddr_in et sockaddr_un, qui manipulent les adresses de sockets binaires nécessaires aux appels bas niveau. Le tag d'importation :crlf donne des noms symboliques aux conventions diverses de fin de ligne afin que vous n'ayez pas à vous fier aux interprétations natives de \r et \n, qui peuvent varier. La plupart des protocoles de l'Internet préfèrent CRLF, mais tolèrent LF. Le module standard IO::Socket fournit une interface de plus haut niveau à TCP. Voir le chapitre 16.
32-39. Symbol▲
use Symbol "delete_package";
delete_package("Truc::Bidule");
print "supprimé\n" unless exists $Truc::{"Bidule::"};
use Symbol "gensym";
$sym1 = gensym(); # Renvoie un nouveau typeglob anonyme.
$sym2 = gensym(); # Et encore un autre.
package Demo;
use Symbol "qualify";
$sym = qualify("x"); # "Demo::x"
$sym = qualify("x", "Truc"); # "Truc::x"
$sym = qualify("Bidule::x"); # "Bidule::x"
$sym = qualify("Bidule::x", "Truc"); # "Bidule::x"
use Symbol "qualify_to_ref";
sub pass_handle(*) {
my $hf = qualify_to_ref(shift, caller);
...
}
# Maintenant vous pouvez appeler pass_handle avec HF, "HF", *HF ou \*HF.Le module Symbol fournit des fonctions pour faciliter la manipulation des noms globaux : les typeglobs, les noms de formats, les handles de fichiers, les tables de symboles de paquetages et toute autre chose que vous pourriez vouloir nommer via une table de symboles. La fonction delete_package nettoie complètement l'espace de nom d'un paquetage (en rendant effectivement anonymes toutes références supplémentaires aux référants de la table de symboles, y compris les références de code précompilé). La fonction gensym renvoie un typeglob anonyme chaque fois qu'elle est appelée. (Cette fonction n'est plus tellement utilisée de nos jours, maintenant que les scalaires indéfinis s'autovivifient avec les handles de fichiers appropriés lorsqu'ils sont utilisés comme arguments de open, pipe, socket et leurs semblables.)
La fonction qualify prend un nom qui peut être complètement qualifié avec un paquetage, ou pas, et renvoie un nom qui l'est. Si elle a besoin de préfixer le nom du paquetage, elle utilisera le nom spécifié via le second argument (ou s'il est omis, votre nom de paquetage courant). La fonction qualify_to_ref fonctionne de la même manière, mais produit une référence au typeglob que le symbole représenterait. Ceci est important dans les fonctions qui requièrent qu'ils soient passés en tant que références. En convertissant cet argument avec qualify_to_ref, vous pouvez maintenant utiliser le handle fourni même avec strict refs activé. Vous pouvez également le consacrer avec bless dans une forme objet, puisqu'il s'agit d'une référence valide.
32-40. Sys::Hostname▲
use Sys::Hostname;
$hote = hostname();Le module Sys::Hostname ne fournit qu'une seule fonction, hostname, qui compense ce fait en se remuant le derrière pour essayer de deviner comment votre hôte courant s'appelle. Sur les systèmes qui supportent l'appel système standard gethostname(2), celui-ci est utilisé, comme il s'agit de la méthode la plus efficace.6 Sur les autres systèmes, l'affichage de l'appel standard hostname(1) est employé. Sur d'autres encore, on appelle la fonction uname(3) de votre bibliothèque C, laquelle est également accessible par la fonction POSIX::uname de Perl. Si ces stratégies échouent toutes, d'autres efforts héroïques sont tentés. Quelles que soient les opinions de votre système sur ce qui est sensé ou insensé, Perl essaie de son mieux pour faire avec. Sur certains systèmes, ce nom d'hôte peut ne pas être pleinement qualifié avec le nom de domaine ; voir le module Net::Domain de CPAN si vous avez besoin de cela.
Il faut également prendre en considération que hostname ne renvoie qu'une seule valeur, mais que votre système peut avoir plusieurs interfaces réseaux configurées, vous pouvez donc ne pas vous voir renvoyer le nom associé à l'interface à laquelle vous vous intéressez si vous prévoyez d'utiliser ce module pour certains types de programmation de sockets. Il s'agit des cas où vous devrez probablement glaner dans l'affichage de la commande ifconfig(8) ou dans l'équivalent moral sur votre système.
32-41. Sys::Syslog▲
use Sys::Syslog; # Perd setlogsock.
use Sys::Syslog qw(:DEFAULT setlogsock); # Obtient également setlogsock.
openlog($programme, 'cons,pid', 'user');
syslog('info', 'ceci est un autre test');
syslog('mail|warning', 'ceci est un meilleur test : %d', time());
closelog();
syslog('debug', 'ceci est le dernier test');
setlogsock('unix');
openlog("$programme $$", 'ndelay', 'user');
syslog('info', 'le problème était %m'); # %m = $! pour le journal système
syslog('notice', 'prog_truc : ceci est vraiment terminé');
setlogsock('unix'); # "inet" ou "unix"
openlog("mon_programme", $logopt, $services);
syslog($priorite, $format, @args);
$ancien_masque = setlogmask($priorite_masque);
closelog();Le module Sys::Syslog se comporte comme la fonction syslog(3) de votre bibliothèque C, en envoyant des messages au démon de votre journal système, syslogd(8). Il est particulièrement utile dans les démons ou d'autres programmes qui ne disposent pas de terminal pour recevoir les affichages de diagnostics ou pour des programmes préoccupés par la sécurité qui veulent produire un enregistrement plus durable de leurs actions (ou des actions de quelqu'un d'autre). Les fonctions supportées sont :
openlog IDENT, LISTE_OPT, SERVICES
- Établit une connexion avec votre amical démon syslog. IDENT est la chaîne sous laquelle enregistrer le message (comme
$0, le nom de votre programme). LISTE_OPT est une chaîne avec des options séparées par des virgules comme « cons », « pid » et « ndelay ». SERVICES est quelque chose comme « auth », « daemon », « kern », « lpr », « mail », « news » ou « user » pour les programmes système et parmi « local0 » .. « local7 » pour les programmes locaux. Davantage de messages sont enregistrés en utilisant un service donné et la chaîne identificatrice.
syslog PRIORITE, FORMAT, ARGS
- Envoie un message au démon en employant la PRIORITE donnée. Le FORMAT est exactement comme
printfen comblant les séquences d'échappement des pourcentages avec les ARGS qui suivent excepté le fait qu'en respectant les conventions de la fonction syslog(3) de la bibliothèque standard, la séquence spéciale «%m» est interpolée avec errno (la variable$!de Perl) à cet endroit.
setlogsock TYPE
- TYPE doit valoir soit « inet », soit « unix ». Certains démons de systèmes ne font pas attention par défaut aux messages de syslog provenant du domaine Internet, vous pouvez alors lui affecter « unix » à la place, puisqu'il ne s'agit pas de la valeur par défaut.
closelog
- Rompt la connexion avec le démon.
Pour que ce module fonctionne avec les versions de Perl antérieures à la 5.6.0, votre administrateur système doit lancer h2ph(1) sur votre fichier d'en-tête sys/syslog.h pour créer un fichier de bibliothèque sys/syslog.ph. Toutefois, ceci n'était pas accompli par défaut à l'installation de Perl. Les versions ultérieures utilisent maintenant une interface XS, la préparation de sys/syslog.ph n'est donc plus nécessaire.
32-42. Term::Cap▲
use Term::Cap;
$ospeed = eval {
require POSIX;
my $termios = POSIX::Termios->new();
$termios->getattr;
$termios->getospeed;
} || 9600;
$terminal = Term::Cap->Tgetent({ TERM => undef, OSPEED => $ospeed });
$terminal->Tputs('cl', 1, STDOUT); # Efface l'écran.
$terminal->Tgoto('cm', $col, $lig, STDOUT); # Déplace le curseur.Le module Term::Cap donne accès aux routines termcap(3) de votre système. Voir la documentation de votre système pour plus de détails. Les systèmes qui ne disposent que de terminfo(5), mais pas de termcap(5) échoueront. (Beaucoup de systèmes terminfo peuvent émuler termcap.) Toutefois, vous trouverez sur CPAN un module Term::Info ainsi que Term::ReadKey, Term::ANSIColor et divers modules Curses pour vous aider avec les entrées caractère par caractère, les affichages en couleur ou la gestion des écrans de terminaux à un niveau plus élevé que Term::Cap ou Term::Info.
32-43. Text::Wrap▲
use Text::Wrap; # Importe wrap().
@lignes = (< <"FIN_G&S" =~ /\\S.*\S/g);
Ceci est particulièrement rapide,
un boniment inintelligible
n'est généralement
pas entendu,
et s'il
l'est, on
s'en fiche.
FIN_G&S
$Text::Wrap::columns = 50;
print wrap(" " x 8, " " x 3, @lignes), "\n";Ceci affiche :
Ceci est particulièrement rapide, un boniment inintelligible n'est généralement pas entendu, et s'il l'est, on s'en fiche.Le module Text::Wrap implémente un formateur de paragraphes simples. Sa fonction wrap formate un simple paragraphe à la fois en coupant les lignes sans le faire au milieu d'un mot. Le premier argument est le préfixe ajouté au début de la première ligne renvoyée. Le second est la chaîne utilisée comme préfixe pour toutes les lignes sauf la première. Tous les arguments suivants sont joints en utilisant un saut de ligne comme séparateur et ils sont renvoyés comme une seule chaîne de paragraphe reformatée. Vous devez apprécier vous-même la largeur de votre terminal ou au moins spécifier ce que vous désirez dans $Text::Wrap::columns. Bien que l'on puisse utiliser l'appel ioctl TIOCWINSZ pour apprécier le nombre de colonnes, il serait plus facile pour ceux qui ne sont pas habitués à la programmation en C, d'installer le module Term::Readkey de CPAN et d'utiliser la routine GetTerminalSize de ce module.
32-44. Time::Local▲
use Time::Local;
$date = timelocal($sec,$min,$heures,$jour_m,$mois,$annee);
$date = timegm($sec,$min,$heures,$jour_m,$mois,$annee);
$date = timelocal(50, 45, 3, 18, 0, 73);
print "scalar localtime donne : ", scalar(localtime($date)), "\n";
$date += 28 * 365.2425 * 24 * 60 * 60;
print "Vingt-huit années plus tard, il est maintenant\n\t",
scalar(localtime($date)), "\n";Ceci affiche :
scalar localtime donne : Thu Jan 18 03:45:50 1973
Vingt-huit années plus tard, il est maintenant
Wed Jan 17 22:43:26 2001Le module Time::Local fournit deux fonctions, timelocal et timegm, qui fonctionne exactement à l'inverse des fonctions localtime et gmtime, respectivement. C'est-à-dire qu'elles prennent une liste de valeurs numériques pour les divers composants de ce que localtime renvoie dans un contexte de liste et déterminent quel paramètre passé en entrée à localtime aurait produit ces valeurs. Vous pouvez utiliser ceci si vous voulez comparer ou lancer des calculs sur deux dates différentes. Bien que ces fonctions ne soient pas génériques pour analyser les dates et les heures, si vous pouvez vous arranger pour avoir vos paramètres dans le bon format, elles sont souvent suffisantes. Comme vous pouvez le voir dans l'exemple ci-dessus, la date et l'heure possèdent tout de même quelques excentricités et même de simples calculs échouent souvent pour faire ce qu'on leur demande à cause des années bissextiles, des secondes intercallaires et de la phase de la lune. Deux modules de CPAN, énormes, mais complets, s'occupent de ces problèmes et bien plus encore : Date::Calc et Date::Manip.
32-45. Time::localtime▲
use Time::localtime;
print "L'année est %d\n", localtime->year() +1900;
$maintenant = ctime();
use Time::localtime;
use File::stat;
$date_chaine = ctime(stat($fichier)->mtime);Ce module supplante la fonction intrinsèque localtime en la remplaçant avec une version qui renvoie un objet Time::tm (ou undef en cas d'échec). Le module Time::gmtime fait de même, mais il remplace la fonction intrinsèque gmtime à la place. L'objet renvoyé possède des méthodes qui accèdent aux champs nommés comme ceux de la structure struct tm dans time.h de la bibliothèque C : sec, min, hour, mday, mon, year, wday, yday et isdst. La fonction ctime donne un moyen d'obtenir la fonction originale (dans son sens scalaire) CORE::localtime. Remarquez que les valeurs renvoyées proviennent directement d'une structure struct tm, elles se situent donc dans les mêmes intervalles, voir l'exemple ci-dessus pour la manière correcte de produire une année sur quatre chiffres. La fonction POSIX::strftime est encore plus utile pour formater les dates et les heures avec une grande variété de styles plus alléchants les uns que les autres.
32-46. User::grent▲
use User::grent;
$gr = getgrgid(0) or die "Pas de groupe zéro";
if ($gr->name eq "audio" && @{$gr->members} > 1) {
print "le gid zéro s'appelle audio et compte d'autres membres";
}
$gr = getgr($n_importe_qui); # Accepte à la fois une chaîne ou un nombr
use User::grent ':FIELDS';
$gr = getgrgid(0) or die "Pas de groupe zéro";
if ($gr_name eq "audio" && @gr_members > 1) {
print "le gid zéro s'appelle audio et compte d'autres membres";
}Les exportations par défaut de ce module supplantent les fonctions intrinsèques getgrent, getgruid et getgrnam, en les remplaçant par des versions qui renvoient un objet User::grent (ou undef en cas d'échec). Cet objet possède des méthodes qui accèdent aux champs nommés comme ceux de la structure struct group dans grp.h de la bibliothèque C : name, passwd, gid et members (et pas mem comme en C !). Les trois premières renvoient des scalaires et la dernière une référence de tableau. Vous pouvez également importer les champs de la structure dans votre propre espace de noms en tant que variables ordinaires en utilisant le tag d'importation « :FIELDS », bien que ceci supplante toujours les fonctions intrinsèques. Les variables (les trois scalaires et le tableau) sont préfixées par « gr_ ». La fonction getgr est une simple bascule frontale qui fait suivre tout argument numérique à getgrid et tout argument chaîne à getgrnam.
32-47. User::pwent▲
# Par défaut, supplante seulement les fonctions intrinsèques.
use User::pwent;
$pw = getpwnam("daemon") or die "Pas d'utilisateur daemon";
if ($pw->uid == 1 && $pw->dir =~ m#^/(bin|tmp)?$# ) {
print "uid 1 sur le répertoire racine";
}
$pw = getpw($n_importe_qui); # Accepte à la fois une chaîne ou un nombre.
$shell_reel = $pw->shell || '/bin/sh';
for (($nom_complet, $bureau, $tel_bur, $tel_maison) =
split /\s*,\s*/, $pw->gecos)
{
s/&/ucfirst(lc($pw->name))/ge;
}
# positionne des variables globales dans le paquetage courant.
use User::pwent qw(:FIELDS);
$pw = getpwnam("daemon") or die "Pas d'utilisateur daemon";
if ($pw_uid == 1 && $pw_dir =~ m#^/(bin|tmp)?$# ) {
print "uid 1 sur le répertoire racine";
}
use User::pwent qw/pw_has/;
if (pw_has(qw[gecos expire quota])) { ... }
if (pw_has("name uid gid passwd")) { ... }
printf "Votre struct pwd supporte [%s]\n", scalar pw_has();Les exportations par défaut de ce module supplantent les fonctions intrinsèques getpwent, getpwuid et getpwnam, en les remplaçant par des versions qui renvoient un objet User::pwent (ou undef en cas d'échec). Il est souvent préférable d'utiliser ce module plutôt que les fonctions intrinsèques qu'il remplace, car les fonctions intrinsèques surchargent, voire omettent divers éléments dans la liste renvoyer au nom de la compatibilité ascendante.
L'objet renvoyé possède des méthodes qui accèdent aux champs nommés comme ceux de la structure passwd dans pwd.h de la bibliothèque C, avec le préfixe « pw_ » en moins : name, passwd, uid, gid, change, age, quota, comment, class, gecos, dir, shell et expire. Les champs passwd, gecos et shell sont marqués. Vous pouvez également importer les champs de la structure dans votre propre espace de noms en tant que variables ordinaires en utilisant le tag d'importation « :FIELDS », bien que ceci supplante toujours les fonctions intrinsèques. Vous accédez à ces champs en tant que variables scalaires nommées avec un préfixe « pw_ » devant le nom de la méthode. La fonction getpw est une simple bascule frontale qui fait suivre tout argument numérique à getpwuid et tout argument chaîne à getpwnam.
Perl croit qu'aucune machine n'a plus d'un champ parmi change, age ou quota d'implémenté, ni plus d'un parmi comment ou class. Certaines machines ne supportent pas expire, gecos, on dit que certaines machines ne supportent même pas passwd. Vous pouvez appeler ces méthodes, quelle que soit la machine sur laquelle vous êtes, mais elles retourneront undef si elles ne sont pas implémentées. Voir passwd(5) et getpwent(3) pour plus de détails.
Vous pouvez déterminer si ces champs sont implémentés en le demandant à la fonction non portable pw_has. Elle renvoie vrai si tous les paramètres sont des champs supportés sur la plate-forme ou faux si au moins un ne l'est pas. Elle lève une exception si vous demandez un champ dont le nom n'est pas reconnu. Si vous ne passez aucun argument, elle renvoie la liste des champs que votre bibliothèque C pense qu'ils sont supportés.
L'interprétation du champ gecos varie entre les systèmes, mais il comprend souvent quatre champs séparés par des virgules contenant le nom complet de l'utilisateur, l'emplacement de son bureau, son téléphone professionnel et son téléphone personnel. Un & dans le champ gecos doit être remplacé par le nom de login, name, de l'utilisateur avec les majuscules et minuscules correctes. Si le champ shell est vide, on suppose qu'il vaut /bin/sh, bien que Perl ne le fasse pas pour vous. Le passwd est donnée par une fonction de hachage à sens unique produisant du charabia au lieu d'un texte lisible, et on ne peut inverser la fonction de hachage en essayant brutalement toutes les combinaisons possibles. Les systèmes sécurisés utilisent souvent une fonction de hachage plus sûre que DES. Sur les systèmes supportant les mots de passe cachés, Perl renvoie automatiquement l'entrée du mot de passe sous sa forme cachée lorsqu'un utilisateur suffisamment puissant l'appelle, même si la bibliothèque C sous-jacente fournie par votre constructeur avait une vision trop courte pour réaliser qu'il aurait dû faire cela.
33. Messages de diagnostic▲
Ces messages sont classés dans un ordre croissant de désespoir :
|
Classe |
Signification |
|---|---|
|
(W) |
Un avertissement (optionnel). |
|
(D) |
Une obsolescence (optionnelle). |
|
(S) |
Un avertissement sérieux (obligatoire). |
|
(F) |
Une erreur fatale (interceptable). |
|
(P) |
Une erreur interne (panique) que vous ne devriez jamais rencontrer (interceptable). |
|
(X) |
Une erreur extrêmement fatale (non-interceptable). |
|
(A) |
Une erreur venue de l'au-delà (non générée par Perl). |
La plupart des messages des trois premières classifications ci-dessus (W, D et S) peuvent être contrôlés en utilisant le pragma warnings ou les options -w et -W. Si un message peut être contrôlé avec le pragma warnings, la catégorie correspondante de cet avertissement est donnée après la lettre de classification ; par exemple, (W misc) indique un avertissement de type divers. Le pragma warnings est décrit au chapitre 31, Modules de pragmas.
Les avertissements peuvent être capturés plutôt qu'affichés en faisant pointer $SIG{__WARN__} sur une référence de routine qui sera appelée pour chaque message. Vous pouvez également en prendre le contrôle avant qu'une erreur interceptable « meure » en assignant une référence de sous-programme à $SIG{__DIE__}, mais si vous n'appelez pas die à l'intérieur de ce gestionnaire, l'exception sera toujours présente en revenant. En d'autres termes, il n'est pas possible de la « défataliser » par ce biais. Vous devez utiliser eval à cet effet.
Les avertissements par défaut sont toujours activés sauf s'ils sont explicitement désactivés avec le pragma warnings ou l'option -X.
Dans les messages suivants, %s représente une chaîne interpolée qui n'est déterminée qu'au moment de la génération du message. (De même, %d représente un nombre interpolé — pensez aux formats de printf, mais %d signifie ici un nombre dans n'importe quelle base.) Remarquez que certains messages commencent par %s — d'où une certaine difficulté à les classer dans l'ordre alphabétique. Vous pouvez chercher dans ces messages si celui que vous recherchez n'apparaît pas à l'endroit attendu. Les symboles "%-?@ sont triés avant les caractères alphabétiques, alors que [ et \ le sont après.
Si vous êtes persuadé qu'un bogue provient de Perl et non de vous, essayez de le réduire à un cas de test minimal et faites un rapport avec le programme perlbug qui est fourni avec Perl.
N.d.T. Les messages sont indiqués ici en anglais tels qu'ils apparaissent à l'exécution de vos scripts Perl. Toutefois, nous en donnons ici une traduction pour en faciliter la compréhension.
"%s" variable %s masks earlier declaration in same %s
- (La variable
"%s"masque une déclaration précédente dans la même%s) (W misc) Une variable my ou our a été redéclarée dans la portée ou dans l'instruction courante, éliminant effectivement tout accès à l'instance précédente. Il s'agit presque toujours d'une erreur de typographie. Remarquez que la variable déclarée plus tôt existera toujours jusqu'à la fin de la portée ou jusqu'à ce que toutes les fermetures qui s'y réfèrent soient détruites.
"my sub" not yet implemented ("my sub" n'est pas encore implémenté)
- (F) Les sous-programmes de portée lexicale ne sont pas encore implémentés. N'essayez pas encore cela.
"my" variable %s can't be in a package
- (La variable "my"
%sne peut pas se trouver dans un paquetage) - (F) Les variables de portée lexicale ne se trouvent pas dans un paquetage, et il ne sert donc à rien d'essayer d'en déclarer une, préfixée d'un qualificateur de paquetage. Utilisez local si vous désirez donner une valeur locale à une variable de paquetage.
"no" not allowed in expression ("no" n'est pas autorisé dans une expression)
- (F) Le mot-clef no est reconnu et exécuté à la compilation et il ne renvoie aucune valeur utile.
"our" variable %s redeclared
- (La variable "our"
%sest redéclarée) (W misc) Il semble que vous avez déjà déclaré la même variable globale auparavant dans la même portée lexicale.
"use" not allowed in expression
- ("use" n'est pas autorisé dans une expression)
- (F) Le mot-clef use est reconnu et exécuté à la compilation et il ne renvoie aucune valeur utile.
'!' allowed_only_after types %s
- (
'!n'est autorisé qu'après les types%s) - (F) Le '
!'n'est autorisé danspacketunpackqu'après certains types.
'|' and '<' may not both be specified on command line
- ('
|'et '<'ne peuvent pas être spécifiés en même temps sur la ligne de commande) - (F) Il s'agit d'une erreur spécifique à VMS. Perl effectue ses propres redirections dans la ligne de commande. Il se trouve que STDIN était un pipe et que vous avez essayé de rediriger STDIN en utilisant
<. Un seul flux STDIN par personne, s'il vous plaît.
'|' and '>' may not both be specified on command line
- (
'|et '>'ne peuvent pas être spécifiés en même temps sur la ligne de commande) - (F) Il s'agit d'une erreur spécifique à VMS. Perl effectue ses propres redirections dans la ligne de commande et pense que vous avez essayé de rediriger STDOUT à la fois dans un fichier et dans un pipe vers une autre commande. Vous devez choisir l'un ou l'autre, bien que rien ne vous empêche de rediriger dans un pipe vers un programme ou un script Perl qui sépare la sortie standard en deux flux, comme dans :
open(SORTIE,">$ARGV[0]") or die "Impossible d'écrire dans $ARGV[0] : $!";
while (<STDIN>) {
print;
print SORTIE;
} close SORTIE;/ cannot take a count
- (
/ne peut pas être lié à un compteur) - (F) Vous aviez un canevas pour
unpackindiquant une chaîne d'une longueur sujette à un compteur, mais vous avez également spécifié une taille explicite pour cette chaîne.
/ must be followed by a, A ou Z
- (
/doit être suivi par A, a ou Z) - (F) Vous aviez un canevas pour
unpackindiquant une chaîne d'une longueur sujette à un compteur ; cette chaîne doit être suivie d'une des lettres a, A ou Z pour indiquer quelle sorte de chaîne doit être dépaquetée.
/ must be followed by a*, A* ou Z*
- (
/doit être suivi par A*, a*ou Z*) - (F) Vous aviez un canevas pour
unpackindiquant une chaîne d'une longueur sujette à un compteur. Actuellement, les seules choses dont on peut compter la longueur sont a*, A*ou Z*.
/ must follow a numeric type
- (
/doit suivre un type numérique) - (F) Vous aviez un canevas pour
unpackcontenant un#, mais celui-ci ne suivait pas l'une des spécifications numériques d'unpack.
% may only be used in unpack
- (
%ne peut être utilisé que dansunpack) - (F) Vous ne pouvez pas empaqueter une chaîne avec
packen fournissant une somme de contrôle, car le traitement de cette dernière fait perdre de l'information et vous ne pouvez pas revenir en arrière.
Repeat count in pack overflows
- (Dépassement du compteur de répétitions dans
pack) - (F) Vous ne pouvez pas spécifier un compteur de répétitions tellement grand qu'il dépasse la limite pour vos entiers signés.
Repeat count in unpack overflows
- (Dépassement du compteur de répétitions dans
unpack) - (F) Vous ne pouvez pas spécifier un compteur de répétitions tellement grand qu'il dépasse la limite pour vos entiers signés.
/%s/ Unrecognized escape \\%c passed through
- (
/%s/: Rencontre d'une séquence d'échappement \\%cinconnue) - (W regexp) Vous avez employé une combinaison avec un caractère antislash qui n'est pas reconnue par Perl. Cette combinaison apparaît dans une variable interpolée ou une expression régulière délimitée par '. Le caractère a été interprété littéralement.
/%s/ Unrecognized escape \\%c in character class passed through
- (
/%s/: Rencontre d'une séquence d'échappement \\%cinconnue dans une classe de caractères) - (W regexp) Vous avez employé une combinaison avec un caractère antislash qui n'est pas reconnue par Perl à l'intérieur d'une classe de caractères. Le caractère a été interprété littéralement.
/%s/ should probably be written as "%s"
- (
/%s/devrait probablement être écrit "%s") - (W syntax) Vous avez employé un motif là où Perl s'attendait à trouver une chaîne, comme dans le premier argument de
join. Perl utilisera comme chaîne le résultat vrai ou faux de la correspondance entre le motif et$_, ce qui n'est probablement pas ce que vous aviez en tête.
%s(...) interpreted as function
- (
%s(...) interprété comme une fonction) - (W syntax) Vous avez dérogé à la règle qui dit que tout opérateur de liste suivi par des parenthèses devient une fonction prenant comme arguments tous les opérateurs de listes trouvés entre les parenthèses.
%s() called too early to check protoype
- (
%s() appelée trop tôt pour vérifier le prototype) - (W prototype) Vous avez appelé une fonction possédant un prototype avant que l'analyseur syntaxique ne voie sa déclaration ou sa définition et Perl ne peut pas vérifier si l'appel se conforme au prototype. Pour obtenir une vérification correcte du prototype, vous devez soit ajouter une déclaration du prototype pour le sous-programme en question plus haut dans le code, soit déplacer la définition du sous-programme avant l'appel. Ou alors, si vous êtes certains d'appeler la fonction correctement, vous pouvez mettre une esperluette devant le nom pour éviter l'avertissement.
%s argument is not a HASH or ARRAY element
- (L'argument
%sn'est un élément ni de HACHAGE, ni de TABLEAU) - (F) L'argument de
existsdoit être un élément de hachage ou de tableau, comme :
$truc{$bidule}
$ref->{"susie"}[12]%s argument is not a HASH or ARRAY element or slice
- (L'argument
%sn'est un élément ni de HACHAGE, ni de TABLEAU, ni une tranche) - (F) L'argument de
deletedoit être soit un élément de hachage ou de tableau, comme :
$truc{$bidule} $ref->{"susie"}[12]soit une tranche de hachage ou de tableau, comme :
@truc[$bidule, $machin, $chouette] @{$ref->[12]}{"susie", "queue"}%s argument is not a subroutine name
- (L'argument
%sn'est pas un nom de sous-programme) - (F) L'argument de
existspourexists&sub doit être un nom de sous-programme et non un appel de sous-programme.exists&sub() générera cette erreur.
%s did not return a true value
- (
%sn'a pas renvoyé une valeur vraie) - (F) Un fichier requis par require (ou utilisé par use) doit retourner une valeur vraie pour indiquer qu'il s'est compilé correctement et que l'initialisation de son code s'est bien passée. Il est habituel de placer un
1; à la fin d'un tel fichier, bien qu'une quelconque valeur fasse l'affaire.
%s failed--call queue aborted
- (
%sa échoué — file d'appels abandonnée) - (F) Une exception non capturée a été levée pendant l'exécution d'un sous-programme CHECK, INIT ou END. Le traitement du reste de la file contenant de telles routines s'est terminé prématurément.
%s found where operator expected
- (
%strouvé là où l'on attendait un opérateur) - (S) L'analyseur lexicographique de Perl sait s'il attend un terme ou un opérateur. S'il voit ce qu'il sait être un terme alors qu'il s'attend à un opérateur, il vous donne ce message d'alerte. Habituellement, cela indique qu'un opérateur ou un séparateur a été omis, comme un point-virgule.
%s had compilation errors
- (
%sa engendré des erreurs de compilation) - (F) C'est le message final lorsqu'un perl -c échoue.
%s has too many errors
- (
%sa engendré trop d'erreurs) - (F) L'analyseur abandonne son analyse du programme après 10 erreurs. Les messages suivant ne seraient pas sensés.
%s matches null string many times
- (
%scorrespond trop de fois à la chaîne vide) - (W regexp) Le motif que vous avez spécifié rentrerait dans une boucle infinie si le moteur d'expressions régulières ne contrôlait pas cela.
%s never introduced
- (
%sn'a jamais été introduit) - (S internal) Le symbole en question a été déclaré, mais sa portée s'est terminée avant qu'il soit possible de s'en servir.
%s package attribute may clash with future reserved word: %s
- (L'attribut de paquetage
%srisque de rentrer en conflit avec le mot%sréservé pour une utilisation ultérieure) - (W reserved) Un nom d'attribut en minuscules géré par un paquetage spécifique a été utilisé. Ce mot pourrait avoir un sens pour Perl un jour, même si ce n'est pas encore le cas. Peut-être devriez-vous employer à la place un nom avec des majuscules et des minuscules mélangées.
%s syntax OK
- (
%ssyntaxe OK) - (F) Message final lorsqu'un perl -c a réussi.
%s: Command not found
- (
%s: Commande introuvable) - (A) Vous avez lancé accidentellement votre script avec csh au lieu de Perl. Vérifiez la ligne avec
#!ou lancez vous-même votre script manuellement dans Perl avec perl nom_script.
%s: Expression syntax
- (
%s: Syntaxe d'expression) - (A) Vous avez lancé accidentellement votre script avec csh au lieu de Perl. Vérifiez la ligne avec
#!ou lancez vous-même votre script manuellement dans Perl avec perl nom_script.
%s: Undefined variable
- (
%s: Variable indéfinie) - (A) Vous avez lancé accidentellement votre script avec csh au lieu de Perl. Vérifiez la ligne avec
#!ou lancez vous-même votre script manuellement dans Perl avec perl nom_script.
%s: not found
- (
%s: introuvable) - (A) Vous avez lancé accidentellement votre script avec le Bourne Shell au lieu de Perl. Vérifiez la ligne avec
#!ou lancez vous-même votre script manuellement dans Perl avec perl nom_script.
(in cleanup) %s
- ((au nettoyage)
%s) - (W misc) Ce préfixe indique habituellement qu'une méthode DESTROY a levé l'exception indiquée. Puisque les destructeurs sont appelés habituellement par le système à un moment arbitraire durant l'exécution, et bien souvent un grand nombre de fois, cet avertissement n'est affiché qu'une seule fois pour tous les échecs qui sinon auraient causé une répétition du même message. Les échecs des fonctions de rappel (callbacks) définies par l'utilisateur et propagées par l'emploi du flag G_KEEPERR peuvent également entraîner cet avertissement. Voir perlcall(1).
(Missing semicolon on previous line?)
- (Point-virgule manquant sur la ligne précédente ?)
- (S) Il s'agit d'une supposition donnée en complément du message «
%sfound where operator expected ». Pour autant, n'ajoutez pas systématiquement un point-virgule simplement parce que vous avez lu ce message
-P not allowed for setuid/setgid script
- (
-P n'est pas autorisé pour un script setuid/setgid) - (F) Le préprocesseur C a voulu ouvrir le script en l'appelant par son nom, ce qui entraîne une situation de concurrence (N.d.T. : race condition) qui casse la sécurité.
-T and -B not implemented on filehandles
- (
-T et-B ne sont pas implémentés sur les handles de fichiers) - (F) Perl ne peut utiliser le tampon d'entrée/sortie du handle de fichier quand il ne connaît pas votre type d'entrées/sorties standards. Vous devez utiliser un nom de fichier à la place.
-p destination: %s
- (Destination de
-p :%s) - (F) Une erreur est survenue durant l'affichage sur la sortie standard implicite invoquée par l'option de la ligne de commande
-p. (Cette sortie est redirigée vers STDOUT à moins que vous ne l'ayez redirigée avecselect.)
500 Server error
- (Erreur de serveur 500) Voir Server error (Erreur de serveur).
?+* follows nothing in regexp
- (
?+*ne suivent rien dans l'expression régulière) - (F) Vous avez commencé une expression rationnelle avec un quantifiant. Mettez un antislash devant si vous vouliez l'employer au sens littéral.
@ outside of string
- (
@à l'extérieur de la chaîne) - (F) Vous aviez un canevas empaqueté qui spécifiait une position absolue en dehors de la chaîne à dépaqueter.
<> should be quotes
- (
<>devraient être des apostrophes) - (F) Vous avez écrit require
<fichier>alors que vous auriez dû écrire require'fichier'.
\1 better written as $1
- (Il est préférable d'écrire
$1plutôt que \1) - (W syntax) À l'extérieur des motifs, les références arrière (backreferences) existent en tant que variables. L'utilisation d'antislashs du côté droit d'une substitution était autorisée pour nos grands-pères, mais stylistiquement, il mieux vaut adopter la forme des variables attendue par les autres programmeurs Perl. De plus, cela fonctionne mieux s'il y a plus de neuf références arrière.
accept() on closed socket %s
- (
accept() sur une socket fermée%s) - (W closed) Vous avez tenté de faire un
acceptsur une socket fermée. Peut-être avez-vous oublié de vérifier la valeur retournée par l'appel desocket?
Allocation too large: %lx
- (Allocation trop grande :
%lx) - (X) Vous ne pouvez allouer plus de 64K sur une machine MS-DOS.
Applying %s to %s will act on scalar(%s)
- (Appliquer
%sà%sfonctionne avec un scalaire (%s)) - (W misc) Les opérateurs de recherche de correspondance (
//), de substitution (s///) et de translation (tr///) fonctionnent avec des valeurs scalaires. Si vous appliquez l'un d'eux à un tableau ou à un hachage, il convertit ce dernier en une valeur scalaire — la longueur du tableau ou les informations sur le peuplement du hachage — puis travaille sur la valeur scalaire. Ce n'est probablement pas ce que vous vouliez faire.
Arg too short for msgsnd
- (Argument trop court pour
msgsnd) - (F)
msgsndnécessite une chaîne au moins aussi longue que sizeof(long).
Ambiguous use of %s resolved as %s
- (Utilisation ambiguë de
%srésolue avec%s) - (W ambiguous | S) Vous avez exprimé quelque chose qui n'est pas interprété comme vous le pensiez. Normalement il est assez facile de clarifier la situation en rajoutant une apostrophe manquante, un opérateur, une paire de parenthèses ou une déclaration.
Ambiguous call resolved as CORE::%s(), qualify as such or use &
- (Appel ambigu résolu avec CORE::
%s, qualifiez-le ainsi ou utiliser&) - (W ambiguous) Un sous-programme que vous avez déclaré a le même nom qu'un mot-clef de Perl et vous avez utilisé ce nom sans le qualifier pour que l'on puisse distinguer l'un de l'autre. Perl décide d'appeler la fonction interne, car votre sous-programme n'est pas importé. Pour forcer l'interprétation sur l'appel de votre sous-programme, mettez une esperluette avant le nom ou qualifiez votre sous-programme avec son nom de paquetage. Ou alors, vous pouvez importer le sous-programme (ou prétendre le faire avec le pragma use subs).
- Pour l'interpréter en silence comme l'opérateur Perl, utilisez le préfixe CORE:: sur cet opérateur (ex. CORE::log(
$x)) ou déclarez le sous-programme en tant que méthode objet.
Args must match #! line
- (Les arguments doivent correspondre à la ligne
#!) - (F) L'émulateur setuid nécessite que les arguments invoqués par Perl correspondent avec ceux utilisés sur la ligne
#!. Comme certains systèmes imposent un unique argument sur la ligne#!, essayez de combiner les options ; par exemple, changez -w -U en -wU.
Argument "%s" isn't numeric
- (L'argument "
%s" n'est pas numérique) - (W numeric) La chaîne indiquée est utilisée comme un argument avec un opérateur qui s'attend plutôt à une valeur numérique. Si vous êtes chanceux, le message indique quel opérateur a été si malchanceux.
Array @%s missing the @ in argument %d of %s()
- (D deprecated) Les versions vraiment antérieures de Perl permettaient d'omettre le @ des tableaux à certains endroits. Ceci est maintenant largement obsolète.
assertion botched: %s
- (assertion sabotée :
%s) - (P) Le paquetage malloc fourni avec Perl a subi une erreur interne.
Assertion failed: file "%s"
- (L'assertion a échoué : fichier "
%s") - (P) Une assertion générale a échoué. Le fichier en question doit être examiné.
Assignment to both a list and a scalar
- (Assignement simultané à une liste et à un scalaire)
- (F) Si vous affectez à un opérateur conditionnel, les deuxième et troisième arguments doivent soit être tous les deux des scalaires, soit tous les deux des listes. Autrement Perl ne connaît pas le contexte à fournir au côté droit.
Attempt to free non-arena SV: 0x%lx
- (Tentative de libérer un SV hors d'une zone : 0x
%lx) - (P internal) Tous les objets SV sont supposés être alloués dans une zone qui sera nettoyée à la sortie du script. Un SV a été découvert en dehors d'une de ces zones.
Attempt to free nonexistent shared string
- (Tentative de libérer une chaîne partagée inexistante)
- (P internal) Perl maintient une table interne qui compte les références de chaînes pour optimiser le stockage et l'accès aux clefs de hachages et aux autres chaînes. Ce message indique que quelqu'un a essayé de décrémenter le compteur de références d'une chaîne que l'on ne peut plus trouver dans la table.
Attempt to free temp prematurely
- (Tentative prématurée de libérer une valeur temporaire)
- (W debugging) Les valeurs à l'agonie (mortalized) sont supposées être libérées par la routine interne free_tmps. Ce message indique que quelque chose d'autre est en train de libérer le SV avant que la routine free_tmps ait une chance de le faire, ce qui signifie que la routine free_tmps libérera un scalaire non référencé au moment où elle tentera de le faire.
Attempt to free unreferenced glob pointers
- (Tentative de libérer des pointeurs de glob non référencés)
- (P internal) Le compteur de références a été endommagé en ce qui concerne les alias de symboles.
Attempt to free unreferenced scalar
- (Tentative de libérer un scalaire non référencé)
- (W internal) Perl allait décrémenter un compteur de références d'un scalaire pour voir s'il arrivait à 0 et a découvert qu'il était déjà arrivé à 0 auparavant et qu'il se pourrait qu'il ait été libéré et, en fait, qu'il a probablement été libéré. Cela peut indiquer que SvREFCNT_dec a été appelé trop de fois ou que SvREFCNT_inc n'a pas été appelé assez de fois ou encore que le SV a été achevé (mortalized) alors qu'il n'aurait pas dû l'être ou enfin que la mémoire a été corrompue.
Attempt to join self
- (Tentative de se rejoindre soi-même)
- (F) Vous avez essayé de rejoindre avec
joinune tâche (thread) à partir d'elle-même, ce qui est une opération impossible. Vous pourriez rejoindre la mauvaise tâche ou avoir besoin de déplacer lejoinvers une autre tâche.
Attempt to pack pointer to temporary value
- (Tentative d'empaqueter un pointeur vers une valeur temporaire)
- (W pack) Vous avez essayé de passer une valeur temporaire (comme le résultat d'une fonction ou une expression calculée) au canevas p de
pack. Cela signifie que le résultat contient un pointeur vers un endroit qui pourrait devenir invalide à tout moment, même avant la fin de l'instruction en cours. Utilisez des valeurs littérales ou globales comme arguments du canevas p depackpour éviter cet avertissement.
Attempt to use reference as lvalue in substr
- (Tentative d'utiliser une référence en tant que lvalue dans
substr) - (W substr) Vous avez soumis une référence utilisée en tant que lvalue comme premier argument de
substr, ce qui est vraiment étrange. Peut-être avez-vous oublié de la déréférencer en premier lieu.
Bad arg length for %s, is %d, should be %d
- (Mauvaise longueur d'argument pour
%s, vaut%d, devrait valoir%d) - (F) Vous avez passé un tampon de taille incorrecte à
msgctl,semctloushmctl. En C, les tailles correctes sont respectivement sizeof(struct msqid_ds*), sizeof(struct semid_ds*) et sizeof(struct shmid_ds*).
Bad evalled substitution pattern
- (Mauvaise évaluation du motif de substitution)
- (F) Vous avez utilisé l'option
/e pour évaluer l'expression de remplacement pour une substitution, mais Perl a trouvé une erreur de syntaxe dans le code à évaluer, très certainement une parenthèse fermante inattendue.
Bad filehandle: %s
- (Mauvais handle de fichier :
%s) - (F) Un symbole a été passé à quelque chose qui s'attendait à un handle de fichier, mais le symbole n'a aucun handle de fichier qui lui soit associé. Peut-être avez-vous oublié de faire un
openou dans vous l'avez fait dans un autre paquetage.
Bad free() ignored
- (Mauvais free() ignoré)
- (S malloc) Une routine interne a appelé free sur quelque chose qui n'avait jamais été alloué avec malloc dans un premier temps. Ce message est obligatoire, mais peut être désactivé en positionnant la variable d'environnement PERL_BADFREE à 1. Ce message peut être assez fréquent avec DB_file sur les systèmes avec une édition de liens dynamiques en « dur », comme AIX et OS/2. C'est un bogue de Berkeley DB.
Bad hash
- (Mauvais hachage)
- (P) Une des routines internes concernant un hachage a passé un pointeur HV nul.
Bad index while coercing array into hash
- (Mauvais indice lors de la transformation d'un tableau en hachage)
- (F) La recherche dans le hachage, 0ème élément d'un pseudohachage, a découvert un indice illégal. La valeur des indices doit être supérieure ou égale à 1.
Bad name after %s::
- (Mauvais nom après
%s::) - (F) Vous avez commencé un nom de symbole en utilisant un préfixe de paquetage puis vous n'avez pas fini le symbole. En particulier, vous ne pouvez pas faire d'interpolation en dehors des guillemets, ainsi :
$var = 'ma_var';
$sym = mon_paquetage::$var;n'est pas identique à :
$var = 'ma_var'; $sym = "mon_paquetage::$var";Bad realloc() ignored
- (Mauvais realloc() ignoré)
- (S malloc) Une routine interne a appelé realloc sur quelque chose qui n'avait jamais été alloué avec malloc dans un premier temps. Ce message est obligatoire, mais peut être désactivé en positionnant la variable d'environnement PERL_BADFREE à 1.
Bad symbol for array
- (Mauvais symbole pour un tableau)
- (P) Une requête interne a demandé à ajouter une entrée de tableau à quelque chose qui n'est pas une entrée dans la table des symboles.
Bad symbol for filehandle
- (Mauvais symbole pour un handle de fichier)
- (P) Une requête interne a demandé d'ajouter une entrée de handle de fichier à quelque chose qui n'est pas une entrée dans la table des symboles.
Bad symbol for hash
- (Mauvais symbole pour un hachage)
- (P) Une requête interne a demandé à ajouter une entrée de hachage à quelque chose qui n'est pas une entrée dans la table des symboles.
Badly placed ()'s
- (Parenthèses mal disposées)
- (A) Vous avez lancé accidentellement votre script avec csh au lieu de Perl. Vérifiez la ligne avec
#!ou lancez vous-même votre script dans Perl avec perl nom_script.
Bareword "%s" not allowed while "strict subs" in use
- (Mot simple "
%s" interdit lorsque "strict subs" est activé) - (F) Avec « strict subs » activé, un mot simple n'est autorisé que comme identificateur de sous-programme, entre accolades ou à la gauche du symbole
=>. Peut-être devriez-vous déclarer au préalable votre sous-programme ?
Bareword "%s" refers to nonexistent package
- (Le mot simple "
%s" se réfère à un paquetage inexistant) - (W bareword) Vous avez utilisé un mot simple qualifié de la forme, Truc:: mais le compilateur n'a pas vu d'autre utilisation de cet espace de noms avant cet endroit. Peut-être devriez-vous déclarer au préalable votre paquetage ?
Bareword found in conditional
- (Mot simple détecté dans une condition)
- (W bareword) Le compilateur a trouvé un mot simple là où il attendait une condition, ce qui indique souvent qu'un
||ou un&&a été analysé comme faisant partie du dernier argument de la construction précédente, par exemple :
open FOO || die;- Cela peut également indiquer une constante mal orthographiée qui a été interprétée en tant que mot simple :
- Le pragma strict est très utile pour éviter de telles erreurs.
BEGIN failed--compilation aborted
- (Échec de BEGIN — compilation abandonnée)
- (F) Une exception non interceptable a été levée pendant l'exécution d'un sous-programme BEGIN. La compilation s'arrête immédiatement et l'on quitte l'interpréteur.
BEGIN not safe after errors--compilation aborted
- (BEGIN non sécurisé après des erreurs — compilation abandonnée)
- (F) Perl a trouvé un sous-programme BEGIN (ou une directive use, ce qui implique un BEGIN) après qu'une ou plusieurs erreurs de compilation sont déjà survenues. Comme l'environnement du BEGIN ne peut être garanti (à cause des erreurs) et comme le code qui suit est susceptible de dépendre de son bon fonctionnement, Perl rend la main.
Binary number > 0b11111111111111111111111111111111 non portable
- (Nombre binaire >
0b11111111111111111111111111111111, non portable) - (W portable) Le nombre binaire que vous avez spécifié est plus grand que
2**31-1(4 294 967 295) et n'est donc pas portable entre les systèmes.
bind() on closed socket %s
- (
bindsur une socket fermée%s) - (W closed) Vous avez essayé de faire un
bindsur une socket fermée. Peut-être avez-vous oublié de vérifier la valeur renvoyée par l'appel desocket?
Bit vector size > 32 non portable
- (Taille de vecteur de bits >32, non portable)
- (W portable) L'utilisation de tailles de vecteurs de bits supérieures à 32 n'est pas portable.
Bizarre copy of %s in %s
- (Copie étrange de
%sdans%s) - (P) Perl a détecté une tentative de copie d'une valeur interne qui n'est pas copiable.
Buffer overflow in prime_env_iter: %s
- (Dépassement du tampon dans prime_env_iter :
%s) - (W internal) Il s'agit d'un avertissement spécifique à VMS. Pendant que Perl se préparait à parcourir
%ENV, il a rencontré un nom logique ou une définition de symbole qui était trop long, il l'a donc tronqué vers la chaîne indiquée.
Callback called exit
- (La fonction de rappel a appelé exit)
- (F) Un sous-programme invoqué depuis un paquetage externe via call_sv s'est terminée en appelant exit.
Can't "goto" out of a pseudo block
- ("goto" impossible vers l'extérieur d'un pseudobloc)
- (F) Une instruction goto a été exécutée pour quitter ce qui semblerait être un bloc, excepté que ce n'est pas un bloc correct. Ceci se produit habituellement si vous essayez de sauter hors d'un bloc sort ou d'un sous-programme, ce qui n'a pas de sens.
Can't "goto" into the middle of a foreach loop
- ("goto" impossible vers le milieu d'une boucle foreach)
- (F) Une instruction goto a été exécutée pour sauter au milieu d'une boucle foreach. Vous ne pouvez y aller depuis cet endroit.
Can't "last" outside a loop block
- ("last" impossible vers l'extérieur d'un bloc de boucle)
- (F) Une instruction last a été exécutée pour sortir du bloc courant, excepté ce léger problème qu'il n'existe pas de bloc courant. Remarquez que les blocs if ou else ne comptent pas comme des blocs de boucle, tout comme tout comme les blocs passés à
sort,mapougrep. Vous pouvez habituellement doubler les accolades pour obtenir le même effet, car les accolades intérieures seront considérées comme un bloc qui boucle une seule fois.
Can't "next" outside a loop block
- ("next" impossible vers l'extérieur d'un bloc de boucle)
- (F) Une instruction next a été exécutée pour recommencer le bloc courant, mais il n'existe pas de bloc courant. Remarquez que les blocs if ou else ne comptent pas comme des blocs de boucle, tout comme les blocs passés à
sort,mapougrep. Vous pouvez habituellement doubler les accolades pour obtenir le même effet, car les accolades intérieures seront considérées comme un bloc qui boucle une seule fois.
Can't read CRTL environ
- (Impossible de lire l'environnement de CRTL)
- (S) Il s'agit d'un avertissement spécifique à VMS. Perl a essayé de lire un élément de
%ENVdepuis le tableau d'environnement interne de CRTL et a découvert que le tableau n'existait pas. Vous devez déterminer où CRTL a incorrectement placé son environnement ou définir PERL_ENV_TABLES (voir perlvms(1)) pour que le tableau d'environnement ne soit pas recherché.
Can't "redo" outside a loop block
- (
"redo" impossible vers l'extérieur d'un bloc de boucle) - (F) Une instruction redo a été exécutée pour recommencer le bloc courant, mais il n'existe pas de bloc courant. Remarquez que les blocs if ou else ne comptent pas comme des blocs de boucle, tout comme les blocs passés à
sort,mapougrep. Vous pouvez habituellement doubler les accolades pour obtenir le même effet, car les accolades intérieures seront considérées comme un bloc qui boucle une seule fois.
Can't bless non-reference value
- (Impossible de consacrer avec
blessune valeur qui ne soit pas une référence) - (F) Seules les références en dur peuvent être consacrées avec
bless. C'est de cette manière que Perl « applique » l'encapsulation des objets.
Can't break at that line
- (Impossible de s'arrêter à cette ligne)
- (S internal) Il s'agit d'un message d'erreur qui n'est affiché que lorsque le programme s'exécute avec le débogueur, indiquant que le numéro de ligne spécifié n'est pas l'emplacement d'une instruction à laquelle on peut s'arrêter.
Can't call method "%s" in empty package "%s"
- (Impossible d'appeler la méthode "
%s" dans le paquetage vide "%s") - (F) Vous avez appelé une méthode correctement et vous avez indiqué correctement le paquetage pris en tant que classe, mais ce paquetage n'a rien de défini et n'a pas de méthodes.
Can't call method "%s" on unblessed reference
- (Impossible d'appeler la méthode "
%s" sur une référence non consacrée avecbless) - (F) Un appel de méthode doit connaître depuis quel paquetage elle est supposée être lancée. Il trouve habituellement ceci dans la référence de l'objet que vous soumettez, mais vous n'avez pas fourni de référence d'objet dans ce cas. Une référence n'est pas une référence d'objet jusqu'à ce qu'elle ait été consacrée (avec
bless).
Can't call method "%s" without a package or object reference
- (Impossible d'appeler la méthode "
%s" dans un paquetage ou une référence d'objet) - (F) Vous avez utilisé la syntaxe d'un appel de méthode, mais la place réservée à la référence d'objet ou au nom du paquetage contient une expression qui retourne une valeur définie qui n'est ni une référence d'objet ni un nom de paquetage. Quelque chose comme ceci reproduira l'erreur :
$MAUVAISE_REF = 42;
traite $MAUVAISE_REF 1,2,3;
$MAUVAISE_REF->traite(1,2,3);Can't call method "%s" on an undefined value
- (Impossible d'appeler la méthode "
%s" sur une valeur indéfinie) - (F) Vous avez utilisé la syntaxe d'un appel de méthode, mais la place réservée à la référence d'objet ou au nom du paquetage contient une une valeur indéfinie. Quelque chose comme ceci reproduira l'erreur :
$MAUVAISE_REF = undef;
traite $MAUVAISE_REF 1,2,3;
$MAUVAISE_REF->traite(1,2,3);Can't chdir to %s
- (
chdirimpossible vers%s) - (F) Vous avez appelé perl -x/truc/bidule, mais /truc/bidule n'est pas un répertoire dans lequel vous pouvez rentrer avec
chdir, probablement parce qu'il n'existe pas.
Can't check filesystem of script "%s" for nosuid
- (Impossible de vérifier le nosuid pour le système de fichier du script "
%s") - (P) Pour une raison ou pour une autre, vous ne pouvez pas vérifier le nosuid pour le système de fichier du script.
Can't coerce %s to integer in %s
- (Impossible de convertir
%svers un entier dans%s) - (F) On ne peut pas forcer certains types de SV, en particulier les entrées de la table des symboles (typeglobs) à cesser d'être ce qu'ils sont. Donc vous ne pouvez pas faire des choses telles que :
*truc += 1;Vous pouvez écrire :
$truc = *truc; $truc += 1;- mais alors
$trucne contient plus de glob.
Can't coerce %s to number in %s
- (Impossible de convertir
%svers un nombre dans%s) - (F) On ne peut pas forcer certains types de SVs, en particulier les entrées de la table des symboles (typeglobs) à cesser d'être ce qu'ils sont.
Can't coerce %s to string in %s
- (Impossible de convertir
%svers une chaîne dans%s) - (F) On ne peut pas forcer certains types de SVs, en particulier les entrées de la table des symboles (typeglobs) à cesser d'être ce qu'ils sont.
Can't coerce array into hash
- (Impossible de convertir un tableau vers un hachage)
- (F) Vous avez utilisé un tableau là où un hachage était attendu, mais le tableau n'a pas d'informations sur la manière de passer des clefs aux indices de tableau. Vous ne pouvez faire cela qu'avec les tableaux qui ont une référence de hachage à l'indice 0.
Can't create pipe mailbox
- (Impossible de créer un pipe de boîte aux lettres)
- (P) Il s'agit d'une erreur spécifique à VMS. Le processus souffre de quotas dépassés ou d'autres problèmes de plomberie.
Can't declare class for non-scalar %s in "%s"
- (Impossible de déclarer une classe pour le non-scalaire
%sdans "%s") - (S) Actuellement, seules les variables scalaires peuvent être déclarées avec un qualificateur de classe spécifique dans une déclaration my ou our. Les sémantiques peuvent être étendues à d'autres types de variables à l'avenir.
Can't declare %s in "%s"
- (Impossible de déclarer
%sdans "%s") - (F) Seuls les scalaires, les tableaux et les hachages peuvent être déclarés comme variables my ou our. Ils doivent avoir un identificateur ordinaire comme nom.
Can't do inplace edit on %s: %s
- (Impossible d'éditer sur place
%s) - (S inplace) La création du nouveau fichier a échoué à cause de la raison indiquée.
Can't do inplace edit without backup
- (Impossible d'éditer sur place sans copie de sauvegarde)
- (F) Vous êtes sur un système comme MS-DOS qui s'embrouille si vous essayez de lire un fichier supprimé (mais toujours ouvert). Vous devez écrire -i.bak, ou quelque chose comme ça.
Can't do inplace edit: %s would not be unique
- (Impossible d'éditer sur place :
%sne serait pas unique) - (S inplace) Votre système de fichier ne supporte pas les noms de fichiers plus longs que 14 caractères et Perl n'a pas pu créer un nom de fichier unique durant l'édition sur place avec l'option -i. Ce fichier a été ignoré.
Can't do inplace edit: %s is not a regular file
- (Impossible d'éditer sur place :
%sn'est pas un fichier ordinaire) - (S inplace) Vous avez essayé d'utiliser l'option -i sur un fichier spécial, comme un fichier dans /dev ou une FIFO. Le fichier a été ignoré.
Can't do setegid!
- (setegid impossible !)
- (P) L'appel à setegid a échoué pour une raison ou pour une autre dans l'émulateur setuid de suidperl.
Can't do seteuid!
- (seteuid impossible !)
- (P) L'émulateur setuid de suidperl a échoué pour une raison ou pour une autre.
Can't do setuid
- (setuid impossible)
- (F) Cela veut généralement dire que le perl ordinaire a essayé de faire
execsuidperl pour émuler le setuid, mais n'a pas pu faire leexec. Il cherche un nom de la forme sperl5.000 dans le même répertoire que celui où réside l'exécutable perl sous le nom perl5.000, généralement /usr/local/bin sur les machines Unix. Si le fichier s'y trouve, vérifiez les permissions d'exécution. S'il n'est pas là, demandez à votre administrateur système pourquoi.
Can't do waitpid with flags
- (
waitpidimpossible avec les drapeaux) - (F) Cette machine n'a pas ni
waitpidni wait4, ainsi seulwaitpidsans aucun drapeau est émulé.
Can't do {n,m} with n > m
- (Impossible de faire
{n,m}avec n > m) - (F) Les minima doivent être inférieurs ou égaux aux maxima. Si vous voulez vraiment que votre expression régulière corresponde 0 fois, faites juste
{0}.
Can't emulate -%s on #! line
- (Impossible d'émuler -
%ssur la ligne#!) - (F) La ligne
#!spécifie une option qui n'a pas de sens à cet endroit. Par exemple, il serait un peu idiot de mettre l'option -x sur cette ligne#!.
Can't exec "%s": %s
- (
execde "%s" impossible :%s) - (W exec) L'appel à
system,exec, ouopensur un pipe n'a pu s'exécuter pour la raison indiquée. Les raisons typiques incluent de mauvaises permissions sur le fichier, que le fichier n'a pu être trouvé dans$ENV{PATH}, que l'exécutable en question a été compilé pour une autre architecture ou que la ligne#!pointe vers un interpréteur qui ne peut pas être lancé pour des raisons similaires. (Ou peut-être votre système ne supporte pas du tout#!).
Can't exec %s
- (
exec%simpossible) - (F) Perl a essayé d'exécuter le programme indiqué pour vous, car c'est ce qui est spécifié sur la ligne
#!. Si ce n'est pas ce que vous vouliez, vous devrez mentionner perl quelque part sur la ligne#!.
Can't execute %s
- (Impossible d'exécuter
%s) - (F) Vous avez utilisé l'option -S, mais les copies du script à exécuter trouvées dans le PATH n'ont pas les bonnes permissions.
Can't find %s on PATH, '.' not in PATH
- (Impossible de trouver
%sdans le PATH,"." n'est pas dans le PATH) - (F) Vous avez utilisé l'option -S, mais le script à exécuter ne peut être trouvé dans le PATH ou tout au moins avec des permissions incorrectes. Le script existe dans le répertoire courant, mais le PATH l'empêche de se lancer.
Can't find %s on PATH
- (Impossible de trouver
%sdans le PATH) - (F) Vous utilisez l'option -S, mais le script à exécuter ne peut être trouvé dans le PATH.
Can't find an opnumber for "%s"
- (Impossible de trouver un numéro d'opération pour "
%s") - (F) Une chaîne de la forme CORE::mot a été donnée à, prototype mais il n'existe pas de fonction interne nommée mot.
Can't find label %s
- (Impossible de trouver l'étiquette
%s) - (F) Vous avez dit par un goto d'aller à une étiquette qui n'est mentionnée à aucun endroit où il nous est possible d'aller.
Can't find string terminator %s anywhere before EOF
- (Impossible de trouver la fin de la chaîne
%squelque part avant EOF) - (F) Les chaînes de caractères en Perl peuvent s'étirer sur plusieurs lignes. Ce message signifie que vous avez oublié le délimitateur fermant. Comme les parenthèses protégées par des apostrophes comptent pour un niveau, il manque dans l'exemple suivant la parenthèse finale :
print q(Le caractère '(' commence une nouvelle citation.);- Si vous obtenez cette erreur depuis un document « ici-même » (N.d.T. : here document), vous devez avoir mis des espaces blancs non visibles avant ou après la marque de fermeture. Un bon éditeur pour les programmeurs devrait pouvoir vous aider à trouver ces caractères.
Can't fork
- (
forkimpossible) - (F) Une erreur fatale est survenue en essayant de faire un
fork.
Can't get filespec -stale stat buffer?
- (Impossible d'obtenir la spécification du fichier — tampon
statpérimé ?) - (S) Il s'agit d'un avertissement spécifique à VMS. Ceci arrive à cause des différences entre les contrôles d'accès sous VMS et sous le modèle Unix qui est celui que Perl présuppose. Sous VMS, les contrôles d'accès sont faits par le nom de fichier, plutôt que par les bits du tampon de
stat, ce qui fait que les ACL et les autres protections peuvent être pris en compte. Malheureusement, Perl présuppose que le tampon destatcontient toutes les informations nécessaires et le fournit, à la place de la spécification du fichier, à la fonction de contrôle d'accès. Il va essayer d'obtenir les spécifications du fichier en utilisant le nom du périphérique et le FID présents dans le tampon destat, mais si vous avez fait ensuite un appel à la fonctionstatde CRTL, cela ne fonctionnera pas, car le nom du périphérique est écrasé à chaque appel. Si cet avertissement apparaît, la recherche de nom a échoué et la fonction de contrôle d'accès a rendu la main en retournant une valeur fausse, histoire d'être un peu conservateur. (Remarque : la fonction de contrôle d'accès connaît l'opérateurstatde Perl et les tests de fichiers, vous ne devriez donc jamais voir cet avertissement en réponse à une commande Perl ; il ne se produit que si du code interne prend les tampons destatà la légère.)
Can't get pipe mailbox device name
- (Impossible d'obtenir le nom de périphérique d'un pipe de boîte aux lettres)
- (P) Il s'agit d'une erreur spécifique à VMS. Après avoir créé une boîte aux lettres se comportant comme un pipe, Perl ne peut obtenir son nom pour un usage ultérieur.
Can't get SYSGEN parameter value for MAXBUF
- (Impossible d'obtenir la valeur du paramètre SYSGEN pour MAXBUF)
- (P) Il s'agit d'une erreur spécifique à VMS. Perl a demandé à
$GETSYIquelle taille vous voulez pour vos tampons de boîtes aux lettres et il n'a pas obtenu de réponse.
Can't goto subroutine outside a subroutine
- (goto vers un sous-programme impossible à l'extérieur d'un sous-programme)
- (F) L'appel hautement magique goto SOUS_PROGRAMME ne peut que remplacer l'appel d'une fonction par une autre. Il ne peut en fabriquer une brute de fonderie. En général, vous ne devriez de toute façon l'appeler que depuis une fonction d'AUTOLOAD.
Can't goto subroutine from an eval-string
- (goto vers un sous-programme impossible depuis une chaîne eval)
- (F) L'appel goto SOUS_PROGRAMME ne peut être utilisé pour sortir d'une chaîne eval. (Vous pouvez l'utiliser pour sortir d'un, eval BLOC mais ce n'est probablement pas ce que vous voulez.)
Can't ignore signal CHLD, forcing to default
- (Impossible d'ignorer le signal CHLD, la valeur par défaut est forcée)
- (W signal) Perl a détecté qu'il avait été lancé avec le signal SIGCHLD (quelquefois appelé SIGCLD) désactivé. Comme la désactivation de ce signal va interférer avec une détermination correcte du statut de sortie des processus fils, Perl a remis le signal à sa valeur par défaut. Cette situation indique généralement que le programme père sous lequel Perl pourrait tourner (exemple : cron) est très peu précautionneux.
Can't localize through a reference
- (Impossible de rendre locale via une référence)
- (F) Vous avez écrit quelque chose comme local
$$ref, ce que Perl ne sait actuellement pas gérer, car quand il va restaurer l'ancienne valeur de ce vers quoi$refpointait après que la portée du local est terminée, il ne peut être sûr que$refsoit toujours une référence.
Can't localize lexical variable %s
- (Impossible de rendre locale la variable
%s) - (F) Vous avez utilisé local sur une variable qui a déjà été déclarée auparavant comme une variable lexicale à l'aide de my. Ceci n'est pas permis. Si vous voulez rendre locale une variable de paquetage du même nom, qualifiez-la avec le nom du paquetage.
Can't localize pseudo-hash element
- (Impossible de rendre local un élément de pseudohachage)
- (F) Vous avez écrit quelque chose comme local
$tab->{'clef'}, où$tabest une référence vers un pseudohachage. Cela n'a pas encore été implémenté, mais vous pouvez obtenir un effet similaire en rendant local l'élément du tableau correspondant directement -local$tab->[$tab->[0]{'clef'}].
Can't locate auto/%s.al in @INC
- (Impossible de trouver auto
/%s.al dans@INC) - (F) Une fonction (ou une méthode) a été appelée dans un paquetage qui autorise le chargement automatique, mais il n'existe pas de fonction à charger automatiquement. Les causes les plus probables sont une faute de frappe dans le nom de la fonction ou de la méthode ou un échec dans l'AutoSplit du fichier, disons, lors du make install.
Can't locate %s
- (Impossible de trouver
%s) - (F) Vous avez écrit de faire un do (ou un require ou un use) sur un fichier qui n'a pu être trouvé. Perl cherche le fichier dans tous les emplacements mentionnés dans
@INC, à moins que le nom du fichier ne précise son chemin complet. Peut-être avez-vous besoin de positionner la variable d'environnement PERL5LIB ou PERL5OPT pour indiquer où se trouve la bibliothèque ou il est possible que le script ait besoin d'ajouter le nom de la bibliothèque à@INC. Ou enfin, vous avez peut-être seulement mal épelé le nom du fichier.
Can't locate object method "%s" via package "%s"
- (Impossible de trouver la méthode objet "
%s" via le paquetage%s) - (F) Vous avez appelé une méthode correctement et vous avez correctement indiqué un paquetage fonctionnant comme une classe, mais ce paquetage ne définit pas cette méthode-là, ni aucune de ses classes de base.
Can't locate package %s for @%s::ISA
- (Impossible de trouver le paquetage
%spour@%s::ISA) - (W syntax) Le tableau
@ISAcontient le nom d'un autre paquetage qui semble ne pas exister.
Can't make list assignment to \%ENV on this system
- (Impossible d'assigner une liste à \
%ENVsur ce système) - (F) L'affectation d'une liste à
%ENVn'est pas supporté sur certains systèmes, notamment VMS.
Can't modify %s in %s
- (Impossible de modifier
%sdans%s) - (F) Vous n'êtes pas autorisé à faire d'affectation sur l'élément indiqué, ou à essayer de le changer autrement, comme avec une incrémentation automatique.
Can't modify non-lvalue subroutine call
- (Impossible de modifier un appel de sous-programme qui ne soit pas une lvalue)
- (F) Les sous-programmes destinés à être utilisés dans un contexte de lvalue doivent être déclarés en tant que tels.
Can't modify nonexistent substring
- (Impossible de modifier une sous-chaîne inexistante)
- (P) La routine interne qui fait l'affectation
substra capturé un NULL.
Can't msgrcv to read-only var
- (
msgrcvd'une var en lecture seule impossible) - (F) La cible d'un
msgrcvdoit être modifiable pour être utilisée comme un tampon de réception.
Can't open %s:%s
- (Impossible d'ouvrir
%s:%s) - (S inplace) L'ouverture implicite d'un fichier via le handle de fichier
<>, soit implicitement via les options de la ligne de commande -n ou -p, soit explicitement, a échoué à cause de la raison indiquée. Habituellement c'est parce que vous n'avez pas les permissions en lecture sur le fichier que vous avez indiqué sur la ligne de commande.
Can't open bidirectional pipe
- (Impossible d'ouvrir un pipe bidirectionnel)
- (W pipe) Vous avez essayé d'écrire
open(CMD,"|cmd|"), ce qui n'est pas supporté. Vous pouvez essayer l'un des nombreux modules de la bibliothèque Perl pour faire cela, comme IPC::Open2. Ou alors, dirigez la sortie du pipe dans un fichier en utilisant>et ensuite lisez-le dans un handle de fichier différent.
Can't open error file %s as stderr
- (Impossible d'ouvrir le fichier d'erreur
%scomme stderr) - (F) Il s'agit d'une erreur spécifique à VMS. Perl fait ses propres redirections de la ligne de commande et ne peut ouvrir le fichier spécifié après
2>ou2>>sur la ligne de commande pour y écrire.
Can't open input file %s as stdin
- (Impossible d'ouvrir le fichier d'entrée
%scomme stdin) - (F) Il s'agit d'une erreur spécifique à VMS. Perl fait ses propres redirections de la ligne de commande et ne peut ouvrir le fichier spécifié après
<sur la ligne de commande pour y lire.
Can't open output file %s as stdout
- (Impossible d'ouvrir le fichier de sortie
%scomme stdout) - (F) Il s'agit d'une erreur spécifique à VMS. Perl fait ses propres redirections de la ligne de commande et ne peut ouvrir le fichier spécifié après
>ou>>sur la ligne de commande pour y écrire.
Can't open output pipe (name: %s)
- (Impossible d'ouvrir le pipe de sortie (nom :
%s)) - (P) Il s'agit d'une erreur spécifique à VMS. Perl fait ses propres redirections de la ligne de commande et ne peut ouvrir le pipe dans lequel envoyer les données destinées à STDOUT.
Can't open perl script "%s": %s
- (Impossible d'ouvrir le script perl "
%s" :%s) - (F) Le script que vous avez spécifié ne peut être ouvert pour la raison indiquée.
Can't redefine active sort subroutine %s
- (Impossible de redéfinir le sous-programme de
sortactif) - (F) Perl optimise la gestion interne des sous-programmes de
sortet garde des pointeurs vers ceux-ci. Vous avez essayé de redéfinir un de ces sous-programmes desortalors qu'il était actuellement actif, ce qui n'est pas permis. Si vous voulez vraiment faire cela, vous devez écriresort{&fonc}@xau lieu desortfonc@x.
Can't remove %s:%s, skipping file
- (Impossible de supprimer
%s:%s, fichier passé) - (S inplace) Vous avez demandé une édition sur place sans créer un fichier de sauvegarde. Perl a été incapable de supprimer le fichier original pour le remplacer avec celui modifié. Le fichier a été laissé inchangé.
Can't rename %s to %s:%s, skipping file
- (Impossible de renommer
%sen%s:%s, fichier passé) - (S inplace) Le renommage effectué par l'option -i a échoué pour une raison ou pour une autre, probablement parce que vous n'avez pas le droit d'écrire dans le répertoire.
Can't reopen input pipe (name: %s) in binary mode
- (Impossible de rouvrir le pipe d'entrée (nom :
%s) en mode binaire) - (P) Il s'agit d'une erreur spécifique à VMS. Perl pensait que STDIN était un pipe et a essayé de le rouvrir pour accepter des données binaires. Hélas, cela a échoué.
Can't resolve method "%s" overloading "%s" in paquetage "%s"
- (Impossible de résoudre la méthode "
%s" surchargeant "%s" dans le paquetage "%s") - (F|P) Une erreur s'est produite lors de la résolution de la surcharge spécifiée par un nom de méthode (à l'inverse d'une référence de sous-programme) : aucune méthode de ce nom ne peut être appelée via ce paquetage. Si le nom de la méthode est
???, il s'agit d'une erreur interne.
Can't reswap uid and euid
- (Impossible d'échanger à nouveau l'uid et l'euid)
- (P) L'appel setreuid a échoué pour une raison ou pour une autre dans l'émulateur setuid de suidperl.
Can't return outside a subroutine
- (return impossible à l'extérieur d'un sous-programme)
- (F) L'instruction return a été exécutée dans le fil principal du code, c'est-à-dire là où il n'y a aucun appel de sous-programme dont on peut revenir avec return.
Can't return %s from lvalue subroutine
- (Impossible de renvoyer
%sd'un sous-programme utilisé comme lvalue) - (F) Perl a détecté que la valeur renvoyée par un sous-programme utilisé comme lvalue est illégale (constante ou variable temporaire). C'est interdit.
Can't stat script "%s"
- (
statdu script impossible :%s) - (P) Pour une raison ou pour une autre, vous ne pouvez faire de fstat sur le script même si vous l'avez déjà ouvert. Bizarre.
Can't swap uid and euid
- (Impossible d'échanger l'uid et l'euid)
- (P) L'appel setreuid a échoué pour une raison ou pour une autre dans l'émulateur setuid de suidperl.
Can't take log of %g
- (Impossible de calculer le log de
%g) - (F) Pour les nombres réels ordinaires, vous ne pouvez calculer le logarithme d'un nombre négatif ou nul. Il existe toutefois un paquetage Math::Complex livré en standard avec Perl, si c'est vraiment ce que vous voulez faire cela avec les nombres négatifs.
Can't take sqrt of %g
- (Impossible de calculer la racine carrée de
%g) - (F) Pour les nombres réels ordinaires, vous ne pouvez calculer la racine carrée d'un nombre négatif. Il existe toutefois le paquetage Math::Complex livré en standard avec Perl, si vous voulez vraiment faire cela.
Can't undef active subroutine
- (
undefdu sous-programme actif impossible) - (F) Vous ne pouvez rendre indéfinie une fonction qui est actuellement utilisée. Cependant, vous pouvez la redéfinir pendant qu'elle tourne et même faire un
undefsur le sous-programme redéfini pendant que l'ancien tourne. Maintenant, c'est à vous de voir.
Can't unshift
- (
unshiftimpossible) - (F) Vous avez essayé de faire un
unshiftsur un tableau « irréel » qui ne peut accepter cette opération, comme la pile principale de Perl.
Can't upgrade that kind of scalar
- (Impossible de mettre à niveau ce type de scalaire)
- (P) La routine interne sv_upgrade a ajouté des « membres » à un SV, ce qui fait qu'il se trouve dans une sorte de SV plus spécialisée. Les différents types les plus élevés de SV sont cependant si spécialisés, qu'ils ne peuvent être convertis entre eux. Ce message indique qu'une telle conversion a été tentée.
Can't upgrade to undef
- (Impossible de mettre à niveau vers
undef) - (P) Le SV indéfini représente le niveau zéro de l'évolutivité. L'évolution vers
undefindique une erreur dans le code appelant sv_upgrade.
Can't use %%! because Errno.pm is not available
- (Impossible d'utiliser,
%%!car Errno.pm n'est pas disponible) - (F) La première fois que le hachage
%!est utilisé, Perl charge automatiquement le module Errno. On attend du module Errno qu'il se lie avectieau hachage%!pour fournir des noms symboliques pour les valeurs des numéros d'erreur de$!.
Can't use "my %s" in sort comparison
- (Impossible d'utiliser « my
%s» dans les comparaisons desort) - (F) Les variables globales
$aet$bsont réservées pour les comparaisons desort. Vous avez mentionné$aou$bdans la même ligne que les opérateurs<=>oucmpet la variable avait été déclarée précédemment en tant que variable lexicale. Soit qualifiez la variable desortavec le nom de paquetage, soit renommez la variable lexicale.
Can't use %s for loop variable
- (Impossible d'utiliser
%scomme variable de boucle) - (F) Seule une variable scalaire simple peut être utilisée comme variable de boucle dans un foreach.
Can't use %s ref as %s ref
- (Impossible d'utiliser la ref
%sen tant que ref de%s) - (F) Vous avez mélangé vos types de références. Vous devez déréférencer la référence du type nécessaire. Vous pouvez utiliser la fonction
refpour tester le type de la référence, si besoin.
Can't use \%c to mean $%c in expression
- (Impossible d'utiliser \
%cpour signifier$%cdans une expression) - (W syntax) Dans une expression ordinaire, l'antislash est un opérateur unaire qui crée une référence vers son argument. L'utilisation d'un antislash pour indiquer une référence arrière vers une sous-chaîne réussissant la correspondance n'est valide qu'à l'intérieur du motif de l'expression régulière. Essayer de faire cela dans un code ordinaire Perl produit une valeur qui s'affiche comme SCALAR(
0xdecaf). Utilisez la forme$1à la place.
Can't use bareword ("%s") as %s ref while "strict refs" in use
- (Impossible d'utiliser un mot simple ("
%s") en tant que ref de%spendant que"strict refs"est actif) - (F) Les références en dur sont les seules autorisées par strict refs. Les références symboliques sont interdites.
Can't use string ("%s") as %s ref while "strict refs" in use
- (Impossible d'utiliser une chaîne ("
%s") en tant que ref de%spendant que "strict refs" est actif) - (F) Les références en dur sont les seules autorisées par strict refs. Les références symboliques sont interdites.
Can't use an undefined value as %s reference
- (Impossible d'utiliser une valeur indéfinie comme référence de
%s) - (F) Une valeur utilisée soit comme une référence en dur, soit comme une référence symbolique doit avoir une valeur définie. Cela aide à débloquer certaines erreurs insidieuses.
Can't use global %s in "my"
- (Impossible d'utiliser la variable globale
%sdans "my") - (F) Vous avez essayé de déclarer une variable magique en tant que variable lexicale. Cela n'est pas permis, car la variable magique ne peut être liée qu'à un seul endroit (nommé variable globale) et il serait incroyablement confus d'avoir des variables dans votre programme qui ressemblent à des variables magiques, mais qui n'en sont pas.
Can't use subscript on %s
- (Impossible d'utiliser un indice sur
%s) - (F) Le compilateur a essayé d'interpréter une expression entre crochets en tant qu'indice. Mais à gauche des crochets, il y avait une expression qui ne ressemblait pas à une référence de tableau, ni à quoi que ce soit que l'on puisse indicer.
Can't weaken a nonreference
- (Impossible d'affaiblir une non-référence)
- (F) Vous avez tenté d'affaiblir quelque chose qui n'était pas une référence. Seules les références peuvent être affaiblies.
Can't x= to read-only value
- (
x=impossible sur une valeur en lecture seule) - (F) Vous avez essayé de répéter une valeur constante (souvent la valeur indéfinie) avec un opérateur d'affectation, ce qui implique de modifier la valeur elle-même. Peut-être devriez-vous copier la valeur dans une variable temporaire, et répéter cela.
Character class [:%s:] unknown
- (Classe de caractères [:
%s:] inconnue) - (F) La classe dans la syntaxe pour une classe de caractères [: :] est inconnue.
Character class syntax [%s] belongs inside character classes
- (La syntaxe [
%s] pour une classe de caractères appartient aux classes de caractères) - (W unsafe) Les constructions de classes de caractères [: :], [
==] et [. .] se rangent dans les classes de caractères, par exemple :/[012[:alpha:]345]/. Remarquez que les constructions [==] et [. .] ne sont pas implémentées actuellement ; ce sont juste des places réservées pour de futures extensions.
Character class syntax [. .] is reserved for future extensions
- (Syntaxe [. .] pour une classe de caractère réservée pour de futures extensions)
- (W regexp) À l'intérieur des classes de caractères dans les expressions régulières ([]), la syntaxe commençant par [. et se terminant par .] est réservée pour de futures extensions. Si vous avez besoin de représenter de telles séquences de caractères à l'intérieur d'une classe de caractères dans une expression régulière, protégez simplement les crochets avec un antislash : \[. et .\].
Character class syntax [= =] is reserved for future extensions
- (Syntaxe [
==] pour une classe de caractère réservée pour de futures extensions) - (W regexp) À l'intérieur des classes de caractères dans les expressions régulières ([]), la syntaxe commençant par [
=et se terminant par=] est réservée pour de futures extensions. Si vous avez besoin de représenter de telles séquences de caractères à l'intérieur d'une classe de caractères dans une expression régulière, protégez simplement les crochets avec un antislash : \[. et .\].
chmod() mode argument is missing initial 0
- (Il manque le
0au début de l'argument représentant le mode dechmod()) -
(W chmod) Un utilisateur novice aura tendance à écrire :
Sélectionnezchmod777,$fichier - en ne réalisant pas que 777 sera interprété comme un nombre décimal, équivalent à 01411. Les constantes octales sont introduites en les faisant débuter par un 0 en Perl, tout comme en C.
Close on unopened file <%s>
- (Ferme un fichier non ouvert <
%s>) - (W) Vous avez essayé de fermer un descripteur de fichier qui n'avait jamais été ouvert.
Compilation failed in require
- (Échec de la compilation dans require)
- (F) Perl n'a pas pu compiler le fichier spécifié dans une instruction require. Perl utilise ce message générique lorsqu'aucune des erreurs rencontrées n'est assez grave pour arrêter la compilation immédiatement.
Complex regular subexpression recursion limit (%d) exceeded
- (Limite de récursion pour les expressions régulières complexes (
%d) atteinte) - (W regexp) Le moteur d'expressions régulières utilise la récursion dans les situations complexes où les retours arrières sont nécessaires. La profondeur de la récursion est limitée à 32 766, ou peut-être moins sur les architectures où la pile ne peut croître arbitrairement. (Les situations « simples » et « moyennes » peuvent être gérées sans récursion et ne sont pas sujettes à une limite.) Essayez de raccourcir la chaîne examinée, faites des boucles dans le code Perl (exemple : avec while) plutôt qu'avec le moteur d'expressions régulières ou réécrivez l'expression régulière pour qu'elle soit plus simple ou qu'elle contienne moins de retours arrière.
connect() on closed socket %s
- (
connect() sur une socket fermée%s) - (W closed) Vous avez essayé de faire un
connectsur une socket fermée. Peut-être avez-vous oublié de vérifier la valeur retournée par l'appel desocket?
Constant is not %s reference
- (La constante n'est pas une référence de
%s) - (F) Une valeur constante (déclarée peut-être en utilisant le pragma use constant) est déréférencée, mais équivaut à une référence d'un mauvais type. Le message indique le type de référence qui était attendu. Ceci indique habituellement une erreur de syntaxe en déréférençant la valeur constante.
Constant subroutine %s redefined
- (Sous-programme constant
%sredéfini) - (S|W redefine) Vous avez redéfini un sous-programme qui a été désigné auparavant comme étant en ligne (inlining).
Constant subroutine %s undefined
- (Sous-programme constant
%sindéfini) - (W misc) Vous avez rendu indéfini un sous-programme qui a été désigné auparavant comme étant en ligne (inlining).
constant(%s): %s
- (constant(
%s) :%s) - (F) L'analyseur syntaxique a trouvé des incohérences soit en tentant de définir une constante surchargée, soit en essayant de trouver le nom de caractère spécifié dans la séquence d'échappement \N
{...}. Peut-être avez-vous oublié de charger les pragmas correspondants overload ou charnames.
Copy method did not return a reference
- (La méthode de copie n'a pas renvoyé de référence)
- (F) La méthode qui surcharge
=est boguée.
CORE::%s is not a keyword
- (CORE::
%sn'est pas un mot clef) - (F) L'espace de noms CORE:: est réservé pour les mots clefs de Perl.
Corrupt malloc ptr 0x%lx at 0x%lx
- (Pointeur de malloc 0x
%lxcorrompu en 0x%lx) - (P) Le paquetage malloc distribué avec Perl a eu une erreur interne.
corrupted regexp pointers
- (Pointeurs d'expressions régulières corrompus)
- (P) Le moteur d'expressions régulières est devenu confus parce que le compilateur d'expressions régulières lui a donné.
corrupted regexp program
- (Programme d'expressions régulières corrompu)
- (P) On a passé au moteur d'expressions régulières un programme d'expression régulière sans nombre magique valide.
Deep recursion on subroutine "%s"
- (Récursion profonde pour le sous-programme "
%s") - (W recursion) Ce sous-programme s'est appelé lui-même (directement ou indirectement) 100 fois de plus qu'il n'est revenu. Ceci indique probablement une récursion infinie, à moins que vous n'écriviez un étrange programme de benchmark, auquel cas cela indique quelque chose d'autre.
defined(@array) is deprecated
- (
defined(@tableau) est déprécié) - (D deprecated)
definedn'est habituellement pas très utile sur les tableaux, car il teste la présence d'une valeur scalaire indéfinie. Si vous voulez voir si le tableau est vide, vous n'avez qu'à utiliser if (@tableau){# pas vide }.
defined(%hash) is deprecated
- (
defined(%hachage) est déprécié) - (D deprecated)
definedn'est habituellement pas très utile sur les hachages, car il teste la présence d'une valeur scalaire indéfinie. Si vous voulez voir si le hachage est vide, vous n'avez qu'à utiliser if (%hachage){# pas vide }.
Delimiter for here document is too long
- (Le délimiteur pour le document « ici-même » est trop long)
- (F) Dans une construction de document « ici-même », comme
<<TRUC, l'étiquette TRUC est trop longue pour que Perl puisse la gérer. Il faut que vous soyez sérieusement tordu pour écrire un code qui déclenche cette erreur.
Did not produce a valid header
- (N'a pas produit un en-tête valide)
- Voir Server error.
(Did you mean &%s instead?)
- (Avez-vous plutôt voulu dire
&%s?) - (W) Vous avez probablement fait référence à un sous-programme importé
&TRUC en faisant$TRUCou quelque chose du genre.
(Did you mean "local" instead of "our"?)
- (Avez-vous voulu dire
"local"plutôt que"our"?) - (W misc) Souvenez-vous que our ne rend pas locale la variable déclarée comme globale. Vous l'avez redéclarée dans la même portée lexicale, ce qui semble superflu.
(Did you mean $ or @ instead of %?)
- (Avez-vous voulu dire
$ou@plutôt que%?) - (W) Vous avez probablement écrit
%hachage{$clef}alors que vous pensiez$hachage{$clef}ou@hachage{@clefs}. D'un autre côté, peut-être avez-vous juste voulu dire%hachageet vous vous êtes laissé emporter.
Died
- (Mort)
- (F) Vous avez appelé à die une chaîne vide (l'équivalent de die
"") ou vous l'avez appelé sans arguments et à la fois$@et$_étaient vides.
(Do you need to predeclare %s?)
- (Avez-vous besoin de prédéclarer
%s) - (S) Il s'agit d'une supposition donnée en complément du message «
%sfound where operator expected ». Cela veut souvent dire qu'un nom de sous-programme ou de module a été référencé alors qu'il n'a pas encore été défini. C'est peut être un problème d'ordre dans votre fichier ou parce qu'il manque une instruction sub, package, require ou use. Si vous référencez quelque chose qui n'est pas encore défini, en fait vous n'avez pas à définir le sous-programme ou le paquetage avant cet endroit. Vous pouvez utiliser un sub truc; ou un package TRUC; vide pour entrer une déclaration « par avance ».
Document contains no data
- (Le document ne contient pas de données)
- Voir Server error.
Don't know how to handle magic of type '%s'
- (Ne sait pas comment gérer la magie du type '
%s') - (P) On a jeté un sort sur la gestion interne des variables magiques.
do_study: out of memory
- (do_study : débordement de mémoire)
- (P) Ce message aurait plutôt dû être capturé par safemalloc.
Duplicate free() ignored
- (Duplication de free() ignorée)
- (S malloc) Une routine interne a appelé free sur quelque chose qui a déjà été libéré.
elseif should be elsif
- (elseif devrait être elsif)
- (S) Il n'y a pas de mot-clef « elseif » en Perl, car Larry pense que c'est très laid. Votre code sera interprété comme une tentative d'appel à la méthode nommée elseif pour la classe renvoyée par le bloc qui suit. Ce n'est sûrement pas ce que vous voulez.
entering effective %s failed
- (L'entrée dans
%seffectif a échoué) - (F) Alors que le pragma use filetest était actif, l'échange entre les UID ou les GID réels et effectifs a échoué.
Error converting file specification %s
- (Erreur en convertissant la spécification de fichier
%s) - (F) Il s'agit d'une erreur spécifique à VMS. Comme Perl doit gérer des spécifications de fichiers dans les syntaxes VMS ou Unix, il convertit celles-ci dans un format unique lorsqu'il doit les traiter directement. Soit vous avez passé des spécifications de fichier invalides, soit vous avez trouvé un cas que les routines de conversion ne gèrent pas. Zut !
%s: Eval-group in insecure regular expression
- (
%s: Groupe eval dans une expression régulière non sécurisée) - (F) Perl a détecté une donnée marquée en essayant de compiler une expression régulière qui contient l'assertion de longueur zéro (
?{...}) , ce qui n'est pas sécurisé.
%s: Eval-group not allowed, use re 'eval'
- (
%s: Groupe eval interdit, utilisez use re'eval') - (F) Une expression régulière contenait l'assertion de longueur nulle (
?{...}), mais cette construction est seulement permise quand le pragma use re'eval'est actif.
%s: Eval-group not allowed at run time
- (
%s: Groupe eval interdit à l'exécution) - (F) Perl a essayé de compiler une expression régulière contenant l'assertion de longueur nulle (
?{...}) à l'exécution, comme il le ferait si le motif contenait des valeurs interpolées. Comme c'est un risque de sécurité, cela n'est pas permis. Si vous insistez, vous pouvez toujours le faire en construisant explicitement votre motif depuis une chaîne interpolée à l'exécution et l'utiliser dans un eval.
Excessively long <> operator
- (Opérateur
<>excessivement long) - (F) Le contenu d'un opérateur
<>ne doit pas excéder la taille maximum d'un identificateur Perl. Si vous essayez seulement d'obtenir les extensions d'une longue liste de fichiers, essayez d'utiliser l'opérateurglobou mettez les noms de fichiers dans une variable et faites unglobdessus.
Execution of %s aborted due to compilation errors
- (Exécution de
%sabandonnée à cause d'erreurs de compilation) - (F) Le message de résumé final lorsqu'une compilation Perl échoue.
Exiting eval via %s
- (Sortie d'un eval via
%s) - (W exiting) Vous êtes sorti d'un eval d'une façon non conventionnelle, comme un goto ou une instruction de contrôle de boucle.
Exiting format via %s
- (Sortie d'un
formatvia%s) - (W exiting) Vous êtes sorti d'un
formatd'une façon non conventionnelle, comme un goto ou une instruction de contrôle de boucle.
Exiting pseudoblock via %s
- (Sortie d'un pseudobloc via
%s) - (W exiting) Vous êtes sorti d'une construction tout à fait spéciale de bloc (comme un bloc ou un sous-programme de
sort) d'une façon non conventionnelle, comme un goto, ou une instruction de contrôle de boucle.
Exiting subroutine via %s
- (Sortie d'un sous-programme via
%s) - (W exiting) Vous êtes sorti d'un sous-programme d'une façon non conventionnelle, comme un goto ou une instruction de contrôle de boucle.
Exiting substitution via %s
- (Sortie d'une substitution via
%s) - (W exiting) Vous êtes sorti d'une substitution d'une façon non conventionnelle, comme un goto ou une instruction de contrôle de boucle.
Explicit blessing to '' (assuming package main)
- (Consécration par
blessexplicite vers''(paquetage principal main adopté)) - (W misc) Vous avez consacré par
blessune référence à une chaîne de longueur nulle. Cela a pour effet de consacrer la référence dans le paquetage principal main. Ce n'est pas habituellement ce que vous voulez. Pensez à fournir un paquetage cible par défaut, comme dansbless($ref,$p||'Mon_Paquetage');.
false [] range "%s" in regexp
- (Faux intervalle [] "
%s" dans l'expression régulière) - (W regexp) Un intervalle de classe de caractères doit débuter et finir par un caractère littéral et non par une autre classe de caractères comme \d ou [:alpha:]. Le dans votre faux intervalle est interprété comme un
-littéral. Pensez à protéger le comme cela : \-.
Fatal VMS error at %s, line %d
- (Erreur VMS fatale dans
%s, ligne%d) - (P) Il s'agit d'une erreur spécifique à VMS. Il s'est passé quelque chose de fâcheux dans un service du système VMS ou dans une routine CRTL ; le statut de sortie de Perl devrait fournir plus de détails. Le nom de fichier dans at
%set le numéro de ligne dans line%dvous indiquent quelle section du code source Perl a été affectée.
fcntl is not implemented
- (
fcntlnon implémenté) - (F) Votre machine n'implémente apparemment pas
fcntl. Qu'est-ce que c'est que ça, un PDP-11 ou quelque chose de similaire ?
Filehandle %s never opened
- (Handle de fichier
%sjamais ouvert) - (W unopened) Une opération d'entrée/sortie a été tentée sur un handle de fichier qui n'a jamais été initialisé. Vous devez faire un appel à
openou àsocketou appeler un constructeur du module FileHandle.
Filehandle %s opened only for input
- (Handle de fichier
%souvert seulement pour les entrées) - (W io) Vous avez tenté d'écrire dans un handle de fichier ouvert en lecture seule. Si vous vouliez que ce soit un handle de fichier ouvert en lecture-écriture, vous deviez l'ouvrir avec
+<,+>ou+>>au lieu de<ou rien du tout. Si vous désiriez uniquement écrire dans le fichier, utilisez>ou>>.
Filehandle %s opened only for output
- (Handle de fichier
%souvert seulement pour les sorties) - (W io) Vous avez tenté de lire dans un handle de fichier ouvert en écriture seule. Si vous vouliez que ce soit un handle de fichier ouvert en lecture-écriture, vous deviez l'ouvrir avec
+<,+>ou+>>au lieu de<ou rien du tout. Si vous désiriez uniquement lire dans le fichier, utilisez<.
Final $ should be \$ or $name
- (
$final devrait être \$ou$nom) - (F) Vous devez maintenant décider si le
$final dans une chaîne devait être interprété comme le signe dollar littéral ou s'il était là pour introduire un nom de variable s'avérant manquer. Vous devez donc ajouter soit l'antislash, soit le nom.
Final @ should be \@ or @name
- (
@final devrait être \@ou@nom) - (F) Vous devez maintenant décider si le
@final dans une chaîne devait être interprété comme le signe arobase littéral ou s'il était là pour introduire un nom de variable s'avérant manquer. Vous devez donc ajouter soit l'antislash, soit le nom.
flock() on close filehandle %s
- (
flock() sur un handle de fichier fermé%s) - (W closed) Le handle de fichier sur lequel vous avez essayé de faire
flocka été lui-même fermé quelque temps auparavant. Vérifiez le flux logique de votre programme.flockagit sur des handles de fichiers. Avez-vous tenté d'appelerflocksur un handle de répertoire du même nom ?
Format %s redefined
- (Format
%sredéfini) - (W redefine) Vous avez redéfini un format. Pour supprimer cet avertissement, écrivez
Format not terminated
- (Format inachevé)
- (F) Un format doit être terminé par une ligne contenant uniquement un point. Perl est arrivé en fin de fichier sans trouver une telle ligne.
Found = in conditional, should be ==
- (
=trouvé dans une condition, devrait être==) - (W syntax) Vous avez écrit :
if ($truc = 123)-
alors que vous vouliez dire :
Sélectionnezif ($truc==123) - (ou quelque chose de similaire).
gdbm store returned %d, errno %d, key "%s"
- (Le stockage gdbm a renvoyé
%d, numéro d'erreur%d, clef "%s") - (S) Un avertissement de l'extension GDBM_File indique qu'un stockage a échoué.
gethostent not implemented
- (
gethostentnon implémenté) - (F) Votre bibliothèque C n'implémente apparemment pas
gethostent, probablement parce que si elle le faisait, elle se sentirait moralement obligée de renvoyer chaque nom d'hôte existant sur Internet.
get%sname() on closed socket %s
- (get
%sname() sur une socket fermée%s) - (W closed) Vous avez essayé d'obtenir une socket ou une socket parente d'une socket fermée. Peut-être avez-vous oublié de vérifier la valeur renvoyée par l'appel
socket?
getpwnam returned invalid UIC %#o for user "%s"
- (getpwname a renvoyé l'UIC
%#0invalide pour l'utilisateur "%s") - (S) Il s'agit d'un avertissement spécifique à VMS. L'appel à sys
$getuai, sous-jacent de l'opérateurgetpwnam, a retourné une UIC invalide.
glob failed (%s)
- (Échec du
glob) - (W glob) Quelque chose s'est mal passé avec le(s) programme(s) externe(s) utilisé(s) par
globet<*.c>. Habituellement, cela signifie que vous avez fourni un motif deglobqui a entraîné l'échec du programme externe qui s'est terminé avec un statut différent de zéro. Si le message indique que la sortie anormale a engendré une copie du cœur du programme (core dump), ceci peut également vouloir dire que votre csh (C shell) est corrompu. Si c'est le cas, vous devriez changer toutes les variables se rapportant à csh dans config.sh. Si vous utilisez tcsh, changez les variables qui s'y réfèrent comme si c'était csh. (ex. full_csh='/usr/bin/tcsh') ; sinon, videz-les toutes (sauf d_csh qui devrait valoir 'undef') pour que Perl croit qu'il manque csh. Dans tous les cas, une fois config.sh mis à jour, lancez ./Configure -S et reconstruisez Perl.
Glob not terminated
- (Glob non terminé)
- (F) L'analyseur lexical a vu un signe inférieur à un endroit où il s'attendait à trouver un terme, il recherche donc le signe supérieur correspondant et ne le trouve pas. Il y a des chances que vous ayez oublié des parenthèses nécessaires auparavant dans la ligne et que vous avez réellement voulu dire le symbole
<.
Global symbol "%s" requires explicit package name
- (Le symbole global "
%s" exige un nom de paquetage explicite) - (F) Vous avez écrit use strict vars, ce qui indique que toutes les variables doivent soit avoir une portée lexicale (en utilisant my), soit être déclarés au préalable en utilisant our, soit être explicitement qualifiées pour dire à quel paquetage la variable globale appartient (en utilisant ::).
Got an error from DosAllocMem
- (Erreur rencontrée depuis DosAllocMem)
- (P) Il s'agit d'une erreur spécifique à OS/2. Le plus probable est que vous employez une version obsolète de Perl, cette erreur ne devrait donc jamais se produire de toute façon.
goto must have label
- (goto doit avoir une étiquette)
- (F) Au contraire de next et de last, vous n'êtes pas autorisés à faire un goto vers une destination non spécifiée.
Had to create %s unexpectedly
- (A dû créer
%sde manière inattendue) - (S internal) Une routine a demandé un symbole dans une table des symboles qui aurait dû déjà exister, mais pour une raison ou pour une autre ce n'était pas le cas elle a été crée en urgence pour éviter une copie du cœur du programme (core dump).
Hash %%s missing the % in argument %d of %s()
- (Il manque le
%du hachage%%sdans l'argument%dde%s()) - (D deprecated) Seules les versions de Perl vraiment anciennes vous permettaient d'omettre le
%dans les noms de hachage à certains endroits. C'est maintenant largement obsolète.
Hexadecimal number > 0xffffffff non-portable
- (Nombre hexadécimal >
0xffffffff, non portable) - (W portable) Le nombre hexadécimal que vous avez spécifié est plus grand que
2**32-1(4 294 967 295) et n'est donc pas portable d'un système à l'autre.
Identifier too long
- (Identificateur trop long)
- (F) Perl limite la taille des identificateurs (noms des variables, fonctions, etc.) à 250 caractères environ pour les noms simples et un peu plus pour les noms composés (comme
$A::B). Vous avez dépassé les limites de Perl. Les futures versions de Perl seront susceptibles d'éliminer ces limitations arbitraires.
Ill-formed CRTL environ value "%s"
- (Valeur d'environnement de CRTL "
%s" mal formée) - (W internal) Il s'agit d'un avertissement spécifique à VMS. Perl a essayé de lire le tableau d'environnement interne de CRTL et a rencontré un élément sans le séparateur
=utilisé pour séparer les clefs des valeurs. L'élément est ignoré.
Ill-formed message in prime_env_iter: |%s|
- (Message mal formé dans prime_env_iter :
|%s|) - (W internal) Il s'agit d'un avertissement spécifique à VMS. Perl a essayé de lire un nom logique ou une définition de symbole CLI en se préparant à parcourir
%ENVet il n'a pas vu le séparateur attendu entre les clefs et les valeurs, la ligne a donc été ignorée.
Illegal character %s (carriage return)
- (Caractère illégal
%s(retour chariot)) - (F) D'ordinaire, Perl traite les retours chariots dans le texte du programme au même titre que n'importe quel autre caractère d'espacement, ce qui signifie que vous ne devriez jamais voir cette erreur lorsque Perl a été construit en utilisant les options standards. Pour une raison ou pour une autre, votre version de Perl semble avoir été construite sans ce support. Parlez-en à votre administrateur Perl.
Illegal division by zero
- (Division par zéro illégale)
- (F) Vous avez essayé de diviser un nombre par 0. Soit quelque chose clochait dans votre logique, soit vous devez placer une condition pour vous préserver de cette entrée dénuée de sens.
Illegal modulus zero
- (Modulo zéro illégal)
- (F) Vous avez essayé de diviser un nombre par 0 pour obtenir le reste. La plupart des nombres ne peuvent faire cela gentiment.
Illegal binary digit
- (Chiffre binaire illégal)
- (F) Vous avez utilisé un chiffre autre que 0 ou 1 dans un nombre binaire.
Illegal octal digit
- (Chiffre octal illégal)
- (F) Vous avez utilisé un 8 ou un 9 dans un nombre octal.
Illegal binary digit %s ignored
- (Chiffre binaire illégal
%s, ignoré) - (W digit) Vous avez essayé d'utiliser un chiffre autre que 0 ou 1 dans un nombre binaire. L'interprétation du nombre binaire s'est arrêtée avant le chiffre en cause.
Illegal octal digit %s ignored
- (Chiffre octal illégal
%s, ignoré) - (W digit) Vous avez peut-être essayé d'utiliser un 8 ou un 9 dans un nombre octal. L'interprétation du nombre octal s'est arrêtée avant le 8 ou le 9.
Illegal hexadecimal digit %s ignored
- (Chiffre hexadécimal illégal
%s, ignoré) - (W digit) Vous avez essayé d'utiliser un caractère autre qui n'est ni entre
0et9, ni entre A et F, ni entre a et f dans un nombre hexadécimal. L'interprétation du nombre hexadécimal s'est arrêtée avant le caractère illégal.
Illegal number of bits in vec
- (Nombre de bits illégal dans
vec) - (F) Le nombre de bits dans
vec(le troisième argument) doit être une puissance de deux de 1 à 32 (ou 64 si votre plate-forme le supporte).
Illegal switch in PERL5OPT: %s
- (Option illégale dans PERL5OPT :
%s) - (X) La variable d'environnement PERL5OPT ne peut être utilisée que pour positionner les options suivantes : -[DIMUdmw].
In string, @%s now must be written as \@%s
- (Dans une chaîne,
@%sdoit maintenant s'écrire \@%s) - (F) Perl essayait auparavant de deviner si vous vouliez un tableau interpolé ou un
@littéral. Il faisait ceci lorsque la chaîne était utilisée la première fois pendant l'exécution. Les chaînes sont maintenant analysées à la compilation et les instances ambiguës de@doivent être éclaircies, soit en préfixant par un antislash pour indiquer qu'il s'agit d'un littéral, soit en déclarant (ou en utilisant) le tableau dans le programme avant la chaîne (lexicalement). (Un jour un@sans antislash sera simplement interprété comme une interpolation d'un tableau.)
Insecure dependency in %s
- (Dépendance non sécurisée dans
%s) - (F) Vous avez essayé de faire quelque chose que le mécanisme de marquage des variables n'a pas apprécié. Ce mécanisme de marquage est activé quand vous exécutez un script setuid ou setgid, ou lorsque vous spécifiez -T pour l'activer explicitement. Le mécanisme de marquage étiquette toutes les données dérivées directement ou indirectement de l'utilisateur, qui est considéré indigne de votre confiance. Si l'une de ces données est utilisée dans une opération « dangereuse », vous obtenez cette erreur.
Insecure directory in %s
- (Répertoire non sécurisé dans
%s) - (F) Vous ne pouvez utilisez
system,execou un pipe ouvert vers un script setuid ou setgid si$ENV{PATH}contient un répertoire qui a les droits en écriture pour tout le monde.
Insecure $ENV{%s} while running %s
- (
$ENV{%s}non sécurisé alors que%sest en train de tourner) - (F) Vous ne pouvez utiliser
system,execou un pipe ouvert vers un script setuid ou setgid si$ENV{PATH},$ENV{IFS},$ENV{CDPATH},$ENV{ENV}ou$ENV{BASH_ENV}sont dérivés de données fournies (ou potentiellement fournies) par l'utilisateur. Le script doit positionner le chemin à une valeur connue, en utilisant une donnée digne de confiance.
Integer overflow in %s number
- (Dépassement d'entier dans le nombre %s)
- (W overflow) Le nombre hexadécimal, octal ou binaire que vous avez spécifié soit comme littéral, soit comme argument de
hexouoctest trop grand pour votre architecture. Sur les machines 32-bits, les plus grands nombres hexadécimaux, octaux ou binaires représentables sans dépassement sont 0xFFFFFFFF, 037777777777 et 0b11111111111111111111111111111111, respectivement. Remarquez que Perl élève de manière transparente tous les nombres vers une représentation interne en virgule flottante — sujette à des erreurs de perte de précision dans les opérations ultérieures.
Internal inconsistency in tracking vforks
- (Incohérence interne dans la recherche des vfork s)
- (S) Il s'agit d'un avertissement spécifique à VMS. Perl garde une trace du nombre de fois où vous avez appelé
forketexec, pour déterminer si l'appel courant àexecdevrait affecter le script en cours ou un sous-processus (Voir « exec LIST » dans perlvms(1)). De toute façon, ce compte est devenu perturbé, Perl fait donc une supposition et traite ceexeccomme une requête pour terminer le script Perl et exécuter la commande spécifiée.
internal disaster in regexp
- (désastre interne dans une expression régulière)
- (P) Quelque chose s'est très mal passé dans l'analyseur d'expressions régulières.
internal urp in regexp at /%s/
- (gloups interne dans une expression régulière)
- (P) Quelque chose a très mal tourné dans l'analyseur d'expressions régulières.
Invalid %s attribute: %s
- (Attribut
%sinvalide :%s) - (F) L'attribut indiqué pour un sous-programme ou une variable n'a pas été reconnu par Perl ou par un gestionnaire fourni par l'utilisateur.
Invalid %s attributes: %s
- (Attributs
%sinvalides :%s) - (F) Les attributs indiqués pour un sous-programme ou une variable n'ont pas été reconnus par Perl ou par un gestionnaire fourni par l'utilisateur.
invalid [] range "%s" in regexp
- (Intervalle [] "
%s" invalide dans l'expression régulière) - (F) L'intervalle spécifié dans une classe de caractères a un caractère de début supérieur au caractère de fin.
Invalid conversion in %s:"%s"
- (Conversion invalide dans
%s: "%s") - (W printf) Perl ne comprend pas le format de conversion donné.
Invalid separator character %s in attribute list
- (Caractère de séparation
%sinvalide dans la liste d'attributs) - (F) Quelque chose d'autre qu'un deux-points ou qu'un espacement a été détecté entre les éléments d'une liste d'attributs. Si l'attribut précédent avait une liste de paramètres entre parenthèses, peut-être que cette liste s'est terminée trop tôt.
Invalid type in pack: '%s'
- (Type invalide dans
pack: '%s') - (F) Le caractère donné n'est pas un type d'empaquetage valide.
- (W pack) Le caractère donné n'est pas un type d'empaquetage valide, mais l'habitude était de l'ignorer silencieusement.
Invalid type in unpack: '%s'
- (Type invalide dans
unpack: '%s') - (F) Le caractère donné n'est pas un type de dépaquetage valide.
- (W unpack) Le caractère donné n'est pas un type de dépaquetage valide, mais l'habitude était de l'ignorer silencieusement.
ioctl is not implemented
- (F) Votre machine n'implémente apparemment pas
ioctl, ce qui est quelque peu surprenant de la part d'une machine qui supporte le C.
junk on end of regexp
- (Déchets à la fin de l'expression régulière)
- (P) L'analyseur d'expressions régulières s'est embrouillé.
Label not found for "last %s"
- (Étiquette introuvable pour
"last%s") - (F) Vous avez nommé une boucle pour en sortir, mais vous n'êtes pas actuellement dans une boucle de ce nom, même si vous comptez d'où vous avez été appelé.
Label not found for "next %s"
- (Étiquette introuvable pour
"next%s") - (F) Vous avez nommé une boucle pour effectuer l'itération suivante, mais vous n'êtes pas actuellement dans une boucle de ce nom, même si vous comptez d'où vous avez été appelé.
Label not found for "redo %s"
- (Étiquette introuvable pour "redo
%s") - (F) Vous avez nommé une boucle pour recommencer l'itération en cours, mais vous n'êtes pas actuellement dans une boucle de ce nom, même si vous comptez d'où vous avez été appelé.
leaving effective %s failed
- (la sortie de
%seffectif a échoué) - (F) Alors que le pragma use filetest était actif, l'échange entre les UID ou les GID réels et effectifs a échoué.
listen() on closed socket %s
- (
listen() sur une socket fermée%s) - (W closed) Vous avez essayé de faire un
listensur une socket fermée. Peut-être avez-vous oublié de vérifier la valeur renvoyée par votre appel àsocket?
Lvalue subs returning %s not implemented yet
- (Sous-programmes en tant que lvalue retournant
%spas encore implémentés) - (F) À cause de limitations dans l'implémentation actuelle, les valeurs de tableaux et de hachages ne peuvent pas être renvoyées dans un contexte de lvalue.
Malformed PERLLIB_PREFIX
- (PERLLIB_PREFIX malformée)
-
(F) Il s'agit d'une erreur spécifique à OS/2. PERLLIB_PREFIX doit être de la forme :
Sélectionnezprefixe1 ;prefixe2 -
ou :
Sélectionnezprefixe1 prefixe2 - avec prefixe1 et prefixe2 non vides. Si prefixe1 est en fait un préfixe d'un chemin de recherche de bibliothèque interne, on lui substitue prefixe2. L'erreur peut survenir si les composants ne sont pas trouvés ou s'ils sont trop longs. Voir PERLLIB_PREFIX dans le fichier README.os2 inclus dans la distribution de Perl.
Method for operation %s not found in package %s during blessing
- (La méthode pour l'opération
%sn'a pas été trouvée dans le paquetage%sdurant la consécration avecbless) - (F) Une tentative a été effectuée pour spécifier une entrée dans une table de surcharge qui ne peut être résolue par un sous-programme valide.
Method %s not permitted
- (Méthode
%sinterdite) - Voir Server error.
Might be a runaway multi-line %s string starting on line %d
- (
%spourrait être une chaîne galopant sur plusieurs lignes, débutant à la ligne%d) - (S) Une suggestion indiquant que l'erreur précédente peut avoir été causée par un séparateur manquant dans une chaîne ou un motif, car la chaîne se finissait éventuellement plus tôt sur la ligne courante.
Misplaced _ in number
- (_ mal placé dans un nombre)
- (W syntax) Un caractère souligné dans une constante décimale n'était pas sur une limite de 3 chiffres.
Missing $ on loop variable
- (
$manquant dans une variable de boucle) - (F) Apparemment, vous avez programmé en csh un peu trop longtemps. Les variables en Perl sont toujours précédées du
$, au contraire des shells, ou cela peut varier d'une ligne à l'autre.
Missing %sbrace%s on \N{}
- (
%saccolades%smanquantes sur \N{}) - (F) Vous avez employé la mauvaise syntaxe de nom de caractère littéral \N
{nom_caractere}à l'intérieur d'un contexte de guillemets.
Missing comma after first argument to %s function
- (Virgule manquante après le premier argument de la fonction
%s) - (F) Alors que certaines fonctions vous permettent de spécifier un handle de fichier ou un « objet indirect » avant la liste d'arguments, celle-ci n'en fait pas partie.
Missing command in piped open
- (Commande manquante dans un
openavec un pipe) - (W pipe) Vous avez utilisé la construction
open(HF,"| commande") ou,open(HF,"commande |") mais il manquait la commande ou alors elle était vide.
Missing name in "my sub"
- (Nom manquant dans "my sub")
- (F) La syntaxe réservée pour les sous-programmes de portée lexicale exige qu'ils aient un nom par lequel on puisse les trouver.
(Missing operator before %s?)
- (Opérateur manquant avant
%s?) - (S) Il s'agit d'une supposition donnée en complément du message «
%sfound where operator expected ». Souvent l'opérateur manquant est une virgule.
Missing right curly or square bracket
- (Accolade fermante ou crochet fermant manquant)
- (F) L'analyseur lexical a compté plus d'accolades ouvrantes ou de crochets ouvrants que d'accolades fermantes ou de crochets fermants. En règle générale, vous trouverez le signe manquant à côté de l'endroit où vous venez d'éditer.
Modification of a read-only value attempted
- (Tentative de modification d'une valeur en lecture seule)
-
(F) Vous avez essayé, directement ou indirectement, de changer la valeur d'une constante. Vous ne pouvez pas, bien entendu, essayer de faire,
2=1car le compilateur intercepte ceci. Mais une autre façon simple de faire la même chose est :Sélectionnezsub mod{$_[0]=1}mod(2); - Un autre moyen serait d'affecter à
substrce qui se trouve au-delà de la fin de la chaîne.
Modification of non-creatable array value attempted, subscript %d
- (Tentative de modification d'une valeur de impossible à créer, indice
%d) - (F) Vous avez essayé de faire naître une valeur de tableau et l'indice était probablement négatif, même en comptant à rebours depuis de la fin du tableau.
Modification of non-creatable hash value attempted, subscript "%s"
- (Tentative de modification d'une valeur de hachage impossible à créer, indice "
%s") - (P) Vous avez essayé de faire naître une valeur de hachage et elle n'a pu être créée pour une raison particulière.
Module name must be constant
- (Le nom de module doit être constant)
- (F) Seul un nom de module brut est permis comme premier argument d'un use.
msg%s not implemented
- (msg
%snon implémenté) - (F) Vous n'avez pas d'implémentation de messages des IPC System V sur votre système.
Multidimensional syntax %s not supported
- (Syntaxe multidimensionnelle
%snon supportée) - (W syntax) Les tableaux multidimensionnels ne s'écrivent pas
$truc[1,2,3]. Ils s'écrivent$truc[1][2][3], tout comme en C.
Name "%s::%s" used only once: possible typo
- (Nom
%s::%s"utilisé une seule fois : faute de frappe possible) - (W once) Les fautes de frappe apparaissent fréquemment sous la forme de noms de variable uniques. Si vous avez une bonne raison pour cela, vous n'avez qu'à mentionner la variable à nouveau pour supprimer ce message. La déclaration our est destinée à cela.
Negative length
- (Longueur négative)
- (F) Vous avez essayé de faire une opération
read/write/send/recvavec un tampon de longueur plus petite que 0. C'est difficile à imaginer.
nested *?+ in regexp
- (
*?+imbriqué dans l'expression régulière) - (F) Vous ne pouvez quantifier un quantifiant sans faire intervenir de parenthèses.
- Donc les choses comme
**,+*ou?*sont illégales. Remarquez cependant que les quantifiants de recherche de correspondance minimum,*?,+?, et??ressemblent à des quantifiants imbriqués, mais ne le sont pas.
No #! line
- (Pas de ligne
#!) - (F) L'émulateur setuid exige que le script possède une ligne valide de la forme
#!même sur les machines ne supportant pas la construction#!.
No %s allowed while running setuid
- (Pas de
%sautorisé alors que l'on tourne avec setuid) - (F) Pour des questions de sécurité, certaines opérations sont trop dangereuses pour être exécutées, voire tentées, dans un script setuid ou setgid. Généralement, il y existera bien un autre moyen pour faire ce que vous voulez, c'est-à-dire que si ce moyen n'est pas sécurisé, il est au moins sécurisable.
No -e allowed in setuid scripts
- (pas de
-e autorisé dans les scripts setuid) - (F) Un script setuid ne peut être spécifié par l'utilisateur.
No %s specified for -%c (Pas de %s spécifié pour -%c)
- (F) L'option de la ligne de commande indiquée nécessite un argument obligatoire, mais vous n'en avez pas spécifié.
No comma allowed after %s
- (Pas de virgule autorisée après
%s) - (F) Lorsqu'un opérateur de liste a un handle de fichier ou un « object indirect », il ne doit pas y avoir une virgule ce premier argument et les arguments suivants. Sinon, il serait juste interprété comme tout autre un argument.
- Une situation ténébreuse dans laquelle ce message se produit est lorsque vous vous attendez à importer une constante dans votre espace de noms avec use ou, import mais qu'une telle importation ne s'est pas produite. Vous auriez dû utiliser une liste d'importation explicite des constantes que vous vous attendiez à voir. Une liste d'importation explicite aurait probablement intercepté cette erreur plus tôt. Ou peut-être s'agit-il seulement d'une erreur de frappe dans le nom de la constante.
No command into which to pipe on command line
- (Pas de commande dans laquelle envoyer un pipe sur la ligne de commande)
- (F) Il s'agit d'une erreur spécifique à VMS. Perl effectue ses propres redirections dans la ligne de commande et a trouvé un
|à la fin de la ligne de commande, il ne sait donc pas vers où vous voulez rediriger avec un pipe la sortie de cette commande.
No DB::DB routine defined
- (Pas de routine DB::DB de définie)
- (F) Le code en train d'être exécuté a été compilé avec l'option -d, mais pour une raison ou pour une autre le fichier perl5db.pl (ou alors un fac-similé) n'a pas défini de routine à appeler au début de chaque instruction. Ce qui est étrange, car le fichier aurait dû être chargé automatiquement et n'a pas pu être analysé correctement.
No dbm on this machine
- (Pas de dbm sur cette machine)
- (P) Ceci est compté comme une erreur interne ; chaque machine doit fournir dbm de nos jours, car Perl est livré avec SDBM.
No DBsub routine
- (Pas de routine DBsub)
- (F) Le code en train de s'exécuter a été compilé avec l'option -d, mais pour une raison ou pour une autre le fichier perl5db.pl (ou alors un fac-similé) n'a pas défini de routine DB::sub à appeler au début de chaque appel de sous-programme ordinaire.
No error file after 2> or 2>> on command line
- (Pas de fichier d'erreur après
2>ou2>>sur la ligne de commande) - (F) Il s'agit d'une erreur spécifique à VMS. Perl effectue ses propres redirections dans la ligne de commande et y a trouvé un
2>ou un2>>mais sans trouver le nom du fichier dans lequel écrire les données destinées à STDERR.
No input file after < on command line
- (Pas de fichier d'entrée après
<sur la ligne de commande) - (F) Il s'agit d'une erreur spécifique à VMS. Perl effectue ses propres redirections dans la ligne de commande et y a trouvé un
<mais sans trouver le nom du fichier depuis lequel lire les données de STDIN.
No output file after > on command line
- (Pas de fichier de sortie après
2>ou2>>sur la ligne de commande) - (F) Il s'agit d'une erreur spécifique à VMS. Perl effectue ses propres redirections dans la ligne de commande et a trouvé un
>isolé à la fin de la ligne de commande, mais sans savoir où vous vouliez redirigez STDOUT.
No output file after > or >> on command line
- (Pas de fichier de sortie après
>ou>>sur la ligne de commande) - (F) Il s'agit d'une erreur spécifique à VMS. Perl effectue ses propres redirection dans la ligne de commande et y a trouvé un
>ou un>>mais sans trouver le nom du fichier dans lequel écrire les données destinées à STDOUT.
No package name allowed for variable %s in "our"
- (Pas de nom de paquetage autorisé pour la variable
%sdans "our") - (F) Les noms de variable pleinement qualifiés ne sont pas autorisés dans les déclarations, our car cela n'aurait pas beaucoup de sens avec les sémantiques existantes. Une telle syntaxe est réservée pour de futures extensions.
No Perl script found in input
- (Pas de script Perl trouvé en entrée)
- (F) Vous avez appelé perl -x, mais aucune ligne n'est trouvée dans le fichier commençant par
#!et contenant le mot « perl ».
No setregid available
- (Pas de setregid de disponible)
- (F) Configure n'a rien trouvé qui ressemble à l'appel setregid pour votre système.
No setreuid available
- (Pas de setreuid de disponible)
- (F) Configure n'a rien trouvé qui ressemble à l'appel setreuid pour votre système.
No space allowed after -%c
- (Pas d'espace autorisé après
-%c) - (F) L'argument de l'option de la ligne de commande indiquée doit suivre immédiatement l'option, sans qu'aucun espace n'intervienne.
No such pseudohash field "%s"
- (Aucun champ de pseudohachage "
%s") - (F) Vous avez essayé d'accéder à un tableau en tant que hachage, mais le nom de champ utilisé n'est pas défini. Le hachage à l'indice 0 doit faire correspondre tous les noms de champs valides aux indices du tableau pour que cela fonctionne.
No such pseudohash field "%s" in variable %s of type %s
- (Aucun champ de pseudohachage "
%s" dans la variable%sde type%s) - (F) Vous avez essayé d'accéder à un champ d'une variable typée, mais le type ignore le nom du champ. Les noms de champ sont recherchés dans le hachage
%FIELDSdans le paquetage du type à la compilation. Le hachage%FIELDSest généralement initialisé avec le pragma fields.
No such pipe open
- (Aucun pipe ouvert)
- (P) Il s'agit d'une erreur spécifique à VMS. La routine interne my_pclose a essayé de fermer un pipe qui n'avait pas été ouvert. Ceci aurait dû être capturé plus tôt comme une tentative de fermeture d'un handle de fichier non ouvert.
No such signal: SIG%s
- (Aucun signal : SIG
%s) - (W signal) Le nom de signal que vous avez spécifié comme indice de
%SIGn'a pas été reconnu. Faites kill -l dans votre shell pour voir les noms de signaux valides sur votre système.
No UTC offset information; assuming local time is UTC
- (Pas d'information sur le décalage UTC ; adopte UTC comme heure locale)
- (S) Il s'agit d'un avertissement spécifique à VMS. Perl a été incapable de trouver le décalage horaire pour l'heure locale, il a donc supposé que l'heure locale du système et UTC étaient équivalentes. SI ce n'est pas le cas, définissez le nom logique SYS
$TIMEZONE_DIFFERENTIALpour qu'il traduise le nombre de secondes à ajouter à UTC afin d'obtenir l'heure locale.
Not a CODE reference
- (Non une référence de CODE)
- (F) Perl a essayé d'évaluer une référence vers une valeur de code (c'est-à-dire un sous-programme), mais a trouvé une référence vers quelque chose d'autre à la place. Vous pouvez utiliser la fonction
refpour trouver de quelle sorte de référence il s'agissait exactement.
Not a format reference
- (Non une référence de format)
- (F) Nous ne sommes pas sûrs de la manière dont vous vous arrangez pour générer une référence vers un format anonyme, mais ce message indique que vous l'avez fait et que cela n'existe pas.
Not a GLOB reference
- (Non une référence de GLOB)
- (F) Perl a essayé d'évaluer une référence vers un « typeglob » (c'est-à-dire une entrée dans la table des symboles ressemblant à
*truc), mais a trouvé une référence vers quelque chose d'autre à la place. Vous pouvez utiliser la fonctionrefpour trouver de quelle sorte de référence il s'agissait exactement.
Not a HASH reference
- (Non une référence de HACHAGE)
- (F) Perl a essayé d'évaluer une référence vers une valeur de hachage, mais a trouvé une référence vers quelque chose d'autre à la place. Vous pouvez utiliser la fonction
refpour trouver de quelle sorte de référence il s'agissait exactement.
Not a perl script
- (Non un script perl)
- (F) L'émulateur setuid exige que le script possède une ligne valide de la forme
#!même sur les machines ne supportant pas la construction#!. La ligne doit mentionner « perl ».
Not a SCALAR reference
- (Non une référence de SCALAIRE)
- (F) Perl a essayé d'évaluer une référence vers une valeur scalaire, mais a trouvé une référence vers quelque chose d'autre à la place. Vous pouvez utiliser la fonction
refpour trouver de quelle sorte de référence il s'agissait exactement.
Not a subroutine reference
- (Non une référence de sous-programme)
- (F) Perl a essayé d'évaluer une référence vers une valeur de code (c'est-à-dire un sous-programme), mais a trouvé une référence vers quelque chose d'autre à la place. Vous pouvez utiliser la fonction
refpour trouver de quelle sorte de référence il s'agissait exactement.
Not a subroutine reference in overload table
- (Non une référence de sous-programme dans la table de surcharge)
- (F) Une tentative a été faite pour spécifier une entrée dans une table de surcharge qui ne pointe pas d'une façon ou d'une autre vers un sous-programme valide.
Not an ARRAY reference
- (Non une référence de TABLEAU)
- (F) Perl a essayé d'évaluer une référence vers une valeur de tableau, mais a trouvé une référence vers quelque chose d'autre à la place. Vous pouvez utiliser la fonction
refpour trouver de quelle sorte de référence il s'agissait exactement.
Not enough arguments for %s
- (Pas assez d'arguments pour
%s) - (F) La fonction exige plus d'arguments que vous n'en avez spécifié.
Not enough format arguments
- (Pas assez d'arguments de format)
- (W syntax) Un format spécifiait plus de champs d'images que la ligne suivante ne lui en a fourni.
Null filename used
- (Nom de fichier vide utilisé)
- (F) Vous ne pouvez exiger un nom de fichier vide, notamment car sur beaucoup de machines ceci signifie le répertoire courant !
Null picture in formline
- (Image vide dans
formline) - (F) Le premier argument de
formlinedoit être une spécification de format d'image valide. On a trouvé que cet argument était vide, ce qui signifie probablement que vous lui avez fourni une valeur non initialisée.
NULL OP IN RUN
- (OP NUL DANS RUN)
- (P debugging) Une routine interne a appelé run avec un pointer de code d'opération (opcode) nul.
Null realloc
- (réallocation nulle)
- (P) Une tentative a eu lieu pour réallouer le pointeur NULL.
NULL regexp argument
- (argument NUL dans l'expression régulière)
- (P) Les routines internes de recherche de motifs ont tout explosé.
NULL regexp parameter
- (paramètre NUL dans l'expression régulière)
- (P) Les routines internes de recherche de motifs ont perdu la tête.
Number too long
- (Nombre trop long)
- (F) Perl limite la représentation des nombres décimaux dans les programmes à environ 250 caractères. Vous avez dépassé cette longueur. Les futures versions de Perl sont susceptibles d'éliminer cette limitation arbitraire. En attendant, essayez d'utiliser la notation scientifique (ex.
1e6au lieu de1_000_000).
Octal number > 037777777777 non portable
- (Nombre octal >
037777777777, non portable) - (W portable) Le nombre octal que vous avez spécifié est plus grand que
2**32-1(4 294 967 295) et n'est donc pas portable d'un système à l'autre.
Octal number in vector unsupported
- (Nombre octal dans un vecteur non supporté)
- (F) Les nombres commençant par un
0ne sont actuellement pas autorisés dans les vecteurs. L'interprétation en octal de tels nombres sera peut-être supportée dans une future version.
Odd number of elements in hash assignment
- (Nombre impair d'éléments dans une affectation de hachage)
- (W misc) Vous avez spécifié un nombre impair d'éléments pour initialiser un hachage, ce qui est un impair à la règle, car un hachage va avec des paires clef/valeur.
Offset outside string
- (Décalage en dehors de la chaîne)
- (F) Vous avez essayé de faire une opération
read/write/send/recvavec un décalage pointant en dehors du tampon. Ceci est difficile à imaginer. La seule exception à cette règle est que faire unsysreadaprès un tampon étendra ce tampon et remplira de zéros la nouvelle zone.
oops: oopsAV
- (gloups : gloupsAV)
- (S internal) Il s'agit d'un avertissement interne comme quoi la grammaire est abîmée.
oops: oopsHV
- (gloups gloupsHV)
- (S internal) Il s'agit d'un avertissement interne indiquant que la grammaire est abîmée.
Operation "%s": no method found, %s
- (Opération "
%s" : aucune méthode trouvée,%s) - (F) Une tentative a été faite pour effectuer une opération de surcharge pour laquelle aucun gestionnaire n'a été défini. Alors que certains gestionnaires peuvent être autogénérés en termes d'autres gestionnaires, il n'existe pas de gestionnaire par défaut pour quelque opération que ce soit, à moins que la clef de surcharge fallback soit spécifiée comme étant vraie.
Operator or semicolon missing before %s
- (Opérateur ou point-virgule manquant avant
%s) - (S ambiguous) Vous avez utilisé une variable ou un appel de sous-programme là où l'analyseur syntaxique s'attendait à trouver un opérateur. L'analyseur a considéré que vous pensiez vraiment utiliser un opérateur, mais cela est fortement susceptible de s'avérer incorrect. Par exemple, si vous écrivez accidentellement
*truc*truc, cela sera interprété comme si vous aviez écrit*truc*'truc'.
Out of memory!
- (Dépassement de mémoire !)
- (X) La fonction interne de Perl malloc a renvoyé 0, ce qui indique que la mémoire restante (ou la mémoire virtuelle) n'a pas suffi à satisfaire la requête. Perl n'a pas d'autre option que de sortir immédiatement.
- (Dépassement de mémoire pour la pile de yacc)
- (F) L'analyseur syntaxique yacc a voulu agrandir sa pile pour qu'il puisse continuer son analyse, mais realloc n'a pas voulu lui donner plus de mémoire, virtuelle ou autre.
Out of memory during request for %s
- (Dépassement de mémoire pendant une requête pour
%s) - (X|F) La fonction malloc a renvoyé 0, ce qui indique que la mémoire restante (ou la mémoire virtuelle) n'a pas suffi à satisfaire la requête. La requête a été jugée faible, la possibilité de la capturer est donc dépendante de la façon dont Perl a été compilé. Par défaut, elle ne peut être capturée. Cependant, s'il a été compilé à cet effet, Perl peut utiliser le contenu de
$^Mcomme une zone d'urgence après être sorti par die avec ce message. Dans ce cas l'erreur peut-être capturée une seule fois.
Out of memory during "large" request for %s
- (Dépassement de mémoire pendant une requête « large » pour
%s) - (F) La fonction malloc a renvoyé 0, ce qui indique que la mémoire restante (ou la mémoire virtuelle) n'a pas suffit à satisfaire la requête. Cependant, la requête a été jugée assez large (par défaut 64K à la compilation), la possibilité de sortir en capturant cette erreur est donc permise.
Out of memory during ridiculously large request
- (Dépassement de mémoire pendant une requête ridiculement large)
- (F) Vous ne pouvez allouer plus de
2**31+« epsilon » octets. Cette erreur est généralement causée par une faute de frappe dans le programme Perl (ex.$tab[time] au lieu de$tab[$time]).
page overflow
- (dépassement de page mémoire)
- (W io) Un seul appel à
writea produit plus de lignes que ne peut en contenir une page.
panic: ck_grep
- (panique : ck_grep)
- (P) Le programme a échoué sur un test de cohérence interne en essayant de compiler un
grep.
panic: ck_split
- (panique : ck_split)
- (P) Le programme a échoué sur un test de cohérence interne en essayant de compiler un
split.
panic: corrupt saved stack index
- (panique : index de la pile de sauvegarde corrompu)
- (P) On a demandé à la pile de sauvegarde de restaurer plus de valeurs localisées qu'il n'en existe.
panic: del_backref
- (panique : référence arrière supprimée)
- (P) Le programme a échoué sur un test de cohérence interne en essayant de réinitialiser une référence lâche (weak reference).
panic: die %s
- (panique : die
%s) - (P) Nous avons passé l'élément du dessus de la pile de contexte à un contexte d'eval pour découvrir alors que l'on n'était pas dans un contexte d'eval.
panic: do_match
- (panique : do_match)
- (P) La routine interne pp_match a été appelée avec des données opérationnelles invalides.
panic: do_split
- (panique : do_split)
- (P) Quelque chose de terrible s'est mal passé lors de la préparation pour un
split.
panic: do_subst
- (panique : do_subst)
- (P) La routine interne pp_subst a été appelée avec des données opérationnelles invalides.
panic: do_trans
- (panique : do_trans)
- (P) La routine interne do_trans a été appelée avec des données opérationnelles invalides.
panic: frexp
- (panique : frexp)
- (P) La fonction de la bibliothèque frexp a échoué, rendant le
printf("%f") impossible.
panic: goto
- (panique : goto)
- (P) Nous avons passé l'élément du dessus de la pile à un contexte avec l'étiquette spécifiée et découvert ensuite qu'il ne s'agissait pas d'un contexte que nous savions joindre par un goto.
panic: INTERPCASEMOD
- (panique : INTERPCASEMOD)
- (P) L'analyseur lexical s'est retrouvé dans un mauvais état à un modificateur de casse (majuscule/minuscule).
panic: INTERPCONCAT
- (panique : INTERPCONCAT)
- (P) L'analyseur lexical s'est retrouvé dans un mauvais état en analysant une chaîne de caractères avec des parenthèses.
panic: kid popen errno read
- (panique : lecture du numéro d'erreur dans le popen d'un fils)
- (F) Un fils issu d'un
forka renvoyé un message incompréhensible à propose de son numéro d'erreur.
panic: last
- (panique : last)
- (P) Nous avons passé l'élément du dessus de la pile à un contexte de bloc et découvert par la suite que ce n'était pas un contexte de bloc.
panic: leave_scope clearsv
- (panique : clearsv dans la sortie de la portée)
- (P) Une variable lexicale modifiable est maintenant en lecture seule dans le bloc pour une raison ou pour une autre.
panic: leave_scope inconsistency
- (panique : sortie de la portée incohérente)
- (P) La pile de sauvegarde n'est sûrement plus synchronisée. Du moins, il y avait un type enum invalide à son sommet.
panic: malloc
- (panique : malloc)
- (P) Quelque chose a demandé un nombre négatif d'octets à malloc.
panic: magic_killbackrefs
- (panique : suppression magique de toutes les références arrière)
- (P) Le programme a échoué sur un test de cohérence interne en essayant de réinitialiser toutes les références lâches vers un objet.
panic: mapstart
- (panique : mapstart)
- (P) Le compilateur s'est embrouillé avec la fonction
map.
panic: null array
- (panique : tableau nul)
- (P) On a passé à l'une des routines internes pour les tableaux un pointeur d'AV nul.
panic: pad_alloc
- (panique : pad_alloc)
- (P) Le compilateur ne sait plus quelle mémoire de travail (scratchpad) il allouait et libérait les valeurs temporaires et lexicales.
panic: pad_free curpad
- (panique : pad_free curpad)
- (P) Le compilateur ne sait plus quelle mémoire de travail (scratchpad) il allouait et libérait les valeurs temporaires et lexicales.
panic: pad_free po
- (panique : pad_free po)
- (P) Un décalage incorrect dans la mémoire de travail (scratchpad) a été détecté en interne.
panic: pad_reset curpad
- (panique : pad_reset curpad)
- (P) Le compilateur ne sait plus quelle mémoire de travail (scratchpad) il allouait et libérait les valeurs temporaires et lexicales.
panic: pad_sv po
- (panique : pad_sv po)
- (P) Un décalage incorrect dans la mémoire de travail (scratchpad) a été détecté en interne.
panic: pad_swipe curpad
- (panique : pad_swipe curpad)
- (P) Le compilateur ne sait plus quelle mémoire de travail (scratchpad) il allouait et libérait les valeurs temporaires et lexicales.
panic: pad_swipe po
- (panique : pad_swipe po)
- (P) Un décalage incorrect dans la mémoire de travail (scratchpad) a été détecté en interne.
panic: pp_iter
- (panique : pp_iter)
- (P) L'itérateur de foreach a été appelé dans un contexte qui n'était pas un contexte de boucle.
panic: realloc
- (panique : realloc)
- (P) Quelque chose a demandé un nombre négatif d'octets à realloc.
panic: restartop
- (panique : restartop)
- (P) Une routine interne a demandé un goto (ou quelque chose de semblable), mais n'a pas fourni de destination.
panic: return
- (panique : return)
- (P) Nous avons passé l'élément du dessus de la pile de contexte à un sous-programme ou à un contexte d'eval pour découvrir alors que l'on n'était ni dans un sous-programme, ni dans un contexte d'eval.
panic: scan_num
- (panique : scan_num)
- (P) La fonction interne de Perl scan_num a été appelée sur quelque chose qui n'était pas un nombre.
panic: sv_insert
- (panique : sv_insert)
- (P) On a demandé à la routine sv_insert d'enlever plus de chaînes qu'il en existe.
panic: top_env
- (panique : top_env)
- (P) Le compilateur a tenté de faire un goto ou quelque chose d'aussi bizarre.
panic: yylex
- (panique : yylex)
- (P) L'analyseur lexical s'est retrouvé dans un mauvais état en traitant un modificateur de casse (majuscule/minuscule).
panic: %s
- (panique :
%s) - (P) Une erreur interne.
Parentheses missing around "%s" list
- (Parenthèses manquantes autour de la liste "
%s") -
(W parenthesis) Vous avez écrit quelque chose comme :
Sélectionnezmy$truc,$machin=@_; -
alors que vous vouliez dire :
Sélectionnezmy ($truc,$machin)=@_; - Souvenez-vous que my, our et local regroupent plus fortement que la virgule.
Perl %3.3f required--this is only version %s, stopped
- (Perl
%3.3frequis — il ne s'agit que de la version%s, arrêt) - (F) Le module en question utilise des fonctionnalités offertes par une version plus récente que celle exécutée actuellement. Depuis combien de temps n'avez-vous pas fait de remise à niveau ?
PERL_SH_DIR too long
- (PERL_SH_DIR trop long)
- (F) Il s'agit d'une erreur spécifique à OS/2. PERL_SH_DIR est le répertoire où se trouve le shell sh. Voir PERL_SH_DIR dans le fichier README.os2 compris dans la distribution de Perl.
Permission denied
- (Permission refusée)
- (F) L'émulateur setuid de suidperl a décidé que vous n'étiez pas quelqu'un de bon.
pid %x not a child
- (le pid
%xn'est pas un fils) - (W exec) Il s'agit d'une alerte spécifique à VMS ; on a demandé à
waitpidd'attendre un processus qui n'est pas un sous-processus du processus courant. Même si cela est correct dans la perspective de VMS, cela n'est probablement pas ce que vous vouliez.
POSIX getpgrp can't take an argument
- (
getpgrpPOSIX ne prend pas d'argument) - (F) Votre système dispose de la fonction POSIX
getpgrp, qui ne prend pas d'argument, au contraire de la version BSD, qui prend un PID.
Possible Y2K bogue: %s
- (Bogue possible de l'an 2000)
- (W y2k) Vous êtes en train de concaténer le nombre 19 avec un autre nombre, ce qui pourrait être un problème potentiel pour l'an 2000.
Possible attempt to put comments in qw() list
- (Tentative possible de mettre des commentaires dans une liste
qw()) -
(W qw) Les listes qw contiennent des éléments séparés par des espacements ; comme avec les chaînes littérales, les caractères de commentaires ne sont pas ignorés, mais au lieu de ça traités comme des données littérales. (Vous auriez pu utiliser des délimiteurs différents des parenthèses indiquées ici ; les accolades sont également fréquemment utilisées.) Vous avez probablement écrit quelque chose comme ceci :
Sélectionnez@liste=qw(a # un commentaireb # un autre commentaire); -
alors que vous auriez dû écrire cela :
Sélectionnez@liste=qw(ab); - Si vous voulez vraiment des commentaires, construisez votre liste à l'ancienne, avec des apostrophes et des virgules :
@liste = (
'a', # un commentaire
'b', # un autre commentaire
);Possible attempt to separate words with commas
- (Tentative possible de séparer les mots avec des virgules)
- (W qw) Les listes qw contiennent des éléments séparés par des espacements ; les virgules ne sont donc pas nécessaires pour séparer les éléments. (Vous auriez pu utiliser des délimiteurs différents des parenthèses indiquées ici ; les accolades sont également fréquemment utilisées.)
-
Vous avez probablement écrit quelque chose comme ceci :
Sélectionnezqw( a,b, c ); - ce qui place les caractères virgules parmi certains éléments de la liste. Écrivez-le sans virgules si vous ne voulez pas les voir apparaître dans vos données :
qw( a b c );Possible memory corruption: %s overflowed 3rd argument
- (Corruption possible de la mémoire : le 3e argument de
%sa débordé) - (F) Un
ioctlou unfcntla renvoyé plus que ce Perl demandait. Perl anticipe un tampon de taille raisonnable, mais place un octet de sentinelle à la fin du tampon au cas où. On a écrasé cet octet de sentinelle et Perl suppose que la mémoire est maintenant corrompue.
pragma "attrs" is deprecated, use "sub NAME : ATTRS" instead
- (le pragma "attrs" est déprécié, utilisez à la place "sub NOM : ATTRS")
-
(W deprecated) Vous avez écrit quelque chose comme ceci :
-
Vous auriez dû utiliser à la place la nouvelle syntaxe de déclaration :
Sélectionnezsub fait : locked{... - Le pragma use attrs est maintenant obsolète et n'est fourni que pour assurer une compatibilité antérieure.
Precedence problem: open %s should be open(%s)
- (Problème de précédence :
open%sdevrait êtreopen(%s)) -
(S precedence) L'ancienne construction irrégulière :
SélectionnezopenTRUC||die; -
est maintenant mal interprétée en :
Sélectionnezopen(TRUC||die); - à cause la stricte régularisation de la grammaire de Perl 5 en opérateurs unaires et opérateur de listes. (L'ancien
openétait un peu des deux.) Vous devez mettre des parenthèses autour du handle de fichier ou utiliser le nouvel opérateurorà la place de||.
Premature end of script headers
- (Fin prématurée des en-têtes du script)
- Voir Server error.
print() on closed filehandle %s
- (
print() sur le handle de fichier fermé%s) - (W closed) Le handle de fichier dans lequel vous imprimez s'est retrouvé fermé à un moment auparavant. Vérifier le flux logique de votre programme.
printf() on closed filehandle %s
- (
printf() sur le handle de fichier fermé%s) - (W closed) Le handle de fichier dans lequel vous écrivez s'est retrouvé fermé à un moment auparavant. Vérifier le flux logique de votre programme.
Process terminated by SIG%s
- (Processus terminé par SIG
%s) - (W) Il s'agit d'un message standard formulé par les applications OS/2, alors que les applications Unix meurent en silence. C'est considéré comme une caractéristique du portage sous OS/2. Cet avertissement peut facilement être désactivé en positionnant les gestionnaires de signaux appropriés. Voir également « Process terminated by SIGTERM/SIGINT » (N.d.T. : Processus terminé par SIGTERM/SIGINT) dans le fichier README.os2 livré avec la distribution de Perl.
Prototype mismatch: %s vs %s
- (Non correspondance de prototypes :
%scontre%s) - (S) La sous-fonction qui est en train d'être déclarée ou définie a été précédemment déclarée ou définie avec un prototype différent.
Range iterator outside integer range
- (Itérateur d'intervalle en dehors d'un intervalle)
- (F) L'un (ou les deux) des arguments numériques de l'opérateur d'intervalle .. est en dehors de l'intervalle qui peut être représenté en interne par des entiers. Contourner cela est en forçant Perl à utiliser des incréments de chaînes magiques en ajoutant
0au début de vos nombres.
readline() on closed filehandle %s
- (readline() sur un handle de fichier fermé
%s) - (W closed) Le handle de fichier dans lequel vous êtes en train de lire s'est retrouvé fermé un moment auparavant. Vérifier le flux logique de votre programme.
realloc() of freed memory ignored
- (realloc() sur de la mémoire libérée, ignoré)
- (S malloc) Une routine interne a appelé realloc sur quelque chose qui avait déjà été libéré.
Reallocation too large: %lx
- (Réallocation trop grande :
%lx) - (F) Vous ne pouvez allouez plus de 64K sur une machine MS-DOS.
Recompile perl with -DDEBUGGING to use -D switch
- (Recompilez Perl avec
-DDEBUGGING pour utiliser l'option-D) - (F debugging) Vous ne pouvez utiliser l'option -D que si Perl a été compilé avec le code qui produit la sortie désirée ; comme cela implique une certaine surcharge, cela n'a pas été inclus dans votre installation de Perl.
Recursive inheritance detected in package '%s'
- (Héritage récursif détecté dans le paquetage '
%s') - (F) Plus de 100 niveaux d'héritage ont été utilisés. Ceci indique probablement une boucle accidentelle dans votre hiérarchie de classes.
Recursive inheritance detected while looking for method '%s' in package '%s'
- (Héritage récursif détecté en recherchant la méthode '
%s' dans le paquetage '%s') - (F) Plus de 100 niveaux d'héritages ont été utilisés. Ceci indique probablement une boucle accidentelle dans votre hiérarchie de classes.
Reference found where even-sized list expected
- (Référence trouvée où une liste de taille paire était attendue)
- (W misc) Vous avez donné une seule référence là où Perl s'attendait à avoir une liste avec un nombre pair d'éléments (pour affection à un hachage). Cela veut habituellement dire que vous avez utilisé le constructeur de hachage anonyme alors que vous vouliez utiliser des parenthèses. Dans tous les cas, un hachage exige des paires clef/valeur.
%hachage = { un => 1, deux => 2, }; # MAUVAIS
%hachage = [ qw( un tableau anonyme /)]; # MAUVAIS
%hachage = ( un => 1, deux => 2, ); # juste
%hachage = qw( un 1 deux 2 ); # également correctReference is already weak
- (La référence est déjà lâche)
- (W misc) Vous avez tenté de relâcher une référence qui était déjà lâche. Ceci n'a aucun effet.
Reference miscount in sv_replace()
- (Mauvais compte de références dans sv_replace())
- (W internal) On a passé à la fonction interne sv_replace un nouvel SV avec un nombre de références différent de 1.
regexp *+ operand could be empty
- (L'opérande
*+de l'expression régulière pourrait être vide) - (F) La partie d'une expression régulière sujette au quantifiant
*ou+pourrait correspondre à une chaîne vide.
regexp memory corruption
- (Corruption de la mémoire de l'expression régulière)
- (P) Le moteur d'expressions régulières s'est trompé avec ce que l'expression régulière lui a donné.
regexp out of space
- (Plus d'espace pour l'expression régulière)
- (P) Il s'agit d'une erreur « qui ne peut pas arriver », car safemalloc aurait dû la capturer plus tôt.
Reversed %s= operator
- (Opérateur
%s=inversé) - (W syntax) Vous avez écrit votre opérateur d'affectation à l'envers. Le
=doit toujours arriver en dernier, pour éviter l'ambiguïté avec les opérateurs unaires suivants.
Runaway format
- (Format s'échappant)
- (F) Votre format contenait la séquence de répétition jusqu'à un caractère blanc,
~~mais il a produit 200 lignes d'un coup et la 200e ligne ressemblait exactement à la 199e. Apparemment vous ne vous êtes pas arrangé pour que les arguments soient consommés, soit en utilisant^au lieu de@(pour les variables scalaires), soit en faisant unshiftou unpop(pour les variables de tableaux).
Scalar value @%s[%s] better written as $%s[%s]
- (Valeur scalaire
@%s[%s] mieux écrite avec$%s[%s]) - (W syntax) Vous avez utilisé une tranche de tableau (indiqué par
@) pour sélectionner un seul élément d'un tableau. Généralement il vaut mieux demander une valeur scalaire (indiquée par$). La différence est que$truc[&machin] se comporte toujours comme un scalaire, à la fois lors de son affectation et lors de l'évaluation de son argument, alors que@truc[&machin] se comporte comme une liste lorsque vous y affectez quelque chose en fournissant un contexte de liste à son indice, ce qui peut donner des choses étranges si vous vous attendez à un seul indice. D'un autre côté, si vous espériez vraiment traiter l'élément du tableau comme une liste, vous devez regarder comment fonctionnent les références, car Perl ne va pas par magie faire la conversion entre les scalaires et les listes à votre place.
Scalar value @%s{%s} better written as $%s{%s}
- (Valeur scalaire
@%s{%s}mieux écrite avec$%s{%s}) - (W syntax) Vous avez utilisé une tranche de hachage (indiquée par
@) pour sélectionner un seul élément d'un hachage. Généralement il vaut mieux demander une valeur scalaire (indiquée par$). La différence est que$truc{&machin}se comporte toujours comme un scalaire, à la fois lors de son affectation et lors de l'évaluation de son argument, alors que@truc{&machin}se comporte comme une liste lorsque vous y affectez quelque chose en fournissant un contexte de liste à son indice, ce qui peut donner des choses étranges si vous vous attendez à un seul indice. D'un autre côté, si vous espériez vraiment traiter l'élément du hachage comme une liste, vous devez regarder comment fonctionnent les références, car Perl ne va pas par magie faire la conversion entre les scalaires et les listes à votre place.
Script is not setuid/setgid in suidperl
- (Le script n'est pas en setuid/setgid dans suidperl)
- (F) Curieusement, le programme suidperl a été invoqué sur un script qui n'a pas de bit setuid ou setgid bit positionné. Cela n'a vraiment aucun sens.
Search pattern not terminated
- (Motif de recherche non terminé)
- (F) L'analyseur lexical n'a pas pu trouver le délimiteur final d'une construction
//ou m{}. Souvenez-vous que les délimiteurs fonctionnant par paires « ouvrant/fermant » (tels que les parenthèses, les crochets, les accolades ou les signes inférieur/supérieur) comptent les niveaux imbriqués. Omettre le$au début d'une variable$mpeut causer cette erreur.
%sseek() on unopened file
- (
%sseek() sur un fichier non ouvert) - (W unopened) Vous avez essayé d'utiliser la fonction
seekousysseeksur un handle de fichier qui soit n'a jamais été ouvert, soit a été fermé depuis.
select not implemented
- (
selectnon implémenté) - (F) Cette machine n'implémente pas l'appel système
select.
sem%s not implemented
- (sem
%snon implémenté) - (F) Vous n'avez pas d'implémentation des sémaphores des IPC System V sur votre système.
semi-panic: attempt to dup freed string
- (Demi-panique : tentative de dupliquer une chaîne libérée)
- (S internal) La routine interne newSVsv a été appelée pour dupliquer un scalaire qui avait été marqué auparavant comme étant libre.
Semicolon seems to be missing
- (Il semble manquer un point-virgule)
- (W semicolon) Une quasi-erreur de syntaxe a probablement été causée par un point-virgule manquant ou un autre opérateur manquant peut-être, comme une virgule.
send() on closed socket
- (
send() sur une socket fermée) - (W closed) La socket dans laquelle vous envoyer des données s'est retrouvée fermée à un moment auparavant. Vérifiez le flux logique de votre programme.
Sequence (? incomplete
- (Séquence (
?incomplète) - (F) Une expression régulière finissait par une extension incomplète (
?.
Sequence (?#... not terminated
- (Séquence (
?... non terminée) - (F) Un commentaire d'une expression régulière doit se terminer par une parenthèse fermée. Les parenthèses imbriquées ne sont pas autorisées.
Sequence (?%s...) not implemented
- (Séquence (
?%s...) non implémentée) - (F) Une proposition d'extension des expressions régulières a réservé le caractère, mais n'a pas encore été écrite.
Sequence (?%s...) not recognized
- (Séquence (
?%s...) non reconnue) - (F) Vous avez utilisé une expression régulière qui n'a aucun sens.
Server error
- (Erreur du serveur)
- Il s'agit du message d'erreur généralement vu dans une fenêtre de navigateur lorsque vous essayez de lancer un programme CGI (y compris SSI) sur le Web. Le véritable texte d'erreur varie largement d'un serveur à l'autre. Les variantes les plus fréquemment vues sont «
500Server error », « Method (something)notpermitted », « Document contains no data », « Premature end of script headers » et « Didnotproduce a valid header » (« Erreur de serveur500», « Méthode (quelque_chose) non permise », « Le documentnecontient aucune donnée », « Fin prématurée des en-têtes de script » et « N'a pas produit d'en-tête valide »). - Il s'agit d'une erreur CGI, non d'une erreur Perl.
-
Vous devez vous assurer que votre script soit exécutable, accessible par l'utilisateur sous lequel le script CGI tourne (qui n'est probablement pas le compte utilisateur sous lequel vous avez fait vos tests), qu'il ne repose sur aucune variable d'environnement (telle que PATH) que l'utilisateur ne va pas avoir et qu'il ne se trouve pas à un emplacement inatteignables pour le serveur CGI. Pour plus d'informations, merci de voir les liens suivants :
- http://www.perl.com/CPAN/doc/FAQs/cgi/idiots-guide.html
- http://www.perl.com/CPAN/doc/FAQs/cgi/perl-cgi-faq.html
- ftp://rtfm.mit.edu/pub/usenet/news.answers/www/cgi-faq [ftp://rtfm.mit.edu/pub/usenet/news.answers/www/cgi-faq]
- http://hoohoo.ncsa.uiuc.edu/cgi/interface.html
- http://www-genome.wi.mit.edu/WWW/faqs/www-security-faq.html
- Vous devriez également regarder la FAQ Perl.
setegid() not implemented
- (setegid() non implémenté)
- (F) Vous avez essayé d'affecter,
$) mais votre système d'exploitation ne supporte pas l'appel système setegid (ou un équivalent) ou du moins c'est ce que pense Configure.
seteuid() not implemented
- (seteuid() non implémenté)
- (F) Vous avez essayé d'affecter,
$>mais votre système d'exploitation ne supporte pas l'appel système seteuid (ou un équivalent) ou du moins c'est ce que pense Configure.
setpgrp can't take arguments
- (
setpgrpne peut pas prendre d'arguments) - (F) Votre système dispose de la fonction
setpgrpde BSD 4.2, qui ne prend pas d'argument, au contraire de setpgid POSIX, qui prend un ID de processus et un ID de groupe de processus.
setrgid() not implemented
- (setrgid() non implémenté)
- (F) Vous avez essayé d'affecter,
$( mais votre système d'exploitation ne supporte pas l'appel système setrgid (ou un équivalent) ou du moins c'est ce que pense Configure.
setruid() not implemented
- (setruid() non implémenté)
- (F) Vous avez essayé d'affecter,
$<mais votre système d'exploitation ne supporte pas l'appel système setruid (ou un équivalent) ou du moins c'est ce que pense Configure.
setsockopt() on closed socket %s
- (
setsockopt() sur une socket fermée%s) - (W closed) Vous avez essayé de positionner des options sur une socket fermée. Peut-être avez-vous oublié de vérifier la valeur renvoyée par votre appel à
socket?
Setuid/gid script is writable by world
- (Script setuid
/setgid modifiable par le monde entier) - (F) L'émulateur setuid ne lancera pas un script modifiable par le monde entier, car le monde entier peut très bien déjà l'avoir modifié.
shm%s not implemented
- (shm
%snon implémenté) - (F) Vous n'avez pas d'implémentation de la mémoire partagée des IPC System V sur votre système.
shutdown() on closed socket %s
- (
shutdown() sur une socket fermée%s) - (W closed) Vous avez essayé de faire un
shutdownsur socket fermée. Cela semble quelque peu superflu.
SIG%s handler "%s" not defined
- (Gestionnaire "
%s" pour SIG%snon défini) - (W signal) Le gestionnaire pour le signal nommé dans
%SIGn'existe en fait pas. Peut-être l'avez-vous mis dans le mauvais paquetage ?
sort is now a reserved word
- (
sortest maintenant un mot réservé) - (F) Il s'agit d'un ancien message d'erreur que pratiquement personne ne rencontrera plus. Mais avant que
sortsoit un mot-clef, les gens l'utilisaient parfois comme un handle de fichier.
Sort subroutine didn't return a numeric value
- (Le sous-programme de
sortn'a pas renvoyé de valeur numérique) - (F) Une routine de comparaison pour
sortdoit retourner un nombre. Vous l'avez probablement foutu en l'air en n'utilisant pas<=>oucmp, ou en ne les utilisant pas correctement.
Sort subroutine didn't return single value
- (Le sous-programme de
sortn'a pas renvoyé une valeur unique) - (F) Une routine de comparaison pour
sortne peut pas renvoyer une valeur de liste avec plus ou moins d'un élément.
Split loop
- (Boucle dans un
split) - (P) Le
splitbouclait sans fin. (Évidemment, unsplitne devrait boucler plus de fois qu'il n'y a de caractères en entrée, ce qui s'est passé.)
Stat on unopened file <%s>
- (
statsur un fichier non ouvert <%s>) - (W unopened) Vous avez essayé d'utiliser la fonction
stat(ou un test de fichier équivalent) sur un handle de fichier qui n'a jamais été ouvert ou qui a été fermé depuis.
Statement unlikely to be reached
- (Instruction peu susceptible d'être atteinte)
- (W exec) Vous avez fait un
execavec des instructions le suivant autres qu'un die. Il s'agit presque toujours d'une erreur, carexecne revient jamais à moins qu'il n'y ait une erreur. Vous vouliez probablement utilisersystemà la place, qui lui revient. Pour supprimer cet avertissement, mettez-leexecdans un bloc tout seul.
Strange *+?{} on zero-length expression
- (
*+?{}étrange sur une expression de longueur nulle) - (W regexp) Vous avez appliqué un quantifiant d'expression régulière à un endroit où cela n'a aucun sens, comme dans une assertion de longueur nulle. Essayez de plutôt mettre le quantifiant à l'intérieur de l'assertion. Par exemple, le moyen de réussir la correspondance avec abc, si c'est suivi par trois répétitions de xyz est
/abc(?=(?:xyz){3})/, et non/abc(?=xyz){3}/.
Stub found while resolving method '%s' overloading '%s' in package '%s'
- (Souche trouvée lors de la résolution de la méthode '
%s' surchargeant '%s' dans le paquetage '%s') - (P) La résolution de la surcharge dans l'arbre
@ISAa peut être été rompue par des souches (stubs) d'importation. Les souches ne devraient jamais être implicitement créées, mais les appels explicites à can peuvent rompre cela.
Subroutine %s redefined
- (Sous-programme
%sredéfini) - (W redefine) Vous avez redéfini un sous-programme. Pour supprimer cet avertissement, écrivez :
Substitution loop
- (Boucle dans une substitution)
- (P) La substitution boucle sans fin. (Évidemment, une substitution ne devrait boucler plus de fois qu'il n'y a de caractères en entrée, ce qui s'est passé.)
Substitution pattern not terminated
- (Motif pour la substitution non terminé)
- (F) L'analyseur lexical ne peut trouver le délimiteur intérieur d'une construction s
///ou s{}{}. Souvenez-vous que les délimiteurs fonctionnant par paires « ouvrant/fermant » (tels que les parenthèses, les crochets, les accolades ou les signes inférieur/supérieur) comptent les niveaux imbriqués. Omettre le$au début d'une variable$speut causer cette erreur.
Substitution replacement not terminated
- (Remplacement pour la substitution non terminé)
- (F) L'analyseur lexical ne peut trouver le délimiteur final d'une construction s
///ou s{}{}. Souvenez-vous que les délimiteurs fonctionnant par paires « ouvrant/fermant » (tels que les parenthèses, les crochets, les accolades ou les signes inférieur/supérieur) comptent les niveaux imbriqués. Omettre le$au début d'une variable$speut causer cette erreur.
substr outside of string
- (
substrà l'extérieur d'une chaîne) - (W substr|F) Vous avez essayé de référencer un
substrqui pointait en dehors d'une chaîne. C'est-à-dire que la valeur absolue du décalage est plus grande que la longueur de la chaîne. Cet avertissement est fatal sisubstrest utilisé dans un contexte de lvalue (par exemple comme opérateur du côté gauche d'une affectation ou comme argument d'un sous-programme).
suidperl is no longer needed since %s
- (suidperl n'est plus nécessaire depuis
%s) - (F) Votre Perl a été compilé avec -DSETUID_SCRIPTS_ARE_SECURE_NOW, mais une version de l'émulateur setuid est tout de même arrivé à se lancer d'une manière ou d'une autre.
switching effective %s is not implemented
- (l'échange de
%seffectif n'est pas implémenté) - (F) Avec le pragma use filetest actif, nous ne pouvons pas échanger les UID ou les GID réels et effectifs.
syntax error
- (erreur de syntaxe)
-
(F) Ce message veut probablement dire que vous avez eu une erreur de syntaxe. Les raisons habituelles incluent :
- un mot-clef est mal orthographié ;
- il manque un point-virgule ;
- il manque une virgule ;
- il manque une parenthèse ouvrante ou fermante ;
- il manque un crochet ouvrant ou fermant ;
- il manque une apostrophe ou un guillemet fermant.
- Souvent un autre message sera associé avec l'erreur de syntaxe donnant plus d'informations. (Parfois, cela aide d'activer -w.) Le message d'erreur en lui-même dit souvent à quel endroit de la ligne Perl a décidé de s'arrêter. Parfois la véritable erreur se trouve quelques tokens avant, car Perl est doué pour comprendre ce que l'on entre aléatoirement. Occasionnellement, le numéro de ligne peut être inexact et la seule manière de savoir ce qui ce passe est d'appeler de façon répétitive, une fois tous les 36 du mois, perl -c en éliminant à chaque fois la moitié du programme pour voir où l'erreur disparaît. Il s'agit d'une sorte de version cybernétique du jeu des 20 questions.
syntax error at line %d:'%s' unexpected
- (erreur de syntaxe à la ligne
%d:'%s' inattendu) - (A) Vous avez accidentellement lancé votre script via le Bourne shell au lieu de Perl. Vérifiez la ligne
#!ou lancez vous-même votre script manuellement dans Perl avec perl nom_script.
System V %s is not implemented on this machine
- (
%sde System V n'est pas implémenté sur cette machine) - (F) Vous avez essayé de faire quelque chose avec une fonction commençant par sem, shm ou, msg mais cet IPC System V n'est pas implémenté sur votre machine. (Sur certaines machines, la fonctionnalité peut exister, mais peut ne pas être configurée.)
syswrite() on closed filehandle
- (
syswrite() sur un handle de fichier fermé) - (W closed) Le handle de fichier dans lequel vous écrivez s'est retrouvé fermé à un moment auparavant. Vérifiez le flux logique de votre programme.
Target of goto is too deeply nested
- (La cible du goto est trop profondément imbriquée)
- (F) Vous avez essayé d'utiliser goto pour atteindre une étiquette qui était trop profondément imbriquée pour que Perl puisse l'atteindre. Perl vous fait une faveur en vous le refusant.
tell() on unopened file
- (
tell() sur un fichier non ouvert) - (W unopened) Vous avez essayé d'utiliser la fonction
tell() sur un handle de fichier qui n'a jamais été ouvert ou qui a été fermé depuis.
Test on unopened file %s
- (Test sur un fichier non ouvert
%s) - (W unopened) Vous avez essayé d'invoquer un opérateur de test de fichier sur un handle de fichier qui n'est pas ouvert. Vérifiez votre logique.
- (Cette utilisation de $[ n'est pas supportée)
-
(F) L'affectation de
$[ est maintenant strictement circonscrite et interprétée comme une directive de compilation. Vous devez maintenant écrire une seule possibilité parmi celles-ci : - Ceci est imposé pour prévenir le problème d'un module changeant la base des tableaux depuis un autre module par inadvertance.
The %s function is unimplemented
- (La fonction
%sn'est pas implémentée) - La fonction indiquée n'est pas implémentée sur cette architecture, selon les tests de Configure.
The crypt() function is unimplemented due to excessive paranoia
- (La fonction
crypt() n'est pas implémentée à cause d'une paranoïa excessive) - (F) Configure n'a pas pu trouver la fonction
cryptsur votre machine, probablement parce que votre vendeur ne l'a pas fournie, probablement parce qu'il pense que le gouvernement des États-Unis pense que c'est un secret ou du moins continue à prétendre que c'en est un.
The stat preceding -l _ wasn't an lstat
- (Le
statprécédant-l _ n'était pas unlstat) - (F) Cela n'a pas de sens de vérifier si le tampon courant de
statest un lien symbolique si le dernier stat que vous avez écrit dans le tampon a déjà passé le lien symbolique pour obtenir le fichier réel. Utilisez un véritable nom de fichier à la place.
This Perl can't reset CRTL environ elements (%s)
- (Cette copie de Perl ne peut pas réinitialiser les éléments de l'environnement de CRTL (
%s))
This Perl can't set CRTL environ elements (%s = %s)
- (Cette copie de Perl ne peut pas positionner les éléments de l'environnement de CRTL (
%s=%s)) - (W internal) Il s'agit d'avertissements spécifiques à VMS. Vous avez essayé de modifier ou de supprimer un élément du tableau d'environnement interne de CRTL, mais votre copie de Perl n'a pas été compilée avec un CRTL contenant la fonction interne setenv. Vous devrez recompiler Perl avec un CRTL qui le contienne ou redéfinir PERL_ENV_TABLES (voir perlvms(1)) pour que le tableau d'environnement ne soit pas la cible de la modification de
%ENVqui a produit cet avertissement.
times not implemented
- (
timesnon implémenté) - (F) Votre version de la bibliothèque C ne fait apparemment pas de
times. Je suspecte que vous n'êtes pas sous Unix.
Too few args to syscall
- (Trop peu d'arguments pour
syscall) - (F) Il doit y avoir au moins un argument à
syscallpour spécifier l'appel système à appeler, pauvre étourdi !
Too late for "-T" option
- (Trop tard pour l'option "
-T") - (X) La ligne
#!(ou son équivalent local) dans un script Perl contient l'option -T, mais Perl n'a pas été invoqué avec -T sur la ligne de commande. Il s'agit d'une erreur, car le temps que Perl découvre un -T dans un script, il est trop tard pour marquer proprement l'intégralité de l'environnement. Donc Perl abandonne. - Si le script Perl a été exécuté en tant que commande en utilisant le mécanisme
#!(ou son équivalent local), cette erreur peut habituellement être corrigée en éditant la ligne#!pour que l'option -T fasse partie du premier argument de Perl : ex. changer perl-n-T en perl-T-n. - Si le script Perl a été exécuté en tant que perl nom_script alors l'option -T doit apparaître sur la ligne de commande : perl -T nom_script.
Too late for "-%s" option
- (Trop tard pour l'option « -%s »)
- (X) La ligne
#!(ou son équivalent local) dans un script Perl contient l'option -M ou-m. Il s'agit d' une erreur, car les options -M et -m ne sont pas prévues pour être utilisées à l'intérieur des scripts. Utilisez use à la place.
Too late to run %s bloc
- (Trop tard pour lancer le bloc
%s) - (W void) Un bloc CHECK ou INIT a été défini à l'exécution, lorsque l'opportunité de le lancer est déjà passée. Vous chargez peut-être un fichier avec require ou do alors que vous devriez utiliser use à la place. Ou vous devriez peut-être mettre le require ou le do à l'intérieur d'un bloc BEGIN.
Too many ('s
- (Trop de « ( »)
Too many )'s
- (trop de « ) »)
- (A) Vous avez lancé accidentellement votre script via csh au lieu de Perl. Vérifiez la ligne
#!ou lancez vous-même votre script manuellement dans Perl avec perl nom_script.
Too many args to syscall
- (Trop d'argument pour
syscall) - (F) Perl supporte un maximum de 14 arguments seulement pour
syscall.
Too many arguments for %s
- (Trop d'argument pour
%s) - (F) La fonction demande moins d'arguments que vous en avez spécifié.
trailing \ in regexp
- (\ à la fin de l'expression régulière)
- (F) L'expression régulière se termine par un antislash qui n'est pas protégé par un antislash. Faites-le.
Transliteration pattern not terminated
- (Motif pour la traduction non terminé)
- (F) L'analyseur lexical n'a pas pu trouver le délimiteur intérieur d'une construction tr
///, tr[][], y///ou y[][]. Omettre le$au début des variables$trou$ypeut causer cette erreur.
Transliteration replacement not terminated
- (Remplacement pour la traduction non terminé)
- (F) L'analyseur lexical n'a pas pu trouver le délimiteur final d'une construction tr
///ou tr[][].
truncate not implemented
- (
truncatenon implémenté) - (F) Votre machine n'implémente pas de mécanisme de troncation de fichier que Configure puisse reconnaître.
Type of arg %d to %s must be %s (not %s)
- (Le type de l'argument
%dde%sdoit être%s(pas%s)) - (F) Cette fonction exige que l'argument à cette position soit d'un certain type. Les tableaux doivent être
@NOMou@{EXPR}. Les hachages doivent être%NOMou%{EXPR}. Aucun déréférencement implicite n'est permis — utilisez la forme{EXPR}en tant que déréférencement explicite.
umask: argument is missing initial 0
- (
umask: il manque0au début de l'argument) - (W umask) Un umask de
222est incorrect. Il devrait être,0222car les littéraux octaux commencent toujours par0en Perl, tout comme en C.
umask not implemented
- (
umasknon implémenté) - (F) Votre machine n'implémente pas la fonction
umasket vous avez essayé de l'utiliser pour restreindre les permissions pour vous-même. (EXPR&0700).
Unable to create sub named "%s"
- (Incapable de créer le sous-programme nommé "
%s") - (F) Vous avez tenté de créer ou d'accéder à un sous-programme avec un nom illégal.
Unbalanced context: %d more PUSHes than POPs
- (Contexte déséquilibré :
%dPUSH de plus que de POP) - (W internal) Le code de sortie a détecté une incohérence interne entre le nombre de contextes d'exécution dans lesquels on est entré et depuis lesquels on est sorti.
Unbalanced saves: %d more saves than restores
- (Sauvegardes déséquilibrées :
%dsauvegardes de plus que de restaurations) - (W internal) Le code de sortie a détecté une incohérence interne entre le nombre de variables qui ont été sauvegardées par local.
Unbalanced scopes: %d more ENTERs than LEAVEs
- (Portées déséquilibrées :
%dENTER de plus que de LEAVE) - (W internal) Le code de sortie a détecté une incohérence interne entre le nombre de blocs dans lequel on est rentré et depuis lesquels on est sorti.
Unbalanced tmps: %d more allocs than frees
- (Valeurs temporaires déséquilibrées :
%dallouées de plus que de libérées) - (W internal) Le code de sortie a détecté une incohérence interne entre le nombre de scalaires mortels qui ont été alloués et libérés.
Undefined format "%s" called
- (Format indéfini "
%s" appelé) - (F) Le format indiqué ne semble pas exister. Peut-être est-il réellement dans un autre paquetage ?
Undefined sort subroutine "%s" called
- (Sous-programme de
sortindéfini "%s" appelé) - (F) La routine de comparaison de
sortspécifiée ne semble pas exister. Peut-être est-elle dans un autre paquetage?
Undefined subroutine &%s called
- (Sous-programme indéfini
&%sappelé) - (F) Le sous-programme indiqué n'a pas été défini ou s'il l'a été, il a été indéfini depuis.
Undefined subroutine called
- (Sous-programme indéfini appelé)
- (F) Le sous-programme anonyme que vous essayez d'appeler n'a pas été défini ou s'il l'a été, il a été indéfini depuis.
Undefined subroutine in sort
- (Sous-programme indéfini dans
sort) - (F) La routine de comparaison de
sortspécifiée est déclarée, mais ne semble pas avoir été définie pour le moment.
Undefined top format "%s" called
- (Format d'en-tête indéfini "
%s" appelé) - (F) Le format indiqué ne semble pas exister. Peut-être est-il en réalité dans un autre paquetage?
Undefined value assigned to typeglob
- (Valeur indéfinie affectée à un typeglob)
- (W misc) Une valeur indéfinie a été affectée à un typeglob, comme
*truc=undef. - Ceci n'a aucun effet. Il est possible que vous vouliez dire en réalité
undef*truc.
unexec of %s into %s failed!
- (Échec de l'unexec de
%sdans%s!) - (F) La routine unexec a échoué pour une raison ou pour une autre. Voir votre représentant local FSF (Free Software Fondation), qui l'a probablement mis là en premier lieu.
Unknown BYTEORDER
- (BYTEORDER inconnu)
- (F) Il n'y a aucune fonction d'échange d'octets pour une machine fonctionnant avec cet ordre d'octets.
Unknown open() mode '%s'
- (Mode d'
open() '%s' inconnu) - (F) Le deuxième argument d'un
openà trois arguments n'est pas dans la liste des modes valides :<,>,>>,+<,+>,+>>,-|,|-.
Unknown process %x sent message to prime_env_iter: %s
- (Le processus inconnu
%xa envoyé un message au prime_env_iter :%s) - (P) Il s'agit d'une erreur spécifique à VMS. Perl lisait des valeurs pour
%ENVavant de le parcourir et quelqu'un d'autre a collé un message dans le flux de données que Perl attendait. Quelqu'un de très perturbé ou peut-être essayant de subvertir le contenu de%ENVpour Perl dans un but néfaste.
unmatched () in regexp
- (() sans correspondance dans l'expression régulière)
- (F) Les parenthèses non protégées par un antislash doivent toujours être équilibrées dans les expressions régulières. Si vous êtes utilisateur de vi, la touche
%est parfaitement adaptée pour trouver la parenthèse correspondante.
Unmatched right %s bracket
- (Signe
%sfermant sans correspondance) - (F) L'analyseur lexical a compté plus d'accolades ou de crochets fermants que d'ouvrants, vous avez donc probablement oublié de mettre un signe ouvrant correspondant. En règle générale, vous trouverez le signe manquant (si l'on peut s'exprimer ainsi) près de l'endroit où vous étiez en train d'éditer en dernier.
unmatched [] in regexp
- ([] sans correspondance dans l'expression régulière)
- (F) Les crochets autour d'une classe de caractères doivent se correspondre. Si vous voulez inclure un crochet fermant dans une classe de caractères, protégez-le avec un antislash ou mettez-le en premier.
Unquoted string "%s" may clash with future reserved word
- (Chaîne sans guillemets ni apostrophes "
%s" susceptible d'être en conflit avec un mot réservé dans le futur) - (W reserved) Vous utilisez un mot simple qui pourrait être un jour proclamé comme étant un mot réservé. Le mieux est de mettre un tel mot entre guillemets ou entre apostrophes ou en lettres capitales ou d'insérer un souligné dans son nom. Vous pouvez également le déclarer en tant que sous-programme.
Unrecognized character %s
- (Caractère
%snon reconnu) - (F) L'analyseur syntaxique de Perl ne sait absolument pas quoi faire avec le caractère spécifié dans votre script Perl (ou dans un eval). Peut-être avez-vous essayé de lancer un script compressé, un programme binaire ou un répertoire en tant que programme Perl.
Unrecognized escape \\%c passed through
- (Rencontre d'une séquence d'échappement \\
%cnon reconnu) - (W misc) Vous avez employé une combinaison avec un caractère antislash qui n'est pas reconnu.
Unrecognized signal name "%s"
- (Nom de signal "
%s" non reconnu) - (F) Vous avez spécifié un nom de signal à la fonction
killqui n'est pas reconnue. Faiteskill-l dans votre shell pour voir les noms de signaux valides sur votre système.
Unrecognized switch: -%s (-h will show valid options)
- (Option on reconnue :
-%s(-h donne les options valides)) - (F) Vous avez spécifié une option illégale pour Perl. Ne faites pas cela. (Si vous pensez ne pas l'avoir fait, vérifiez la ligne
#!pour voir si elle ne spécifie pas la mauvaise option dans votre dos.)
Unsuccessful %s on filename containing newline
- (Échec de
%ssur un nom de fichier contenant un saut de ligne) - (W newline) Une opération de fichier a été tentée sur un nom de fichier et cette opération a échoué, probablement parce que le nom de fichier contenait un caractère de saut de ligne, probablement parce que vous avez oublié de le faire sauter par un
chopou unchomp.
Unsupported directory function "%s" called
- (Fonction "
%s" sur les répertoires non supportée appelée) - (F) Votre machine ne supporte pas
opendiretreaddir.
Unsupported function fork
- (Fonction
forknon supportée) - (F) Votre version d'exécutable ne supporte pas le
fork. Remarquez que sur certains systèmes, comme OS/2, il peut y avoir différentes versions d'exécutables Perl, certaines d'entre elles supportentfork, d'autres non. - Essayez de changer le nom que vous utilisez pour appelez Perl en perl_, perl__ et ainsi de suite.
Unsupported function %s
- (Fonction
%snon supportée) - (F) Cette machine n'implémente apparemment pas la fonction indiquée ou du moins c'est ce que pense Configure.
Unsupported socket function "%s" called
- (Fonction "
%s" sur les sockets non supportée appelée) - (F) Votre machine ne supporte pas le mécanisme des sockets Berkeley ou du moins c'est ce que pense Configure.
Unterminated <> operator
- (Opérateur
<>non terminé) - (F) L'analyseur lexical a vu un signe inférieur à un endroit où il s'attendait à un terme, il recherche donc le signe supérieur correspondant et ne le trouve pas. Il y a des chances que vous ayez oublié des parenthèses obligatoires plus tôt dans la même ligne et vous que pensiez vraiment à un
<signifiant « inférieur à ».
Unterminated attribute parameter in attribute list
- (Paramètre d'attribut non terminé dans une liste d'attributs)
- (F) L'analyseur lexical a vu une parenthèse ouvrante lorsqu'il analysait une liste d'attributs, mais n'a pas trouvé la parenthèse fermante correspondante. Vous devez ajouter (ou enlever) un caractère antislash pour équilibrer vos parenthèses.
Unterminated attribute list
- (Liste d'attributs non terminée)
- (F) L'analyseur lexical a trouvé quelque chose d'autre qu'un identificateur simple au début d'un attribut et ce n'était pas un point-virgule ni le début d'un bloc. Peut-être avez-vous terminé trop tôt la liste de paramètres de l'attribut précédent.
- (L'utilisation de
$#est dépréciée) - (D deprecated) Il s'agissait d'une tentative mal avisée d'émuler une fonctionnalité de awk mal définie. Utilisez plutôt un
printfousprintfexplicite.
- (L'utilisation de
$*est dépréciée) - (D deprecated) Cette variable activait comme par magie la recherche de motifs en multilignes, à la fois pour vous et pour les sous-programmes malchanceux que vous seriez amené à appeler. Maintenant, vous devriez utiliser les modificateurs
//m et//s pour faire cela sans les effets dangereux d'action à distance de$*.
Use of %s in printf format not supported
- (Utilisation de
%snon supportée dans un format deprintf) - (F) Vous avez essayé d'utiliser une fonctionnalité de
printfqui est accessible en C. Cela veut habituellement dire qu'il existe une meilleure manière de faire cela en Perl.
Use of bare << to mean <<"" is deprecated
- (L'utilisation d'un
<<brut signifiant<<""est dépréciée) - (D deprecated) Vous êtes maintenant encouragé à utiliser la forme explicite avec des guillemets ou des apostrophes si vous désirez utiliser une ligne vide comme délimiteur final d'un document « ici-même » (here document).
Use of implicit split to @_ is deprecated
- (L'utilisation d'un
splitimplicite sur@_est dépréciée) - (D deprecated) Vous donnez beaucoup de travail au compilateur lorsque vous écrasez la liste d'arguments d'un sous-programme, il vaut donc mieux affecter explicitement les résultats d'un
splità un tableau (ou à une liste).
Use of inherited AUTOLOAD for non-method %s() is deprecated
- (L'utilisation de l'héritage par AUTOLOAD pour la non-méthode
%s() est dépréciée) - (D deprecated) Comme fonctionnalité (hum) accidentelle, les sous-programmes AUTOLOAD étaient recherchés de la même façon que les méthodes (en utilisant la hiérarchie de
@ISA) même lorsque les sous-programmes à autocharger étaient appelés en tant que fonctions brutes (ex. : Truc::bidule()) et pas en tant que méthodes (par exemple, Truc->bidule() ou$obj->bidule()). - Ce bogue a été rectifié dans Perl 5.005, qui utilisait la recherche de méthodes seulement pour l'AUTOLOAD de méthodes. Cependant, il y a une base significative de code existant susceptible d'utiliser l'ancien comportement. Ainsi, en tant qu'étape intermédiaire, Perl 5.004 émettait cet avertissement optionnel quand des non-méthodes utilisaient des AUTOLOAD héritées.
- La règle simple est la suivante : l'héritage ne fonctionnera pas quand il y a autochargement de non-méthodes. La simple correction pour de l'ancien code est : dans tout module qui avait l'habitude de dépendre de l'héritage d'AUTOLOAD pour les non-méthodes d'une classe de base nommée Classe_Base, exécutez
*AUTOLOAD=&Classe_Base::AUTOLOAD au démarrage. - Dans le code qui actuellement fait use AutoLoader;
@ISA=qw(AutoLoader);, vous pouvez supprimer AutoLoader de@ISAet changer use AutoLoader; en use AutoLoader'AUTOLOAD';.
Use of reserved word "%s" is deprecated
- (L'utilisation du mot réservé "
%s" est dépréciée) - (D deprecated) Le mot simple indiqué est un mot réservé. Les futures versions de Perl peuvent l'utiliser en tant que mot-clef, vous feriez donc mieux de mettre explicitement le mot entre guillemets ou entre apostrophes d'une manière appropriée à son contexte d'utilisation ou d'utiliser de surcroît un nom différent. L'avertissement peut être supprimé pour les noms de sous-programmes en ajoutant un préfixe
&ou en qualifiant la variable avec le paquetage, comme&local(), ou Truc::local().
- (L'utilisation de
%sest dépréciée) - (D deprecated) La construction indiquée n'est plus recommandée, généralement parce qu'il y a une meilleure façon de faire et également parce que l'ancienne méthode a de mauvais effets de bord.
Use of uninitialized value %s
- (Utilisation d'une valeur non initialisée %s)
- (W uninitialized) Une valeur indéfinie a été utilisée comme si elle avait déjà été définie. Elle a été interprétée comme un
""ou un,0mais peut-être est-ce une erreur. Pour supprimer cet avertissement, affectez une valeur définie à vos variables.
- (Utilisation inutile du pragma "re")
- (W) Vous avez fait un use re sans aucun argument. Ceci n'est vraiment pas très utile.
Useless use of %s in void context
- (Utilisation inutile de
%sdans un contexte vide) -
(W void) Vous avez fait quelque chose sans effet de bord dans un contexte qui ne fait rien de la valeur de retour, comme une instruction ne renvoyant pas de valeur depuis un bloc ou le côté gauche d'un opérateur scalaire virgule. Par exemple, vous obtiendrez ceci si vous confondez les précédences en C avec les précédences en Python en écrivant :
Sélectionnez$un,$deux=1,2; -
alors que vous vouliez dire :
Sélectionnez($un,$deux)=(1,2); -
Une autre erreur courante est l'utilisation de parenthèses ordinaires pour construire une liste de références alors vous devriez utiliser des accolades ou des crochets, par exemple, si vous écrivez :
Sélectionnez$tableau=(1,2); -
alors que vous vouliez dire :
Sélectionnez$tableau=[1,2]; - Les crochets transforment explicitement une valeur de liste en une valeur scalaire tandis que les parenthèses ne le font pas. Donc, lorsqu'une liste entre parenthèses est évaluée dans un contexte scalaire, la virgule est traitée comme l'opérateur virgule du C, qui rejette l'argument de gauche, ce qui n'est pas ce que vous voulez.
untie attempted while %d inner references still exist
- (untie tenté alors que
%dréférences intérieures existent toujours) - (W untie) Une copie de l'objet renvoyé par
tie(ou partied) était toujours valide lorsqu'untiea été appelé.
Value of %s can be "0"; test with defined()
- (La valeur de
%speut valoir "0" ; testez avecdefined()) - (W misc) Dans une expression conditionnelle, vous avez utilisé
<HANDLE>,<*>(glob),eachoureaddiren tant que valeur booléenne. Chacune de ces constructions peut renvoyer une valeur de "0" ; cela rendrait fausse l'expression conditionnelle, ce qui n'est probablement pas ce que vous désiriez. Quand vous utilisez ces constructions dans des expressions conditionnelles, testez leur valeur avec l'opérateurdefined.
Value of CLI symbol "%s" too long
- (Valeur du symbole de CLI "
%s" trop longue) - (W misc) Il s'agit d'un avertissement spécifique à VMS. Perl a essayé de lire la valeur d'un élément de
%ENVdepuis la table de symboles de CLI et a trouvé une chaîne résultante plus longue que 1 024 caractères. La valeur de retour a été tronquée à 1 024 caractères.
Variable "%s" is not imported %s
- (La variable "
%s" n'est pas importée de%s) - (F) Alors que use strict est activé, vous vous êtes référés à une variable globale qu'apparemment vous pensiez avoir importée depuis un autre module, car quelque chose d'autre ayant le même nom (habituellement un sous-programme) est exporté par ce module. Cela veut habituellement dire que vous vous êtes trompé de drôle de caractère (
$,@,%ou&) devant votre variable.
Variable "%s" may be unavailable
- (La variable "
%s" peut être inaccessible) -
(W closure) Un sous-programme anonyme intérieur (imbriqué) se trouve dans un sous-programme nommé et encore à l'extérieur se trouve un autre sous-programme ; et le sous-programme anonyme (le plus à l'intérieur) fait référence à une variable lexicale définie dans le sous-programme le plus à l'extérieur. Par exemple :
-
Si le sous-programme anonyme est appelé ou référencé (directement ou indirectement) depuis le sous-programme le plus à l'extérieur, il va partager la variable comme vous pouviez vous y attendre. Mais si le sous-programme anonyme est appelé ou référencé lorsque le sous-programme le plus à l'extérieur est inactif, il verra la valeur de la variable partagée telle qu'elle était avant et pendant le premier appel au sous-programme le plus à l'extérieur, ce qui n'est probablement pas ce que vous voulez.
- Dans ces circonstances, il vaut habituellement mieux rendre anonyme le sous-programme du milieu anonyme, en utilisant la syntaxe sub
{}. Perl possède un support spécifique pour les variables partagées dans les sous-programmes anonymes imbriqués ; un sous-programme nommé entre les deux interfère avec cette fonctionnalité.
Variable "%s" will not stay shared
- (La variable "
%s" ne restera pas partagée) - (W closure) Un sous-programme nommé intérieur (imbriqué) fait référence à une variable lexicale définie dans un sous-programme extérieur. Lorsque le sous-programme intérieur est appelé, il verra probablement la valeur de la variable du sous-programme extérieur telle qu'elle était avant et pendant le premier appel au sous-programme extérieur ; dans ce cas, après que le premier appel au sous-programme extérieur est terminé, les sous-programmes intérieur et extérieur ne partageront plus de valeur commune pour la variable. En d'autres termes, la variable ne sera plus partagée.
- De plus, si le sous-programme extérieur est anonyme et fait référence à une variable lexicale en dehors de lui-même, alors les sous-programmes intérieur et extérieur ne partageront jamais la variable donnée.
- Le problème peut habituellement être résolu en rendant anonyme le sous-programme intérieur, en utilisant la syntaxe sub
{}. Lorsque des sous-programmes anonymes intérieurs, faisant référence à des variables dans des sous-programmes extérieurs, sont appelés ou référencés, ils sont automatiquement reliés à la valeur courante de ces variables.
Variable syntax
- (Syntaxe de variable)
- (A) Vous avez lancé accidentellement votre script via csh au lieu de Perl. Vérifiez la ligne
#!ou lancez vous-même votre script manuellement dans Perl avec perl nom_script.
Version number must be a constant number
- (Le numéro de version doit être un nombre constant)
- (P) La tentative de conversion d'une instruction use Module n.n LISTE vers le bloc BEGIN équivalent a trouvé une incohérence interne dans le numéro de version.
perl: warning: Setting locale failed.
- (perl : avertissement : Échec avec la configuration des locales)
-
(S) Le message d'avertissement complet ressemblera quelque peu à :
Sélectionnezperl: warning: Setting locale failed. perl: warning: Please check that your locale settings: LC_ALL="Fr_FR", LANG=(unset) are supportedandinstalled on yoursystem. perl: warning: Falling back to the standard locale ("C").N.d.T. :Sélectionnezperl : avertissement : Échec avec la configuration des locales. perl : avertissement : Merci de vérifier que votre configuration des locales : LC_ALL="Fr_FR", LANG=(non configuré) soit supportée et installée sur votre système. perl : avertissement : Retour aux locales standards ("C"). - (La configuration des locales qui a échoué variera.) Cette erreur indique que Perl a détecté que vous ou votre administrateur système avez configuré les variables du système ainsi nommées, mais Perl n'a pas pu utiliser cette configuration. Ce n'est pas mortel, heureusement : il existe une locale par défaut appelée « C » que Perl peut et va utiliser pour le script puisse ainsi fonctionner. Mais avant que vous résolviez vraiment ce problème, vous allez toutefois avoir le même message d'erreur à chaque fois que vous lancerez Perl. La manière de vraiment résoudre le problème peut être trouvée dans perllocale(1), à la section « Locale Problems ».
Warning: something's wrong
- (Avertissement : quelque chose s'est mal passé)
- (W) Vous avez passé à
warnune chaîne vide (l'équivalent d'unwarn"") ou vous l'avez appelé sans arguments et$_était vide.
Warning: unable to close filehandle %s properly
- (Avertissement : incapable de fermer proprement le handle de fichier
%s) - (S) Le
closeimplicite effectué par unopena reçu une indication d'erreur sur leclose. Cela indique habituellement que votre système de fichier a épuisé l'espace disque disponible.
Warning: Use of "%s" without parentheses is ambiguous
- (Avertissement : L'utilisation de "
%s" sans parenthèses est ambiguë) -
(S ambiguous) Vous avez écrit un opérateur unaire suivi par quelque chose ressemblant à un opérateur binaire, mais pouvant également être interprété comme un terme ou un opérateur unaire. Par exemple, si vous savez que la fonction
randa un argument par défaut valant1.0et que vous écrivez :Sélectionnezrand+5; -
vous pouvez pensez que vous avez écrit la même chose que :
Sélectionnezrand()+5; -
alors qu'en fait vous avez obtenu :
Sélectionnezrand(+5); - Donc mettez des parenthèses pour dire ce que vous voulez vraiment dire.
write() on closed filehandle
- (
write() sur un handle de fichier fermé) - (W closed) Le handle de fichier dans lequel vous écrivez s'est retrouvé fermé un moment auparavant. Vérifiez le flux logique de votre programme.
X outside of string
- (X en dehors d'une chaîne)
- (F) Vous aviez un canevas pour
packspécifiant une position relative avant le début de la chaîne en train d'être dépaqueté.
x outside of string
- (
xen dehors d'une chaîne) - (F) Vous aviez un canevas pour
packspécifiant une position relative après la fin de la chaîne en train d'être dépaqueté.
Xsub "%s" called in sort
- (Xsub "
%s" appelé dans unsort) - (F) L'utilisation d'un sous-programme externe pour la comparaison d'un
sortn'est pas encore supportée.
Xsub called in sort
- (Xsub "
%s" appelé dans unsort) - (F) L'utilisation d'un sous-programme externe pour la comparaison d'un
sortn'est pas encore supportée.
You can't use -l on a filehandle
- (Vous ne pouvez pas utiliser
-l sur un handle de fichier) - (F) Un handle de fichier représente un fichier ouvert et lorsque vous avez ouvert le fichier, il avait déjà passé tous les liens symboliques que vous essayez vraisemblablement de rechercher. Utilisez plutôt un nom de fichier.
YOU HAVEN'T DISABLED SET-ID SCRIPTS IN THE KERNEL YET!
- (VOUS N'AVEZ TOUJOURS PAS DÉSACTIVÉ LES SCRIPTS SET-ID DANS LE NOYAU !)
- (F) Et vous ne le ferez probablement jamais, car vous n'avez pas les sources du noyau et probablement que votre fabricant se moque éperdument de ce que vous voulez. La meilleure solution est de mettre une surcouche setuid en C autour de votre script en utilisant le script wrapsuid situé dans le répertoire eg de la distribution Perl.
You need to quote "%s"
- (Vous devez protéger "
%s" avec des guillemets ou des apostrophes) - (W syntax) Vous avez affecté un mot simple comme nom d'un gestionnaire de signaux. Malheureusement, vous avez déjà un sous-programme avec ce nom, ce qui veut dire que Perl 5 essayera d'appeler ce sous-programme lorsque l'affectation sera exécutée, ce qui n'est probablement pas ce que vous voulez. (Si c'est bien ce que vous voulez, mettez une & devant.)
