


II. Séance de dissection▲
2. Composants de Perl▲
Où nous étudions les éléments de l'ensemble.
Dans les prochains chapitres, nous progresserons du particulier vers le général, approche ascendante, en commençant par décrire les composants élémentaires qui permettront d'aborder les structures plus élaborées, un peu à la manière dont les atomes forment les molécules. L'inconvénient est que vous n'en aurez pas nécessairement une image globale sans auparavant avoir été submergé par de nombreux détails, mais l'avantage est que vous comprendrez les exemples au fur et à mesure. (si vous préférez l'approche inverse, retournez le livre et lisez ce chapitre à l'envers).
Chaque chapitre est construit sur le précédent ce qui nécessite une lecture linéaire, (vous devrez donc faire attention si vous êtes du genre à sautiller d'une page à l'autre).
Vous êtes invité à utiliser les différentes annexes à la fin du livre. (Ce qui n'est pas du sautillement.) Chaque mot distingué par une police type se trouve au chapitre 29, Fonctions. Bien que nous avons essayé de ne pas privilégier un système d'exploitation, si vous êtes peu au courant de la terminologie Unix et si vous rencontrez un mot qui semble dire autre chose que ce que vous pensez, reportez-vous au glossaire. Si cela ne marche pas, essayez l'index.
2-1. Atomes▲
Le plus petit élément visible du langage est le caractère, celui que l'on peut visualiser dans un éditeur par exemple. Au départ, Perl ne faisait pas la distinction entre octets et caractères ASCII, mais pour des raisons d'internationalisation, il faut bien distinguer les deux.
Le code Perl peut être écrit exclusivement en ASCII, mais autorise aussi l'utilisation d'un codage sur 8 ou 16 bits, qu'il soit celui d'une langue ou bien de tout autre codage défini régulièrement, à condition de le faire dans des chaînes litérales uniquement. Bien sûr, Perl ne vérifiera pas le contenu du texte, mais saura simplement qu'un caractère est codé sur 16 bits.
Comme expliqué au chapitre 15, Unicode, Perl implémente Unicode.(35) C'est transparent pour l'utilisateur du langage qui peut en utiliser aussi bien dans des identificateurs (noms de variables, etc.) que dans des chaînes litérales. Pour Perl, tous les caractères ont la même taille de référence, par exemple 1, quelle que soit la représentation interne qu'il en fait ensuite. En principe, il code les caractères sous forme UTF-8 et donc un caractère peut avoir une forme interne sur 1, 2, 3... octets. (L'Unicode smiley U-263A est une séquence de 3 octets.)
Mais poursuivons l'analogie physique un peu plus avant avec les atomes. Les caractères sont atomiques de la même façon que les atomes codent les différents éléments. Un caractère est composé de bits et d'octets, mais si on le désintègre (dans un accélérateur de caractères, sans doute), il perd toutes ses propriétés propres. De la même manière que les neutrons composent l'atome d'Uranium U-238, les octets qui composent le caractère smiley U-263A sont un détail de son implémentation.
Il faut donc bien distinguer le mot « caractère » du mot « octet ». C'est pourquoi on peut le préciser à l'interpréteur avec la directive use bytes. (Voir le chapitre 31, Modules de pragmas). De toute manière, Perl saura par lui-même faire le codage sur 8 bits quand il le faudra.
Maintenant, passons dans la prochaine dimension.
2-2. Molécules▲
Perl est un langage informel, ce qui ne veut pas dire qu'il n'a pas de forme, mais plutôt dans le sens usuel du terme, c'est-à-dire un langage qu'on peut écrire avec des espaces, tabulations et caractères de nouvelle ligne partout où vous voulez sauf dans les unités syntaxiques.
Par définition, un symbole ne contient pas d'espace. Un symbole est une unité syntaxique avec un sens pour l'interpréteur, comme pour un mot dans une phrase, mais qui peut contenir d'autres caractères que des lettres tant que cette unité n'est pas rompue. (Ce sont de vraies molécules qui peuvent utiliser toutes sortes d'atomes. Par exemple, les nombres et les opérateurs mathématiques sont des symboles. Un identificateur est un symbole qui débute par une lettre ou un souligné et qui ne contient que des lettres, chiffres ou soulignés. Un symbole ne peut contenir d'espace puisque le caractère espace couperait le symbole en deux nouveaux symboles, tout comme un caractère espace, en français couperait un mot en deux nouveaux mots.(36)
Bien que le caractère espace soit nécessaire entre deux symboles, les espaces ne sont obligatoires qu'entre deux symboles qui, sinon, seraient pris pour un seul. À cet effet, tous les espaces sont équivalents. Un commentaire est compté comme un espace. Les sauts de ligne ne sont différents des espaces qu'entre des délimiteurs, dans certains formats et pour des formes orientées ligne de protection. Plus précisément le caractère de saut de ligne ne délimite pas une instruction comme en FORTRAN ou en Python. Les instructions en Perl se terminent par le caractère « ; » comme en C.
Les caractères d'espace Unicode sont autorisés dans un programme Perl Unicode moyennant certaines précautions. Si vous utilisez les caractères spéciaux Unicode séparateurs de paragraphe et de ligne, d'une manière différente que ne le fait votre éditeur de texte, les messages d'erreur seront plus difficile à interpréter. C'est mieux d'utiliser les caractères de saut de ligne classiques.
Les symboles sont détectés d'une manière large ; l'interpréteur Perl lit le symbole le plus long possible lors de la lecture du code. Si vous voulez qu'il distingue deux symboles, il suffit d'insérer un espace blanc entre eux. (La tendance est d'insérer plusieurs espaces pour rendre le code plus lisible.)
Un commentaire commence par le caractère # et s'étend jusqu'à la fin de la ligne. Un commentaire équivaut à un espace et joue le rôle de séparateur. Perl n'interprète pas une ligne placée en commentaire.(37)
Si une ligne, et c'est une autre originalité lexicale, commence par = à un endroit où une instruction serait légale, Perl ignore tout de cette ligne jusqu'à la prochaine contenant =cut. Le texte ignoré est supposé être du POD, ou Plain Old Documentation (des programmes Perl permettent de convertir ces commentaires au format des pages de manuel, ou en documents , HTML et bientôt XML). D'une manière complémentaire, l'analyseur lexical extrait le code Perl d'un module et ignore les balises pod, ce qui permet de conserver la documentation à l'intérieur des modules. Voir le chapitre 26, POD, pour les détails sur pod et la documentation multiligne.
Mais seul le premier # est nécessaire, les autres ne sont que de la décoration, bien que la plupart des codeurs l'utilisent pour faire des effets visuels comme avec le langage C ou ils font une utilisation abondante du caractère *.
En Perl, comme en chimie ou en linguistique, on construit des structures de plus en complexes à partir d'éléments simples. Par exemple, une instruction est une séquence de symboles sur le mode impératif. On peut combiner une série d'instructions pour former un bloc délimité par des accolades. Les blocs peuvent eux-mêmes constituer d'autres blocs. Certains blocs fonctionnels tels que les sous-programmes peuvent être combinés en modules eux-mêmes combinés en programmes, nous verrons tout ceci dans les prochains chapitres. Mais créons encore des symboles avec nos caractères.
2-3. Types internes▲
Avant de construire des types plus complexes, nous devons introduire quelques abstractions, plus précisément trois types de données.
Chaque langage dispose de ses propres types de données et à la différence des autres, Perl en possède peu ce qui réduit les confusions possibles. Prenons par exemple le langage C qui dispose des types suivants : char, short, int, long, long long, bool, wchar_t, size_t, off_t, regex_t, uid_t, u_longlong_t, pthread_key_t, fp_exception_field_type, et ainsi de suite. Ce sont juste les types entiers! Il y a ensuite les nombres flottants, les pointeurs et les chaînes.
Tous ces types compliqués n'en font qu'un en Perl : le scalaire. (Les types simples de données sont suffisants pour les besoins usuels, et il est possible de créer ses propres types en utilisant la programmation objet en Perl, voir le chapitre 12, Objets.) Les trois types de base en Perl sont : les scalaires, les tableaux de scalaires et les hachages de scalaires (connus aussi sous le nom de tableaux associatifs). On peut aussi les appeler structures de données.
Les scalaires constituent le type fondamental à partir duquel les structures plus complexes peuvent être construites. Un scalaire peut contenir une seule valeur simple, typiquement une chaîne ou un nombre. Les éléments de ce type simple peuvent être combinés à l'intérieur des deux autres types composés. Un tableau est une liste ordonnée de scalaires accessibles par un indice numérique (les indices démarrent à zéro). Contrairement aux autres langages, Perl traite les indices négatifs en comptant à partir de la fin du type indexé — aussi bien des chaînes que des listes. Un hachage est un ensemble non ordonné de paires clef/valeur accessibles par une clef de type chaîne utilisée pour accéder à la valeur scalaire associée. Les variables ont toujours l'un de ces trois types. (À part les variables, Perl comprend des bidules plus ou moins confidentiels tels que des handles de fichiers et de répertoires, des sous-programmes, des typeglobs, des formats et des tables de symboles.)
Laissons la théorie et passons à la pratique du langage pour en voir les possibilités. Nous allons donc écrire du code et pour cela vous présenter les termes constituant les expressions en Perl régies par des règles syntaxiques. Nous utilisons la terminologie terme quand nous parlerons des unités syntaxiques, un peu comme dans les équations mathématiques.
La fonction des termes en Perl est de fournir des valeurs pour des opérateurs tels l'addition ou la multiplication. Mais à la différence d'une équation, Perl interprète l'expression dans une action logique de la machine. Une des actions les plus courantes est la sauvegarde d'une valeur en mémoire :
$x = $y;C'est un exemple de l'opérateur d'affectation (non pas l'opérateur de test d'égalité des valeurs numériques, ce qui s'écrit == en Perl). L'affectation prend la valeur de $y et la place dans la variable $x. Notez que le terme $x n'est pas utilisé pour sa valeur, mais pour sa fonction de mémorisation. (L'ancienne valeur de $x disparaît avec l'affectation.) Nous disons que $x est une lvalue, parce qu'elle est cible d'une affectation à gauche d'une expression. Et nous disons que $y est une rvalue car à droite dans ce type d'expression.
Il y a un troisième type de valeur appelée temporaire qu'il est nécessaire de comprendre. Considérons l'expression simple suivante :
$x=$y + 1;Perl prend la rvalue $y et lui ajoute la rvalue 1, ce qui produit une valeur temporaire qui est ensuite affectée à la lvalue $x. Ces valeurs temporaires sont placées dans une structure interne appelée pile.(38)
Les termes d'une expression empilent des valeurs, alors que ses opérateurs (dont nous parlerons dans le prochain chapitre) dépilent des valeurs et peuvent aussi empiler des résultats pour le prochain opérateur. Dans la pile, une expression produit autant de valeurs qu'elle en consomme. Nous reviendrons sur les valeurs temporaires.
Certains termes sont exclusivement des rvalues comme 1, certains autres peuvent jouer les deux rôles, comme la variable de l'exemple précédent nous l'a montré. C'est ce que nous allons voir dans la prochaine section.
2-4. Variables▲
Il y existe trois types de variables correspondant aux trois types abstraits mentionnés plus haut. Chacun d'eux est préfixé par un caractère spécial.(39) Les variables scalaires sont toujours définies avec un caractère $ initial, même si elles font référence à des scalaires à l'intérieur d'un tableau ou d'un hachage. Ce caractère fonctionne un peu comme l'article défini singulier (le ou la). Nous avons donc :
|
Construction |
Signification |
|---|---|
|
|
Valeur scalaire simple |
|
|
29e élément du tableau |
|
|
Valeur « Fev » du hachage |
Noter que vous pouvez utiliser le même nom pour $jours, @jours, et %jours, Perl ne les confondra pas.
Il existe d'autres caractères spéciaux qui s'appliquent sur les scalaires et sont utilisés dans des cas précis. Ils ressemblent à ceci :
|
Construction |
Signification |
|---|---|
|
|
Identique à |
|
|
Une autre variable |
|
|
Dernier index du tableau |
|
|
29e élément du tableau pointé par la référence |
|
|
Tableau multidimensionnel. |
|
|
Hachage multidimensionnel. |
|
|
Émulation de hachage multidimensionnel. |
Les tableaux ou les tranches de tableaux (ainsi que les tranches de hachage) débutent par le caractère @, qui fonctionne un peu comme l'article défini pluriel (les) :
|
Construction |
Signification |
|---|---|
|
|
équivaut à ( |
|
|
équivaut à ( |
|
|
équivaut à |
|
|
équivaut à ( |
équivaut à ($jours[0], $jours[1],... $jours[n]). équivaut à ($jours[3], $jours[4], $jours[5]). équivaut à @jours[3,4,5]. équivaut à ($jours{'jan'}, $jours{'fev'}).
Les hachages débutent par % :
|
Construction |
Signification |
|---|---|
|
|
|
Chacun de ces neuf exemples peut servir de lvalue, c'est-à-dire qu'ils spécifient une adresse à laquelle on peut, en autres choses, loger une valeur. Avec les tableaux, les hachages et les tranches de tableaux ou de hachages, la lvalue fournit un moyen simple d'affecter plusieurs valeurs d'un seul coup :
@days =1.. 7;2-5. Noms▲
Nous avons parlé de variables pour mémoriser des valeurs, mais il faut aussi mémoriser les noms et définitions de ces variables. En théorie, cela s'appelle des espaces de nommage. Perl dispose de deux sortes d'espaces de nommages : la table des symboles et les portées lexicales.(40) Il peut y avoir un nombre quelconque de tables et de portées lexicales et l'intersection des deux ensembles est nulle, pour chaque instance de l'interpréteur Perl. Nous détaillerons chacun de ces types tout au long de cet ouvrage. Disons simplement pour le moment que les tables de symboles sont des hachages à portée globale qui contiennent la table des symboles des variables globales (y compris les hachages des autres tables de symboles). A contrario, les portées lexicales sont des espaces anonymes non inclus dans une table, mais liés à un bloc de code du programme courant. Ils contiennent des variables accessibles uniquement dans le bloc en cours. (C'est pourquoi on utilise le terme portée.) Le mot lexical veut dire relatif au bloc de texte courant (ce qui n'a rien à voir avec ce qu'un lexicographe entend par là. Ne vous fâchez pas.).
Dans chaque espace de nommage, global ou lexical, chaque type de variable dispose de son propre sous-espace de nommage déterminé par le caractère spécial affecté au type. Il est possible, sans risque de conflit, d'utiliser le même nom pour une variable scalaire, un tableau ou un hachage (ou encore, pour un handle de fichier, un nom de sous-programme, un label ou votre lama familier). Cela signifie que $machin et @machin sont deux variables différentes. Cela veut aussi dire que $machin[1] est un élément de @machin et non une partie de $machin. Bizarre, vous avez dit bizarre ? Mais c'est normal, bizarrement.
Pour l'appel d'un sous-programme le caractère & est facultatif. Généralement un nom de sous-programme n'est pas une lvalue, quoique dans les versions récentes de Perl un sous-programme peut s'évaluer à une lvalue de telle sorte que l'on peut lui affecter une valeur en retour.
Parfois on veut accéder aux variables d'un symbole donné, « sym » par exemple. Il suffit d'utiliser le caractère spécial * où l'astérisque indique tout type de variable (scalaire, tableau, hachage). On les appelle typeglobs ; ils ont plusieurs fonctions. Ils peuvent être utilisés comme lvalues. L'importation des modules se fait par l'affectation des typeglobs. Nous reviendrons sur ce thème plus tard.
Perl, comme tout langage informatique, dispose d'une liste de mots réservés qu'il reconnaît comme termes spéciaux. Cependant, les noms de variables commençant par un caractère spécial, il n'y a pas de confusion possible avec les premiers. D'autres types de noms ne commencent pas par ces caractères : les descripteurs de fichiers et les étiquettes. Avec ceux-ci attention à ne pas entrer en conflit avec des mots réservés. Nous vous recommandons pour ces types, d'utiliser des majuscules pour leurs noms. Par exemple, si vous écrivez open(LOG, logfile) plutôt que le regrettable open(log, "logfile"). Perl comprendra que vous ne parlez pas de la fonction log et des logarithmes,(41) et prévient les futurs conflits avec les nouvelles versions de Perl. Le nom des modules utilisateurs commence avec une majuscule alors que les modules pragmas prédéfinis sont écrits en minuscules. Quand nous aborderons la programmation orientée objet, vous verrez que les noms de classes sont en capitales pour la même raison.
Comme vous pouvez le déduire du précédent paragraphe, la casse est importante dans les identificateurs — TRUC, Truc, et truc sont trois noms différents en Perl. Un identificateur commence avec une lettre ou un souligné, il peut contenir des lettres et des chiffres, y compris les caractères Unicode, et peut avoir une longueur comprise entre 1 et 251 inclus. Les idéogrammes Unicode sont des lettres, mais nous vous déconseillons de les utiliser si vous ne savez pas les lire. Voir le chapitre 15.
Les noms qui suivent ces caractères spéciaux ne sont pas nécessairement des identificateurs. Ils peuvent commencer par un chiffre auquel cas l'identificateur ne peut contenir que des chiffres comme dans $123. Les noms qui commencent par tout autre caractère qu'une lettre, un chiffre ou souligné (comme $? ou $$), sont limités à ce caractère et sont prédéfinis en Perl. Par exemple $$ est l'ID du processus courant et $? est l'indicateur d'état retourné par le dernier processus fils créé.
Dans la version 5.6 de Perl est implémentée une syntaxe extensible pour les noms de variable interne. Toute variable de la forme ${^NAME} est une variable spéciale réservée par Perl. Tous ces noms spéciaux sont dans la table principale de symboles. Voir le chapitre 28, Noms spéciaux, pour les exemples.
On pourrait penser que noms et identificateurs désignent la même chose, mais lorsqu'on parle de nom, c'est du nom absolu qu'il s'agit, c'est-à-dire celui qui indique à quelle table de symboles il appartient. De tels noms sont formés par une série d'identificateurs séparés par le symbole :: :
$Doc::Aide::Perl::Classe::chameauCe qui fonctionne comme un nom absolu de fichier :
/Doc/Aide/Perl/Classe/chameauEn Perl, ce chemin absolu indique les tables de symboles imbriquées, et le dernier identificateur est le nom de la variable elle-même, contenu dans la dernière table imbriquée. Par exemple, pour la variable de l'exemple précédent, la table de symboles se nomme Doc::Aide::Perl::Classe, et le nom de la variable dans cette table est $chameau. (la valeur de cette variable est bien entendu « beige ».)
Une table de symboles en Perl se nomme aussi un paquetage. Donc ces variables sont aussi appelées variables de paquetage. Les variables de paquetage sont dites privées relativement à leur paquetage, mais sont globales dans le sens où les paquetages sont eux-mêmes globaux, c'est-à-dire qu'il suffit de nommer le paquetage pour y accéder, ce qui est difficile à faire par inadvertance. Par exemple, un programme qui référence $Doc::categorie demande la variable $categorie dans le paquetage Doc::, qui n'a rien à voir avec la variable $Livre::categorie. Voir le chapitre 10, Paquetages.
Les variables attachées à une portée lexicale ne sont pas contenues dans un paquetage, et ne contiennent pas la séquence ::. (Les variables à portée lexicale sont déclarées avec my.)
2-5-a. Recherche des noms▲
La question est donc comment Perl devine le chemin absolu d'un nom ? Comment trouve-t-il par exemple le nom de $categorie ? Voici les étapes successives suivies par l'interpréteur Perl dans la phase de lecture du code, pour résoudre les noms dans le contexte courant :
- Premièrement, Perl inspecte le bloc immédiatement contenant, pour une déclaration du type my (ou our) (Voir le chapitre 29, ainsi que la section Déclarations avec portée au chapitre 4, Instructions et déclarations). S'il trouve cette déclaration, alors la variable est à portée lexicale et n'existe dans aucun — elle existe uniquement dans le bloc courant. Une portée lexicale est anonyme et ne peut donc être atteinte hors du bloc la contenant.(42)
- S'il ne trouve pas, Perl cherche une variable à portée lexicale dans le bloc contenant le précédent et s'il la trouve, il la marque comme appartenant à ce bloc de niveau supérieur. À noter que dans ce cas, sa portée comprend le bloc de la première étape. Dans le cas inverse, il répète cette deuxième étape jusqu'à la sortie du bloc racine, le plus grand contenant les précédents.
- Quand il n'y a plus de blocs contenants, l'interpréteur examine l'unité de compilation entière, ce qui peut être le fichier entier ou la chaîne en cours de compilation dans le cas de l'expression eval CHAINE. Dans ce dernier cas, la portée lexicale est la chaîne elle-même et non un bloc entre accolades. Si Perl ne trouve pas la variable dans la portée lexicale de la chaîne, il considère qu'il n'y a plus de bloc et retourne à l'étape 2 en partant de la portée lexicale du bloc eval STRING.
- À ce point, Perl n'a pas encore trouvé de déclaration pour notre variable (ni my, ni our). Perl abandonne la recherche d'une variable lexicale, et suppose que la variable recherchée est une variable de paquetage. Le degré suivant de recherche est donc le paquetage. Si la directive strict est active, le compilateur provoque une erreur, (sauf si la variable est prédéfinie ou importée dans le paquetage courant), car il ne peut exister de variable globale sans qualifiant. Il cherche la déclaration package toujours dans la portée lexicale, et s'il la trouve, insère le nom du paquetage trouvé au début de la variable.
- S'il ne trouve pas de déclaration de paquetage dans la portée lexicale, Perl recherche la variable dans le paquetage main qui contient tous les autres. En l'absence de déclaration contraire,
$categorieveut dire$::categorie, qui veut dire$main::categorie.(main étant un paquetage dans le paquetage de plus haut niveau, cela veut aussi dire$::main::categorie ou encore$main::main::categorie et$::main::main::categorie et ainsi de suite. On en verra toute l'utilité dans Tables de symboles au chapitre 10.)
Il y a plusieurs conséquences que nous devons souligner ici :
- Le fichier étant la plus grande portée lexicale, une variable à portée lexicale ne peut être vue en dehors du fichier dans lequel elle est déclarée. Les portées de fichier ne sont pas imbriquées.
- Tout code Perl compilé appartient à au moins une portée lexicale et exactement un paquetage. La portée obligatoire est le fichier de code lui-même. Les blocs contenant définissent les portées successives. Tout code Perl est compilé dans un paquetage exactement, et si la déclaration du paquetage a une portée lexicale, le paquetage n'en a pas, il est global.
- Une variable sans qualifiant peut être cherchée dans différentes portées lexicales, mais dans un seul paquetage, qui est le paquetage actif (déterminé par la portée lexicale de la variable).
- Un nom de variable ne peut avoir qu'une portée. Bien que deux portées sont actives au même moment (lexicale et paquetage), une variable ne peut exister que dans une seule à la fois.
- Un nom de variable sans qualifiant ne peut exister que dans une place mémoire, soit dans la première portée lexicale, soit dans le paquetage courant, mais pas les deux.
- La recherche s'arrête dès que la place mémoire est trouvée, et les autres places mémoire qui auraient été trouvées si la recherche s'était poursuivie, ces places mémoire donc sont néanmoins inaccessibles.
- La place mémoire d'une variable typique peut être complètement déterminée à la compilation.
Maintenant on sait comment le compilateur Perl résoud les noms, mais parfois on ne connaît pas ce nom au moment de la compilation : par exemple dans le cas d'une indirection. Dans ce cas, Perl fournit un mécanisme qui permet de remplacer une variable par une expression qui retourne une référence à cette variable. Par exemple, au lieu de dire :
$categorie
vous diriez :
${ une_expression() }
et si la fonction une_expression() retourne une référence à la variable $categorie (ou bien la chaîne "categorie"), cela fonctionne de la même manière. Par contre, si la fonction retourne $thesaurus ce sera cette variable à la place. Cette syntaxe est la plus générale (et la moins lisible) des formes d'indirection, mais nous verrons des variantes plus pratiques au chapitre 8, Références.
2-6. Valeurs scalaires▲
Qu'il soit référencé directement ou indirectement, dans une variable, un tableau ou bien une variable temporaire, un scalaire contient toujours une valeur simple qui peut être un nombre, une chaîne ou une référence à une autre donnée. Il peut aussi n'avoir aucune valeur auquel cas il est dit indéfini. Les scalaires sont sans type, même s'ils peuvent référencer toutes sortes de données : il n'est pas nécessaire de les déclarer.(43)
Perl mémorise les chaînes comme des séquences de caractères sans contrainte de longueur ni de contenu. Nul besoin de déclarer une taille à l'avance et tout caractère peut y être inclus, y compris le caractère nul. Les nombres sont représentés sous forme d'entiers signés si possible, ou bien sous forme de nombres à virgule flottante en double précision dans le format natif de la machine. Les valeurs flottantes ne sont pas infiniment précises, c'est pourquoi certaines comparaisons de la forme (10/3 == 1/3*10) échouent mystérieusement.
Perl convertit les scalaires en différents sous-types suivant les besoins ; le numérique peut être traité comme du caractère et inversement, Perl faisant Ce Qu'il Faut. Pour convertir du caractère en numérique, Perl utilise la fonction C atof(3). Pour passer du numérique à une chaîne de caractères, il fait l'équivalent de sprintf(3) avec le format "%.14g" sur la plupart des machines. La conversion d'une chaîne non numérique comme truc convertit le literal à la valeur 0 ; s'ils sont actifs, les avertissements sont affichés sinon rien. Voir le chapitre 5, pour des exemples permettant d'identifier le contenu d'une chaîne.
Alors que les chaînes de caractères et les numériques sont interchangeables dans à peu près tous les cas, les références sont d'un genre différent. Elles sont fortement typées, ce sont des pointeurs non convertibles (transtypables) comprenant des compteurs de références et des invocations de destructeurs internes. Ils sont utilisables pour créer des types de données complexes, incluant vos propres objets. Ceci dit, les références restent des scalaires, car ce qui importe n'est pas tant la complexité d'une structure que le fait de la considérer comme un simple scalaire.
Par non convertibles, nous voulons dire que l'on ne peut pas, par exemple, convertir une référence de tableau en une référence de hachage. Les références ne sont pas convertibles en un autre type pointeur. Cependant, en utilisant une référence en numérique ou en caractère, on obtient une valeur numérique ou une chaîne de caractères, ce qui permet de se souvenir du caractère unique d'une référence, même si le « référencement » de la valeur est perdu au cours de la copie depuis la vraie référence. On peut comparer différentes références ou tester si elles sont définies. Mais on ne peut en faire beaucoup plus puisqu'il n'existe pas de moyen de convertir du numérique ou du caractère en référence. En principe, si Perl n'oblige pas à faire de l'arithmétique de pointeurs — ou carrément l'interdit —, ce n'est pas un problème. Voir le chapitre 8 pour en connaître plus sur les références.
2-6-a. Littéraux numériques▲
Les littéraux numériques sont spécifiés par n'importe quel format courant(44) de virgule flottante ou d'entier :
$x = 12345; # entier
$x = 12345.67; # virgule flottante
$x = 6.02E23; # notation scientifique
$x = 4_294_967_296; # souligné pour la lisibilité
$x = 0377; # octal
$x = 0xffff; # hexadécimal
$x = 0b1100_0000; # binaireComme Perl utilise la virgule comme séparateur de liste, elle ne peut servir comme séparateur des milliers pour les grands nombres. Pour améliorer leur lisibilité, Perl permet d'utiliser à la place le caractère souligné. Celui-ci ne fonctionne qu'avec des constantes numériques définies dans le programme, et non pour les chaînes de caractères traitées comme du numérique ou pour les données externes lues par ailleurs. De même, les caractères initiaux 0x en hexadécimal et 0 en octal marchent uniquement avec les constantes. La conversion automatique d'une chaîne en un nombre ne reconnaît pas ces préfixes — vous devez faire une conversion explicite(45) avec la fonction oct (qui marche aussi pour les données hexadécimales à condition d'indiquer 0x ou 0b au début).
2-6-b. Chaînes littérales▲
Les littéraux alphanumériques sont habituellement délimités par des apostrophes simples ou doubles. Ils fonctionnent un peu comme les quotes (les délimiteurs de protection) sous UNIX : les apostrophes doubles permettent une interpolation des antislashs et des variables, les apostrophes simples non. (\ et \\ permettent d'inclure un antislash dans une chaîne entre apostrophes simples). Si vous voulez inclure toute autre séquence telle que \n (saut de ligne), vous devez utiliser les apostrophes doubles. (Les séquences antislashs sont des séquences d'échappement, car elles permettent d'« échapper » temporairement à l'interprétation normale des caractères.)
Une chaîne entre apostrophes simples doit être séparée du mot précédent par un espace, car ce caractère est valide — mais archaïque — dans un identificateur. On utilise plutôt la séquence :: plus visuelle : $main'var et $main::var représentent la même variable, la deuxième étant beaucoup plus lisible.
Les chaînes entre guillemets permettent l'interpolation de différents types de caractères bien connus dans les autres langages. Ils sont listés au tableau 2-1.
|
Code |
Signification |
|---|---|
|
\n |
Saut de ligne (généralement LF). |
|
\r |
Retour chariot (généralement CR). |
|
\t |
Tabulation horizontale. |
|
\f |
Saut de page. |
|
\b |
Retour arrière. |
|
\a |
Alerte (bip). |
|
\e |
Caractère ESC. |
|
\ |
ESC en octal. |
|
\x7f |
DEL en hexadécimal. |
|
\cC |
Control-C. |
|
\ |
Unicode (smiley). |
|
\N |
Caractère nommé. |
La notation \N{NOM} est utilisée avec la directive use charnames décrite au chapitre 31. Cette notation permet d'utiliser les noms symboliques comme \N{GREEK SMALL LETTER SIGMA}, \N{greek:Sigma}, ou \N{sigma} — suivant la directive utilisée. Voir aussi le chapitre 15.
Il existe de plus des séquences d'échappement pour modifier la casse des caractères qui suivent. Voir le tableau 2-2.
|
Code |
Signification |
|---|---|
|
\u |
Force le caractère suivant en majuscule (« titlecase » en Unicode). |
|
\l |
Force le caractère suivant en minuscule. |
|
\U |
Force tous les caractères suivants en majuscules. |
|
\L |
Force tous les caractères suivants en minuscules. |
|
\Q |
Préfixe avec antislash tous les caractères non alphanumériques. |
|
\E |
Fin de \U, \L, ou \Q. |
Il est aussi possible d'insérer le caractère de saut de ligne dans une chaîne qui peut donc s'étendre sur plus d'une ligne. Ceci peut être utile, mais aussi dangereux si vous oubliez un guillemet, auquel cas l'erreur sera annoncée à la prochaine occurrence de guillemet qui peut se trouver beaucoup plus loin dans votre fichier source. Heureusement ceci provoque immédiatement une erreur de syntaxe sur la même ligne, et Perl est suffisamment futé pour vous avertir qu'il s'agit peut-être d'une chaîne qui n'est pas terminée au bon endroit, et de plus il vous indique la ligne où la chaîne a dû commencer.
Parallèlement aux séquences d'échappement ci-dessus, les chaînes entre doubles apostrophes permettent une interpolation des variables scalaires et des listes de valeurs. Cela signifie que les valeurs de certaines variables peuvent être directement insérées dans une chaîne. C'est en fait une forme pratique de concaténation de chaîne.(46) L'interpolation ne peut être effectuée que pour des variables scalaires, la totalité d'un tableau (mais pas d'un hachage), des éléments unitaires d'un tableau ou d'un hachage, ou enfin, des tranches (des sélections multiples d'éléments) de tableaux ou de hachages. En d'autres termes, seules les expressions commençant par $ ou @ peuvent être interpolées, car ce sont les deux caractères (avec l'antislash) que l'analyseur de chaîne recherche. À l'intérieur d'une chaîne, un caractère @ ne faisant pas partie de l'identifiant d'un tableau ou d'un hachage doit être inclus dans une séquence d'échappement avec un antislash (@), sous peine d'une erreur de compilation. Bien qu'un hachage complet spécifié par % ne puisse être interpolé dans une chaîne, un élément ou une sélection multiples d'éléments d'un hachage peuvent l'être, car ils commencent respectivement par les caractères $ et @.
Le bout de code suivant affiche "Le prix est de $100.".
$Prix = '$100'; # non interpolé
print "Le prix est de $Prix.\n"; # interpoléComme dans certains shells, les accolades autour d'un identifiant permettent de le différencier des autres caractères alphanumériques : "How ${verb}able!". En fait un identifiant entre accolades est forcément interprété en chaîne, comme les chaînes clefs d'un hachage. Par exemple,
$jours{'fev'}peut aussi être écrit :
$jours{fev}et les apostrophes sont censées être automatiquement présentes. Mais toute chose plus complexe dans l'indice sera interprétée comme une expression.
et vous devriez les mettre entre guillemets simples :
En particulier, il est nécessaire d'utiliser les simples guillemets dans les tranches de tableau :
@jours{'Jan','Fev'} # Ok.
@jours{"Jan","Fev"} # Ok aussi.
@jours{ Jan, Fev } # erreur si la directive use strict est activeExceptés les indices de tableaux interpolés ou de hachages, il n'existe pas de niveaux multiples d'interpolation. En particulier, contrairement aux attentes de nombreux programmeurs shell, les apostrophes inverses ne permettent pas d'interpoler à l'intérieur d'apostrophes doubles. De même, les apostrophes simples ne permettent pas d'empêcher l'évaluation de variables à l'intérieur d'apostrophes doubles. L'interpolation est très puissante, mais d'un contrôle strict en Perl. Elle ne se produit que dans les guillemets et certaines opérations que nous décrirons dans la prochaine section.
print "\n"; # Ok, imprime un saut de ligne.
print \n ; # MAUVAIS, pas de contexte d'interpolation.2-6-c. Choisissez vos délimiteurs▲
Alors que l'on ne considère souvent les délimiteurs que comme des constantes, ils fonctionnent plus comme des opérateurs avec Perl, permettant plusieurs formes d'interpolation et de correspondance de motifs. Perl fournit des délimiteurs spécifiques pour ces fonctions, mais offre également le moyen de choisir un délimiteur pour chacune. Au tableau 2-3, on peut utiliser tout caractère autre qu'alphanumérique ou d'espace comme délimiteur à la place de /. (Les caractères saut de ligne et d'espace ne sont plus admis dans les nouvelles versions de Perl.)
|
Habituelle |
Générique |
Signification |
Interpolation |
|---|---|---|---|
|
|
|
chaîne littérale |
non |
|
|
|
chaîne littérale |
oui |
|
|
|
exécution de commande |
oui |
|
() |
|
liste de mots |
non |
|
|
m |
recherche de motif |
oui |
|
s |
s |
substitution de motif |
oui |
|
y |
tr |
traduction |
non |
|
|
|
expression rationnelle |
oui |
Certains, ci-dessus, sont uniquement des formes de « sucre syntaxique » ; ils évitent d'alourdir une chaîne avec trop d'antislashs, en particulier dans les expressions régulières où slash et antislash se côtoient.
Si vous utilisez les guillemets simples comme délimiteurs, aucune interpolation de variable ne sera faite (même si le tableau ci-dessus indique « oui »). Si le délimiteur ouvrant est un crochet, une parenthèse, une accolade ou le signe inférieur, le délimiteur fermant doit lui correspondre (les occurrences de délimiteurs doivent correspondre par paires). Par exemple :
$simple = q!Je dis "Tu dis, 'Elle l'a dit.'"!;
$double = qq(On ne peut pas avoir une "bonne" $variable?);
$bout_de_code = q {
if ($condition) {
print "Pris!";
}
};Le dernier exemple montre qu'il est possible d'utiliser le caractère espace entre l'opérateur de protection et le délimiteur. Pour les constructions à deux éléments, comme s/// et tr///, si la première paire de délimiteurs est une accolade, la seconde partie peut en utiliser un autre : on peut écrire s<foo>(bar) ou tr(a-f)[A-F]. Les espaces sont autorisés entre les deux paires de délimiteurs, ainsi le dernier exemple peut s'écrire :
tr [a-z]
[A-Z];Les caractères espace sont toutefois interdits lorsque le délimiteur est #. q#foo# est lu comme 'foo', alors que q #foo# est lu comme l'opérateur q suivi d'un commentaire. Le délimiteur sera pris sur la ligne suivante. Les commentaires peuvent être placés au milieu d'une construction à deux éléments, ce qui permet d'écrire :
s {foo} # Remplacer foo
{bar}; # par bar.
tr [a-f] # Translittération de minuscule hexa
[A-F]; # vers majuscule hexa2-6-d. Ou n'en mettez pas du tout▲
Un mot qui n'a pas d'interprétation dans la grammaire sera traité comme s'il était dans une chaîne protégée. Ce sont les mots simples.(47) Comme pour les handles de fichier et les labels, un mot simple entièrement en minuscules risque d'entrer en conflit avec un futur mot réservé. Si vous utilisez l'option -w, Perl vous avertira de ce risque. Par exemple :
@jours = (Lun,Mar,Mer,Jeu,Ven);
print STDOUT Salut, ' ', monde, "\n";stocke dans le tableau @jours les abréviations des jours de la semaine et affiche « Salut tout le monde » suivi d'un saut de ligne sur STDOUT. En ôtant le handle de fichier, Perl essaiera d'interpréter Salut comme un handle de fichier avec à la clef une erreur de syntaxe. C'est tellement source d'erreur que certains voudront déclarer hors la loi les mots simples. Les opérateurs de protection listés ci-avant ont d'autres formes y compris l'opérateur « quote words » qw// qui opère sur une liste de mots séparés par des espaces :
@jours = qw(Lun Mar Mer Jeu Ven);
print STDOUT "Salut, tout le monde\n";Vous pouvez aussi bannir les mots simples de votre code. Si on écrit :
alors tout mot simple qui n'est pas interprété comme un appel à un sous-programme produit à la place une erreur de compilation. Cette restriction dure jusqu'à la fin du bloc qui la contient. Un autre bloc peut l'annuler par
Il faut remarquer que les identifiants dans des constructions telles que :
"${verb}able"
$jours{Fév}ne sont pas considérés comme des mots simples, car ils sont autorisés par une règle explicite plutôt que par le fait de « ne pas avoir d'interprétation dans la grammaire ».
Un nom simple avec :: en fin, tel que main:: ou bien Chameau:: est toujours considéré comme un nom de paquetage. Perl transforme Chameau:: en chaîne « Chameau » au moment de la compilation, et ne sera pas rejeté par la directive use strict.
2-6-e. Interpolation des tableaux▲
Les variables tableau sont interpolées dans une chaîne entre doubles apostrophes en réunissant tous leurs éléments avec le délimiteur spécifié dans la variable $"(48) l'espace sera pris par défaut. Les exemples suivants sont équivalents :
$temp = join($",@ARGV);
print $temp;
print "@ARGV";À l'intérieur des motifs de recherche (qui comprend aussi une interpolation identique à celle des doubles guillemets) il existe une ambiguïté déplaisante : /$machin[chose]/ est-il interprété comme /${machin}[chose]/ (où [chose] est une classe de caractères pour l'expression) ou comme /${machin[chose]}/ (où [chose] est l'indice du tableau @machin) ? Si @machin n'existe pas, c'est bien sûr une classe de caractères. Si @machin existe, Perl devinera [chose], presque toujours à bon escient.(49) S'il décrypte mal, ou si vous êtes paranoïaque, des accolades permettent de forcer l'interprétation correcte comme ci-dessus. Et même si vous êtes simplement prudent, ce n'est pas une mauvaise idée.
2-6-f. Documents « ici même »▲
Un format de séparation orienté ligne est basé sur la syntaxe des documents « ici même » (« here » documents) du shell(50) Après les caractères <<, on saisit une chaîne destinée à terminer la partie à délimiter, toutes les lignes suivant la ligne courante jusqu'à la chaîne de terminaison étant délimitées. La chaîne de terminaison peut être un identifiant (un mot) comme du texte délimité. Dans ce cas, le type de délimiteur utilisé détermine le traitement du texte, comme en délimitation standard. Un identifiant non délimité fonctionne comme des apostrophes doubles. Il ne doit pas y avoir d'espace entre les caractères << et l'identifiant (un espace est traité comme un identifiant nul, ce qui est valable, mais pas recommandé, et correspond avec la première ligne vide ; voir le premier exemple Hourra~! plus loin). La chaîne de terminaison doit apparaître en tant que telle (sans délimiteurs et non entourée d'espaces) sur la dernière ligne.
print <<EOF; # même exemple que précédemment
Le prix est $Prix.
EOF
print <<"EOF"; # même exemple qu'au-dessus avec des apostrophes
# doubles explicites
Le prix est $Prix.
EOF
print <<'EOF'; # avec des apostrophes simples
Tout est possible (par exemple le passage d'un chameau par le chas
d'une aiguille), c'est vrai. Mais imaginez l'état du chameau,
déformé en un long fil sanglant de la tête aux pieds.
--C.S. Lewis
EOF
print << x 10; # affiche la ligne suivante 10 fois
Les chameaux débarquent! Ho u rra! Hourra!
print <<"" x 10; # La même chose, en mieux
Les chameaux débarquent! Ho u rra! Hourra!
print <<`EOC`; # exécute les commandes
echo comment vas-tu
echo yau de poêle?
EOC
print <<"dromadaire", <<"camelide"; # on peut les empiler
Je dis bactriane.
dromadaire
Elle dit lama.
camelideN'oubliez quand même pas de mettre un point virgule à la fin pour finir la phrase, car Perl ne sait pas que vous n'allez pas essayer de faire ceci :
print <<ABC
179231
ABC
+ 20; # affiche 179251Si vous voulez indenter vos documents « ici même » avec votre code, il faut enlever les espaces devant chaque ligne manuellement :
($quote = <<'QUOTE') =~ s/^\s+//gm;
The Road goes ever on and on,
down from the door where it began.
QUOTEIl est aussi possible d'instancier un tableau avec les lignes d'un document « ici même » comme suit :
@sauces = <<fin_lignes =~ m/(\S.*\S)/g;
tomate normale
tomate épicée
chili vert
pesto
vin blanc
fin_lignes2-6-g. Litéral V-chaîne▲
Un litéral qui commence avec un v suivi d'un ou plusieurs entiers séparés par des points est traduit en chaîne dont chaque atome a pour valeur ordinale chaque entier.
$crlf = v13.10; # valeur ASCII: retour chariot, saut de ligneLe terme v-chaîne est une contraction de « vecteur-chaîne » ou « version de chaîne ». Il fournit une alternative plus cohérente pour construire une chaîne à partir des valeurs numériques de chaque caractère. Par exemple, il est plus facile d'écrire v1.20.300.4000 plutôt que :
"\x{1}\x{14}\x{12c}\x{fa0}"
pack("U*", 1, 20, 300, 4000)
chr(1) . chr(20) . chr(300) . chr(4000)Si un tel littéral est composé de deux ou trois points (au moins trois entiers), le préfixe v peut être omis.
print v9786; # affiche le caractère UTF-8 SMILEY, "\x{263a}"
print v102.111.111; # affiche "foo"
print 102.111.111; # idem
use 5.6.0; # nécessite au moins cette version de Perl
$ipaddr = 204.148.40.9; # l'addresse IP de oreilly.comLes v-chaînes sont pratiques pour représenter les adresses IP ou les numéros de version. En particulier avec le codage de caractères sur plus d'un octet qui devient courant de nos jours, on peut comparer les numéros de version de toute taille avec les v-chaînes.
Les numéros de version et les adresses IP ne sont pas très lisibles sous la forme de v-chaînes. Pour obtenir une chaîne affichable, utilisez l'option v dans un masque avec printf, par exemple dans "%vd", tel que décrit au chapitre 29. Pour en savoir plus sur les chaînes Unicode, voir le chapitre 15, ainsi que la directive use bytes au chapitre 31 ; pour la comparaison des versions avec les opérateurs de comparaison de chaîne, voir $^V au chapitre 28 ; et pour la représentation des adresses IPv4, voir gethostbyaddr au chapitre 29.
2-6-h. Autres symboles littéraux▲
Tout symbole préfixé par deux caractères « souligné » et postfixé de même est réservé pour un usage spécial par Perl. Deux mots spéciaux, à savoir __LINE__ et __FILE__, représentent le numéro de la ligne courante et le fichier à ce stade du programme. Ils ne peuvent être utilisés que comme des mots séparés ; ils ne sont pas interpolés dans les chaînes. De la même manière, __PACKAGE__ est le nom du paquetage courant de compilation. S'il n'existe pas, ce qui est le cas lorsque la directive package; est vide, __PACKAGE__ vaut undef. Le symbole __END__, ou les caractères Control-D ou Control-Z, peuvent être utilisés pour indiquer la fin logique du script courant avant la fin physique du fichier. Tout caractère suivant est ignoré par le lecteur Perl, mais peut être lu via le descripteur spécial DATA.
__DATA__ fonctionne de la même façon que __END__, mais ouvre le handle de fichier DATA à l'intérieur de l'espace de nom du paquetage courant, ce qui fait que si vous insérez plusieurs fichiers par require, chacun peut disposer de son handle DATA personnel et l'ouvrir sans conflit avec les autres. Pour en savoir plus, voir DATA au chapitre 28.
2-7. Contexte▲
Jusqu'à présent, nous avons vu un certain nombre de termes pouvant produire des valeurs scalaires. Avant d'en voir davantage, nous devons aborder la notion de contexte.
2-7-a. Contexte scalaire et contexte de liste▲
Chaque opération(51) d'un script Perl est évaluée dans un contexte spécifique, et la façon dont l'opération se comportera peut dépendre des contraintes de ce contexte. Il existe deux contextes majeurs : les scalaires et les listes. Par exemple, l'affectation d'une variable scalaire évalue la partie droite dans un contexte scalaire :
$x = fonction(); # contexte scalaire
$x[1] = fonction(); # contexte scalaire
$x{"ray"} = fonction(); # contexte scalaireMais l'affectation d'un tableau ou d'un hachage (ou d'une tranche de ceux-ci) évalue la partie droite dans un contexte de liste. L'affectation d'une liste de scalaire se fera aussi par un contexte de liste pour la partie droite.
@x = fonction(); # contexte de liste
@x[1] = fonction(); # id
@x{"ray"} = fonction(); # id
%x = fonction(); # idL'affectation à une liste de scalaires fournit aussi un contexte de liste en rvalue, même s'il n'y a qu'un seul élément dans la liste produite :
($x,$y,$z) = fonction(); # contexte de liste
($x) = fonction(); # idCes règles sont inchangées quand la variable est déclarée avec les termes my ou our, ainsi nous avons :
my $x = fonction(); # contexte scalaire
my @x = fonction(); # contexte de liste
my %x = fonction(); # id
my ($x) = fonction(); # idVous aurez beaucoup de problèmes jusqu'au jour où vous aurez compris la différence entre le contexte scalaire et le contexte de liste, car certains opérateurs (telle notre fonction imaginaire fonction()), connaissent leur contexte de retour et typent leur valeur de retour en conséquence. (Ce comportement sera toujours signalé quand c'est le cas.) En langage informatique, on dit que les opérateurs ont leur type de retour surchargé par le contexte d'affectation. Il s'agit de la surcharge la plus simple basée sur deux types simples, le scalaire et la liste.
Si certains opérateurs répondent suivant le contexte, c'est parce que quelque chose indique son type scalaire ou liste. L'affectation se comporte comme une fonction qui fournit à son opérande de droite le contexte. On a besoin de savoir quel opérateur fournit quel contexte pour ses opérandes. Toutes les fonctions avec un contexte de liste, ont le terme LISTE dans leur description. Celles qui ne l'ont pas ont un scalaire. C'est en général assez intuitif.(52) Au besoin, on peut forcer un contexte scalaire au milieu d'un contexte de LISTE en utilisant la pseudo-fonction scalar. (Perl ne fournit pas le moyen de forcer un contexte de liste en contexte scalaire, car partout où un contexte de liste est prévu, ceci est déjà indiqué par le contexte LISTE de certaines fonctions de contrôle.)
Le contexte scalaire peut ensuite être classé en contexte de chaînes, numériques ou contexte tolérant. À la différence de la distinction entre scalaire et liste que nous venons de faire, les opérations ne savent jamais quel type de contexte scalaire elles ont en entrée. Elles se contentent de renvoyer le type de valeur scalaire qu'elles désirent et laissent Perl traduire les numériques en chaîne dans un contexte de chaîne, et les chaînes en nombres dans un contexte numérique. Certains contextes scalaires se moquent de savoir si une chaîne ou un numérique est retourné, ce qui fait qu'aucune conversion ne sera effectuée. (Cela arrive, par exemple, lorsqu'on affecte une valeur à une autre variable. Celle-ci prend simplement le même sous-type que l'ancienne valeur.)
2-7-b. Contexte booléen▲
Le contexte booléen est un contexte scalaire particulier. Il correspond à l'endroit où une expression est évaluée pour savoir si elle est à vrai ou à faux. Parfois nous écrivons Vrai ou Faux à la place de la définition technique utilisée par Perl : une valeur scalaire est à vrai si ce n'est pas une chaîne nulle ou le nombre 0 (ou sa chaîne équivalente : "0"). Les références sont toujours vraies. Une référence est toujours vraie, car c'est une adresse physique jamais nulle. Une valeur indéfinie, appelée undef, est toujours fausse, car elle vaut, suivant le contexte, "" ou 0. (Les listes n'ont pas de valeur booléenne, car elles ne sont jamais produites dans un contexte scalaire !)
Puisque le contexte booléen est un contexte tolérant, il n'entraîne aucune conversion ; à noter que c'est un contexte scalaire, et tout opérande pour lequel c'est nécessaire sera converti en scalaire. Et pour tout opérande le nécessitant, le scalaire retourné dans un contexte scalaire est une valeur booléenne possible, ce qui signifie par exemple qu'un opérateur retournant une liste, peut être utilisé dans un test booléen : la fonction unlink qui opère dans un contexte de liste, peut utiliser un argument de type array :
unlink @liste_fichiers; # détruit chaque fichier de la liste.Maintenant, utilisons le tableau dans une condition (donc contexte booléen), alors le tableau retourne sa cardinalité, car il sait que c'est un contexte scalaire ; cette valeur est vraie tant qu'il reste des éléments dans le tableau. Supposons alors que nous voulons vérifier que les fichiers ont été supprimés correctement, on écrirait :
while (@liste_fichiers) {
my $fichier = shift @liste_fichiers;
unlink $fichier or warn "Ne peut pas supprimer $fichier: $!\n";
}Ici @liste_fichier est évaluée dans le contexte booléen induit par la boucle while, de telle sorte que Perl évalue le tableau pour voir si sa valeur est vraie ou fausse. Cette valeur est vraie tant que la liste contient des éléments et devient fausse dès que le dernier élément est enlevé (par l'opérateur shift). Notez que la liste n'est pas évaluée dans un contexte scalaire. Nous indiquons au tableau qu'il est scalaire et lui demandons ce qu'il vaut dans ce contexte.
N'essayez pas d'utiliser defined @files pour ce faire. La fonction defined regarde si le scalaire est égal à undef, et un tableau n'est pas un scalaire. Un simple test booléen suffit dans ce cas.
2-7-c. Contexte vide▲
Un autre type particulier des contextes scalaires est le contexte vide. Non seulement il se moque de la valeur à retourner, mais en plus il ne veut même pas de valeur de retour. Du point de vue du fonctionnement des fonctions, il n'est pas différent des autres contextes scalaires, mais par le switch -w de la ligne de commande, le compilateur Perl prévient de l'utilisation d'une expression sans effet secondaire à un endroit qui ne veut pas d'une valeur, comme dans une phrase qui ne renvoie pas de valeur. Par exemple, si une chaîne est employée comme phrase :
"Camel Lot";on peut obtenir un avertissement tel que :
Useless use of a constant in void context in monprog line 123;2-7-d. Contexte interpolatif▲
Nous avons déjà mentionné que les apostrophes doubles autour d'une chaîne permettent une interpolation des variables et une interprétation des antislashs, mais le contexte interpolatif (souvent appelé « contexte double quotes ») ne s'applique pas qu'aux chaînes entre doubles apostrophes. Les autres constructions à doubles quotes concernent l'opérateur général apostrophe inverse qx//, l'opérateur de recherche de motif m// et l'opérateur de substitution s/// et l'opérateur d'expression régulière qr//. En fait, l'opérateur de substitution fait une interpolation de sa partie gauche avant de faire la recherche de motif, puis à chaque motif trouvé fait une interpolation de sa partie droite.
Le contexte interpolatif n'intervient qu'entre apostrophes, ou pour des choses qui fonctionnent de la même façon, et il n'est donc peut-être pas vraiment correct de l'appeler contexte au même titre que les contextes scalaires ou les contextes de liste (ou peut-être bien que si).
2-8. Valeur de liste et tableaux▲
Maintenant que nous avons parlé des contextes, nous pouvons parler des listes de valeurs et de leur comportement dans les différents contextes. Nous avons déjà vu les listes de littéraux, définies en séparant chaque valeur par une virgule (et en encadrant la liste par une paire de parenthèses). Comme il n'est pas gênant (presque jamais) d'ajouter des parenthèses supplémentaires, la forme syntaxique d'une liste s'écrit :
(LISTE)Nous venons de voir que la forme LISTE indique un terme qui retourne une liste à son argument, mais une liste littérale simple est l'exception à cette règle en ce qu'elle fournit un contexte de liste uniquement quand la liste elle-même est dans un contexte de liste. La valeur d'une liste litérale dans un contexte de liste est simplement les valeurs de chaque élément séparées par une virgule dans l'ordre spécifié. Comme un terme dans une expression, une liste litérale empile simplement des valeurs temporaires sur la pile Perl, elles seront utilisées ensuite par l'opérateur qui attend cette liste.
Dans un contexte scalaire, la valeur d'une liste est la valeur de son dernier élément, comme avec l'opérateur virgule du C qui ignore toujours la valeur à gauche et renvoie celle de droite (en faisant référence à ce que nous disions plus haut, la partie à gauche de la virgule fournit un contexte vide). L'opérateur virgule étant associatif à gauche, une liste de valeurs séparées par des virgules fournit toujours le dernier élément, car la virgule oublie chaque valeur précédente. Par exemple :
@truc = ("un", "deux", "trois");affecte toute la liste de valeurs au tableau @truc, mais :
$truc = ("un", "deux", "trois");n'affecte que la valeur « trois » à la variable $truc. Comme pour le tableau @liste_fichiers, l'opérateur virgule sait s'il est dans un contexte scalaire ou de liste et adapte son comportement en conséquence.
C'est important de souligner qu'une liste est différente d'un tableau. Une variable tableau connaît aussi son contexte, et dans un contexte de liste retourne la liste de ses valeurs internes comme une liste littérale. Mais dans un contexte scalaire elle retourne simplement sa longueur. Le code suivant affecte la valeur 3 à la variable $truc :
@truc = ("un", "deux", "trois");
$truc = @truc;Si vous pensiez obtenir la valeur « trois », vous avez généralisé un peu vite, car en fait Perl a détecté le contexte scalaire et n'a empilé que la longueur du tableau. Aucun terme ou opérateur n'empilera des valeurs de liste dans un contexte scalaire. Il empilera une valeur scalaire, qui ne sera certainement pas la dernière valeur de la liste qu'il retournerait dans un contexte de liste, valeur scalaire qui est ici la longueur du tableau. Il faut bien comprendre cet exemple (sinon, relisez le paragraphe, car c'est important).
Retournons aux vraies LISTE, celles qui induisent un contexte de liste. Jusqu'à présent nous avons soutenu que le contexte LISTE ne contient que des littéraux. Mais en fait, toute expression qui retourne une valeur peut être utilisée à l'intérieur d'une liste. Les valeurs ainsi utilisées peuvent être des valeurs scalaires ou des listes de valeurs. Le contexte LISTE fait automatiquement une interpolation des sous-listes. C'est pourquoi, lorsqu'un contexte LISTE est évalué, chaque élément de la liste est évalué dans ce contexte et la valeur de la liste résultante est interpolée dans LISTE comme si chaque élément individuel était un membre de LISTE. Les tableaux perdent ainsi leur identité dans LISTE. La liste :
(@machin,@chose,&sousProgramme)contient tous les éléments de @machin, suivis de tous les éléments de @chose, suivis de tous les éléments renvoyés par le sous-programme sousProgramme lorsqu'il est appelé dans un contexte de liste. Notez que si l'un quelconque des éléments est nul, son interpolation ne compte pas. La liste nulle est représentée par (). Son interpolation dans une liste n'a pas d'effet. Ainsi ((),(),()) est équivalent à (). De même, l'interpolation d'un tableau sans élément donne, à ce stade, la même chose que s'il n'avait pas été interpolé.
Une conséquence est que l'on peut mettre une virgule optionnelle à la fin de toute liste. Ceci facilitera ultérieurement les ajouts d'éléments.
@nombres = (
1,
2,
3,
);Le mot qw, que nous avons mentionné plus tôt, permet aussi d'entrer une liste littérale. Il construit quelque chose d'équivalent à une chaîne entre apostrophes éclatée sur plusieurs lignes. Par exemple :
@machin = qw(
pomme banane carambole
orange goyave kumquat
mandarine nectarine pêche
poire persimmon prune
);Remarquez que ces parenthèses ne sont pas ordinaires et fonctionnent comme des apostrophes. On aurait pu aussi mettre des signes inférieur-supérieur, des accolades ou des slashs (mais les parenthèses c'est joli).
Une liste de valeurs peut aussi être indicée comme un tableau standard. Vous devez alors mettre la liste entre parenthèses (des vraies) pour éviter toute ambiguïté. Si cela sert souvent pour obtenir une valeur du tableau, c'est aussi une tranche de la liste et la forme syntaxique s'écrit :
(LISTE)[LISTE]Exemples :
# Stat renvoie une valeur liste.
$modification_time = (stat($fichier))[8];
# ERREUR DE SYNTAXE ICI.
$modification_time = stat($fichier)[8]; # OUPS, PAS DE PARENTHESES
# Trouver un chiffre hexa.
$chiffrehexa = ('a','b','c','d','e','f')[$chiffre-10];
# Un "opérateur virgule inverse".
return (pop(@machin),pop(@machin))[0];
# Affectation de plusieurs valeurs à l'aide d'une tranche.
($jour, $mois, $annee) = (localtime)[3,4,5];2-8-a. Affectation de liste▲
Une liste est affectée si chacun de ses éléments est affecté :
($a, $b, $c) = (1, 2, 3);
($map{rouge}, $map{vert}, $map{bleu}) = (0xff0000, 0x00ff00, 0x0000ff);Il est possible d'affecter à undef dans une liste. C'est utile pour ignorer certaines valeurs de retour d'une fonction :
($dev, $ino, undef, undef, $uid, $gid) = stat($fichier);L'élément final d'une liste peut être un tableau ou un hachage :
($a, $b, @reste) = split;
my ($a, $b, %reste) = @arg_list;Vous pouvez mettre un tableau ou un hachage dans la liste affectée en sachant que le premier de ce type rencontré absorbera les valeurs restantes et les variables restantes seront initialisées à undef. Ceci peut être utile dans une initialisation de type my ou local, où on veut que les tableaux soient vides.
Il est aussi possible d'affecter une liste vide :
() = fonction_bidon();De cette façon, la fonction est appelée dans un contexte de liste, mais on laisse tomber les valeurs renvoyées. Si vous aviez fait l'appel sans affectation, la fonction aurait été évaluée dans un contexte vide, qui est un contexte scalaire, et se serait comportée complètement différemment.
L'affectation de liste dans un contexte scalaire retourne le nombre d'éléments que fournit la partie droite de l'affectation :
$x = ( ($machin,$truc) = (7,7,7) ); # $x contient 3, pas 2
$x = ( ($machin,$truc) = f() ); # $x contient le nombre d'éléments de f()
$x = ( () = f() ); # idemC'est pratique lorsqu'on veut faire l'affectation d'une liste dans un contexte booléen, car la plupart des fonctions liste retournent une liste nulle lorsqu'elles se terminent, valeur qui affectée à un scalaire produit la valeur 0 qui vaut faux dans ce contexte. Voici un exemple d'utilisation dans une boucle while :
2-8-b. Longueur d'un tableau▲
Le nombre d'éléments du tableau @jours est donné par l'évaluation de @jours dans un contexte scalaire :
@jours + 0; # force implicitement @jours dans un contexte scalaire
scalar(@jours) # force explicitement @jours dans un contexte scalaireAttention, cela ne fonctionne que pour les tableaux. Cela ne fonctionne pas pour les listes de valeurs en général. Une liste avec des virgules comme séparateur évaluée dans un contexte scalaire retournera la dernière valeur, comme l'opérateur virgule en C. Mais puisqu'il n'est presque jamais nécessaire de connaître la longueur d'une liste en Perl ce n'est pas un problème.
$#jours est très proche de l'évaluation scalaire de @jours. Cette dernière renvoie l'indice du dernier élément du tableau, ou un de moins que la longueur puisqu'il existe (habituellement) un élément d'indice zéro. L'affectation de $#jours change la longueur du tableau. Raccourcir un tableau de la sorte détruit les valeurs intermédiaires. Vous pouvez être plus efficace en surdimensionnant à l'avance un tableau destiné à s'agrandir (pour agrandir un tableau, on peut lui affecter un élément au-delà de sa fin). Un tableau peut être tronqué par l'affectation de la liste nulle (). Les deux instructions suivantes sont équivalentes :
@nimportequoi = ();
$#nimportequoi = -1;Et celle qui suit est toujours vraie :
scalar(@nimportequoi) == $#nimportequoi + 1;La troncation d'un tableau ne récupère pas la mémoire ainsi libérée. Il faut faire un undef(@nimportequoi) pour récupérer sa mémoire dans le processus courant. Vous ne pouvez vraisemblablement pas la retourner au système d'exploitation, car peu de systèmes en sont capables.
2-9. Hachages▲
Comme nous l'avons déjà dit, un hachage n'est qu'un type spécial de tableau dans lequel on retrouve les valeurs par une chaîne-clef au lieu d'un indice numérique. En fait, on définit des associations entre les clefs et les valeurs, et c'est pourquoi les hachages sont souvent appelés tableaux associatifs par les personnes assez courageuses pour taper sur un clavier.
Il n'existe pas vraiment de syntaxe particulière aux hachages en Perl, mais si une liste ordinaire est affectée à un hachage, chaque paire de valeurs de la liste sera prise comme une association clef/valeur.
%map = ('rouge',0xff000,'vert',0x00ff00,'bleu',0x0000ff);Ce qui a le même effet que :
%map = (); # d'abord initialiser le hachage
$map{rouge} = 0xff0000;
$map{vert} = 0x00ff00;
$map{bleu} = 0x0000ff;Il est souvent plus lisible d'utiliser l'opérateur => entre la clef et sa valeur. L'opérateur => est synonyme de la virgule, mais il est plus clair visuellement et permet aussi une séparation d' identifiant à gauche (comme les identifiants entre accolades ci-dessus) ; l'initialisation des variables hachages devient plus simple :
%map = (
rouge => 0xff0000,
vert => 0x00fff0,
bleu => 0x0000ff,
);ou pour initialiser des références banalisées de hachage utilisées comme des enregistrements :
$rec = {
NOM => 'John Smith'
GRADE => 'Captain'
MATRICULE => '951413',
};ou pour utiliser des appels complexes de fonctions par un nom :
$field = $query->radio_group(
NOM => 'group_name',
VALEURS => ['eenie','meenie','minie'],
DEFAUT => 'meenie',
SAUTDELIGNE => 'true',
LABELS => %labels,
);Mais n'allons pas trop vite. Revenons à nos hachages.
Une variable hachage (%hachage) peut être utilisée dans un contexte de liste, toutes ses paires clef/valeurs étant interpolées dans la liste. Mais ce n'est pas parce que le hachage a été initialisé dans un certain ordre que les valeurs sont retournées dans le même. Les hachages sont implémentés au niveau interne en utilisant des tables de hachage pour une recherche rapide, ce qui signifie que l'ordre dans lequel les données sont stockées dépend du type de fonction de hachage utilisée pour déterminer la place de la paire clef/valeur. Ainsi, les entrées sont apparemment retournées dans un ordre quelconque (au niveau d'une paire clef/valeur, les deux éléments sont bien sûr rendus dans le bon ordre). Pour des exemples de réordonnancement en sortie, voir la fonction keys au chapitre 29.
Si un hachage est évalué dans un contexte scalaire, une valeur vraie est renvoyée si et seulement si le hachage contient des paires clef/valeur. (S'il existe plusieurs paires, la valeur renvoyée est une chaîne contenant le nombre de cellules utilisées (buckets) et le nombre de cellules allouées, séparés par un slash. Ceci n'est utile que pour savoir si l'algorithme résident de Perl traite correctement ou non l'ensemble de données. Par exemple, on entre 10 000 éléments dans un hachage, mais l'évaluation de %HASH dans un contexte scalaire révèle « 1/8 », cela signifie que seulement une des 8 cellules a été touchée, et qu'elle contient probablement les 10 000 éléments. Ce n'est pas censé se produire.
Pour trouver le nombre de clefs dans un hachage, utilisez la fonction keys dans un contexte scalaire : scalar(keys(%HASH)).
Il est possible d'émuler un tableau multidimensionnel en spécifiant plus d'une clef dans les accolades séparées par une virgule. Les clefs listées sont concaténées ensemble séparées par le caractère $; ($SUBSCRIPT_SEPARATOR) qui a la valeur chr(28) par défaut. La clef résultante devient une clef du hachage. Ces deux lignes font la même chose :
$habitants{ $pays, $département } = $résultat_recensement;
$habitants{ join $; =>; $pays, $département } = $résultat_recensement;Cette fonctionnalité fut à l'origine implémentée pour le traducteur a2p (awk vers perl). Aujourd'hui, vous utiliseriez plus justement un tableau multidimensionnel comme il est décrit au chapitre 9, Structures de données. Un usage encore pratique de cet ancien style est la liaison des hachages aux fichiers DBM (voir DB_File au chapitre 32, Modules standards), qui n'implémentent pas les clefs multidimensionnelles.
Ne confondez pas l'émulation multidimensionnelle des hachages avec les tranches de tableaux. L'un est une valeur scalaire, l'autre représente une liste :
$hachage{ $x, $y, $z } # une valeur simple
@hachage{ $x, $y, $z } # une tranche de trois valeurs2-10. Typeglobs et handles de fichiers▲
Perl utilise un type spécial appelé typeglob qui contient la table des types Perl pour ce symbole. (La table des symboles *foo contient les valeurs de $foo, @foo, %foo, &foo et d'autres interprétations de foo.) Le préfixe de typage d'un typeglob est *, car il représente tous les types.
Les typeglobs (ou leurs références) sont toujours utilisés pour passer ou stocker des handles de fichier. Pour sauvegarder un handle de fichier il faut taper :
$fh = *STDOUT;ou comme une vraie référence, de cette manière :
$fh = \*STDOUT;C'est aussi le moyen de créer un handle de fichier local. Par exemple :
sub newopen {
my $path = shift;
local *FH; # et non my ou our!
open (FH, $path) || return undef;
return *FH; # et non \*FH!
}
$fh = newopen('/etc./passwd');Voir la fonction open pour générer d'autres handles de fichiers.
Cependant, la principale utilisation des typeglobs est actuellement de servir d'alias entre deux entrées symboliques. C'est comme un surnom. Si on écrit
*machin = $truc; tout ce qui s'appelle « machin », est synonyme de tout ce qui s'appelle « truc ». L'alias peut porter sur un seul type des variables du nom en affectant une référence :
*machin = $truc;$machin devient alias de $truc, mais @machin n'est pas synonyme de @truc, ni %machin de %truc. Tout ceci ne concerne que les variables globales, c'est-à-dire définies dans un paquetage ; les variables lexicales ne peuvent être accédées à travers la table des symboles. Le mécanisme d'import/export est entièrement basé sur ce principe, l'alias ne présuppose en effet aucune appartenance à un module spécifique. Cette instruction :
local *Ici::bleu = \$Ailleurs::vert;fait de $Ici::bleu un alias pour $Ailleurs::vert, mais ne fait pas de @Ici::bleu un alias pour @Ailleurs::vert, ni %Ici::bleu un alias pour %Ailleurs;::vert. Heureusement, toutes ces manipulations compliquées de typeglobs sont transparentes la plupart du temps. Voir le chapitre 8, et Tables de symboles au chapitre 10 et le chapitre 11, Modules, pour un développement sur ces sujets.
2-11. Opérateurs d'entrée▲
Nous allons maintenant présenter plusieurs opérateurs d'entrée qui sont analysés comme des termes. En fait, on les appelle parfois des pseudo-littéraux, car ils agissent, dans bien des cas, comme des chaînes protégées (les opérateurs de sortie comme print fonctionnent comme des opérateurs de liste et sont traités au chapitre 29.)
2-11-a. Opérateur d'exécution de commande (Backtick)▲
Premièrement il y a l'opérateur de ligne de commande, aussi appelé opérateur backtick, et qui ressemble à ceci :
$info = `finger $user`;Une chaîne protégée par des apostrophes inverses procède tout d'abord à une interpolation des variables comme dans une chaîne entre apostrophes doubles. Le résultat est alors interprété comme une commande par le shell, et la sortie de la commande devient la valeur de l'identifiant (ceci fonctionne comme certains opérateurs similaires des shells UNIX). Dans un contexte scalaire, le résultat est une chaîne simple contenant toutes les sorties de la commande. Dans un contexte de liste, une liste de valeurs est renvoyée, une pour chaque ligne sortie par la commande. (On peut utiliser $/ pour avoir un autre caractère de terminaison de ligne.)
La commande est interprétée chaque fois que l'identifiant est évalué. La valeur numérique du statut de la commande est stockée dans $? (voir le chapitre 28 pour l'interprétation de $?, connu aussi sous le nom de $CHILD_ERROR). À la différence de csh, aucune transformation n'est faite sur les données renvoyées ; les sauts de ligne restent des sauts de ligne. À l'inverse de tous les shells, les apostrophes simples n'empêchent pas l'interprétation des noms de variables. Pour passer un $ au shell il faut le cacher par un antislash. Le $user de notre exemple ci-dessus est interpolé par Perl, mais non par le shell (la commande lançant un processus shell, consultez le chapitre 23, Sécurité, pour les problèmes de sécurité).
La forme généralisée pour les apostrophes inverses est qx// (pour quoted execution, exécution protégée), mais l'opérateur fonctionne exactement de la même façon que les apostrophes inverses ordinaires. Il suffit de choisir ses caractères de protection. Comme avec les pseudo-fonctions de protection, si vous choisissez un simple guillemet comme délimiteur, la chaîne de commande n'est pas interpolée :
$perl_info = qx(ps $$); # Variable $$ de Perl
$shell_info = qx'ps $$'; # Variable $$ du shell2-11-b. Opérateur de lecture de ligne (Angle)▲
L'opérateur de lecture de ligne est l'opérateur le plus utilisé, aussi connu sous le nom d'opérateur inférieur-supérieur, ou fonction readline. L'évaluation d'un handle de fichier entre inférieur-supérieur (par exemple <STDIN>) donne la ligne suivante du fichier associé. Le saut de ligne est inclus, donc en accord avec les critères de véracité de Perl, chaque ligne lue a une valeur vrai, et lorsque le programme atteint la fin du fichier, l'opérateur angle retourne undef, c'est-à-dire faux. On affecte d'habitude la valeur lue à une variable, mais il existe un cas où une affectation automatique se produit. Si, et seulement si, l'opérateur de lecture de ligne est la seule chose présente dans le test de boucle d'un while, la valeur est automatiquement affectée à la variable spéciale $_. La valeur affectée est alors testée pour savoir si elle est définie (cela peut vous paraître idiot, mais vous utiliserez cette construction dans presque tous vos scripts Perl). Bref, les lignes suivantes sont toutes équivalentes :
while (defined($_ = <STDIN>)) { print $_; } # méthode longue
while ($_ = <STDIN>) { print; } # utilise $_ explicitement
while (<STDIN>) { print; } # méthode courte
for (;<STDIN>;) { print; } # boucle while déguisée
print $_ while defined($_ = <STDIN>); # instruction modifiée longue
print while $_ = <STDIN>; # utilise $_
print while <STDIN>; # instruction modifiée courteSouvenez-vous que cette astuce requiert une boucle while. Si vous utilisez l'opérateur ailleurs, vous devez affecter le résultat explicitement pour garder la valeur.
while (<FH1> && <FH2>) {...} # mauvais : perd les deux entrées
if (<STDIN>) { print; } # mauvais, affiche l'ancienne
# valeur de $_
if ($_ = <STDIN>) { print; } # ne teste pas si $_ est défini
if (defined($_ = <STDIN>)) { print; } # meilleurQuand la variable $_ est implicitement affectée dans une boucle, c'est la variable globale dont il s'agit. Vous pouvez protéger la valeur de $_ de la manière suivante :
L'ancienne valeur est rétablie à la sortie de la boucle. $_ peut toujours être accédée depuis la boucle. Pour éviter toute confusion, il est préférable d'utiliser une variable lexicale :
(Ces deux boucles while testent si l'affectation est defined, car my et local ne changent pas son comportement habituel.) Les handles de fichiers STDIN, STDOUT et STDERR sont prédéfinis et ouverts. D'autres handles peuvent être créés avec les fonctions open ou sysopen. Voir la documentation de ces fonctions au chapitre 29 pour les détails.
Dans la boucle while ci-dessus, la ligne d'entrée est évaluée dans un contexte scalaire, chaque valeur est retournée séparément. Si on l'utilise dans un contexte de liste, une liste de toutes les lignes d'entrée restantes est retournée, chaque ligne étant un élément de liste. Un important espace de données peut ainsi être créé, et il faut donc l'utiliser avec précaution :
$une_ligne = <MYFILE>; # Donne la première ligne.
@toutes_lignes = <MYFILE>; # Donne le reste des lignes.Il n'existe pas de magie particulière pour le while associé à la forme liste de l'opérateur d'entrée, car la condition d'une boucle while est toujours un contexte scalaire (comme toutes les conditions).
L'utilisation du handle de fichier nul à l'intérieur de l'opérateur inférieur-supérieur (ou opérateur angle) est particulière et peut être utilisée pour émuler la ligne de commande de programmes standards d'UNIX tels que sed et awk. Quand on lit les lignes depuis <>, toutes les lignes de tous les fichiers mentionnés sur la ligne de commande sont renvoyées. Si aucun fichier n'était spécifié, c'est l'entrée standard qui est renvoyée à la place et le programme peut ainsi être facilement inséré entre des processus pour former un pipe.
Voici comment cela fonctionne : la première fois que <> est évalué, le tableau @ARGV est contrôlé, et s'il est nul, $ARGV[0] est mis à« -», qui donne l'entrée standard quand on l'ouvre. Le tableau @ARGV est traité comme une liste de noms de fichiers. La boucle
while (<>) {
... # code pour chacune des lignes
}est équivalente au pseudo-code Perl suivant :
while (@ARGV and $ARGV[0] =~ /^-/) {
$_=shift;
last if /^--$/;
if (/^-D(.*)/) { $debug = $1 }
if (/^-V/) { $verbose++ }
... # autres alternatives
}
while (<>) {
... # du code dans chaque ligne
}à part une meilleure lisibilité, le résultat reste identique. Le tableau @ARGV est décalé et le nom du fichier courant est stocké dans la variable $ARGV. Le handle de fichier ARGV est aussi utilisé en interne ; <> est simplement un synonyme de <ARGV>, qui est magique (le pseudo-code ci-dessus ne fonctionne pas parce qu'il traite <ARGV> comme non-magique).
Il est possible de modifier @ARGV avant l'instruction <> du moment que le tableau est construit avec les noms de fichier que vous attendez. Le nom de fichier « -» qui représente l'entrée standard, peut être ouvert avec la fonction open, ainsi que des flux plus ésotériques comme « gzip -dc < file.gz| »). Les numéros de ligne ($.) s'incrémentent comme s'il n'existe qu'un fichier en entrée. (Mais observez l'exemple ci-dessous sur eof pour voir comment on réinitialise les numéros de ligne à chaque fichier.)
Pour affecter @ARGV à une liste de fichiers, c'est direct :
# par défaut: le fichier README si aucun argument n'est donné
@ARGV = ("README") unless @ARGV;Pour passer des options dans un script, on peut utiliser un des modules Getopt ou mettre une boucle initiale telle que :
while ($_ = $ARGV[0], /^-/) {
shift;
last if /^--$/;
if (/^-D(.*)/) { $debug = $1 }
if (/^-v/) { $verbose++ }
... # autres options
}
while (<>) {
... # code pour chacune des lignes
}Le symbole <> ne renvoie faux qu'une seule fois. En cas d'appel ultérieur, une autre liste @ARGV est supposée être traitée, et si @ARGV n'est pas initialisé les lectures se font depuis STDIN.
Si la chaîne entre l'opérateur angle est une variable (par exemple, <$machin>), alors celle-ci contient le nom du fichier à lire ou une référence à celui-ci. Par exemple :
$fh = \*STDIN;
$ligne = <$fh>;ou :
open($fh, "<donnees.txt>");
$line = "<$fh>";2-11-c. Opérateur de globalisation des noms de fichier▲
Vous vous souciez peut-être de ce qui peut arriver à un opérateur de lecture de ligne si vous mettez quelque chose de bizarre entre l'inférieur et le supérieur. Il est alors transformé en un opérateur différent. Si la chaîne à l'intérieur de l'opérateur angle est différente du nom d'un handle de fichier ou d'une variable scalaire (même s'il agit d'espace), elle sera interprétée comme étant un motif de fichier à « globaliser ».(53) Le motif de recherche s'applique aux fichiers du répertoire courant (ou dans le répertoire spécifié dans le motif glob lui-même), et les fichiers correspondants sont retournés par l'opérateur. Comme pour les lectures de ligne, les noms sont renvoyés un à un dans un contexte scalaire, ou tous à la fois dans un contexte de liste. Ce dernier usage est en fait prédominant. Il est courant de voir :
my @fichiers = <*.xml>;Comme pour d'autres types de pseudo-constantes, un premier niveau d'interpolation est effectué, mais on ne peut pas écrire <$machin>, car il s'agit d'un handle de fichier indirect, comme nous l'avons déjà vu. Dans d'anciennes versions de Perl, les programmeurs inséraient des accolades pour forcer une interprétation de nom de fichier glob : <${machin}>. De nos jours, on considère qu'il est plus propre d'appeler la fonction interne directement par glob($machin), ce qui aurait dû être le cas dès l'origine. On écrirait donc :
@fichiers = glob("*.xml");si vous préférez.
Que l'on utilise la fonction glob ou sa forme ancienne avec l'opérateur d'angle, l'opérateur de globalisation fonctionne de la même façon dans une boucle que l'opérateur while en affectant le résultat à $_. (Ce fut la première raison de surcharger cet opérateur.) Par exemple, si vous vouliez changer les autorisations de fichiers de code C, vous écririez :
while (glob "*.c") {
chmod 0644, $_;
}ce qui est équivalent à :
while (<*.c>) {
chmod 0644, $_;
}La fonction glob était implémentée comme une commande shell dans les anciennes versions de Perl (aussi dans les anciennes versions d'Unix), était plus coûteuse en ressources et ne fonctionnait pas de la même façon sur tous les systèmes. C'est aujourd'hui une fonction prédéfinie plus fiable et plus rapide. Voyez la description du module File::Glob au chapitre 32 pour modifier son comportement par défaut pour, par exemple, traiter les espaces dans ces arguments, l'expansion de certains caractères (tilde ou accolade), l'insensibilité à la casse ou bien le classement des valeurs retournées, entre autres choses.
Bien sûr, la façon la plus courte et la moins lisible pour faire la commande chmod ci-dessus, est d'utiliser la globalisation comme un opérateur sur liste :
chmod 0644, <*.c>;Un glob n'évalue son argument que quand il démarre une nouvelle liste. Toutes les valeurs doivent être lues avant son exécution. Dans un contexte de liste, ce n'est pas très important, puisqu'on les a toutes automatiquement. Mais dans un contexte scalaire, l'opérateur renvoie la prochaine valeur à chaque appel, ou une valeur fausse si on arrive au bout. Attention, faux n'est retourné qu'une seule fois. Ainsi, si l'on attend une valeur unique pour un glob, il vaut mieux écrire :
($fichier) = <blurch*>; # contexte de listeau lieu de :
$fichier = <blurch*>; # contexte scalairecar la première forme avale tous les noms de fichier correspondants et réinitialise l'opérateur, alors que ce que renvoie la seconde alterne entre un nom de fichier et faux.
Pour interpoler des variables, il faut absolument utiliser l'opérateur glob, car l'ancienne syntaxe peut être confondue avec la notation indirecte des handles de fichiers. Mais à ce niveau, il devient évident que la frontière entre les termes et les opérateurs est un peu floue.
@files = <$dir/*.[ch]>; # à éviter
@files = glob("$dir/*.[ch]"); # appelle glob en tant que fonction
@files = glob $un_motif; # appelle glob en tant qu'opérateurNous ne mettons pas les parenthèses dans le second exemple pour montrer que glob peut être utilisé comme un opérateur unaire, c'est-à-dire un opérateur préfixe avec un seul argument. L'opérateur glob est un exemple d'opérateur unaire défini, qui n'est qu'un des types d'opérateurs dont nous parlerons dans le prochain chapitre. Ensuite nous parlerons des opérations de recherche de motif, qui ressemblent elles aussi à des termes, mais fonctionnent comme des opérateurs.
3. Opérateurs unaires et binaires▲
Dans le chapitre précédent, nous avons parlé des différents types de termes que vous pouvez utiliser dans une expression. Mais pour être honnête, les termes isolés sont un peu ennuyeux. Beaucoup de termes sont de joyeux fêtards ; ils aiment communiquer les uns avec les autres. Un terme typique ressent une forte envie de s'identifier avec d'autres termes, ou de les influencer de différentes manières. Cependant, il existe de nombreuses sortes d'interactions sociales et de nombreux niveaux d'implication. En Perl, ces relations sont exprimées à l'aide d'opérateurs.
Il faut bien que la sociologie serve à quelque chose.
D'un point de vue mathématique, les opérateurs sont des fonctions ordinaires avec une syntaxe spéciale. D'un point de vue linguistique, les opérateurs sont juste des verbes du troisième groupe. Mais comme tout linguiste vous le dira, les verbes du troisième groupe sont généralement ceux que l'on utilise le plus souvent. C'est important du point de vue de la théorie de l'information, car les verbes du troisième groupe sont généralement plus courts et plus efficaces tant pour la production que pour la reconnaissance.
D'un point de vue pratique, les opérateurs sont maniables.
On distingue plusieurs variétés d'opérateurs, en fonction de leur arité (le nombre d'opérandes qu'ils prennent), leur précédence (leur capacité à prendre leurs opérandes aux opérateurs voisins), et leur associativité (agissent-ils de gauche à droite ou de droite à gauche quand ils sont associés à des opérateurs de même précédence).
Les opérateurs Perl se présentent sous trois arités : unaire, binaire ou ternaire. Les opérateurs unaires sont toujours des opérateurs préfixes (exceptés les opérateurs de post-incrémentation et de post-décrémentation).(54) Tous les autres sont des opérateurs infixes — à moins que vous ne comptiez les opérateurs de liste, qui peuvent précéder autant d'arguments que vous voulez. Cependant la plupart des gens préfèrent voir les opérateurs de liste comme des fonctions normales autour desquelles on peut oublier de mettre des parenthèses. Voici quelques exemples :
! $x # un opérateur unaire
$x * $y # un opérateur binaire
$x ? $y : $z # un opérateur ternaire
print $x, $y, $z # un opérateur de listeLa précédence d'un opérateur détermine sa force d'attraction. Les opérateurs de plus haute précédence capturent les arguments qui les entourent avant les opérateurs de moindre précédence. L'exemple typique sort tout droit des mathématiques élémentaires, où la multiplication est prioritaire sur l'addition :
2+3 * 4 # vaut 14, et non 20L'ordre dans lequel sont exécutés deux opérateurs de même précédence dépend de leur associativité. Les règles suivent en partie les conventions des mathématiques :
2 * 3 * 4 # signifie (2 * 3) * 4, associatif à gauche
2 ** 3 ** 4 # signifie 2 ** (3 ** 4), associatif à droite
2 != 3 != 4 # illégal, car non associatifLe tableau 3-1 liste l'associativité et l'arité des opérateurs Perl par ordre de précédence décroissante.
|
Associativité |
Arité |
Classe de précédence |
|---|---|---|
|
Non associatifs |
0 |
Termes et opérateurs de liste (vers la gauche) |
|
Gauche |
2 |
|
|
Non associatifs |
1 |
|
|
Droite |
2 |
|
|
Droite |
1 |
|
|
Gauche |
2 |
|
|
Gauche |
2 |
|
|
Gauche |
2 |
|
|
Gauche |
2 |
|
|
Droite |
0,1 |
Opérateurs unaires nommés |
|
Non associatifs |
2 |
|
|
Non associatifs |
2 |
|
|
Gauche |
2 |
|
|
Gauche |
2 |
|
|
Gauche |
2 |
|
|
Gauche |
2 |
|
|
Non associatifs |
2 |
..... |
|
Droite |
3 |
|
|
Droite |
2 |
|
|
Gauche |
2 |
, |
|
Droite |
0+ |
Opérateurs de liste (vers la droite) |
|
Droite |
1 |
|
|
Gauche |
2 |
|
|
Gauche |
2 |
|
Vous pourriez penser qu'il y a bien trop de niveaux de précédence à se souvenir. Et bien vous avez raison. Heureusement, deux choses jouent en votre faveur. D'abord les niveaux de précédence tels qu'ils sont définis sont en général assez intuitifs, en supposant que vous n'êtes pas psychotique. Ensuite, si vous êtes seulement névrosé, vous pouvez toujours ajouter des parenthèses supplémentaires pour calmer votre angoisse.
Notez également que tous les opérateurs empruntés à C conservent les mêmes relations de précédence entre eux, même quand les règles de précédence de C sont légèrement biscornues. (Cela rend Perl d'autant plus facile à apprendre pour les personnes qui connaissent C ou C++. Peut-être même pour celles qui connaissent Java.)
Les sections qui suivent couvrent ces opérateurs dans leur ordre de précédence. À de très rares exceptions, ils opèrent tous uniquement sur des valeurs scalaires et non sur des listes. Nous indiquerons les exceptions quand elles se présenteront.
Bien que les références soient des valeurs scalaires, utiliser la plupart de ces opérateurs sur des références n'a pas beaucoup de sens, car la valeur numérique d'une référence n'a de signification que dans les profondeurs de Perl. Néanmoins, si une référence pointe sur un objet d'une classe qui autorise la surcharge d'opérateurs, vous pouvez utiliser ces opérateurs sur cet objet ; si la classe a défini une surcharge pour tel ou tel opérateur, cela décrit comment l'objet sera traité par cet opérateur. C'est ainsi par exemple que les nombres complexes sont implémentés en Perl. Pour plus d'informations sur la surcharge d'opérateurs, voir le chapitre 13, Surcharge.
3-1. Termes et opérateurs de listes (vers la gauche)▲
En Perl, tout terme est de précédence maximale. Les termes comprennent les variables, les apostrophes et les opérateurs de type quote, la plupart des expressions entre parenthèses, crochets ou accolades, et toute fonction dont les arguments sont entre parenthèses. En fait, si on regarde les choses ainsi, il n'y a pas vraiment de fonctions, mais seulement des opérateurs de liste et des opérateurs unaires qui se comportent comme des fonctions parce que vous avez mis des parenthèses autour de leurs arguments. Tout cela n'empêche pas le chapitre 29 de s'appeler Fonctions.
Maintenant, lisez attentivement. Voici quelques règles très importantes qui simplifient grandement les choses, mais qui peuvent à l'occasion produire des résultats contraires à l'intuition pour les imprudents. Si un opérateur de liste (comme print) ou un opérateur unaire nommé (comme chdir) est suivi d'une parenthèse ouvrante comme token suivant (sans tenir compte des blancs), l'opérateur et ses arguments entre parenthèses ont la précédence la plus haute, comme s'il s'agissait d'un appel de fonction normal. La règle est la suivante : si cela ressemble à un appel de fonction, alors c'est un appel de fonction. Vous pouvez le faire ressembler à une non-fonction en préfixant les parenthèses avec un plus unaire, qui ne fait absolument rien sémantiquement parlant ; il ne convertit même pas les arguments en numérique.
Par exemple, puisque || a une précédence plus faible que chdir, nous aurons :
chdir $toto || die; # (chdir $toto) || die
chdir($toto) || die; # (chdir $toto) || die
chdir ($toto) || die; # (chdir $toto) || die
chdir +($toto) || die; # (chdir $toto) || diemais comme * a une précédence plus grande que chdir, nous aurons :
chdir $toto * 20; # chdir ($toto * 20)
chdir($toto) * 20; # (chdir $toto) * 20
chdir ($toto) * 20; # (chdir $toto) * 20
chdir +($toto) * 20; # chdir ($toto * 20)De même pour n'importe quel opérateur numérique qui est également un opérateur unaire nommé, comme rand :
rand 10 * 20; # rand (10 * 20)
rand(10) * 20; # (rand 10) * 20
rand (10) * 20; # (rand 10) * 20
rand +(10) * 20; # rand (10 * 20)En l'absence de parenthèses, la précédence d'opérateurs de liste comme print, sort, ou chmod est soit très haute soit très basse selon que vous regardez à gauche ou à droite de l'opérateur (c'est le sens du « vers la gauche » dans le titre de cette section). Par exemple, dans :
@tab = (1, 3, sort 4, 2);
print @tab; # imprime 1324Les virgules à droite de sort sont évaluées avant le sort, mais les virgules à sa gauche sont évaluées après. En d'autres termes, un opérateur de liste tend à avaler tous les arguments qui le suivent, puis à se comporter comme un simple terme pour l'expression qui le précède. Il vous faut encore être prudent avec les parenthèses :
# Ces arguments sont évalués avant de faire le print :
print($toto, exit); # Évidemment pas ce que vous voulez.
print $toto, exit; # Ici non plus.
# Ces lignes font le print avant d'évaluer l'exit :
(print $toto), exit; # C'est ce que vous voulez.
print($toto), exit; # Ici aussi.
print ($toto), exit; # Et même ceciLe cas le plus simple pour se faire piéger, c'est quand vous utilisez des parenthèses pour grouper des arguments mathématiques, en oubliant que les parenthèses servent aussi à regrouper les arguments de fonctions :
print ($toto & 255) + 1, "\n"; # affiche ($toto & 255)Cela ne fait probablement pas ce à quoi vous vous attendiez au premier coup d'œil. Heureusement, les erreurs de cette nature provoquent des avertissements comme « Useless use of addition in a void context » quand les avertissements sont activés (avec l'option de ligne de commande -w).
Les constructions do {} et eval {} sont aussi analysées comme des termes, de même que les appels de sous-programmes et de méthodes, les créateurs de tableaux et de hachages anonymes, [] et {}, et le créateur de sous-programme anonymes sub {}.
3-2. L'opérateur flèche▲
Tout comme en C et en C++, l'opérateur binaire -> est un opérateur infixe de déréférencement. Si à droite on trouve un indice de tableau entre [...], un indice de hachage entre {...} ou une liste d'arguments de sous-programme entre (...), alors la partie à gauche de la f lèche doit être respectivement une référence (symbolique ou en dur) de tableau, de hachage ou de sous-programme. Dans un contexte de lvalue (où l'on peut affecter une valeur), si la partie à gauche n'est pas une référence, elle doit être capable de contenir une référence, auquel cas cette référence sera autovivifiée pour vous. Pour en savoir plus à ce sujet (et pour quelques avertissements sur l'autovivification accidentelle), voir le chapitre 8, Références.
$aref->[42] # un déréférencement de tableau
$href->{"corned beef"} # un déréférencement de hachage
$sref->(1,2,3) # un déréférencement de sous-programmeSinon, c'est une sorte d'appel de méthode. La partie à droite doit être un nom de méthode (ou une simple variable scalaire contenant le nom de la méthode) et la partie à gauche doit s'évaluer soit comme un objet (une référence consacrée), soit comme un nom de classe (c'est-à-dire un nom de paquetage) :
$yogi = Ours->new("Yogi"); # un appel de méthode de classe
$yogi->pique($piquenique); # un appel de méthode sur une instanceLe nom de méthode peut être qualifié avec un nom de paquetage pour indiquer dans quelle classe commencer à chercher la méthode, ou avec le nom de paquetage spécial SUPER::, pour indiquer que la recherche doit commencer dans la classe parente. Voir le chapitre 12, Objets.
3-3. Auto-incrémentation et autodécrémentation▲
Les opérateurs ++ et -- fonctionnent comme en C. C'est-à-dire que, placés avant une variable, ils l'incrémentent ou la décrémentent avant d'en renvoyer la valeur. Quand ils sont placés après, ils l'incrémentent ou la décrémentent après en avoir renvoyé la valeur. Par exemple, $A++(55) incrémente la valeur de la variable $A et en retourne la valeur avant de réaliser l'incrémentation. De même, --$b{(/(\w+)/)[0]} décrémente l'élément du hachage %b indexé par le premier « mot » de la variable de recherche par défaut ($_) et renvoie la valeur après la décrémentation.(56)
L'opérateur d'auto-incrémentation comporte en plus un peu de magie. Si vous incrémentez une variable qui est numérique, ou qui a été utilisée à un moment donné dans un contexte numérique, vous avez une incrémentation normale. Si au contraire la variable n'a été utilisée que dans des contextes de chaîne depuis qu'elle a été affectée, que sa valeur est non nulle et correspond au motif /^[a-zA-Z]*[0-9]*$/, l'incrémentation est faite sur la chaîne, en préservant chaque caractère dans son domaine, avec une retenue :
print ++($toto = '99'); # prints '100'
print ++($toto = 'a9'); # prints 'b0'
print ++($toto = 'Az'); # prints 'Ba'
print ++($toto = 'zz'); # prints 'aaa'À l'heure où nous écrivons ces lignes, l'auto-incrémentation magique n'a pas été étendue aux lettres et chiffres Unicode, mais pourrait l'être dans le futur.
L'opérateur d'autodécrémentation n'est, lui, pas magique, et il n'est pas prévu que cela change.
3-4. Exponentiation▲
L'opérateur ** binaire est l'opérateur d'exponentiation. Notez qu'il lie encore plus fortement que le moins unaire ; c'est pourquoi -2**4 vaut -(2**4), et non (-2)**4. L'opérateur est implémenté grâce à la fonction pow(3) de C, qui fonctionne en interne avec des nombres en virgule flottante. Les calculs sont faits grâce à des logarithmes, ce qui signifie qu'il fonctionne avec des puissances fractionnaires, mais que vous obtiendrez parfois des résultats moins précis qu'avec une simple multiplication.
3-5. Opérateurs unaires idéographiques▲
La plupart des opérateurs portent simplement des noms (voir Opérateurs unaires nommés et de test de fichier plus loin dans ce chapitre), mais certains opérateurs sont jugés suffisamment importants pour mériter leur propre représentation symbolique spéciale. Ces opérateurs semblent tous avoir un rapport avec la négation. Plaignez-vous auprès des mathématiciens.
Le ! unaire réalise une négation logique, c'est-à-dire un « non ». Voyez not pour une version de moindre précédence du non logique. La valeur d'un opérande nié est vraie (1) si l'opérande est faux (0 numérique, chaîne "0", chaîne vide ou valeur indéfinie) et fausse ("") si l'opérande est vrai.
Le - unaire effectue une négation arithmétique si son opérande est numérique. Si l'opérande est un identificateur, une chaîne composée d'un signe moins concaténé à l'identificateur est renvoyée. Sinon, si la chaîne commence avec un plus ou un moins, une chaîne commençant avec le signe opposé est renvoyée. Un des effets de ces règles est que -motsimple est équivalent à "-motsimple". C'est particulièrement utile aux programmeurs Tk.
Le ~ unaire réalise une négation sur les bits, c'est-à-dire un complément à 1. Par définition, ce n'est pas vraiment portable quand c'est limité par la taille du mot-machine de votre ordinateur. Par exemple, sur une machine 32 bits ~123 vaut 4294967172, tandis que sur une machine 64 bits, cela vaut 18446744073709551492. Mais vous le saviez déjà.
Ce que vous ne saviez peut-être pas, c'est que si l'argument de ~ est une chaîne au lieu d'un nombre, une chaîne de même longueur est renvoyée avec tous ses bits complémentés. C'est une manière rapide de basculer un grand nombre de bits d'un coup, et de façon portable puisque cela ne dépend pas de la taille de votre mot-machine. Plus tard nous verrons aussi les opérateurs logiques sur les bits, qui ont eux des variantes pour les chaînes.
Le + n'a aucun effet sémantique, même sur les chaînes. Son utilité est surtout syntaxique, pour séparer le nom d'une fonction d'une expression entre parenthèses qui serait sinon interprétée comme la liste complète des arguments de la fonction. (Voir les exemples dans la section Termes et opérateurs de listes (vers la gauche).) Si vous y réfléchissez d'une manière un peu détournée, le + inverse l'effet qu'ont les parenthèses de changer les opérateurs préfixes en fonctions.
Le \ crée une référence sur ce qui le suit. Utilisé sur une liste, il crée une liste de références. Voir la section L'opérateur antislash au chapitre 8 pour plus de détails. Attention à ne pas confondre ce comportement avec celui de l'antislash dans une chaîne, bien que les deux formes comportent la notion vaguement négative de protection de leurs arguments contre l'interprétation. Cette ressemblance n'est pas purement fortuite.
3-6. Opérateurs de liaison▲
Le =~ binaire lie une expression scalaire à un opérateur de recherche de motif, de substitution ou de translittération (négligemment appelée traduction). Ces opérations chercheraient ou modifieraient sinon la chaîne contenue dans $_ (la variable par défaut). La chaîne à lier est placée à gauche, tandis que l'opérateur lui-même est placé à droite. La valeur de retour indique le succès ou l'échec de l'opération effectuée à droite, puisque l'opérateur de lien ne fait rien par lui-même.
Si l'argument de droite est une expression plutôt qu'une recherche de motif, une substitution ou une translittération, il sera interprété comme une recherche de motif à l'exécution. C'est-à-dire que $_ =~ $pat est équivalent à $_ =~ /$pat/. C'est moins efficace qu'une recherche explicite, puisque le motif doit être vérifié et potentiellement recompilé à chaque fois que l'expression est évaluée. Vous pouvez éviter cette recompilation en précompilant le motif original avec l'opérateur qr// de citation d'expression régulière (« quote regex » en anglais).
Le !~ binaire est identique à =~ sauf que la valeur de retour est inversée logiquement. Les expressions suivantes sont fonctionnellement équivalentes :
$chaine !~ /pattern/ not
$chaine =~ /pattern/Nous avons dit que la valeur de retour indique le succès, mais il existe plusieurs sortes de succès. La substitution renvoie le nombre de substitutions réussies, comme la translittération. (En fait, la translittération sert souvent à compter les caractères.) Puisque n'importe quel résultat non nul est vrai, tout fonctionne. La forme de valeur vraie la plus spectaculaire est une valeur de liste : en contexte de liste, les recherches de motif peuvent renvoyer les sous-chaînes capturées par les parenthèses dans le motif. Conformément aux règles de l'affectation de liste, cette affectation retournera vrai si quelque chose a été détecté et affecté, et faux dans le cas contraire. C'est pourquoi vous voyez parfois des choses comme :
if ( ($c,$v) = $chaine =~ m/(\w+)=(\w*)/ ) {
print "CLE $c VALEUR $v\n";
}Décomposons tout cela. Le =~ a la précédence sur =, il se produit donc en premier. Le =~ lie $chaine à la recherche de motif à droite. Celle-ci recherche ce qui ressemble à CLE=VALEUR dans votre chaîne. Il se trouve en contexte de liste, car du côté droit d'une affectation de liste. Si le motif est trouvé, il renvoie une liste à affecter à $c et $v. L'affectation de liste elle-même se trouve dans un contexte scalaire et renvoie donc 2, le nombre de valeurs à droite de l'affectation. Et il se trouve que 2 est vrai, puisque notre contexte scalaire est aussi un contexte booléen. Quand la recherche échoue, aucune valeur n'est affectée, ce qui renvoie 0, qui est faux.
Voir le chapitre 5, Recherche de motif, pour en savoir plus sur le fonctionnement des motifs.
3-7. Opérateurs multiplicatifs▲
Perl fournit des opérateurs proches de ceux de C : * (multiplication), / (division) et % (modulo). * et / fonctionnent exactement comme vous vous y attendez, en multipliant ou divisant leurs deux opérandes. La division se fait en virgule flottante, à moins que vous n'ayez spécifié le pragma integer.
L'opérateur % convertit ses opérandes en entiers avant de calculer le reste de la division entière. (Néanmoins cette division est faite en virgule flottante donc vos opérandes peuvent faire 15 chiffres sur la plupart des machines 32 bits.) Supposons que nos deux opérandes s'appellent $a et $b. Si $b est positif, alors le résultat de $a % $b est $a moins le plus grand multiple de $b inférieur à $a (ce qui veut dire que le résultat sera toujours dans l'intervalle 0 .. $b-1). Si $b est négatif, alors le résultat de $a % $b est $a moins le plus petit multiple de $b supérieur à $a (ce qui veut dire que le résultat sera toujours dans l'intervalle $b+1 .. 0).
Quand on est à portée de use integer, % vous donne directement accès à l'opérateur modulo tel qu'il est implémenté par votre compilateur C. Cet opérateur n'est pas bien défini pour les opérandes négatifs, mais s'exécutera plus rapidement.
Le x est l'opérateur de répétition. En réalité, il s'agit de deux opérateurs. En contexte scalaire, il retourne une chaîne concaténée composée de l'opérande de gauche répété le nombre de fois spécifié par l'opérande de droite. (Pour assurer la compatibilité avec les versions précédentes, il le fait également en contexte de liste si l'argument de gauche n'est pas entre parenthèses.)
print '-' x 80; # imprime une rangée de tirets
print "\t" x ($tab/8), ' ' x ($tab%8); # tabule à la colonne $tabEn contexte de liste, si l'opérande de gauche est une liste entre parenthèses, x fonctionne comme un réplicateur de liste plutôt que comme un réplicateur de chaîne. Cela peut servir à initialiser à la même valeur tous les éléments d'un tableau de longueur indéterminée.
@ones = (1) x 80; # une liste de 80 1
@ones = (5) x @ones; # met tous les éléments à 5De la même manière, vous vous pouvez également utiliser x pour initialiser des tranches de tableaux et de hachages.
@cles = qw(du Perl aux cochons);
@hash{@cles} = ("") x @cles;Si cela vous laisse perplexe, remarquez que @cles est utilisé à la fois comme une liste à gauche de l'affectation et comme une valeur scalaire (qui renvoie la longueur du tableau) à droite. L'exemple précédent a le même effet sur %hash que :
$hash{du} = "";
$hash{Perl} = "";
$hash{aux} = "";
$hash{cochons} = "";3-8. Opérateurs additifs▲
Étonnamment, Perl dispose des opérateurs usuels + (addition) et - (soustraction). Ces deux opérateurs convertissent leurs arguments de chaîne en valeurs numériques si nécessaire, et renvoient un résultat numérique.
Perl fournit également l'opérateur . qui réalise la concaténation de chaînes. Par exemple :
$presque = "Fred" . "Pierrafeu"; # renvoie FredPierrafeuRemarquez que Perl n'ajoute pas d'espace entre les chaînes concaténées. Si vous voulez l'espace ou si vous avez plus de deux chaînes à concaténer, vous pouvez utiliser l'opérateur join, décrit au chapitre 29, Fonctions. Cependant, la plupart du temps on concatène implicitement dans une chaîne entre doubles apostrophes :
$nomcomplet = "$prenom $nom";3-9. Opérateurs de décalage▲
Les opérateurs de décalage de bits (<< et >>) renvoient la valeur de l'argument de gauche décalé à gauche (<<) ou à droite (>>) du nombre de bits spécifié par l'argument de droite. Les arguments doivent être des entiers. Par exemple :
1 << 4; # renvoie 16
32 >> 4; # renvoie 2Faites attention cependant, car les résultats sur de grands nombres (ou sur des nombres négatifs) peuvent dépendre du nombre de bits utilisés par votre machine pour représenter les entiers.
3-10. Opérateurs unaires nommés et de test de fichier▲
Certaines des « fonctions » décrites au chapitre 29 sont en fait des opérateurs unaires. Le tableau 3-2 liste tous les opérateurs unaires nommés.
|
|
|
|
|
|
|
|
lock |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
int |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Les opérateurs unaires nommés ont une précédence supérieure à celle de certains opérateurs binaires. Par exemple :
sleep 4 | 3;ne dort pas pendant 7 secondes ; il dort pendant 4 secondes puis prend la valeur de retour de sleep (typiquement zéro) et la combine par OU avec 3, comme si l'expression avait des parenthèses comme suit :
(sleep 4) | 3;À comparer avec :
print 4 | 3;qui prend effectivement la valeur de 4 combiné par OU avec 3 avant de l'afficher (7 dans ce cas), comme s'il était écrit :
print (4 | 3);En effet, print est un opérateur de liste, et non un simple opérateur unaire. Une fois que vous saurez quels opérateurs sont des opérateurs de liste, vous n'aurez plus de problème pour distinguer les opérateurs de liste des opérateurs unaires. En cas de doute, vous pouvez toujours utiliser des parenthèses pour transformer un opérateur unaire en fonction. Souvenez-vous, si ça ressemble à une fonction, c'est une fonction.
Une autre caractéristique curieuse des opérateurs unaires nommés est que beaucoup d'entre eux prennent $_ comme argument par défaut, si vous ne leur en fournissez pas d'autre. Cependant, si vous omettez l'argument et que ce qui suit ressemble au début d'un argument, Perl va se tromper, car il attend un terme. Quand le caractère suivant du programme est l'un de ceux listés au tableau 3-3, le tokeniseur de Perl renvoie différents types de token selon qu'il attend un terme ou un opérateur.
|
Caractère |
Opérateur |
Terme |
|---|---|---|
|
|
Addition |
Plus unaire |
|
|
Soustraction |
Moins unaire |
|
|
Multiplication |
*typeglob |
|
|
Division |
/motif/ |
|
|
Inférieur à, décalage à gauche |
<HANDLE>, <<END |
|
. |
Concaténation |
.3333 |
|
|
?: |
?motif? |
|
|
Modulo |
%assoc |
|
|
&, && |
&sousprogramme |
Une erreur typique est donc :
où pour l'analyseur le < ressemble au début du symbole <> (un terme) au lieu du « inférieur à » (un opérateur) auquel vous pensiez. Il n'existe pas vraiment de moyen d'arranger les choses tout en gardant Perl pathologiquement éclectique. Si vous êtes paresseux au point de ne pouvoir vous résoudre à taper les deux caractères $_, l'une de ces instructions devrait faire l'affaire :
next if length() < 80;
next if (length) < 80;
next if 80 > length;
next unless length >= 80;Quand un terme est attendu, un signe moins suivi d'une lettre seule sera toujours interprété comme un test de fichier. Un opérateur de test de fichier est un opérateur unaire qui prend comme argument un nom ou un handle de fichier, et teste le fichier associé pour savoir si une certaine propriété est vraie à son sujet. Si l'argument est omis, il teste $_, sauf pour -t, qui teste STDIN. Sauf si c'est indiqué autrement dans la documentation, il retourne 1 pour vrai et "" pour faux, ou la valeur indéfinie si le fichier n'existe pas ou n'est pas accessible. Les opérateurs de test de fichier actuellement implémentés sont listés au tableau 3-4.
|
Opérateur |
Signification |
|---|---|
|
|
Fichier lisible par l'UID/GID effectif. |
|
|
Fichier en écriture pour l'UID/GID effectif. |
|
|
Fichier exécutable par l'UID/GID effectif. |
|
|
Fichier possédé par l'UID/GID effectif. |
|
|
Fichier lisible par l'UID/GID réel. |
|
|
Fichier en écriture pour l'UID/GID réel. |
|
|
Fichier exécutable par l'UID/GID réel. |
|
|
Fichier possédé par l'UID/GID réel. |
|
|
Le fichier existe. |
|
|
Fichier de taille nulle. |
|
|
Fichier de taille non nulle (renvoie la taille) |
|
|
Fichier simple. |
|
|
Le fichier est un répertoire. |
|
|
Le fichier est un lien symbolique. |
|
|
Le fichier est un tube nommé (FIFO). |
|
|
Le fichier est une socket. |
|
|
Fichier spécial de type bloc |
|
|
Fichier spécial de type caractère. |
|
|
Handle de fichier ouvert sur un tty. |
|
|
Fichier avec bit setuid. |
|
|
Fichier avec bit setgid. |
|
|
Fichier avec sticky bit. |
|
|
Fichier texte. |
|
|
Fichier binaire (le contraire de -T). |
|
|
Âge du fichier (au démarrage) en jours depuis sa modification. |
|
|
Âge du fichier (au démarrage) en jours depuis le dernier accès. |
|
|
Âge du fichier (au démarrage) en jours depuis le changement d'inode. |
Remarquez que -s/a/b/ ne fait pas une substitution négative. -exp($foo) fonctionne cependant comme prévu ; seules les lettres isolées qui suivent un signe moins sont interprétées comme des tests de fichier.
L'interprétation des opérateurs de test de permissions -r, -R, -w, -W, -x et -X est fondée uniquement sur le mode du fichier et les ID d'utilisateur et de groupe de l'utilisateur. Il peut y avoir d'autres raisons pour lesquelles vous ne pouvez effectivement pas lire, écrire ou exécuter le fichier, comme les listes de contrôle d'accès d'AFS (Andrew File System).(57) Notez également que pour le super utilisateur -r, -R, -w et -W renvoient toujours 1, et que -x et -X renvoient 1 si l'un des bits d'exécution est à 1 dans le mode. C'est pourquoi les scripts lancés par le super utilisateur peuvent nécessiter un stat ffin de connaître le véritable mode du fichier, ou bien remplacer temporairement l'UID par autre chose.
Les autres opérateurs de test de fichier se moquent de savoir qui vous êtes. N'importe qui peut utiliser le test pour les fichiers « simples » :
Les options -T et -B fonctionnent comme suit. Le premier bloc (plus ou moins) du fichier est examiné à la recherche de caractères inhabituels comme des codes de contrôle ou des octets donc le bit de poids fort est à 1 (et qui n'ont pas l'air d'être de l'UTF-8). Si on trouve plus d'un tiers d'octets inhabituels, c'est un fichier binaire ; sinon c'est un fichier texte. De même, tout fichier dont le premier bloc contient le caractère ASCII NUL (\0) est considéré comme binaire. Si -T ou -B est utilisé sur un handle de fichier, le tampon d'entrée standard (standard I/O ou « stdio ») en cours est examiné, au lieu du premier bloc du fichier. -T et -B renvoient vrai sur un fichier vide, ou sur un fichier à EOF (end-of-file : fin de fichier) quand on teste un handle. Comme Perl doit lire le fichier pour faire le test -T, vous devrez éviter de vous en servir sur des fichiers qui risquent de bloquer ou de vous causer des ennuis. C'est pourquoi la plupart du temps, vous devrez tester avec un -f d'abord, comme dans :
Si l'on donne à l'un des tests de fichier (ou à l'un des opérateurs stat ou lstat) le handle spécial constitué d'un souligné unique, c'est la structure stat du dernier test de fichier (ou de l'opérateur stat) qui est utilisée, économisant ainsi un appel système. (Cela ne marche pas avec -t, et il faudra vous souvenir que lstat et -l laissent dans la structure stat les valeurs pour le lien symbolique et non pour le fichier réel. De même, -l _ sera toujours faux après un stat normal.)
Voici quelques exemples :
print "Fait l'affaire.\n" if -r $a || -w _ || -x _;
stat($fichier);
print "En lecture\n" if -r _;
print "En écriture\n" if -w _;
print "Exécutable\n" if -x _;
print "Setuid\n" if -u _;
print "Setgid\n" if -g _;
print "Sticky\n" if -k _;
print "Texte\n" if -T _;
print "Binaire\n" if -B _;Les âges des fichiers donnés par -M, -A et -C sont en jours (avec partie fractionnaire) depuis le moment où le script a commencé à tourner. Cette date est stockée dans la variable spéciale $^T ($BASETIME). Donc, si le fichier a été modifié depuis que le script a démarré, vous obtiendrez une durée négative. Remarquez que comme la plupart des durées (86 399 sur 86 400 en moyenne) sont fractionnaires, il est généralement illusoire de tester l'égalité avec un entier sans passer par la fonction int. Exemples :
next unless -M $fichier > .5; # fichier vieux de plus de 12 heures
&nouveaufichier if -M $fichier < 0; # fichier plus récent que le processus
&avertissemnt if int(-A) == 90; # fichier ($_) accédé il y a 90 jours
# aujourd'huiPour remettre à la date courante la date de démarrage du script, écrivez :
$^T = time;3-11. Opérateurs relationnels▲
Perl possède deux classes d'opérateurs relationnels. L'une d'elles opère sur les valeurs numériques et l'autre sur les valeurs de chaîne, comme indiqué au tableau 3-5.
|
Numérique |
Chaîne |
Signification |
|---|---|---|
|
|
|
Supérieur à. |
|
|
|
Supérieur ou égal à. |
|
|
Inférieur à. |
|
|
|
|
Inférieur ou égal à. |
Ces opérateurs renvoient 1 pour vrai et "" pour faux. Notez que les opérateurs relationnels sont non-associatifs, ce qui signifie que $a < $b < $c provoquera une erreur de syntaxe.
En l'absence de déclaration de locales, les comparaisons de chaînes s'appuient sur l'ordre lexicographique ASCII/Unicode et, contrairement à certains autres langages informatiques, les espaces finaux comptent pour la comparaison. Avec une déclaration de locale, l'ordre lexicographique spécifié par la locale est utilisé. (Les mécanismes de tri fondés sur les locales peuvent plus ou moins bien interagir avec les mécanismes Unicode actuellement en cours de développement.)
3-12. Opérateurs d'égalité▲
Les opérateurs d'égalité listés au tableau 3-6 ressemblent beaucoup aux opérateurs relationnels.
|
Numérique |
Chaîne |
Signification |
|---|---|---|
|
|
Égal à. |
|
|
|
|
Différent de. |
|
|
|
Comparaison, avec résultat signé. |
Les opérateurs égal et différent renvoient 1 pour vrai et "" pour faux (exactement comme les opérateurs relationnels). Les opérateurs <=> et cmp renvoient -1 si l'opérande de gauche est inférieur à celui de droite, 0 s'il sont égaux et +1 si l'opérande de gauche est supérieur à celui de droite. Bien que ces opérateurs semblent très proches des opérateurs relationnels, ils ont un niveau de précédence plus faible, et la syntaxe de $a < $b <=> $c < $d est donc valide.
Pour des raisons évidentes pour quiconque a vu Star Wars, l'opérateur <=> est aussi connu sous le nom d'opérateur « vaisseau spatial » (spaceship operator).
3-13. Opérateurs sur les bits▲
Comme C, Perl dispose des opérateurs ET, OU et OU-exclusif sur les bits : &, | et ^. Vous avez bien sûr remarqué, après votre étude attentive du tableau au début de ce chapitre, que le ET sur les bits possède une précédence supérieure aux autres ; nous avons triché pour tous les inclure dans cette discussion.
Ces opérateurs fonctionnent différemment sur les valeurs numériques et sur les chaînes. (C'est l'un des rares cas où Perl fait une différence.) Si l'un des opérandes est un nombre (ou a été utilisé comme un nombre), les deux opérandes sont convertis en entiers, puis l'opération sur les bits est effectuée. Ces entiers font au moins 32 bits de long, mais peuvent faire 64 bits sur certaines machines. L'important est qu'il existe une limite arbitraire imposée par l'architecture de la machine.
Si les deux opérandes sont des chaînes (et n'ont pas été utilisés comme des nombres depuis leur dernière mise à jour), les opérateurs font les opérations sur les bits sur les bits correspondants des deux chaînes. Dans ce cas, il n'y a aucune limite arbitraire, puisque les chaînes ne sont pas limitées en taille. Si l'une des chaînes est plus longue que l'autre, on considère que la plus courte dispose d'un nombre suffisant de bits à 0 pour compléter la différence.
Par exemple, si vous faites un ET entre deux chaînes :
"123.45" & "234.56"vous obtenez une autre chaîne :
"020.44"Mais si vous faites un ET sur une chaîne et un nombre :
"123.45" & 234.56La chaîne est d'abord convertie en nombre, ce qui donne :
123.45 & 234.56Les nombres sont ensuite convertis en entiers :
123 & 234ce qui donne 106. Remarquez que toutes les chaînes de bits sont vraies (à moins de donner la chaîne « 0 »). Cela signifie que si vous voulez vérifier si l'un des octets résultant est non nul, vous ne devrez pas écrire ceci :
if ( "fred" & "\1\2\3\4" ) { ... }mais cela :
if ( ("fred" & "\1\2\3\4") =~ /[^\0]/ ) { ... }3-14. Opérateurs logiques de type C (à court-circuit)▲
Comme C, Perl propose également les opérateurs && (ET logique) et || (OU logique). Ils sont évalués de gauche à droite (&& ayant une précédence légérement supérieure à celle de ||) pendant le test de vérité de l'instruction. Ces opérateurs sont appelés opérateurs court-circuit, car ils déterminent la vérité de l'instruction en évaluant le plus petit nombre d'opérandes possible. Par exemple, si l'opérande à gauche d'un opérateur && est faux, l'opérande de droite ne sera jamais évalué, car le résultat de l'opérateur sera faux quelle que soit la valeur de l'opérande de droite.
|
Exemple |
Nom |
Résultat |
|---|---|---|
|
|
Et |
|
|
|
Ou |
|
Non seulement de tels courts-circuits font gagner du temps, mais ils sont fréquemment utilisés pour contrôler le flux de l'évaluation. Par exemple, un idiome courant en Perl est :
open(FILE, "monfichier") || die "Impossible d'ouvrir monfichier: $!\n";Dans ce cas, Perl évalue d'abord la fonction open. Si sa valeur est vraie (car monfichier a été ouvert avec succès), l'exécution de la fonction die n'est pas nécessaire et est donc omise. Vous pouvez littéralement lire « Ouvre mon fichier ou meurs ! ».
Les opérateurs && et || diffèrent de ceux de C en ceci qu'au lieu de retourner 0 ou 1, ils renvoient la dernière valeur évaluée. Dans le cas de ||, cela a le délicieux effet de vous permettre de choisir la première valeur vraie d'une série. Une manière raisonnablement portable de trouver le répertoire personnel d'un utilisateur pourrait donc être :
$home = $ENV{HOME}
|| $ENV{LOGDIR}
|| (getpwuid($<))[7]
|| die "Vous êtes SDF !\n";D'un autre côté, comme l'argument de gauche toujours évalué en contexte scalaire, vous ne pouvez pas vous servir de || afin choisir entre deux agrégats pour une affectation :
@a = @b || @c; # Ceci ne fait pas ce que vous voulez
@a = scalar(@b) || @c; #, car voici ce que cela veut dire.
@a = @b ? @b : @c; # En revanche cela marche bien.Perl fournit également des opérateurs and et or de moindre précédence, que certains trouvent plus lisibles et qui ne vous forcent pas à utiliser des parenthèses sur les opérateurs de liste. Ils sont aussi à court-circuit. Voir le tableau 1-1 pour la liste complète.
3-15. Opérateur d'intervalle▲
L'opérateur d'intervalle .. comprend en fait deux opérateurs différents selon le contexte.
L'opérateur est bi-stable, comme un flip-flop électronique, et émule l'opérateur d'intervalle de ligne (virgule) de sed, awk et d'autres éditeurs. Chaque opérateur .. scalaire mémorise son propre état booléen. Il est faux tant que son opérande de gauche est faux. Une fois que l'opérande de gauche est vrai, l'opérateur reste vrai jusqu'à ce que l'opérande de droite soit vrai, après quoi l'opérateur d'intervalle redevient faux. L'opérateur ne devient pas faux jusqu'à sa prochaine évaluation. Il peut tester l'opérande de droite et devenir faux pendant la même évaluation que celle sur laquelle il est devenu vrai (comme l'opérateur de awk), mais renvoie vrai au moins une fois. Si vous ne voulez pas qu'il teste l'opérande de droite avant la prochaine évaluation (comme l'opérateur de sed) utilisez simplement trois points (...) au lieu de deux. Pour les deux opérateurs .. et ..., l'opérande de droite n'est pas évalué tant que l'opérateur se trouve dans l'état faux, et l'opérande de gauche n'est pas évalué tant que l'opérateur est dans l'état vrai.
La valeur renvoyée est soit la chaîne vide pour faux soit un numéro de séquence (commençant à 1) pour vrai. Le numéro de séquence est remis à zéro pour chaque opérateur d'intervalle rencontré. La chaîne « E0 » est accolée à la fin du numéro de séquence final dans un intervalle, ce qui n'affecte pas sa valeur numérique, mais vous donne quelque chose à chercher si vous voulez exclure l'élément final. Vous pouvez exclure le point de départ en attendant que le numéro de séquence soit plus grand que 1. Si l'un des opérandes de .. est un littéral numérique, cet opérande est implicitement comparé à la variable $., qui contient le numéro de ligne courant de votre fichier d'entrée. Exemples :
if (101 .. 200) { print; } # imprime la deuxième centaine de lignes
next line if (1 .. /^$/); # passe les entêtes d'un message
s/^/> / if (/^$/ .. eof()); # cite le corps d'un messageEn contexte de liste, .. renvoie une liste de valeurs comptées à partir de la valeur de gauche jusqu'à la valeur de droite (par incréments de un). Cela sert à écrire des boucles for (1..10) et pour faire des tranches de tableaux :
for (101 .. 200) { print; } # affiche 101102...199200
@foo = @foo[0 .. $#foo]; # un no-op coûteux
@foo = @foo[ -5 .. -1]; # la tranche des 5 derniers élémentsSi la valeur de gauche est supérieure à celle de droite, une liste vide est renvoyée. (Pour construire une liste en ordre inverse, voir l'opérateur reverse.)
Si ses opérandes sont des chaînes, l'opérateur d'intervalle emploie l'algorithme d'autoincrémentation magique vu précédemment.(58) Vous pouvez donc écrire :
@alphabet = ('A' .. 'Z');pour obtenir toutes les lettres de l'alphabet (latin), ou :
$hexdigit = (0 .. 9, 'a' .. 'f')[$nombre & 15];pour obtenir un chiffre hexadécimal, ou :
@z2 = ('01' .. '31'); print $z2[$jour];pour obtenir des dates avec un zéro en tête. Vous pouvez également écrire :
@combis = ('aa' .. 'zz');pour obtenir toutes les combinaisons de deux lettres minuscules. Attention cependant à quelque chose comme :
@grossescombis = ('aaaaaa' .. 'zzzzzz');car cela va nécessiter beaucoup de mémoire. Pour être précis, il faudra de l'espace pour stocker 308 915 776 scalaires. Espérons que vous avez une grosse partition de swap. Vous devriez vous intéresser à une approche itérative.
3-16. Opérateur conditionnel▲
L'opérateur ?: est le seul opérateur ternaire, comme en C. On l'appelle souvent l'opérateur conditionnel, car il fonctionne comme un if-then-else, excepté qu'il peut être inclus sans problème dans d'autres expressions et fonctions, car c'est une expression et non une instruction. En tant qu'opérateur ternaire, ses deux éléments séparent trois expressions :
COND ? EXPR_SI_VRAI : EXPR_SI_FAUXSi la condition COND est vrai, seule l'expression EXPR_SI_VRAI est évaluée, et la valeur de cette expression devient la valeur de toute l'expression. Sinon, seule l'expression EXPR_SI_FAUX est évaluée, et sa valeur devient celle de toute l'expression.
Le contexte scalaire ou de liste se propage vers le deuxième ou le troisième argument, selon celui qui est sélectionné. (Le premier argument est toujours en contexte scalaire, puisque c'est une condition.)
$a = $ok ? $b : $c; # donne un scalaire
@a = $ok ? @b : @c; # donne un tableau
$a = $ok ? @b : @c; # donne le nombre d'éléments d'un tableauVous verrez souvent l'opérateur conditionnel inclus dans des listes de valeurs à formater avec printf, car personne n'a envie de dupliquer une instruction complète juste pour basculer entre deux valeurs proches.
printf "J'ai %d chameau%s.\n",
$n, $n <= 1 ? "" : "x";La précédence de ?: est opportunément plus grande que celle de la virgule, mais inférieure à celle de la plupart des opérateurs que vous utiliserez à l'intérieur (comme == dans cet exemple) ; vous n'aurez donc généralement pas à utiliser de parenthèses. Mais vous pouvez ajouter des parenthèses pour clarifier, si vous voulez. Pour les opérateurs conditionnels emboîtés à l'intérieur de la partie EXPR_SI_VRAI d'autres opérateurs conditionnels, nous vous suggérons de de faire des sauts de ligne et d'indenter comme s'il s'agissait d'instruction if ordinaires :
$bissextile =
$annee % 4 == 0
? $annee % 100 == 0
? $annee % 400 == 0
? 1
: 0
: 1
: 0;Pour les conditions imbriquées dans des parties EXPR_SI_FAUX d'opérateurs conditionnels précédents, vous pouvez faire quelque chose d'équivalent :
$bissextile =
$annee % 4
? 0
: $annee % 100
? 1
: $annee % 400
? 0
: 1;mais il est habituellement préférable d'aligner verticalement toutes les COND et les EXPR_SI_VRAI :
$bissextile =
$annee % 4 ? 0 :
$annee % 100 ? 1 :
$annee % 400 ? 0 : 1;Même des structures assez encombrées peuvent s'éclaircir en alignant les points d'interrogation et les deux-points :
printf "Oui, j'aime mon livre du %s!\n",
$i18n eq "anglais" ? "camel" :
$i18n eq "allemand" ? "Kamel" :
$i18n eq "japonais" ? "\x{99F1}\x{99DD}" :
"chameau"Vous pouvez affecter à l'opérateur conditionnel(59) si le deuxième et le troisième arguments sont tous les deux des lvalues légales (c'est-à-dire qu'on peut leur affecter une valeur), et que tous deux sont soit des scalaires, soit des listes (sinon Perl ne saura pas quel contexte fournir à la partie droite de l'affectation) :
($a_ou_b ? $a : $b) = $c; # donne la valeur de $c soit à $a, soit à $bSouvenez-vous que l'opérateur conditionnel lie encore plus fort que les multiples opérateurs d'affectation. C'est habituellement ce que vous voulez (voir l'exemple $bissextile plus haut, par exemple), mais vous ne pourrez pas obtenir l'effet inverse sans parenthèses. L'utilisation d'affectations dans un opérateur conditionnel vous attirera des ennuis, et vous risquez même de ne pas avoir d'erreur à l'analyse, car l'opérateur conditionnel peut être analysé comme une lvalue. Par exemple, vous pourriez écrire ceci :
$a% 2?$a+=10: $a += 2 # FAUXMais ce serait analysé comme cela :
(($a%2)?($a+=10) : $a) += 23-17. Opérateurs d'affectation▲
Perl reconnaît les opérateurs d'affectation de C, et fournit également les siens. Il y en a un certain nombre :
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
. |
|
|
||||
|
|
Chaque opérateur nécessite une lvalue cible (typiquement une variable ou un élément de tableau) à sa gauche et une expression à sa droite. Pour l'opérateur d'affectation simple :
CIBLE = EXPRLa valeur de EXPR est stockée dans la variable ou à l'endroit désigné par CIBLE. Pour les autres opérateurs, Perl évalue l'expression :
CIBLE OP= EXPRcomme s'il était écrit :
CIBLE = CIBLE OP EXPRC'est un bon moyen mnémotechnique, mais il est trompeur, et de deux manières. D'abord les opérateurs d'affectation sont analysés au niveau de précédence des affectations ordinaires, quelle que soit la précédence que l'opérateur OP aurait eue par lui-même. Ensuite, CIBLE n'est évalué qu'une seule fois. Habituellement cela n'a aucune importance, sauf en cas d'effets secondaires, comme pour une auto-incrémentation.
$var[$a++] += $valeur; # $a is incrementé une fois
$var[$a++] = $var[$a++] + $valeur; # $a is incrementé deux foisÀ la différence de C, l'opérateur d'affectation produit une lvalue valide. Modifier une affectation revient à faire l'affectation puis à modifier la variable à laquelle on vient d'affecter une valeur. Cela peut servir à modifier une copie de quelque chose, comme ceci :
($tmp = $global) += $constante;qui est équivalent à :
$tmp = $global + $constante;De même :
($a +=2)*= 3;est équivalent à :
$a += 2;
$a *= 3;Ce n'est pas tellement utile, mais voici un idiome fréquent :
($nouveau = $ancien) =~ s/toto/titi/g;Dans tous les cas, la valeur de l'affectation est la nouvelle valeur de la variable. Comme les opérateurs d'affectations sont associatifs de droite à gauche, cela peut servir à affecter la même valeur à plusieurs variables, comme dans :
$a=$b =$c = 0;qui affecte 0 à $c et le résultat de cette opération (toujours 0) à $b, puis le résultat de (toujours 0) à $a.
Les affectations de listes ne se font qu'avec l'opérateur d'affectation simple, =. Dans un contexte de liste, une affectation de liste retourne la liste des nouvelles valeurs, tout comme l'affectation scalaire. En contexte scalaire, une affectation de liste renvoie le nombre de valeurs qui étaient disponibles à droite de l'affectation, comme indiqué au chapitre 2, Composants de Perl. Cela sert pour tester les fonctions qui renvoient une liste vide quand elles échouent (ou finissent par échouer), comme dans :
3-18. Opérateurs virgule▲
Le « , » binaire est l'opérateur virgule. En contexte scalaire, il évalue son argument de gauche en contexte vide, jette le résultat, puis évalue son argument de droite et retourne cette valeur. Exactement comme l'opérateur virgule de C. Par exemple :
$a = (1, 3);affecte 3 à $a. Attention à ne pas confondre son utilisation en contexte scalaire avec son utilisation en contexte de liste. Dans un contexte de liste, une virgule est juste le séparateur des arguments de la liste et il insère ses deux arguments dans la LISTE. Il ne jette aucune valeur.
Par exemple, si vous modifiez l'exemple précédent en :
@a = (1, 3);vous construisez une liste de deux éléments, tandis que :
atan2(1, 3);appelle la fonction atan2 avec deux arguments.
La plupart du temps, le digramme => est juste un synonyme pour l'opérateur virgule. Il sert à documenter les arguments appariés. Il force également l'interprétation comme chaîne de tout identificateur placé à sa gauche.
3-19. Opérateurs de liste (vers la droite)▲
La partie droite d'un opérateur de liste commande tous les arguments de l'opérateur de liste, qui sont séparés par des virgules ; donc la précédence d'un opérateur de liste est plus faible que celle de la virgule, si vous regardez vers la droite. Une fois qu'un opérateur de liste commence à avaler des arguments séparés par des virgules, les seules choses qui l'arrêtent sont les tokens qui terminent l'expression tout entière (comme les points-virgules ou les modificateurs d'instructions) ou les tokens qui terminent la sous-expression en cours (comme les parenthèses ou les crochets fermants) ou les opérateurs logiques de faible précédence dont nous aller parler tout de suite.
3-20. And, or, not et xor logiques▲
Perl fournit les opérateurs and, or, et not comme alternatives de moindre précédence à &&, ||, et !. Le comportement de ces opérateurs est identique — en particulier, and et or court-circuitent comme leurs alter ego, ce qui leur donne leur utilité non seulement pour les expressions logiques, mais aussi pour le contrôle du flux d'évaluation.
Comme la précédence de ces opérateurs est beaucoup plus basse que celle des opérateurs empruntés à C, vous pouvez les utiliser en toute sécurité après un opérateur de liste, sans qu'il soit besoin de parenthèses.
unlink "alpha", "beta", "gamma"
or enrage(), next LIGNE;Avec les opérateurs issus de C, vous auriez dû l'écrire comme ceci :
unlink("alpha", "beta", "gamma")
|| (enrage(), next LIGNE);Mais vous ne pouvez pas simplement remplacer toutes les occurrences de || par or. Supposons que vous changiez ceci :
$xyz=$x|| $y|| $z;en cela :
$xyz=$xor$yor $z; # FAUXCela ne ferait pas du tout la même chose ! La précédence de l'affectation est supérieure à celle de or, mais plus basse que celle de ||, donc on affecterait toujours $x à $xyz pour ensuite seulement faire les or. Pour obtenir le même résultat qu'avec ||, vous devrez écrire :
$xyz= ($xor $y or $z );La morale de cette histoire, c'est qu'il faut toujours apprendre les règles de précédence (ou utiliser les parenthèses) quels que soient les opérateurs logiques que vous utilisez.
Il existe également un xor logique qui n'a pas d'équivalent exact en C ou en Perl, puisque le seul autre opérateur OU-exclusif (^) travaille sur les bits. L'opérateur xor ne peut pas court-circuiter, car les deux côtés doivent être évalués. Le meilleur équivalent de $a xor $b est peut-être !$a != !$b. On pourrait également écrire !$a ^ !$b ou même $a ? !$b : !!$b, bien sûr. L'essentiel est que $a et $b doivent tous les deux être évalués comme vrais ou faux dans un contexte booléen, et l'opérateur sur les bits existants n'en fournit pas sans qu'on l'y aide.
3-21. Opérateurs C manquant en Perl▲
Voici ce que C a et que Perl n'a pas :
& unaire
-
L'opérateur adresse-de. L'opérateur \ de Perl (qui fournit une référence) occupe la même niche écologique :
Sélectionnez$ref_var=\$var; - Mais les références de Perl sont plus sûres que les pointeurs de C.
* unaire
- L'opérateur de déréférencement d'adresse. Comme Perl ne connaît pas les adresses, il n'a pas besoin de les déréférencer. En revanche, Perl a des références et ce sont donc les caractères de préfixe variable qui servent d'opérateurs de déréférence, tout en indiquant le type :
$,@,%et&. Étonnamment, il existe bien un opérateur*de déréférencement, mais comme*est le drôle de caractère indiquant un typeglob, vous ne l'utiliserez pas ainsi.
(TYPE)
- L'opérateur de transtypage. De toute façon, personne n'aime se faire transtyper.
4. Instructions et déclarations▲
Un programme Perl consiste en une séquence de déclarations et d'instructions. Une déclaration peut-être placée partout où une instruction peut l'être, mais son effet premier se produit à la compilation. Certaines déclarations jouent un double rôle en tant qu'instructions, mais la plupart sont totalement transparentes à l'exécution. Après la compilation, la séquence d'instructions principale est exécutée une seule fois.
Contrairement à beaucoup de langages de programmation, Perl n'impose pas de déclarer explicitement les variables ; elles se mettent à exister à leur première utilisation, que vous les ayez déclarées ou non. Si vous essayez d'utiliser la valeur d'une variable à laquelle aucune valeur n'a jamais été affectée, elle est traitée silencieusement comme si elle contenait 0 si vous vouliez un nombre, comme "" si vous vouliez une chaîne ou simplement comme une valeur fausse si vous vouliez une valeur logique. Si vous préférez être averti de l'utilisation de valeurs non définies comme si elles étaient de véritables chaînes ou nombres, ou même traiter cette utilisation comme une erreur, la déclaration use warnings s'en chargera ; voir la section Pragmas à la fin de ce chapitre.
Cependant, si vous préférez, vous pouvez éventuellement déclarer vos variables, en utilisant soit my ou our avant le nom de variable. Vous pouvez même faire qu'utiliser une variable non déclarée soit une erreur. C'est bien de vouloir de la discipline, encore faut-il la demander. Normalement, Perl ne s'intéresse pas à vos habitudes de programmation ; mais avec la déclaration use strict, l'utilisation de variables non déclarées est détectée à la compilation. De nouveau, voir la section Pragmas.
4-1. Instructions simples▲
Une instruction simple est une expression évaluée pour ses effets secondaires. Toute instruction simple doit se terminer par un point-virgule, sauf si c'est la dernière instruction d'un bloc. Dans ce cas, le point-virgule est optionnel — Perl sait que vous en avez fini avec cette instruction, puisque vous avez fini le bloc. Mais mettez quand même le point-virgule s'il s'agit d'un bloc multiligne, car vous pourriez bien ajouter une autre ligne par la suite.
Bien que des opérateurs comme eval {}, do {} et sub {} ressemblent à des instructions composées, en fait ce n'en sont pas. Certes, ils permettent d'avoir plusieurs instructions à l'intérieur, mais cela ne compte pas. Vus de l'extérieur, ces opérateurs sont juste des termes dans une expression ; c'est pourquoi ils nécessitent un point-virgule explicite quand ils sont utilisés comme dernier élément d'une instruction.
Toute instruction simple peut être optionnellement suivie d'un modificateur unique, juste avant le point-virgule final (ou la fin de bloc). Les modificateurs possibles sont :
Les modificateurs if et unless fonctionnent comme peuvent s'y attendre les anglophones :
$trash->take('out') if $you_love_me; # sors la poubelle si tu m'aimes
shutup() unless $you_want_me_to_leave; # tais-toi, sauf si tu veux que
# je m'en ailleLes modificateurs while et until sont évalués de façon répétée. Comme notre lectorat anglophone pouvait s'y attendre, un modificateur while exécute l'expression tant que sa propre expression reste vraie, tandis qu'un modificateur until continue de s'exécuter tant qu'elle reste fausse :
$expression++ while -e "$file$expression";
kiss('me') until $I_die; # embrasse-moi jusqu'à la mortLe modificateur foreach (aussi orthographié for) est évalué une fois par élément de sa LISTE, $_ étant un alias de l'élément courant :
Les modificateurs while et until ont la sémantique usuelle des boucles while (la condition est évaluée en premier), sauf quand ils s'appliquent à un doBLOC (ou à l'instruction maintenant dépréciée doSUBROUTINE), auquel cas le bloc s'exécute une fois avant que la condition soit évaluée. Cela vous permet d'écrire des boucles comme :
Voyez aussi les trois différentes entrées de do au chapitre 29, Fonctions. Remarquez également que les opérateurs de contrôle de boucle décrits plus loin ne fonctionnent pas dans cette construction, car les modificateurs de boucles ne prennent pas d'étiquette. Vous pouvez toujours placer un bloc supplémentaire autour pour terminer plus tôt, ou à l'intérieur pour itérer avant la fin de la boucle, comme cela est décrit dans la section Blocs simples. Ou bien vous pourriez écrire une vraie boucle avec plusieurs commandes de contrôle de boucle à l'intérieur. À propos de vraies boucles, nous allons maintenant parler des instructions composées.
4-2. Instructions composées▲
On appelle bloc une séquence d'instructions définie dans une portée(60). Parfois la portée s'étend sur un fichier tout entier, par exemple un fichier appelé avec require ou le fichier contenant votre programme principal. D'autres fois la portée a l'étendue d'une chaîne évaluée avec eval. Mais en général, un bloc est entouré d'accolades ({}). Quand nous parlons de portée, cela signifie n'importe laquelle de ces trois possibilités. Quand nous voudrons dire un bloc entouré d'accolades, nous emploierons le terme BLOC.
Les instructions composées sont construites à partir d'expressions et de BLOC. Les expressions sont construites à partir de termes et d'opérateurs. Dans nos descriptions syntaxiques, nous utiliserons le mot EXPR pour indiquer un emplacement où vous pouvez utiliser n'importe quelle expression scalaire. Pour indiquer une expression évaluée en contexte de liste, nous dirons LISTE.
Les constructions suivantes peuvent être utilisées pour contrôler l'exécution de BLOC de façon conditionnelle ou répétée. (L'étiquette LABEL est optionnelle.)
if (EXPR) BLOC
if (EXPR) BLOC else BLOC
if (EXPR) BLOC elsif (EXPR) BLOC ...
if (EXPR) BLOC elsif (EXPR) BLOC ... else BLOC
unless (EXPR) BLOC
unless (EXPR) BLOC else BLOC
unless (EXPR) BLOC elsif (EXPR) BLOC ...
unless (EXPR) BLOC elsif (EXPR) BLOC ... else BLOC
LABEL while (EXPR) BLOC
LABEL while (EXPR) BLOC continue BLOC
LABEL until (EXPR) BLOC
LABEL until (EXPR) BLOC continue BLOC
LABEL for (EXPR; EXPR; EXPR) BLOC
LABEL foreach (LISTE) BLOC
LABEL foreach VAR (LISTE) BLOC
LABEL foreach VAR (LISTE) BLOC continue BLOC
LABEL BLOC
LABEL BLOC continue BLOCRemarquez qu'à l'inverse de C et de Java, elles sont définies en termes de BLOC, et non d'instructions. Cela signifie que les accolades sont obligatoires ; les instructions isolées ne sont pas autorisées. Si vous voulez écrire des conditions sans accolades, il y a plusieurs manières de le faire. Les lignes suivantes font toutes la même chose :
unless (open(TOTO, $toto)) { die "Impossible d'ouvrir $toto: $!" }
if (!open(TOTO, $toto)) { die "Impossible d'ouvrir $toto: $!" }
die "Impossible d'ouvrir $toto: $!" unless open(TOTO, $toto);
die "Impossible d'ouvrir $toto: $!" if !open(TOTO, $toto);
open(TOTO, $toto) || die "Impossible d'ouvrir $toto: $!";
open TOTO, $toto or die "Impossible d'ouvrir $toto: $!";Nous avons tendance à préférer les deux dernières dans la plupart des cas. Elles sont plus lisibles que les autres, en particulier la version « or die ». Avec || vous devez vous habituer à utiliser les parenthèses religieusement, tandis qu'avec la version or, ce n'est pas grave de les oublier.
Mais la principale raison pour laquelle nous préférons les dernières versions est qu'elles mettent la partie la plus importante de l'instruction au début de la ligne, là où vous la verrez le mieux. La gestion d'erreur est repoussée vers la droite, où vous n'avez pas besoin d'y faire attention, sauf si vous le voulez2. Et si vous tabulez tous vos tests « or die » à la même position à droite de chaque ligne, c'est encore plus facile à lire :
4-3. Instructions if et unless▲
L'instruction if est simple. Comme les BLOCs sont délimités par des accolades, il n'y jamais d'ambiguïté pour savoir à quel if en particulier un else ou un elsif est lié. Dans une séquence donnée de BLOCs if/elsif/else, seul le premier dont la condition est vraie est exécuté. Si aucune des conditions n'est vraie, alors le BLOC else, s'il existe, est exécuté. C'est en général une bonne idée de mettre un else à la fin d'une chaîne de elsif, afin de se prémunir contre un cas oublié.
Si vous utilisez unless à la place de if, le sens du test est inversé. C'est-à-dire que :
unless ($x == 1) ...est équivalent à :
if ($x != 1) ...ou au plus laid :
if (!($x == 1)) ...La portée d'une variable déclarée dans la condition de contrôle s'étend de sa déclaration jusqu'à la fin de l'instruction conditionnelle, y compris tous les elsif et l'éventuelle clause else finale, mais pas plus loin :
if ((my $couleur = <STDIN>) =~ /rouge/i) {
$valeur = 0xff0000;
}
elsif ($couleur =~ /vert/i) {
$valeur = 0x00ff00;
}
elsif ($couleur =~ /bleu/i) {
$valeur = 0x0000ff;
}
else {
warn "`$couleur' : composante RGB inconnue, le noir est sélectionné\n";
$valeur = 0x000000;
}Après le else, la variable $couleur est hors de portée. Si vous voulez que sa portée s'étende plus loin, déclarez la variable plus tôt.
4-4. Instructions de boucle▲
Dans leur syntaxe formelle, toutes les instructions de boucle comportent un LABEL (ou étiquette) facultatif. (Vous pouvez mettre une telle étiquette sur n'importe quelle instruction, mais cela a une signification spéciale pour les boucles.) S'il est présent, le label consiste en un identificateur suivi de deux-points. Il est courant d'écrire l'étiquette en majuscules pour éviter tout conflit avec des mots réservés et les faire mieux ressortir. Bien que Perl ne se pose pas de problème si vous utilisez un label qui a déjà une signification comme if ou open, vos lecteurs risquent de se tromper.
4-4-a. Instructions while et until▲
L'instruction while exécute le bloc tant que EXPR est vraie. Si le mot while est remplacé par until, le sens du test est inversé ; c'est-à-dire qu'il exécute le bloc tant que EXPR est fausse. La condition est cependant toujours testée avant la première itération.
Les instructions while ou until comportent un bloc supplémentaire facultatif : le bloc continue. Ce bloc est exécuté à chaque fois que l'on achève l'itération, soit en sortant à la fin du premier bloc, soit par un next explicite (next est un opérateur de contrôle de boucle qui passe à l'itération suivante). En pratique, le bloc continue n'est pas très utilisé, mais il est présent afin de pouvoir définir rigoureusement la boucle for dans la section qui suit.
Contrairement à la boucle for que nous allons voir dans un moment, une boucle while ne localise jamais implicitement de variables dans sa condition de test. Cela peut avoir d'« intéressantes » conséquences quand des boucles while utilisent des variables globales comme variables de boucle. En particulier, consultez la section Opérateur de lecture de ligne (Angle) au chapitre 2 pour voir comment une affectation implicite à la variable globale $_ peut se produire dans certaines boucles while, ainsi qu'un exemple de gestion de ce problème en localisant explicitement $_. Il est cependant préférable de déclarer les autres variables de boucle avec my, comme dans l'exemple suivant.
Une variable déclarée dans la condition de test d'une instruction while ou d'un until est visible seulement dans le ou les blocs pilotés par ce test. Sa portée ne s'étend pas au-delà. Par exemple :
while (my $ligne = <STDIN>) {
$ligne = lc $ligne;
}
continue {
print $ligne; # toujours visible
}
# $ligne maintenant hors de portéeIci, la portée $ligne s'étend de sa déclaration dans l'expression de contrôle à l'ensemble de la boucle, y compris le bloc continue, mais pas au-delà. Si vous voulez que sa portée s'étende plus loin, déclarez la variable avant la boucle.
4-4-b. Boucles for▲
La boucle for en trois parties comporte trois expressions séparées par des points-virgules entre ses parenthèses. Ces expressions sont respectivement l'initialisation, la condition et la réinitialisation de la boucle. Ces trois expressions sont optionnelles (mais pas les points-virgules) ; si la condition est omise, elle est toujours vraie. La boucle for peut être définie dans les termes de la boucle while correspondante. Ce qui suit :
est donc identique à :
sinon qu'il n'y a pas vraiment de bloc extérieur. (Nous l'avons juste mis là pour montrer les limites du my.)
Si vous voulez itérer deux variables simultanément, il vous suffit de séparer les expressions parallèles par des virgules :
for ($i = 0, $bit = 0; $i < 32; $i++, $bit <<= 1) {
print "Le bit $i is est à 1\n" if $mask & $bit;
}
# les valeurs de $i et $bit persistent après la boucleOu bien déclarer ces variables comme visibles seulement à l'intérieur de la boucle for:
for (my ($i, $bit) = (0, 1); $i < 32; $i++, $bit <<= 1) {
print "Le bit $i is est à 1\n" if $mask & $bit;
}
# les $i et $bit de la boucle sont maintenant hors de portéeEn plus des boucles habituelles sur les indices de tableaux, for a d'autres applications intéressantes. Il n'a même pas besoin d'une variable de boucle explicite. Voici un exemple permettant d'éviter le problème que vous rencontrez en testant explicitement la fin de fichier sur un descripteur de fichier interactif, provoquant ainsi le blocage du programme.
$sur_un_tty = -t STDIN && -t STDOUT;
sub prompt { print "yes? " if $sur_un_tty }
for ( prompt(); <STDIN>; prompt() ) {
# fait quelque chose
}Une autre application traditionnelle pour le for en trois parties vient du fait que les trois expressions sont optionnelles et que la condition par défaut est vraie. Si vous omettez les trois expressions, vous obtenez une boucle infinie :
for (;;) {
...
}Ce qui est exactement équivalent à :
while (1) {
...
}Si la notion de boucle infinie vous inquiète, nous devrions souligner que vous pouvez toujours sortir de la boucle quand vous voulez avec un opérateur de contrôle explicite de boucle comme last. Bien sûr, si vous écrivez le code de contrôle d'un missile de croisière, vous n'aurez jamais vraiment besoin de sortir de la boucle. Elle se terminera automatiquement au moment opportun.(61)
4-4-c. Boucles foreach▲
La boucle foreach parcourt une liste de valeurs en affectant tour à tour chaque élément de la liste à la variable de contrôle (VAR) :
foreach VAR (LISTE) {
...
}Le mot-clef foreach est juste un synonyme du mot-clef for, vous pouvez donc utiliser au choix for et foreach, selon lequel vous trouvez le plus lisible dans une situation donnée. Si VAR est omis, la variable globale $_ est utilisée. (Ne vous inquiétez pas — Perl distingue facilement for (@ARGV) de for ($i=0; $i<$#ARGV; $i++), car ce dernier contient des points-virgules.) Voici quelques exemples :
$somme = 0; foreach $valeur (@tableau) { $somme += $valeur }
for $decompte (10,9,8,7,6,5,4,3,2,1,'BOUM') { # compte à rebours
print "$decompte\n"; sleep(1);
}
for (reverse 'BOUM', 1 .. 10) { # pareil
print "$_\n"; sleep(1);
}
for $champ (split /:/, $data) { # toute expression de LISTE
print "Le champ contient : '$champ'\n";
}
foreach $cle (sort keys %hash) {
print "$cle => $hash{$cle}\n";
}Le dernier représente la manière classique d'afficher les valeurs d'un hachage dans l'ordre des clefs. Consultez les entrées keys et sort au chapitre 29 pour des exemples plus élaborés.
Il n'existe aucune manière de savoir où vous en êtes dans une liste avec foreach. Vous pouvez comparer des éléments adjacents en vous souvenant du précédent dans une variable, mais il faudra parfois vous contenter d'écrire une boucle for en trois parties avec des indices. Après tout, cet autre for est justement là pour ça.
Si LISTE est entièrement constituée d'éléments auxquels on peut affecter une valeur (c'est-à-dire de variables, pas d'une énumération de constantes), vous pouvez modifier chacune de ces variables en modifiant VAR à l'intérieur de la boucle. Cela provient du fait que la variable d'indice de la boucle foreach est un alias implicite de chaque élément de la liste sur laquelle vous bouclez. Vous pouvez non seulement modifier un tableau d'un coup, mais également plusieurs tableaux ou hachages dans une seule liste :
foreach $paye (@salaires) { # une augmentation de 8%
$paye *= 1.08;
}
for (@noel, @paques) { # change le menu
s/pâté/foie gras/;
}
s/pâté/foie gras/ for @noel, @paques; # idem
for ($scalaire, @tableau, values %hash) {
s/^\s+//; # retire les espaces initiaux
s/\s+$//; # retire les espaces finaux
}La variable de boucle est valide uniquement dans la portée dynamique ou lexicale de la boucle et sera implicitement lexicale si la variable a été précédemment déclarée avec my. Cela la rend invisible à toute fonction définie en dehors de la portée lexicale de la variable, même si elle est appelée depuis cette boucle. Cependant si aucune déclaration lexicale n'est à portée, la variable de boucle sera une variable globale localisée (à portée dynamique) ; cela permet aux fonctions appelées depuis la boucle d'accéder à cette variable. Dans tous les cas, la valeur qu'avait la variable localisée avant la boucle sera restaurée à la sortie de la boucle.
Si vous préférez, vous pouvez déclarer explicitement quel type de variable (lexicale ou globale) utiliser. Ceux qui maintiennent votre code sauront plus facilement ce qui se passe ; sinon, ils devront remonter la chaîne des portées successives à la recherche d'une déclaration pour deviner de quelle variable il s'agit :
for my $i (1 .. 10) { ... } # $i toujours lexicale
for our $Tick (1 .. 10) { ... } # $Tick toujours globaleQuand une déclaration accompagne la variable de boucle, l'écriture courte for est toujours préférable à foreach, car cela se lit mieux en anglais.(62)
Voici comment un programmeur C ou Java pourrait d'abord penser à écrire un algorithme donné en Perl :
for ($i = 0; $i < @tab1; $i++) {
for ($j = 0; $j < @tab2; $j++) {
if ($tab1[$i] > $tab2[$j]) {
last; # Impossible d'aller à la boucle externe. :-(
}
$tab1[$i] += $tab2[$j];
}
# voici où ce last m'emmène
}Mais voici comment un programmeur Perl expérimenté pourrait l'écrire :
WID: foreach $ceci (@tab1) {
JET: foreach $cela (@tab2) {
next WID if $ceci > $cela;
$ceci += $cela;
}
}Vous voyez combien c'était simple en Perl idiomatique ? C'est plus propre, plus sûr et plus rapide. C'est plus propre, car il y a moins de bruit. C'est plus sûr, car si du code est ajouté par la suite entre les boucles interne et externe, ce code ne sera pas accidentellement exécuté, car next (expliqué plus loin) reboucle sur la boucle externe.
Mais vous codez comme vous préférez. TMTOWTDI.
Comme l'instruction while, l'instruction foreach peut aussi avoir un bloc continue. Cela vous permet d'exécuter un bout de code à la fin de chaque itération de boucle, que vous en soyez arrivé là par le cours normal des événements ou par un next.
4-4-d. Contrôle de boucle▲
Nous avons déjà mentionné que vous pouviez mettre un LABEL sur une boucle pour lui donner un nom. L'étiquette identifie la boucle pour les opérateurs de contrôle de boucle next, last et redo. Le LABEL désigne la boucle tout entière, pas seulement le début de celle-ci. Une commande de contrôle de boucle ne « va » pas au LABEL lui-même. Pour l'ordinateur l'étiquette aurait aussi bien pu être placée à la fin de la boucle. Mais il semble que les gens préfèrent les étiquettes au début.
Les boucles sont typiquement nommées d'après les éléments qu'elles manipulent à chaque itération. Cela se combine bien avec les opérateurs de contrôle de boucle, qui sont conçus pour se lire comme de l'anglais quand ils sont utilisés avec une étiquette appropriée et un modificateur d'instruction. La boucle typique traite des lignes, donc l'étiquette de boucle typique est LINE: ou LIGNE: et l'opérateur de contrôle de ligne typique ressemble à ceci :
La syntaxe des opérateurs de contrôle de boucle est :
Le LABEL est optionnel ; s'il est omis, l'opérateur se réfère à la boucle englobante la plus interne. Mais si vous voulez sauter plus d'un niveau, vous devez utiliser un LABEL pour désigner la boucle sur laquelle agir. Ce LABEL n'a pas besoin d'être dans la même portée lexicale que l'opérateur de contrôle, mais c'est probablement préférable. En fait, le LABEL peut être n'importe où dans la portée dynamique. Si cela vous force à sortir d'un eval ou d'un sous-programme, Perl émet un avertissement (sur demande).
Tout comme vous pouvez avoir autant de return que vous voulez dans une fonction, vous pouvez avoir autant d'opérateurs de contrôle de boucle que vous voulez dans une boucle. Cela n'a pas à être considéré comme mauvais ou pas cool. Aux débuts de la programmation structurée, certaines personnes insistaient sur le fait que les boucles et les sous-programmes ne devaient avoir qu'une entrée et qu'une sortie. La notion d'entrée unique est toujours une bonne idée, mais la notion de sortie unique a conduit à l'écriture de beaucoup de code artificiel. La programmation consiste principalement à parcourir des arbres de décision. Un arbre de décision commence naturellement par une racine unique, mais se termine par de nombreuses feuilles. Écrivez votre code avec le nombre de sorties de boucle (et de retours de fonction) qui est naturel pour le problème que vous essayez de résoudre. Si vous avez déclaré vos variables dans des portées raisonnables, tout sera automatiquement nettoyé le moment venu, quelle que soit la manière dont vous quittez le bloc.
L'opérateur last sort immédiatement de la boucle en question. Le bloc continue, s'il existe, n'est pas exécuté. L'exemple suivant s'éjecte de la boucle à la première ligne blanche :
LIGNE: while (<STDIN>) {
last LIGNE if /^$/; # sort quand l'entête de mail est fini
...
}L'opérateur next passe le reste de l'itération courante de la boucle et commence la suivante. S'il existe une clause continue sur la boucle, elle est exécutée juste avant que la condition soit réévaluée, exactement comme la troisième partie d'une boucle for. Elle peut donc servir à incrémenter une variable de boucle, même si une itération particulière de la boucle a été interrompue par un next :
LIGNE: while (<STDIN>) {
next LIGNE if /^#/; # ignore les commentaires
next LIGNE if /^$/; # ignore les lignes blanches
...
} continue {
$compte++;
}L'opérateur redo redémarre le bloc de boucle sans réévaluer la condition. Le bloc continue, s'il existe, n'est pas exécuté. Cet opérateur s'utilise souvent pour des programmes qui veulent se cacher à eux-mêmes ce qui vient d'être entré. Supposons que vous traitez un fichier dont les lignes sont parfois terminées par un antislash pour indiquer qu'elles continuent sur la ligne suivante. Voici un exemple d'utilisation de redo dans ce cas :
while (<>) {
chomp;
if (s/\\$//) {
$_ .= <>;
redo unless eof; # ne pas lire au-delà de la fin de chaque fichier
}
# traitement de $_
}qui est la version Perl usuelle du plus explicite (et laborieux) :
LIGNE: while (defined($ligne = <ARGV>)) {
chomp($ligne);
if ($ligne =~ s/\\$//) {
$ligne .= <ARGV>;
redo LIGNE unless eof(ARGV);
}
# traitement de $ligne
}Voici un exemple tiré d'un programme réel qui utilise les trois opérateurs de contrôle de boucle. Bien que cette méthode soit moins courante maintenant que nous disposons des modules Getopt::* dans la distribution de Perl standard, c'est toujours une illustration intéressante de l'utilisation des opérateurs de contrôle de boucle sur des boucles nommées et imbriquées :
ARG: while (@ARGV && $ARGV[0] =~ s/^-(?=.)//) {
OPT: for (shift @ARGV) {
m/^$/ && do { next ARG; };
m/^-$/ && do { last ARG; };
s/^d// && do { $Niveau_Debug++; redo OPT; };
s/^l// && do { $Genere_Listing++; redo OPT; };
s/^i(.*)// && do { $Sur_Place = $1 || ".bak"; next ARG; };
say_usage("Option inconnue : $_");
}
}Encore un mot au sujet des opérateurs de contrôle de boucle. Vous avez peut-être remarqué que nous ne les appelons pas « instructions ». Ce ne sont en effet pas des instructions — bien que comme toute expression, on puisse les utiliser comme des instructions. Vous pouvez presque les considérer comme des opérateurs unaires qui modifient le déroulement du programme. En fait, vous pouvez même vous en servir là où cela n'a aucun sens. On voit parfois cette erreur de codage :
open FICHIER, $fichier
or warn "Impossible d'ouvrir $fichier : $!\n", next FICHIER; # FAUXL'intention est bonne, mais next FICHIER est analysé comme l'un des paramètres de warn, qui est un opérateur de liste. Donc le next s'exécute avant que le warn ait la moindre chance d'émettre son avertissement. Dans ce cas, cela se corrige facilement en changeant l'opérateur de liste warn en la fonction warn à l'aide de parenthèses bien placées :
open FICHIER, $fichier
or warn("Impossible d'ouvrir $fichier : $!\n"), next FICHIER; # CorrectNéanmoins, vous trouverez peut-être ceci plus facile à lire :
4-5. Blocs simples▲
Un BLOC (étiqueté ou non) est en soi l'équivalent sémantique d'une boucle qui s'exécute une seule fois. C'est pourquoi vous pouvez utiliser last pour quitter un bloc ou redo pour relancer le bloc.(63) Remarquez que ceci n'est pas le cas des blocs à l'intérieur d'eval {}, de sub {} ou, ce qui en étonne beaucoup, de do {}. En effet, ce ne sont pas des blocs de boucle, car ce ne sont pas des blocs par eux-mêmes. Le mot-clef qui les précède fait d'eux les termes d'expressions qui se trouvent contenir un bloc de code. N'étant pas des blocs de boucle, ils ne peuvent être étiquetés et les contrôles de boucle ne s'y appliquent pas. Les contrôles de boucle ne s'appliquent qu'aux véritables boucles, tout comme return ne s'utilise que dans un sous-programme (ou un eval).
Les contrôles de boucle ne marchent pas non plus avec un if ou un unless, puisque ce ne sont pas des boucles. Mais vous pouvez toujours ajouter une paire d'accolades supplémentaires pour construire un bloc simple qui lui est une boucle :
if (/pattern/) {{
last if /alpha/;
last if /beta/;
last if /gamma/;
# ne fait quelque chose que si on se trouve encore dans le if()
}}Voici comment utiliser un bloc pour faire fonctionner les opérateurs de contrôle de boucle avec une construction do {}. Pour faire un next ou un redo sur un do, ajouter un bloc simple à l'intérieur :
Vous devez être plus subtil pour last :
Et si vous voulez vous servir des deux contrôles de boucle disponibles, vous allez devoir distinguer ces blocs avec des étiquettes :
DO_LAST: {
do {
DO_NEXT: {
next DO_NEXT if $x == $y;
last DO_LAST if $x = $y ** 2;
# faire quelque chose ici
}
} while $x++ <= $z;
}Mais quand vous en arrivez à ce point (ou même avant), vous feriez mieux d'utiliser une simple boucle infinie avec un last à la fin :
for (;;) {
next if $x == $y;
last if $x = $y ** 2;
# faire quelque chose ici
last unless $x++ <= $z;
}4-5-a. Structures de cas▲
Contrairement à d'autres langages de programmation, Perl n'a pas d'instruction switch ou case officielle. Perl n'en a pas besoin, puisqu'il y a plus d'une manière de faire la même chose. Un bloc simple est particulièrement commode pour construire des structures à choix multiples. En voici une :
SWITCH: {
if (/^abc/) { $abc = 1; last SWITCH; }
if (/^def/) { $def = 1; last SWITCH; }
if (/^xyz/) { $xyz = 1; last SWITCH; }
$rien = 1;
}et une autre :
SWITCH: {
/^abc/ && do { $abc = 1; last SWITCH; };
/^def/ && do { $def = 1; last SWITCH; };
/^xyz/ && do { $xyz = 1; last SWITCH; };
$rien = 1;
}ou, formaté pour que chaque cas ressorte mieux :
SWITCH: {
/^abc/ && do {
$abc = 1;
last SWITCH;
};
/^def/ && do {
$def = 1;
last SWITCH;
};
/^xyz/ && do {
$xyz = 1;
last SWITCH;
};
$rien = 1;
}ou même, horreur :
if (/^abc/) { $abc = 1; }
elsif (/^def/) { $def = 1; }
elsif (/^xyz/) { $xyz = 1; }
else { $rien = 1; }Remarquez comme dans cet exemple l'opérateur last ignore les blocs do, qui ne sont pas des boucles, et sort de la boucle for :
for ($nom_de_variable_tres_long[$i++][$j++]->methode()) {
/ce motif/ and do { push @flags, '-e'; last; };
/celui-là/ and do { push @flags, '-h'; last; };
/quelque chose d'autre/ and do { last; };
die "valeur inconnue: `$_'";
}Vous pouvez trouver bizarre de boucler sur une seule valeur, puisque vous n'allez traverser qu'une fois la boucle, mais il est commode de pouvoir utiliser les capacités d'alias de for/foreach pour affecter $_ temporairement et localement. Cela rend les comparaisons multiples à la même valeur beaucoup plus faciles à taper et il est donc plus difficile de se tromper. On échappe aux effets secondaires d'une nouvelle évaluation de l'expression. Et pour rester en rapport avec cette section, c'est l'un des idiomes les plus répandus pour implémenter une structure de cas.
Pour des cas simples, une cascade d'opérateurs ?: peut également marcher. Ici encore, nous utilisons les capacités d'alias de for afin de rendre les comparaisons multiples plus lisibles :
for ($couleur_utilisateur) {
$value = /rouge/ ? 0xFF0000 :
/vert/ ? 0x00FF00 :
/bleu/ ? 0x0000FF :
0x000000 ; # noir s'il n'y a plus d'espoir
}Dans des situations comme celle-ci, il vaut parfois mieux vous construire un hachage et le classer rapidement pour en tirer la réponse. Contrairement aux conditions en cascade que nous avons vues, un hachage peut croître à un nombre illimité d'éléments sans prendre plus de temps pour trouver le premier ou le dernier élément. L'inconvénient est que vous ne pourrez faire que des comparaisons exactes et pas des recherches de motif. Si vous avez un hachage comme celui-ci :
%couleur = (
azur => 0xF0FFFF,
chartreuse => 0x7FFF00,
lavande => 0xE6E6FA,
magenta => 0xFF00FF,
turquoise => 0x40E0D0,
);alors une recherche exacte de chaîne tourne vite :
$valeur = $couleur{ lc $couleur_utilisateur } || 0x000000;Même les instructions compliquées de branchement multiple (où chaque cas implique l'exécution de plusieurs instructions différentes) peuvent se transformer en une rapide consultation. Vous avez juste besoin de vous servir d'un hachage de références à des functions. Pour savoir comment les manipuler, voyez la section Hachages de fonctions au chapitre 9, Structures de données.
4-6. goto▲
Perl supporte aussi un opérateur goto, mais il n'est pas destiné aux œurs sensibles. Il se présente sous trois formes : goto LABEL, goto EXPR et goto &NOM.
La forme goto LABEL trouve l'instruction étiquetée avec LABEL et reprend l'exécution à partir de là. Elle ne peut pas servir à sauter à l'intérieur d'une structure qui nécessite une initialisation, comme un sous-programme ou une boucle foreach. Elle ne peut pas non plus servir pour entrer dans une structure qui a été éliminée lors de l'optimisation (voir le chapitre 18, Compilation). Elle peut servir pour aller à peu près n'importe où dans le bloc courant ou dans un bloc dans votre portée dynamique (c'est-à-dire un bloc duquel vous avez été appelé). Vous pouvez même sortir d'un sous-programme par goto, mais il vaut en général mieux utiliser une autre construction. L'auteur de Perl n'a jamais ressenti le besoin d'utiliser cette forme de goto (en Perl ; en C, c'est une autre affaire).
La forme goto EXPR n'est qu'une généralisation de goto LABEL. Elle attend de l'expression qu'elle produise un nom d'étiquette, dont la position doit évidemment être résolue dynamiquement par l'interpréteur. Cela permet des goto calculés à la FORTRAN, mais n'est pas nécessairement recommandé si vous cherchez à optimiser la maintenabilité du code :
goto(("TOTO", "TITI", "TUTU")[$i]); # en espérant que 0 <= i < 3
@loop_label = qw/TOTO TITI TUTU/;
goto $loop_label[rand @loop_label]; # téléportation au hasardDans presque tous les cas de ce genre, il est très, très largement préférable d'utiliser les mécanismes structurés de contrôle de flux de next, last ou redo au lieu d'avoir recours à un goto. Pour certaines applications, un hachage de références à des fonctions ou le mécanisme de capture et de gestion d'exceptions s'appuyant sur eval et die sont des approches prudentes.
La forme goto &NAME est fortement magique et suffisamment éloignée du goto usuel pour exempter ceux qui l'utilisent de l'opprobre qui couvre habituellement les utilisateurs de goto. Elle substitue à la routine en cours d'exécution un appel au sous-programme nommé. Ce fonctionnement est utilisé par les routines AUTOLOAD pour charger un autre sous-programme et faire croire que c'est cet autre sous-programme qui était appelé. Après le goto, même caller ne pourra dire que cette routine a été appelée en premier. Les modules autouse, AutoLoader et SelfLoader utilisent tous cette stratégie pour définir les fonctions lorsqu'elles sont appelées pour la première fois puis les lancer sans que personne ne puisse jamais savoir que ces fonctions n'ont pas toujours été là.
4-7. Déclarations globales▲
Les déclarations de sous-programmes et de formats sont des déclarations globales. Où que vous les placiez, ce qu'elles déclarent est global (c'est local au paquetage, mais comme les paquetages sont globaux au programme, tout ce qui est dans un paquetage est visible de partout). Une déclaration globale peut être placée partout où l'on peut mettre une instruction, mais n'a aucun effet sur l'exécution de la séquence primaire d'instructions, les déclarations prennent effet à la compilation.
Cela signifie que vous ne pouvez pas faire de déclaration conditionnelle de sous-programmes ou de formats et les cacher du compilateur au moyen d'une condition qui ne sera prise en compte qu'à l'exécution. Le compilateur voit les déclarations de sous-programmes et de formats (ainsi que les déclarations use et no) où qu'elles se produisent.
Les déclarations globales sont généralement mises au début ou à la fin de votre programme, ou dans un autre fichier. Cependant si vous déclarez des variables à portée lexicale (voir la section suivante), vous devrez vous assurer que vos déclarations de formats et de sous-programmes sont à portée de vos déclarations de variables si vous espérez accéder à ces variables privées.
Vous avez remarqué que nous sommes sournoisement passés des déclarations aux définitions. Séparer la définition de la déclaration a parfois un intérêt. La seule différence syntaxique entre les deux est que la définition fournit un BLOC contenant le code à exécuter, et pas la déclaration. (Une définition de sous-programme agit comme une déclaration si aucune déclaration n'a été vue.) Séparer la définition de la déclaration vous permet de mettre la déclaration au début du fichier et la définition à la fin (avec vos variables lexicales joyeusement au milieu) :
sub compte (@); # Le compilateur sait maintenant comment appeler
# compte().
my $x; # Le compilateur connaît maintenant la variable
# lexicale.
$x = compte(3,2,1); # Le compilateur peut valider l'appel de fonction.
sub compte (@) { @_ } # Le compilateur sait maintenant ce que fait compte().Comme le montre cet exemple, les sous-programmes n'ont pas besoin d'être définis avant que les appels vers eux soient compilés (en fait, leur définition peut même être repoussée jusqu'à leur première utilisation, si vous utilisez l'autochargement), mais la déclaration des sous-programmes aide le compilateur de différentes manières et vous donne plus de choix dans votre façon de les appeler.
La déclaration d'un sous-programme lui permet d'être utilisé sans parenthèses, comme s'il s'agissait d'un opérateur intégré depuis ce point de la compilation. (Nous avons utilisé des parenthèses pour appeler compte dans l'exemple précédent, mais en fait nous n'en avions pas besoin.) Vous pouvez déclarer un sous-programme sans le définir juste en disant :
Une déclaration simple comme celle-ci déclare la fonction comme un opérateur de liste et non comme un opérateur unaire, aussi faites attention à utiliser or et non || dans ce cas. L'opérateur || lie trop fortement pour être utilisé après des opérateurs de liste, même si vous pouvez toujours mettre des parenthèses autour des arguments de l'opérateur de liste pour le changer en appel de fonction. Autrement, vous pouvez utiliser le prototype ($) pour transformer la routine en opérateur unaire :
C'est maintenant analysé comme vous vous y attendez, mais vous devriez tout de même garder l'habitude d'utiliser or dans cette situation. Pour en savoir plus sur les prototypes, voir le chapitre 6, Sous-programmes.
Vous devez définir le sous-programme à un moment donné, sinon vous obtiendrez une erreur à l'exécution indiquant que vous avez appelé un sous-programme indéfini. À moins de définir le sous-programme vous-même, vous pouvez récupérer les définitions depuis d'autres endroits de plusieurs façons.
Vous pouvez charger les définitions depuis d'autres fichiers avec une simple instruction require ; c'était la meilleure manière de charger des fichiers en Perl 4, mais elle pose deux problèmes. Premièrement, l'autre fichier va typiquement insérer des noms de sous-programmes dans un paquetage (une table de symboles) de son choix, et non vos propres paquetages. Deuxièmement, un require se produit à l'exécution et donc arrive trop tard pour servir de déclaration dans le fichier invoquant le require. Il arrive cependant que vous cherchiez justement à retarder le chargement.
Une manière plus utile de charger les déclarations et les définitions est la déclaration use, qui fait un require du module à la compilation (car use compte comme un bloc BEGIN) et vous laisse importer une partie des déclarations du module dans votre propre programme. On peut donc considérer use comme une déclaration globale en ce qu'elle importe les noms à la compilation dans votre propre paquetage (global) comme si vous les aviez déclarés vous-même. Voir la section Tables de symboles, au chapitre 10, Paquetages au sujet du fonctionnement bas niveau de l'importation entre paquetages, le chapitre 11, Modules, pour savoir comment configurer les paramètres d'importation et d'exportation des modules, et le chapitre 18 pour une explication de BEGIN et de ses cousins CHECK, INIT et END, qui sont aussi des sortes de déclarations globales puisqu'elles sont traitées à la compilation et peuvent avoir un effet global.
4-8. Déclarations avec portée▲
Comme les déclarations globales, les déclarations à portée lexicale ont un effet au moment de la compilation. Contrairement aux déclarations globales, les déclarations à portée lexicale ne s'appliquent que du point de déclaration jusqu'à la fin du bloc encadrant le plus interne (le premier bloc, fichier ou eval trouvé). C'est pourquoi nous les appelons à portée lexicale, bien que le terme « portée textuelle » soit peut-être plus exact, puisque la portée lexicale n'a rien à voir avec les lexiques. Mais les informaticiens du monde entier savent ce que signifie « portée lexicale », aussi perpétuons-nous cet usage ici.
Perl supporte aussi les déclarations à portée dynamique. Une portée dynamique s'étend aussi jusqu'à la fin du bloc encadrant le plus interne, mais « encadrant » dans ce cas est défini dynamiquement à l'exécution, plutôt que textuellement à la compilation. Pour le dire autrement, les bloc s'emboîtent dynamiquement en invoquant d'autres blocs, pas en les incluant. Cet emboîtement de portées dynamiques peut être corrélé en quelque sorte à l'emboîtement des portées lexicales, mais les deux sont en général différents, particulièrement quand des sous-programmes ont été invoqués.
Nous avons mentionné que certains aspects de use pouvaient être considérés comme des déclarations globales, mais d'autres aspects de use sont à portée lexicale. En particulier, use n'importe pas seulement les symboles, mais implémente également diverses directives de compilation magiques, connues sous le nom de pragmas (ou si vous préférez la forme classique, pragmata). La plupart des pragmas sont à portée lexicale, y compris le pragma use strict 'vars' qui vous oblige à déclarer vos variables avant de vous en servir. Voir plus loin la section Pragmas.
Une déclaration package, curieusement, est elle-même à portée lexicale, malgré le fait qu'un paquetage est une entité globale. Mais une déclaration package se contente de déclarer l'identité du paquetage par défaut pour le reste du bloc l'encadrant. Les noms de variables non déclarés, non qualifiés(64) sont recherchés dans ce paquetage. En un sens, un paquetage n'est jamais déclaré du tout, mais il se met à exister quand vous faites référence à quelque chose qui appartient à ce paquetage. C'est très Perlien.
4-8-a. Déclarations de variables à portée limitée▲
Le reste de ce chapitre parle surtout de l'utilisation de variables globales. Ou plutôt, parle de la non-utilisation de variables globales. Il existe plusieurs déclarations qui vous aident à ne pas utiliser de variables globales — ou au moins à ne pas les utiliser bêtement.
Nous avons déjà mentionné la déclaration package, qui a été introduite en Perl il y a bien longtemps pour pouvoir séparer les variables globales en paquetages séparés. Cela marche assez bien pour un certain type de variables. Les paquetages sont utilisés par des bibliothèques, des modules et des classes pour stocker leurs données d'interface (et certaines de leurs données semi-privées) pour éviter les conflits avec des variables et des fonctions de même nom dans votre programme principal ou dans d'autres modules. Si vous voyez quelqu'un écrire $Quelque::chose,(65) il se sert de la variable scalaire $chose du paquetage Quelque. Voir le chapitre 10.
Si c'était tout ce qu'il existait en la matière, les programmes Perl deviendraient de plus en plus difficiles à manipuler en grossissant. Heureusement, les trois déclarations de portée de Perl permettent de créer facilement des variables complètement privées (avec my), de donner sélectivement l'accès aux globales (avec our) et de donner des valeurs temporaires à des variables globales (avec local).
Si plusieurs variables sont listées, la liste doit être placée entre parenthèses. Pour my et our, les éléments ne peuvent être que de simples scalaires, tableaux ou hachages. Pour local, les contraintes sont quelque peu relâchées : vous pouvez également localiser des typeglobs en entier ou de simples éléments, ou des tranches de tableaux ou de hachages :
Chacun de ces modificateurs propose une sorte d'isolation différente aux variables qu'il modifie. Pour simplifier légèrement : our confine les noms à une portée, local confine les valeurs à une portée, et my confine à la fois les noms et les valeurs à une portée.
Ces constructions peuvent se voir affecter des valeurs, mais diffèrent en ce qu'elles font réellement avec ces valeurs, puisqu'elles proposent des mécanismes différents de stockage des valeurs. Elles sont aussi quelque peu différentes quand vous ne leur affectez aucune valeur (comme dans notre exemple ci-dessus) : my et local font démarrer les variables en question à la valeur undef ou () appropriée selon le contexte ; our au contraire ne modifie pas la valeur de la variable globale associée.
Syntaxiquement, my, our et local sont simplement des modificateurs (comme des adjectifs) agissant sur une lvalue. Quand vous affectez à une lvalue modifiée, le modificateur ne change pas le fait que la lvalue soit vue comme un scalaire ou une liste. Pour savoir comment le modificateur va fonctionner, faites comme s'il n'était pas là. Ces deux constructions fournissent donc un contexte de liste du côté droit :
Tandis que celle-ci fournit un contexte scalaire :
my $toto = <STDIN>;Les modificateurs lient plus fort (avec une précédence supérieure) que l'opérateur virgule. L'exemple suivant ne déclare qu'une variable au lieu de deux, car la liste qui suit le modificateur n'est pas entre parenthèses.
my $toto, $titi = 1; # FAUXCela a le même effet que :
my $toto;
$titi = 1;Vous serez averti de cette erreur si vous avez demandé les avertissements, avec les options de ligne de commande -w ou -W, ou de préférence avec la déclaration use warnings expliquée plus loin dans la section Pragmas.
En général, il vaut mieux déclarer une variable dans la plus petite portée nécessaire. Comme les variables déclarées dans des instructions de contrôle de flux ne sont visibles que dans le bloc concerné par cette instruction, leur visibilité est réduite. Cela se lit également mieux en anglais (ce qui a moins d'intérêt pour ceux qui codent en français).
sub verifie_stock {
for my $machin (our @Inventaire) {
print "J'ai un $machin en stock aujourd'hui.\n";
}
}La forme de déclaration la plus fréquente est my, qui déclare des variables à portée lexicale dont le nom et la valeur sont stockés dans le bloc-note temporaire de la portée en cours et ne peuvent être accédés de manière globale. La déclaration our est très proche de cela, et fait entrer un nom lexical dans la portée en cours, tout comme my, mais pointe en réalité vers une variable globale à laquelle n'importe qui pourrait accéder s'il le voulait. En d'autres termes, c'est une variable globale maquillée en variable lexicale.
L'autre forme de portée, la portée dynamique, s'applique aux variables déclarées avec local, qui malgré l'emploi du mot « local » sont en fait des variables globales qui n'ont rien à voir avec le bloc-notes local.
4-8-b. Variables à portée lexicale : my▲
Pour vous éviter le casse-tête du suivi des variables globales, Perl fournit des variables à portée lexicale, appelées parfois lexicales pour faire court. Contrairement aux globales, les lexicales vous garantissent le secret de vos variables. Tant que vous ne distribuez pas des références à ces variables privées qui permettraient de les tripatouiller indirectement, vous pouvez être sûr que tous les accès possibles à ces variables privées sont restreints au code contenu dans une section limitée et aisément identifiable de votre programme. Après tout, c'est la raison pour laquelle nous avons choisi le mot-clef my.
Une séquence d'instructions peut contenir des déclarations de variables à portée lexicale. De telles déclarations sont habituellement placées au début de la séquence d'instructions, mais ce n'est pas une obligation. En plus de déclarer les noms de variables à la compilation, les déclarations fonctionnent comme des instructions normales à l'exécution : chacune d'entre elles est élaborée dans la séquence d'instructions comme s'il s'agissait d'une instruction usuelle sans le modificateur :
my $nom = "fred";
my @affaires = ("voiture", "maison", "marteau");
my ($vehicule, $domicile, $outil) = @affaires;Ces variables lexicales sont totalement cachées du monde à l'extérieur de la portée les contenant immédiatement. Contrairement aux effets de portée dynamique de local (voir la section suivante), les lexicales sont cachées à tout sous-programme appelé depuis leur portée. Cela reste vrai même si le même sous-programme est appelé depuis lui-même ou ailleurs — chaque instance du sous-programme possède son propre « bloc-notes » de variables lexicales.
Contrairement aux portées de blocs, les portées de fichiers ne s'emboîtent pas ; il ne se produit pas d'« inclusion », tout au moins pas textuellement. Si vous chargez du code d'un autre fichier avec do, require ou use, le code contenu dans ce fichier ne pourra pas accéder à vos variables lexicales, tout comme vous ne pourrez pas accéder aux siennes.
Cependant toute portée à l'intérieur d'un fichier (ou même le fichier lui-même) fait l'affaire. Il est souvent utile d'avoir des portées plus larges que la définition de sous-programme, car cela vous permet de partager des variables privées avec un nombre limité de routines. C'est ainsi que vous créez des variables qu'un programmeur C appellerait « statiques » :
{
my $etat = 0;
sub on { $etat = 1 }
sub off { $etat = 0 }
sub change { $etat = !$etat }
}L'opérateur eval CHAINE fonctionne aussi comme une portée emboîtée, puisque le code à l'intérieur de l'eval peut voir les variables lexicales de l'appelant (tant que leurs noms ne sont pas cachés par des déclarations identiques dans la portée définie par l'eval lui-même). Les routines anonymes peuvent de même accéder à n'importe quelle variable lexicale des portées les renfermant ; si elles le font, elles sont alors nommées fermetures.(66) En combinant ces deux notions, si un bloc evalue une chaîne qui crée un sous-programme anonyme, ce sous-programme devient une fermeture avec accès complet aux lexicales de l'eval et du bloc, même après que le l'eval et le bloc se sont terminés. Voir la section Fermetures au chapitre 8.
La variable nouvellement déclarée (ou la valeur, dans le cas de local) n'apparaît pas avant la fin de l'instruction suivant l'instruction contenant la déclaration. Vous pourriez donc copier une variable de cette façon :
my$x = $x;Cela initialise le nouveau $x interne avec la valeur courante de $x, que la signification de $x soit globale ou lexicale. (Si vous n'initialisez pas la nouvelle variable, elle démarre avec une valeur vide ou indéfinie.)
La déclaration d'une variable lexicale d'un nom donné cache toute variable lexicale du même nom déclarée précédemment. Elle cache aussi toute variable globale non qualifiée du même nom, mais celle-ci reste toujours accessible en la qualifiant explicitement avec le nom du paquetage la contenant, par exemple $NomPaquetage::nomvar.
4-8-c. Déclarations de globales à portée lexicale : our▲
La déclaration our est une meilleure manière d'accéder aux globales, en particulier pour les programmes et les modules tournant avec la déclaration use strict. Cette déclaration est à portée lexicale dans le sens où elle ne s'applique que jusqu'à la fin de la portée courante. Mais contrairement au my à portée lexicale ou au local à portée dynamique, our n'isole rien dans la portée lexicale ou dynamique en cours. En fait, il donne accès à une variable globale dans le paquetage en cours, en cachant les lexicales de même nom qui vous auraient sinon empêché de voir cette globale. À cet égard, nos variables our fonctionnent tout comme mes variables my.
Si vous placez une déclaration our en dehors de tout bloc délimité par des accolades, elle dure jusqu'à la fin de l'unité de compilation en cours. Souvent, on la place juste au début de la définition d'un sous-programme pour indiquer qu'il accède à une variable globale :
sub verifie_entrepot {
our @Inventaire_Courant;
my $machin;
foreach $machin (@Inventaire_Courant) {
print "J'ai un $machin en stock aujourd'hui.\n";
}
}Comme les variables globales ont une durée de vie plus longue et une visibilité plus large que les variables privées, nous préférons utiliser pour elles des noms plus longs et plus voyants que pour les variables temporaires. Cette simple habitude, si elle est suivie consciencieusement, peut faire autant que use strict pour décourager l'emploi de variables globales, particulièrement chez ceux qui ne sont pas des virtuoses du clavier.
Des déclarations our répétées ne s'emboîtent pas clairement. Chaque my emboîté produit une nouvelle variable, et chaque local emboîté produit une nouvelle valeur. Mais à chaque fois que vous employez our, vous mentionnez la même variable globale, sans notion d'emboîtement. Quand vous affectez à une variable our, les effets de cette affectation persistent une fois hors de portée de la déclaration. C'est parce que our ne crée jamais de valeur ; il donne seulement une forme d'accès limité à la globale qui, elle, existe pour toujours :
our $NOM_PROGRAMME = "client";
{
our $NOM_PROGRAMME = "serveur";
# Le code appelé d'ici voit "serveur".
...
}
# Le code exécuté ici voit toujours "serveur".Comparez ceci avec ce qui arrive avec my ou local, quand la variable ou la valeur redevient visible après le bloc :
my $i = 10;
{
my $i = 99;
...
}
# Le code compilé ici voit la variable externe.
local $NOM_PROGRAMME = "client";
{
local $NOM_PROGRAMME = "serveur";
# Le code appelé d'ici voit "serveur".
...
}
# Le code exécuté ici voit "client" de nouveau.Faire une déclaration our n'a en général de sens qu'une seule fois, probablement tout au début de votre programme ou module ou, plus rarement, quand vous préfixez le our de son propre local :
4-8-d. Variables à portée dynamique : local▲
L'utilisation de l'opérateur local sur une variable globale lui donne une valeur temporaire à chaque fois que local est exécuté, mais n'affecte pas la visibilité globale de cette variable. Quand le programme atteint la fin de cette portée dynamique, cette valeur temporaire est jetée et la valeur précédente restaurée. Mais pendant que ce bloc s'exécute, c'est toujours une variable globale qui se trouve juste contenir une valeur temporaire. Si vous appelez une autre fonction pendant que votre variable globale contient la valeur temporaire et que cette fonction accède à cette variable globale, elle verra la valeur temporaire et pas la valeur initiale. En d'autres termes, cette autre fonction est dans votre portée dynamique, même si elle n'est probablement pas dans votre portée lexicale.(67)
Si vous avez un local qui ressemble à ceci :
{
local $var = $nouveau;
ma_fonction();
...
}vous pouvez le voir entièrement en termes d'affectations à l'exécution :
{
$ancien = $var;
local $var = $nouveau;
ma_fonction();
...
}
continue {
$var = $ancien;
}La différence est qu'avec local, la valeur est restaurée quelle que soit la manière dont vous quittez le bloc, même si vous sortez de cette portée en faisant un return prématuré. La variable est toujours la même variable globale, mais la valeur qui s'y trouve dépend de la portée d'où la fonction a été appelée. C'est pourquoi on l'appelle portée dynamique : parce qu'elle change au cours de l'exécution.
Comme avec my, vous pouvez initialiser un local avec une copie de la même variable globale. Toutes les modifications faites à cette variable pendant l'exécution du sous-programme (et de tous les autres appelés depuis celui-ci, qui peuvent bien sûr voir cette globale à portée dynamique) seront perdues quand la routine se terminera. Vous devriez sûrement commenter ce que vous faites :
# ATTENTION : les modifications sont temporaires
# pour cette portée dynamique
local $Ma_Globale = $Ma_Globale;Une variable globale est donc toujours visible dans l'intégralité de votre programme, qu'elle ait été déclarée avec our, qu'elle ait été créée à la volée ou qu'elle contienne une valeur locale destinée à être jetée une fois hors de portée. Ce n'est pas compliqué pour de petits programmes. Mais vous allez rapidement ne plus retrouver où sont utilisées ces variables globales dans de plus gros programmes. Si vous voulez, vous pouvez interdire l'utilisation accidentelle de variables globales à l'aide du pragma use strict 'vars', décrit à la section suivante.
Bien que my et local confèrent toutes deux un certain niveau de protection, vous devriez largement préférer my à local. Cependant, vous devrez de temps en temps utiliser local pour pouvoir modifier temporairement la valeur d'une variable globale existante, comme celles décrites au chapitre 28, Noms spéciaux. Seuls les identificateurs alphanumériques peuvent avoir une portée lexicale et beaucoup de ces variables spéciales ne sont pas strictement alphanumériques. Vous aurez aussi besoin de local pour faire des modifications temporaires à la table des symboles d'un paquetage, comme c'est décrit dans la section Tables de symboles au chapitre 10. Enfin, vous pouvez aussi utiliser local sur un élément isolé ou toute une tranche d'un tableau ou d'un hachage. Cela fonctionne même si le tableau ou le hachage est en fait une variable lexicale, en rajoutant la couche de comportement de portée dynamique de local au-dessus de ces variables lexicales. Nous ne parlerons pas plus de la sémantique de local ici. Pour plus d'informations, voir local au chapitre 29.
4-9. Pragmas▲
De nombreux langages de programmation vous permettent de donner des directives au compilateur. En Perl ces directives sont passées au compilateur par la déclaration use. Certains de ces pragmas sont :
use warnings;
use strict;
use integer;
use bytes;
use constant pi => ( 4 * atan2(1,1) );Les pragmas de Perl sont décrits au chapitre 31, Modules de pragmas, mais nous allons tout de suite parler des plus utiles par rapport au contenu de ce chapitre.
Bien que certains soient des déclarations qui affectent les variables globales ou le paquetage en cours, la plupart des pragmas sont des déclarations à portée lexicale dont les effets ne durent que jusqu'à la fin du bloc, du fichier ou de l'eval qui les contient (en fonction du premier qui se présente). Un pragma à portée lexicale peut être annulé dans une portée incluse avec une déclaration no, qui fonctionne exactement comme use, mais à l'envers.
4-9-a. Contrôle des avertissements▲
Pour vous montrer comment tout cela fonctionne, nous allons manipuler le pragma warnings pour dire à Perl s'il doit nous avertir de pratiques discutables :
use warnings; # Permet les avertissements d'ici à la fin de fichier
...
{
no warnings; # Désactive les avertissements dans le bloc
...
}
# Les avertissements sont automatiquement réactivés iciUne fois les avertissements demandés, Perl vous signalera les variables utilisées une seule fois, les déclarations qui cachent d'autres déclarations dans la même portée, les conversions incorrectes de chaînes en nombres, l'utilisation de valeurs indéfinies comme des nombres ou des chaînes normaux, les tentatives d'écriture sur des fichiers ouverts en lecture seule (ou pas ouverts du tout) et bien d'autres problèmes potentiels listés au chapitre 33, Messages de diagnostic.
La méthode de contrôle des avertissements recommandée est l'utilisation de use warnings. Les anciens programmes ne pouvaient utiliser que l'option de ligne de commande -w ou bien modifier la variable globale $^W :
{
local $^W = 0;
...
}Il vaut beaucoup mieux utiliser les pragmas use warnings et no warnings. Un pragma vaut mieux, car il se produit à la compilation, parce que c'est une déclaration lexicale et ne peut donc pas affecter du code qu'il n'était pas censé affecter, et (bien que nous ne vous l'ayons pas montré dans ces simples exemples) qu'il permet un contrôle plus fin sur plusieurs ensembles de classes. Pour en savoir plus sur le pragma warnings, y compris comment transformer des avertissements qui font juste un peu de bruit en erreurs fatales et comment supplanter le pragma pour activer les avertissements même si le module ne veut pas, voir use warnings au chapitre 31.
4-9-b. Contrôle de l'utilisation des globales▲
Une autre déclaration communément rencontrée est le pragma use strict, qui a plusieurs fonctions dont celle de contrôler l'utilisation des variables globales. Normalement, Perl vous laisse créer de nouvelles variables (ou trop souvent, écraser d'anciennes variables) simplement en les citant. Aucune déclaration de variable n'est nécessaire (par défaut). Sachant que l'utilisation débridée de globales peut rendre les gros programmes ou les gros modules pénibles à maintenir, vous pourrez vouloir décourager leur utilisation accidentelle. Pour prévenir de tels accidents, vous pouvez écrire :
Cela signifie que toute variable mentionnée à partir d'ici jusqu'à la fin de la portée courante doit faire référence soit à une variable lexicale, soit à une variable globale explicitement autorisée. Si ce n'est pas le cas, une erreur de compilation se produit. Une variable globale est explicitement autorisée si l'une de ces propositions est vraie :
- C'est l'une des variables spéciales de Perl (voir le chapitre 28).
- Elle est complètement définie avec son nom de paquetage (voir le chapitre 10).
- Elle a été importée dans le paquetage courant (voir le chapitre 11).
- Elle se fait passer pour une variable lexicale à l'aide d'une déclaration our. (C'est la raison principale pour laquelle nous avons ajouté la déclaration our à Perl.)
Bien sûr, il reste toujours la cinquième possibilité. Si le pragma est trop exigeant, annulez-le simplement dans un bloc intérieur avec :
Avec ce pragma vous pouvez aussi demander une vérification stricte des déréférencements symboliques et de l'utilisation des mots simples. Habituellement, les gens tapent juste :
pour mettre en œuvre les trois restrictions. Pour plus d'informations, voir l'entrée use strict, au chapitre 31.
5. Recherche de motif▲
Le support intégré de Perl pour la recherche de motif vous permet de rechercher dans de grandes quantités de données simplement et efficacement. Que vous fassiez tourner un énorme site portail commercial balayant tous les groupes de news existants à la recherche de potins intéressants, un organisme public occupé à comprendre la démographie humaine (ou le génome humain), une institution scolaire désireuse de mettre des informations dynamiques sur votre site web, Perl est l'outil qu'il vous faut ; d'une part à cause de ses liens avec les bases de données, mais surtout à cause de ses capacités de recherche de motif. Si vous prenez le mot « texte » dans son sens le plus large, près de 90 % de tout ce vous faites est du traitement de texte. C'est vraiment ce pour quoi Perl est fait et a toujours été fait — en fait, cela fait même partie de son nom : Practical Extraction and Report Language. Les motifs de Perl fournissent de puissants moyens pour ratisser des montagnes de données brutes et en extraire de l'information utile.
Vous spécifiez un motif en créant une expression rationnelle (ou expression régulière(68) ou regex) et le moteur d'expressions régulières de Perl (le « Moteur », pour le reste de ce chapitre) prend cette expression et détermine si (et comment) le motif correspond à vos données. Alors que la plupart de vos données seront probablement des chaînes de caractères, rien ne vous empêche de vous servir des regex pour rechercher et remplacer n'importe quelle séquence de bits, y compris ce que vous auriez cru être des données « binaires ». Pour Perl, les octets sont juste des caractères qui ont une valeur ordinale inférieure à 256. (Pour en savoir plus sur ce sujet, voir le chapitre 15, Unicode.)
Si vous connaissiez déjà les expressions régulières avec d'autres outils, nous devons vous prévenir que celles de Perl sont un peu différentes. Premièrement elles ne sont pas vraiment « régulières » (ou « rationnelles ») au sens théorique du mot, ce qui signifie qu'elles peuvent faire beaucoup plus que les expressions rationnelles qu'on apprend en cours d'informatique. Deuxièmement, elles sont tellement utilisées en Perl, qu'elles ont leurs propres variables spéciales et leurs propres conventions de citation qui sont étroitement intégrées au langage, pas vaguement liées comme n'importe quelle autre librairie. Les nouveaux programmeurs Perl cherchent souvent en vain des fonctions comme :
match( $chaine, $motif );
subst( $chaine, $motif, $remplacement );Mais la recherche et la substitution sont deux tâches si fondamentales en Perl qu'elles méritent leurs propres opérateurs d'une lettre : m/MOTIF/ et s/MOTIF/REMPLACEMENT/. Ils sont non seulement brefs syntaxiquement, mais ils sont aussi analysés comme des chaînes entre apostrophes doubles plutôt que comme des opérateurs ordinaires ; toutefois, ils fonctionnent comme des opérateurs, c'est pourquoi nous les appelons ainsi. Tout au long de ce chapitre, vous les verrez utilisés pour comparer des motifs à des chaînes. Si une partie de la chaîne correspond au motif, nous disons que la correspondance (ou recherche) est réussie. Il y a plein de trucs sympas à faire avec des correspondances réussies. En particulier, si vous utilisez s///, une correspondance réussie provoque le remplacement de la partie correspondante dans la chaîne parce que vous avez spécifié comme REMPLACEMENT.
Tout ce chapitre concerne la construction et l'utilisation de motifs. Les expressions régulières de Perl sont puissantes, et concentrent beaucoup de sens en peu de volume. Elles peuvent donc vous intimider si vous essayez de saisir le sens d'un long motif d'un seul coup. Mais si vous pouvez le découper en petits morceaux et que vous savez comment le Moteur interprète ces morceaux, vous pouvez comprendre n'importe quelle expression régulière. Il n'est pas rare de voir une centaine de lignes de code C ou Java exprimées en une expression régulière d'une ligne en Perl. Cette expression régulière est peut-être un peu plus difficile à comprendre que n'importe quelle ligne du gros programme ; d'un autre côté, la regex sera beaucoup plus facile à comprendre que le plus long programme pris dans son ensemble. Il vous faut juste garder tout cela en perspective.
5-1. Bestiaire des expressions régulières▲
Avant de nous plonger dans les règles d'interprétation des expressions régulières, regardons à quoi certains motifs ressemblent. La plupart des caractères d'une expression régulière se correspondent à eux-mêmes. Si vous enchaînez plusieurs caractères à la suite, ils se correspondent dans l'ordre, comme on s'y attend. Donc si vous écrivez la recherche suivante :
/Frodon/vous pouvez être sûr que le motif ne correspondra que si la chaîne contient quelque part la sous-chaîne « Frodon ». (Une sous-chaîne est juste un morceau de chaîne.) La correspondance peut se faire n'importe où dans la chaîne, tant que ces six caractères apparaissent quelque part, l'un après l'autre et dans cet ordre.
D'autres caractères ne se correspondent pas à eux-mêmes, mais se comportent d'une étrange manière. Nous les appelons métacaractères. (Tous les métacaractères sont des coquins, mais certains sont si mauvais, qu'ils conduisent les caractères voisins à se comporter aussi mal qu'eux.)
Voici les scélérats :
\|()[ { ^ $ * + ? .Les métacaractères sont en fait très utiles et ont une signification spéciale à l'intérieur des motifs. Nous vous expliquerons toutes ces significations au fur et à mesure de ce chapitre. Mais sachez d'abord que vous pourrez toujours détecter n'importe lequel de ces douze caractères en le faisant précéder d'un antislash. Par exemple, comme l'antislash est un métacaractère, pour détecter un antislash, vous devrez l'antislasher : \\.
Vous voyez, l'antislash est le genre de caractère qui pousse les autres caractères à mal se conduire. Finalement, quand vous faites mal se conduire un métacaractère indiscipliné, il se conduit bien — un peu comme une double négation. Antislasher un caractère pour le prendre littéralement marche, mais seulement sur les caractères de ponctuation ; antislasher un caractère alphanumérique (qui habituellement se comporte correctement) fait le contraire : cela transforme le caractère littéral en quelque chose de spécial. Dès que vous voyez une telle séquence de deux caractères :
\b\D \t\3 \svous saurez que la séquence est un métasymbole qui correspond à quelque chose d'étrange. Par exemple, \b correspond à une limite de mot, tandis que \t correspond à un caractère de tabulation ordinaire. Remarquez qu'une tabulation fait un caractère de large, alors que la limite de mot a une largeur de zéro caractère, puisque c'est un point entre deux caractères. Nous appellerons donc \b une assertion de largeur nulle. Cependant, \t et \b se ressemblent en ce qu'ils supposent quelque chose sur une caractéristique de la chaîne. À chaque fois que vous faites une assertion au sujet de quelque chose dans une expression régulière, vous demandez à ce que quelque chose en particulier soit vrai pour que le motif corresponde.
La plupart des éléments d'une expression régulière sont des assertions, y compris les caractères ordinaires qui veulent se correspondre à eux-mêmes. Pour être plus précis, ils supposent aussi que le prochain élément sera en correspondance un caractère plus loin dans la chaîne, c'est pourquoi nous disons que la tabulation est de « largeur un caractère ». Certaines assertions (comme \t) consomment un peu de la chaîne au fur et à mesure qu'ils entrent en correspondance et d'autres (comme \b) non. Mais nous réservons en général le terme « assertion » pour les assertions de largeur nulle. Pour éviter les confusions, nous appellerons celles qui ont une largeur des atomes. (Si vous êtes physicien, vous pouvez voir les atomes de largeur non nulle comme des particules massives, à la différence des assertions, qui n'ont pas de masse comme les photons.)
Vous allez voir aussi des métacaractères qui ne sont pas des assertions ; ils sont plutôt structurels (tout comme les accolades et les points-virgules définissent la structure du code Perl, mais ne font pas vraiment quelque chose). Ces métacaractères structurels sont d'une certaine manière les plus importants, car le premier pas dans votre apprentissage de la lecture des expressions régulières est d'habituer votre regard à reconnaître les métacaractères structurels. Une fois que vous avez appris cela, lire des expressions régulières est un jeu d'enfant(69).
L'un de ces métacaractères structurels est la barre verticale, qui indique un choix :
/Frodon|Pippin|Merry|Sam/Cela signifie que n'importe laquelle de ces chaînes peut correspondre. Ceci est traité dans la section Alternative plus loin dans ce chapitre. Dans la partie Capture et regroupement, nous vous montrerons comment utiliser les parenthèses autour de morceaux de votre motif pour faire des regroupements :
/(Frodon|Drogon|Bilbon) Sacquet/ou même :
/(Frod|Drog|Bilb)on Sacquet/Une autre chose que vous verrez sont les quantificateurs, qui disent combien de fois ce qui précède doit être trouvé à la queue leu leu. Les quantificateurs ressemblent à ceci :
* + ? *? {3} {2,5}Vous ne les verrez cependant jamais isolément. Les quantificateurs n'ont de sens qu'attachés à des atomes — c'est-à-dire à des assertions qui ont une largeur non nulle.(70) Les quantificateurs s'attachent à l'atome précédent seulement. Ce qui signifie en termes clairs qu'ils ne quantifient normalement qu'un seul caractère. Si vous voulez une correspondance avec trois copies de « bar » à la suite, vous devez regrouper les caractères individuels de « bar » dans une seule « molécule » avec des parenthèses, comme ceci :
/(bar){3}/Cela correspondra avec « barbarbar ». Si vous aviez écrit /bar{3}/, cela aurait correspondu avec « barrr » — qui aurait sonné écossais, mais n'aurait pas constitué un barbarbarisme. Pour en savoir plus sur les quantificateurs, voir plus loin la section Quantificateurs.
Maintenant que vous avez rencontré quelques-unes des bestioles qui habitent les expressions régulières, vous êtes sûrement impatient de commencer à les apprivoiser. Cependant, avant que nous ne discutions sérieusement des expressions régulières, nous allons un petit peu rebrousser chemin et parler des opérateurs qui utilisent les expressions régulières. (Et si vous apercevez quelques nouvelles bestioles regex en chemin, n'oubliez pas le guide.)
5-2. Opérateurs de recherche de motifs▲
Zoologiquement parlant, les opérateurs de recherche de motif de Perl fonctionnent comme une sorte de cage à expressions régulières : ils les empêchent de sortir. Si nous laissions les regex errer en liberté dans le langage, Perl serait une jungle complète. Le monde a besoin de jungles bien sûr — après tout, ce sont les moteurs de la diversité biologique —, mais les jungles devraient rester où elles sont. De même, bien qu'étant le moteur de la diversité combinatoire, les expressions régulières devraient rester à l'intérieur des opérateurs de recherche de motifs où est leur place. C'est une jungle, là-dedans.
Comme si les expressions régulières n'étaient pas assez puissantes, les opérateurs m// et s/// leur donnent le pouvoir (lui aussi confiné) de l'interpolation entre apostrophes doubles. Comme les motifs sont analysés comme des chaînes entre apostrophes doubles, toutes les conventions usuelles des apostrophes doubles fonctionnent, y compris l'interpolation de variables (à moins que vous n'utilisiez les apostrophes simples comme délimiteurs) et les caractères spéciaux indiqués par des séquences d'échappement avec antislash. (Voir Caractères spécifiques plus loin dans ce chapitre.) Celles-ci sont appliquées avant que la chaîne soit interprétée comme une expression régulière. (C'est l'un des quelques endroits de Perl où une chaîne subit un traitement en plusieurs passes.) La première passe n'est pas une interprétation entre apostrophes doubles tout à fait normale, en ce qu'elle sait ce qu'elle doit interpoler et ce qu'elle doit passer à l'analyseur d'expressions régulières. Donc par exemple, tout $ immédiatement suivi d'une barre verticale, d'une parenthèse fermante ou de la fin de chaîne ne sera pas traité comme une interpolation de variable, mais comme la traditionnelle assertion de regex qui signifie fin-de-ligne. Donc si vous écrivez :
$toto = "titi";
/$toto$/;la passe d'interpolation entre apostrophes doubles sait que ces deux $ fonctionnent différemment. Elle fait l'interpolation de $toto puis envoie ceci à l'analyseur d'expressions régulières :
/titi$/;Une autre conséquence de cette analyse en deux passes est que le tokener ordinaire de Perl trouve la fin de l'expression régulière en premier, tout comme s'il cherchait le délimiteur final d'une chaîne ordinaire. C'est seulement après avoir trouvé la fin de la chaîne (et fait les interpolations de variables) que le motif est traité comme une expression régulière. Entre autres choses, cela signifie que vous ne pouvez pas « cacher » le délimiteur final d'un motif à l'intérieur d'un élément de regex (comme une classe de caractères ou un commentaire de regex, que nous n'avons pas encore couvert). Perl verra le délimiteur où qu'il se trouve et terminera le motif à cet endroit.
Vous devez également savoir que l'interpolation de variables dans un motif ralentit l'analyseur de motif, car il se sent obligé de vérifier si la variable a été modifiée, au cas où il aurait à recompiler le motif (ce qui le ralentira encore plus). Voir la section Interpolation de variables plus loin dans ce chapitre.
L'opérateur de translittération tr/// ne fait pas d'interpolation de variables ; il n'utilise même pas d'expressions régulières ! (En fait, il ne devrait probablement pas faire partie de ce chapitre, mais nous n'avons pas trouvé de meilleur endroit où le mettre.) Il a cependant une caractéristique commune avec m// et s/// : il se lie aux variables grâce aux opérateurs =~ et !~.
Les opérateurs =~ et !~, décrits au chapitre 3, Opérateurs unaires et binaires, lient l'expression scalaire à leur gauche à l'un des trois opérateurs de type apostrophes (ou guillemets) à leur droite : m// pour rechercher un motif, s/// pour substituer une chaîne à une sous-chaîne correspondant au motif et tr/// (ou son synonyme, y///) pour traduire un ensemble de caractères en un autre ensemble de caractères. (Vous pouvez écrire // pour m// sans le m si les slash sont utilisés comme délimiteurs.) Si la partie à droite de =~ ou !~ n'est aucune de ces trois-là, elle compte toujours comme une opération m/// de recherche, mais il n'y a pas la place de mettre un seul modificateur final (voir plus loin la section Modificateurs de motif) et vous devrez gérer vos propres apostrophes :
print "correspond" if $unechaine =~ $unmotif;Vraiment, il n'y a pas de raison de ne pas l'écrire explicitement :
print "correspond" if $unechaine =~ m/$unmotif/;Quand ils sont utilisés pour une recherche de correspondance, =~ et !~ se prononcent parfois respectivement « correspond à » et « ne correspond pas à » (bien que « contient » et « ne contient pas » puissent être plus clair).
Hormis les opérateurs m// et s///, les expressions régulières apparaissent à deux autres endroits dans Perl. Le premier argument de la fonction split est une forme spéciale de l'opérateur de correspondance spécifiant les parties à ne pas retourner quand on découpe une chaîne en plusieurs sous-chaînes. Voir la description de split et les exemples au chapitre 29, Fonctions. L'opérateur qr// (quote regex) spécifie également un motif à l'aide d'une regex, mais il n'essaie pas de faire une correspondance avec quoi que ce soit (contrairement à m//, qui le fait). Au lieu de cela, il retourne une forme compilée de la regex pour une utilisation ultérieure. Voir Interpolation de variables pour plus d'informations.
Vous appliquez l'un des opérateurs m//, s/// ou tr/// à une chaîne particulière avec l'opérateur de lien =~ (qui n'est pas un véritable opérateur, mais plutôt un indicateur du sujet de l'opération). Voici quelques exemples :
$meuledefoin =~ m/aiguille/ # cherche un motif simple
$meuledefoin =~ /aiguille/ # pareil
$italiano =~ s/beurre/huile d'olive/ # une substitution bonne pour la santé
$rotate13 =~ tr/a-zA-Z/n-za-mN-ZA-M/ # encryption simple (à casser)Sans opérateur de lien, c'est $_ qui est implicitement utilisé comme "sujet" :
/nouvelles vies/ and # explore $_ et (si on trouve quelque chose)
/autres civilisations/ # au mépris du danger, explore encore $_
s/sucre/aspartame/ # substitue un substitut dans $_
tr/ATCG/TAGC/ # complémente le brin d'ADN dans $_Comme s/// et tr/// modifient le scalaire auquel ils sont appliqués, vous ne pouvez les utiliser qu'avec des lvalues valides :
"onshore" =~ s/on/off/; # FAUX : erreur à la compilationEn revanche, m// fonctionne sur le résultat de n'importe quelle expression scalaire :
if ((lc $chapeau_magique->contenu->comme_chaine) =~ /lapin/) {
print "Euh, quoi d'neuf, docteur ?\n";
}
else {
print "Ce tour ne marche jamais !\n";
}Mais vous devez être un petit peu prudent, car =~ et !~ ont une précédence assez élevée (dans notre exemple précédent, les parenthèses sont nécessaires autour du terme de gauche).(71) L'opérateur de lien !~ fonctionne comme =~, mais inverse la logique du résultat de l'opération :
if ($romance !~ /parole/) {
print qq/"$romance" semble être une romance sans parole.\n/;
}Comme m//, s/// sont des opérateurs apostrophes (ou guillemets), vous pouvez choisir vos délimiteurs. Ils fonctionnent de la même façon que les opérateurs de citation q//, qq//, qr//, et qw// (voir la section Choisissez vos délimiteurs, chapitre 2, Composants de Perl).
$path =~ s#/tmp#/var/tmp/scratch#;
if ($dir =~ m[/bin]) {
print "Pas de répertoires de binaires, s'il vous plait.\n";
}Quand vous utilisez des délimiteurs appariés avec s/// ou tr///, si la première partie utilise l'une des quatre paires usuelles d'encadrement (parenthèses, crochets, accolades ou chevrons), vous pouvez choisir des délimiteurs différents des premiers pour la seconde partie :
s(oeuf)<larve>;
s{larve}{chrysalide};
s[chrysalide]/imago/;Les blancs sont autorisés avant les délimiteurs ouvrants :
s (oeuf) <larve>;
s {larve} {chrysalide};
s [chrysalide] /imago/;À chaque fois qu'un motif correspond avec succès (y compris les motifs de substitution), il affecte aux variables $`, $& et $' le texte à gauche de la correspondance, le texte correspondant et le texte à droite de la correspondance. C'est utile pour séparer les chaînes en leurs éléments :
"pain au chocolat" =~ /au/;
print "Trouvé : <$`> $& <$'>\n"; # Trouvé : <pain > au < chocolat>
print "Gauche : <$`>\n"; # Gauche : <pain >
print "Correspondance : <$&>\n"; # Correspondance : <au>
print "Droite : <$'>\n"; # Droite : < chocolat>Pour plus d'efficacité et de contrôle, utilisez des parenthèses pour capturer les portions spécifiques que vous voulez conserver. Chaque paire de parenthèses capture la sous-chaîne correspondant au sous-motif entre parenthèses. Les paires de parenthèses sont numérotées de gauche à droite par la position de chaque parenthèse ouvrante. Une fois la correspondance établie, les sous-chaînes correspondantes sont disponibles dans les variables numérotées $1, $2, $3 et ainsi de suite :(72)
$_ = "Bilbon Sacquet est né le 22 Septembre";
/(.*) est né le (.*)/;
print "Personne: $1\n";
print "Date: $2\n";$`, $&, $' et les variables numérotées sont implicitement localisées dans la portée dynamique les contenant. Elles durent jusqu'à la prochaine recherche réussie ou jusqu'à la fin de la portée courante, selon ce qui arrive en premier. Nous en reparlerons plus tard, dans un cadre différent.
Une fois que Perl a détecté que vous aurez besoin de l'une des variables $`, $& ou $' quelque part dans votre programme, il les fournira pour chaque correspondance. Cela va ralentir un peu votre programme. Comme Perl utilise un mécanisme semblable pour produire $1, $2 et les autres, pour chaque motif contenant des parenthèses de capture vous payez un peu en performance. (Voir Regroupement pour éviter le coût de la capture en conservant la possibilité de regrouper.) Si vous n'utilisez jamais $`, $& ou $', alors les motifs sans parenthèses ne seront pas pénalisés. Si vous pouvez, il vaut donc mieux en général éviter d'utiliser $`, $& et $', en particulier dans les modules de bibliothèque. Mais si vous devez les utiliser au moins une fois (et certains algorithmes apprécient vraiment leur commodité), alors utilisez-les autant que vous voulez, car vous avez déjà payé le prix. $& n'est pas aussi coûteux que les deux autres dans les versions récentes de Perl.
5-2-a. Modificateurs de motif▲
Nous allons discuter des différents opérateurs de recherche de motif dans un moment, mais nous aimerions d'abord parler d'un de leurs points communs à tous : les modificateurs.
Vous pouvez placer un ou plusieurs modificateurs d'une lettre immédiatement après le délimiteur final, dans n'importe quel ordre. Par souci de clarté, les modificateurs sont souvent appelés « le modificateur /o » et prononcés « le modificateur slash oh », même si le modificateur final peut être autre chose qu'un slash. (Certaines personnes disent « drapeau » ou « option » pour « modificateur ». C'est bien aussi.)
Certains modificateurs changent le comportement d'un seul opérateur, aussi les décrirons-nous en détail plus loin. D'autres changent la façon dont la regex est interprétée. Les opérateurs m//, s/// et qr//(73) acceptent tous les modificateurs suivants après le délimiteur final :
|
Modificateur |
Signification |
|---|---|
|
|
Ignore les distinctions de casse des caractères (insensible à la casse). |
|
|
Fait correspondre . avec le saut de ligne et ignore la variable obsolète |
|
|
Fait correspondre |
|
|
Ignore (la plupart) des blancs et autorise les commentaires dans le motif. |
|
|
Ne compile le motif qu'une seule fois. |
Le modificateur /i indique de faire la correspondance à la fois en majuscules et en minuscules (et en casse de titre en Unicode). Ainsi /perl/i correspondrait avec « SUPERLATIF » ou « Perlimpinpin » (entre autres choses). Le pragma use locale peut aussi avoir une influence sur ce qui est considéré comme équivalent. (Cela peut avoir une mauvaise influence sur les chaînes contenant de l'Unicode.)
Les modificateurs /s et /m n'impliquent rien de coquin. Ils affectent la manière dont Perl traite les correspondances avec des chaînes contenant des sauts de ligne. Ils n'indiquent pas si votre chaîne contient réellement des sauts de ligne ; mais plutôt si Perl doit supposer que votre chaîne contient une seule ligne (/s) ou plusieurs lignes (/m), car certains métacaractères fonctionnent différemment selon qu'ils sont censés se comporter d'une manière orientée ligne ou non.
D'ordinaire le métacaractère « . » correspond à tout caractère sauf un saut de ligne, parce que sa signification traditionnelle est de correspondre aux caractères à l'intérieur d'une ligne. Avec un /s cependant, le métacaractère « . » peut aussi correspondre à des sauts de ligne, car vous avez dit à Perl d'ignorer le fait que la chaîne contient plusieurs sauts de ligne. (Le modificateur /s fait aussi ignorer à Perl la variable obsolète $*, dont nous espérons que vous l'ignoriez aussi.) Le modificateur /m, de son côté, change l'interprétation des métacaractères ^ et $ en leur permettant de correspondre à côté de sauts de lignes à l'intérieur de la chaîne au lieu de considérer seulement les extrémités de la chaîne. Voir les exemples dans la section Positions plus loin dans ce chapitre.
Le modificateur /o contrôle la recompilation des motifs. Sauf si les délimiteurs sont des apostrophes simples, (m'MOTIF', s'MOTIF'REMPLACEMENT', ou qr'MOTIF'), toute variable dans le motif sera interpolée (et pourra provoquer la recompilation du motif) à chaque fois que l'opérateur de motif sera évalué. Si vous voulez qu'un motif ne soit compilé qu'une fois et une seule, servez-vous du modificateur /o. Cela empêche une recompilation coûteuse à l'exécution ; cela peut servir quand la valeur interpolée ne change pas au cours de l'exécution. Cependant, utiliser /o revient à faire la promesse de ne pas modifier les variables dans le motif. Si vous les modifiez, Perl ne s'en rendra même pas compte. Pour avoir un meilleur contrôle de la recompilation des motifs, utilisez l'opérateur de citation de regex qr//. Pour plus de détails, voir la section Interpolation de variables plus loin dans ce chapitre.
Le modificateur /x est l'expressif : il vous permet d'exploiter les blancs et les commentaires explicatifs pour exalter la lisibilité de votre motif, ou même lui permettre d'explorer au-delà des limites des lignes.
Euh, c'est-à-dire que /x modifie la signification des blancs (et du caractère #) : au lieu de les laisser se correspondre à eux-mêmes comme le font les caractères ordinaires, il les transforme en métacaractères qui, étrangement, se comportent comme les blancs (et les caractères de commentaires) devraient le faire. /x permet donc l'utilisation d'espaces, de tabulations et de sauts de lignes pour le formatage, exactement comme le code Perl habituel. Il permet également l'utilisation du caractère #, qui n'est normalement pas un caractère spécial dans un motif, pour introduire un commentaire qui s'étend jusqu'au bout de la ligne en cours à l'intérieur de la chaîne de motif.(74) Si vous voulez détecter un véritable espace (ou le caractère #), alors vous devrez le mettre dans une classe de caractères, le protéger avec un antislash ou bien l'encoder en octal ou en hexadécimal. (Mais les blancs sont normalement détectés avec une séquence \s* ou \s+, donc la situation ne se rencontre pas souvent en pratique.)
À elles toutes, ces fonctionnalités font beaucoup pour rendre les expressions régulières plus proches d'un langage lisible. Dans l'esprit de TMTOWTDI, il existe donc plus d'une manière d'écrire une même expression rationnelle. En fait, il y a plus de deux manières :
m/\w+:(\s+\w+)\s*\d+/; # Mot, deux-points, espace, mot, espace, chiffres.
m/\w+: (\s+ \w+) \s* \d+/x; # Mot, deux-points, espace, mot, espace, chiffres.
m{
\w+: # Détecte un mot et un deux-points.
( # (début de groupe)
\s+ # Détecte un ou plusieurs blancs.
\w+ # Détecte un autre mot.
) # (fin de groupe)
\s* # Détecte zéro ou plusieurs blancs.
\d+ # Détecte des chiffres.
}x;Nous expliquerons ces nouveaux métasymboles plus loin dans ce chapitre. (Cette section était supposée décrire les modificateurs de motifs, mais nous l'avons laissé dériver dans notre excitation au sujet de /x. Bref.) Voici une expression régulière qui trouve les mots doublés dans un paragraphe, emprunté à Perl en action (The Perl Cookbook). Il utilise les modificateurs /x et /i, ainsi que le modificateur /g décrit plus loin.
# Trouve les doublons dans les paragraphes, si possible malgré les
# enjambements.
# Utilise /x pour les espaces et les commentaires, / pour détecter les
# deux 'tout' dans "Tout tout va bien ?", et /g pour trouver tous les
# doublons.
$/ = ""; # mode "paragrep"
while (<>) {
while ( m{
\b # commence à une limite de mot
(\w\S+) # trouve un morceau de "mot"
(
\s+ # séparé par des blancs
\1 # et ce même morceau
) + # ad lib
\b # jusqu'à une autre limite de mot
}xig
)
{
print "doublon '$1' au paragraphe $.\n";
}
}Quand on l'exécute sur ce chapitre, il affiche des avertissements tels que :
doublon 'nous' au paragraphe 36Bien sûr, nous nous sommes aperçus que dans ce cas particulier c'est normal.
5-2-b. L'opérateur m// (match)▲
EXPR =~ m/MOTIF/cgimosx
EXPR =~ /MOTIF/cgimosx
EXPR =~ ?MOTIF?cgimosx
m/MOTIF/cgimosx
/MOTIF/cgimosx
?MOTIF?cgimosxL'opérateur m// recherche dans la chaîne contenue dans le scalaire EXPR le motif MOTIF. Si le délimiteur est / ou ?, le m initial est facultatif. ? et ' ont tous deux une signification particulière en tant que délimiteurs : le premier fait une détection à usage unique, le second supprime l'interpolation de variables et les six séquences de traduction (\U et autres, décrits plus loin).
Si l'évaluation de MOTIF conduit à une chaîne vide, soit parce que vous l'avez spécifié ainsi en utilisant // ou parce qu'une variable interpolée a donné la chaîne vide, la dernière expression régulière exécutée avec succès sans être cachée à l'intérieur d'un bloc inclus (ou à l'intérieur d'un split, grep ou map) est exécutée à la place.
En contexte scalaire, l'opérateur renvoie vrai (1) en cas de succès, et faux ("") sinon. Cette forme se rencontre habituellement en contexte booléen :
if ($comte =~ m/Sacquet/) { ... } # recherche Sacquet dans la $comté
if ($comte =~ /Sacquet/) { ... } # recherche Sacquet dans la $comté
if ( m#Sacquet# ) { ... } # cherche ici dans $_
if ( /Sacquet/ ) { ... } # cherche ici dans $Utilisé en contexte de liste, m// renvoie la liste des sous-chaînes détectées par les parenthèses de capture du motif (c'est-à-dire $1, $2, $3 et ainsi de suite), comme cela est décrit plus loin dans la section Capture et regroupement. Les variables numérotées sont modifiées malgré tout, même si la liste est retournée. Si la recherche réussit en contexte de liste, mais qu'il n'y avait pas de parenthèses de capture (ni de /g), une liste consistant en
(1) est retournée. Comme elle renvoie la liste vide en cas d'échec, cette forme de m// peut aussi être utilisée en contexte booléen, mais seulement quand elle y participe indirectement via une affectation de liste :
if (($cle,$valeur) = /(\w+): (.*)/) { ... }Les modificateurs valides pour m// (sous toutes ses formes) sont listés dans le tableau 5-1.
|
Modificateur |
Signification |
|---|---|
|
|
Ignore la casse des caractères. |
|
|
Permet à |
|
|
Permet au . de détecter des sauts de lignes et ignore la variable obsolète |
|
|
Ignore (presque tous) les blancs et permet les commentaires à l'intérieur du motif. |
|
|
Compile le motif une seule fois. |
|
|
Recherche globale, pour détecter toutes les occurrences. |
|
|
Permet de continuer la recherche après un échec dans |
Les cinq premiers modificateurs s'appliquent à la regex et ont été décrits précédemment. Les deux derniers modifient le comportement de l'opérateur lui-même. Le modificateur /g indique une détection globale — c'est-à-dire que l'on recherche autant de fois qu'il est possible à l'intérieur de la chaîne. La façon dont cela se comporte dépend du contexte. En contexte de liste, m//g renvoie la liste de toutes les occurrences trouvées. Dans l'exemple suivant, nous trouvons toutes les endroits où quelqu'un a mentionné « perl », « Perl », « PERL », et ainsi de suite :
if (@perls = $paragraphe =~ /perl/gi) {
printf "Perl a été mentionné %d fois.\n", scalar @perls;
}S'il n'y a pas de parenthèses de capture dans le motif /g, alors les correspondances complètes sont renvoyées. S'il y a des parenthèses de capture, seules les chaînes capturées sont retournées. Imaginez une chaîne comme celle-ci :
$chaine = "password=xyzzy verbose=9 score=0";Imaginez également que vous souhaitez initialiser un hachage comme ceci :
%hash = (password => "xyzzy", verbose => 9, score => 0);Sauf évidemment que vous n'avez pas une liste, vous avez une chaîne. Pour obtenir la liste correspondante, vous pouvez utiliser l'opérateur m//g en contexte de liste pour capturer tous les couples clef/valeur de la chaîne :
%hash = $chaine =~ /(\w+)=(\w+)/g;La séquence (\w+) capture un mot alphanumérique. Voir la section Capture et regroupement.
Utilisé en contexte scalaire, le modificateur /g indique une détection progressive, qui reprend une nouvelle recherche sur la même chaîne à la position qui suit celle où la dernière s'est arrêtée. L'assertion \G représente cette position dans la chaîne. Voir la section Positions plus loin dans ce chapitre pour une description de \G. Si vous utilisez le modificateur /c (pour « continuer ») en plus de /g, alors quand le /g ne détecte plus rien, la détection ratée ne réinitialise pas le pointeur de position.
Si le délimiteur est ?, comme dans ?MOTIF?, la recherche fonctionne comme un /MOTIF/ normal, sauf qu'elle ne trouve qu'une seule occurrence entre deux appels à l'opérateur reset. Cela peut être une optimisation utile, quand vous désirez détecter seulement la première occurrence du motif pendant l'exécution du programme, et pas toutes les occurrences. L'opérateur fait la recherche à chaque fois que vous l'appelez, jusqu'à ce qu'il trouve finalement quelque chose, à la suite de quoi il se bloque de lui-même, renvoyant faux jusqu'à ce que vous le réenclenchiez avec reset. Perl se souvient de l'état de la détection pour vous.
L'opérateur ?? est particulièrement utile quand une recherche de motif ordinaire trouverait la dernière occurrence plutôt que la première :
open DICT, "/usr/dict/words_fr" or die "Impossible d'ouvrir words_fr: $!\n";
while (<DICT>) {
$premier = $1 if ?(^neur.*)?;
$dernier = $1 if /(^neur.*)/;
}
print $premier,"\n"; # affiche "neural"
print $dernier,"\n"; # affiche "neurula"L'opérateur reset ne réinitialisera que les instances de ?? qui ont été compilées dans le même paquetage que l'appel à reset. m?? et ?? sont équivalents.
5-2-c. L'opérateur s/// (substitution)▲
LVALUE =~ s/MOTIF/REMPLACEMENT/egimosx
s/MOTIF/REMPLACEMENT/egimosxCet opérateur recherche MOTIF dans une chaîne, et s'il le détecte, remplace la chaîne correspondante par le texte de REMPLACEMENT. (Les modificateurs sont décrits plus loin dans cette section.)
$lotr = $hobbit; # Copie juste Bilbon le hobbit
$lotr =~ s/Bilbon/Frodon/g; # et écrit très simplement une suite.La valeur de retour d'un s/// (en contexte scalaire comme en contexte de liste) est le nombre de fois qu'il a réussi (ce qui peut être plus d'une fois s'il a été utilisé avec le modificateur /g décrit plus tôt). En cas d'échec, il renvoie faux (""), qui est numériquement équivalent à 0.
if ($lotr =~ s/Bilbon/Frodon/) { print "Suite écrite avec succès." }
$changements = $lotr =~ s/Bilbon/Frodon/g;La partie de remplacement est traitée comme une chaîne entre apostrophes doubles. Vous pouvez utiliser toutes les variables à portée dynamique décrites plus tôt ($`, $&, $, $1, $2, et ainsi de suite) dans la chaîne de remplacement, ainsi que tous les trucs utilisables avec des apostrophes doubles. Voici un exemple qui trouve toutes les chaînes « revision », « version », ou « release », et les remplace chacune par son équivalent avec une majuscule, à l'aide de la séquence d'échappement \u dans la partie de remplacement :
s/revision|version|release/\u$&/g; # Utilisez | pour dire "ou"
# dans un motifToutes les variables scalaires sont interpolées en contexte d'apostrophes doubles, et pas seulement les étranges que nous venons de voir. Supposons que vous ayez un hachage %Noms qui fasse correspondre aux numéros de version des noms de projet interne ; par exemple $Noms{"3.0"} pourrait avoir le nom de code « Isengard ». Vous pourriez utiliser s/// pour trouver les numéros de version et les remplacer par le nom des projets correspondants :
s/version ([0-9.]+)/la livraison $Noms{$1}/g;Dans la chaîne de remplacement, $1 retourne ce que la première (et unique) paire de parenthèses a capturé. (Vous auriez pu aussi utiliser \1 comme vous l'auriez fait dans le motif, mais cet emploi est obsolète dans le remplacement. Dans une chaîne entre apostrophes doubles normale, \1 signifie Contrôle-A.)
Si MOTIF est une chaîne vide, la dernière expression régulière exécutée avec succès est utilisée à la place. MOTIF et REMPLACEMENT sont tous deux sujets à l'interpolation de variables. Cependant, un MOTIF est interpolé à chaque évaluation du s/// en tant que tel, tandis que le REMPLACEMENT n'est évalué qu'à chaque fois qu'une correspondance est trouvée. (Le MOTIF peut correspondre plusieurs fois en une évaluation si vous utilisez le modificateur /g.)
Comme précédemment, les cinq modificateurs du tableau 5-2 modifient le comportement de la regex ; ce sont les mêmes que pour m// et qr//. Les deux derniers affectent l'opérateur de substitution lui-même.
|
Modificateur |
Signification |
|---|---|
|
|
Ignore la casse des caractères (lors de la correspondance). |
|
|
Permet à |
|
|
Permet au . de détecter des sauts de ligne et ignore la variable obsolète |
|
|
Ignore (presque tous) les blancs et permet les commentaires à l'intérieur du motif. |
|
|
Compile le motif une seule fois. |
|
|
Replacement global, c'est-à-dire de toutes les occurrences. |
|
|
Évalue la partie droite comme une expression. |
Le modificateur /g est utilisé avec s/// pour remplacer chaque occurrence de MOTIF par la valeur REMPLACEMENT, et pas seulement la première rencontrée. Un opérateur s///g agit comme un rechercher-remplacer global, en faisant toutes les modifications en une seule fois. Tout comme un m//g en contexte de liste, sauf que m//g ne change rien. (Et que s///g ne fait pas de détection progressive comme le faisait un m//g en contexte scalaire.)
Le modificateur /e traite le REMPLACEMENT comme s'il s'agissait d'un bout de code Perl plutôt que d'une chaîne interpolée. Le résultat de l'exécution de ce code est utilisé comme chaîne de remplacement. Par exemple, s/([0-9]+)/sprintf("%#x", $1)/ge remplacerait 2581 par 0xb23. Ou supposez que dans notre exemple précédent, vous n'ayez pas été sûr de disposer d'un nom pour toutes les versions et que vous ayez voulu laisser inchangées les versions sans nom. Avec un formatage un peu créatif de /x, vous auriez pu écrire :
s{
version
\s+
(
[0-9.]+
)
}{
$Noms{$1}
? "la livraison $Names{$1}"
: $&
}xge;La partie droite de votre s///e (ou dans ce cas, la partie basse) est vérifiée syntaxiquement et compilée en même temps que le reste de votre programme. Toute erreur de syntaxe est détectée à la compilation, et les exceptions dynamiques ne sont pas relevées. Chaque nouveau /e ajouté à la suite du premier (comme /ee, /eee et ainsi de suite) revient à appeler eval CHAINE sur le résultat du code, une fois par /e supplémentaire. Ceci évalue le résultat du code dans l'expression et capture les exceptions dans la variable spéciale $@. Voir la section Motifs programmatiques plus loin dans ce chapitre pour plus de détails.
5-2-c-i. Modifier les chaînes en passant▲
Parfois vous voulez une nouvelle chaîne, modifiée sans altérer celle sur laquelle elle est basée. Au lieu d'écrire :
$lotr = $hobbit;
$lotr =~ s/Bilbon/Frodon/g;vous pouvez combiner ces deux instructions en une seule. À cause de la précédence, des parenthèses sont requises autour de l'affectation, tout comme dans la plupart des combinaisons appliquant =~ à une expression.
($lotr = $hobbit) =~ s/Bilbon/Frodon/g;Sans les parenthèses autour de l'affectation, vous n'auriez fait que changer $hobbit et récupérer le nombre de modifications dans $lotr, ce qui nous aurait donné une suite fort peu intéressante.
Vous ne pouvez pas utiliser un opérateur s/// directement sur un tableau. Pour cela, vous aurez besoin d'une boucle. Par une heureuse coïncidence, l'idiome Perl standard pour rechercher et modifier sur chaque élément d'un tableau s'obtient grâce au système d'alias de for/foreach, combiné avec l'utilisation de $_ comme variable par défaut de la boucle :
for (@chapitres) { s/Bilbon/Frodon/g } # Fait les substitutions chapitre
# par chapitre.
s/Bilbon/Frodon/g for @chapitres; # Pareil.Comme avec les variables scalaires, vous pouvez également combiner substitution et affectation si vous désirez conserver une copie de l'original :
@anciens = ('oiseau bleu', 'bleu roi', 'bleu nuit', 'bleu de travail');
for (@nouveaux = @anciens) { s/bleu/rouge/ }
print "@nouveaux\n"; # affiche : oiseau rouge rouge roi rouge
# nuit rouge de travailLa manière idiomatique d'appliquer des substitutions répétées sur une même variable est d'utiliser une boucle à un seul tour. Par exemple, voici comment normaliser les blancs dans une variable :
for ($chaine) {
s/^\s+//; # supprime les blancs au début
s/\s+$//; # supprime les blancs à la fin
s/\s+/ /g; # minimise les blancs internes
}ce qui produit exactement le même résultat que :
$chaine = join(" ", split " ", $chaine);Vous pouvez également utiliser une telle boucle dans une affectation, comme nous l'avons fait dans le cas du tableau :
for ($nouveau = $ancien) {
s/Fred/Homer/g;
s/Wilma/Marge/g;
s/Pebbles/Lisa/g;
s/Dino/Bart/g;
}5-2-c-ii. Quand une substitution globale n'est pas assez globale▲
De temps en temps, vous ne pouvez tout simplement pas utiliser un /g pour que tous les changements soient faits, soit parce que les substitutions se produisent de droite à gauche, soit parce que la longueur de $` doit changer entre deux occurrences. En général, vous pouvez faire cela en appelant s/// à répétition. Mais vous voulez tout de même que la boucle s'arrête quand le s/// finit par échouer, ce qui ne laisse rien à faire dans la partie principale de la boucle. Alors nous écrivons un simple 1, qui est une chose plutôt ennuyeuse à faire, mais souvent le mieux que vous pouvez espérer. Voici quelques exemples qui utilisent quelques-unes de ces étranges bestioles que sont les regex :
# met des points aux bons endroits dans un entier
1 while s/(\d)(\d\d\d)(?!\d)/$1.$2/;
# change les tabulations pour des espacements sur 8 colonnes
1 while s/\t+/' ' x (length($&)*8 - length($`)%8)/e;
# supprime les parenthèses (imbriquées (ou même très imbriquées (comme ça)))
1 while s/\([^()]*\)//g;
# supprime les doublons (et les triplons (et les quadruplons...))
1 while s/\b(\w+) \1\b/$1/gi;Cette dernière nécessite une boucle, car sinon elle transformerait ceci :
Paris AU AU AU AU printemps.en cela :
Paris AU AU printemps.5-2-d. L'opérateur tr/// (translittération)▲
LVALUE =~ tr/LISTEDERECHERCHE/LISTEDEREMPLACEMENT/cds tr/LISTEDERECHERCHE/LISTEDEREMPLACEMENT/cdsPour les fans de sed, y/// est fourni comme synonyme de tr///. C'est la raison pour laquelle vous ne pouvez pas plus appeler une fonction y que vous ne pouvez l'appeler q ou m. Hormis cela, y/// est exactement identique à tr/// et nous ne le mentionnerons plus.
Cet opérateur n'aurait pas vraiment de raison d'apparaître dans un chapitre consacré à la détection de motif, puisqu'il n'utilise pas de motif. Cet opérateur balaie une chaîne caractère par caractère, et remplace chaque occurrence d'un caractère de LISTEDERECHERCHE (qui n'est pas une expression régulière) par le caractère correspondant dans LISTEDEREMPLACEMENT (qui n'est pas une chaîne de remplacement). Cependant, il ressemble un peu à m// et à s///, et vous pouvez même utiliser les opérateurs de lien =~ et !~ dessus. C'est pourquoi nous le décrivons ici. (qr// et split sont des opérateurs de recherche de motif, mais on ne peut pas utiliser les opérateurs de lien dessus, c'est pourquoi ils sont ailleurs dans ce livre. Allez comprendre.)
La translittération retourne le nombre de caractères remplacés ou effacés. Si aucune chaîne n'est spécifiée par les opérateurs =~ ou !~, c'est la chaîne $_ qui est modifiée. LISTEDERECHERCHE et LISTEDEREMPLACEMENT peuvent définir des intervalles de caractères successifs à l'aide d'un tiret :
$message =~ tr/A-Za-z/N-ZA-Mn-za-m/; # cryptage rot13.Remarquez qu'un intervalle comme A-Z suppose un ensemble de caractères linéaire comme l'est la table ASCII. Mais chaque ensemble de caractères a son propre point de vue concernant l'ordre de ses caractères, et donc de quels caractères font partie d'un intervalle particulier. Un principe sain est d'utiliser des intervalles qui commencent et finissent sur des caractères de la même casse (a-e, A-E) ou des chiffres (0-4). Tout le reste est suspect. En cas de doute, décrivez l'ensemble qui vous intéresse en entier : ABCDE.
LISTEDERECHERCHE et LISTEDEREMPLACEMENT ne subissent pas d'interpolation de variable comme des chaînes entre apostrophes doubles ; vous pouvez cependant utiliser les séquences avec antislash qui correspondent à des caractères spécifiques, comme \n ou \015.
Le tableau tableau 5-3 donne la liste des modificateurs qui s'appliquent à l'opérateur tr///. Ils sont complètement différents de ceux que vous appliquez à m//, s/// ou qr//, même si certains d'entre eux y ressemblent. Si le modificateur /c est spécifié, le jeu de caractères dans LISTEDERECHERCHE est complémenté ; c'est-à-dire que la liste de recherche effective comprend tous les caractères qui ne se trouvent pas dans LISTEDERECHERCHE. Dans le cas de l'Unicode, cela peut représenter un grand nombre de caractères, mais comme ils sont stockés logiquement et non physiquement, vous n'avez pas à vous inquiéter d'un éventuel manque de mémoire.
|
Modificateur |
Signification |
|---|---|
|
|
Complémente la LISTEDERECHERCHE. |
|
|
Supprime les caractères trouvés, mais non remplacés. |
|
|
Concentre les caractères dupliqués remplacés. |
Le modificateur /d transforme tr/// en ce qu'on pourrait appeler l'opérateur de « transoblitération » : tout caractère spécifié par LISTEDERECHERCHE, mais qui n'a pas de caractère de remplacement dans LISTEDEREMPLACEMENT est effacé. (C'est un peu plus souple que le comportement de certains tr(1), qui effacent tout ce qu'ils trouvent dans LISTEDERECHERCHE, point.)
Si le modificateur /s est spécifié, les suites de caractères qui sont convertis en un caractère identique sont réduites à un seul exemplaire de ce caractère.
Si le modificateur /d est utilisé, LISTEDEREMPLACEMENT est toujours interprétée comme elle est spécifiée. Sinon, si LISTEDEREMPLACEMENT est plus courte que LISTEDERECHERCHE, le dernier caractère est répliqué jusqu'à ce qu'elle soit assez longue. Si LISTEDEREMPLACEMENT est vide, la LISTEDERECHERCHE est répliquée, ce qui est étonnamment utile si vous voulez juste compter les caractères, et non les modifier. C'est aussi utile pour compacter les séquences de caractères. avec /s.
tr/aeiou/!/; # change toutes les voyelles en !
tr{/\\\r\n\b\f. }{_}; # change les caractères bizarres en soulignés
tr/A-Z/a-z/ for @ARGV; # normalise en minuscules ASCII
$compte = ($para =~ tr/\n//); # compte les sauts de lignes dans $para
$compte = tr/0-9//; # compte les chiffres dans $_
$mot =~ tr/a-zA-Z//s; # illettrisme -> iletrisme
tr/@$%*//d; # supprime tous ceux-là
tr#A-Za-z0-9+/##cd; # supprime les caractères hors base64
# change en passant
($HOTE = $hote) =~ tr/a-z/A-Z/;
$pathname =~ tr/a-zA-Z/_/cs; # change les caractères ASCII non
# alphabétiques en un seul souligné
tr [\200-\377]
[\000-\177]; # supprime le 8e bit de chaque octetSi le même caractère apparaît plusieurs fois dans la LISTEDERECHERCHE, seul le premier est utilisé. Ainsi, ceci :
tr/AAA/XYZ/changera tout A en X (dans $_). Bien que les variables ne soient pas interpolées par tr///, vous pouvez obtenir le même
effet en utilisant eval EXPR :
$compte = eval "tr/$ancien/$nouveau/";
die if $@; # propage l'exception due à un contenu de eval incorrectEncore un mot : si vous voulez passer votre texte en majuscules ou en minuscules, n'utilisez pas tr///. Utilisez plutôt les séquences \U ou \L dans des chaînes entre apostrophes doubles (l'équivalent des fonctions uc et lc), car elles seront attentives aux informations de locales et à l'Unicode, alors que tr/a-z/A-Z ne le sera pas. De plus, dans les chaînes Unicode, la séquence \u et la fonction correspondante ucfirst comprennent la notion de casse de titre, ce qui pour certaines langues peut être différent de simplement convertir en majuscules.
5-3. Métacaractères et métasymboles▲
Maintenant que nous avons admiré les jolies cages, nous pouvons de nouveau nous intéresser aux bestioles dans ces cages, les étranges caractères que vous mettez dans les motifs. Maintenant vous avez compris que ces symboles ne sont pas du code Perl normal comme les appels de fonction ou les opérateurs arithmétiques. Les expressions régulières ont leur propre petit langage inclus dans Perl. (Chacun a son jardin et sa jungle secrète.)
Malgré leur puissance et leur expressivité, les motifs de Perl reconnaissent les mêmes 12 caractères traditionnels (les « Douze salopards », s'il en est) qu'on trouve dans de nombreux autres modules d'expressions régulières.
\|()[ { ^ $ * + ? .Certains d'entre eux changent les règles, rendant spéciaux les caractères normaux qui les suivent. Nous n'aimons pas appeler les séquences de plus d'un caractère des « caractères », c'est pourquoi nous les appellerons métasymboles (ou même seulement « symboles »). Mais au plus haut niveau, ces douze métacaractères sont tout ce dont vous (et Perl) avez à vous inquiéter. Tout le reste procède de là.
Certains métacaractères simples fonctionnent par eux-mêmes, comme ., ^ et $. Ils n'affectent directement rien de ce qui les entoure. Certains métacaractères fonctionnent comme des opérateurs préfixes, contrôlant ce qui les suit, comme \. D'autres fonctionnent comme des opérateurs postfixes, et contrôlent ce qui les précède immédiatement, comme *, + et ?. Un métacaractère, |, fonctionne comme un opérateur infixe, en se tenant entre les deux opérandes qu'il affecte. Il existe même des métacaractères de parenthésage, qui fonctionnent comme des opérateurs « circonfixes », et régissent ce qu'ils contiennent, comme (...) et [...]. Les parenthèses sont particulièrement importantes, car elles définissent les limites de | à l'intérieur, et celles de *, + et ? à l'extérieur.
Si vous n'apprenez qu'un seul des douze métacaractères, choisissez l'antislash. (Euh... et les parenthèses.) C'est parce que l'antislash invalide les autres. Quand un antislash précède un caractère non alphanumérique dans un motif Perl, il en fait toujours un caractère littéral. Si vous avez besoin de faire une correspondance littérale avec l'un des douze métacaractères, vous n'avez qu'à l'écrire précède d'un antislash. Ainsi, \. est un vrai point, \$ un vrai dollar, \\ un vrai antislash, et ainsi de suite. On appelle cela « protéger » le métacaractère, ou simplement l'« antislasher ». (Bien sûr, vous savez déjà que l'antislash sert à supprimer l'interpolation de variable dans les chaînes entre apostrophes doubles.)
Bien qu'un antislash transforme un métacaractère en caractère littéral, il a l'effet inverse sur un caractère alphanumérique le suivant. Il prend ce qui était normal et le rend spécial. C'est-à-dire qu'à eux deux, ils forment un métasymbole. Une liste alphabétique de ces métasymboles se trouve juste en dessous dans le tableau 5-7.
5-3-a. Tables de métasymboles▲
Dans les tableaux qui suivent, la colonne Atomique indique « Oui » si le métasymbole correspondant est quantifiable (c'est-à-dire s'il peut correspondre à quelque chose qui a une largeur, plus ou moins). Nous avons également utilisé « ... » pour représenter « quelque chose d'autre ». (Consultez la discussion qui suit pour savoir ce que « ... » signifie, si le commentaire du tableau n'est pas suffisant.)
Le tableau 5-4 liste les métasymboles traditionnels de base. Les quatre premiers sont les métasymboles structurels déjà mentionnés, tandis que les trois suivants sont de simples métacaractères. Le métacaractère . est un exemple d'atome, car il correspond à quelque chose qui a une largeur (la largeur d'un caractère, dans ce cas) ; ^ et $ sont des exemples d'assertions, car ils correspondent à quelque chose de largeur nulle et ne sont évalués que pour savoir s'ils sont vrais ou faux.
|
Symbole |
Atomique |
Signification |
|---|---|---|
|
\... |
Variable |
Rend le caractère non alphanumérique suivant littéral, rend le caractère alphanumérique suivant méta (peut-être). |
|
... |
Non |
Alternative (correspond à l'un ou l'autre). |
|
(...) |
Oui |
Regroupement (traite comme une unité). |
|
[...] |
Oui |
Classe de caractères (correspond à un caractère d'un ensemble). |
|
|
Non |
Vrai au début d'une chaîne (ou après toute nouvelle ligne, éventuellement). |
|
. |
Oui |
Correspond à un caractère (sauf le saut de ligne, normalement). |
|
|
Non |
Vrai en fin de chaîne (ou avant toute nouvelle ligne, éventuellement). |
Les quantificateurs, décrits plus loin dans leur propre section, indiquent combien de fois l'atome qui les précède (caractère simple ou regroupement) doit correspondre. Ils sont listés dans le tableau 5-5.
|
Quantificateur |
Atomique |
Signification |
|---|---|---|
|
|
Non |
Correspond 0 fois ou plus (maximal). |
|
|
Non |
Correspond 1 fois ou plus (maximal). |
|
|
Non |
Correspond 0 ou 1 fois (maximal). |
|
|
Non |
Correspond exactement COMPTE fois. |
|
|
No |
Correspond au moins MIN fois (maximal). |
|
|
No |
Correspond au moins MIN fois, mais pas plus de MAX fois (maximal). |
|
|
Non |
Correspond 0 fois ou plus (minimal). |
|
|
Non |
Correspond 1 fois ou plus (minimal). |
|
|
Non |
Correspond 0 ou 1 fois (minimal). |
|
|
Non |
Correspond au moins MIN fois (minimal). |
|
|
Non |
Correspond au moins MIN fois, mais pas plus de MAX fois (minimal). |
Un quantificateur minimal essaie de correspondre aussi peu que possible dans l'intervalle autorisé. Un quantificateur maximal essaie de correspondre le plus possible, dans l'intervalle autorisé. Par exemple, .+ est sûr de correspondre à au moins un des caractères de la chaîne, mais correspondra à tous s'il en a l'occasion. Ces occasions seront décrites plus loin dans « Le petit Moteur qui /(ne )?pouvait( pas)?/ ».
Vous remarquerez qu'un quantificateur ne peut jamais être quantifié.
Nous voulions fournir une syntaxe extensible pour pouvoir introduire de nouveaux types de métasymboles. Étant donné que nous n'avions qu'une douzaine de métacaractères à notre disposition, nous avons choisi d'utiliser une séquence de regex anciennement incorrecte pour ces extensions syntaxiques arbitraires. Ces métasymboles sont tous de la forme (?CLE...) ; c'est-à-dire une parenthèse (équilibrée) suivie d'un point d'interrogation, suivie par une CLE et le reste du sous-motif. Le caractère CLE indique de quelle extension de regex il s'agit. Voyez le tableau 5-6 pour en avoir la liste. La plupart d'entre eux se comportent bien structurellement, car ils sont basés sur des parenthèses, mais ont également une signification supplémentaire. De nouveau, seuls les atomes peuvent être quantifiés, car ils représentent quelque chose qui est vraiment là (potentiellement).
|
Extension |
Atomique |
Signification |
|---|---|---|
|
( |
Non |
Commentaire, ignoré. |
|
( |
Oui |
Parenthèses de regroupement seul, sans capture. |
|
( |
No |
Active/désactive les modificateurs de motif. |
|
( |
Oui |
Parenthèses de regroupement, et modificateurs. |
|
( |
Non |
Vrai si l'assertion de pré-vision est un succès. |
|
( |
Non |
Vrai si l'assertion de pré-vision est un échec. |
|
( |
Non |
Vrai si l'assertion de rétro-vision est un succès. |
|
( |
Non |
Vrai si l'assertion de rétro-vision est un échec. |
|
( |
Yes |
Correspond au motif sans retour arrière. |
|
( |
Non |
Exécute le code Perl inclus. |
|
( |
Oui |
Fait correspondre la regex du code Perl inclus. |
|
( |
Oui |
Correspond avec un motif si-alors-sinon. |
|
( |
Oui |
Correspond avec un motif si-alors. |
Enfin, tableau 5-7 donne la liste de tous les métasymboles alphanumériques usuels. (Les symboles qui sont traités durant la passe d'interpolation de variables sont indiqués avec un tiret dans la colonne Atomique, car le Moteur ne les voit jamais.)
|
Symbole |
Atomique |
Signification |
|---|---|---|
|
\ |
Oui |
Correspond au caractère nul (ASCII NUL). |
|
\NNN |
Oui |
Correspond au caractère donné en octal, jusqu'à \ |
|
\n |
Oui |
Correspond à la nième chaîne capturée (en décimal). |
|
\a |
Oui |
Correspond au caractère alarme (BEL). |
|
\A |
Non |
Vrai au début d'une chaîne. |
|
\b |
Oui |
Correspond au caractère espace arrière (BS). |
|
\b |
Non |
Vrai à une limite de mot. |
|
\B |
Non |
Vrai hors d'une limite de mot. |
|
\cX |
Oui |
Correspond au caractère de contrôle Contrôle-X (\cZ, \c[ , etc.). |
|
\C |
Oui |
Correspond à un octet (un char en C), même en utf8 (dangereux). |
|
\d |
Oui |
Correspond à tout caractère numérique. |
|
\D |
Oui |
Correspond à tout caractère non numérique. |
|
\e |
Oui |
Correspond au caractère d'échappement (ASCII ESC, pas l'antislash). |
|
\E |
— |
Termine la traduction de casse (\L, \U) ou la citation de métacaractères. |
|
\f |
Oui |
Correspond au caractère de fin de page (FF). |
|
\G |
Non |
Vrai à la position de fin de recherche du m |
|
\l |
— |
Passe le prochain caractère seulement en minuscules. |
|
\L |
— |
Minuscules jusqu'au prochain \E. |
|
\n |
Oui |
Correspond au caractère de saut de ligne (en général NL, mais CR sur les Mac). |
|
\N |
Oui |
Correspond au caractère nommé (\N |
|
\p |
Oui |
Correspond à tout caractère ayant la propriété citée. |
|
\P |
Oui |
Correspond à tout caractère n'ayant pas la propriété citée. |
|
\Q |
— |
Cite les métacaractères (désactive leur côté méta) jusqu'au prochain \E. |
|
\r |
Oui |
Correspond au caractère de retour chariot (CR en général, mais NL sur les Mac). |
|
\s |
Oui |
Correspond à tout caractère blanc. |
|
\S |
Oui |
Correspond à tout caractère non blanc. |
|
\t |
Oui |
Correspond au caractère de tabulation (HT). |
|
\u |
— |
Passe le prochain caractère seulement en grandes initiales. |
|
\U |
— |
Passe en majuscules (et non en grandes initiales) jusqu'au prochain \E. |
|
\w |
Oui |
Correspond à tout caractère de « mot » (alphanumériques et « _ ») |
|
\W |
Oui |
Correspond à tout caractère non « mot ». |
|
\ |
Oui |
Correspond au caractère donné en hexadécimal. |
|
\X |
Oui |
Correspond à une « séquence de caractères Unicode combinés ». |
|
\z |
Non |
Vrai seulement en fin de chaîne. |
|
\Z |
Non |
Vrai en fin de chaîne ou avant un éventuel saut de ligne. |
Les accolades sont facultatives pour \p et \P si le nom de la propriété fait un seul caractère. Les accolades sont facultatives pour \x si le nombre hexadécimal fait deux chiffres ou moins. Les accolades ne sont jamais facultatives pour \N.
Seuls les métasymboles dont la description est « Correspond à... » peuvent être utilisés dans une classe de caractères. C'est-à-dire que les classes de caractères ne peuvent contenir que des ensembles spécifiques de caractères, et vous ne pouvez donc utiliser à l'intérieur que des métasymboles qui décrivent d'autres ensembles spécifiques de caractères ou qui décrivent des caractères individuels. Bien sûr, ces métasymboles peuvent aussi être utilisés en dehors des classes de caractères, avec les autres métasymboles (qui ne peuvent être utilisés qu'hors classe). Remarquez cependant que \b est en fait deux bestioles complètement différentes : c'est un espace arrière dans une classe de caractères, mais une assertion de limite de mot en dehors.
Il y a un certain chevauchement entre les caractères auxquels un motif peut correspondre et les caractères qu'une chaîne entre apostrophes doubles peut interpoler. Comme les regex subissent deux passes, il est parfois ambigu de savoir quelle passe doit traiter quel caractère. Quand il y a une ambiguïté, la passe d'interpolation de variable défère l'interprétation de ces caractères à l'analyseur d'expressions régulières.
Mais la passe d'interpolation de variable ne peut déférer à l'analyseur de regex que quand elle sait qu'elle est en train d'analyser une regex. Vous pouvez spécifier des expressions régulières comme des chaînes entre apostrophes doubles ordinaires, mais vous devez alors suivre les règles normales des apostrophes doubles. Chacun des métasymboles précédents qui correspond à un caractère existant continuera de marcher, même s'il n'est pas déféré à l'analyseur de regex. Mais vous ne pourrez utiliser aucun des autres métasymboles entre des apostrophes doubles ordinaires (ou dans toute construction analogue comme `...`, qq(...), qx(...) ou les documents ici même équivalents). Si vous voulez que votre chaîne soit analysée comme une expression régulière sans faire de correspondance, vous devriez utiliser l'opérateur qr// (quote regex).
Notez que les séquences d'échappement de casse et de métacitation (\U et compagnie) doivent être traitées durant la passe d'interpolation, car leur rôle est de modifier la façon dont les variables sont interpolées. Si vous supprimez l'interpolation de variable avec des apostrophes simples, vous n'aurez pas non plus les séquences d'échappement. Ni les variables ni les séquences d'échappement (\U, etc.) ne sont étendues dans les chaînes entre apostrophes simples, ni dans les opérateurs m'...' ou qr'...' avec apostrophes simples. Et même si vous faites une interpolation, ces séquences d'échappement sont ignorées si elles apparaissent dans le résultat de l'interpolation de variable, car à ce moment-là il est trop tard pour influencer l'interpolation de variable.
Bien que l'opérateur de translittération ne prenne pas d'expression régulière, tout métasymbole précédemment discuté qui correspond à un caractère spécifique simple marche aussi dans une opération tr///. Les autres ne marchent pas (sauf bien sûr l'antislash qui continue toujours à fonctionner à sa manière bien à lui).
5-4. Caractères spécifiques▲
Comme mentionné précédemment, tout ce qui n'est pas spécial dans un motif se correspond à lui-même. Cela signifie qu'un /a/ correspond à un « a », un /=/ correspond à un « = », et ainsi de suite. Certains caractères ne sont cependant pas très faciles à taper au clavier ou, même si vous y arrivez ne s'afficheront pas lisiblement ; les caractères de contrôle sont connus pour cela. Dans une expression régulière, Perl reconnaît les alias d'apostrophes doubles suivants :
|
Échappement |
Signification |
|---|---|
|
\ |
Caractère nul (ASCII NUL) |
|
\a |
Alarme (BEL) |
|
\e |
Échappement (ESC) |
|
\f |
Fin de page (FF) |
|
\n |
Saut de ligne (NL, CR sur Mac) |
|
\r |
Retour chariot (CR, NL sur Mac) |
|
\t |
Tabulation (HT) |
Tout comme dans les chaînes entre apostrophes doubles, Perl reconnaît également les quatre métasymboles suivants dans les motifs :
\cX
- Un caractère de contrôle nommé, comme \cC pour Contrôle-C, \cZ pour Contrôle-Z, \c[ pour ESC, et \c
?pour DEL.
\NNN
- Un caractère spécifié en utilisant son code octal à deux ou trois chiffres. Le
0initial est facultatif, sauf pour les valeurs inférieures à010(8 en décimal), car (contrairement aux chaînes entre apostrophes doubles) les versions à un seul chiffre sont toujours considérées comme des références arrière à des chaînes capturées dans un motif. Les versions à plusieurs chiffres sont interprétées comme la nième référence arrière si vous avez capturé au moins n sous-chaînes plus tôt dans le motif (avec n considéré comme un nombre décimal). Sinon, elle est interprétée comme un caractère octal.
\x{HEXLONG}\xHEX
- Un caractère spécifié par son numéro à un ou deux chiffres hexadécimaux ([
0-9afA-F]), comme \x1B. La forme à un seul chiffre est utilisable quand le caractère suivant n'est pas un chiffre hexadécimal. Si vous utilisez des accolades, vous pouvez mettre autant de chiffres que vous voulez, ce qui peut conduire à un caractère unicode. Par exemple, \x{262f}correspond à un YIN YANG Unicode.
\N{NOM}
- Un caractère nommé, comme \N
{GREEK SMALL LETTER EPSILON}, \N{greek:epsilon}, ou \N{epsilon}. Ceci requiert l'utilisation du pragma use charnames décrit au chapitre 31, Modules de pragmas, et qui détermine aussi lequel de ces noms vous pouvez utiliser (":long",":full",":short"qui correspondent respectivement aux trois styles que nous venons de citer). - Vous trouverez une liste de tous les noms de caractères Unicode dans vos documents de standard Unicode préférés ou dans le fichier PATH_TO_PERLLIB/unicode/Names.txt.
5-4-a. Métasymboles jokers▲
Trois métasymboles spéciaux sont utilisés comme des jokers génériques, chacun d'entre eux correspondant à « tout » caractère (pour certaines valeurs de « tout »). Ce sont le point ("."), \C et \X. Aucun d'entre eux ne peut être utilisé dans une classe de caractères. Vous ne pouvez pas y utiliser le point, car il correspondrait à (presque) tout caractère existant. C'est donc déjà une sorte de classe de caractères universelle par lui-même. Si vous voulez tout inclure ou tout exclure, il n'y a pas grand intérêt à utiliser une classe de caractères. Les jokers spéciaux \C et \X ont une signification structurelle spécifique qui ne s'accorde pas bien avec l'idée de choisir un seul caractère Unicode, ce qui est le niveau auquel fonctionne une classe de caractères.
Le métacaractère point correspond à tout caractère autre que le saut de ligne. (Et avec le modificateur /s, il lui correspond aussi.) Comme chacun des autres caractères spéciaux dans un motif, pour correspondre à un point littéral, vous devez le protéger avec un antislash. Par exemple, ceci vérifie si un nom de fichier se termine par un point suivi d'une extension à un caractère :
if ($chemin =~ /\.(.)\z/s) {
print "Se termine par $1\n";
}Le premier point, celui qui est protégé, est un caractère littéral, tandis que le second dit « correspond à tout caractère ». Le \z demande de ne correspondre qu'à la fin de la chaîne, et le modificateur /s permet au point de correspondre également à un saut de ligne. (Certes, utiliser un saut de ligne comme extension n'est Pas Très Gentil, mais cela ne veut pas dire que cela ne peut pas se produire.)
Le métacaractère point est le plus souvent utilisé avec un quantificateur. Un .* correspond à un nombre maximal de caractères, tandis qu'un .*? correspond à un nombre minimal de caractères. Mais il est aussi utilisé parfois sans quantificateur pour sa propre largeur : /(..):(..):(..)/ correspond à trois champs séparés par des deux-points, chacun faisant deux caractères de large.
Si vous utilisez un point dans un motif compilé sous le pragma à portée lexicale use utf8, alors il correspondra à tout caractère Unicode. (Vous n'êtes pas supposé avoir besoin de use utf8 pour cela, mais il y a toujours des accidents. Le pragma peut ne plus être utile d'ici à ce que vous lisiez ces lignes.)
use utf8;
use charnames qw/:full/;
$BWV[887] = "G\N{MUSIC SHARP SIGN} minor"; # partition anglaise
($note, $noire, $mode) = $BWV[887] =~ /^([A-G])(.)\s+(\S+)/;
print "C'est en dièse !\n" if $n eq chr(9839);Le métasymbole \X correspond à un caractère Unicode dans un sens plus étendu. Il correspond en fait à une chaîne d'un ou plusieurs caractères Unicode connue sous le nom de « séquence de caractères combinés ». Une telle séquence consiste en un caractère de base suivi par l'un des caractères de « marquage » (signe diacritique comme une cédille ou un tréma) qui se combine avec le caractère de base pour former une unité logique. \X est exactement équivalent à (?:\PM\pM*). Cela permet de correspondre à un seul caractère logique, même si celui est en fait constitué de plusieurs caractères distincts. La longueur de la correspondance de /\X/ peut excéder un caractère si celui-ci a trouvé des caractères combinés. (Et nous parlons ici de la longueur en caractères, qui n'a pas grand-chose à voir avec la longueur en octets.)
Si vous utilisez Unicode et que vous voulez vraiment travailler sur un seul octet plutôt que sur un seul caractère, vous pouvez utiliser le métasymbole \C. Ceci correspondra toujours à un seul octet (spécifiquement, à un seul élément de type char de C), même si cela vous désynchronise de votre flux de caractères Unicode. Référez-vous aux avertissements relatifs à cela au chapitre 15.
5-5. Classes de caractères▲
Dans une recherche de motif, vous pouvez établir une correspondance avec tout caractère qui a — ou n'a pas — une propriété particulière. Il existe quatre manières de spécifier les classes de caractères. Vous pouvez spécifier une classe de caractères de la manière traditionnelle en utilisant des crochets et en énumérant les caractères possibles, ou en utilisant l'un des trois raccourcis mnémotechniques : les classes Perl habituelles, les nouvelles propriétés Unicode de Perl ou les classes POSIX standard. Chacun de ces raccourcis correspond à un seul caractère de son ensemble. Quantifiez-les si vous voulez faire une correspondance avec un plus grand nombre d'entre eux, comme \d+ pour correspondre à plusieurs chiffres. (Une erreur facile à faire est de croire que \w correspond à un mot. Utilisez \w+ pour trouver un mot.)
5-5-a. Classes de caractères personnalisées▲
Une liste de caractères énumérée entre crochets est appelée une classe de caractère et correspond à tout caractère dans la liste. Par exemple, [aeiouy] correspond à une voyelle (non accentuée). Pour correspondre à un crochet fermant, antislashez-le ou bien placez-le en premier dans la liste.
Des intervalles de caractères peuvent être indiqués en utilisant un tiret et la notation a-
z. Plusieurs intervalles peuvent être combinés ; par exemple [0-9a-fA-F] correspond à un « chiffre » hexadécimal. Vous pouvez utiliser un antislash pour protéger un tiret qui serait sinon interprété comme un délimiteur d'intervalle, ou simplement le placer en début de liste (une pratique probablement moins lisible, mais plus traditionnelle).
Un chapeau (ou accent circonflexe, ou flèche vers le haut) au début de la classe de caractère l'inverse, la faisant correspondre à tout caractère ne se trouvant pas dans la liste. (Pour correspondre à un chapeau, ou bien ne le mettez pas au début, ou mieux, protégez-le avec un antislash.) Par exemple, [^aeiouy] correspond à tout caractère qui n'est pas une voyelle (non accentuée). Cependant, soyez prudent avec la négation de classe, car l'univers des caractères est en expansion. Par exemple, cette classe de caractère correspond aux consonnes — et aussi aux espaces, aux sauts de ligne, et à tout (y compris les voyelles) en cyrillique, en grec ou tout autre alphabet, sans compter tous les idéogrammes chinois, japonais et coréens. Et un jour aussi le cirth, le tengwar et le klingon. (Mais déjà le linéaire B et l'étrusque.) Il vaut donc peut-être mieux spécifier vos consonnes explicitement, comme [bcdfghjklmnpqrstvwxyz], ou [b-df-hj-np-tv-z] pour faire plus court. (Cela résout aussi le problème du « y » qui devrait être à deux endroits à la fois, ce qu'interdit l'utilisation de l'ensemble complémentaire.)
Les métasymboles caractères normaux, comme \n, \t, \cX, \NNN et \N{NOM} sont utilisables dans une classe de caractères (voir la section Caractères spécifiques). De plus, vous pouvez utiliser \b dans une classe de caractères pour signifier un espace arrière, exactement comme dans une chaîne entre apostrophes doubles. Normalement, dans une recherche de motif, il représente une limite de mot. Mais les assertions de largeur nulle n'ont aucun sens dans une classe de caractères, c'est pourquoi \b retrouve la signification qu'il a dans les chaînes. Vous pouvez également utiliser les classes de caractères prédéfinies qui sont décrites plus loin dans ce chapitre (classique, Unicode ou POSIX), mais n'essayez pas de les utiliser comme point initial ou final d'un intervalle — cela n'ayant pas de sens, le « -» sera interprété comme un caractère littéral.
Tous les autres métasymboles perdent leur signification spéciale quand ils sont entre crochets. En particulier, vous ne pouvez utiliser aucun des trois jokers génériques : « . », \X ou \C. Le premier surprend souvent, mais cela n'a pas grand sens d'utiliser la classe de caractère universelle à l'intérieur d'une classe plus restrictive, et de plus vous avez souvent besoin de faire une correspondance avec un point littéral dans une classe de caractère — quand vous travaillez sur des noms de fichier, par exemple. Cela n'a pas grand sens non plus de spécifier des quantificateurs, des assertions ou des alternatives dans une classe de caractères, puisque les caractères sont interprétés individuellement. Par exemple, [fee|fie|foe|foo] a exactement la même signification que [feio|].
5-5-b. Raccourcis de classes de caractères classiques Perl▲
Depuis l'origine, Perl a fourni un certain nombre de raccourcis pour les classes de caractères. La liste est fournie dans le tableau 5-8. Tous sont des métasymboles alphabétiques antislashés, et dans chaque cas, la version en majuscule est la négation de la version en minuscules. Leur signification est n'est pas aussi rigide que vous pourriez le croire : leur sens peut être influencé par les définitions de locales. Même si vous n'utilisez pas les locales, leur signification peut changer à chaque fois qu'un nouveau standard Unicode sortira, ajoutant de nouveaux scripts avec de nouveaux chiffres et de nouvelles lettres. (Pour conserver l'ancienne signification par octets, vous pouvez toujours utiliser use bytes. Voir Propriétés Unicode un peu plus loin dans ce chapitre pour des explications sur les correspondances utf8. Dans tous les cas, les correspondances utf8 sont un surensemble des correspondances sur les octets.) (Oui, nous savons que la plupart des mots ne comportent ni chiffres ni soulignés, mais parfois des accents ; \w sert à trouver des « mots » au sens des tokens dans un langage de programmation usuel. Ou en Perl.)
|
Symbole |
Signification |
En octets |
En utf8 |
|---|---|---|---|
|
\d |
Chiffre |
[ |
\p |
|
\D |
Non chiffre |
[ |
\P |
|
\s |
Blanc |
[ \t\n\r\f] |
\p |
|
\S |
Non blanc |
[ |
\P |
|
\w |
Caractère de mot |
[a |
\p |
|
\W |
Non-(caractère mot) |
[ |
\P |
Ces métacaractères peuvent être utilisés à l'extérieur ou à l'intérieur de crochets, c'est-à-dire soit par eux-mêmes ou comme élément d'une classe de caractères :
5-5-c. Propriétés Unicode▲
Les propriétés Unicode sont disponibles en utilisant \p{PROP} et son ensemble complémentaire \P{PROP}. Pour les rares propriétés qui ont un nom en un seul caractère, les accolades sont facultatives, comme dans \pN pour indiquer un caractère numérique (pas nécessairement décimal — les chiffres romains sont aussi des caractères numériques). Ces classes de propriétés peuvent être utilisées par elles-mêmes ou combinées dans une classe de caractères :
if ($var =~ /^\p{IsAlpha}+$/) { print "tout alphabétique" }
if ($var =~ s/[\p{Zl}\p{Zp}]/\n/g) { print "saut de lignes" }Certaines propriétés sont directement définies dans le standard Unicode, et d'autres sont des composées définies par Perl, en s'appuyant sur les propriétés standard. Zl et Zp sont des propriétés Unicode standard qui représentent les séparateurs de lignes et de paragraphes, tandis qu'IsAlpha est définie par Perl comme une classe regroupant les propriétés standard Ll, Lu, Lt et Lo (c'est-à-dire les lettres qui sont en majuscules, en minuscules, en casse de titre ou autre). À partir de la version 5.6.0 de Perl, vous avez besoin de use utf8 pour que ces propriétés fonctionnent. Cette restriction sera assouplie dans le futur.
Il y a un grand nombre de propriétés. Nous allons lister celles que nous connaissons, mais la liste sera forcément incomplète. De nouvelles propriétés sont susceptibles d'apparaître dans les nouvelles versions d'Unicode, et vous pouvez même définir vos propres propriétés. Nous verrons cela plus loin.
Le Consortium Unicode produit les informations que l'on retrouve dans les nombreux fichiers que Perl utilise dans son implémentation d'Unicode. Pour plus d'informations sur ces fichiers, voyez le chapitre 15. Vous pouvez lire un bon résumé de ce qu'est Uni-code dans le document PATH_TO_PERLLIB/unicode/Unicode3.html où PATH_TO_PERLLIB est ce qui est affiché par :
perl -MConfig -le 'print $Config{privlib}'La plupart des propriétés Unicode sont de la forme \p{IsPROP}. Le Is est facultatif, mais vous pouvez le laisser pour des raisons de lisibilité.
5-5-c-i. Propriétés Unicode de Perl▲
Le tableau 5-9 donne la liste des propriétés composites de Perl. Elles sont définies de façon à être raisonnablement proches des définitions POSIX standard pour les classes de caractères.
|
Propriété |
Équivalent |
|---|---|
|
IsASCII |
[\x00 |
|
IsAlnum |
[\p |
|
IsAlpha |
[\p |
|
IsCntrl |
\p |
|
IsDigit |
\p |
|
IsGraph |
[ |
|
IsLower |
\p |
|
IsPrint |
\P |
|
IsPunct |
\p |
|
IsSpace |
[\t\n\f\r\p |
|
IsUpper |
[\p |
|
IsWord |
[_\p |
|
IsXDigit |
[ |
Perl fournit également les composites suivants pour chacune des principales catégories des propriétés Unicode standard (voir la section suivante) :
|
Propriété |
Signification |
Normative |
|---|---|---|
|
IsC |
Codes de contrôle et équivalents |
Oui |
|
IsL |
Lettres |
Partiellement |
|
IsM |
Marqueurs |
Oui |
|
IsN |
Nombres |
Oui |
|
IsP |
Ponctuation |
Non |
|
IsS |
Symboles |
Non |
|
IsZ |
Séparateurs (Zéparateurs?) |
Oui |
5-5-c-ii. Propriétés Unicode standard▲
Le tableau 5-10 donne la liste des propriétés Unicode standard les plus basiques, qui dérivent de la catégorie de chaque caractère. Aucun caractère n'est membre de plus d'une catégorie. Certaines propriétés sont normatives ; d'autres sont simplement informatives. Reportez-vous au standard Unicode pour savoir combien l'information normative est normative, et combien l'information informative ne l'est pas.
|
Propriété |
Signification |
Normative |
|---|---|---|
|
IsCc |
Autre, contrôle |
Oui |
|
IsCf |
Autre, format |
Oui |
|
IsCn |
Autre, non affecté |
Oui |
|
IsCo |
Autre, usage privé |
Oui |
|
IsCs |
Autre, substitut |
Oui |
|
IsLl |
Lettre, minuscule |
Oui |
|
IsLm |
Lettre, modificateur |
Non |
|
IsLo |
Lettre, autre |
Non |
|
IsLt |
Lettre, casse de titre |
Oui |
|
IsLu |
Lettre, majuscule |
Oui |
|
IsMc |
Marque, combinante |
Oui |
|
IsMe |
Marque, entourant |
Oui |
|
IsMn |
Marque, non-espacement |
Oui |
|
IsNd |
Nombre, chiffre décimal |
Oui |
|
IsNl |
Nombre, lettre |
Oui |
|
IsNo |
Nombre, autre |
Oui |
|
IsPc |
Ponctuation, connecteur |
Non |
|
IsPd |
Ponctuation, tiret |
Non |
|
IsPe |
Ponctuation, fermeture |
Non |
|
IsPf |
Ponctuation, guillemet fermant |
Non |
|
IsPi |
Ponctuation, guillemet ouvrant |
Non |
|
IsPo |
Ponctuation, autre |
Non |
|
IsPs |
Ponctuation, ouvert |
Non |
|
IsSc |
Symbole, monnaie |
Non |
|
IsSk |
Symbole, modificateur |
Non |
|
IsSm |
Symbole, math |
Non |
|
IsSo |
Symbole, autre |
Non |
|
IsZl |
Séparateur, de ligne |
Oui |
|
IsZp |
Séparateur, de paragraphe |
Oui |
|
IsZs |
Séparateur, espace |
Oui |
Un autre ensemble de propriétés utiles est lié au fait qu'un caractère peut être décomposé (de façon canonique ou compatible) en d'autres caractères plus simples. La décomposition canonique ne perd aucune information de formatage. La décomposition compatible peut perdre des informations de formatage, comme le fait de savoir si le caractère est en exposant.
|
Propriété |
Information perdue |
|---|---|
|
IsDecoCanoni |
Rien |
|
IsDecoCompati |
Quelque chose (parmi les suivants) |
|
IsDCcirclei |
Cercle autour du caractère |
|
IsDCfinali |
Préférence de position finale (Arabe) |
|
IsDCfonti |
Préférence de variante de fonte |
|
IsDCfractioni |
Caractéristique de fraction ordinaire |
|
IsDCinitiali |
Préférence de position initiale (Arabe) |
|
IsDCisolatedi |
Préférence de position isolée (Arabe) |
|
IsDCmediali |
Préférence de position médiane (Arabe) |
|
IsDCnarrowi |
Caractéristique d'étroitesse |
|
IsDCnoBreaki |
Préférence de non-coupure sur un espace ou un tiret |
|
IsDCsmalli |
Caractéristique de petite taille |
|
IsDCsquarei |
Carré autour d'un caractère CJK |
|
IsDCsubi |
Position d'indice |
|
IsDCsuperi |
Position d'exposant |
|
IsDCverticali |
Rotation (d'horizontal à vertical) |
|
IsDCwidei |
Caractéristique de largeur |
|
IsDCcompati |
Identité (variable) |
Voici quelques propriétés qui intéressent les personnes faisant du rendu bidirectionnel :
|
Propriété |
Signification |
|---|---|
|
IsBidiL |
Gauche à droite (Arabe, Hébreu) |
|
IsBidiLRE |
Inclusion de gauche à droite |
|
IsBidiLRO |
Force de gauche à droite |
|
IsBidiR |
Droite à gauche |
|
IsBidiAL |
Droite à gauche arabe |
|
IsBidiRLE |
Inclusion de droite à gauche |
|
IsBidiRLO |
Force de droite à gauche |
|
IsBidiPDF |
Dépile le format directionnel |
|
IsBidiEN |
Nombre européen |
|
IsBidiES |
Séparateur de nombre européen |
|
IsBidiET |
Terminateur de nombre européen |
|
IsBidiAN |
Nombre arabe |
|
IsBidiCS |
Séparateur de nombres communs |
|
IsBidiNSM |
Marque de non-espacement |
|
IsBidiBN |
Limite neutre |
|
IsBidiB |
Séparateur de paragraphe |
|
IsBidiS |
Séparateur de segment |
|
IsBidiWS |
Blanc |
|
IsBidiON |
Autres neutres |
|
IsMirrored |
Image miroir quand utilisé de droite à gauche |
Les propriétés suivantes classent différents syllabaires selon les sonorités des voyelles :
|
IsSylA |
IsSylE |
IsSylO |
IsSylWAA |
IsSylWII |
|
IsSylAA |
IsSylEE |
IsSylOO |
IsSylWC |
IsSylWO |
|
IsSylAAI |
IsSylI |
IsSylU |
IsSylWE |
IsSylWOO |
|
IsSylAI |
IsSylII |
IsSylV |
IsSylWEE |
IsSylWU |
|
IsSylC |
IsSylN |
IsSylWA |
IsSylWI |
IsSylWV |
Par exemple, \p{IsSylA} correspondrait à \N{KATAKANA LETTER KA}, mais pas à \N{KATAKANA LETTER KU}.
Maintenant que nous vous avons parlé de toutes ces propriétés Unicode 3.0, nous devons tout de même lister quelques-unes des plus ésotériques qui ne sont pas implémentées dans Perl 5.6.0, car cette implémentation était basée en partie sur Unicode 2.0, et que des choses comme l'algorithme bidirectionnel étaient encore sur le métier. Cependant, comme d'ici à ce que vous lisiez ceci, les propriétés manquantes pourraient bien avoir été implémentées, nous les avons listées quand même.
5-5-c-iii. Propriétés de bloc Unicode▲
Certaines propriétés Unicode sont de la forme \p{InSCRIPT}. (Remarquez la distinction entre Is et In.) Les propriétés In servent à tester l'appartenance à des blocs d'un SCRIPT unique. Si vous avez un caractère et que vous vous demandez s'il est écrit en écriture hébraïque, vous pouvez le tester avec :
print "Pour moi c'est de l'Hébreu!\n" if chr(1488) =~ /\p{InHebrew}/;Cela fonctionne en vérifiant si un caractère est « dans » l'intervalle valide de ce type d'écriture. Cela peut être inversé avec \P{InSCRIPT} pour savoir si quelque chose n'est pas dans un bloc de script particulier, comme \P{InDingbats} pour savoir si une chaîne contient un caractère non dingbat. Dans les propriétés de bloc, on trouve les éléments suivants :
|
InArabic |
InCyrillic |
InHangulJamo |
InMalayalam |
InSyriac |
|
InArmenian |
InDevanagari |
InHebrew |
InMongolian |
InTamil |
|
InArrows |
InDingbats |
InHiragana |
InMyanmar |
InTelugu |
|
InBasicLatin |
InEthiopic |
InKanbun |
InOgham |
InThaana |
|
InBengali |
InGeorgian |
InKannada |
InOriya |
InThai |
|
InBopomofo |
InGreek |
InKatakana |
InRunic |
InTibetan |
|
InBoxDrawing |
InGujarati |
InKhmer |
InSinhala |
InYiRadicals |
|
InCherokee |
InGurmukhi |
InLao |
InSpecials |
InYiSyllables |
Sans oublier les impressionnants :
|
InAlphabeticPresentationForms |
InHalfwidthandFullwidthForms |
|
InArabicPresentationForms-A |
InHangulCompatibilityJamo |
|
InArabicPresentationForms-B |
InHangulSyllables |
|
InBlockElements |
InHighPrivateUseSurrogates |
|
InBopomofoExtended |
InHighSurrogates |
|
InBraillePatterns |
InIdeographicDescriptionCharacters |
|
InCJKCompatibility |
InIPAExtensions |
|
InCJKCompatibilityForms |
InKangxiRadicals |
|
InCJKCompatibilityIdeographs |
InLatin-1Supplement |
|
InCJKRadicalsSupplement |
InLatinExtended-A |
|
InCJKSymbolsandPunctuation |
InLatinExtended-B |
|
InCJKUnifiedIdeographs |
InLatinExtendedAdditional |
|
InCJKUnifiedIdeographsExtensionA |
InLetterlikeSymbols |
|
InCombiningDiacriticalMarks |
InLowSurrogates |
|
InCombiningHalfMarks |
InMathematicalOperators |
|
InCombiningMarksforSymbols |
InMiscellaneousSymbols |
|
InControlPictures |
InMiscellaneousTechnical |
|
InCurrencySymbols |
InNumberForms |
|
InEnclosedAlphanumerics |
InOpticalCharacterRecognition |
|
InEnclosedCJKLettersandMonths |
InPrivateUse |
|
InGeneralPunctuation |
InSuperscriptsandSubscripts |
|
InGeometricShapes |
InSmallFormVariants |
|
InGreekExtended |
InSpacingModifierLetters |
Et le mot le plus long :
- InUnifiedCanadianAboriginalSyllabics
Pas mieux.
Consultez PATH_TO_PERLLIB/unicode/In/*.pl pour obtenir une liste à jour de toutes ces propriétés de blocs de caractères. Remarquez que les propriétés In ne font que vérifier si le caractère est dans l'intervalle alloué pour ce script. Rien ne vous garantit que tous les caractères dans cet intervalle sont définis ; vous devrez également tester l'une des propriétés Is discutées précédemment pour vérifier si le caractère est défini. Rien ne vous garantit non plus qu'une langue particulière n'utilise pas des caractères en dehors de l'intervalle qui lui est affecté. En particulier, de nombreuses langues européennes mélangent les caractères latins étendus avec des caractères Latin-1.
Mais bon, si vous avez besoin d'une propriété particulière qui n'est pas fournie, ce n'est pas un gros problème. Continuez à lire.
5-5-d. Définir vos propres propriétés de caractères▲
Pour définir vos propres propriétés, vous devrez écrire un sous-programme portant le nom de la propriété que vous voulez (voir chapitre 6, Sous-programmes). Le sous-programme doit être défini dans le paquetage qui a besoin de la propriété, ce qui signifie que si vous désirez l'utiliser dans plusieurs paquetages, vous devrez soit l'importer d'un autre module (voir chapitre 11, Modules), ou l'hériter comme méthode de classe depuis le paquetage dans lequel il est défini (voir chapitre 12, Objets).
Une fois que cela est fait, le sous-programme doit renvoyer des données dans le même format que les fichiers du répertoire PATH_TO_PERLLIB/unicode/Is. C'est-à-dire que vous devez juste retourner une liste de caractères ou des intervalles de caractères en hexadécimal, un par ligne. S'il y a un intervalle, les deux nombres sont séparés par une tabulation. Supposons que vous vouliez créer une propriété qui serait vraie si votre caractère est dans l'intervalle de l'un des deux syllabaires japonais, nommés hiragana et katakana. (Ensemble on les appelle simplement kana.) Vous pouvez juste mettre les deux intervalles comme suit :
Vous pourriez également le définir à l'aide de noms de propriétés existantes :
Vous pouvez aussi faire une soustraction en utilisant un préfixe « -». Supposons que vous ne vouliez que les véritables caractères, et pas seulement les blocs de caractères. Vous pouvez retirer tous les caractères indéfinis comme ceci :
Vous pouvez aussi démarrer avec le complément d'un ensemble de caractères en utilisant le préfixe « ! »:
Perl lui-même utilise les mêmes trucs pour définir la signification de ses propres classes de caractères « classiques » (comme \w) quand vous les incluez dans vos classes de caractères personnalisées (comme [-.\w\s]). Vous pourriez penser que plus les règles deviennent compliquées, plus lentement cela tournera ; mais en fait, une fois que Perl a calculé le motif de bits pour le bloc de 64 bits de votre propriété, il le mémorise pour n'avoir jamais à le recalculer. (Cela est fait dans des blocs de 64 bits pour ne même pas avoir à décoder votre utf8 pour faire les recherches.) Ainsi, toutes les classes de caractères, internes ou personnalisées, tournent toutes à peu près à la même vitesse (rapide) une fois mises en route.
5-5-e. Classes de caractères de style POSIX▲
Contrairement aux autres raccourcis de classes de caractères, la notation de style POSIX, [:CLASSE:], n'est utilisable que pour la construction d'autres classes de caractères, c'est-à-dire à l'intérieur d'une autre paire de crochets. Par exemple, /[.,[:alpha:][:digit:]]/ va chercher un caractère qui est soit un point (littéral, car dans une classe de caractères), une virgule, ou un caractère alphabétique ou un nombre.
Les classes POSIX disponibles à partir de la version 5.6 de Perl sont listées dans le tableau 5-11.
|
Classe |
Signification |
|---|---|
|
alnum |
Tout alphanumérique, c'est-à-dire un alpha ou un digit. |
|
alpha |
Toute lettre. (Cela fait beaucoup plus de lettres que vous pensez, sauf si vous pensez en Unicode, auquel cas cela fait quand même beaucoup.) |
|
ascii |
Tout caractère avec une valeur numérique comprise entre 0 et 127. |
|
cntrl |
Tout caractère de contrôle. En général ce sont des caractères qui ne produisent pas d'affichage par eux-mêmes, mais contrôlent le terminal d'une façon ou d'une autre. Par exemple, les caractères de nouvelle ligne, de fin de page ou d'espace arrière sont des caractères de contrôle. Les caractères |
|
ayant |
une valeur numérique inférieure à 32 sont le plus souvent considérés comme des caractères de contrôle. |
|
digit |
Un caractère représentant un chiffre décimal, comme ceux entre 0 et 9. (Cela comprend d'autres caractères en Unicode.) Équivalent à \d. |
|
graph |
Tout caractère alphanumérique ou de ponctuation. |
|
lower |
Une lettre minuscule. |
|
|
Tout caractère alphanumérique, de ponctuation ou d'espacement. |
|
punct |
Tout caractère de ponctuation. |
|
space |
Tout caractère d'espacement. Cela inclut tabulation, nouvelle ligne, saut de page et retour chariot (et encore beaucoup plus en Unicode). Équivalent à \s. |
|
upper |
Tout caractère en majuscule (ou casse de titre). |
|
word |
Tout caractère d'identificateur, soit un alnum ou un souligné. |
|
xdigit |
Tout chiffre hexadécimal. Bien que cela semble un peu bête ([0-9a-fA-F] marche très bien), c'est inclus pour être complet. |
Vous pouvez inverser la classe de caractères POSIX en préfixant le nom de la classe par un ^ après le [:. (C'est une extension apportée par Perl.) Par exemple :
|
POSIX |
Classique |
|---|---|
|
[: |
\D |
|
[: |
\S |
|
[: |
\W |
Si le pragma use utf8 n'est pas demandé, mais que le pragma use locale l'est, la classe correspond directement avec les fonctions équivalentes de l'interface isalpha(3) de la librairie C (excepté word, qui est une extension Perl correspondant à \w).
Si le pragma utf8 est utilisé, les classes de caractères POSIX sont exactement équivalentes aux propriétés Is listées dans le tableau 5-9. Par exemple, [:lower:] et \p{Lower} sont équivalentes, sauf que les classes POSIX ne peuvent être utilisées que dans les classes de caractères construites, tandis que les propriétés Unicode ne sont pas soumises à de telles restrictions et peuvent être utilisées dans des motifs partout où les raccourcis Perl comme \s et \w peuvent l'être.
Les crochets font partie de la construction de style POSIX [::] et pas de la classe de caractères. Ce qui nous amène à écrire des motifs tels que /^[[:lower:][:digit:]]+$/ pour correspondre à une chaîne consistant entièrement de lettres minuscules ou de chiffres (avec un saut de ligne final facultatif). En particulier, ceci ne fonctionne pas :
42 =~ /^[:digit:]+$/ # FAUXCela est dû au fait qu'on n'est pas dans une classe de caractères. Ou plutôt, c'est une classe de caractères, celle qui représente les caractères « : », « i », « t », « g » et « d ». Perl se moque du fait que vous ayez utilisé deux « : » (et deux « i »).
Voici ce dont vous avez en fait besoin :
42 =~ /^[[:digit:]]+$/Les classes de caractères POSIX [.cc.] et [=cc=] sont reconnues, mais produisent une erreur indiquant qu'elles ne sont pas utilisables. L'utilisation de n'importe quelle classe de caractères POSIX dans une version de Perl plus ancienne ne marchera pas, et de façon probablement silencieuse. Si vous comptez utiliser les classes de caractères POSIX, il est préférable d'imposer l'utilisation d'une nouvelle version de Perl en écrivant :
use 5.6.0;5-6. Quantificateurs▲
À moins que vous n'en décidiez autrement, chaque élément d'une expression régulière ne correspond qu'une fois à quelque chose. Avec un motif comme /nop/, chacun de ces caractères doit correspondre, l'un à la suite de l'autre. Les mots comme « panoplie » ou « xénophobie » marchent bien, car où la correspondance se fait n'a aucune importance.
Si vous vouliez trouver à la fois « xénophobie » et « Snoopy », vous ne pourriez pas utiliser le motif /nop/, puisque cela requiert qu'il n'y ait qu'un seul « o » entre le « n » et le « p », et que Snoopy en a deux. C'est ici que les quantificateurs montrent leur utilité : ils indiquent combien de fois quelque chose peut correspondre, au lieu de une fois par défaut. Les quantificateurs dans une expression régulière sont comme les boucles dans un programme ; en fait, si vous regardez une expression régulière comme un programme, alors ce sont des boucles. Certaines boucles sont exactes, comme « répète cette correspondance cinq fois seulement » ({5}). D'autres vous donnent à la fois la limite inférieure et la limite supérieure du nombre de correspondances, comme « répète ceci au moins deux fois, mais pas plus de quatre » ({2,4}). D'autres n'ont pas de limite supérieure du tout, comme « trouve ceci au moins deux fois, mais ensuite autant de fois que tu veux » ({2,}).
Le tableau 5-12 liste les quantificateurs que Perl reconnaît dans un motif.
|
Maximum |
Minimum |
Plage autorisée |
|---|---|---|
|
{MIN, |
MAX} {MIN, MAX}? |
Doit apparaître au moins MIN fois, mais pas plus de MAX fois |
|
{MIN,} |
{MIN,}? |
Doit apparaître au moins MIN fois |
|
{COMPTE} |
{COMPTE}? |
Doit apparaître exactement COMPTE fois |
|
|
|
0 ou plus (comme {0,}) |
|
|
|
1 fois ou plus (comme {1,}) |
|
|
|
0 ou 1 fois (comme {0,1}) |
Quelque chose suivi d'un * ou d'un ? n'est pas obligé de correspondre à tout prix. C'est parce que cela peut correspondre 0 fois et toujours être considéré comme un succès. Un + est souvent un meilleur choix, car l'élément recherché doit être présent au moins une fois.
Ne vous laissez pas embrouiller par l'emploi de « exactement » dans le tableau précédent. Il ne fait référence qu'au nombre de répétitions, et pas à la chaîne complète. Par exemple, $n =~ /\d{3}/ ne dit pas « est-ce que cette chaîne fait exactement trois chiffres de long ? ». En fait le motif se préoccupe de savoir s'il existe une position dans $n à laquelle trois chiffres apparaissent les uns à la suite des autres. Des chaînes comme « 101 rue de la République » correspondent, tout comme des chaînes telles que « 75019 » ou « 0 825 827 829 ». Toutes contiennent trois chiffres à la suite à un ou plusieurs endroits, ce qui est tout ce que vous demandiez. Voir dans la section Positions l'utilisation des assertions de position (comme dans /^\d{3}$/) pour préciser votre recherche.
Si on leur donne la possibilité de correspondre un nombre variable de fois, les quantificateurs maximaux vont essayer de maximiser le nombre de répétitions. C'est pourquoi quand nous disons « autant de fois que tu veux », les quantificateurs gourmands le comprennent comme « le plus de fois que tu le peux », à la seule condition que cela n'empêche pas des spécifications plus loin dans l'expression de correspondre. Si un motif contient deux quantificateurs ouverts, les deux ne peuvent évidemment pas consommer l'intégralité de la chaîne : les caractères utilisés par la première partie de l'expression ne sont plus disponibles pour la partie qui suit. Chaque quantificateur est gourmand aux dépens de ceux qui le suivent, en lisant le motif de gauche à droite.
C'est du moins le comportement traditionnel des quantificateurs dans les expressions régulières. Cependant Perl vous permet de modifier le comportement de ses quantificateurs : en mettant un ? après un quantificateur, vous le transformez de maximal en minimal. Cela ne signifie pas qu'un quantificateur minimal va toujours correspondre au nombre minimum de répétitions permises par ses spécifications, pas plus qu'un quantificateur maximal correspond toujours au plus grand nombre défini dans ses spécifications. La correspondance globale doit toujours se faire, et le quantificateur minimal prendra juste ce qu'il faut pour que ce soit un succès, et pas plus. (Les quantificateurs minimaux préfèrent la satisfaction à la gourmandise.)
Par exemple dans la correspondance :
"exigence" =~ /e(.*)e/ # $1 vaut maintenant "xigenc"le .* correspond à « xigenc », la plus longue chaîne possible à laquelle il peut correspondre. (Il stocke également cette valeur dans $1, comme cela est expliqué dans la section Capture et regroupement plus loin dans ce chapitre.) Bien qu'une correspondance plus courte fut possible, un quantificateur gourmand s'en moque. S'il a le choix entre deux possibilités à partir de la même position, il retournera toujours la plus longue des deux.
Comparez ceci avec cela :
"exigence" =~ /e(.*?)e/ # $1 vaut maintenant "xig"Ici, c'est la version minimale, .*?, qui est utilisée. L'ajout du ? à l'* fait que *? a un comportement opposé : ayant le choix entre deux possibilités à partir du même point, il prend toujours la plus courte des deux.
Bien que vous puissiez lire *? comme une injonction à correspondre à zéro ou plus de quelque chose en préférant zéro, cela ne veut pas dire qu'il correspondra toujours à zéro caractère. Si c'était le cas ici, par exemple, et qu'il laissait $1 à la valeur "", alors le second
« e » ne serait pas trouvé, puisqu'il ne suit pas immédiatement le premier.
Vous pourriez aussi vous demander pourquoi, alors qu'il cherchait une correspondance minimale avec /e(.*?)e/, Perl n'a pas plutôt mis « nc » dans $1. Après tout, « nc » se trouve lui aussi entre deux e et est plus court que « xig ». En Perl, le choix minimal/maximal se fait seulement lorsqu'on recherche la plus courte ou la plus longue parmi plusieurs correspondances ayant toutes le même point de départ. Si plusieurs correspondances possibles existent, mais commencent à des endroits différents dans la chaîne, alors leurs longueurs n'ont aucune importance — pas plus que le fait que vous ayez utilisé un quantificateur minimal ou maximal. La première de plusieurs correspondances possibles est toujours prépondérante devant celles qui la suivent. C'est seulement lorsque plusieurs correspondances possibles démarrent du même point dans la chaîne que le côté minimal ou maximal de la correspondance sert à les départager. Si les points de départ sont différents, il n'y a rien à départager. Les correspondances de Perl sont normalement de type la plus à gauche la plus longue ; avec une correspondance minimale, cela devient la plus à gauche la plus courte. Mais la partie la plus à gauche ne change pas et reste le critère dominant.(75)
Il y a deux manières de passer l'orientation à gauche du détecteur de motif. Premièrement vous pouvez utiliser un quantificateur gourmand au début (typiquement .*) pour essayer de consommer le début de la chaîne. En cherchant la correspondance pour un quantificateur gourmand, il essaie d'abord la correspondance la plus longue ce qui provoque effectivement une recherche de droite à gauche dans le reste de la chaîne :
"exigence" =~ /.*e(.*?)e/ # $1 vaut maintenant "nc"Mais faites attention avec cette méthode, car la correspondance complète contient maintenant toute la chaîne jusqu'à ce point.
La seconde manière de défaire cette inclination à gauche est d'utiliser les assertions de position, qui sont discutées dans la section suivante.
5-7. Positions▲
Certaines constructions de regex représentent des positions dans la chaîne à traiter, qui est juste un emplacement à gauche ou à droite d'un véritable caractère. Ces métasymboles sont des exemples d'assertions de largeur nulle. Nous les appellerons souvent simplement « assertions ». (On les connaît aussi sous le nom d'« ancres », car elles lient une partie du motif à une position particulière.)
Vous pouvez toujours manipuler les positions dans une chaîne sans utiliser de motif. La fonction intégrée substr vous permet d'extraire et d'affecter des sous-chaînes, calculées à partir du début de la chaîne, de la fin de la chaîne ou à partir d'une position numérique particulière. C'est juste ce dont vous avez besoin si vous travaillez avec des enregistrements de longueur fixe. Les motifs deviennent nécessaires quand un décalage numérique n'est plus suffisant. Et la plupart du temps, les décalages ne sont pas suffisants — disons pas suffisamment commodes, par rapport aux motifs.
5-7-a. Les débuts : assertions \A et ^▲
L'assertion \A correspond seulement au début de la chaîne, quelles que soient les circonstances. Cependant l'assertion ^ est l'assertion traditionnelle de début de ligne, ainsi que celle de début de chaîne. C'est pourquoi si le motif utilise le modificateur /m(76) et que la chaîne contient des sauts de ligne, ^ correspond également n'importe où dans la chaîne immédiatement après un caractère de saut de ligne :
/\Abar/ # Correspond à "bar" et "barbecue"
/^bar/ # Correspond à "bar" et "barbecue"
/^bar/m # Correspond à "bar" et "barbecue" et "zinc\nbar"Utilisée en même temps que /g, le modificateur /m permet à ^ de correspondre plusieurs fois dans la même chaîne :
s/^\s+//gm; # Supprime les blancs en tête de chaque ligne
$total++ while /^./mg; # Compte les lignes qui ne sont pas vides5-7-b. Fins : assertions \z, \Z et $▲
Le métasymbole \z correspond à la fin de la chaîne, quoi qu'il y ait à l'intérieur. \Z correspond juste avant le saut de ligne en fin de chaîne s'il y en a un, ou à la fin s'il n'y en a pas. Le métacaractère $ signifie en général la même chose que \Z. Cependant, si le modificateur /m a été spécifié et que la chaîne contient des sauts de ligne, alors $ peut aussi correspondre n'importe où dans la chaîne, juste avant un saut de ligne :
/bot\z/ # Correspond avec "robot"
/bot\Z/ # Correspond avec "robot" et "poulbot\n"
/bot$/ # Correspond avec "robot" et "poulbot\n"
/bot$/m # Correspond avec "robot" et "poulbot\n" et "robot\nménager"
/^robot$/ # Correspond avec "robot" et "robot\n"
/^robot$/m # Correspond avec "robot" et "robot\n" et "ce\nrobot\n"
/\Arobot\Z/ # Correspond avec "robot" et "robot\n"
/\Arobot\z/ # Correspond avec "robot" uniquement -- mais pourquoi ne
#pas avoir utilisé eq ?Tout comme avec ^, le modificateur /m permet à $ de correspondre plusieurs fois dans la même chaîne quand il est utilisé avec /g. (Ces exemples supposent que vous avez lu un enregistrement multiligne dans $_, par exemple en mettant $/ à "" avant la lecture.)
s/\s*$//gm; # Supprime les blancs en fin de chaque ligne du paragraphe
while (/^([^:]+):\s*(.*)/gm ) { # obtient les en-têtes de mail
$headers{$1} = $2;
}Plus loin dans ce chapitre, à la section Interpolation de variables, nous discuterons de la façon dont vous pouvez interpoler des variables dans des motifs : si $toto vaut « bc », alors /a$toto/ est équivalent à /abc/. Ici, le $ ne correspond pas à la fin de la chaîne. Pour qu'un $ corresponde à la fin de la chaîne, il doit être à la fin du motif ou être immédiatement suivi d'une barre verticale ou d'une parenthèse fermante.
5-7-c. Limites : assertions \b et \B▲
L'assertion \b correspond à toute limite de mot, celle-ci étant définie comme la position entre un caractère \w et un caractère \W, dans n'importe quel ordre. Si l'ordre est \W\w c'est la limite en début de mot, et si l'ordre est \w\W c'est la limite en fin de mot. (Une extrémité de chaîne compte comme un caractère \W ici.) L'assertion \B correspond à toute position qui n'est pas une limite de mot, c'est-à-dire au milieu de \w\w ou de \W\W.
/\best\b/ # correspond à "ce qu'il est" et "à l'est d'Eden"
/\Best\B/ # correspond à "zeste" et "intestin"
/\best\B/ # correspond à "estival" et "il t'estime"
/\Best\b/ # correspond à "al et "ouest puis nord"Comme \W comprend tous les caractères de ponctuation, (sauf le souligné), il y a des limites \b au milieu de chaînes comme « aujourd'hui », « booktech@oreilly.com »,
« S.N.C.F. » et « clef/valeur ».
À l'intérieur d'une classe de caractères ([\b]), un \b représente un caractère espace arrière plutôt qu'une limite de mot.
5-7-d. Reconnaissance progressive▲
Utilisée avec le modificateur /g, la fonction pos vous permet de connaître ou de modifier la position à partir de laquelle la prochaine comparaison progressive commencera :
$voleur = "Bilbon Baggins";
while ($voleur =~ /b/gi) {
printf "Trouvé un B en %d\n", pos($voleur)-1;
}(Nous retirons un de la position, car c'est la longueur de la chaîne que nous voulions, alors que pos renvoie toujours la position juste après la fin de la reconnaissance précédente.)
Le code ci-dessus affiche :
Trouvé un B en 0
Trouvé un B en 3
Trouvé un B en 7Après un échec, la position de reconnaissance est normalement remise à zéro. Si vous utilisez le modificateur /c (pour « continue »), alors quand le /g se termine, l'échec de la reconnaissance ne réinitialise pas le pointeur de position. Cela vous permet de continuer votre recherche au-delà de ce point, sans recommencer à partir du début.
$voleur = "Bilbon Baggins";
while ($voleur =~ /b/gci) { # AJOUT DE /c
printf "Trouvé un B en %d\n", pos($voleur)-1;
}
while ($voleur =~ /i/gi) {
printf "Trouvé un I en %d\n", pos($voleur)-1;
}En plus des trois B trouvés précédemment, Perl indique maintenant qu'il a trouvé un i à la position 11. Sans le /c, la seconde boucle de reconnaissance aurait recommencé depuis le début de la chaîne et d'abord trouvé un autre i à la position 1.
5-7-e. Là où vous en étiez : assertion \G▲
Dès que vous commencez à réfléchir en termes de la fonction pos, il est tentant de commencer à creuser dans votre chaîne à coups de substr, mais c'est rarement la bonne chose à faire. La plupart du temps, si vous avez commencé avec une recherche de motif, vous devriez continuer avec une recherche de motif. Cependant, si vous recherchez une assertion de position, c'est probablement \G qu'il vous faut.
L'assertion \G représente à l'intérieur du motif le même point que pos représente à l'extérieur. Quand vous faites une recherche progressive avec le modificateur /g (ou que vous avez utilisé la fonction pos pour sélectionner directement le point de départ), vous pouvez utiliser \G pour spécifier la position qui suit la fin de la reconnaissance précédente. C'est-à-dire qu'il reconnaît la position immédiatement avant le caractère qui serait identifié par pos. Cela vous permet de vous souvenir où vous en étiez :
($recette = <<'DISH') =~ s/^\s+//gm;
# Anchois sauce Roswel
Préchauffer le four à 451 deg. fahrenheit.
Mélanger 1 ml. de dilithium avec 3 oz. de
NaCl et y plonger 4 anchois. Glacer avec
1 gr. de mercure. Faire cuire 4 heures et
laisser refroidir 3 secondes. Pour 10 martiens.
DISH
$recette =~ /\d+ /g;
$recette =~ /\G(\w+)/; # $1 vaut "deg"
$recette =~ /\d+ /g;
$recette =~ /\G(\w+)/; # $1 vaut "ml"
$recette =~ /\d+ /g;
$recette =~ /\G(\w+)/; # $1 vaut "gr"Le métasymbole \G est souvent utilisé dans une boucle, comme nous allons le montrer dans notre prochain exemple. Nous faisons une « pause » après chaque suite de chiffres, et à cette position, nous testons s'il y a une abréviation. Si oui, nous récupérons les deux mots qui suivent. Sinon, nous récupérons seulement le mot suivant :
pos($recette) = 0; # Par sécurité, initialise \G à 0
while ( $recette =~ /(\d+) /g ) {
my $quantite = $1;
if ($recette =~ / \G (\w{0,3}) \. \s+ de \s+ (\w+) /x) { # abrév. + mot
print "$quantite $1 de $2\n";
} else {
$recette =~ / \G (\w+) /x; # juste un mot
print "$quantite $1\n";
}
}Ce qui donne :
451 deg
1 ml de dilithium
3 oz de NaCl
4 anchois
1 gr de mercure
4 heures
3 secondes
10 martiens5-8. Capture et regroupement▲
Les motifs vous permettent de regrouper des portions de votre motif dans des sous-motifs et de vous souvenir des chaînes reconnues par ces sous-motifs. Nous appellerons le premier comportement regroupement et le second capture.
5-8-a. Capture▲
Pour capturer une sous-chaîne pour une utilisation ultérieure, mettez des parenthèses autour du motif qui la reconnaît. La première paire de parenthèses stocke sa sous-chaîne dans $1, la deuxième paire dans $2 et ainsi de suite. Vous pouvez utiliser autant de parenthèses que vous voulez ; Perl continuera à définir des variables numérotées pour que vous puissiez représenter ces chaînes capturées.
Quelques exemples :
/(\d)(\d)/ # Trouve deux chiffres, qui sont capturés dans $1 et $2
/(\d+)/ # Trouve un ou plusieurs chiffres, capturés ensemble dans $1
/(\d)+/ # Trouve un chiffre une fois ou plus, et capture le dernier dans $1Remarquez la différence entre le deuxième et le troisième motifs. La deuxième forme est en général ce que vous voulez. La troisième forme ne crée pas plusieurs variables pour plusieurs chiffres. Les parenthèses sont numérotées quand le motif est compilé, pas quand il est utilisé.
Les chaînes capturées sont souvent appelées références arrière, car elles font référence à des parties du texte situées en arrière par rapport à la position courante. Il existe en fait deux manières d'utiliser ces références arrière. Les variables numérotées que vous avez vues donnent accès en dehors du motif aux références arrière, mais à l'intérieur du motif, cela ne marche pas. Vous devez utiliser \1, \2, etc.(77) Pour trouver les mots doublés comme « le le » ou « est est », vous pourriez utiliser ce motif :
/\b(\w+) \1\b/iMais la plupart du temps, vous utiliserez la forme $1, car en général on applique un motif, pour ensuite faire quelque chose des sous-chaînes. Supposons que vous ayez du texte (des en-têtes de mail) qui ressemble à ça :
From: gnat@perl.com
To: camelot@oreilly.com
Date: Mon, 17 Jul 2000 09:00:00 -1000
Subject: Eye of the needle
et que vous vouliez construire un hachage qui fasse lelien entre le texte avant les deux-points et celui après. Si vous boucliez sur ce texte ligne à ligne (par exemple parce que vous lisez un fichier), vous pourriez faire comme suit :
while (<>) {
/^(.*?): (.*)$/; # Texte avant les deux-points dans $1, après dans $2
$champs{$1} = $2;
}Comme $`, $& et $'', ces variables numérotées sont à portée dynamique jusqu'à la fin du bloc ou de la chaîne eval englobant, ou jusqu'à la prochaine recherche de motif réussie, selon lequel se produit le premier. Vous pouvez également les utiliser dans la partie droite (la zone de remplacement) d'une substitution :
s/^(\S+) (\S+)/$2 $1/; # Intervertit les deux premiers motsLes regroupements peuvent s'emboîter, et quand ils le font, les groupes sont comptés par l'ordre de leurs parenthèses ouvrantes. Donc, si on donne la chaîne « Primula Brandebouc » au motif :
/^((\w+) (\w+))$/il capturerait « Primula Brandebouc » dans $1, « Primula » dans $2, et « Brandebouc » dans $3. Cela est décrit à la figure 5-1.
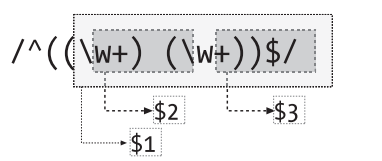
Les motifs avec capture sont souvent utilisés en contexte de liste pour remplir une liste de valeurs, car le motif est assez malin pour retourner les sous-chaînes comme une liste :
($premier, $dernier) = /^(\w+) (\w+)$/;
($tout, $premier, $dernier) = /^((\w+) (\w+))$/;Avec le modificateur /g, un motif peut renvoyer plusieurs sous-chaînes issues de plusieurs correspondances, le tout dans une seule liste. Supposons que vous ayez l'en-tête que nous avons vu précédemment dans une seule chaîne (disons dans $_). Vous pourriez faire la même chose que notre boucle ligne à ligne avec une seule instruction :
%champs = /^(.*?): (.*)$/gm;Le motif réussit quatre fois, et à chaque fois il trouve deux sous-chaînes. La recherche /gm retourne l'ensemble comme une liste plate de huit chaînes, que l'affectation de liste à %champs interprètera comme quatre couples clef/valeur, ramenant ainsi l'harmonie dans l'univers.
Plusieurs autres variables spéciales traitent du texte capturé dans des recherches de motif. $& contient la chaîne trouvée dans son ensemble, $` tout ce qui est à gauche de la correspondance, $' tout ce qui est à droite. $+ garde le contenu de la dernière référence arrière.
$_ = "Parlez, <EM>ami</EM>, et entrez.";
m[ (<.*?>) (.*?) (</.*?>) ]x; # Une balise, du texte, et une balise de fin
print "prematch: $`\n"; # Parlez,
print "match: $&\n"; # <EM>ami</EM>
print "postmatch: $'\n"; # , et entrez.
print "lastmatch: $+\n"; # </EM>Pour plus d'explication sur ces variables elfiques magiques (et pour savoir comment les écrire en anglais), voir le chapitre 28, Noms spéciaux.
Le tableau @- (@LAST_MATCH_START) contient les positions des débuts de chacune des correspondances, et @+ (@LAST_MATCH_END) contient les positions de leurs fins :
#!/usr/bin/perl
$alphabet = "abcdefghijklmnopqrstuvwxyz";
$alphabet =~ /(hi).*(stu)/;
print "La recherche complète a commencé en $-[0] et s'est terminée en $+[0]\n";
print "La première recherche a commencé en $-[1] et s'est terminée en $+[1]\n";
print "La deuxième recherche a commencé en $-[2] et s'est terminée en $+[2]\n";Si vous voulez trouver une parenthèse littérale plutôt que de l'interpréter comme un métacaractère, antislashez-la :
/\(p.e., .*?\)/Ceci trouve un exemple entre parenthèses (p.e., celui-ci). Mais comme le point est un joker, cela trouve aussi toute phrase entre parenthèses dont la première lettre est un p et la troisième un e (pied, par exemple).
5-8-b. Regroupement▲
Les parenthèses simples regroupent et capturent à la fois. Mais parfois vous n'en demandez pas tant. Parfois vous voulez juste regrouper des portions du motif sans créer de référence arrière. Vous pouvez utiliser une forme étendue de parenthèses pour supprimer la capture : la notation (?:PATTERN) va regrouper sans capturer.
Il y a au moins trois raisons pour lesquelles vous voudrez regrouper sans capturer :
- Pour quantifier quelque chose.
- Pour limiter la portée d'une alternative ; par exemple,
/^chat|chien|vache$/aura besoin d'être écrit/^(?:chat|chien|vache)$si vous ne voulez pas que le chat file avec le^. - Pour limiter la portée d'un modificateur de motif à un sous-motif spécifique, comme dans
/toto(?-i:Attention_A_La_Casse)titi/i. (Voir la section suivante, Modificateurs cloîtrés.)
De plus, il est plus efficace de supprimer la capture de quelque chose que vous n'allez pas utiliser. En revanche, la notation est un peu moins lisible.
Dans un motif, une parenthèse ouvrante immédiatement suivie d'un point d'interrogation indique une extension de regex. Le bestiaire actuel des expressions régulières est relativement fixé — nous n'osons pas créer un nouveau métacaractère, de peur de casser d'anciens programmes Perl. Au lieu de cela, la syntaxe d'extension permet d'ajouter de nouvelles fonctionnalités au bestiaire.
Dans le reste du chapitre, nous allons voir beaucoup d'autres extensions de regex, lesquelles feront toutes du regroupement sans capture, avec quelque chose d'autre. L'extension (?:MOTIF) est spéciale en ce qu'elle ne fait rien d'autre. Donc si vous écrivez :
@champs = split(/\b(?:a|b|c)\b/)c'est comme :
@champs = split(/\b(a|b|c)\b/)sauf que cela ne renvoie pas de champs supplémentaires. (L'opérateur split est un peu comme m//g en ce qu'il retournera des champs supplémentaires pour chaque chaîne capturée dans le motif. D'ordinaire, split ne retourne que ce qui n'a pas été trouvé. Pour en savoir plus sur split, voir le chapitre 29.)
5-8-c. Modificateurs cloîtrés▲
Vous pouvez cloîtrer les modificateurs /i, /m, /s et /x dans une portion de votre motif en les insérant (sans le slash) entre le ? et le : de la notation de regroupement. Si vous écrivez :
/Harry (?i:s) Truman/cela correspondra à la fois à « Harry S Truman » et à « Harry s Truman », tandis que :
/Harry (?x: [A-Z] \.? \s )?Truman/correspondra à la fois à « Harry S Truman » et « Harry S. Truman », aussi bien qu'à « Harry Truman », et :
/Harry (?ix: [A-Z] \.? \s )?Truman/trouvera les cinq, en combinant les modificateurs /i et /x dans le cloître. Vous pouvez également soustraire des modificateurs d'un cloître avec un signe moins :
/Harry (?x-i: [A-Z] \.? \s )?Truman/iCeci trouve le nom dans toutes les combinaisons de majuscules et minuscules — mais si l'initiale centrale est fournie, elle doit être en majuscules, car le /i appliqué au motif dans son ensemble est suspendu à l'intérieur du cloître.
En omettant les deux-points et le MOTIF, vous pouvez exporter les réglages des modificateurs à un regroupement extérieur, en le transformant en cloître. C'est-à-dire que vous pouvez sélectivement activer ou désactiver les modificateurs pour le regroupement qui se trouve un niveau à l'extérieur des parenthèses du modificateur, comme ceci :
/(?i)toto/ # Équivalent à /toto/i
/toto((?-i)titi)/i # "titi" doit être en minuscules
/toto((?x-i) titi)/ # Active /x et désactive /i pour "titi"Remarquez que le deuxième et le troisième exemples créent des références arrière. Si ce n'était pas ce que vous vouliez, alors vous auriez dû utiliser respectivement (?-i:titi) et (?x-i: titi).
Activer les modificateurs sur une partie de votre motif est particulièrement utile quand vous voulez que « . » corresponde à des sauts de ligne dans une partie de votre motif, mais pas dans le reste. Activer /s sur tout le motif ne vous sera d'aucune utilité dans ce cas.
5-9. Alternative▲
À l'intérieur d'un motif ou d'un sous-motif, utilisez le métacaractère | pour spécifier un ensemble de possibilités dont chacune peut correspondre. Par exemple :
/Gandalf|Saroumane|Radagaste/correspond à Gandalf, Saroumane ou Radagaste. L'alternative s'étend seulement jusqu'aux parenthèses qui l'entourent les plus proches (qu'elles capturent ou non) :
/perc|l|s|tes/ # Trouve perc, l, s ou tes
/per(c|l|s|t)es/ # Trouve perces, perles, perses ou pertes
/per(?:c|l|s|t)es/ # Trouve perces, perles, perses ou pertesLa deuxième et la troisième formes correspondent aux mêmes chaînes, mais la deuxième capture le caractère changeant, tandis que la troisième ne le fait pas.
Dans toutes les positions, le Moteur essaie de trouver le premier élément de l'alternative, puis le deuxième, et ainsi de suite. La longueur de chaque élément n'a pas d'importance, ce qui signifie que dans ce motif :
/(Sam|Samsagace)/ $1 ne vaudra jamais Samsagace, quelle que soit la chaîne sur laquelle on l'utilise, car Sam sera toujours trouvé en premier. Quand vous avez des recherches qui se superposent comme ceci, mettez les plus longues au début.
Mais l'ordre des éléments de l'alternative n'a d'importance qu'à une position donnée. La boucle externe du Moteur fait une recherche de gauche à droite, c'est pourquoi ce qui suit trouve toujours le premier Sam :
"'Sam je suis,' dit Samsagace" =~ /(Samsagace|Sam)/; # $1 eq "Sam"Mais vous pouvez forcer une recherche de droite à gauche en utilisant les quantificateurs gourmands, comme nous l'avons vu précédemment dans Quantificateurs :
"'Sam je suis,' dit Samsagace" =~ /.*(Samsagace|Sam)/; # $1 eq "Samsagace"Vous pouvez défaire toute recherche gauche à droite (ou de droite à gauche) en incluant n'importe laquelle des assertions de position vues précédemment, comme \G, ^ et $. Ici nous ancrons le motif à la fin de la chaîne :
"'Sam je suis,' dit Samsagace" =~ /(Samsagace|Sam)$/; # $1 eq "Samsagace"Cet exemple met le $ en facteur en dehors de l'alternative (car nous avions déjà une paire de parenthèses en dehors de laquelle le mettre), mais en l'absence de parenthèses vous pouvez également distribuer les assertions sur tout ou partie des éléments de l'alternative, selon comment vous voulez qu'ils trouvent. Ce petit programme affiche les lignes qui commencent par un token __DATA__ ou __END__ :
Mais faites attention avec cela. Souvenez-vous que le premier et le dernier éléments de l'alternative (avant le premier | et après le dernier) ont tendance à avaler les autres de chaque côté, sauf s'il y a des parenthèses autour. Une erreur courante est de demander :
/^chat|chien|vache$/quand vous voulez en fait :
/^(chat|chien|vache)$/La première trouve « chat » au début de la chaîne, ou « chien » n'importe où, ou bien « vache » en fin de chaîne. La deuxième trouve n'importe quelle chaîne consistant simplement de « chat », « chien » ou « vache ». Elle capture également $1, ce qui n'est pas forcément ce que vous voulez. Vous pouvez également écrire :
/^chat$|^chien$|^vache$/Nous vous montrerons une autre solution plus loin.
Un élément de l'alternative peut être vide, auquel cas il réussit toujours.
/com(posite|)/; # Trouve "composite" ou "com"
/com(posite(s|)|)/; # Trouve "composites", "composite" ou "com"Cela revient à utiliser le quantificateur ?, qui trouve 0 ou 1 fois :
/com(posite)?/; # Trouve "composite" ou "com"
/com(posite(s?))?/; # Trouve "composites", "composite" ou "com"
/com(posites?)?/; # Pareil, mais n'utilise pas $2Il y a cependant une différence. Quand vous appliquez le ? à un sous-motif qui fait une capture dans une variable numérotée, cette variable sera indéfinie s'il n'y a pas de chaîne à y mettre. Si vous avez mis l'élément vide dans l'alternative, elle serait toujours fausse, mais ce serait en fait une chaîne vide définie.
5-10. Garder le contrôle▲
Comme le sait tout bon chef d'équipe, cela ne sert à rien d'être toujours sur le dos de vos employés. Dites-leur simplement ce que vous voulez, et laissez-les trouver la meilleure manière de le faire. De même, la meilleure manière de voir une expression régulière, c'est comme une spécification : « Voilà ce que je veux ; trouve-moi une chaîne qui correspond ».
D'un autre côté, les meilleurs chefs d'équipe comprennent ce que leurs employés essayent de faire. C'est également vrai pour les expressions régulières en Perl. Mieux vous comprenez comment Perl s'acquitte de la tâche de trouver un motif particulier, plus vous serez capable d'utiliser les capacités de recherche de motif de Perl en connaissance de cause.
Une des choses les plus importantes à comprendre à propos de la recherche de motif en Perl, c'est quand ne pas l'utiliser.
5-10-a. Laisser Perl faire le boulot▲
Quand certaines personnes apprennent les expressions régulières, elles sont souvent tentées de voir tout problème comme un problème de recherche de motif. Et quand bien même ce serait vrai en général, la recherche de motif est plus que la simple évaluation d'expressions régulières. C'est aussi comme rechercher vos clefs de voiture où vous les avez fait tomber, et pas seulement sous le réverbère, là où vous y voyez le mieux. Dans le monde réel, nous savons tous qu'il est plus efficace de chercher aux bons endroits qu'aux mauvais.
De même, vous devriez utiliser le contrôle de f lux de Perl pour décider quels motifs exécuter et lesquels ignorer. Une expression régulière est plutôt maligne, mais pas plus qu'un cheval. Elle peut être distraite si elle voit trop de choses à la fois. C'est pourquoi il vous faut parfois lui mettre des œillères. Par exemple, souvenez-vous de notre précédent exemple d'alternative :
/Gandalf|Saroumane|Radagaste/Cela marche comme prévu, mais pas aussi bien que possible, car elle cherche chaque nom à chaque position dans la chaîne avant de passer à la suivante. Les lecteurs attentifs du Seigneur des anneaux se souviendront que, des trois magiciens mentionnés ci-dessus, Gandalf est mentionné plus souvent que Saroumane, et que Saroumane est mentionné plus souvent que Radagaste. Il est donc en général plus efficace d'utiliser les opérateurs logiques de Perl pour réaliser l'alternative :
/Gandalf/ || /Saroumane/ || /Radagaste/C'est également une autre manière de passer outre la recherche « orientée à gauche » du Moteur. Il ne recherche Saroumane que si Gandalf est introuvable. Et il ne cherche Radagaste que si Saroumane est également absent.
Non seulement cela change l'ordre de recherche des différents termes, but cela permet également à l'optimiseur d'expressions régulières de mieux fonctionner. Il est en général plus simple d'optimiser la recherche pour une seule chaîne que pour plusieurs à la fois. De même, les recherches ancrées peuvent souvent être optimisées si elles ne sont pas trop compliquées.
Vous n'avez pas à vous limiter à l'opérateur || pour le contrôle de flux. Vous pouvez souvent contrôler les choses au niveau des instructions. Vous devriez toujours penser à vous débarrasser des cas les plus courants en premier. Supposons que vous écriviez une boucle pour traiter un fichier de configuration. La plupart des fichiers de configuration sont composés principalement de commentaires. C'est souvent mieux de supprimer les commentaires et les lignes blanches avant de s'attaquer aux lourds traitements, même si les lourds traitements supprimeraient également les commentaires et lignes blanches en cours de route :
Même si vous n'essayez pas d'être efficace, vous avez souvent besoin d'alterner entre les expressions Perl normales et les expressions régulières, simplement parce que vous voulez faire quelque chose qui n'est pas possible (ou qui est très difficile) à l'intérieur d'une expression régulière, comme afficher quelque chose. Voici un classificateur de nombres bien utile :
warn "contient des non-chiffres" if /\D/;
warn "pas un nombre naturel" unless /^\d+$/; # rejette -3
warn "pas un entier" unless /^-?\d+$/; # rejette +3
warn "pas un entier" unless /^[+-]?\d+$/;
warn "pas un nombre décimal" unless /^-?\d+\.?\d*$/; # rejette .2
warn "pas un nombre décimal" unless /^-?(?:\d+(?:\.\d*)?|\.\d+)$/;
warn "pas un flottant de C"
unless /^([+-]?)(?=\d|\.\d)\d*(\.\d*)?([Ee]([+-]?\d+))?$/;Nous pourrions encore beaucoup allonger cette section, mais ceci est vraiment le sujet de tout le livre. Vous verrez encore beaucoup d'exemples mêlant du code Perl et des recherches de motif au long du livre. En particulier, reportez-vous à la section suivante Motifs programmatiques. (Mais vous pouvez quand même commencer par lire ce qui suit, bien sûr.)
5-10-b. Interpolation de variables▲
L'utilisation des mécanismes de contrôle de flux de Perl pour contrôler les expressions régulières a ses limites. La difficulté principale est qu'il s'agit d'une approche « tout ou rien » ; soit vous faites tourner le motif, soit vous ne le faites pas tourner. Parfois vous savez vaguement ce que vous cherchez, mais vous aimeriez avoir la possibilité de le paramétrer. L'interpolation de variables fournit cette capacité, tout comme le paramétrage des sous-programmes vous permet d'avoir une plus grande influence sur leur comportement que simplement de choisir entre les appeler ou non. (Vous en verrez plus sur les sous-programmes au chapitre suivant.)
Un des intérêts de l'interpolation est de fournir un peu d'abstraction, ainsi qu'un peu de lisibilité. Avec des expressions régulières, il est certes possible d'écrire les choses de façon concise :
if ($num =~ /^[-+]?\d+\.?\d*$/) { ... }Mais ce que vous voulez dire est plus compréhensible ainsi :
$signe = '[-+]?';
$chiffres = '\d+';
$point_decimal = '\.?';
$encore_des_chiffres = '\d*';
$nombre = "$signe$chiffres$point_decimal$encore_des_chiffres";
...
if ($num =~ /^$nombre$/o) { ... }Nous couvrirons un peu plus cette utilisation de l'interpolation dans la section Motifs générés, plus loin dans ce chapitre. Notez juste que nous avons utilisé le modificateur /o pour supprimer la recompilation du motif, car nous ne nous attendons pas à ce que $nombre change de valeur au cours du programme.
Un autre truc sympa est de renverser vos tests et de vous servir de la chaîne variable comme motif vis-à-vis d'un ensemble de chaînes connues :
chomp($reponse = <STDIN>);
if ("SEND" =~ /^\Q$reponse/i) { print "Action : send\n" }
elsif ("STOP" =~ /^\Q$reponse/i) { print "Action : stop\n" }
elsif ("ABORT" =~ /^\Q$reponse/i) { print "Action : abort\n" }
elsif ("LIST" =~ /^\Q$reponse/i) { print "Action : list\n" }
elsif ("EDIT" =~ /^\Q$reponse/i) { print "Action : edit\n" }Ceci permet à l'utilisateur de lancer l'action « send » en tapant S, SE, SEN ou SEND (dans n'importe quel mélange de majuscules et minuscules). Pour faire « stop », il lui faudra au moins taper ST (ou St, sT ou st).
5-10-b-i. Retour de l'antislash▲
Quand vous pensez à l'interpolation entre apostrophes doubles, vous pensez généralement à l'interpolation des variables et des antislashs. Mais comme nous l'avons indiqué précédemment, il y a deux passes pour les expressions régulières, et la passe d'interpolation laisse la plus grande partie du travail d'interprétation des antislashs à l'analyseur d'expressions régulières (dont nous parlerons plus tard). D'ordinaire, vous ne remarquerez pas de différence, car Perl fait bien attention à les masquer. (Une séquence qui est évidemment différente est le métasymbole \b, qui se transforme en assertion de limite — en dehors des classes de caractères, en tout cas. À l'intérieur d'une classe de caractères, où les assertions n'ont aucun sens, il redevient un espace arrière, comme d'habitude.)
Il est en fait assez important que l'analyseur de regex gère les antislashs. Imaginons que vous cherchiez les caractères de tabulation avec un motif sous le modificateur /x :
($col1, $col2) = /(.*?) \t+ (.*?)/x;Si Perl ne laissait pas l'interpolation de \t à l'analyseur de regex, le \t se serait transformé en un blanc que l'analyseur de regex aurait bêtement ignoré à cause du /x. Mais Perl n'est ni si ignoble, ni si piégeant.
Vous pouvez cependant vous piéger tout seul. Imaginons que vous ayez un peu virtualisé le séparateur de colonne, comme ceci :
$sepcol = "\t+"; # (apostrophes doubles)
($col1, $col2) = /(.*?) $sepcol (.*?)/x;Et maintenant vous voilà fait comme un rat, car le \t se transforme en véritable tabulation avant d'atteindre l'analyseur de regex, qui croira que vous avez écrit /(.*?)+(.*?)/ une fois les blancs supprimés. Oups. Pour corriger cela, évitez /x ou bien utilisez des apostrophes simples. Ou mieux, utilisez qr//. (Voir la section suivante.)
Les seules séquences d'échappement entre apostrophes doubles qui sont traitées comme telles sont les six séquences de traduction : \U, \u, \L, \l, \Q et \E. Si jamais vous vous plongez un jour dans le fonctionnement interne du compilateur d'expressions régulières, vous y trouverez du code destiné à gérer les séquences d'échappement comme \t pour la tabulation, \n pour le saut de ligne, et ainsi de suite. Mais vous n'y trouverez pas de code pour ces six séquences de traduction. (Nous les avons listées dans le tableau 5-7 uniquement, car c'est là qu'on s'attend à les trouver.) Si vous vous débrouillez pour les inclure dans le motif sans passer par l'évaluation entre apostrophes doubles, elles ne seront pas reconnues.
Comment ont-elles pu s'y glisser ? Vous pouvez contrecarrer l'interpolation en utilisant des apostrophes simples comme délimiteurs de motifs. Les apostrophes simples suppriment l'interpolation de variables et le traitement des séquences de traduction dans m, qr et s, comme ils le feraient dans une chaîne entre apostrophes simples. Écrire m ne trouvera pas une version en majuscules de ce pauvre frodon. Cependant, comme les antislash « normaux » ne sont pas vraiment traités à ce niveau, m trouvera toujours une vraie tabulation suivie d'un chiffre quelconque.
Une autre manière de contrecarrer l'interpolation est de passer par l'interpolation elle-même. Si vous écrivez :
$var = '\U';
/${var}frodon/;ce pauvre frodon reste en minuscules. Perl ne refera pas la passe d'interpolation pour vous simplement parce que vous avez interpolé quelque chose qui a l'air de vouloir être interpolé. Vous ne pouvez pas plus espérer que cela soit interpolé que vous ne pourriez attendre que cette double interpolation marche :
$hobbit = 'Frodon';
$var = '$hobbit'; # (apostrophes simples)
/$var/; # signifie m'$hobbit', et pas m'Frodon'.Voici un autre exemple qui montre comment les antislashs sont interprétés par l'analyseur de regex et pas par l'interpolation de variables. Imaginons que vous ayez un petit utilitaire simple à la grep :(78)
Si vous appelez ce programme pgrep et l'invoquez comme suit :
% pgrep '\t\d' *.calors vous découvrirez qu'il affiche toutes les lignes de tous vos fichiers source C dans lesquelles un chiffre suit une tabulation. Vous n'avez rien eu à faire de spécial pour que Perl se rende compte que \t était une tabulation. Si les motifs de Perl étaient simplement interpolés en contexte d'apostrophes doubles, vous auriez dû faire quelque chose ; heureusement ils ne le sont pas. Ils sont directement reconnus par l'analyseur de regex.
Le vrai programme grep a une option -i qui rend la recherche insensible à la casse. Vous n'avez pas besoin d'ajouter une telle option à votre programme pgrep ; il peut déjà le faire sans modification. Il suffit de lui passer un motif un peu plus élaboré, avec un modificateur /i inclus :
% pgrep '(?i)anneau' LotR*.podOn cherche maintenant « Anneau », « anneau », « ANNEAU » et ainsi de suite. Vous ne verrez pas beaucoup cette fonctionnalité dans les motifs littéraux, puisque vous pouvez simplement écrire /anneau/i. Mais pour les motifs passés sur la ligne de commande, dans les formulaires web ou inclus dans les fichiers de configuration, cela peut s'avérer primordial.
5-10-b-ii. L'opérateur qr// de citation de regex▲
Les variables qui sont interpolées en motifs le sont nécessairement à l'exécution et non à la compilation. Ceci ralentit l'exécution, car Perl doit vérifier que vous n'avez pas changé le contenu de la variable ; si c'est le cas, il faut alors recompiler l'expression régulière. Comme mentionné dans Opérateurs de recherche de motifs, si vous promettez de ne jamais modifier le motif, vous pouvez utiliser l'option /o pour interpoler et compiler une seule fois :
print if /$pattern/o;Bien que cela fonctionne correctement dans notre programme pgrep, ce n'est pas le cas en général. Imaginez que vous ayez une flopée de motifs et que vous vouliez tous les tester dans une boucle, peut-être comme ceci :
foreach $elem (@donnees) {
foreach $motif (@motifs) {
if ($elem =~ /$motif/) { ... }
}
}Vous ne pourriez pas écrire /$motif/o, car la signification de $motif change à chaque tour de la boucle interne.
Ce problème est résolu par l'opérateur qr/MOTIF/imosx. Cet opérateur cite — et compile — son MOTIF comme une expression régulière. MOTIF est interpolé de la même façon que dans m/MOTIF/. Si ' est utilisé comme délimiteur, aucune interpolation de variable (ni des séquences de traduction) n'est faite. L'opérateur renvoie une valeur Perl qui peut être utilisée à la place de la chaîne littérale équivalente dans la recherche ou la substitution correspondante. Par exemple :
$regex = qr/ma.CHAINE/is;
s/$regex/quelque chose d'autre/;est équivalent à :
s/ma.CHAINE/quelque chose d'autre/is;Pour résoudre notre problème précédent de boucles emboîtées, vous pouvez donc d'abord traiter le motif dans une boucle séparée :
@regexes = ();
foreach $motif (@motifs) {
push @regexes, qr/$motif/;
}Ou bien d'un seul coup en utilisant l'opérateur map de Perl :
@regexes = map { qr/$_/ } @motifs;Puis modifier la boucle pour utiliser ces regex précompilées :
Désormais quand vous faites tourner la recherche, Perl n'est plus obligé de créer une expression régulière compilée à chaque test if, car il se rend compte qu'il en possède déjà une.
Le résultat d'un qr// peut même être interpolé dans un motif plus grand, comme s'il s'agissait d'une simple chaîne :
$regex = qr/$motif/;
$chaine =~ /toto${regex}titi/; # interpolation dans un motif plus grandCette fois Perl recompile le motif, mais vous pourriez chaîner plusieurs opérateurs qr// en un seul.
La raison pour laquelle cela fonctionne est que l'opérateur qr// retourne un objet spécial pour lequel la conversion en chaîne est surchargée comme décrit au chapitre 13, Surcharge. Si vous affichez la valeur de retour, vous verrez la chaîne équivalente :
$re = qr/ma.CHAINE/is;
print $re; # affiche (?si-xm:ma.CHAINE)Les modificateurs /i et /s ont été activés dans le motif, car ils ont été fournis à qr//. De même, /x et /m sont désactivés, car ils n'ont pas été fournis.
À chaque fois que vous interpolez des chaînes de provenance inconnue dans un motif, vous devriez être prêt à traiter les exceptions renvoyées par le compilateur de regex, dans le cas où l'on vous aurait passé une chaîne contenant des bestioles indomptables :
$re = qr/$motif/is; # peut s'échapper et vous mordre
$re = eval { qr/$motif/is } || warn ... # pris dans une cage extérieurePour en savoir plus sur l'opérateur eval, voir le chapitre 29.
5-10-c. Le compilateur de regex▲
Après que la passe d'interpolation de variable est passée sur la chaîne, l'analyseur de regex a enfin une occasion d'essayer de comprendre votre expression régulière. À ce niveau-là, il n'y a plus grand-chose qui peut mal se passer, sinon embrouiller les parenthèses ou utiliser une séquence de métacaractères qui n'a aucun sens. L'analyseur fait une analyse récursive descendante de votre expression régulière et si elle est correcte, la met sous une forme interprétable par le Moteur (voir la section suivante). La plupart des choses intéressantes qui se passent dans l'analyseur sont liées à l'optimisation de votre expression régulière afin qu'elle soit exécutée le plus rapidement possible. Nous ne chercherons pas à expliquer cette partie-là. C'est un secret de fabrication. (Ne croyez pas les rumeurs qui disent que regarder le code lié aux expressions régulières vous rendra fou ; elles sont très exagérées. Espérons-le.)
Mais vous pourriez avoir envie de savoir ce que l'analyseur a vraiment pensé de votre expression régulière. Si vous lui demandez poliment, il vous le dira. En utilisant use re "debug";, vous pouvez examiner le traitement de votre motif par l'analyseur. (Vous pouvez également obtenir la même information en utilisant l'option de ligne de commande -Dr. Celle-ci est disponible si votre Perl a été compilé avec l'option -DDEBUGGING à l'installation.)
#!/usr/bin/perl
use re "debug";
"Smeagol" =~ /^Sm(.*)g[aeiou]l$/;La sortie suit. Vous pouvez voir qu'avant l'exécution Perl compile la regex et donne une signification aux composantes du motif : BOL pour le début de ligne (^ ou Beginning Of Line), REG_ANY pour le point, et ainsi de suite :
Compiling REx `^Sm(.*)g[aeiou]l$'
size 24 first at 2
rarest char l at 0
rarest char S at 0
1: BOL(2)
2: EXACT <Sm>(4)
4: OPEN1(6)
6: STAR(8)
7: REG_ANY(0)
8: CLOSE1(10)
10: EXACT <g>(12)
12: ANYOF[aeiou](21)
21: EXACT <l>(23)
23: EOL(24)
24: END(0)
anchored `Sm' at 0 floating `l'$ at 4..2147483647 (checking anchored)
anchored(BOL) minlen 5Certaines de ces lignes résument les conclusions de l'optimiseur de regex. Il sait que la chaîne doit commencer par « Sm » et qu'il n'y a donc aucune raison de faire l'habituelle recherche de gauche à droite. Il sait que la chaîne doit se terminer par un « l » et peut donc rejeter directement celles qui ne le sont pas. Il sait que la chaîne doit faire au moins cinq caractères de long, et peut donc ignorer toute chaîne plus courte que cela sans autre forme de procès. Il sait également quels sont les caractères les moins courants dans chaque sous-chaîne constante, ce qui peut aider avec les chaînes « étudiées » par study. (Voir study au chapitre 29.)
Ensuite il liste la façon dont le motif est exécuté :
Guessing start of match, REx `^Sm(.*)g[aeiou]l$' against `Smeagol'...
Guessed: match at offset 0
Matching REx `^Sm(.*)g[aeiou]l$' against `Smeagol'
Setting an EVAL scope, savestack=3
0 <> <Smeagol> | 1: BOL
0 <> <Smeagol> | 2: EXACT <Sm>
2 <Sm> <eagol> | 4: OPEN1
2 <Sm> <eagol> | 6: STAR
REG_ANY can match 5 times out of 32767...
Setting an EVAL scope, savestack=3
7 <Smeagol> <> | 8: CLOSE1
7 <Smeagol> <> | 10: EXACT <g>
failed...
6 <Smeago> <l> | 8: CLOSE1
6 <Smeago> <l> | 10: EXACT <g>
failed...
5 <Smeag> <ol> | 8: CLOSE1
5 <Smeag> <ol> | 10: EXACT <g>
failed...
4 <Smea> <gol> | 8: CLOSE1
4 <Smea> <gol> | 10: EXACT <g>
5 <Smeag> <ol> | 12: ANYOF[aeiou]
6 <Smeago> <l> | 21: EXACT <l>
7 <Smeagol> <> | 23: EOL
7 <Smeagol> <> | 24: END
Match successful!
Freeing REx: `^Sm(.*)g[aeiou]l$'Si vous suivez le blanc au milieu de Smeagol, vous pouvez voir le Moteur aller au plus loin pour que le .* soit aussi gourmand que possible, puis revient en arrière jusqu'à trouver une façon pour le reste du motif de réussir. Mais c'est justement le sujet de la section suivante.
5-10-d. « Le petit Moteur qui /(ne )?pouvait( pas)?/ »▲
Et maintenant nous aimerions vous raconter l'histoire du petit Moteur de Regex qui dit « Je crois que j'peux. Je crois que j'peux. Je crois que j'peux. »(79)
Dans cette section, nous allons présenter les règles que le Moteur utilise pour effectuer les recherches de correspondance de motifs. Le Moteur est extrêmement persévérant et travailleur. Il est tout à fait capable de continuer à travailler alors que vous croyiez qu'il aurait déjà abandonné. Le Moteur n'abandonne pas tant qu'il n'est pas absolument sûr qu'il n'y a aucun moyen pour lui de trouver une correspondance entre le motif et la chaîne. Les règles ci-dessous expliquent comment le Moteur « croit qu'il peut » aussi longtemps que possible, jusqu'à ce qu'il sache qu'il peut ou ne peut pas. Le problème de notre Moteur est qu'il ne s'agit pas simplement de faire monter un train en haut d'une colline. Il s'agit de parcourir un espace (potentiellement) très compliqué de possibilités, en se souvenant de là où il est passé ou pas.
Le Moteur utilise un automate fini non déterministe (NFA, nondeterministic finite-state automaton) pour trouver une correspondance. Cela signifie simplement qu'il garde une trace de ce qu'il a et n'a pas essayé, et quand cela ne donne aucun résultat, il revient en arrière et essaye autre chose. C'est le retour arrière, ou backtracking. Le Moteur Perl est capable d'explorer un million de possibilités pour une partie de la recherche, pour les abandonner et aller à la partie de recherche suivante, puis recommencer à explorer pour celle-ci le même million de possibilités. Le Moteur n'est pas très intelligent ; il est juste persévérant et exhaustif. Il est cependant possible d'écrire des motifs efficaces qui n'occasionnent pas trop de retours arrière inutiles.
Quand on vous dit « Les regex choisissent la correspondance la plus à gauche la plus longue », cela signifie que Perl préfère la plus à gauche à la plus longue. Mais le Moteur ne sait pas qu'il privilégie quelque chose à ce niveau. Le choix global résulte de nombreux choix particuliers et indépendants. Voici ces choix :(80)
Règle 1
- Le Moteur essaye de trouver une correspondance aussi loin que possible à gauche de la chaîne, afin que la totalité de l'expression régulière corresponde selon la règle 2.
- Le Moteur démarre juste avant le premier caractère et essaye de faire correspondre la totalité de l'expression régulière depuis ce point. L'expression régulière correspond si et seulement si le moteur atteint la fin de l'expression sans s'être arrêté à la fin de la chaîne. S'il a trouvé, il s'arrête immédiatement — il ne recherche pas s'il existe une « meilleure » solution, même si le motif peut correspondre à la recherche de plusieurs autres manières.
- S'il n'arrive pas à trouver une correspondance au motif à la première position de la chaîne, il reconnaît temporairement sa défaite et va à la position suivante de la chaîne, entre le premier et le deuxième caractères, puis réessaie à nouveau toutes les possibilités. En cas de succès, il s'arrête. Sinon, il continue plus avant dans la chaîne. La recherche de correspondance dans son ensemble ne sera considérée comme un échec qu'après avoir essayé de faire correspondre toute l'expression régulière à toutes les positions de la chaîne, y compris après le dernier caractère.
- Une chaîne de n caractères fournit donc en fait n
+1positions où correspondre. C'est parce que les début et fin de correspondance se trouvent entre les caractères de la chaîne. Cette règle surprend parfois les gens quand ils écrivent un motif tel que/x*/qui recherche zéro ou plus «x». Si vous essayez ce motif sur une chaîne comme « dix », il ne trouvera pas le «x». Il trouvera en fait la chaîne nulle juste avant le « d » et n'ira jamais chercher plus loin. Si vous voulez trouver un ou plusieursx, vous devriez plutôt utiliser le motif/x+/. Voir les quantificateurs à la règle 5. Un corollaire à cette règle est que toute expression régulière qui peut trouver la chaîne nulle est assurée de correspondre à la position la plus à gauche de la chaîne (en l'absence de toute assertion de largeur vide qui vérifie le contraire).
Règle 2
- Quand le Moteur rencontre une alternative (aux éléments séparés par des
|), que ce soit au niveau global ou au niveau du regroupement courant, il les essaie successivement de gauche à droite, en s'arrêtant à la première correspondance qui assure le succès du motif dans son ensemble. - Une alternative correspond à une chaîne si un élément quelconque de l'alternative correspond au sens de la règle 3. Si aucun des éléments de l'alternative ne correspond, il retourne à la règle qui a invoqué cette règle, qui est en général la règle 1, mais pourrait très bien être la règle 4 ou 6 dans un regroupement. Cette règle cherchera alors une nouvelle position où appliquer la règle 2.
- S'il n'existe qu'un seul terme d'alternative, alors celui-ci est vérifié ou non, et la règle 2 est toujours valable. (Il n'existe pas de zéro alternative, car une chaîne vide correspond toujours à quelque chose de longueur nulle.)
Règle 3
- Un terme donné d'une alternative est vérifié si chacun de ses éléments est lui aussi vérifié selon les règles 4 et 5 (de façon à ce que toute l'expression régulière soit satisfaite).
- Un élément peut consister en une assertion, qui est régie par la règle 4, ou en un atome quantifié, qui est régi par la règle 5. Les éléments à choix multiples sont hiérarchisés de la gauche vers la droite. Si les éléments ne peuvent être vérifiés, le Moteur rebrousse chemin jusqu'au choix suivant selon la règle 2.
- Les éléments qui doivent être vérifiés séquentiellement ne sont pas séparés dans l'expression régulière par quoi que ce soit de syntaxique ; ils sont simplement juxtaposés dans l'ordre dans lequel ils doivent être vérifiés. Lorsque vous cherchez
/^toto/, vous demandez en fait la détection de cinq éléments les uns à la suite des autres. Le premier est une assertion de longueur nulle et les quatre autres des lettres ordinaires qui se correspondent à elles-mêmes, l'une après l'autre, selon la règle 5. -
L'ordre hiérarchique de gauche à droite implique que dans un motif tel que :
Sélectionnez/x*y*/ x*choisit une manière de correspondre, puis y*essaie toutes ses possibilités. Si cela échoue,x*choisit alors sa deuxième possibilité, et fait réessayer toutes ses possibilités à y*. Et ainsi de suite. Les éléments à droite « varient plus vite », pour emprunter une expression au vocabulaire des tableaux multidimensionnels.
Règle 4
- Si une assertion ne correspond pas à la position courante, le Moteur revient en arrière à la règle 3 et réessaie les éléments plus haut dans la hiérarchie avec des choix différents.
- Certaines assertions sont plus fantaisistes que d'autres. Perl connaît beaucoup d'extensions de regex, dont certaines sont des assertions de largeur nulle. Par exemple, l'assertion positive de prévision (
?=...) et l'assertion négative de prévision (?!...) ne correspondent en réalité à aucun caractère, mais s'assurent plutôt que l'expression régulière représentée par ... correspondrait (ou non), si nous l'avions essayée.(81)
Règle 5
- Un atome quantifié n'est vérifié que si et seulement si l'atome lui-même est vérifié un nombre de fois autorisé par le quantificateur. (L'atome est vérifié selon la règle 6). Des quantificateurs différents impliquent un nombre différent de vérifications, et la plupart d'entre eux permettent un nombre variable de vérifications. Les correspondances multiples doivent être faites à la suite, c'est-à-dire qu'elles sont adjacentes dans la chaîne. Un atome non quantifié est supposé avoir un quantificateur ne demandant qu'une seule vérification (c'est-à-dire que
/x/est identique à/x{1}/). Si aucune correspondance n'est trouvée à la position courante pour aucune des quantités autorisées pour l'atome en question, le Moteur revient à la règle 3 et réessaye des éléments d'ordre hiérarchique plus élevé avec des valeurs différentes. - Les quantificateurs sont
*,+,?,*?,+?,??et les différentes formes d'accolades. Si vous utilisez la forme{COMPTE}, alors il n'y a pas le choix et l'atome doit correspondre le nombre exact de fois précisé, ou pas du tout. Sinon, l'atome peut être recherché parmi un ensemble de possibilités de répétition, et le Moteur garde une trace de tous les choix pour revenir en arrière si besoin est. Mais la question est alors de savoir quel choix faire en premier. On pourrait commencer par le nombre maximal et le réduire au fur et à mesure, ou démarrer avec le nombre minimal et l'augmenter petit à petit. - Les quantificateurs traditionnels (sans point d'interrogation à la suite) spécifient une recherche gourmande ; c'est-à-dire qu'ils essaient de vérifier autant de caractères que possible. Pour trouver la correspondance maximale, le Moteur doit faire un petit peu attention. Les mauvais choix coûtent potentiellement cher, c'est pourquoi le Moteur ne compte pas vraiment à partir de la valeur maximale, qui pourrait après tout être Très Grande et provoquer des millions de mauvais choix. Le Moteur fait en réalité quelque chose d'un petit peu plus malin : il commence par compter de façon croissante combien d'atomes correspondants (à la suite) sont effectivement présents dans la chaîne, puis utilise ce maximum réel comme premier essai. (Il se souvient aussi des choix les plus courts, au cas où le plus long ne marcherait pas.) Il essaie (enfin) de vérifier le reste du motif, en supposant que le choix le plus long est le bon. Si le choix le plus long ne produit de correspondance pour le reste du motif, il revient en arrière et essaie le plus long suivant.
- Si vous écrivez
/.*toto/par exemple, il essayera de trouver le nombre maximum de caractères « quelconques » (représentés par le point) jusqu'à la fin de la ligne avant même de commencer à chercher « toto » ; puis quand le « toto » ne correspond pas à cet endroit (et il ne peut pas, puisqu'il n'y a pas assez de place en fin de chaîne pour le trouver), le Moteur va reculer d'un caractère à la fois jusqu'à trouver un « toto ». S'il y a plus d'un « toto » sur la ligne, il s'arrêtera au dernier, puisque ce sera en fait le premier qu'il rencontre au cours de sa remontée. Quand le motif complet réussit en utilisant une longueur particulière de .*, le Moteur sait qu'il peut abandonner les autres choix plus courts pour .*(ceux qu'il aurait utilisés si le « toto » en cours n'avait finalement pas fonctionné). - En mettant un point d'interrogation après n'importe quel quantificateur gourmand, vous le transformez en quantificateur frugal qui choisit la plus petite quantité pour son premier essai. Donc, si vous écrivez
/.*?toto/, le .*?essayera d'abord de correspondre à 0 caractères, puis 1, puis 2, et ainsi de suite jusqu'à trouver le « toto ». Au lieu de rebrousser chemin en arrière, il rebrousse chemin en avant, pour ainsi dire. Et finit par trouver le premier « toto » de la ligne au lieu du dernier.
Règle 6
- Chaque atome correspond selon son type. Si l'atome n'est pas vérifié (ou l'est, mais que sa vérification ne permet pas de correspondance pour le reste du motif), le Moteur revient en arrière à la règle 5 et essaie le choix suivant possible en quantité pour cet atome.
-
Les atomes correspondent selon les types suivants :
- Une expression régulière entre parenthèses, (...), trouve tout ce que l'expression régulière représentée par ... trouve selon la règle 2. Les parenthèses servent donc d'opérateur de regroupement pour la quantification. Les parenthèses simples ont également pour effet de capturer la sous-chaîne trouvée pour une utilisation ultérieure comme référence arrière (ou backreference en anglais). Cet effet de bord peut être supprimé en utilisant plutôt (
?:...), qui n'a que les propriétés de regroupement ; il ne stocke rien dans$1,$2et autres. Il existe d'autres formes d'atomes (et d'assertions) entre parenthèses — voir la suite de ce chapitre. - Un point correspond à tout caractère, sauf éventuellement le saut de ligne.
- Une liste de caractères entre crochets (une classe de caractères) correspond à n'importe lequel des caractères spécifiés dans la liste.
- Une lettre précédée d'un antislash correspond soit à un caractère particulier, soit à un caractère d'un ensemble particulier, comme indiqué dans le tableau 5-7.
- Tout autre caractère précédé d'un antislash correspond à ce caractère lui-même.
- Tout caractère non mentionné ci-dessus se correspond à lui-même.
- Une expression régulière entre parenthèses, (...), trouve tout ce que l'expression régulière représentée par ... trouve selon la règle 2. Les parenthèses servent donc d'opérateur de regroupement pour la quantification. Les parenthèses simples ont également pour effet de capturer la sous-chaîne trouvée pour une utilisation ultérieure comme référence arrière (ou backreference en anglais). Cet effet de bord peut être supprimé en utilisant plutôt (
Tout cela peut sembler plutôt compliqué, mais l'avantage est que pour chaque liste de choix donnée par un quantificateur ou une alternative, le Moteur a un bouton à tourner. Il tournera tous ces boutons jusqu'à ce que tout le motif corresponde. Les règles ne font qu'indiquer dans quel ordre le Moteur peut tourner ces boutons. Dire que le Moteur préfère la correspondance la plus longue à gauche signifie simplement que le bouton qu'il tourne le plus lentement est celui correspondant à la position de départ. Revenir en arrière consiste simplement à tourner dans l'autre sens le bouton tourné à l'instant de façon à essayer un autre bouton plus haut dans l'ordre hiérarchique, c'est-à-dire un qui varie plus lentement.
Voici un exemple plus concret sous la forme d'un programme qui détecte quand deux mots consécutifs partagent un suffixe et un préfixe communs :
$a = 'conflit';
$b = 'litige';
if ("$a $b" =~ /^(\w+)(\w+) \2(\w+)$/) {
print "$2 superposé dans $1-$2-$3\n";
}Ceci affiche :
lit superposé dans conf-lit-igeVous pourriez croire que $1 capture d'abord l'intégralité de « chienlit » par gourmandise. C'est exactement ce qu'il fait — d'abord. Mais une fois rendu là, il n'y a plus de caractères à mettre dans $2, qui a besoin de recevoir des caractères à cause du quantificateur +. Le Moteur bat donc en retraite et $1 donne à contrecœur un caractère à $2. Cette fois l'espace est trouvé correctement, mais quand il voit le \2, qui représente un simple « t ». Le caractère suivant dans la chaîne n'est pas un « t », mais un « l ». Ceci fait donc revenir le Moteur en arrière et réessayer plusieurs fois, pour finalement forcer $1 à laisser le lit à $2.
En fait, cela ne marchera pas forcément bien si la superposition elle-même est un doublon, comme pour les mots « rococo » et « cocon ». L'algorithme ci-dessus aurait simplement décidé que la chaîne en superposition, $2, devait être « co » plutôt que « coco ». Mais nous ne voulons pas de « rocococon » ; nous voulons plutôt un « rococon ». Nous voici dans un cas où il est possible d'être plus malin que le Moteur. L'ajout d'un quantificateur minimal à la partie correspondant à $1 donne le motif bien meilleur /^(\w+?)(\w+) \2(\w+)$/, qui fait exactement ce que nous voulons.
Pour une discussion plus détaillée des avantages et inconvénients des différentes sortes de moteurs d'expressions rationnelles, reportez-vous au livre de Jeffrey Friedl, Maîtrise des expressions régulières (ou en version originale Mastering Regular Expressions). Le Moteur d'expressions régulières de Perl fonctionne très bien pour tous les problèmes quotidiens que vous voulez résoudre avec Perl, mais tout aussi correctement pour ce genre de problème pas si quotidien, pourvu que vous soyez un peu compréhensif.
5-11. Motifs étendus▲
5-11-a. Assertions périphériques▲
Parfois vous voulez juste jeter un œil. Voici quatre extensions de regex qui vous aident justement à faire cela. Nous les appelons périphériques (en anglais lookaround), car elles vous permettent de jeter un œil alentour de façon hypothétique, sans correspondre effectivement à des caractères. Ces assertions testent le fait qu'un motif correspondrait (ou non) dans le cas où nous l'essayerions. Le Moteur fait cela en essayant effectivement de faire correspondre le motif puis en prétendant par la suite qu'il n'y a pas eu de correspondance de faite (même si c'est le cas).
Quand le Moteur regarde en avant par rapport à sa position actuelle dans la chaîne, nous parlons d'assertion de prévision(82) (lookahead). S'il regarde en arrière, nous parlons d'assertion de rétrovision. Les motifs de prévision peuvent être n'importe quelle expression rationnelle, tandis que les motifs de rétrovision ne peuvent qu'être de longueur fixe, car ils doivent savoir d'où partir pour leur correspondance hypothétique.
Alors que ces quatre extensions sont toutes de largeur nulle, et ne consomment donc pas de caractères (du moins pas officiellement), vous pouvez en fait capturer des sous-chaînes à l'intérieur si vous fournissez un niveau supplémentaire de parenthèses de capture.
(?=MOTIF) (positive de prévision)
- Quand le Moteur rencontre (
?=MOTIF), il regarde en avant dans la chaîne pour s'assurer que MOTIF se produit. Pour mémoire, dans notre précédent suppresseur de doublons, nous avons dû écrire une boucle, car notre motif consommait trop de texte à chaque tour :
$_ = "Paris AU AU AU AU printemps."
# supprime les doublons (et les triplons (et les quadruplons...))
1 while s/\b(\w+) \1\b/$1/gi;- À chaque fois que vous entendez « consomme trop », vous devriez immédiatement penser « assertion de pré-vision ». (Enfin, presque toujours.) En regardant à l'avance au lieu de directement avaler le deuxième mot, vous pouvez écrire un suppresseur de doublons qui fonctionne en une passe, comme ceci :
s/ \b(\w+) \s (?= \1\b ) //gxi;- Évidemment, il y a encore un problème, puisque cela va malmener des phrases parfaitement valides comme « J'ai une BELLE BELLE-mère ».
(?!MOTIF) (négative de prévision)
- Quand le Moteur rencontre (
?!MOTIF), il regarde en avant dans la chaîne pour s'assurer que MOTIF n'apparaît pas. Pour corriger notre exemple précédent, nous pouvons ajouter une assertion négative de prévision après l'assertion positive pour éliminer le cas des mots composés :
s/ \b(\w+) \s (?= \1\b (?! -\w))//xgi;- Ce \w final est nécessaire pour éviter de confondre un mot composé avec mot suivi d'un tiret. Nous pouvons même aller plus loin, puisque plus tôt dans ce chapitre nous nous sommes intentionnellement servis de l'expression « nous nous sommes », et que nous aimerions que notre programme ne « corrige » pas cela pour nous. Nous pouvons donc ajouter une alternative à l'assertion négative de pré-vision de manière à ne pas corriger cela (et montrer ainsi que n'importe quel type de parenthèses peut servir à regrouper des alternatives) :
s/ \b(\w+) \s (?= \1\b (?! -\w | \s sommes))//gix;- Nous nous sommes maintenant assurés que cette formulation spécifique n'aura pas de problème. Hélas le poème Mes petites amoureuses de Rimbaud est toujours cassé(83). Aussi ajoutons-nous une nouvelle exception :
s/ \b(\w+) \s (?= \1\b (?! -\w | \s sommes | \s aimions))//igx;- Voilà qui commence à s'emballer. Faisons plutôt une Liste Officielle d'Exceptions, en utilisant un mignon petit truc d'interpolation avec la variable
$"pour séparer les éléments de l'alternative avec le caractère|:
@nousnous = qw(sommes aimions);
local $" = '|';
s/ \b(\w+) \s (?= \1\b (?! -\w | \s (?: @nousnous )))//xig;(?<=PATTERN) (positive de rétrovision)
- When the Engine encounters (
?<=PATTERN), it looks backward in the string to ensure that PATTERN already occurred. Notre exemple a toujours un problème. Bien que l'on permette à Rimbaud de dire « Nous nous aimions », cela autorise également « La totalité des des sommes seront converties en Euros ». Nous pouvons ajouter une assertion positive de rétro-vision en tête de notre liste d'exceptions pour nous assurer que nous n'appliquons nos exceptions@nousnousqu'à un vrai « nous nous ».
s/ \b(\w+) \s (?= \1\b (?! -\w | (?<= nous) \s (?: @nousnous )))//ixg;- Oui, tout cela devient bien compliqué, mais rappelons que cette section s'appelle Motifs étendus. Si vous avez besoin de compliquer encore le motif après ce que nous lui avons fait subir, l'utilisation judicieuse des commentaires et de
qr//devrait vous aider à ne pas devenir fou.
(?<!MOTIF) (négative de rétrovision)
- Quand le Moteur rencontre (
?<!MOTIF), il regarde en arrière dans la chaîne pour s'assurer que MOTIF n'a pas été trouvé. Essayons avec un exemple simple cette fois-ci. Pourquoi pas une règle d'orthographe facile ? Si vous ne savez plus si un mot se termine en « euil » ou en « ueil », et que vous avez plutôt la manie d'écrire « ueil » (parce que vous êtes né à Rueil, par exemple). L'expression régulière suivante peut remettre les choses en ordre :
s/(?<!c|g)ueil/euil/g- Ne pas savoir écrire « fauteuil » ou « cerfeuil » n'est pas un écueil et ne doit pas blesser votre orgueil.
5-11-b. Sous-motifs sans retour arrière▲
Comme nous l'avons décrit dans « Le petit Moteur qui /(ne )?pouvait( pas)?/ », le Moteur fait souvent machine arrière alors qu'il progresse le long d'un motif. Vous pouvez empêcher le Moteur de faire demi-tour au milieu d'une série de possibilités en créant un sous-motif sans retour arrière. Un sous-motif sans retour arrière se présente comme (?>MOTIF), et fonctionne exactement comme un simple (?:MOTIF), sauf qu'une fois que MOTIF a trouvé une correspondance, il supprime toute possibilité de retour arrière sur tous les quantificateurs ou alternatives à l'intérieur du sous-motif. (C'est pourquoi il est inutile d'utiliser cela sur un MOTIF qui ne contient pas de quantificateurs ou d'alternatives.) La seule manière de le faire changer d'avis est de rebrousser chemin jusqu'à quelque chose avant ce sous-motif et de réentrer dans le sous-motif par la gauche.
C'est comme rendre visite à un concessionnaire automobile. Après un certain temps de discussion sur le prix, vous finissez par donner un ultimatum : « Voici ma meilleure offre : c'est à prendre ou à laisser. ». S'ils ne la prennent pas, vous ne recommencez pas à marchander. Vous opérez un retour arrière vers la porte. Vous pouvez ensuite aller voir un autre concessionnaire et recommencer à marchander. Vous pouvez recommencer à marchander, mais seulement parce que vous êtes réentré dans le sous-motif sans retour arrière dans un contexte différent.
Pour les adorateurs de Prolog ou SNOBOL, vous pouvez voir cela comme un opérateur cut ou fence à portée limitée.
Voyons comment dans "aaab" =~ /(?:a*)ab/, le a* commence par trouver trois a, puis en laisse un car le dernier a est utilisé plus loin. Le sous-motif sacrifie une partie de son butin pour permettre à toute la correspondance de réussir. (Ce qui revient à laisser le marchand de voitures obtenir un peu plus de votre argent par peur de ne pas pouvoir conclure l'affaire.) En revanche, le sous-motif dans "aaab" = ~ /(?>a*)ab/ n'abandonnera rien de ce qu'il a pu trouver, même si cette attitude fait échouer la correspondance tout entière.
Bien que (?>MOTIF) soit utile pour modifier le comportement d'un motif, il est souvent utilisé pour accélérer l'échec de certaines recherches dont vous savez qu'elles vont échouer (à moins qu'elles ne réussissent tout à fait). Le Moteur peut prendre un temps extraordinairement long pour échouer, en particulier avec des quantificateurs emboîtés. Le motif suivant réussira de façon quasi instantanée :
$_ = "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaab";
/a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*[b]/;Mais ce n'est pas le succès qui est un problème. C'est l'échec qui en est un. Si vous retirez ce « b » final de la chaîne, le motif va probablement tourner pendant des années et des années avant d'échouer. Pendant des millénaires et des millénaires. En réalité des milliards et des milliards d'années.(84) Vous pouvez constater en examinant le motif qu'il ne peut réussir s'il n'y a pas de « b » à la fin de la chaîne ; mais l'optimiseur n'est pas assez malin (au moment où nous écrivons ces lignes) pour se rendre compte que /[b]/ est équivalent à /b/. Mais si vous lui donnez un indice, vous pouvez le faire échouer rapidement tout en le laissant réussir là où il peut :
/(?>a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*a*)[b]/;Voici un exemple plus réaliste (espérons). Imaginez un programme qui est supposé lire paragraphe par paragraphe et n'afficher que les lignes qui se continuent, les lignes de continuation étant spécifiées par un antislash final. Voici un exemple tiré du Makefile de Perl qui utilise cette convention :
# Files to be built with variable substitution before miniperl
# is available.
sh = Makefile.SH cflags.SH config_h.SH makeaperl.SH makedepend.SH \
makedir.SH myconfig.SH writemain.SHVous pourriez écrire votre programme de cette façon :
#!/usr/bin/perl -00p
while ( /( (.+) ( (?<=\\) \n .* )+ ) /gx) {
print "J'ai $.: $1\n\n";
}Ça marche, mais c'est vraiment très lent. C'est parce que le Moteur fait machine arrière un caractère à la fois depuis la fin de la ligne, en diminuant ce qui se trouve dans $1. C'est sans intérêt. L'écrire sans les captures surnuméraires n'améliore pas sensiblement les choses. Utiliser :
(.+(?:(?<=\\)\n.*)+)pour un motif est un peu plus rapide, mais pas tellement. C'est dans ce cas qu'un motif sans retour arrière est très utile. Le motif :
((?>.+)(?:(?<=\\)\n.*)+)fait la même chose, mais est plus rapide d'un ordre de grandeur. C'est parce qu'il ne perd pas son temps à chercher quelque chose qui n'est pas là.
Il n'est pas possible d'obtenir avec (?>...) un succès que vous n'auriez obtenu avec (?:...) ou même un simple (...). Mais si votre recherche doit échouer, autant échouer rapidement et passer à la suite.
5-11-c. Motifs programmatiques▲
La plupart des programmes Perl sont écrits dans un style impératif (aussi appelé procédural). C'est un peu comme une suite d'ordres listés dans un facile à suivre : « Préchauffer le four, mélanger, glacer, cuire, laisser refroidir, servir aux martiens. ». Parfois vous rajoutez à ce mélange une bonne cuillerée de programmation fonctionnelle (« Utilisez un peu plus de glaçage que vous ne pensez en avoir besoin, même après avoir tenu compte de ce conseil, récursivement ») ou vous le saupoudrez de quelques techniques orientées objet (« Merci de laisser les objets anchois de côté »). Souvent c'est un mélange de tout cela à la fois.
Mais le Moteur d'expressions régulières a une approche complètement différente de la résolution de problèmes, une approche plus déclarative. Vous décrivez vos objectifs dans le langage des expressions régulières, et le Moteur implémente la logique nécessaire pour atteindre vos objectifs. Les langages de programmation logique (comme Prolog) ont une moins grande visibilité que les trois autres styles, mais ils sont plus répandus que vous ne pourriez le croire. Perl ne pourrait même pas être construit sans make ou yacc ; tous deux pouvant être considérés, sinon comme des langages purement déclaratifs, au moins comme des hybrides qui mélangent la programmation impérative et la programmation logique.
Vous pouvez aussi faire ce genre de choses en Perl, en mélangeant ensemble des déclarations d'objectifs avec du code impératif, de façon encore plus fluide que nous ne l'avons fait jusqu'à présent afin de profiter des forces de chacun. Vous pouvez construire programmatiquement la chaîne que vous allez finir par proposer au Moteur de regex, c'est-à-dire d'une certaine manière créer un programme qui écrit un nouveau programme à la volée.
Vous pouvez également fournir des expressions Perl normales comme remplacement dans s/// à l'aide du modificateur /e. Ceci vous permet de générer dynamiquement la chaîne de remplacement en exécutant un morceau de code à chaque fois que le motif correspond.
D'une manière encore plus élaborée, vous pouvez inclure des bouts de code partout où vous le voulez au beau milieu d'un motif en utilisant l'extension (?{CODE}). Celui-ci sera exécuté à chaque fois que le Moteur rencontrera ce code, au fur et à mesure de ses pérégrinations, dans la danse compliquée des retours en arrière.
Enfin, vous pouvez utiliser s///ee ou (??{CODE}) pour ajouter un nouveau niveau d'indirection : le résultat de l'exécution de ces bouts de code sera lui-même réévalué pour être réutilisé, créant des morceaux de programme et de motif au vol, juste à temps.
5-11-d. Motifs générés▲
Il a été dit(85) que les programmes qui écrivent des programmes sont les programmes les plus heureux au monde. Dans le livre de Jeffrey Friedl, Maîtrise des expressions régulières (Mastering Regular Expressions), le tour de force final montre comment écrire un programme qui produit une expression régulière capable de déterminer si une chaîne est conforme au standard défini par le RFC 822 ; c'est-à-dire s'il contient un en-tête de mail conforme au standard. Le motif produit fait plusieurs milliers de caractères de long, et est aussi facile à lire qu'un dump mémoire binaire après un crash. Mais le détecteur de motif de Perl s'en moque ; il compile juste le motif sans difficulté et, ce qui est encore plus intéressant, l'exécute très rapidement — bien plus rapidement, en fait, que beaucoup de motifs beaucoup plus courts qui ont des besoins de retour arrière plus compliqués.
C'est un exemple très compliqué. Nous vous avons précédemment montré un exemple très simple de la même technique quand nous avons fabriqué un motif $nombre à partir de ses éléments constitutifs (voir la section Interpolation de variables). Mais pour vous montrer la puissance de l'approche programmatique pour la production d'un motif, nous allons nous pencher sur un problème de complexité moyenne.
Supposons que vous vouliez trouver tous les exemples de mots avec une certaine suite de voyelles et de consonnes ; par exemple « audio » et « aeree » suivent tous deux un motif VVCVV. Même si décrire ce qui compte comme voyelle ou consonne est simple(86) , vous n'aurez pas vraiment envie de l'écrire plus d'une fois. Même pour un cas simple comme notre VVCVV, vous devrez écrire un motif comme :
^[aeiouy][aeiouy][bcdfghjklmnpqrstvwxzy][aeiouy][aeiouy]$Un programme plus général accepterait une chaîne comme « VVCVV » pour générer (programmatiquement) le motif pour vous. Pour être même encore plus flexible, il pourrait même accepter un mot comme « audio », l'utiliser comme modèle pour en déduire « VVCVV » et de là construire le long motif ci-dessus. Cela a l'air compliqué, mais ne l'est vraiment pas, car nous allons laisser le programme générer le motif pour nous. Voici un simple programme cvmap qui fait tout cela :
#!/usr/bin/perl
$voyelles = 'aeiouy';
$consonnes = 'bcdfghjklmnpqrstvwxzy';
%assoc = (C => $consonnes,
V => $voyelles); # initialise la liste pour V et C
for $classe ($voyelles, $consonnes) { # pour chaque type
for (split //, $class) { # récupère chaque lettre de chaque type
$assoc{$_} .= $class; # et réassocie chaque lettre à chaque type
}
}
for $char (split //, shift) { # pour chaque lettre du modèle
$motif .= "[$assoc{$char}]"; # ajoute la classe de caractères
appropriée
}
$re = qr/^${motif}$/i; # compile le motif
print "REGEX : $re\n"; # affiche une vérification
@ARGV = ('/usr/dict/words') # prend un dictionnaire par défaut
if -t && !@ARGV;
while (<>) { # et maintenant parcourt l'entrée
print if /$re/; # en affichant les lignes qui
# correspondent
}La variable %assoc contient tous les morceaux intéressants. Elle utilise chaque lettre de l'alphabet comme clef, et la valeur correspondante est l'ensemble des lettres du même type. Nous ajoutons également V et C, pour que vous puissiez utiliser « VVCVV » ou « audio » et tout de même obtenir « aeree ». Chaque caractère de l'argument fourni est utilisé pour trouver la classe de caractères associée et l'ajouter au motif. Une fois le motif créé et compilé par qr//, la correspondance (même si le motif est très long) va tourner rapidement. Voici un extrait de ce que vous pourriez obtenir en faisant tourner ce programme « fortuitement » :
% cvmap fortuitement /usr/dict/words_fr
REGEX : (?i-xsm:^[cbdfghjklmnpqrstvwxzy][aeiouy][cbdfghjklmnpqrstvwxzy][cbd
fghjklmnpqrstvwxzy][aeiouy][aeiouy][cbdfghjklmnpqrstvwxzy][aeiouy][cbdfghjk
lmnpqrstvwxzy][aeiouy][cbdfghjklmnpqrstvwxzy][cbdfghjklmnpqrstvwxzy]$)
banqueterent
becqueterent
bestialement
biscuiterent
cabriolerent
cabriolerons
cabrioleront
certainement
circuiterent
...En vous laissant admirer cette REGEX, nous vous persuaderons verbeusement, mais certainement de l'économie de frappe ainsi sommairement réalisée.
5-11-e. Évaluations de substitution▲
Quand le modificateur /e (« e » pour évaluation d'expression) est utilisé sur une expression s/MOTIF/CODE/e, la partie de remplacement est interprétée comme une expression, et pas seulement comme une chaîne entre apostrophes doubles. C'est comme un do {CODE}. Même si cela a l'air d'une chaîne, c'est simplement un bloc de code qui sera compilé en même temps que le reste de votre programme, bien avant que la substitution ne soit réellement faite.
Vous pouvez utiliser le modificateur /e pour construire des chaînes de remplacement avec une logique plus fantaisiste que celle que permet l'interpolation entre doubles apostrophes. Voici la différence :
s/(\d+)/$1 * 2/; # Remplace "42" par "42 * 2"
s/(\d+)/$1 * 2/e; # Remplace "42" par "84"Et ceci convertit les degrés Celsius en Fahrenheit :
$_ = "Préchauffez le four à 233C.\n";
s/\b(\d+\.?\d*)C\b/int($1 * 1.8 + 32) . "F"/e; # convertit en 451FLes applications sont sans limite. Voici un filtre qui modifie un fichier en place (comme un éditeur) en ajoutant 100 à tout nombre qui se trouve en début de ligne (et qui n'est pas suivi par des deux-points, que nous ne faisons que regarder, sans les trouver ni les remplacer) :
% perl -pi -e 's/^(\d+)(?=:)/100 + $1/e' fichierDe temps à autre, vous voudrez faire un peu plus que simplement utiliser dans un autre calcul la chaîne que vous avez trouvée. Vous voulez parfois que cette chaîne soit un calcul, dont vous utiliserez l'évaluation en tant que valeur de remplacement. Chaque modificateur /e supplémentaire rajoute un eval autour du code à exécuter. Les deux lignes suivantes font la même chose, mais la première est plus facile à lire :
s/MOTIF/CODE/ee
s/MOTIF/eval(CODE)/eVous pourriez utiliser cette technique pour remplacer les apparitions de valeurs scalaires simples par leurs valeurs :
s/(\$\w+)/$1/eeg; # Interpole les valeurs de la plupart des scalairesComme c'est vraiment un eval, le /ee trouve même les variables lexicales. Un exemple un peu plus élaboré calcule la valeur de remplacement pour des expressions arithmétiques simples sur des entiers (positifs) :
$_ = "J'ai 4 + 19 euros et 8/2 centimes.\n";
s{ (
\d+ \s* # trouve un entier
[+*/-] # et un opérateur arithmétique
\s* \d+ # et un autre entier
)
}{ $1 }eegx; # puis trouve $1 et exécute ce code
print; # "J'ai 23 euros et 4 centimes."Comme tout autre eval CHAINE, les erreurs de compilation (comme des problèmes de syntaxe) et les exceptions à l'exécution (comme une division par zéro) sont capturées. Dans ce cas, la variable $@ ($EVAL_ERROR) dit ce qui s'est mal passé.
5-11-f. Évaluation de code lors de la recherche▲
Dans la plupart des programmes qui utilisent les expressions régulières, ce sont les structures de contrôle du programme tout autour qui dirigent le flux logique de l'exécution. Vous écrivez des boucles if ou while, faites des appels de fonctions ou de méthodes, qui se trouvent appeler une opération de recherche de motif de temps à autre. Même avec s///e, c'est l'opérateur de substitution qui a le contrôle et n'exécute le code de remplacement qu'après une recherche réussie.
Avec les sous-motifs de code, la relation usuelle entre les expressions régulières et le code du programme est inversée. Alors que le Moteur applique ses règles à votre motif au moment de la recherche, il peut tomber sur une extension de regex de la forme (?{CODE}). Quand il est déclenché, ce sous-motif ne fait aucune reconnaissance ni aucune assertion périphérique. C'est une assertion de largeur nulle qui « réussit » toujours et n'est évaluée que pour ses effets de bord. À chaque fois que le moteur doit passer sur le sous-motif de code pour progresser dans le motif, il exécute ce code.
"glyphe" =~ /.+ (?{ print "yo" }) ./x; # Affiche "yo" deux foisAlors que le Moteur essaie d'établir la correspondance entre « glyphe » et ce motif, il laisse d'abord .+ avaler les cinq lettres. Puis il affiche « yo ». Quand il tombe sur le point final, les cinq lettres ont déjà été avalées ; il lui faut donc faire machine arrière sur le .+ et lui faire rendre une des lettres. Il avance de nouveau dans le motif, faisant un nouvel affichage de « yo » au passage, fait correspondre e au point final et termine sa recherche avec succès.
Les accolades autour du fragment de CODE sont destinées à vous rappeler qu'il s'agit d'un bloc de code Perl, et qu'il se comporte comme un bloc au sens lexical. C'est-à-dire que si vous utilisez my pour déclarer une variable à portée lexicale, elle sera privée à ce bloc. Mais si vous utilisez local pour localiser une variable à portée dynamique, il risque de ne pas faire ce à quoi vous vous attendez. Un sous-motif (?{CODE}) crée une portée dynamique implicite qui reste valide pour le reste du motif, jusqu'à ce qu'il réussisse ou qu'il fasse machine arrière à travers ce sous-motif de code. Une manière de voir cela est que le bloc ne retourne pas vraiment quand il arrive à la fin. Au lieu de cela, il faut un appel récursif invisible au Moteur pour essayer de détecter le reste du motif. C'est seulement quand cet appel récursif se termine qu'il revient du bloc, en « délocalisant » les variables localisées.(87)
Dans l'exemple suivant, nous initialisons $i à 0 en incluant un sous-motif de code au début du motif. Ensuite nous capturons autant de caractères que possible avec .* — mais nous mettons un autre sous-motif de code entre le . et l'* comme cela nous pourrons savoir combien de fois le . trouve quelque chose.
$_ = 'lothlorien';
m/ (?{ $i = 0 }) # Met $i à 0
(. (?{ $i++ }) )* # Met à jour $i, même après un retour
# en arrière
lori # Force un retour arrière
/x;Le Moteur se met donc joyeusement en route, mettant $i à 0 et laissant .* gober les 10 caractères de la chaîne. Quand il rencontre le lori dans le motif, il revient en arrière et abandonne quatre caractères du .*. À la fin de la recherche, $i vaudra toujours 10.
Si vous vouliez que $i représente le nombre de caractères que le .* a effectivement conservés à la fin, vous pouvez utiliser la portée dynamique à l'intérieur du motif :
$_ = 'lothlorien';
m/ (?{ $i = 0 })
(. (?{ local $i = $i + 1; }) )* # Met à jour $i, avec protection contre le retour arrière
lori
(?{ $resultat = $i }) # Copie dans une variable non localisée
/x;Ici nous utilisons local pour nous assurer que $i contient le nombre de caractères trouvés par .*, en tenant compte des retours en arrière. $i sera perdue après la fin de l'expression régulière, aussi le sous-motif de code (?{ $result = $i }) conserve la valeur de $i dans $resultat.
La variable spéciale $^R (décrite au chapitre 28) contient le résultat du dernier (?{CODE}) qui a été exécuté au cours d'une recherche réussie.
Vous pouvez utiliser une extension (?{CODE}) comme la COND d'une (?(COND)SIVRAI|SIFAUX). Si vous faites cela, $^R ne sera pas mis à jour et vous pouvez omettre les parenthèses autour de la condition :
"glyphe" =~ /.+(?(?{ $toto{titi} gt "symbole" }).|signet)./;Ici, nous testons si $toto{titi} est plus grand que symbole. Si oui, nous incluons . dans le motif, sinon nous incluons signet dans le motif. On peut l'étirer pour le rendre un peu plus lisible :
"glyphe" =~ m{
.+ # quelques n'importe quoi
(?(?{ # si
$toto{titi} gt "symbole" # ceci est vrai
})
. # trouve un autre n'importe quoi
| # sinon
signet # trouve signet
)
. # et un n'importe quoi de plus
}x;Quand use re est enclenché, une regex a le droit de contenir un sous-motif (?{CODE}) même si l'expression régulière interpole des variables :
/(.*?) (?{length($1) < 3 && warn}) $suffixe/; # Erreur sans use re 'eval'Ceci est normalement interdit pour des raisons de sécurité. Même si le motif ci-dessus est sans danger, car $suffixe est sans danger, l'analyseur de regex ne peut pas savoir quelles parties de la regex ont été interpolées et lesquelles ne l'ont pas été. C'est pourquoi il interdit simplement les sous-motifs de code s'il y a eu de l'interpolation.
Si le motif s'obtient à partir de données entachées, même use re n'autorisera pas la recherche de motif à continuer.
Quand use re 'taint' est enclenché et qu'une chaîne entachée est la cible d'une regex, les sous-motifs capturés (dans les variables numérotées ou dans la liste de valeurs renvoyées par m// en contexte de liste) sont entachés. Cela est utile quand les opérations de regex sur des données entachées sont destinées non pas à extraire des sous-chaînes sûres, mais plutôt pour faire de nouvelles transformations. Voir le chapitre 23, Sécurité, pour en savoir plus sur l'entachement. Pour ce pragma, les expressions régulières précompilées (obtenues en général par qr//) ne sont pas considérées comme interpolées :
/toto${motif}titi/Ceci est autorisé si $motif est une expression régulière précompilée, même si $motif contient des sous-motifs (?{CODE}).
Précédemment nous vous avons montré un peu de ce que use re 'debug' affiche. Une solution de débogage un peu plus primitive consiste à utiliser des sous-motifs (?{CODE}) pour afficher ce qui a été trouvé jusqu'ici dans la recherche :
"abcdef" =~ / .+ (?{print "Trouvé jusqu'à présent : $&\n"}) bcdef $/x;Ceci affiche :
Trouvé jusqu'à présent : abcdef
Trouvé jusqu'à présent : abcde
Trouvé jusqu'à présent : abcd
Trouvé jusqu'à présent : abc
Trouvé jusqu'à présent : ab
Trouvé jusqu'à présent : ace qui montre .+ gobant toutes les lettres et les rendant une par une au fur et à mesure que le Moteur rebrousse chemin.
5-11-g. Interpolation de motif lors de la recherche▲
Vous pouvez construire des morceaux de votre motif depuis l'intérieur du motif lui-même. L'extension (??{CODE}) vous permet d'insérer du code qui s'évalue en un motif valide. C'est comme écrire /$motif/, sauf que vous pouvez générer $motif à l'exécution — plus spécifiquement, lors de la recherche. Par exemple :
/\w (??{ if ($seuil > 1) { "rouge" } else { "bleu" } }) \d/x;C'est équivalent à /\wrouge\d/ si $seuil est plus grand que 1 et à /\wbleu\d/ sinon.
Vous pouvez inclure des références arrière à l'intérieur du code évalué pour déduire de motifs de chaînes trouvées à l'instant (même si elles ne seront plus trouvées plus tard pour cause de retour arrière). Par exemple, ceci trouve toutes les chaînes qui se lisent de la même façon à l'envers et à l'endroit (plus connues sous le nom de palindromadaires, ce sont des phrases avec une bosse au milieu) :
/^ (.+) .? (??{quotemeta reverse $1}) $/xi;Vous pouvez équilibrer des parenthèses comme suit :
$texte =~ /( \(+ ) (.*?) (??{ '\)' x length $1 })/x;Ceci trouve les chaînes de la forme (shazam!) et (((shazam!))), et met shazam! dans $2. Hélas, il est incapable de savoir si les parenthèses au milieu sont équilibrées. Pour cela nous avons besoin de récursion.
Heureusement, vous pouvez aussi faire des motifs récursifs. Vous pouvez avoir un motif compilé utilisant (??{CODE}) et faisant référence à lui-même. La recherche récursive est plus irrégulière, pour des expressions régulières. Tous les textes sur les expressions régulières vous diront qu'une expression rationnelle standard ne peut pas trouver des parenthèses équilibrées correctement. Et c'est correct. Il est aussi vrai que les regex de Perl ne sont pas standard. Le motif suivant(88) trouve un ensemble de parenthèses équilibrées, quelle que soit leur profondeur :
$pe = qr{
\(
(?:
(?> [^()]+ ) # Non parenthèses sans retour arrière
|
(??{ $pe }) # Groupe avec des parenthèses équilibrées
)*
\)
}x;Vous pourriez l'utiliser comme ceci pour trouver un appel de fonction :
$foncmotif = qr/\w+$pe/;
'mafonc(1,(2*(3+4)),5)' =~ /^$foncmotif$/; # Trouvé !5-11-h. Interpolation conditionnelle▲
L'extension de regex (?(COND)SIVRAI|SIFAUX) ressemble à l'opérateur ?: de Perl. Si COND est vrai, le motif SIVRAI est utilisé ; sinon le motif SIFAUX est utilisé. COND peut être une référence arrière (exprimé comme un entier simple, sans le \ ou le $), une assertion périphérique ou un sous-motif de code (voir Assertions périphériques et Évaluation de code lors de la recherche plus haut dans ce chapitre).
Si COND est un entier, il est traité comme une référence arrière. Par exemple :
#!/usr/bin/perl
$x = 'Perl est gratuit.';
$y = 'PatronGiciel coûte 99EUR.';
foreach ($x, $y) {
/^(\w+) (?:est|(coûte)) (?(2)(\d+EUR)|\w+)/; # Soit (\d+EUR), soit \w+
if ($3) {
print "$1 coûte de l'argent.\n"; # PatronGiciel coûte
# de l'argent.
} else {
print "$1 ne coûte rien.\n"; # Perl ne coûte rien.
}
}Ici, COND est (2), qui est vrai s'il existe une deuxième référence arrière. Si c'est le cas, (\d+EUR) est ajouté au motif (et crée la référence arrière $3) ; sinon, \w+ est utilisé.
Si COND est une assertion périphérique ou un sous-motif de code, la véracité de l'assertion est utilisée pour déterminer s'il faut inclure SIVRAI ou SIFAUX :
/[ATGC]+(?(?<=AA)G|C)$/;Ceci utilise une assertion de rétrovision comme COND pour trouver une séquence d'ADN qui se termine soir par AAG ou une autre combinaison de base et un C.
5-11-i. Définir vos propres assertions▲
Vous ne pouvez pas modifier le fonctionnement du Moteur de Perl, mais si vous êtes suffisamment cinglé, vous pouvez changer la façon dont il voit votre motif. Comme Perl interprète votre motif de manière analogue à une chaîne entre apostrophes doubles, vous pouvez utiliser les merveilles de la surcharge des constantes chaîne pour vous arranger pour que les suites de caractères de votre choix soient automatiquement transformées en d'autres suites de caractères.
Dans l'exemple qui suit, nous définissons deux transformations qui doivent se produire quand Perl rencontre un motif. D'abord nous définissons \tag de façon à ce que lorsqu'il apparaît dans un motif, il est automatiquement transformé en (?:<.*?>), qui trouve la plupart des balises HTML et XML. Ensuite, nous « redéfinissons » le métasymbole \w de façon à ce qu'il n'accepte que les lettres anglaises.
Nous allons définir un paquetage nommé Tagger qui cache la surcharge à notre programme principal. Une fois que cela est fait, nous pourrons écrire :
Voici Tagger.pm, soit la forme d'un module Perl (voir chapitre 11) :
package Tagger;
use overload;
sub import { overload::constant 'qr' => \&convert }
sub convert {
my $re = shift;
$re =~ s/ \\tag /<.*?>/xg;
$re =~ s/ \\w /[A-Za-z]/xg;
return $re;
}
1;Le module Tagger reçoit le motif immédiatement avant l'interpolation, aussi pouvez vous sauter la surcharge en sautant l'interpolation, comme suit :
$re = '\tag\w+\tag'; # Cette chaîne commence avec \t, une tabulation
print if /$re/; # Trouve une tabulation, suivie d'un "a"...Si vous vouliez personnaliser la variable interpolée, appelez la fonction convert directement :
$re = '\tag\w+\tag'; # Cette chaîne commence avec \t, une tabulation
$re = Tagger::convert $re; # convertit \tag et \w
print if /$re/; # $re devient <.*?>[A-Za-z]+<.*?>Et maintenant, si vous vous demandez toujours ce que sont ces fameuses sub dans le module Tagger, vous allez le découvrir bien vite, car c'est le sujet du chapitre suivant.
6. Sous-programmes▲
Comme beaucoup de langages, Perl fournit des sous-programmes définis par l'utilisateur.(89) Ces sous-programmes peuvent être définis n'importe où dans le programme principal, chargés depuis d'autres fichiers grâce aux mots clefs do, require ou use ou générés à l'exécution avec eval. Vous pouvez même les charger à l'exécution avec le mécanisme décrit dans la section Autochargement du chapitre 10, Paquetages. Vous pouvez appeler un sous-programme indirectement, en utilisant une variable contenant son nom ou une référence à la routine ou à travers un objet, en laissant l'objet déterminer quel sous-programme doit vraiment être appelé. Vous pouvez générer des sous-programmes anonymes, accessibles seulement à travers des références, et si vous voulez, vous en servir pour cloner de nouvelles fonctions quasiment identiques à l'aide de fermetures, qui sont décrites dans la section du même nom du chapitre 8, Références.
6-1. Syntaxe▲
Pour déclarer un sous-programme nommé sans le définir, utilisez l'une de ces formes :
Pour déclarer et définir un sous-programme, ajoutez un BLOC :
Pour créer un sous-programme anonyme ou une fermeture, omettez le NOM :
PROTO et ATTRS représentent le prototype et les attributs, chacun d'entre eux étant présenté dans sa propre section plus loin dans ce chapitre. Ils ne sont pas si importants ; le NOM et le BLOC sont les parties essentielles, y compris quand elles sont absentes.
Pour les formes sans NOM, vous devez toujours fournir une manière d'appeler le sous-programme. Assurez-vous donc de sauvegarder la valeur de retour, car non seulement cette forme de déclaration de sub est compilée comme vous pouviez vous y attendre, mais elle fournit également une valeur de retour à l'exécution :
$refsub = sub BLOCK;Pour importer des sous-programmes définis dans un autre module, écrivez :
use MODULE qw(NOM1 NOM2 NOM3...);Pour appeler les sous-programmes directement, écrivez :
NOM(LISTE) # & est optionnel avec des parenthèses.
NOM LISTE # Parenthèses facultatives si sub prédéclarée/importée.
&NOM # Passe le @_ courant à ce sous-programme
# (et contourne les prototypes).Pour appeler des sous-programmes de façon indirecte (par leur nom ou par référence), utilisez n'importe laquelle de ces formes :
&$refsub(LISTE) # Le & n'est pas facultatif pour un appel indirect
$refsub->(LISTE) # (sauf en utilisant une notation infixe).
&$refsub # Passe le @_ courant à ce sous-programme.Le nom officiel d'un sous-programme comprend le préfixe &. Un sous-programme peut être appelé en utilisant le préfixe, mais le & est en général optionnel, ainsi que les parenthèses si le sous-programme a été prédéclaré. Cependant, le & n'est pas optionnel quand vous ne faites que nommer le sous-programme, comme quand il est utilisé comme argument de defined ou undef ou quand vous voulez générer une référence à un sous-programme nommé en écrivant $refsub = \&nom. Le & n'est pas non plus optionnel quand vous voulez faire un appel de sous-programme indirect en utilisant l'une des constructions &$refsub() ou &{$refsub}(). Cependant, la notation la plus commode $refsub->() n'en a pas besoin. Voir le chapitre 8 pour en savoir plus au sujet des références de sous-programmes.
Perl n'impose pas de modèle particulier d'écriture en majuscules ou minuscules pour vos noms de sous-programme. Cependant une convention vaguement suivie est que les fonctions appelées indirectement par Perl à l'exécution (BEGIN, CHECK, INIT, END, AUTOLOAD, DESTROY et toutes les fonctions mentionnées au chapitre 14, Variables liées) sont toutes en majuscules, aussi vaut-il probablement mieux éviter ce style. (Mais les sous-programmes utilisés pour des valeurs constantes portent d'habitude un nom tout en capitales. C'est normal. Nous espérons...)
6-2. Sémantique▲
Avant de vous mettre dans tous vos états à cause de toute cette syntaxe, souvenez-vous que la manière normale de définir un simple sous-programme finit par ressembler à cela :
sub guincher {
print "Vous voilà guinché.\n";
}et que la manière normale de l'appeler est simplement :
guincher();Dans ce cas, nous avons ignoré l'entrée (les arguments) et la sortie (les valeurs de retour). Mais les modèles Perl pour passer des données, à et depuis un sous-programme, sont vraiment assez simples : tous les paramètres de la fonction sont passés comme une seule liste à plat de scalaires, et s'il y a plusieurs valeurs de retour, elles sont de même retournées à l'appelant comme une seule liste à plat de scalaires. Comme pour toute LISTE, les tableaux et les hachages passés dans cette liste s'interpoleront dans la liste à plat, perdant par là même leur identité. Mais il existe plusieurs manières de contourner cela, et l'interpolation automatique de liste est souvent très utile. Les listes de paramètres, comme les listes de retour, peuvent contenir autant (ou aussi peu) d'éléments que vous voulez (bien que vous puissiez imposer certaines contraintes aux listes de paramètres en utilisant des prototypes). En effet, Perl est conçu autour de cette notion de fonctions variadiques (qui peuvent prendre n'importe quel nombre d'arguments) ; en C, au contraire, elles sont plus ou moins bidouillées à contreœur de façon à ce que vous puissiez appeler printf(3).
Maintenant, si vous voulez un langage conçu pour passer un nombre variable d'arguments arbitraires, vous devriez vous arranger pour qu'il soit facile de traiter ces listes arbitraires d'arguments. Tout argument passé à un sous-programme Perl est fourni dans le tableau @_. Si vous appelez une fonction avec deux arguments, ils sont accessibles à l'intérieur de la fonction comme les deux premiers éléments de ce tableau : $_[0] et $_[1]. Comme @_ est un tableau ordinaire avec un nom extraordinaire, vous pouvez lui faire tout ce que vous pouvez normalement faire à un tableau.(90) Le tableau @_ est un tableau local, mais ses valeurs sont des alias des véritables paramètres scalaires. (C'est connu sous le nom de sémantique de passage par référence.) Vous pouvez donc modifier les véritables paramètres si vous modifiez l'élément correspondant de @_ (c'est cependant rarement fait, tellement il est facile de renvoyer des valeurs intéressantes en Perl).
La valeur de retour du sous-programme (ou de n'importe quel bloc, en fait) est la valeur de la dernière expression évaluée. Vous pouvez aussi utiliser une instruction return explicite pour spécifier la valeur de retour et sortir du sous-programme depuis n'importe quel point à l'intérieur. Dans les deux cas, si la fonction est appelée en contexte scalaire ou de liste, l'expression finale de cette fonction est appelée dans ce même contexte.
6-2-a. Trucs avec la liste de paramètres▲
Perl n'a pas encore de paramètres formels nommés, mais en pratique tout ce que vous avez besoin de faire, c'est de copier les valeurs de @_ dans une liste my, qui sert parfaitement de liste de paramètres formels. (Ce n'est pas une coïncidence si la copie des valeurs change un passage par référence en passage par valeur, ce qui est le fonctionnement que les gens attendent habituellement, même s'ils ne connaissent pas le vocabulaire de l'informatique théorique.) Voici un exemple typique :
sub setenv_peut_etre {
my ($cle, $valeur) = @_;
$ENV{$cle} = $valeur unless $ENV{$cle};
}Mais vous n'êtes pas obligé de nommer vos paramètres, ce qui est tout l'intérêt du tableau @_. Par exemple, pour calculer un maximum, vous pouvez juste itérer directement sur @_ :
sub max {
my $max = shift(@_);
for my $element (@_) {
$max = $element if $max < $element;
}
return $max;
}
$meilleurjour = max($lun,$mar,$mer,$jeu,$ven);Ou vous pouvez remplir tout un hachage d'un coup :
sub configuration {
my %options = @_;
print "Verbosité maximale.\n" if $options{VERBOSE} == 9;
}
configuration(PASSWORD => "xyzzy", VERBOSE => 9, SCORE => 0);Voici un exemple où vos arguments formels ne sont pas nommés afin de pouvoir modifier les arguments eux-mêmes :
majuscules_sur_place($v1, $v2); # ceci change $v1 et $v2
sub majuscules_sur_place {
for (@_) { tr/a-z/A-Z/ }
}Bien sûr, vous n'avez pas le droit de modifier des constantes de cette façon. Si l'un des arguments était en fait un scalaire comme "hobbit" ou une variable en lecture seule comme $1 et que vous essayiez de le modifier, Perl lèverait une exception (vraisemblablement fatale et menaçant potentiellement votre carrière). Par exemple, ceci ne marchera pas :
majuscules_sur_place("philippe");Ce serait beaucoup plus sûr si la fonction majuscules_sur_place était écrite de façon à renvoyer des copies de ses paramètres, au lieu de les modifier directement :
($v3, $v4) = majuscules($v1, $v2);
sub majuscules {
my @parms = @_;
for (@parms) { tr/a-z/A-Z/ }
# Vérifie si nous avons été appelés en contexte de liste.
return wantarray ? @parms : $parms[0];
}Remarquez comme cette fonction (sans prototype) se moque de savoir si on lui a passé de véritables scalaires ou des tableaux. Perl aplatira tout dans une grande liste à plat de paramètres dans @_. C'est l'un des cas où Perl brille par son style simple de passage de paramètres. La fonction majuscules fonctionnera parfaitement bien sans changer sa définition, même si on lui passe des choses comme ça :
@nouvelleliste = majuscules(@liste1, @liste2);
@nouvelleliste = majuscules( split /:/, $var );Ne vous laissez cependant pas tenter par cela :
(@a, @b) = majuscules(@liste1, @liste2); # FAUXPourquoi ? Parce que, tout comme la liste des paramètres entrants dans @_ est plate, la liste de retour est aussi à plat. Ceci stocke donc tout dans @a, et vide @b en y stockant la liste vide. Voir la section Passage de références pour d'autres manières de s'y prendre.
6-2-b. Indications d'erreur▲
Si vous voulez que votre fonction se termine de façon à ce que l'appelant réalise qu'une erreur s'est produite, la manière la plus naturelle de faire est d'utiliser un return simple sans argument. De cette façon, quand la fonction est appelée en contexte scalaire, l'appelant reçoit undef et quand elle utilisée en contexte de liste, l'appelant reçoit une liste vide.
Dans des circonstances extraordinaires, vous pourriez choisir de lever une exception pour indiquer une erreur. Utilisez cependant cette mesure avec parcimonie, sinon votre programme va se retrouver envahi de gestionnaires d'exception. Par exemple, ne pas réussir à ouvrir un fichier dans une fonction générique d'ouverture de fichier n'est pas vraiment un événement exceptionnel. En revanche ignorer une telle erreur en serait vraiment un. La fonction intégrée wantarray retourne undef si votre fonction a été appelée en contexte vide ; vous pouvez donc savoir si la valeur de retour de votre fonction est ignorée :
6-2-c. Problèmes de portée▲
Les sous-programmes peuvent être appelés de façon récursive, car chaque appel reçoit son propre tableau d'arguments, même quand la routine s'appelle elle-même. Si un sous-programme est appelé en utilisant la forme &, la liste d'arguments est optionnelle. Si la forme en & est utilisée, mais que la liste d'arguments est omise, quelque chose de spécial se produit : le tableau @_ de la routine appelante est fourni implicitement. Il s'agit d'un mécanisme d'efficacité que les nouveaux utilisateurs préféreront éviter.
&toto(1,2,3); # passe trois arguments
toto(1,2,3); # pareil
toto(); # passe une liste vide
&toto(); # pareil
&toto; # toto() reçoit les arguments courants, comme toto(@_),
#, mais plus vite !
toto; # comme toto() si sub toto est prédéclaré, sinon le mot
# simple "toto"Non seulement la forme & rend la liste d'arguments optionnelle, mais elle désactive également toute vérification de prototypage sur les arguments fournis. Ceci en partie pour des raisons historiques et en partie pour fournir un moyen efficace de tricher si vous savez ce que vous faites. Voir la section Prototypes plus loin dans ce chapitre.
Les variables qui sont utilisées dans la fonction, mais qui n'ont pas été déclarées privées à cette fonction, ne sont pas nécessairement des variables globales ; elles continuent à suivre les règles normales de portée de Perl. Comme expliqué dans la section Noms du chapitre 2, Composants de Perl, cela signifie qu'elles cherchent d'abord à être résolues dans la ou les portées lexicales englobantes, puis ensuite dans la portée du paquetage. Du point de vue d'un sous-programme, toute variable my d'une portée lexicale englobante est donc parfaitement visible.
Par exemple, la fonction bumpx, ci-dessous, a accès à la variable lexicale $x (à portée sur tout le fichier), car la portée dans laquelle ce my a été déclaré — le fichier lui-même — n'a pas été fermée avant la définition du sous-programme :
# début du fichier
my $x = 10; # déclare et initialise la variable
sub bumpx { $x++ } # la fonction peut voir la variable lexicale externeLes programmeurs C et C++ verraient probablement $x comme une variable « statique de fichier ». Elle est privée en ce qui concerne les fonctions dans les autres fichiers, mais globale du point de vue des fonctions déclarées après le my. Les programmeurs C qui viennent à Perl en cherchant ce qu'ils appelleraient des « variables statiques » pour des fichiers ou des fonctions ne trouvent pas un tel mot-clef. Les programmeurs Perl évitent en général le mot « statique », parce que les systèmes statiques sont morts et ennuyeux et que le mot est très chargé historiquement.
Bien que Perl ne dispose pas du mot « static » dans son dictionnaire, les programmeurs Perl n'ont aucun problème pour créer des variables qui restent privées à une fonction et persistent d'un appel de fonction à un autre. C'est juste qu'il n'existe pas de mot spécial pour décrire cela. Les primitives de portée de Perl sont plus riches et se combinent avec sa gestion automatique de mémoire de telle manière que quelqu'un cherchant le mot-clef « static » pourrait ne jamais penser à les utiliser.
Les variables lexicales ne passent pas automatiquement au ramasse-miettes simplement parce que l'on est sorti de leur portée ; elles attendent de ne plus être utilisées pour être recyclées, ce qui est bien plus important. Pour créer des variables privées qui ne sont pas automatiquement réinitialisées entre deux appels de fonction, incluez la fonction tout entière dans un bloc supplémentaire et mettez à la fois la déclaration my et la définition de la fonction à l'intérieur de ce bloc. Vous pouvez même y mettre plus d'une fonction pour leur donner un accès partagé à une variable qui, sinon, est privée.
{
my $compteur = 0;
sub next_compteur { return ++$compteur }
sub prev_compteur { return --$compteur }
}Comme toujours, l'accès à la variable lexicale est limité au code se trouvant dans la même portée lexicale. Les noms des deux fonctions sont cependant globalement accessibles (à l'intérieur du paquetage) et, comme les fonctions ont été définies dans la portée de $compteur, elles peuvent tout de même accéder à cette variable bien que personne d'autre ne le puisse.
Si cette fonction est chargée par require ou use, alors c'est probablement parfait. Si tout se passe dans le programme principal, vous devrez vous assurer que toute affectation à my à l'exécution est exécutée suffisamment tôt, soit en mettant tout le bloc avant votre programme principal, soit en plaçant un bloc BEGIN ou INIT autour pour être sûr qu'il sera exécuté avant que votre programme ne démarre :
BEGIN {
my @gamme = qw/ do re mi fa sol la si /;
my $note = -1;
sub ton_suivant { return $gamme[ ($note += 1) %= @gamme ] };
}Le BEGIN n'affecte ni la définition du sous-programme, ni la persistance des lexicales utilisées par le sous-programme. Il est juste là pour s'assurer que les variables sont initialisées avant que la routine soit appelée. Pour plus d'information sur la déclaration de variables privées et globales, voir respectivement my et our au chapitre 29, Fonctions. Les constructions BEGIN et INIT sont expliquées au chapitre 18, Compilation.
6-3. Passage de références▲
Si vous voulez passer plus d'un tableau ou d'un hachage, depuis ou vers une fonction, tout en maintenant leur intégrité, vous aurez alors besoin d'un mécanisme explicite de passage de références. Avant cela, vous aurez besoin de comprendre les références ainsi qu'elles sont expliquées au chapitre 8. Faute de quoi, cette section risque de ne pas être très compréhensible. Enfin, vous pourrez toujours regarder les images...
Voici quelques exemples simples. Définissons d'abord une fonction qui attend une référence à un tableau. Quand le tableau est grand, il est beaucoup plus rapide de le passer comme une simple référence plutôt que comme une longue liste de valeurs :
$total = somme ( \@a );
sub somme {
my ($reftab) = @_;
my ($total) = 0;
foreach (@$reftab) { $total += $_ }
return $total;
}Passons plusieurs tableaux à une fonction, et faisons-la dépiler (via pop) chacun d'entre eux, en renvoyant une nouvelle liste de leurs derniers éléments :
@derniers = popplus ( \@a, \@b, \@c, \@d );
sub popplus {
my @retliste = ();
for my $reftab (@_) {
push @retliste, pop @$reftab;
}
return @retliste;
}Voici comment vous pourriez écrire une fonction qui ferait une sorte d'intersection, en retournant la liste des clefs apparaissant dans tous les hachages qui lui sont passés :
@commun = inter( \%toto, \%titi, \%tutu );
sub inter {
my %vus;
for my $href (@_) {
while (my $k = each %$href ) {
$vus{$k}++;
}
}
return grep { $vus{$_} == @_ } keys %vus;
}Jusqu'ici nous n'avons fait qu'utiliser le mécanisme normal de retour de liste. Que se passe-t-il si vous voulez passer ou renvoyer un hachage ? S'il ne s'agit que d'un seul ou que cela ne vous gêne pas qu'ils soient concaténés, les conventions d'appel habituelles conviennent, bien qu'elles soient un peu coûteuses.
Comme nous l'avons expliqué précédemment, les gens commencent à avoir des problèmes avec :
(@a, @b) = func(@c, @d);Ou bien :
(%a, %b) = func(%c, %d);Cette syntaxe ne fonctionne tout simplement pas. Elle se contente de tout affecter à @a ou %a tout en vidant @b ou %b. De plus la fonction ne reçoit pas deux tableaux ou deux hachages séparés : elle reçoit une longue liste dans @_, comme toujours.
Vous pouvez vous arranger pour que votre fonction prenne des références en paramètre et en renvoie en résultat. Voici une fonction qui prend deux références de tableau en argument et renvoie les deux références de tableaux ordonnées selon le nombre d'éléments qu'ils contiennent.
($aref, $bref) = func(\@c, \@d);
print "@$aref en a plus que @$bref\n";
sub func {
my ($cref, $dref) = @_;
if (@$cref > @$dref) {
return ($cref, $dref);
} else {
return ($dref, $cref);
}
}Pour passer des handles de fichier ou de répertoire à des fonctions ou si vous voulez qu'elles en retournent, voir les sections Références de handles et Références de table de symboles au chapitre 8.
6-4. Prototypes▲
Perl vous permet de définir vos propres fonctions de façon à ce qu'elles soient appelées comme les fonctions internes de Perl. Considérez la fonction push(@tableau, $element), qui doit tacitement recevoir une référence à @tableau, et pas seulement les valeurs de la liste contenues dans @tableau, afin que le tableau soit effectivement modifié. Les prototypes vous permettent de déclarer des sous-programmes qui prennent leurs arguments comme beaucoup de fonctions internes, c'est-à-dire avec certaines contraintes au niveau du nombre et du type des arguments. Nous les appelons prototypes, mais ils fonctionnent comme des modèles automatiques du contexte d'appel plutôt que de la façon à laquelle penseraient des programmeurs C ou Java quand on leur parle de prototypes. Avec ces modèles, Perl ajoutera automatiquement des antislashs implicites ou des appels à scalar ou ce qu'il faut pour que les choses se présentent de manière à respecter le modèle fourni. Par exemple, si vous déclarez :
sub monpush (\@@);alors monpush prendra ses arguments exactement comme push les prend. Pour que cela fonctionne, il faut que la déclaration de la fonction soit visible à la compilation. Le prototype n'affecte l'interprétation des appels de fonction que quand le caractère & est omis. En d'autres termes, si vous l'appelez comme une fonction intégrée, elle se comporte comme une fonction intégrée. Si vous l'appelez comme une bonne vieille routine, elle se comporte comme une bonne vieille routine. Le & supprime les vérifications de prototype et les effets contextuels associés.
Comme les prototypes sont pris en considération seulement à la compilation, il en découle naturellement qu'ils n'ont aucune influence sur les références de sous-programme comme \&toto ou sur les appels de sous-programme indirects comme &{$refsub} ou $refsub->(). Les appels de méthode ne sont pas non plus influencés par les prototypes. C'est parce que la véritable fonction à appeler est indéterminée au moment de la compilation, puisqu'elle dépend de l'héritage, qui est calculé dynamiquement en Perl.
Comme il s'agit avant tout de permettre de définir des sous-programmes qui fonctionnent comme les commandes internes, voici quelques prototypes de fonctions que vous pourriez utiliser pour émuler le fonctionnement des fonctions internes correspondantes :
|
Déclaré comme |
Appelé par |
|---|---|
|
sub monlink ( |
monlink |
|
sub monreverse ( |
monreverse |
|
sub monjoin ( |
monjoin |
|
sub monpop (\ |
monpop |
|
sub monsplice (\ |
monsplice |
|
sub monkeys (\ |
monkeys |
|
sub monpipe ( |
monpipe READHANDLE, WRITEHANDLE |
|
sub monindex ( |
monindex |
|
sub monsyswrite ( |
monsyswrite OUTF, |
|
sub monopen ( |
monopen HANDLE |
|
sub mongrep ( |
mongrep |
|
sub monrand ( |
monrand |
|
sub montime () |
montime |
Tout caractère de prototype précédé d'un antislash (entre parenthèses dans la colonne de gauche ci-dessus) représente un argument réel (dont la colonne de droite donne un exemple) qui doit impérativement commencer par ce caractère. Le premier argument de monkeys doit donc commencer par un %, tout comme le premier argument de keys.
Un point-virgule sépare les arguments obligatoires des arguments optionnels. (Il serait redondant devant un @ ou un % puisque les listes peuvent être vides.) Les caractères de prototype sans antislash ont une signification spéciale. Tout caractère @ ou % consomme tout le reste des arguments et force un contexte de liste. (Il est équivalent à LISTE dans un diagramme de syntaxe.) Un argument représenté par $ force un contexte scalaire. Un & requiert une référence à un sous-programme nommé ou anonyme.
Une * permet au sous-programme d'accepter dans cet emplacement tout ce qui serait accepté comme un handle de fichier par une fonction interne : un nom simple, une constante, une expression scalaire, un typeglob ou une référence à un typeglob. Si vous voulez toujours convertir un tel argument en une référence de typeglob, utilisez Symbol::qualify_to_ref comme suit :
use Symbol 'qualify_to_ref';
sub toto (*) {
my $fh = qualify_to_ref(shift, caller);
...
}Remarquez que les trois derniers exemples dans le tableau sont traités d'une manière spéciale par l'analyseur. Mongrep est analysé comme un véritable opérateur de liste, monrand est analysé comme un véritable opérateur unaire avec la même précédence unaire que rand et montime ne prend vraiment aucun argument, comme time.
C'est-à-dire que si vous écrivez :
montime +2;vous aurez montime() + 2 et non montime(2), qui serait le résultat d'une analyse sans prototype ou avec un prototype unaire.
L'exemple mongrep illustre aussi comment & est traité spécialement quand il est le premier argument. D'ordinaire, un prototype en & nécessiterait un argument comme \&toto ou sub{}. Cependant, quand il est le premier argument, vous pouvez supprimer le sub de votre sous-programme anonyme et simplement passer le bloc simple à l'emplacement de l'« objet indirect » (sans virgule après). L'un des aspects attrayants du prototype & est qu'il permet de générer une nouvelle syntaxe, tant que le & est en première position :
sub try (&$) {
my ($try, $catch) = @_;
eval { &$try };
if ($@) {
local $_ = $@;
&$catch;
}
}
sub catch (&) { $_[0] }
try {
die "phooey";
} # ce n'est pas la fin de l'appel de fonction !
catch {
/phooey/ and print "unphooey\n";
};Ceci affiche « unphooey ». Ici, try est appelé avec deux arguments, la fonction anonyme {die "phooey";} et la valeur de retour de la fonction catch, qui dans ce cas n'est rien d'autre que son propre argument, tout le bloc d'une autre fonction anonyme. Dans le try, la première fonction en argument est appelée sous la protection d'un bloc eval pour intercepter tout ce qui pourrait exploser. Si quelque chose explose effectivement, la seconde fonction est appelée avec une version locale de la variable globale $_ contenant l'exception qui a été levée.(91) Si tout cela est du chinois pour vous, vous allez devoir vous reporter à die et eval au chapitre 29, puis vous informer au sujet des fonctions anonymes et des fermetures au chapitre 8. D'un autre côté, si tout cela vous intrigue, vous pouvez jeter un œil au module Error sur CPAN, qui utilise cette méthode pour implémenter une gestion d'exceptions minutieusement structurée avec les clauses try, catch, except, otherwise et finally.
Voici une réimplémentation de l'opérateur grep (l'opérateur interne est plus efficace, bien sûr) :
sub mongrep (&@) {
my $coderef = shift;
my @resultat;
foreach $_ (@_) {
push(@resultat, $_) if &$coderef;
}
return @resultat;
}Certains préféreraient des prototypes complètement alphanumériques. Les caractères alphanumériques ont été intentionnellement laissés en dehors des prototypes dans le but avoué d'ajouter un jour des paramètres formels nommés. (Peut-être.) L'objectif majeur du mécanisme actuel est de permettre aux auteurs de modules d'imposer un certain nombre de vérifications à la compilation aux utilisateurs de leurs modules.
6-4-a. Substitution en ligne de fonctions constantes▲
Les fonctions prototypées avec (), ce qui signifie qu'elles ne prennent aucun argument, sont analysées comme la fonction interne time. Mieux, le compilateur traite de telles fonctions comme de bonnes candidates pour la mise en ligne. Si le résultat de cette fonction, après la passe d'optimisation et de précalcul des expressions constantes, est soit une constante, soit un scalaire à portée lexicale sans autre référence, alors cette valeur sera utilisée au lieu des appels à la fonction. Les appels faits avec &NOM ne sont cependant jamais mis en ligne, tout comme ils ne sont sujets à aucun autre effet de prototype. (Pour une méthode simple de déclaration de telles constantes, voir le pragma use constant au chapitre 31, Modules de pragmas.)
Les deux versions de ces fonctions calculant ! seront mises en ligne par le compilateur :
sub pi () { 3.14159 } # Pas exact, mais proche
sub PI () { 4 * atan2(1, 1) } # Le mieux qu'on puisse obtenirEn fait, toutes les fonctions suivantes seront mises en ligne, car Perl peut tout déterminer à la compilation :
sub FLAG_TOTO () { 1 << 8 }
sub FLAG_TITI () { 1 << 9 }
sub FLAG_MASK () { FLAG_TOTO | FLAG_TITI }
sub OPT_BLORGH () { (0x1B58 & FLAG_MASK) == 0 }
sub BLORGH_VAL () {
if (OPT_BLORGH) { return 23 }
else { return 42 }
}
sub N () { int(BLORGH_VAL) / 3 }
BEGIN { # le compilateur exécute ce bloc à la compilation
my $prod = 1; # variable privée, persistante
for (1 .. N) { $prod *= $_ }
sub NFACT () { $prod }
}Dans le dernier exemple, la fonction NFACT est mise en ligne, car elle a un prototype vide et que la variable qu'elle retourne n'est pas modifiée par la fonction — et ne peut plus ensuite être modifiée par personne, puisqu'elle est dans une portée lexicale. Le compilateur remplace donc toutes les utilisations de NFACT par cette valeur, qui a été précalculée à la compilation grâce au BEGIN qui l'entoure.
Si vous redéfinissez un sous-programme qui était susceptible d'être mis en ligne, vous aurez un avertissement obligatoire. (Vous pouvez vous servir de cet avertissement pour savoir si le compilateur a mis en ligne une routine en particulier.) L'avertissement est considéré suffisamment important pour ne pas être optionnel, car les invocations précédemment compilées de la fonction continueront d'utiliser l'ancienne valeur de la fonction. Si vous voulez redéfinir la routine, assurez-vous qu'elle n'a pas été mise en ligne en retirant le prototype () (qui change la sémantique d'appel, aussi faites attention) ou en contrecarrant le mécanisme de mise en ligne d'une autre manière, par exemple :
Pour en savoir plus sur ce qui se passe durant les phases de compilation et d'exécution de votre programme, voyez le chapitre 18.
6-4-b. Précautions à prendre avec les prototypes▲
Il vaut probablement mieux réserver les prototypes aux nouvelles fonctions et ne pas les appliquer à d'anciennes fonctions. Ce sont des descripteurs de contexte, pas des protypes du C ANSI, il vous faut donc être extrêmement attentif à ne pas imposer silencieusement un contexte différent. Supposez par exemple que vous décidiez qu'une fonction ne doit prendre qu'un seul paramètre, comme ceci :
Cela la transforme en opérateur unaire (comme l'opérateur interne rand) et modifie la façon dont le compilateur détermine les arguments de la fonction. Avec le nouveau prototype, la fonction consomme un seul argument en contexte scalaire, au lieu de plusieurs arguments en contexte de liste. Si quelqu'un l'a appelée avec un tableau ou une expression de liste, même si ce tableau ou cette liste ne contenait qu'un seul élément, là où cela marchait vous aurez maintenant quelque chose de complètement différent :
func @toto; # compte les éléments de @toto
func split /:/; # compte le nombre d'éléments retournés
func "a", "b", "c"; # passe "a" seulement, le jette avec "b"
# et retourne "c"
func("a", "b", "c"); # soudain, une erreur du compilateur !Vous venez juste de fournir un scalar implicite devant la liste d'arguments, ce qui peut être très surprenant. Ce n'est pas le vieux @toto qui contenait une seule valeur qui est passé. À la place, c'est 1 (le nombre d'éléments de @toto) qui est maintenant passé à func. Le split, étant appelé en contexte scalaire, scribouille partout dans votre liste de paramètres @_. Dans le troisième exemple, comme func a été prototypée comme un opérateur unaire, seul « a » lui est passé ; puis la valeur de retour de func est jetée tandis que l'opérateur virgule évalue les deux éléments suivants et retourne « c ». Dans le dernier exemple, l'utilisateur obtient maintenant une erreur de syntaxe à la compilation, sur du code qui compilait et fonctionnait parfaitement.
Si vous écrivez du nouveau code et que vous voudriez un opérateur unaire qui ne prend qu'une variable scalaire, et pas une expression scalaire, vous pouvez toujours le prototyper pour qu'il prenne une référence à un scalaire :
Maintenant le compilateur ne laissera rien passer qui ne commence pas par un dollar :
func @toto; # erreur de compilation, voit @, veut $
func split/:/; # erreur de compilation, voit une fonction, veut $
func $s; # celui-ci va bien ; on a eu un vrai $
func $a[3]; # celui-ci aussi
func $h{bazar}[-1]; # et même ça
func 2+5; # expression scalaire, toujours une erreur de
# compilation
func ${ \(2+5) }; # ça marche, mais le remède n'est-il pas pire que
# le mal ?Si vous ne faites pas attention, vous pouvez vous attirer des ennuis avec les prototypes. Mais si vous faites attention, vous pouvez faire tout un tas de trucs classe avec. Tout cela est bien sûr très puissant, et ne devrait être utilisé qu'avec modération pour rendre le monde meilleur.
6-5. Attributs de sous-programmes▲
Une déclaration ou une définition de sous-programme peut se voir associer une liste d'attributs. Si une telle liste d'attributs est présente, elle sera découpée en fonction des blancs ou des deux-points et traitée comme si un use attributes avait été vu. Voir le pragma use attributes au chapitre 31 pour des détails internes. Il existe trois attributs standards pour les sous-programmes : locked, method et lvalue.
6-5-a. Les attibuts locked et method▲
# Un seul thread est autorisé dans cette fonction.
sub afunc : locked { ... }
# Un seul thread est autorisé dans cette fonction pour un objet donné.
sub afunc : locked method { ... }Mettre l'attribut locked n'a de sens que lorsque la fonction ou la méthode est supposée être appelée par plusieurs threads simultanément. Quand il est appliqué à une fonction qui n'est pas une méthode, Perl s'assure qu'un verrou est mis sur la routine elle-même avant que l'on n'y entre. Quand il est appliqué à une fonction qui est une méthode (c'est-à-dire une fonction également marquée avec l'attribut method), Perl s'assure que toute invocation de cette méthode verrouille implicitement son premier argument (l'objet) avant l'exécution.
La sémantique de ce verrou est la même qu'en utilisant l'opérateur lock dans un sous-programme en première instruction de ce sous-programme. Pour en savoir plus sur les verrous, voir le chapitre 17, Threads. L'attribut method peut être utilisé tout seul :
À l'heure actuelle, cela n'a pour seul effet que de marquer la routine de façon à ne pas déclencher l'avertissement « Ambiguous call resolved as CORE::%s ». (Nous pourrons lui donner une signification plus importante un de ces jours.)
Le système d'attributs est extensible par l'utilisateur, ce qui vous permet de créer vos propres noms d'attribut. Ces nouveaux attributs doivent porter des noms d'identificateur valides (sans autre caractère de ponctuation que « _ »). Une liste de paramètres peut y être ajoutée, pour laquelle n'est vérifié pour le moment que le bon équilibrage des parenthèses.
Voici des exemples de syntaxe valide (bien que les attributs soient inconnus) :
sub fnord (&\%) : switch(10,foo(7,3)) : expensive;
sub plugh () : Ugly('\(") :Bad;
sub xyzzy : _5x5 { ... }Voici des exemples de syntaxe incorrecte :
sub fnord : switch(10,toto(); # chaîne () déséquilibrée
sub snoid : Laid('('); # chaîne () déséquilibrée
sub xyzzy : 5x5; # "5x5" n'est pas un identificateur valide
sub plugh : Y2::nord; # "Y2::nord" n'est pas un identificateur simple
sub snurt : toto + titi; # "+" n'est ni un espace ni un deux-pointsLa liste d'attributs est passée comme une liste de chaînes constantes au code qui les associe avec le sous-programme. La façon exacte dont cela fonctionne (ou ne fonctionne pas) est hautement expérimentale. Pour des détails actuels sur les listes d'attributs et leur manipulation, voir attributes(3).
6-5-b. L'attribut lvalue▲
Il est possible de renvoyer un scalaire modifiable depuis un sous-programme, mais seulement si vous déclarez que le sous-programme retourne une lvalue :
my $val;
sub modifiable : lvalue {
$val;
}
sub nonmodifiable {
$val;
}
modifiable() = 5; # Affecte à $valeur.
nonmodifiable() = 5; # ERREURSi vous passez des paramètres à un sous-programme lvalué, vous aurez besoin de parenthèses pour lever l'ambiguïté sur ce qui est affecté :
modifiable $x = 5; # affecte 5 à $x avant !
modifiable 42 = 5; # impossible de modifier une constante : erreur
# de compilation
modifiable($x) = 5; # ceci fonctionne
modifiable(42) = 5; # et cela aussiSi vous voulez finasser, vous pouvez contourner cela dans le cas particulier d'une fonction ne prenant qu'un seul argument. Déclarer la fonction avec le prototype ($) la fait analyser avec la précédence d'un opérateur unaire nommé. Comme les opérateurs unaires nommés ont une précédence supérieure à celle de l'affectation, vous n'avez plus besoin de parenthèses. (La question de savoir si cela est souhaitable ou pas est laissée à l'appréciation de la milice du style.)
En revanche, vous n'avez pas besoin de finasser dans le cas d'un sous-programme qui ne prend aucun argument (c'est-à-dire avec un prototype ()). Vous pouvez sans ambiguïté écrire :
modifiable = 5;Cela fonctionne, car aucun terme valide ne commence par =. De même, vous pouvez omettre les parenthèses dans les appels de méthodes lvaluées quand vous ne passez aucun argument :
$obj->modifiable = 5;Nous promettons de ne pas casser ces deux constructions dans les prochaines versions de Perl. Elles sont pratiques quand vous voulez encapsuler des attributs d'objet dans des appels de méthodes (de façon à ce qu'ils soient hérités comme des appels de méthodes, mais accessibles comme des variables).
Le contexte scalaire ou de liste du sous-programme avec l'attribut lvalue et de la partie droite d'une affectation à ce sous-programme est, dans les deux cas, déterminé en remplaçant l'appel de fonction par un scalaire. Considérez par exemple :
data(2,3) = get_data(3,4);Les deux sous-programmes ont été appelés en contexte scalaire, tandis que dans :
(data(2,3)) = get_data(3,4);et dans :
(data(2),data(3)) = get_data(3,4);tous les sous-programmes sont appelés en contexte de liste.
L'implémentation actuelle ne permet pas à des tableaux ou des hachages d'être retournés directement par des sous-programmes lvalués. Vous pouvez toujours renvoyer une référence à la place.
7. Formats▲
Perl dispose d'un mécanisme pour vous aider à générer des rapports et des tableaux simples. Ainsi, Perl vous aide à coder votre page de sortie d'une façon proche de ce à quoi elle ressemblera quand elle s'affichera. Il garde trace du nombre de lignes sur la page, du numéro de page courant, de quand imprimer les en-têtes de page et ainsi de suite. Les mots-clefs sont empruntés à FORTRAN : format pour les déclarer et write pour les exécuter. Voir les sections correspondantes au chapitre 29, Fonctions. Heureusement la disposition est beaucoup plus lisible, plus proche du PRINT USING de BASIC. Vous pouvez le voir comme le nroff(1) du pauvre. (Si vous connaissez nroff, ça ne ressemble peut-être pas à un encouragement.)
Les formats, comme les paquetages et les sous-programmes, sont déclarés plutôt qu'exécutés, et peuvent donc apparaître n'importe où dans votre programme. (Bien qu'en général il vaille mieux les regrouper tous ensemble.) Ils ont leur propre espace de nommage différent de ceux de tous les autres types de Perl. Cela signifie que si vous avez une fonction nommée « toto », elle n'a rien à voir avec le format nommé « toto ». Cependant le nom par défaut du format associé à un handle de fichier donné est le même que le nom de ce handle. Le format par défaut de STDOUT est donc nommé « STDOUT », et le format par défaut du handle de fichier TEMP est également appelé « TEMP ». Ils ont l'air identiques. Mais ils ne le sont pas.
Les formats d'enregistrement de sortie sont déclarés de la manière suivante :
format NOM =
FORMLISTE
.If NOM est omis, c'est le format STDOUT qui est défini. FORMLISTE est composée d'une série de lignes, chacun pouvant être de trois types :
- un commentaire, indiqué par une
#en première colonne ; - une ligne « image », donnant le format pour une ligne de sortie ;
- une ligne d'arguments fournissant les valeurs à insérer dans la ligne d'image précédente.
Les lignes images sont imprimées exactement comme elles apparaissent hormis certains champs auxquels sont substituées des valeurs.(92) Chaque champ de substitution dans une ligne image commence, soit par un signe @, soit par un ^. Ces lignes ne subissent aucune forme d'interpolation de variable. Le champ @ (à ne pas confondre avec le marqueur de tableau @) représente le type normal de champ ; l'autre type, ^, est utilisé pour un remplissage rudimentaire de blocs de texte multilignes. La longueur du champ est indiquée en remplissant le champ avec plusieurs caractères <, > ou | pour indiquer respectivement la justification à gauche, à droite ou au centre. Si la variable excède la longueur spécifiée, elle est tronquée.
Vous pouvez également utiliser, comme autre forme de justification à droite, des caractères # (après un caractère @ ou ^ initial) pour spécifier un champ numérique. Vous pouvez insérer un . à la place de l'un des caractères # pour aligner les points décimaux. Si l'une des valeurs fournies pour ces champs contient un saut de ligne, seul le texte avant ce saut de ligne est imprimé. Enfin, le champ spécial @* peut être utilisé pour imprimer des valeurs multilignes de manière non tronquée ; il devrait généralement apparaître seul sur une ligne image.
Les valeurs sont spécifiées sur la ligne suivante dans le même ordre que les champs images. Les expressions fournissant les valeurs doivent être séparées par des virgules. Les expressions sont toutes évaluées en contexte de liste avant que la ligne ne soit traitée, et une seule expression peut donc produire plusieurs éléments de liste. Les expressions peuvent s'étendre sur plusieurs lignes, si elles sont mises entre accolades. (Dans ce cas, l'accolade ouvrante doit être le premier token sur la première ligne.) Cela vous permet d'aligner les valeurs sous leurs champs de format respectifs pour faciliter la lecture.
Si l'évaluation d'une expression donne un nombre avec une partie décimale, et si l'image correspondante spécifie que la partie décimale doit apparaître dans la sortie (c'est-à-dire n'importe quelle image sauf une série de # sans . inclus), le caractère pour le point décimal est toujours déterminé par la valeur de la locale LC_NUMERIC. Cela signifie que si l'environnement d'exécution spécifie par exemple une locale française, une virgule sera utilisée plutôt qu'un point. Pour plus d'information, voir la page de manuel perllocale.
À l'intérieur d'une expression, les caractères blancs \n, \t et \f sont tous considérés comme équivalents à un espace seul. Vous pourriez voir cela comme si le filtre suivant était appliqué à chaque valeur dans le format :
$valeur =~ tr/\n\t\f/ /;Le caractère blanc restant, \r, force l'affichage d'une nouvelle ligne si la ligne image le permet.
Les champs images qui commencent par ^ plutôt que @ sont traités de manière spéciale. Avec un champ #, celui-ci est vide si la valeur est indéfinie. Pour les autres types de champ, le chapeau permet un genre de mode de remplissage. Au lieu d'une expression arbitraire, la valeur fournie doit être un nom de variable scalaire contenant une chaîne de caractères. Perl met tout le texte qu'il peut dans le champ, puis coupe le début de la chaîne de façon à ce que la fois suivante où la variable est référencée le reste du texte puisse être imprimé. (Oui, cela signifie que le contenu de la variable est altéré pendant l'exécution de l'appel à write et n'est pas préservé. Utilisez une variable temporaire si vous voulez préserver la valeur originale.) Normalement, vous devrez utiliser une séquence de champs alignés verticalement pour afficher un bloc de texte. Vous pouvez terminer le champ final par le texte « ... », qui apparaîtra dans la sortie seulement si le texte était trop long pour être affiché entièrement. Vous pouvez modifier les caractères de « rupture » en modifiant la valeur de la variable $: ($FORMAT_LINE_BREAK_CHARACTERS si vous utilisez le module English) en une liste des caractères désirés.
Les champs ^ peuvent produire des enregistrements de longueur variable. Si le texte à formater est court, répétez quelques fois la ligne de format avec le champ ^. Si vous faites cela pour de courtes données, vous obtiendrez quelques lignes blanches. Pour supprimer les lignes qui finiraient blanches, mettez un caractère ~ (tilde) n'importe où sur la ligne. (Le tilde lui-même est transformé en espace à la sortie.) Si vous mettez un second tilde à la suite du premier, la ligne sera répétée jusqu'à ce que tout le texte des champs de cette ligne ait été affiché. (Cela fonctionne, car tous les champs ^ avalent les chaînes qu'ils impriment. Mais si vous utilisez un champ de type @ en conjonction avec deux tildes, vous avez intérêt à ce que l'expression fournie ne renvoie pas perpétuellement la même valeur ! Utilisez un shift ou un autre opérateur dont l'un des effets secondaires épuise toutes les valeurs.)
Le traitement des en-têtes de format est géré par défaut par un format de même nom que le handle de fichier courant, auquel _TOP a été concaténé. Il est déclenché au début de chaque page. Voir write au chapitre 29.
Voici quelques exemples :
# un rapport sur le fichier /etc./passwd
format STDOUT_TOP =
Fichier Passwd
Nom Login Bureau Uid Gid Home
------------------------------------------------------------------
.
format STDOUT =
@<<<<<<<<<<<<<<<<<< @||||||| @<<<<<<@>>>> @>>>> @<<<<<<<<<<<<<<<<<
$nom, $login, $bureau,$uid,$gid, $home
.
# un rapport à partir d'un formulaire de rapport de bogues
format STDOUT_TOP =
Rapport de bogues
@<<<<<<<<<<<<<<<<<<<<<<< @||| @>>>>>>>>>>>>>>>>>>>>>>>
$systeme, $%, $date
------------------------------------------------------------------
.
format STDOUT =
Sujet: @<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
$suject
Index: @<<<<<<<<<<<<<<<<<<<<<<<<<<<< ^<<<<<<<<<<<<<<<<<<<<<<<<<<<<
$index, $description
Priorité: @<<<<<<<<<< Date: @<<<<<<< ^<<<<<<<<<<<<<<<<<<<<<<<<<<<<
$priorite, $date, $description
De: @<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< ^<<<<<<<<<<<<<<<<<<<<<<<<<<<<
$de, $description
Assigné à: @<<<<<<<<<<<<<<<<<<<<<<<< ^<<<<<<<<<<<<<<<<<<<<<<<<<<<<
$programmeur, $description
~ ^<<<<<<<<<<<<<<<<<<<<<<<<<<<<
$description
~ ^<<<<<<<<<<<<<<<<<<<<<<<<<<<<
$description
~ ^<<<<<<<<<<<<<<<<<<<<<<<<<<<<
$description
~ ^<<<<<<<<<<<<<<<<<<<<<<<<<<<<
$description
~ ^<<<<<<<<<<<<<<<<<<<<<<<...
$description
.Les variables lexicales ne sont pas visibles dans un format sauf si le format est déclaré dans la portée de la variable lexicale.
Il est possible de mélanger des appels à print et à write sur le même canal de sortie, mais il vous faudra gérer la variable spéciale $- ($FORMAT_LINES_LEFT si vous utilisez le module English) vous-même.
7-1. Variables de format▲
Le nom de format en cours est stocké dans la variable $~ ($FORMAT_NAME), et le nom de l'en-tête de format en cours dans $^ ($FORMAT_TOP_NAME). Le numéro de page de sortie courant est stocké dans $% ($FORMAT_PAGE_NUMBER), et le nombre de lignes dans la page se trouve dans $= ($FORMAT_LINES_PER_PAGE). Le vidage automatique du tampon de sortie de ce handle est positionné dans $| ($OUTPUT_AUTOFLUSH). La chaîne à sortie avant chaque en-tête de page est stockée dans $^L ($FORMAT_FORMFEED). Ces variables sont positionnées pour chaque handle de fichier, aussi devrez-vous faire un select sur le handle de fichier associé à un format pour modifier ses variables de format :
select((select(OUTF),
$~ = "Mon_Autre_Format",
$^ = "Mon_Entete_de_Format"
)[0]);C'est bien moche, hein ? C'est cependant un idiome commun, aussi ne soyez pas trop surpris en le voyant. Vous pouvez au moins utiliser une variable temporaire pour conserver le handle de fichier précédent :
$ofh = select(OUTF);
$~ = "Mon_Autre_Format";
$^ = "Mon_Entete_de_Format";
select($ofh);Non seulement c'est une meilleure approche en général, car cela améliore la lisibilité du code, mais vous avez maintenant en plus une instruction intermédiaire où s'arrêter dans le code avec un débogueur en pas à pas. Si vous utilisez le module English, vous pouvez même lire le nom des variables :
use English;
$ofh = select(OUTF);
$FORMAT_NAME = "Mon_Autre_Format";
$FORMAT_TOP_NAME = "Mon_Entete_de_Format";
select($ofh);Mais il vous reste quand même ces appels bizarres à select. Si vous voulez les éviter, utilisez le module FileHandle fourni avec Perl. Maintenant vous pouvez accéder à ces variables spéciales en utilisant des noms de méthodes en minuscules à la place :
use FileHandle;
OUTF->format_name("Mon_Autre_Format");
OUTF->format_top_name("Mon_Entete_de_Format");C'est quand même mieux !
Comme la ligne de valeurs qui suit votre ligne image peut contenir des expressions arbitraires (pour les champs @, pas pour les champs ^), vous pouvez passer les traitements plus compliqués à d'autres fonctions, comme printf ou une de vos propres fonctions. Par exemple pour insérer des virgules dans un nombre :
format Ident =
@<<<<<<<<<<<<<<<
commify($n)
.Pour afficher un vrai @, ~ ou ^ dans un champ, faites comme ceci :
format Ident =
J'ai un @ ici.
"@"
.Pour centrer toute une ligne de texte, faites quelque chose comme cela :
format Ident =
@||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
"Une ligne de texte"
.L'indicateur de longueur de champ > garantit que le texte sera justifié à droite dans le champ, mais le champ lui-même se place exactement où vous l'avez placé. Il n'existe pas de manière intégrée de dire « mets ce champ à droite de la page, quelle que soit sa largeur ». Vous devez spécifier où il se trouve relativement à la marge de gauche. Ceux qui sont vraiment désespérés peuvent générer leur propre format au vol, en s'appuyant sur le nombre courant de colonnes (non fourni) et puis faire un eval :
$format = "format STDOUT = \n"
. '^' . '<' x $cols . "\n"
. '$entry' . "\n"
. "\t^" . "<" x ($cols-8) . "~~\n"
. '$entry' . "\n"
. ".\n";
print $format if $Debug;
eval $format;
die $@ if $@;La ligne la plus importante est probablement celle du print. Ce qu'il imprime ressemble à ceci :
format STDOUT =
^<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
$entry
^<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<~~
$entry
.Voici un petit programme qui se comporte comme l'utilitaire Unix fmt(1) :
format =
^<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< ~~
$_
.
$/ = "";
while (<>) {
s/\s*\n\s*/ /g;
write;
}7-2. Pieds de page▲
Alors que $^ ($FORMAT_TOP_NAME) contient le nom du format d'en-tête courant, il n'existe pas de mécanisme correspondant pour les pieds de page. L'un des problèmes majeurs est de ne pas savoir quelle sera la taille d'un format avant de l'avoir évalué. C'est dans la liste des choses à faire.(93)
Voici une stratégie : si vous avez un pied de page de taille fixe, vous pouvez l'afficher en vérifiant $- ($FORMAT_LINES_LEFT) avant chaque write puis afficher le pied de page si nécessaire.
Voici une autre stratégie : ouvrez un tube sur vous-même, en utilisant open(MOIMEME, "|-") (voir l'entrée open au chapitre 29) et faites toujours des write sur MOIMEME au lieu de STDOUT. Le processus fils devra traiter son STDIN après coup pour réarranger ses entêtes et pieds de page à votre guise. Pas très pratique, mais faisable.
7-2-a. Accès au mécanisme interne de formatage▲
Pour accéder au mécanisme interne de formatage, vous pouvez utiliser l'opérateur intégré formline et accéder à $^A (la variable $ACCUMULATOR) directement. Par exemple :
$str = formline <<'END', 1,2,3;
@<<< @||| @>>>
END
print "Wouah, je viens juste de mettre `$^A' dans l'accumulateur !\n";Ou pour créer un sous-programme swrite qui serait à write ce que sprintf est à printf :
use Carp;
sub swrite {
croak "usage: swrite IMAGE ARGS" unless @_;
my $format = shift;
$^A = "";
formline($format, @_);
return $^A;
}
$chaine = swrite(<<'END', 1, 2, 3);
Vérifiez-moi
@<<< @||| @>>>
END
print $chaine;Si vous utilisiez le module FileHandle, vous pourriez utiliser formline comme suit pour passer à la ligne à la colonne 72 :
8. Références▲
Pour des raisons tant philosophiques que pratiques, Perl a toujours favorisé les structures de données plates et linéaires. Et pour beaucoup de problèmes, c'est exactement ce dont vous avez besoin.
Imaginez que vous vouliez construire une table simple (un tableau à deux dimensions) listant certaines informations anthropométriques — âge, couleur des yeux, poids — concernant un groupe de personnes. Vous pourriez faire cela en créant un tableau pour chaque individu :
@john = (47, "marron", 84);
@mary = (23, "noisette", 58);
@bill = (35, "bleu", 71);Vous pourriez ensuite construire un simple tableau supplémentaire contenant les noms des autres tableaux :
@infos = ('john', 'mary', 'bill');Pour changer la couleur des yeux de John en « rouge » après une virée en ville, il nous faut un moyen de changer le contenu de @john à partir de la simple chaîne « john ». C'est le problème classique des indirections, que différents langages résolvent de différentes manières. En C, la forme la plus courante d'indirection est le pointeur, qui permet à une variable de contenir l'adresse en mémoire d'une autre variable. En Perl, la forme la plus courante d'indirection est la référence.
8-1. Qu'est-ce qu'une référence ?▲
Dans notre exemple, $infos[0] contient la valeur « john ». C'est-à-dire qu'il contient une chaîne qui se trouve être le nom d'une autre variable (globale). On dit que la première variable se réfère à la seconde ; cette sorte de référence est appelée symbolique, puisque Perl doit rechercher @john dans une table de symboles pour le retrouver. (Vous pouvez voir les références symboliques comme analogues aux liens symboliques d'un système de fichiers.) Nous parlerons des références symboliques un peu plus loin dans ce chapitre.
L'autre type de références sont les références en dur (hard references), qui constituent ce que les programmeurs Perl utilisent le plus souvent pour accomplir leurs indirections (quand ce ne sont pas leurs indiscrétions). Nous les appelons références en dur non pas parce qu'elles sont compliquées, mais parce qu'elles sont réelles et solides. Si vous préférez, vous pouvez voir les références en dur comme de vraies références et les références symboliques comme de fausses références. C'est un peu comme la différence entre avoir des amis et avoir des relations. Quand nous ne précisons pas de quel type de référence nous parlons, il s'agit de références en dur. La figure 8-1 présente une variable nommée $titi faisant référence au contenu d'une variable nommée $toto qui a la valeur « robot ».
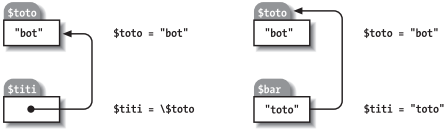
Contrairement aux références symboliques, une vraie référence ne se réfère non pas au nom d'une autre variable (qui n'est que le conteneur d'une valeur), mais à la valeur elle-même, un bout de donnée interne. Il n'y a pas de mot pour décrire cela, mais quand il le faut nous l'appellerons le référent. Supposez par exemple que vous créez une référence en dur vers le tableau à portée lexicale @tableau. Cette référence en dur, et le référent auquel elle se réfère, continueront d'exister même quand @tableau sera hors de portée. Un référent n'est détruit que quand toutes les références qui pointent sur lui ont été éliminées.
Un référent n'a pas vraiment de nom propre, en dehors des références qui s'y réfèrent. Pour le dire d'une autre façon, chaque variable Perl vit dans une sorte de table de symboles, qui contient une référence vers le référent sous-jacent (qui lui n'a pas de nom). Le référent peut être simple, comme un nombre ou une chaîne, ou complexe, comme un tableau ou un hachage. Dans tous les cas, il y a toujours exactement une référence de la variable à sa valeur. Vous pouvez éventuellement créer de nouvelles références en dur vers le même référent, mais si vous le faites, la variable elle-même n'en sait rien (et s'en moque).(94)
Une référence symbolique est juste une chaîne qui se trouve être le nom de quelque chose dans la table des symboles. Ce n'est pas tellement un type distinct, mais plutôt quelque chose que vous faites avec une chaîne. Alors qu'une référence en dur est une créature complètement différente. C'est le troisième des trois types scalaires fondamentaux, les deux autres étant les chaînes et les nombres. Une référence en dur n'a pas besoin de connaître le nom de quelque chose pour pointer dessus, et en fait il est complètement normal qu'il n'y ait pas de nom à utiliser du tout. De tels référents sans nom du tout sont anonymes ; nous en parlons dans la partie Données anonymes ci-dessous.
Référencer une valeur, dans la terminologie de ce chapitre, consiste à créer une référence en dur vers elle. (Il existe un opérateur spécial pour cette action créatrice.) La référence ainsi créée est un simple scalaire, qui se comporte dans les situations usuelles comme n'importe quel autre scalaire. Déréférencer ce scalaire signifie utiliser la référence pour obtenir le référent. Le référencement et le déréférencement se produisent quand vous invoquez des mécanismes explicites ; il ne se produit jamais de référencement ou de déréférencement implicites en Perl. Enfin, presque jamais.
Un appel de fonction peut passer implicitement des références — si elle a un prototype qui la déclare ainsi. Dans ce cas, l'appelant de la fonction ne passe pas explicitement une référence, bien qu'il vous faille toujours déréférencer explicitement celle-ci à l'intérieur de la fonction. Voir la section Prototypes au chapitre 6, Sous-programmes. Et pour être totalement honnête, il se produit aussi des déréférencements en coulisses quand vous utilisez certains types de handles de fichiers. Mais cela relève de la compatibilité antérieure et reste transparent pour l'utilisateur lambda. Finalement, deux fonctions internes, bless et lock, prennent toutes deux une référence en argument, mais la déréférencent implicitement pour faire leurs manipulations sur ce qui se cache derrière. Ces indiscrétions admises, le principe selon lequel Perl n'a pas envie de toucher à vos niveaux d'indirections tient toujours.
Une référence peut pointer sur n'importe quelle structure de données. Comme les références sont des scalaires, vous pouvez les stocker dans des tableaux et des hachages, et ainsi construire des tableaux de tableaux, des tableaux de hachages, des hachages de tableaux, des tableaux de hachages de fonctions, et ainsi de suite. Vous trouverez des exemples de cela dans le chapitre 9, Structures de données.
Gardez cependant à l'esprit que les tableaux et les hachages de Perl sont à une dimension en interne. C'est-à-dire que leurs éléments ne peuvent contenir que des valeurs scalaires (chaînes, nombres et références). Quand nous disons quelque chose comme « tableau de tableaux », nous pensons en fait « tableau de références à des tableaux », tout comme nous pensons « hachage de références à des fonctions » quand nous disons « hachage de fonctions ». Mais comme les références sont la seule façon d'implémenter de telles structures en Perl, il s'ensuit que l'expression plus courte et moins précise n'est tout de même pas fausse, et ne devrait donc pas être totalement dénigrée, à moins que vous ne soyez maniaque.
8-2. Création de références▲
Il existe plusieurs façons de créer des références, dont nous décrirons la plupart avant d'expliquer comment utiliser (déréférencer) les références résultantes.
8-2-a. L'opérateur antislash▲
Vous pouvez créer une référence à une variable nommée ou à un sous-programme grâce à un antislash. (Vous pouvez aussi vous en servir sur une valeur scalaire anonyme comme 7 ou "chameau", bien que cela soit rarement nécessaire.) Cet opérateur fonctionne comme l'opérateur & (adresse de) en C — du moins à première vue.
Voici quelques exemples :
$refscalaire = \$toto;
$refconst = \186_282.42;
$reftableau = \@ARGV;
$refhash = \%ENV;
$refcode = \&handler;
$refglob = \*STDOUT;L'opérateur antislash peut faire bien plus que de créer de simples références. Il créera toute une liste de références s'il est appliqué à une liste. Pour plus de détails, voir la section D'autres tours avec les références en dur.
8-2-b. Données anonymes▲
Dans les exemples que nous venons de vous montrer, l'opérateur antislash se contente de dupliquer une référence qui est déjà contenue dans un nom de variable — avec une exception. Le 186_282.42 n'est référencé par aucune variable — c'est juste une valeur. C'est l'un de ces référents anonymes que nous avons mentionnés précédemment. On ne peut accéder aux référents anonymes qu'à travers des références. Celui-ci est un nombre, mais vous pouvez aussi bien créer des tableaux anonymes, des hachages anonymes et des sous-programmes anonymes.
8-2-b-i. Le composeur de tableaux anonymes▲
Vous pouvez créer une référence à un tableau anonyme en employant des crochets :
$reftableau = [1, 2, ['a', 'b', 'c', 'd']];Ici nous avons construit un tableau anonyme de trois éléments, dont le dernier élément est une référence à un tableau anonyme à quatre éléments (décrit à la figure 8-2). (La syntaxe multidimensionnelle décrite plus loin peut être utilisée pour y accéder. Par exemple, $reftableau->[2][1] aurait la valeur « b ».)
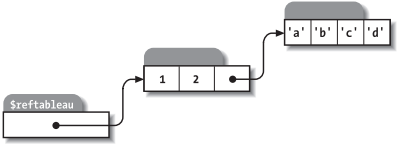
Nous avons maintenant une méthode pour représenter la table du début de ce chapitre :
$table = [ [ "john", 47, "marron", 84],
[ "mary", 23, "noisette", 58],
[ "bill", 35, "bleu", 71] ];Les crochets fonctionnent de cette façon seulement quand l'analyseur de Perl attend un terme dans une expression. Ils ne doivent pas être confondus avec les crochets dans une expression comme $tableau[6] — bien que l'association mnémotechnique avec les tableaux soit volontaire. À l'intérieur d'une chaîne entre guillemets, les crochets ne provoquent pas la création de tableaux anonymes ; ils deviennent simplement des caractères littéraux dans la chaîne. (Les crochets fonctionnent toujours pour l'indexation à l'intérieur de chaînes, sinon vous ne pourriez pas afficher des valeurs comme "VAL=$tableau[6]\n". Et pour être tout à fait honnête, vous pouvez en fait glisser des composeurs de tableaux anonymes dans une chaîne, mais seulement s'ils sont inclus dans une expression plus grande qui est interpolée. Nous parlerons de cette fonctionnalité sympathique un peu plus loin dans ce chapitre, car elle implique du déréférencement aussi bien que du référencement.)
8-2-b-ii. Le composeur de hachages anonymes▲
Vous pouvez créer une référence à un hachage anonyme avec des accolades :
$hashref = {
'Adam' => 'Eve',
'Clyde' => $bonnie,
'Antoine' => 'Cléo' . 'patre',
};Vous pouvez librement mélanger les composeurs d'autres tableaux, hachages ou sous-programmes anonymes pour les valeurs (mais pas pour les clefs) afin de construire une structure aussi compliquée que vous le souhaitez.
Nous avons maintenant une nouvelle manière de représenter la table du début de ce chapitre :
$table = {
"john" => [ 47, "marron", 84 ],
"mary" => [ 23, "noisette", 58 ],
"bill" => [ 35, "bleu", 71 ],
};C'est un hachage de tableaux. Le choix de la meilleure structure est une affaire délicate, et le prochain chapitre y est entièrement dédié. Mais pour vous faire saliver, nous pouvons même utiliser un hachage de hachages pour notre table :
$table = {
"john" => { age => 47,
yeux => "marron",
poids => 84,
},
"mary" => { age => 23,
yeux => "noisette",
poids => 58,
},
"bill" => { age => 35,
yeux => "bleu",
poids => 71,
},
};Comme avec les crochets, les accolades fonctionnent de cette façon uniquement quand Perl attend un terme dans une expression. Il ne faut pas les confondre avec les accolades dans une expression comme $hash{cle} — bien que l'association mnémotechnique soit (encore) volontaire. Les mêmes avertissements s'appliquent quant à l'utilisation des accolades à l'intérieur d'une chaîne.
Voici un avertissement supplémentaire qui ne s'appliquait pas aux crochets. Comme les accolades sont aussi utilisées pour plusieurs autres choses (y compris les blocs), vous pourrez occasionnellement avoir besoin de distinguer les accolades au début d'une instruction en mettant un + ou un return devant, afin que Perl réalise que ce n'est pas un bloc qui commence. Par exemple, si vous voulez une fonction qui crée un nouveau hachage et renvoie une référence sur lui, vous avez les possibilités suivantes :
8-2-b-iii. Le composeur de sous-programmes anonymes▲
Vous pouvez créer une référence à un sous-programme anonyme en utilisant sub sans nom de sous-programme :
$refcode = sub { print "Boink!\n" }; # Maintenant &$refcode affiche
"Boink!"Remarquez la présence du point-virgule, qui est obligatoire pour terminer l'expression. (Il ne le serait pas après la déclaration usuelle subNOM{} qui déclare et définit un sous-programme nommé.) Hormis le fait que le code à l'intérieur n'est pas exécuté immédiatement, un sub {} sans nom est plus un opérateur qu'une déclaration — comme do {} ou eval {}. Il se contente de générer une référence au code, qui dans notre exemple est stockée dans $refcode. Cependant, quel que soit le nombre de fois que vous exécutez la ligne ci-dessus, $refcode se référera toujours au même sous-programme anonyme.(95)
8-2-c. Constructeurs d'objets▲
Les sous-programmes peuvent aussi renvoyer des références. Cela peut sembler banal, mais vous êtes parfois censé vous servir d'un sous-programme pour renvoyer une référence, plutôt que de créer la référence vous-même. En particulier, des sous-programmes spéciaux appelés constructeurs créent et renvoient des références sur des objets. Un objet est juste un type spécial de référence qui sait à quelle classe il est associé ; le et en le transformant en objet grâce à l'opérateur bless (qui signifie « bénir » en anglais), c'est pourquoi nous pouvons parler d'objets comme de références consacrées. Il n'y a rien de religieux dans tout cela ; étant donné qu'une classe fonctionne comme un type défini par l'utilisateur, consacrer un référent en fait un type utilisateur en plus d'un type prédéfini. Les constructeurs sont souvent nommés new — en particulier par les programmeurs C++ —, mais en Perl on peut les appeler comme on veut.
Les constructeurs peuvent être appelés de n'importe laquelle de ces manières :
$refobj = Chien::->new(Queue => 'courte', Oreilles => 'longues'); #1
$refobj = new Chien:: Queue => 'courte', Oreilles => 'longues'; #2
$refobj = Chien->new(Queue => 'courte', Oreilles => 'longues'); #3
$refobj = new Chien Queue => 'courte', Oreilles => 'longues'; #4La première et la deuxième invocations sont identiques. Toutes deux appellent une fonction nommée new qui est fournie par le module Chien. Les troisième et quatrième invocations sont identiques aux deux premières, mais sont légèrement plus ambiguës : l'analyseur va se tromper si vous avez défini votre propre fonction new et que vous n'avez fait ni de require, ni de use, sur le module Chien, chacun des deux ayant pour effet de déclarer le module. Déclarez toujours vos modules si vous voulez utiliser la méthode numéro 4. (Et faites attention aux sous-programmes Chien errants.)
Voir le chapitre 12, Objets, pour une discussion sur les objets Perl.
8-2-d. Références de handles▲
Les références à un handle de fichier ou de répertoire peuvent être créées en prenant une référence à un typeglob de même nom :
bafouille(\*STDOUT);
sub bafouille {
my $fh = shift;
print $fh "heu hum hé bien a hmmm\n";
}
$rec = get_rec(\*STDIN);
sub get_rec {
my $fh = shift;
return scalar <$fh>;
}Si vous faites circuler des handles de fichier, vous pouvez aussi utiliser le typeglob seul pour le faire : dans l'exemple ci-dessus, vous auriez pu utiliser *STDOUT ou *STDIN au lieu de \*STDOUT et \*STDIN.
Bien que vous puissiez en général indifféremment utiliser les typeglobs et les références de typeglob, il y a quelques cas où vous ne pouvez pas. Les typeglobs simples ne peuvent pas être consacrés (avec bless) en objets et les références de typeglobs ne peuvent être passées en dehors de la portée d'un typeglob localisé.
Pour générer de nouveaux handles de fichiers, du code ancien ferait plutôt des choses comme ceci pour ouvrir une liste de fichiers :
for $fichier (@noms) {
local *FH;
open(*FH, $fichier) || next;
$handle{$fichier} = *FH;
}Ça marche encore, mais de nos jours il est aussi facile de laisser une variable non définie s'autovivifier en typeglob anonyme :
Avec les handles de fichiers indirects, que vous utilisiez des typeglobs, des références de typeglob ou l'un des objets d'E/S plus exotiques n'a aucune importance. Vous utilisez simplement un scalaire qui — d'une manière ou d'une autre — sera interprété comme un handle de fichier. Dans la plupart des cas, vous pouvez utiliser un typeglob ou une référence à un typeglob presque aléatoirement. Comme nous l'avons reconnu plus tôt, ce qui se passe ici, c'est la magie du déréférencement implicite.
8-2-e. Références de table de symboles▲
Dans des circonstances inhabituelles, vous pourriez ne pas savoir de quel type de référence vous aurez besoin au moment où vous écrivez votre programme. Une référence peut être créée en utilisant une syntaxe spéciale connue affectueusement sous le nom de syntaxe *foo{THING} (en anglais dans le texte). *toto{CHOSE} (en français dans le texte) retourne une référence à la case CHOSE de *toto, qui est l'entrée de la table de symboles contenant les valeurs de $toto, @toto, %toto et tous leurs amis.
$refscalaire = *toto{SCALAR}; # Même chose que \$toto
$reftableau = *ARGV{ARRAY}; # Même chose que \@ARGV
$refhash = *ENV{HASH}; # Même chose que \%ENV
$refcode = *handler{CODE}; # Même chose que \&handler
$refglob = *toto{GLOB}; # Même chose que \*toto
$refio = *STDIN{IO}; # Euh...Les noms parlent d'eux-mêmes, sauf dans le cas de *STDIN{IO}. Il contient l'objet interne IO::Handle que le typeglob contient, c'est-à-dire la partie du typeglob qui intéresse véritablement les différentes fonctions d'entrée/sortie. Pour assurer la compatibilité avec les anciennes versions de Perl, *toto{FILEHANDLE} est un synonyme de la notation *toto{IO} à la mode.
En théorie, vous pouvez utiliser un *HANDLE{IO} partout où vous auriez utilisé un *HANDLE ou un \*HANDLE, par exemple pour passer des handles à des fonctions ou pour en retourner, ou pour les stocker dans des structures plus grandes. (En pratique il reste encore quelques obstacles à aplanir.) Leur avantage est qu'ils accèdent uniquement au véritable objet d'E/S qui vous intéresse et pas à tout le typeglob, donc vous ne courez pas le risque de défaire plus de choses que vous ne voulez par une affectation de typeglob (mais si vous voulez assigner à une variable scalaire au lieu d'un typeglob, cela ne posera pas de problème). Un des inconvénients est qu'il n'est pas possible d'en autovivifier à l'heure actuelle.(96)
bafouille(*STDOUT);
bafouille(*STDOUT{IO});
sub bafouille {
my $fh = shift;
print $fh "heu hum hé bien a hmmm\n";
}Les deux invocations de bafouille() affichent « heu hum hé bien a hmmm ».
*toto{CHOSE} renvoie undef si cette CHOSE en particulier n'a pas encore été vue par le compilateur, sauf si CHOSE vaut SCALAR. Il se trouve que *toto{SCALAR} renvoie une référence à un scalaire anonyme même si $toto n'a pas encore été vu. (Perl ajoute toujours le scalaire au typeglob pour optimiser un bout de code ailleurs. Mais ne supposez pas que cela restera ainsi dans les prochaines versions.)
8-2-f. Création implicite de références▲
Une dernière méthode de création de références n'en est pas vraiment une. Les références d'un certain type se mettent simplement à exister quand vous les déréférencez dans un contexte de lvalue qui suppose qu'elles existent. Cela est extrêmement utile, et c'est aussi Ce à Quoi On s'Attend. Ce sujet est traité plus loin dans ce chapitre, quand nous verrons comment déréférencer toutes les références que nous avons créées jusqu'ici.
8-3. Utilisation des références en dur▲
Tout comme il existe de nombreuses manières de créer des références, il existe également plusieurs manières d'utiliser, ou de déréférencer une référence. Il existe un seul principe supérieur : Perl ne fait pas de référencement ou de déréférencement implicite.(97) Quand un scalaire contient une référence, il se comporte comme un simple scalaire. Il ne devient pas magiquement un tableau ou un hachage ou un sous-programme ; vous devez lui signifier explicitement de le faire, en le déréférençant.
8-3-a. Emploi d'une variable comme nom de variable▲
Quand vous rencontrez un scalaire comme $toto, vous devriez penser « la valeur scalaire associée à toto ». C'est-à-dire qu'il y a une entrée toto dans la table des symboles et que le drôle de caractère $ est une manière de regarder quelle valeur scalaire se trouve à l'intérieur. Si ce qui se trouve à l'intérieur est une référence, vous pouvez regarder à l'intérieur de cette référence (déréférencer $toto en le faisant précéder d'un autre drôle de caractère. Ou en le regardant du point de vue opposé, vous pouvez remplacer le toto littéral dans $toto par une variable scalaire qui pointe sur le véritable référent. Cela est vrai pour tout type de variable, donc non seulement $$toto est la valeur scalaire de ce à quoi $toto se réfère, mais @$titi est la valeur tableau de ce à quoi $titi se réfère, %$tutu est la valeur hachage de ce à quoi $tutu se réfère, et ainsi de suite. Le résultat est que vous pouvez rajouter un drôle de caractère devant n'importe quelle valeur scalaire pour la déréférencer :
$toto = "trois bosses";
$refscalaire = \$toto; # $refscalaire est maintenant une
# référence à $toto
$type_chameau = $$refscalaire; # $type_chameau vaut maintenant "trois
# bosses"Voici d'autres déréférences :
$titi = $$refscalaire;
push(@$reftableau, $fichier);
$$reftableau[0] = "Janvier"; # Affecte le premier élément
# de @$reftableau
@$reftableau[4..6] = qw/Mai Juin Juillet/; # Affecte plusieurs éléments
# de @$reftableau
%$refhash = (CLE => "TROUSSEAU", OISEAU => "SIFFLER"); # Initialise tout
# le hash
$$refhash{CLE} = "VALEUR"; # Change un couple clef/valeur
@$refhash{"CLE1","CLE2"} = ("VAL1","VAL2"); # Ajoute deux nouveaux couples
&$refcode(1,2,3);
print $refhandle "sortie\n";Cette forme de déréférencement ne peut utiliser qu'une variable simple (sans indice). C'est-à-dire que le déréférencement se produit avant (ou lie plus fort que) toute recherche dans un tableau ou un hachage. Utilisons des accolades pour clarifier notre pensée : une expression comme $$reftableau[0] est équivalente à ${$reftableau}[0] et signifie le premier élément du tableau référencé par $reftableau. Ce n'est pas du tout la même chose que ${$reftableau[0]} qui déréférence le premier élément du tableau nommé @reftableau (et qui n'existe probablement pas). De même, $$refhash{CLE} est équivalent à ${$refhash}{CLE} et n'a rien à voir avec ${$refhash{CLE}} qui déréférencerait une entrée du hachage nommé %refhash (qui n'existe probablement pas). Vous serez malheureux tant que vous n'aurez pas compris cela.
Vous pouvez réaliser plusieurs niveaux de référencement et de déréférencement en concaténant les drôles de caractères de façon appropriée. Ce qui suit affiche « salut » :
$refrefref = \\\"salut";
print $$$$refrefref;Vous pouvez voir les dollars comme opérant de droite à gauche. Mais le début de la chaîne doit toujours être un simple scalaire sans indice. Il existe cependant une technique qui met un peu plus de fantaisie, que nous avons déjà subrepticement utilisée un peu plus tôt, et que nous allons expliquer dans la section suivante.
8-3-b. Emploi d'un BLOC comme nom de variable▲
Non seulement vous pouvez déréférencer un simple nom de variable, mais vous pouvez aussi déréférencer le contenu d'un BLOC. Partout où vous mettriez un identificateur comme partie d'une variable ou d'un nom de sous-programme, vous pouvez remplacer l'identificateur par un BLOC qui renvoie une référence du bon type. En d'autres termes, tous les exemples précédents peuvent être clarifiés comme suit :
$titi = ${$refscalaire};
push(@{$reftableau}, $fichier);
${$reftableau}[0] = "Janvier";
@{$reftableau}[4..6] = qw/Mai Juin Juillet/;
${$refhash}{"CLE"} = "VALEUR";
@{$refhash}{"CLE1","CLE2"} = ("VAL1","VAL2");
&{$refcode}(1,2,3);sans oublier :
$refrefref = \\\"salut";
print ${${${$refrefref}}};Nous sommes d'accord qu'il est idiot de mettre des accolades dans des cas aussi simples, mais le BLOC peut contenir n'importe quelle expression. En particulier, il peut contenir une expression avec des indices. Dans l'exemple suivant, on suppose que $dispatch{$index}} contient une référence à un sous-programme (parfois appelé « coderef »). L'exemple appelle le sous-programme avec trois arguments.
&{ $dispatch{$index} }(1, 2, 3);Ici le BLOC est indispensable. Sans le couple d'accolades extérieures, Perl aurait traité $dispatch comme le coderef à la place de $dispatch{$index}.
8-3-c. Emploi de l'opérateur flèche▲
Dans le cas de hachages, de tableaux ou de sous-programmes, une troisième méthode de déréférencement implique l'utilisation de l'opérateur infixe ->. Cette forme de « sucre syntaxique » facilite l'accès à un élément individuel d'un tableau ou d'un hachage, ainsi que l'appel indirect à un sous-programme.
Le type de déréférencement est déterminé par l'opérande de droite, c'est-à-dire par ce qui suit directement la flèche. Si ce qui suit la flèche est un crochet ou une accolade, l'opérande de gauche est traité respectivement comme une référence à un tableau ou un hachage, indexé par l'expression à droite. Si ce qui suit est une parenthèse ouvrante, l'opérande de gauche est traité comme un sous-programme à appeler avec les paramètres fournis entre les parenthèses à droite.
Chacun des trios qui suivent est équivalent et correspond aux trois notations que nous avons présentées. (Nous avons rajouté des espaces pour que les éléments qui se correspondent soient alignés.)
$ $reftableau [2] = "Dorian"; #1
${ $reftableau }[2] = "Dorian"; #2
$reftableau->[2] = "Dorian"; #3
$ $refhash {TON} = "Fa#majeur"; #1
${ $refhash }{TON} = "Fa#majeur"; #2
$refhash->{TON} = "Fa#majeur"; #3
& $refcode (Presto => 192); #1
&{ $refcode }(Presto => 192); #2
$refcode->(Presto => 192); #3Vous pouvez voir que le premier drôle de caractère manque dans la troisième notation de chaque série. Le drôle de caractère est deviné par Perl, ce qui fait que cette notation ne peut servir pour déréférencer des tableaux ou des hachages entiers, ni même des tranches de ceux-ci. Cependant, tant que vous vous en tenez à des valeurs scalaires, vous pouvez utiliser n'importe quelle expression à gauche de ->, y compris un autre déréférencement, car plusieurs opérateurs flèches s'associent de gauche à droite :
print $tableau[3]->{"Anglais"}->[0];Vous pouvez déduire de cette expression que le quatrième élément de @tableau est supposé être une référence à un hachage, et que la valeur associée à l'entrée « Anglais » de ce hachage est supposée être une référence à un tableau.
Remarquez que $tableau[3] et $tableau->[3] ne sont pas les mêmes. Le premier donne le quatrième élément de @tableau, tandis que le second donne le quatrième élément du tableau (peut-être anonyme) dont la référence se trouve dans $tableau.
Supposez maintenant que $tableau[3] soit indéfini. L'instruction suivante est toujours légale :
$tableau[3]->{"Anglais"}->[0] = "January";C'est l'un des cas que nous avons mentionnés précédemment où les références se mettent à exister (ou sont « autovivifiées ») quand on les utilise comme des lvalues (c'est-à-dire quand une valeur leur est affectée). Si $tableau[3] était indéfini, il est automatiquement défini comme une référence à un hachage afin que nous puissions affecter une valeur à $tableau[3]->{"Anglais"} à l'intérieur. Une fois que c'est fait, $tableau[3]>{"Anglais"} est automatiquement défini comme une référence à un tableau, afin que nous puissions affecter une valeur au premier élément de ce tableau. Remarquez que les rvalues (les valeurs à droite d'une affectation) sont légèrement différentes : print $tableau[3]->{"Anglais"}->[0] ne crée que $tableau[3] et $tableau[3]->{"Anglais"}, et pas $tableau[3]->{"Anglais"}->[0], puisque le dernier élément n'est pas une lvalue. (Le fait que cela définisse les deux premiers dans un contexte de rvalue devrait être considéré comme une bogue. Nous corrigerons peut-être cela un jour.)
La f lèche est optionnelle entre les indices délimités par des accolades ou des crochets, et entre une accolade ou un crochet fermant et une parenthèse destinée à un appel de fonction indirect. Vous pouvez donc réduire le code précédent à :
$dispatch{$index}(1, 2, 3);
$tableau[3]{"Anglais"}[0] = "January";Dans le cas des tableaux ordinaires, cela vous permet d'avoir des tableaux multidimensionnels exactement comme ceux de C :
$reponse[$x][$y][$z] += 42;Bon d'accord, pas exactement comme ceux de C. D'abord C ne sait pas comment faire grossir ses tableaux à la demande, comme Perl. Ensuite certaines constructions similaires dans les deux langages sont analysées différemment. En Perl, les deux instructions suivantes font la même chose :
$refliste->[2][2] = "coucou"; # Assez clair
$$refliste[2][2] = "coucou"; # Prête à confusionLa seconde instruction peut choquer le programmeur C, qui est habitué à utiliser *a[i] pour signifier « ce qui est pointé par le ie élément de a ». Mais en Perl, les cinq caractères ($@*%&) lient plus étroitement que les accolades ou les crochets.(98) C'est donc $$refliste et non $refliste[2] qui est pris comme référence à un tableau. Si vous voulez le comportement de C, soit vous devez écrire ${$refliste[2]} pour forcer l'évaluation de $refliste[2] avant le premier $ déréférenceur, ou bien utiliser la notation -> :
$refliste[2]->[$salutation] = "coucou";8-3-d. Emploi des méthodes d'objets▲
Si une référence se trouve être une référence à un objet, alors la classe qui définit cet objet fournit probablement des méthodes pour accéder à ce qu'il contient, et vous devriez généralement vous en tenir à ces méthodes si vous ne faites qu'utiliser la classe (par opposition à ceux qui l'implémentent). En d'autres termes, soyez correct et ne traitez pas un objet comme une simple référence, bien que Perl vous laisse faire si vous le devez vraiment. Perl n'impose pas l'encapsulation. Nous ne sommes pas des dictateurs. Mais nous espérons cependant un peu de civilité de votre part.
En retour de cette civilité, vous gagnez une complète orthogonalité entre les objets et les structures de données. Toute structure de données peut se comporter comme un objet, si vous le voulez. Et ne pas le faire, si vous ne voulez pas.
8-3-e. Pseudo-hachages▲
Un pseudo-hachage est une référence à un tableau dont le premier élément est une référence à un hachage. Vous pouvez traiter le pseudo-hachage soit comme une référence de tableau (comme vous pouviez vous y attendre) ou comme une référence de hachage (ce à quoi vous ne vous attendiez peut-être pas). Voici un exemple de pseudo-hachage :
$john = [ {age => 1, yeux => 2, poids => 3}, 47, "marron", 84 ];Le hachage sous-jacent dans $john->[0] définit les noms "age", "yeux" et "poids" des éléments de tableau qui suivent (47, "marron" et 84). Maintenant vous pouvez accéder à un élément à la fois par la notation de hachage et par celle de tableau :
$john->{poids} # Traite $john comme une référence de hachage
$john->[3] # Traite $john comme une référence de tableauLa magie des pseudo-hachages n'est pas très puissante ; ils ne connaissent qu'un seul « tour » : comment transformer un déréférencement de hachage en déréférencement de tableau. Quand vous ajoutez un nouvel élément au pseudo-hachage, vous devez explicitement préciser au hachage de correspondance sous-jacent où l'élément va résider avant d'utiliser la notation de hachage :
$john->[0]{hauteur} = 4; # hauteur sera l'élément 4
$john->{hauteur} = "grand"; # Ou $john->[4] = "grand"Perl lève une exception si vous essayez d'effacer une clef de pseudo-hachage, bien que vous puissiez toujours effacer une clef du hachage de correspondance. Perl lève également une exception si vous essayez d'accéder à une clef qui n'existe pas (« existence » signifiant ici « présence dans le hachage de correspondance »).
delete $john->[0]{hauteur}; # Supprime seulement dans le hachage
# sous-jacent
$john->{hauteur}; # Ceci lève désormais une exception
$john->[4]; # Affiche toujours "grand"Ne tentez pas de splice du tableau sans savoir ce que vous faites. Si les éléments du tableau se déplacent, les valeurs de correspondance du hachage feront toujours référence aux anciennes positions des éléments, à moins que vous ne les changiez elles aussi explicitement. La magie des pseudo-hachages n'est pas très puissante.
Pour éviter les incohérences, vous pouvez utiliser la fonction fields::phash fournie par le pragma use fields pour créer un pseudo-hachage :
use fields;
$ph = fields::phash(age => 47, yeux => "marron", poids => 84);
print $ph->{age};Il existe deux manières de vérifier l'existence d'une clef dans un pseudo-hachage. La première est d'utiliser exists, qui vérifie si le champ fourni a jamais été affecté. Il fonctionne de cette façon pour reproduire le comportement d'un véritable hachage. Par exemple :
use fields;
$ph= fields::phash([qw(age yeux poids)], [47]);
$ph->{yeux} = undef;
print exists $ph->{age}; # Vrai, 'age' a été modifié dans la déclaration.
print exists $ph->{poids}; # Faux, 'poids' n'a pas été utilisé.
print exists $ph->{yeux}; # Vrai, les 'yeux' ont été modifiés.La seconde manière est d'utiliser exists sur le hachage de correspondance installé dans le premier élément. Ceci vérifie que la clef donnée est un champ valide pour ce pseudohachage :
print exists $ph->[0]{age}; # Vrai, 'age' est un champ valide
print exists $ph->[0]{nom}; # Faux, 'nom' ne peut pas être utiliséContrairement à ce qui se produit pour un véritable hachage, appeler delete sur un élément de pseudo-hachage n'efface que la valeur dans le tableau, et pas la clef dans le hachage de correspondance. Pour effacer la clef, vous devrez l'effacer explicitement du hachage de correspondance. Une fois que cela est fait, vous ne pouvez plus utiliser ce nom de clef comme indice du pseudo-hachage :
print delete $ph->{age}; # Détruit $ph->[1],
print exists $ph->{age}; # Maintenant c'est f
print exists $ph->[0]{age}; # Vrai, 'age' est encore utilisable
print delete $ph->[0]{age}; # Maintenant 'age' n'existe plus
print $ph->{age}; # Exception à l'exécutionVous commencez sûrement à vous demander ce qui a pu motiver ce carnaval de tableaux se promenant dans un habit de hachage. Les tableaux fournissent un accès plus rapide et un stockage plus efficace, tandis que les hachages offrent la possibilité de nommer (au lieu de numéroter) vos données ; les pseudo-hachages offrent le meilleur des deux mondes. Mais c'est en considérant la phase de compilation de Perl que vous verrez apparaître le meilleur bénéfice de l'opération. Avec l'aide d'un pragma ou deux, le compilateur peut vérifier l'accès correct aux champs valides, aussi pouvez-vous vérifier l'inexistence d'un champ (ou les fautes d'orthographe) avant le début de votre programme.
Les propriétés de vitesse, d'efficacité, de vérification d'accès à la compilation (vous pouvez même le voir comme de la validation de type) sont particulièrement pratiques pour créer des modules de classes robustes et efficaces. Voir la discussion du pragma use fields au chapitre 12 et au chapitre 31, Modules de pragmas.
Les pseudo-hachages sont une fonctionnalité nouvelle et relativement expérimentale ; en tant que telle, l'implémentation en interne est susceptible de changer à l'avenir. Afin de vous protéger de tels changements, utilisez toujours l'interface documentée du module fields, en utilisant ses fonctions phash et new.
8-3-f. D'autres tours avec les références en dur▲
Comme mentionné précédemment, l'opérateur antislash est en général utilisé sur un seul référent pour générer une référence unique, mais ce n'est pas obligatoire. Quand il est utilisé sur une liste de référents, il produit une liste de références correspondantes. La seconde ligne de l'exemple suivant produit exactement le même resultat que la première, car l'antislash est automatiquement distribué sur toute la liste.
@listeref = (\$s, \@a, \%h, \&f); # Liste de quatre références
@listeref = \($s, @a %h, &f); # Même choseSi une expression entre parenthèses contient exactement un tableau ou un hachage, toutes ses valeurs sont interpolées et des références sont renvoyées pour chacune :
@listeref = \(@x); # Interpole le tableau puis prend
# les références
@listeref = map { \$_ } @x; # Même choseCela se produit également quand il y a des parenthèses à l'intérieur :
@listeref = \(@x, (@y)); # Seuls les agrégats simples sont
# interpolés
@listeref = (\@x, map { \$_ } @y); # Même choseSi vous essayez cela avec un hachage, le résultat contiendra des références aux valeurs (comme vous vous y attendez), mais aussi des références à des copies des clefs (comme vous en vous y attendez peut-être pas).
Comme les tranches de tableaux et de hachages sont seulement des listes, vous pouvez antislasher des tranches de l'un ou l'autre type pour obtenir une liste de références. Chacune des trois listes suivantes fait exactement la même chose :
@envrefs = \@ENV{'HOME', 'TERM'}; # Antislashe une tranche
@envrefs = \( $ENV{HOME}, $ENV{TERM} ); # Antislashe une liste
@envrefs = ( \$ENV{HOME}, \$ENV{TERM} ); # Une liste de deux référencesComme les fonctions peuvent retourner des listes, vous pouvez leur appliquer l'opérateur antislash. Si vous avez plusieurs appels de fonction, interpolez d'abord la valeur de retour de chaque fonction dans une liste plus grande avant d'antislasher l'ensemble :
@listeref = \fx();
@listeref = map { \$_ } fx(); # Même chose
@listeref = \( fx(), fy(), fz() );
@listeref = ( \fx(), \fy(), \fz() ); # Même chose
@listeref = map { \$_ } fx(), fy(), fz(); # Même choseComme l'opérateur antislash fourni un contexte de liste à ses opérandes, ces fonctions sont toutes appelées en contexte de liste. Si l'antislash est lui-même en contexte scalaire, vous finirez avec une référence à la dernière valeur de la liste renvoyée par la fonction :
@listeref = \localtime(); # Ref à chacun des neuf éléments de la date
$reffinale = \localtime(); # Ref à l'indicateur de l'heure d'étéÀ cet égard, l'opérateur antislash se comporte comme les opérateurs de liste nommés, comme print, reverse et sort, qui fournissent toujours un contexte de liste à leur droite, quoiqu'il se passe à leur gauche. Comme avec les opérateurs de liste nommés, utilisez un scalar explicite pour forcer ce qui suit à être en contexte de liste :
$refdate = \scalar localtime(); # \"Thu Jul 26 11:37:38 2001"Vous pouvez vous servir de l'opérateur ref pour déterminer vers quoi une référence pointe. Vous pouvez voir l'opérateur ref comme un opérateur « typeof » qui renvoie vrai si son argument est une référence et faux dans le cas contraire. La valeur renvoyée dépend du type de chose référencée. Les types prédéfinis comprennent SCALAR, ARRAY, HASH, CODE, GLOB, REF, LVALUE, IO, IO::Handle et Regexp. Ici, nous nous en servons pour valider les arguments d'un sous-programme :
sub somme {
my $reftableau = shift;
warn "Ce n'est pas une référence de tableau"
if ref($reftableau) ne "ARRAY";
return eval join("+", @$reftableau);
}Si vous utilisez une référence en dur dans un contexte de chaîne, elle sera convertie en une chaîne contenant le type et l'adresse : SCALAR(0x1fc0e). (La conversion inverse ne peut pas être faite, puisque l'information de décompte de références est perdue pendant l'opération de conversion en chaîne — et aussi, car il serait dangereux de laisser des programmes accéder à une adresse mémoire donnée par une chaîne arbitraire.)
Vous pouvez utiliser l'opérateur bless pour associer un référent à un paquetage fonctionnant comme une classe d'objet. Quand vous faites cela, ref renvoie le nom de la classe au lieu du type interne. Une référence d'objet utilisée en contexte de chaîne renvoie une chaîne avec les types interne et externe, ainsi que l'adresse en mémoire : MonType=HASH(0x20d10) ou IO::Handle=IO(0x186904). Pour plus de détails sur les objets, voir le chapitre 12.
Puisque le type de référent que vous désirez est indiqué par la façon dont vous le déréférencez, un typeglob peut être utilisé de la même façon qu'une référence, malgré le fait qu'un référent contienne plusieurs référents de types divers. ${*main::toto} et ${\$main::toto} accèdent donc tous deux à la même variable scalaire, même si le second est plus efficace.
Voici une astuce pour interpoler la valeur de retour d'un appel de fonction dans une chaîne :
print "Ma fonction a renvoyé @{[ mafonction(1,2,3) ]} cette fois.\n";Voici comment cela fonctionne. À la compilation, quand le @{...} est vu à l'intérieur de la chaîne entre guillemets doubles, il est analysé comme un bloc qui renvoie une référence. À l'intérieur du bloc, les crochets créent une référence à un tableau anonyme à partir de ce qui se trouve entre eux. À l'exécution, mafonction(1,2,3) est donc appelée en contexte de liste, et les résultats sont chargés dans un tableau anonyme dont une référence est renvoyée à l'intérieur du bloc. Cette référence de tableau est immédiatement déréférencée par le @{...} qui l'entoure, et la valeur de tableau est interpolée dans la chaîne à doubles guillemets tout comme un tableau ordinaire le serait. Ce stratagème s'avère également utile pour des expressions quelconques, comme :
print "Il nous faut @{ [$n + 5] } machins !\n";Cependant faites attention : les crochets fournissent un contexte de liste à leur expression. Dans ce cas, cela n'a aucune importance, mais l'appel précédent à mafonction aurait pu y être sensible. Quand il le faut, utilisez un scalar explicite pour forcer le contexte :
print "mafonction renvoie @{ [scalar mafonction(1,2,3)] } maintenant.\n";8-3-g. Fermetures▲
Nous avons parlé plus haut de la création de sous-programmes anonymes avec un sub {} sans nom. Vous pouvez voir ces sous-programmes comme s'ils étaient définis à l'exécution, ce qui signifie qu'ils ont un instant de génération en plus d'une position de définition. Certaines variables pourraient être à portée quand le sous-programme est créé, et d'autres variables pourraient être à portée quand le sous-programme est appelé.
Oubliez les sous-programmes pour le moment et considérez une référence qui se réfère à une variable lexicale :
{
my $bestiau = "chameau";
$refbestiau = \$creature;
}La valeur de $$refbestiau restera « chameau » bien que $bestiau disparaisse après l'accolade fermante. Mais $refbestiau aurait très bien pu faire référence à un sous-programme qui se réfère à $bestiau :
C'est une fermeture, qui est une notion sortie du monde de la programmation fonctionnelle de LISP et Scheme.(99) Cela signifie que quand vous définissez un sous-programme anonyme dans une portée lexicale particulière à un moment donné, il prétend continuer à fonctionner dans cette portée particulière, même si vous l'appelez plus tard depuis l'extérieur de cette portée. (Un puriste dirait qu'il n'a pas besoin de prétendre — il fonctionne réellement dans cette portée.)
En d'autres termes, vous êtes assuré de garder la même copie d'une variable lexicale à chaque fois, même si d'autres instances de cette variable lexicale ont été créées avant ou après pour d'autres instances de cette fermeture. Cela vous permet d'ajuster les valeurs utilisées par un sous-programme quand vous le définissez, et pas seulement quand vous l'appelez.
Vous pouvez aussi voir les fermetures comme une manière d'écrire un patron de sous-programme sans utiliser eval. Les variables lexicales servent de paramètres pour remplir le modèle, ce qui est utile pour configurer des petits bouts de code à exécuter plus tard. On les appelle communément des fonctions de rappel en programmation événementielle, quand vous associez un bout de code à la pression d'une touche, à un clic de souris, à l'exposition d'une fenêtre et ainsi de suite. Quand on les utilise comme des fonctions de rappel, les fermetures font exactement ce à quoi vous vous attendez, même si vous ne connaissez rien à la programmation fonctionnelle. (Remarquez que cette histoire de fermeture ne s'applique qu'aux variables my. Les variables globales fonctionnent comme elles ont toujours fonctionné, étant créées et détruites de façon complètement différente des variables lexicales.
Une autre utilisation des fermetures se fait à l'intérieur de générateurs de fonctions ; c'est-à-dire de fonctions qui créent et retournent de nouvelles fonctions. Voici un exemple de générateur de fonction implémenté avec des fermetures :
sub faitbonjour {
my $salut = shift;
my $newfunc = sub {
my $cible = shift;
print "$salut, $cible !\n";
};
return $newfunc; # Renvoie une fermeture
}
$f = faitbonjour("Bonjour"); # Crée une fermeture
$g = faitbonjour("Salutations"); # Crée une autre fermeture
# Le temps passe...
$f->("monde");
$g->("Terriens");Cela affiche :
Bonjour, monde !
Salutations, Terriens !Remarquez en particulier comme $salut continue de faire référence à la valeur effectivement passée à faitbonjour, malgré le fait que le my $salut soit hors de portée quand le sous-programme anonyme tourne. C'est tout l'intérêt des fermetures. Comme $f et $g contiennent des références à des fonctions qui, quand on les appelle, ont toujours besoin d'accéder à des versions distinctes de $salut, ces versions restent automatiquement dans les environs. Si maintenant vous effacez $f, sa version de $salut disparaîtra automatiquement. (Perl nettoie quand vous avez le dos tourné.)
Perl ne fournit pas de références aux méthodes d'objets (décrites au chapitre 12), mais vous pouvez obtenir un effet similaire en utilisant une fermeture. Supposons que vous voulez une référence, pas seulement à la fonction que la méthode représente, mais aussi une référence qui, quand vous l'invoquez, appelle cette méthode sur un objet particulier. Vous pouvez commodément vous souvenir à la fois de l'objet et de la méthode en en faisant des variables lexicales liées à une fermeture :
sub get_ref_methode {
my ($self, $nommethode) = @_;
my $refmeth = sub {
# le @_ ci-dessous est différent de celui au-dessus !
return $self->$nommethode(@_);
};
return $refmeth;
}
my $toutou = new Chien::
Nom => "Lucky",
Pattes => 3,
Queue => "coupée";
our $remueur = get_ref_methode($toutou, 'remuer');
$remueur->("queue"); # Appelle $dog->remuer('queue').Vous pouvez donc demander à Lucky de remuer ce qui lui reste de queue même quand la variable lexicale $toutou est hors de portée et que Lucky n'est plus visible. La variable globale $remueur peut toujours lui faire remuer la queue, où qu'il se trouve.
8-3-g-i. Fermetures comme modèles de fonctions▲
Utiliser une fermeture comme modèle de fonctions vous permet de générer plusieurs fonctions qui agissent de façon similaire. Supposons que vous voulez une suite de fonctions qui génèrent des changements de fonte HTML pour diverses couleurs :
print "Soyez ", rouge("prudent"), "avec cette ", vert("lumière"), " !!!";Les fonctions rouge et vert seraient très similaires. Nous aimerions bien nommer nos fonctions, mais les fermetures n'ont pas de nom puisqu'il s'agit juste de routines qui s'y croient. Pour contourner cela, nous allons utiliser une jolie astuce pour nommer nos sous-programmes anonymes. Vous pouvez lier une référence de code à un nom existant en l'affectant au typeglob du nom de la fonction que vous voulez. (Voir la section Tables de symboles au chapitre 10, Paquetages). Dans ce cas, nous allons la lier à deux noms différents, l'un en majuscules et l'autre en minuscules :
@couleurs = qw(red blue green yellow orange purple violet);
for my $nom (@couleurs) {
no strict 'refs'; # Autorise les références symboliques
*$nom = *{uc $nom} = sub { "<FONT COLOR='$nom'>;@_</FONT>" };
}Vous pouvez maintenant appeler les fonctions nommées red, RED, blue, BLUE et ainsi de suite, et la fermeture appropriée sera invoquée. Cette technique réduit la durée de compilation et conserve la mémoire ; elle est aussi moins susceptible d'erreur, puisque la vérification de syntaxe se fait à la compilation. Il est impératif que les variables dans le sous-programme anonyme soient lexicales afin de créer une fermeture. C'est la raison du my dans l'exemple ci-dessus.
Voici l'un des rares cas où donner un prototype à une fermeture sert à quelque chose. Si vous aviez voulu imposer un contexte scalaire aux arguments de ces fonctions (ce n'est probablement pas une bonne idée pour cet exemple), vous auriez plutôt écrit ceci :
*$nom = sub ($) { "<FONT COLOR='$nom'>$_[0]</FONT>" };C'est presque suffisant. Cependant comme la vérification de prototypes se produit à la compilation, l'affectation à l'exécution se produit trop tard pour servir à quelque chose. Vous pouvez corriger cela en mettant toute la boucle d'affectations dans un bloc BEGIN qui la forcera à se produire à la compilation. (Plus probablement, vous la mettriez dans un module sur lequel vous ferez un use à la compilation.) Les prototypes seront alors visibles pour le reste de la compilation.
8-3-g-ii. Sous-programmes emboîtés▲
Si vous avez l'habitude (prise dans d'autres langages de programmation) d'utiliser des procédures emboîtées dans d'autres procédures, chacune avec ses propres variables privées, il va vous falloir travailler un peu en Perl. Les sous-programmes nommés ne s'emboîtent pas bien, alors que les sous-programmes anonymes le peuvent.(100) De toute façon, nous pouvons émuler des sous-programmes emboîtés à portée lexicale à l'aide de fermetures. En voici un exemple :
sub exterieur {
my $x = $_[0] + 35;
local *interieur = sub { return $x * 19 };
return $x + interieur();
}Maintenant interieur ne peut être appelé que depuis exterieur à cause de l'affectation temporaire de la fermeture. Mais quand il l'est, il a accès normalement à la variable lexicale $x depuis la portée de exterieur.
Ceci a l'intéressant effet de créer une fonction locale à une autre, ce qui est quelque chose qui n'est normalement pas supporté en Perl. Comme local est à portée dynamique, et parce que les noms de fonctions sont globaux à leur paquetage, toute autre fonction qui serait appelée par exterieur pourrait aussi appeler la version temporaire d'interieur. Pour empêcher cela, il vous faudra un niveau supplémentaire d'indirection :
8-4. Références symboliques▲
Que se passe-t-il si vous essayez de déréférencer une valeur qui n'est pas une référence en dur ? La valeur est alors traitée comme une référence symbolique. C'est-à-dire que la référence est interprétée comme une chaîne représentant le nom d'une variable globale.
Voici comment cela fonctionne :
$nom = "bam";
$$nom = 1; # Définit $bam
$nom->[0] = 4; # Définit le premier élément de @bam
$nom->{X} = "Y"; # Définit l'élément X de %bam à Y
@$nom = (); # Vide @bam
keys %$nom; # Renvoie les clefs de %bam
&$nom; # Appelle &bamC'est très puissant et légèrement dangereux, en ce qu'il est possible de vouloir (avec la plus grande sincérité) utiliser une référence en dur, mais d'accidentellement utiliser une référence symbolique à la place. Pour vous protéger contre cela, vous pouvez écrire :
et seules les références en dur seront autorisées dans le reste du bloc englobant. Un bloc intérieur peut suspendre cette restriction par :
Il est aussi important de comprendre la différence entre les deux lignes de code suivantes :
${identificateur}; # Comme $identificateur.
${"identificateur"}; # $identificateur aussi, mais une référence symbolique.Parce que la seconde forme est entre guillemets, elle est traitée comme une référence symbolique, et générera une erreur avec use strict 'refs'. Même si use strict 'refs' n'est pas activé, elle peut seulement faire référence à une variable de paquetage. Mais la première forme est identique à la forme sans accolades, et fera même référence à une variable à portée lexicale s'il y en a de déclarée. L'exemple suivant le montre (et la section suivante en parle).
Seules les variables de paquetage sont accessibles par des références symboliques, car les références symboliques passent toujours par la table de symboles du paquetage. Comme les variables lexicales ne se trouvent pas la table de symboles, elles sont invisibles pour ce mécanisme. Par exemple :
our $valeur = "globale";
{
my $valeur = "privée";
print "À l'intérieur, my est ${valeur}, ";
print "mais our est ${'valeur'}.\n";
}
print "À l'extérieur, ${valeur} est de nouveau ${'valeur'}.\n";ce qui affiche :
À l'intérieur, my est privée, mais our est globale.
À l'extérieur, globale est de nouveau globale.8-5. Accolades, crochets et guillemets▲
Dans la section précédente nous avons vu que ${identificateur} n'est pas traité comme une référence symbolique. Vous vous demandez sûrement comment cela peut interagir avec les mots réservés. La réponse est que cela n'interagit pas. Bien que push soit un mot réservé, ces deux instructions affichent « pop par dessus »:
$push = "pop par ";
print "${push}dessus";La raison en est qu'historiquement, cette utilisation des accolades est celle des shells Unix pour isoler un nom de variable du texte alphanumérique qui le suit, et qui aurait sinon été interprété comme faisant partie du nom. C'est la façon dont beaucoup de gens s'attendent à voir fonctionner l'interpolation, aussi l'avons-nous fait fonctionner de la même façon en Perl. Mais en Perl cette notion s'étend plus loin, et s'applique également aux accolades utilisées pour générer les références, qu'elles soient ou non entre guillemets. Cela signifie que :
print ${push} . 'dessus';ou même (puisque les blancs ne changent rien) :
print ${ push } . 'dessus';affichent tous deux « pop par dessus », même si les accolades sont en dehors des guillemets doubles. La même règle s'applique à tout identificateur utilisé pour indexer un hachage. Ainsi, au lieu d'écrire :
$hash{ "aaa" }{ "bbb" }{ "ccc" }vous pouvez simplement écrire :
$hash{ aaa }{ bbb }{ ccc }ou :
$hash{aaa}{bbb}{ccc}sans vous soucier de savoir si les indices sont des mots réservés. Donc ceci :
$hash{ shift }est interprété comme $hash{"shift"}. Vous pouvez forcer l'interprétation comme un mot réservé en ajoutant quelque chose qui le différencie d'un identificateur :
$hash{ shift() } $hash{ +shift } $hash{ shift @_ }8-5-a. Les références ne fonctionnent pas comme clefs de hachages▲
Les clefs de hachage sont stockées en interne comme des chaînes.(101) Si vous essayez de stocker une référence dans un hachage, la valeur de la clef sera convertie en chaîne :
$x{ \$a}=$a;
($cle, $valeur) = each %x;
print $$cle; # FAUXNous avons mentionné plus tôt que vous ne pouvez pas reconvertir une chaîne en référence en dur. Si vous essayez de déréférencer $cle qui contient une simple chaîne, vous ne récupérerez pas une référence en dur, mais simplement un déréférencement symbolique. Et comme vous n'avez pas de variable nommée SCALAR(0x1fc0e), vous n'obtiendrez pas ce que vous voulez. Vous devriez plutôt essayer quelque chose comme ceci :
$r = \@a;
$x{ $r } = $r;Comme cela vous pourrez au moins utiliser la valeur du hachage, qui sera une référence en dur, au lieu de la clef qui n'en est pas une.
Bien que vous ne puissiez pas stocker une référence en tant que clef, si vous utilisez une référence en dur dans un contexte de chaîne (comme dans l'exemple précédent), vous êtes certain que cela produira une chaîne unique, puisque l'adresse de la référence fait partie de la chaîne retournée. Vous pouvez donc utiliser une référence comme clef d'un hachage. Seulement vous ne pourrez pas la déréférencer par la suite.
Il existe un cas particulier de hachage dans lequel vous pouvez utiliser des références comme clefs. Par la magie(102) du module Tie::RefHash fourni avec Perl, vous pouvez faire ce que nous venons juste de dire que vous ne pouviez pas faire :
use Tie::RefHash;
tie my %h, 'Tie::RefHash';
%h = (
["ceci", "ici"] => "à la maison",
["cela", "là-bas"] => "ailleurs",
);
while ( my($refcle, $valeur) = each %h ) {
print "@$refcle is $valeur\n";
}En fait, en liant des implémentations différentes aux types prédéfinis, vous pouvez faire se comporter des scalaires, des hachages et des tableaux de beaucoup de manières dont nous vous avions dit que c'était impossible. Ça nous apprendra, imbéciles d'auteurs...
Pour en savoir plus sur les liens avec tie, voir le chapitre 14, Variables liées.
8-5-b. Ramasse-miettes, références circulaires et références faibles▲
Les langages de haut niveau permettent aux programmeurs de ne pas s'inquiéter de la libération de la mémoire quand ils ont fini de l'utiliser. Ce procédé de récupération automatique de la mémoire s'appelle en français le ramassage des miettes (en anglais garbage collecting ou collecte des ordures). Dans la plupart des cas, Perl se sert d'un mécanisme simple et rapide de ramasse-miettes fondé sur le comptage de références.
Quand on sort d'un bloc, ses variables à portée locale sont normalement libérées, mais il est possible de cacher vos miettes de façon à ce que le ramasse-miettes de Perl ne puisse les trouver. Un problème sérieux est que de la mémoire inatteignable avec un décompte de références non nul ne sera normalement pas libérée. C'est pourquoi les références circulaires sont une mauvaise idée :
{ # fait pointer $a et $b l'un sur l'autre
my ($a, $b);
$a = \$b;
$b = \$a;
}ou plus simplement :
{ # fait pointer $a sur lui-même
my $a;
$a = \$a;
}Bien que $a doive être désalloué à la fin du bloc, en fait il ne l'est pas. Quand vous construisez des structures de données récursives, il vous faudra casser (ou affaiblir, voir plus loin) l'autoréférence vous-même si vous voulez que la mémoire soit récupérée avant la fin de votre programme (ou de votre thread). (À la sortie, la mémoire sera automatiquement récupérée pour vous par un mécanisme coûteux, mais complet de ramasse-miettes par marquage et balayage.) Si la structure de données est un objet, vous pouvez utiliser la méthode DESTROY pour casser automatiquement la référence ; voir Ramasse-miettes avec les méthodes DESTROY au chapitre 12.
Une situation similaire peut se produire avec les caches — des entrepôts de données conçus pour une récupération plus rapide que la normale. Hors du cache on trouve des références à données à l'intérieur du cache. Le problème se produit quand toutes ces références sont effacées, mais que les données du cache et les références internes restent. L'existence d'une référence empêche Perl de récupérer le référent, même si nous voulons que les données du cache disparaissent dès qu'elles ne sont plus utiles. Comme pour les références circulaires, nous vous une référence qui n'affecte pas le compte de références, et donc ne retarde pas le ramasse-miettes.
Les références faibles résolvent les problèmes causés par les références circulaires en vous permettant d'« affaiblir » n'importe quelle référence ; c'est-à-dire lui permettre de ne pas modifier le compte des références. Quand la dernière référence non faible à un objet est détruite, l'objet est détruit et toutes les références faibles sont automatiquement libérées.
Pour utiliser cette fonctionnalité, vous aurez besoin du module WeakRef disponible sur CPAN qui contient une documentation complémentaire. Les références faibles sont une fonctionnalité expérimentale. Mais il faut bien que quelqu'un serve de cobaye.
9. Structures de données▲
Perl fournit gratuitement beaucoup des structures de données que vous devez construire vous-même dans d'autres langages de programmation. Les piles et les files que les informaticiens en herbe apprennent en cours ne sont que des tableaux en Perl. Quand vous faites push et pop (ou shift et unshift) sur un tableau, c'est une pile ; quand vous faites push et shift (ou unshift et pop) sur un tableau, c'est une file. Beaucoup de structures arborescentes dans le monde sont construites pour fournir un accès rapide et dynamique à une table de consultation conceptuellement plate. Bien sûr, les hachages font partie de Perl et ils fournissent un accès rapide et dynamique à une table de consultation conceptuellement plate. Tout cela sans les abrutissantes structures de données que trouvent magnifiques ceux dont les esprits ont déjà été convenablement abrutis.
Mais parfois vous avez besoin de structures de données imbriquées parce qu'elles modélisent naturellement le problème que vous essayez de résoudre. Perl vous permet alors de combiner et d'emboîter des tableaux et des hachages de manière à créer des structures de données aussi complexes que vous voulez. Quand ils sont utilisés correctement, ils peuvent servir à créer des listes chaînées, des arbres binaires, des tas, des arbres-B, des ensembles, des graphes et tout ce que vous pouvez imaginer d'autre. Voir Mastering Algorithms with Perl (O'Reilly, 1999), Perl en action (O'Reilly, France, 1999)(103), ou CPAN qui sert de dépôt central pour tout ce genre de modules. Mais vous n'aurez peut-être jamais besoin que de simples combinaisons de tableaux et de hachages, aussi est-ce ce dont nous allons parler dans ce chapitre.
9-1. Tableaux de tableaux▲
Il existe de nombreuses sortes de structures de données. La plus simple à construire est le tableau de tableaux, aussi appelé matrice à deux dimensions. (Ceci se généralise de manière évidente : un tableau de tableaux de tableaux est une matrice à trois dimensions, et ainsi de suite pour les dimensions supérieures.) C'est relativement simple à comprendre, et presque tout ce qui s'applique dans ce cas s'appliquera aussi aux structures plus compliquées que nous explorerons dans les sections suivantes.
9-1-a. Création et accès à un tableau à deux dimensions▲
Voici comment construire un tableau à deux dimensions :
# Affecte une liste de références de tableaux à un tableau
@TdT = (
[ "fred", "barney" ],
[ "george", "jane", "elroy" ],
[ "homer", "marge", "bart" ],
);
print $TdT[2][1]; # affiche "marge"La liste complète est entourée par des parenthèses et non par des crochets, car vous faites une affectation à une liste et non à une référence. Si vous préfériez une référence, vous utiliseriez des crochets :
# Crée une référence à un tableau de références.
$ref_a_TdT = [
[ "fred", "barney", "pebbles", "bamm bamm", "dino", ],
[ "homer", "bart", "marge", "maggie", ],
[ "george", "jane", "elroy", "judy", ],
];
print $ref_a_TdT->[2][3]; # affiche "judy"Rappelez-vous qu'il y a un -> implicite entre deux accolades ou crochets adjacents. Ces deux lignes :
$TdT[2][3]
$ref_a_TdT->[2][3]sont donc équivalentes aux deux lignes suivantes :
$TdT[2]->[3]
$ref_a_TdT->[2]->[3]Il n'y a cependant aucun -> implicite avant la première paire de crochets, c'est pourquoi le déréférencement de $ref_a_TdT nécessite le -> initial. N'oubliez pas que vous pouvez aussi compter à partir de la fin d'un tableau avec un indice négatif, donc :
$TdT[0][-2]est l'avant-dernier élément de la première ligne.
9-1-b. Volez de vos propres ailes▲
Ces grosses affectations de listes sont belles et bonnes pour créer une structure de données fixe, mais comment faire si vous voulez construire chaque élément au vol ou construire la structure au coup par coup ?
Lisons une structure de données à partir d'un fichier. Nous supposerons qu'il s'agit d'un fichier texte, où chaque ligne est une rangée de la structure et est composée d'éléments séparés par des blancs. Voici comment procéder :(104)
while (<>) {
@tmp = split; # Splite les éléments dans un tableau
push @TdT, [ @tmp ]; # Ajoute une référence de tableau anonyme à @TdT
}Bien sûr, vous n'avez pas besoin de donner un nom au tableau temporaire et vous pourriez donc aussi écrire :
while (<>) {
push @TdT, [ split ];
}Si vous voulez une référence à un tableau de tableaux, vous pouvez procéder ainsi :
while (<>) {
push @$ref_a_TdT, [ split ];
}Ces deux exemples ajoutent de nouvelles lignes au tableau de tableaux. Comment faire pour ajouter de nouvelles colonnes ? Si vous ne travaillez qu'avec des tableaux à deux dimensions, il est souvent plus facile d'utiliser une affectation simple :(105)
for $x (0 .. 9) { # Pour chaque ligne...
for $y (0 .. 9) { # Pour chaque colonne...
$TdT[$x][$y] = func($x, $y); # ...affecte cette valeur
}
}
for $x ( 0..9 ) { # Pour chaque ligne...
$ref_a_TdT->[$x][3] = func2($x); # ...affecte la quatrième colonne
}L'ordre dans lequel vous affectez les éléments n'a pas d'importance, pas plus que le fait que les éléments indicés de @TdT existent déjà ou non ; Perl les créera pour vous si besoin est en mettant les éléments intermédiaires à la valeur indéfinie. (Perl créera même la référence initiale dans $ref_a_TdT pour vous s'il le faut.) Si vous voulez juste ajouter des éléments au bout d'une ligne, vous devrez faire quelque chose d'un peu plus étrange :
# Ajoute de nouvelles colonnes à une ligne existante.
push @{ $TdT[0] }, "wilma", "betty";Remarquez que ceci ne marcherait pas :
push $TdT[0], "wilma", "betty"; # FAUX !Cela ne compilerait même pas, car l'argument de push doit être un véritable tableau, et pas seulement une référence à un tableau. C'est pourquoi le premier argument doit absolument commencer par un caractère @. Ce qui suit le @ est assez négociable.
9-1-c. Utilisation et affichage▲
Affichons maintenant la structure de données. Si vous ne voulez qu'un seul élément, ceci suffit :
print $TdT[3][2];Mais si vous voulez tout imprimer, vous ne pouvez pas vous contenter d'écrire :
print @TdT; # FAUXC'est incorrect, car vous aurez des références sous forme de chaînes de caractères au lieu de vos données. Perl ne déréférence jamais automatiquement à votre place. Il vous faut donc construire une boucle ou deux. Le code qui suit affiche la structure complète, en bouclant sur les éléments de @TdT et en les déréférençant chacun à l'intérieur de l'instruction print :
for $ligne ( @TdT ) {
print "@$ligne\n";
}Pour garder la trace des indices, vous pouvez faire comme ceci :
for $i ( 0 .. $#TdT ) {
print "La ligne $i est : @{$TdT[$i]}\n";
}ou même cela (remarquez la boucle intérieure) :
for $i ( 0 .. $#TdT ) {
for $j ( 0 .. $#{$TdT[$i]} ) {
print "L'élément $i $j est $AoA[$i][$j]\n";
}
}Comme vous pouvez le voir, les choses se compliquent. C'est pourquoi il est parfois plus simple d'utiliser une variable temporaire en cours de route :
9-1-d. Tranches▲
Si vous voulez accéder à une tranche (une partie de ligne) d'un tableau multidimensionnel, vous allez devoir faire des indexations subtiles. L'opérateur flèche nous donne une façon simple d'accéder à un élément unique, mais rien de tel n'existe pour les tranches. Vous pouvez toujours extraire les éléments de votre tranche un par un avec une boucle :
@partie = ();
for ($y = 7; $y < 13; $y++) {
push @partie, $TdT[4][$y];
}Cette boucle particulière pourrait être remplacée par une tranche de tableau :
@partie = @{ $TdT[4] } [ 7..12 ];Si vous voulez une tranche à deux dimensions, par exemple, avec $x dans l'intervalle 4..8 et $y dans 7..12, voici une manière de procéder :
@nouveauTdT = ();
for ($startx = $x = 4; $x <= 8; $x++) {
for ($starty = $y = 7; $y <= 12; $y++) {
$nouveauTdT[$x - $startx][$y - $starty] = $TdT[$x][$y];
}
}Dans cet exemple, les valeurs individuelles dans notre tableau d'arrivée à deux dimensions, @nouveauTdT, sont affectées une par une à partir d'un sous-tableau à deux dimensions de @TdT. Une autre possibilité consiste à créer des tableaux anonymes, chacun d'entre eux étant constitué de la tranche désirée d'un sous-tableau de @TdT, puis à mettre des références à ces tableaux anonymes dans @nouveauTdT. Nous pourrions alors stocker les références dans @nouveauTdT (indexé une seule fois, pour ainsi dire) au lieu de stocker des valeurs de sous-tableau dans un @nouveauTdT indexé deux fois. Cette méthode élimine la boucle intérieure :
for ($x = 4; $x <= 8; $x++) {
push @nouveauTdT, [ @{ $TdT[$x] } [ 7..12 ] ];
}Bien sûr, si vous faites cela souvent, vous devriez probablement écrire un sous-programme appelé par exemple extraire_rectangle. Et si vous faites cela très souvent avec de grandes séries de données multidimensionnelles, vous devriez probablement utiliser le module PDL (Perl Data Language), disponible sur CPAN.
9-1-e. Erreurs fréquentes▲
Comme nous l'avons déjà mentionné, les tableaux et les hachages de Perl sont à une dimension. En Perl, même les tableaux « multidimensionnels » sont en fait à une dimension, mais les valeurs le long de cette dimension sont des références à d'autres tableaux, qui agrègent plusieurs éléments en un seul. Si vous affichez ces valeurs sans les déréférencer, vous obtiendrez les références converties en chaînes en lieu et place des données désirées. Par exemple ces deux lignes :
@TdT = ( [2, 3], [4, 5, 7], [0] );
print "@TdT";donneront quelque chose comme :
ARRAY(0x83c38) ARRAY(0x8b194) ARRAY(0x8b1d0)D'un autre côté, cette ligne affiche 7 :
print $TdT[1][2];Quand vous construisez un tableau de tableaux, n'oubliez pas de créer de nouvelles références pour les sous-tableaux. Sinon, vous vous contenterez de créer un tableau contenant le nombre d'éléments des sous-tableaux, comme ceci :
for $i (1..10) {
@tableau = fonction($i);
$TdT[$i] = @tableau; # FAUX !
}Ici on accède à @tableau en contexte scalaire, ce qui renvoie donc le nombre de ses éléments, lequel est affecté comme il se doit à $TdT[$i]. La manière correcte d'affecter la référence vous sera montrée dans un moment.
Après avoir fait l'erreur précédente, les gens réalisent qu'ils doivent affecter une référence. L'erreur qu'ils font naturellement ensuite implique de prendre et reprendre une référence vers toujours le même emplacement mémoire :
for $i (1..10) {
@tableau = fonction($i);
$TdT[$i] = \@tableau; # ENCORE FAUX !
}Chaque référence générée par la seconde ligne de la boucle for est la même, c'est-à-dire une référence au seul tableau @tableau. Certes, ce tableau change effectivement à chaque passage dans la boucle, mais quand tout est fini, $TdT contient 10 références au même tableau, qui contient maintenant la dernière série de valeurs qui lui ont été affectées. print @{$TdT[1]} présentera les mêmes valeurs que print @{$TdT[2]}.
Voici une approche qui aura plus de succès :
for $i (1..10) {
@tableau = fonction($i);
$TdT[$i] = [ @tableau ]; # CORRECT !
}Les crochets autour de @tableau créent un nouveau tableau anonyme, dans lequel les éléments de @tableau sont copiés. Nous stockons ensuite une référence à ce nouveau tableau.
Un résultat similaire, bien que beaucoup plus difficile à lire, pourra être obtenu par :
for $i (1..10) {
@tableau = fonction($i);
@{$TdT[$i]} = @tableau;
}Comme $TdT[$i] doit être une nouvelle référence, la référence se met à exister. Le @ qui précède déréférence alors cette nouvelle référence, avec pour résultat d'affecter (en contexte de liste) les valeurs de @tableau au tableau référencé par $TdT[$i]. Pour des raisons de clarté, vous pouvez préférer éviter cette construction.
Mais il existe une situation dans laquelle vous voudrez l'utiliser. Supposons que @TdT est déjà un tableau de références à des tableaux. C'est-à-dire que vous avez fait des affectations comme :
$TdT[3] = \@tableau_original;Et supposons maintenant que vous vouliez modifier @tableau_original (c'est-à-dire que vous voulez modifier la quatrième ligne de $TdT) de façon à ce qu'il réfère aux éléments de @tableau. Ce code fonctionnera :
@{$TdT[3]} = @tableau;Dans ce cas, la référence ne change pas, mais les éléments du tableau référencé changent. Cela écrase les valeurs de @tableau_original.
Finalement, ce code dangereux en apparence fonctionne parfaitement :
C'est parce que la variable à portée lexicale my @tableau est recréée complètement à chaque passage dans la boucle. Bien que vous ayez l'impression d'avoir stocké une référence à la même variable à chaque fois, ce n'est en fait pas le cas. C'est une subtile distinction, mais cette technique peut produire du code plus efficace, au risque de tromper les programmeurs moins éclairés. (C'est plus efficace, car il n'y a pas de copie dans la dernière affectation.) D'un autre côté, s'il vous faut de toute façon copier les valeurs (ce que fait la première affectation de la boucle), vous pouvez aussi bien utiliser la copie impliquée par les crochets et éviter la variable temporaire :
for $i (1..10) {
$TdT[$i] = [ fonction($i) ];
}En résumé :
$TdT[$i] = [ @tableau ]; # Plus sûr, parfois plus rapide
$TdT[$i] = \@tableau; # Rapide mais risqué, dépend du côté "my"
# de @tableau
@{ $TdT[$i] } = @tableau; # Un peu ruséUne fois que vous maîtrisez les tableaux de tableaux, vous voudrez vous mesurer à des structures de données plus complexes. Si vous cherchez les structures (struct) de C ou les enregistrements (record) de Pascal, vous ne trouverez aucun mot réservé en Perl qui en créera pour vous. Ce que vous avez en revanche est un système plus flexible. Si votre idée d'une structure est moins flexible que cela, ou si vous voulez fournir à vos utilisateurs quelque chose de plus rigide et de plus opaque, alors vous pouvez utiliser les fonctionnalités orientées objet détaillées au chapitre 12, Objets.
Perl dispose de deux manières d'organiser les données : comme des listes ordonnées dans des tableaux, dont l'accès aux éléments se fait par leur position, ou comme des listes non ordonnées de couples clef/valeur stockés dans des hachages et auxquels on accède par leur nom. La meilleure façon de représenter un enregistrement en Perl consiste à utiliser une référence de hachage, mais la manière d'organiser de tels enregistrements peut varier. Si vous désirez conserver une liste ordonnée de ces enregistrements et y accéder par leur numéro, vous utiliserez un tableau de références de hachages pour stocker les enregistrements. Ou bien, si vous préférez accéder à ces enregistrements par leurs noms, vous maintiendrez un hachage de références à des hachages. Vous pourriez même faire les deux à la fois avec un pseudo-hachage.
Dans les sections suivantes, vous trouverez des exemples de code décrivant comment composer (à partir de rien), générer (depuis d'autres sources), accéder à et afficher plusieurs structures de données différentes. Nous montrerons d'abord trois combinaisons évidentes de hachages et de tableaux, suivies par un hachage de fonctions puis des structures de données plus irrégulières. Nous terminerons par la présentation d'une manière de sauver ces structures de données. Ces exemples supposent que vous vous êtes déjà familiarisé avec les explications qui précèdent dans ce chapitre.
9-2. Hachages de tableaux▲
Utilisez un hachage de tableaux quand vous voulez accéder à chaque tableau par une chaîne particulière plutôt que par un numéro d'indice. Dans notre exemple de personnages d'émissions de télévision, au lieu de parcourir la liste de noms à partir de la zéroième émission, la première et ainsi de suite, nous allons mettre en place notre structure de façon à pouvoir obtenir la liste des personnages à partir du nom du dessin animé.
Comme notre structure de données est un hachage, nous ne pouvons pas en ordonner le contenu, mais nous pouvons utiliser la fonction sort pour spécifier un ordre de sortie particulier.
9-2-a. Composition d'un hachage de tableaux▲
Vous pouvez créer un hachage de tableaux anonymes comme suit :
# Nous omettons habituellement les guillemets quand les clefs sont
# des identificateurs.
%HdT = (
flintstones => [ "fred", "barney" ],
jetsons => [ "george", "jane", "elroy" ],
simpsons => [ "homer", "marge", "bart" ],
);Pour ajouter un nouveau tableau au hachage, vous pouvez simplement écrire :
$HdT{teletubbies} = [ "tinky winky", "dipsy", "laa-laa", "po" ];9-2-b. Génération d'un hachage de tableaux▲
Voici quelques techniques pour remplir un hachage de tableaux. Pour le lire à partir d'un fichier avec le format suivant :
flintstones: fred barney wilma dino
jetsons: george jane elroy
simpsons: homer marge bartvous pourriez utiliser l'une des deux boucles suivantes :
while ( <> ) {
next unless s/^(.*?):\s*//;
$HdT{$1} = [ split ];
}
while ( $ligne = <> ) {
($qui, $reste) = split /:\s*/, $ligne, 2;
@champs = split ' ', $reste;
$HdT{$qui} = [ @champs ];
}Si vous avez un sous-programme get_famille qui renvoie un tableau, vous pouvez vous en servir pour remplir %HdT avec l'une de ces deux boucles :
for $groupe ( "simpsons", "jetsons", "flintstones" ) {
$HdT{$groupe} = [ get_famille($groupe) ];
}
for $groupe ( "simpsons", "jetsons", "flintstones" ) {
@membres = get_famille($groupe);
$HdT{$groupe} = [ @membres ];
}Vous pouvez ajouter de nouveaux membres à un tableau existant comme ceci :
push @{ $HdT{flintstones} }, "wilma", "pebbles";9-2-c. Utilisation et affichage d'un hachage de tableaux▲
Vous pouvez fixer le premier élément d'un tableau en particulier comme suit :
$HdT{flintstones}[0] = "Fred";Pour mettre en majuscule l'initiale du deuxième Simpson, appliquez une substitution à l'élément de tableau approprié :
$HdT{simpsons}[1] =~ s/(\w)/\u$1/;Vous pouvez afficher toutes les familles en bouclant sur toutes les clefs du hachage :
for $famille ( keys %HdT ) {
print "$famille : @{ $HdT{$famille} }\n";
}Avec un petit effort supplémentaire, vous pouvez également ajouter les indices de tableau :
for $famille ( keys %HoA ) {
print "$famille : ";
for $i ( 0 .. $#{ $HdT{$famille} } ) {
print " $i = $HdT{$famille}[$i]";
}
print "\n";
}Ou trier les tableaux par leur nombre d'éléments :
for $famille ( sort { @{$HdT{$b}} <=> @{$HdT{$a}} } keys %HdT ) {
print "$famille : @{ $HdT{$famille} }\n"
}Ou même trier les tableaux par leur nombre d'éléments puis trier les éléments ASCIIbétiquement (ou pour être précis, « utf8-tiquement ») :
# Affiche l'ensemble trié par le nombre de personnes et leurs noms.
for $famille ( sort { @{$HdT{$b}} <=> @{$HdT{$a}} } keys %HdT ) {
print "$famille : ", join(", ", sort @{ $HdT{$famille} }), "\n";
}9-3. Tableaux de hachages▲
Un tableau de hachages est utile quand vous avez un tas d'enregistrements auxquels vous aimeriez accéder séquentiellement et que chaque enregistrement comporte des couples clef/valeur. Les tableaux de hachages sont moins fréquemment utilisés que les autres structures de ce chapitre.
9-3-a. Composition d'un tableau de hachages▲
Vous pouvez créer un tableau de hachages anonymes comme suit :
@TdH = (
{
mari => "barney",
femme => "betty",
fils => "bamm bamm",
},
{
mari => "george",
femme => "jane",
fils => "elroy",
},
{
mari => "homer",
femme => "marge",
fils => "bart",
},
);Pour ajouter un nouveau hachage au tableau, vous pouvez simplement écrire :
push @TdH, { mari => "fred", femme => "wilma", fille => "pebbles" };9-3-b. Génération d'un tableau de hachages▲
Voici quelques techniques pour remplir un tableau de hachages. Pour lire depuis un fichier écrit selon le format suivant :
mari=fred ami=barneyvous pourriez utiliser l'une des deux boucles suivantes :
while ( <> ) {
$enrt = {};
for $champ ( split ) {
($cle, $valeur) = split /=/, $champ;
$enrt->{$cle} = $valeur;
}
push @TdH, $enrt;
}
while ( <> ) {
push @TdH, { split /[\s=]+/ };
}Si vous avez un sous-programme get_paire_suivante qui renvoie des couples clef/valeur, vous pouvez l'utiliser pour remplir @TdH avec l'un de ces deux boucles :
while ( @champs = get_paire_suivante() ) {
push @TdH, { @champs };
}
while (<>) {
push @TdH, { get_paire_suivante($_) };
}Vous pouvez ajouter de nouveaux éléments à un hachage existant comme ceci :
$TdH[0]{animal} = "dino";
$TdH[2]{animal} = "petit papa Noël";9-3-c. Utilisation et affichage d'un tableau de hachages▲
Vous pouvez modifier un couple clef/valeur d'un hachage particulier comme suit :
$TdH[0]{mari} = "fred";Pour mettre en majuscule le mari du deuxième hachage appliquez une substitution :
$TdH[1]{mari} =~ s/(\w)/\u$1/;Vous pouvez afficher toutes les données comme suit :
for $href ( @TdH ) {
print "{ ";
for $role ( keys %$href ) {
print "$role=$href->{$role} ";
}
print "}\n";
}et avec les indices :
9-4. Hachages de hachages▲
Le hachage multidimensionnel est la plus souple des structures emboîtées de Perl. Cela revient à construire un enregistrement qui contient d'autres enregistrements. Vous indexez à chaque niveau avec des chaînes (entre guillemets si besoin est). Souvenez-vous cependant que les couples clef/valeur du hachage ne sortiront dans aucun ordre particulier ; vous pouvez utiliser la fonction sort pour récupérer les couples dans l'ordre qui vous intéresse.
9-4-a. Composition d'un hachage de hachage▲
Vous pouvez créer un hachage de hachages anonymes comme suit :
%HdH = (
flintstones => {
mari => "fred",
pote => "barney",
},
jetsons => {
mari => "george",
femme => "jane",
"son fils" => "elroy", # Guillemets nécessaires sur la clef
},
simpsons => {
mari => "homer",
femme => "marge",
fiston => "bart",
},
);Pour ajouter un autre hachage anonyme à %HdH, vous pouvez simplement écrire :
$HdH{ mash } = {
capitaine => "pierce",
major => "burns",
caporal => "radar",
};9-4-b. Génération d'un hachage de hachages▲
Voici quelques techniques pour remplir un hachage de hachages. Pour lire des données à partir d'un fichier dans le format suivant :
flintstones: mari=fred pote=barney femme=wilma animal=dinovous pourriez utiliser l'une des deux boucles suivantes :
while ( <> ) {
next unless s/^(.*?):\s*//;
$qui = $1;
for $champ ( split ) {
($cle, $valeur) = split /=/, $champ;
$HdH{$qui}{$cle} = $valeur;
}
}
while ( <> ) {
next unless s/^(.*?):\s*//;
$qui = $1;$enrt = {};
$HdH{$qui} = $enrt;
for $champ ( split ) {
($cle, $valeur) = split /=/, $champ;
$enrt->{$cle} = $valeur;
}
}Si vous avez un sous-programme get_famille qui renvoie une liste de couples clef/valeur, vous pouvez vous en servir pour remplir %HdH avec l'un de ces trois bouts de code :
for $groupe ( "simpsons", "jetsons", "flintstones" ) {
$HdH{$groupe} = { get_famille($groupe) };
}
for $groupe ( "simpsons", "jetsons", "flintstones" ) {
@membres = get_famille($groupe);
$HdH{$groupe} = { @membres };
}
sub hash_familles {
my @ret;
for $groupe ( @_ ) {
push @ret, $groupe, { get_famille($groupe) };
}
return @ret;
}
%HdH = hash_familles( "simpsons", "jetsons", "flintstones" );Vous pouvez ajouter de nouveaux membres à un hachage comme suit :
%nouveaux = (
femme => "wilma",
animal => "dino";
);
for $quoi (keys %nouveaux) {
$HdH{flintstones}{$quoi} = $nouveaux{$quoi};
}9-4-c. Utilisation et affichage d'un hachage de hachages▲
Vous pouvez modifier un couple clef/valeur d'un hachage particulier comme suit :
$HdH{flintstones}{femme} = "wilma";Pour mettre en majuscules la valeur associée à une clef particulière, appliquez une substitution à un élément :
$HdH{jetsons}{'son fils'} =~ s/(\w)/\u$1/;Vous pouvez afficher toutes les familles en bouclant sur les clefs du hachage externe, puis en bouclant sur les clefs du hachage interne :
for $famille ( keys %HdH ) {
print "$famille : ";
for $role ( keys %{ $HdH{$famille} } ) {
print "$role=$HdH{$famille}{$role} ";
}
print "\n";
}Dans les hachages très grands, il peut être un peu plus rapide de récupérer à la fois les clefs et les valeurs en utilisant each (ce qui exclut le tri) :
while ( ($famille, $roles) = each %HdH ) {
print "$famille : ";
while ( ($role, $personne) = each %$roles ) {
print "$role=$personne ";
}
print "\n";
}(Hélas, ce sont les grands hachages qui ont vraiment besoin d'être triés, sinon vous ne trouverez jamais ce que vous cherchez dans ce qui est affiché.) Vous pouvez trier les familles, puis les rôles, comme suit :
for $famille ( sort keys %HdH ) {
print "$famille : ";
for $role ( sort keys %{ $HdH{$famille} } ) {
print "$role=$HdH{$famille}{$role} ";
}
print "\n";
}Pour trier les familles par leur nombre de membres (plutôt qu'ASCII-bétiquement (ou utf8-tiquement)), vous pouvez utiliser keys en contexte scalaire :
for $famille ( sort { keys %{$HdH{$a}} <=> keys %{$HdH{$b}} } keys %HdH ) {
print "$famille : ";
for $role ( sort keys %{ $HdH{$famille} } ) {
print "$role=$HdH{$family}{$role} ";
}
print "\n";
}Pour trier les membres d'une famille dans un certain ordre, vous pouvez leur donner à chacun un rang :
$i = 0;
for ( qw(mari femme fils fille pote animal) ) { $rang{$_} = ++$i }
for $famille ( sort { keys %{$HdH{$a}} <=> keys %{$HdH{$b}} } keys %HdH ) {
print "$famille : ";
for $role ( sort { $rang{$a} <=> $rang{$b} } keys %{ $HdH{$famille} } ) {
print "$role=$HdH{$famille}{$role} ";
}
print "\n";
}9-5. Hachages de fonctions▲
Quand vous écrivez une application complexe ou un service réseau en Perl, vous voulez probablement mettre un grand nombre de commandes à la disposition de vos utilisateurs. Un tel programme pourrait avoir du code comme celui-ci pour examiner le choix de l'utilisateur et agir en conséquence :
if ($cmd =~ /^exit$/i) { exit }
elsif ($cmd =~ /^help$/i) { show_help() }
elsif ($cmd =~ /^watch$/i) { $watch = 1 }
elsif ($cmd =~ /^mail$/i) { mail_msg($msg) }
elsif ($cmd =~ /^edit$/i) { $edited++; editmsg($msg); }
elsif ($cmd =~ /^delete$/i) { confirm_kill() }
else {
warn "Commande inconnue : '$cmd'; Essayez 'help' la prochaine fois\n";
}Vous pouvez également stocker des références à des fonctions dans vos structures de données, tout comme vous pouvez y stocker des tableaux ou des hachages :
%HdF = ( # Compose un hachage de fonctions
exit => sub { exit },
help => \&show_help,
watch => sub { $watch = 1 },
mail => sub { mail_msg($msg) },
edit => sub { $edited++; editmsg($msg); },
delete => \&confirm_kill,
);
if ($HdF{lc $cmd}) { $HdF{lc $cmd}->() } # Appelle la fonction
else { warn "Commande inconnue : '$cmd'; Essayez 'help' la prochaine fois\n" }Dans l'avant-dernière ligne, nous vérifions si le nom de commande spécifié (en minuscules) existe dans notre « table de distribution » %HdF. Si c'est le cas, nous appelons la commande appropriée en déréférençant la valeur du hachage comme une fonction et passons à cette fonction une liste d'arguments vide. Nous pourrions aussi l'avoir déréférencée comme &{ $HoF{lc $cmd} }(), ou à partir de la version 5.6 de Perl, simplement par $HoF{lc $cmd}().
9-6. Enregistrements plus élaborés▲
Jusqu'ici nous avons vu dans ce chapitre des structures de données simples, homogènes et à deux niveaux : chaque élément contient le même genre de référent que tous les autres éléments de ce niveau. Ce n'est pas indispensable. Tout élément peut contenir n'importe quel type de scalaire, ce qui signifie qu'il peut s'agir d'un chaîne, d'un nombre ou d'une référence à n'importe quoi d'autre. La référence peut être une référence à un tableau ou à un hachage, ou à un pseudo-hachage, ou une référence à une fonction nommée ou anonyme, ou un objet. La seule chose que vous ne pouvez pas faire est de mettre plusieurs référents dans un seul scalaire. Si vous vous retrouvez à essayer de faire ce genre de chose, c'est le signe que vous avez besoin d'une référence à un tableau ou un hachage pour superposer plusieurs valeurs en une seule.
Dans les sections qui suivent, vous trouverez des exemples de code destinés à montrer ce qu'il est possible de stocker dans un enregistrement, que nous implémenterons comme une référence à un hachage. Les clefs sont en majuscules, une convention parfois employée quand le hachage est utilisé comme un type d'enregistrement spécifique.
9-6-a. Composition, utilisation et affichage d'enregistrements plus élaborés▲
Voici un enregistrement avec six champs de types différents :
$enrt = {
TEXTE => $chaine,
SEQUENCE => [ @anc_valeurs ],
RECHERCHE => { %une_table },
CODE1 => \&une_fonction,
CODE2 => sub { $_[0] ** $_[1] },
HANDLE => \*STDOUT,
};Le champ TEXTE est une simple chaîne, que vous pouvez donc afficher :
print $enrt->{TEXT};SEQUENCE et RECHERCHE sont des références normales à un tableau et à un hachage :
print $enrt->{SEQUENCE}[0];
$dernier = pop @{ $enrt->{SEQUENCE} };
print $enrt->{RECHERCHE}{"cle"};
($premier_c, $premier_v) = each %{ $enrt->{RECHERCHE} };CODE1 est un sous-programme nommé et CODE2 un sous-programme anonyme, mais sont appelés de la même façon :
$reponse1 = $enrt->{CODE1}->($arg1, $arg2);
$reponse2 = $enrt->{CODE2}->($arg1, $arg2);Avec une paire d'accolades supplémentaires, pour pouvez traiter $rec->{HANDLE} comme un objet indirect :
print { $enrt->{HANDLE} } "une chaîne\n";Si vous utilisez le module FileHandle, vous pouvez même traiter le handle comme un objet normal :
use FileHandle;
$enrt->{HANDLE}->autoflush(1);
$enrt->{HANDLE}->print("une chaîne\n");9-6-b. Composition, utilisation et affichage d'enregistrements encore plus élaborés▲
Naturellement, les champs de vos structures de données peuvent eux-mêmes être des structures de données arbitrairement complexes :
%TV = (
flintstones => {
serie => "flintstones",
soirs => [ "lundi", "jeudi", "vendredi" ],
membres => [
{ nom => "fred", role => "mari", age => 36, },
{ nom => "wilma", role => "femme", age => 31, },
{ nom => "pebbles", role => "enfant", age => 4, },
],
},
jetsons => {
serie => "jetsons",
soirs => [ "mercredi", "samedi" ],
membres => [
{ nom => "george", role => "mari", age => 41, },
{ nom => "jane", role => "femme", age => 39, },
{ nom => "elroy", role => "enfant", age => 9, },
],
},
simpsons => {
serie => "simpsons",
soirs => [ "lundi" ],
membres => [
{ nom => "homer", role => "mari", age => 34, },
{ nom => "marge", role => "femme", age => 37, },
{ nom => "bart", role => "enfant", age => 11, },
],
},
);9-6-c. Génération d'un hachage d'enregistrements complexes▲
Comme Perl est assez bon pour analyser des structures de données complexes, pour pouvez aussi bien mettre vos déclarations de données dans un fichier séparé comme du code Perl normal, puis le charger avec les fonctions intégrées do ou require. Une autre approche courante est d'utiliser un module de CPAN (comme XML::Parser) pour charger des structures de données quelconques écrites dans un autre langage (comme XML).
Vous pouvez construire vos structures de données petit à petit :
$enrt = {};
$enrt->{serie} = "flintstones";
$enrt->{soirs} = [ quels_jours() ];Ou les lire à partir d'un fichier (qu'on suppose ici écrit sous la forme champ=valeur):
@membres = ();
while (<>) {
%champs = split /[\s=]+/;
push @membres, { %champs };
}
$enrt->{membres} = [ @membres ];Puis les inclure dans des structures de données plus grandes, indexées par l'un des sous-champs :
$TV{ $enrt->{serie} } = $enrt;Vous pouvez utiliser des champs supplémentaires pour éviter de dupliquer les données. Par exemple, vous pourriez vouloir inclure un champ "enfants" dans l'enregistrement d'une personne, lequel pourrait être une référence à un tableau contenant des références aux propres enregistrements des enfants. En ayant des parties de votre structure de données qui pointent sur d'autres, vous éviter les dérives résultant de la mise à jour des données à un endroit, mais pas à un autre :
for $famille (keys %TV) {
my $enrt = $TV{$famille}; # pointeur temporaire
my @enfants = ();
for $personne ( @{$enrt->{membres}} ) {
if ($personne->{role} =~ /enfant|fils|fille/) {
push @enfants, $personne;
}
}
# $enrt et $TV{$famille} pointent sur les mêmes données !
$enrt->{enfants} = [ @enfants ];
}L'affectation $enrt->{enfants} = [ @enfants ] copie le contenu du tableau — mais ce sont simplement des références à des données non copiées. Cela signifie que si vous modifiez l'âge de Bart comme suit :
$TV{simpsons}{enfants}[0]{age}++; # incrémente à 12alors vous verrez le résultat suivant, car $TV{simpsons}{enfants}[0] et $TV{simpsons}{membres}[2] pointent tous deux vers le même hachage anonyme :
print $TV{simpsons}{membres}[2]{age}; # affiche 12 égalementEt maintenant pour imprimer toute la structure de données %TV :
for $famille ( keys %TV ) {
print "la famille $famille";
print " passe ", join (" et ", @{ $TV{$famille}{nights} }), "\n";
print "ses membres sont :\n";
for $qui ( @{ $TV{$famille}{membres} } ) {
print " $qui->{name} ($qui->{role}), age $qui->{age}\n";
}
print "enfants: ";
print join (", ", map { $_->{nom} } @{ $TV{$famille}{enfants} } );
print "\n\n";
}9-7. Sauvegarde de structures de données▲
Il existe plusieurs manières de sauver vos structures de données pour les utiliser avec un autre programme par la suite. La manière la plus simple consiste à utiliser le module Data::Dumper de Perl, qui convertit une structure de données (potentiellement autoréférente) en une chaîne qui peut être sauvée pour être reconstituée par la suite avec eval ou do.
use Data::Dumper;
$Data::Dumper::Purity = 1; #, car %TV est autoréférent
open (FILE, "> tvinfo.perldata") or die "impossible d'ouvrir tvinfo: $!";
print FILE Data::Dumper->Dump([\%TV], ['*TV']);
close FILE or die "impossible de fermer tvinfo: $!";Un autre programme (ou le même programme) pourra lire le fichier plus tard :
open (FILE, "< tvinfo.perldata") or die "impossible d'ouvrir tvinfo: $!";
undef $/; # lit tout le fichier d'un coup
eval <FILE>; # recrée %TV
die "impossible de recréer les données depuis tvinfo.perldata: $@" if $@;
close FILE or die "impossible de fermer tvinfo: $!";
print $TV{simpsons}{membres}[2]{age};ou simplement :
do "tvinfo.perldata" or die "impossible de recréer tvinfo: $! $@";
print $TV{simpsons}{membres}[2]{age};Beaucoup d'autres solutions sont disponibles, avec des formats de stockage qui vont des données binaires (très rapide) au XML (très interopérable). Visitez vite un miroir du CPAN près de chez vous !
10. Paquetages▲
Dans ce chapitre, nous allons pouvoir commencer à nous amuser, car nous allons aborder la bonne conception des logiciels. Pour ce faire, parlons de Paresse, d'Impatience et d'Orgueil, les bases de la bonne conception des logiciels.
Nous sommes tous tombés dans le piège du copier/coller alors qu'il fallait définir une abstraction de haut niveau, ne serait-ce qu'une boucle ou une routine simple.(106) Il est vrai que certains partent à l'autre extrême en définissant des tas croissants d'abstractions de plus haut niveau alors qu'il aurait suffi d'un copier/coller.(107) Mais en général, la plupart d'entre nous devraient penser à employer plus d'abstraction plutôt que moins.
Entre les deux se trouvent ceux qui ont une vision équilibrée du degré d'abstraction nécessaire, mais qui se lancent dans la conception de leurs propres abstractions alors qu'ils devraient utiliser un code existant.(108)
Chaque fois que vous êtes tenté d'adopter l'une ou l'autre de ces attitudes, il vous faut d'abord vous asseoir et penser à ce qui sera le mieux pour vous et votre prochain à long terme. Si vous allez déverser vos énergies créatives dans une masse de code, pourquoi ne pas rendre le monde meilleur pendant que vous y êtes ? (Même si vous ne visez qu'à réussir le programme, vous devez vous assurer qu'il convient à la bonne niche écologique.)
La première étape vers une programmation écologiquement soutenable est simple : pas de détritus dans le parc. Lorsque vous écrivez un bout de code, pensez à lui donner son propre espace de noms, de sorte que vos variables et vos fonctions n'écrasent pas celles de quelqu'un d'autre, ou vice-versa. Un espace de noms est un peu comme votre maison, dans laquelle il vous est permis d'être aussi désordonné que vous le voulez, tant que votre interface externe avec les autres citoyens reste un tant soit peu correcte. En Perl, un espace de noms s'appelle un paquetage (package). Les paquetages fournissent la brique de base sur laquelle les concepts de plus haut niveau de module et de classe sont élaborés.
Tout comme la notion de « maison », la notion de « paquetage » est un peu nébuleuse. Les paquetages sont indépendants des fichiers. On peut aussi bien avoir plusieurs paquetages dans un seul fichier, ou un unique paquetage réparti sur plusieurs fichiers, tout comme votre maison peut être soit une petite mansarde dans un grand bâtiment (si vous êtes un artiste sans le sou), soit un ensemble de bâtiments (si votre nom se trouve être Reine Elizabeth). Mais une maison est habituellement composée d'un seul bâtiment, comme un paquetage est habituellement composé d'un seul fichier. Avec Perl, vous pouvez mettre un paquetage dans un seul fichier, tant que vous acceptez de donner au fichier le même nom que le paquetage et d'utiliser l'extension .pm, qui est l'abréviation de « perl module ». Le module est l'unité fondamentale de réutilisation de Perl. En effet, pour utiliser un module, vous vous servez de la commande use, qui est une directive de compilation qui contrôle l'importation des fonctions et des variables d'un module. Chaque exemple de use que vous avez vu jusqu'à maintenant est un exemple de réutilisation de module.
Le Comprehensive Perl Archive Network, ou CPAN, est l'endroit où mettre vos modules si d'autres personnes pouvaient les trouver utiles. Perl a prospéré grâce à la volonté des programmeurs à partager les fruits de leur travail avec la communauté. Évidemment, CPAN est également l'endroit où vous pouvez trouver des modules que d'autres ont gentiment téléchargés pour l'usage de tous. Voir le chapitre 22, CPAN, et www.cpan.org plus de détails.
Depuis 25 ans environ, il est à la mode de concevoir des langages informatiques qui imposent un état de paranoïa. On attend de vous de programmer chaque module comme s'il était en état de siège. Il existe sans doute certaines cultures féodales au sein desquelles ceci est justifiable, mais toutes les cultures ne sont pas ainsi faites. Dans la culture Perl, par exemple, on attend de vous que vous restiez en dehors de la maison de quelqu'un parce que vous n'y avez pas été invité, et non parce qu'il y a des barreaux aux fenêtres.(109)
Ceci n'est pas un livre sur la programmation orientée objet, et nous ne sommes pas là pour vous convertir en fanatique délirant de l'orienté objet, même si justement vous souhaitez être converti. Il existe déjà de nombreux livres disponibles sur ce sujet. La philosophie Perl de la conception orientée objet correspond parfaitement à la philosophie Perl de tout le reste ; utilisez la conception orientée objet (OO) là où elle a un sens, et évitez-la là où elle n'en a pas. À vous de voir.
En parler OO, chaque objet appartient à un groupement appelé classe. En Perl, les classes, les paquetages et les modules sont tellement liés que les débutants peuvent souvent les considérer interchangeables. Typiquement, une classe est implémentée par un module qui définit un paquetage ayant le même nom que la classe. Nous expliquerons cela dans les quelques chapitres qui suivent.
Lorsque vous utilisez un module avec use, vous bénéficiez de la réutilisation directe de logiciel. Avec les classes, vous bénéficiez de la réutilisation indirecte de logiciel lorsqu'une classe en utilise une autre par héritage. Avec les classes, vous gagnez quelque chose de plus : une interface propre avec un autre espace de noms. On n'accède à quelque chose dans une classe qu'indirectement, isolant ainsi la classe du monde extérieur.
Comme nous l'avons indiqué dans le chapitre 8, Références, la programmation orientée objet est réalisée par des références dont les référents savent à quelle classe ils appartiennent. En fait, maintenant que vous connaissez les références, vous connaissez presque tout ce que les objets ont de difficile. Le reste « se trouve sous les doigts », comme dirait un pianiste. Mais cependant il va falloir pratiquer un peu.
Un de vos exercices de gammes de base consiste à apprendre comment protéger différents bouts de code pour qu'une partie n'altère pas par inadvertance les variables des autres parties. Chaque bout de code appartient à un paquetage bien défini, ce qui détermine quelles variables et quelles fonctions sont à sa disposition. Lorsque Perl rencontre un bout de code, il le compile dans le paquetage courant. Le paquetage courant initial est appelé « main », mais vous pouvez passer du paquetage courant à un autre à tout moment avec la déclaration package. Le paquetage courant détermine quelle table de symboles est utilisée pour trouver vos variables, fonctions, handles d'entrée/sortie, et formats.
Toute variable qui n'est pas déclarée avec my est associée à un paquetage — même des variables apparemment omniprésentes comme $_ et %SIG. En fait, les variables globales n'existent pas vraiment en Perl, ce sont simplement des variables de paquetage. (Les identificateurs spéciaux comme _ et SIG ne sont qu'apparemment globaux, car ils sont par défaut dans le paquetage main plutôt que dans le paquetage courant.)
La portée d'une déclaration package commence à la déclaration elle-même et se termine à la fin de la portée qui la contient (bloc, fichier ou eval — celle qui arrive en premier) ou jusqu'à une autre déclaration package au même niveau, qui remplace la précédente. (Ceci est une pratique courante.)
Tous les identificateurs ultérieurs (dont ceux qui sont déclarés avec our, mais non ceux qui sont déclarés avec my ou qualifiés avec le nom d'un autre paquetage) seront placés dans la table de symboles appartenant au paquetage courant. (Les variables déclarées avec my sont indépendantes des paquetages. Elles sont toujours visibles à l'intérieur, et uniquement à l'intérieur, de la portée les contenant, quelles que soient les déclarations de paquetage.)
Une déclaration de paquetage sera habituellement la première instruction d'un fichier destiné à être inclus par require ou use. Mais ce n'est qu'une convention. Vous pouvez mettre une déclaration package partout où vous pouvez mettre une instruction. Vous pouvez même la mettre à la fin d'un bloc, auquel cas elle n'aura pas le moindre effet. Vous pouvez passer d'un paquetage à un autre à plus d'un endroit, car une déclaration de paquetage ne fait que sélectionner la table de symboles à utiliser par le compilateur pour le reste de ce bloc. (C'est ainsi qu'un paquetage donné peut se répartir sur plusieurs fichiers.)
Vous pouvez faire référence aux identificateurs(110) appartenant à d'autres paquetages en les préfixant (« qualifiant ») avec leur nom de paquetage et un double deux-points : $Paquetage::Variable. Si le nom du paquetage est nul, c'est le paquetage principal (main) qui est pris par défaut. C'est-à-dire que $::chaude est équivalent à $main::chaude.(111)
L'ancien délimiteur de paquetage était l'apostrophe, ainsi dans d'anciens programmes Perl vous verrez des variables comme $main'chaude et $unpack'debiere. Mais le double deux-points est conseillé parce qu'il est plus lisible, d'une part pour les humains, et d'autre part pour les macros emacs. Il donne aussi aux programmeurs C++ le sentiment qu'ils savent ce qui se passe — alors que l'apostrophe était là pour donner aux programmeurs Ada le sentiment de savoir ce qui se passe. Comme la syntaxe démodée est encore supportée pour la compatibilité arrière, si vous essayez d'utiliser une chaîne comme "This is $owner's house", vous accèderez à $owner::s, c'est-à-dire la variable $s dans le paquetage owner, ce qui n'est probablement pas ce que vous vouliez dire. Utilisez des accolades pour éliminer l'ambiguïté, par exemple "This is ${owner}'s house".
Le double deux-points peut être utilisé pour mettre bout à bout des identificateurs dans un nom de paquetage : $Rouge::Bleu::var. Ce qui veut dire : le $var appartenant au paquetage Rouge::Bleu. Le paquetage Rouge::Bleu n'a rien à voir avec un quelconque paquetage Rouge ou Bleu existant éventuellement. Une relation entre Rouge::Bleu et Rouge ou Bleu peut avoir un sens pour la personne qui écrit ou utilise le programme, mais n'en a aucun pour Perl. (Enfin, à part le fait que, dans l'implémentation actuelle, la table de symboles Rouge::Bleu se trouve être rangée dans la table de symboles Rouge. Mais le langage Perl n'en fait aucun usage direct.)
Pour cette raison, chaque déclaration package doit déclarer un nom de paquetage complet. Aucun nom de paquetage ne sous-entend un quelconque « préfixe », même s'il est (apparemment) déclaré à l'intérieur de la portée d'une autre déclaration de paquetage.
Seuls les identificateurs (les noms commençant par une lettre ou un souligné) sont rangés dans la table de symboles d'un paquetage. Tous les autres symboles sont gardés dans le paquetage main, notamment toutes les variables non alphabétiques comme $!, $?, et $_. De plus, lorsqu'ils ne sont pas qualifiés, les identificateurs STDIN, STDOUT, STDERR, ARGV, ARGVOUT, ENV, INC et SIG se trouvent obligatoirement dans le paquetage main, même lorsqu'ils sont utilisés à d'autres fins que celles auxquelles ils sont destinés par construction. Ne nommez pas votre paquetage m, s, y, tr, q, qq, qr, qw, ou qx sauf si vous cherchez beaucoup d'ennuis. Par exemple, vous ne pourrez pas utiliser la forme qualifiée d'un identificateur comme handle de fichier, car il sera interprété au contraire comme une recherche de motif, une substitution ou une translittération.
Il y a longtemps, les variables commençant avec un souligné appartenaient obligatoirement au paquetage main, mais nous avons décidé qu'il était plus utile pour les créateurs d'un paquetage de pouvoir utiliser un souligné en début de nom pour indiquer des identificateurs semi-privés destinés uniquement à l'usage interne de ce paquetage. (Des variables réellement privées peuvent être déclarées comme variables lexicales dans la portée d'un fichier, mais cela marche le mieux quand un paquetage et un module ont une relation bijective, ce qui est courant, mais pas obligatoire.)
Le hachage %SIG (qui sert à intercepter les signaux, voir le chapitre 16, Communication interprocessus) est également spécial. Si vous définissez un gestionnaire de signal en tant que chaîne, il est sous-entendu qu'il fait référence à une fonction du paquetage main, sauf si le nom d'un autre paquetage est explicitement utilisé. Qualifiez complètement le nom d'un gestionnaire de signal si vous voulez utiliser un paquetage spécifique, ou évitez entièrement les chaînes en affectant plutôt un typeglob ou une référence à une fonction :
$SIG{QUIT} = "Pack::attrape_quit"; # nom de gestionnaire qualifié
$SIG{QUIT} = "attrape_quit"; # sous-entend "main::attrape_quit"
$SIG{QUIT} = *attrape_quit; # impose la fonction du paquetage courant
$SIG{QUIT} = \&attrape_quit; # impose la fonction du paquetage courant
$SIG{QUIT} = sub { print "Attrapé SIGQUIT\n" }; # fonction anonymeLa notion de « paquetage courant » est un concept concernant à la fois la compilation et l'exécution. La plupart des vérifications de nom de variable se font à la compilation, mais les vérifications à l'exécution se font lorsque des références symboliques sont déréférencées et quand de nouveaux bouts de code sont analysés avec eval. En particulier, quand vous appliquez eval à une chaîne, Perl sait dans quel paquetage eval a été invoqué et propage ce paquetage vers l'intérieur en évaluant la chaîne. (Bien sûr, vous pouvez toujours passer à un autre paquetage à l'intérieur de la chaîne eval, puisqu'une chaîne eval compte pour un bloc, tout comme un fichier chargé avec un do, un require, ou un use.)
D'un autre côté, si eval veut déterminer dans quel paquetage il se trouve, le symbole spécial __PACKAGE__ contient le nom du paquetage courant. Puisque vous pouvez le traiter comme une chaîne, vous pourriez l'utiliser dans une référence symbolique pour accéder à une variable de paquetage. Mais si vous faites cela, il y a des chances que vous ayez plutôt intérêt à déclarer la variable avec our, de sorte qu'on puisse y accéder comme si c'était une variable lexicale.
10-1. Tables de symboles▲
Les éléments contenus dans un paquetage sont dans leur ensemble appelés table de symboles. Les tables de symboles sont rangées dans un hachage dont le nom est le même que celui du paquetage, avec un double deux-points ajouté à la fin. Ainsi le nom de la table de symboles principale, main, est %main::. Puisque main se trouve aussi être le paquetage par défaut, Perl fournit %:: comme abréviation pour %main::.
De même, la table de symboles du paquetage Rouge::Bleu est appelé %Rouge::Bleu::. Il se trouve que la table de symboles main contient toutes les autres tables de symboles de haut niveau, elle-même incluse, donc %Rouge::Bleu:: est aussi %main::Rouge::Bleu::.
Quand nous disons que la table de symboles « contient » une autre table de symboles, nous voulons dire qu'elle contient une référence à une autre table de symboles. Puisque main est le paquetage de plus haut niveau, il contient une référence à lui-même, ainsi %main:: est pareil que %main::main::, et %main::main::main::, et ainsi de suite, ad infinitum. Il est important de prévoir ce cas spécial si vous écrivez du code qui parcourt toutes les tables de symboles.
À l'intérieur du hachage d'une table de symboles, chaque couple clef/valeur fait correspondre à un nom de variable sa valeur. Les clefs sont les identificateurs de symbole et les valeurs les typeglobs correspondants. Donc quand vous utilisez la notation typeglob *NOM, vous accédez en réalité à une valeur dans le hachage qui contient la table de symboles du paquetage courant. En fait, les instructions suivantes ont (quasiment) le même effet :
*sym = *main::variable;
*sym = $main::{"variable"};La première est plus efficace, car on accède à la table de symboles main au moment de la compilation. Elle créera aussi un nouveau typeglob de ce nom s'il n'en existait pas précédemment, alors que la deuxième version ne le fera pas.
Puisqu'un paquetage est un hachage, vous pouvez rechercher les clefs du paquetage et récupérer toutes les variables du paquetage. Puisque les valeurs du hachage sont des typeglobs, vous pouvez les déréférencer de diverses façons. Essayez ceci :
foreach $nomsym (sort keys %main::) {
local *sym = $main::{$nomsym};
print "\$$nomsym est défini\n" if defined $sym;
print "\@$nomsym is non nul\n" if @sym;
print "\%$nomsym is non nul\n" if %sym;
}Puisque tous les paquetages sont accessibles (directement ou indirectement) par le paquetage main, vous pouvez écrire du code Perl pour visiter chaque variable de paquetage de votre programme. C'est précisément ce que fait le débogueur Perl lorsque vous lui demandez d'afficher toutes vos variables avec la commande V. Notez que si vous faites cela, vous ne verrez pas les variables déclarées avec my, puisqu'elles sont indépendantes des paquetages, bien que vous verrez les variables déclarées avec our. Voir le chapitre 20, Le débogueur Perl.
Précédemment nous avons dit que seuls les identificateurs étaient rangés dans des paquetages autres que main. C'était un tout petit mensonge : vous pouvez utiliser la chaîne que vous voulez comme clef dans le hachage de la table de symboles — mais ça ne serait pas du Perl valide si vous essayiez d'utiliser un non-identificateur directement :
$!@#$% = 0; # FAUX, erreur de syntaxe.
${'!@#$%'} = 1; # Ok, mais non qualifié.
${'main::!@#$%'} = 2; # On peut qualifier dans la chaîne
print ${ $main::{'!@#$%'} } # Ok, imprime 2!Les typeglobs servent essentiellement d'alias :
*dick = *richard;rend les variables, fonctions, formats, et handles de fichiers et répertoires accessibles par l'identificateur richard également accessibles par l'identificateur dick. Si vous ne souhaitez affecter un alias qu'à une seule variable ou fonction, affectez plutôt la référence :
*dick = \$richard;Ce qui fait que $richard et $dick sont littéralement la même variable, mais que @richard et @dick restent des tableaux différents. Rusé, non ?
C'est ainsi que fonctionne le paquetage Exporter lorsque l'on importe des variables d'un paquetage vers un autre. Par exemple :
*UnPack::dick = \&AutrePack::richard; importe la fonction &richard du paquetage AutrePack dans le paquetage UnPack, le rendant disponible comme fonction &dick. (Le module Exporter sera décrit dans le prochain chapitre.) Si vous précédez l'affectation avec un local, l'alias ne durera que le temps de la portée dynamique courante.
Ce mécanisme peut être utilisé pour récupérer une référence à partir d'une fonction, rendant le référent disponible avec le type de données approprié :
*unites = renseigner() ; # Affecter \%nouveau_hachage au typeglob
print $unites{kg}; # Affiche 70; pas nécessaire de déréférencer!
sub renseigner {
my %nouveau_hachage = (km => 10, kg => 70);
return \%nouveau_hachage;
}De même, vous pouvez passer une référence à une fonction et l'utiliser sans la déréférencer :
%unites = (kilometres => 6, kilos => 11);
faireleplein( \%unites ); # Passer une référence
print $unites{litres}; # Affiche 4
sub faireleplein {
local *hashsym = shift; # Affecter \%unites au typeglob
$hashsym{litres} = 4; # Modifie %unites; pas nécessaire
# de déréférencer !
}Ce sont des moyens astucieux de manipuler des références quand vous ne voulez pas devoir les déréférencer explicitement. Notez que les deux techniques ne fonctionnent qu'avec des variables de paquetage. Elles ne marcheraient pas si on avait déclaré %unites avec my.
Les tables de symboles s'utilisent aussi pour créer des scalaires « constants » :
*PI = \3.14159265358979;Il vous est maintenant impossible d'altérer $PI, ce qui probablement une bonne chose, somme toute. Ceci n'est pas pareil qu'une fonction constante, qui est optimisée à la compilation. Une fonction constante est une fonction dont le prototype indique qu'elle ne prend pas de paramètres et qu'elle retourne une expression constante ; voir pour plus de détails la section Substitution en ligne de fonctions constantes, chapitre 6, Sous-programmes. Le pragma use constant est un raccourci commode :
Sous le capot, ceci utilise la case « fonction » de *PI, plutôt que la case « scalaire » utilisée ci-dessus. L'expression suivante, plus compacte (mais moins lisible), est équivalente :
*PI = sub () { 3.14159 };En tout cas c'est un idiome pratique à connaître. Affecter un sub {} à un typeglob permet de donner un nom à une fonction anonyme lors de l'exécution.
Affecter une référence à un typeglob à un autre typeglob (*sym = \*oldvar) revient à affecter the typeglob en entier, car Perl déréférence automatiquement la référence au typeglob à votre place. Lorsque vous affectez simplement une chaîne à une typeglob, vous obtenez le typeglob entier nommé par cette chaîne, car Perl va chercher la chaîne dans la table de symboles courante. Les instructions suivantes sont toutes équivalentes entre elles, bien que les deux premières sont calculées à la compilation, alors que les deux dernières le sont à l'exécution :
*sym = *anciennevar;
*sym = \*anciennevar; # déréférence auto
*sym = \*{"anciennevar"}; # recherche explicite dans la table de symboles
*sym = "anciennevar"; # recherche implicite dans la table de symbolesLorsque vous faites l'une des affectations suivantes, vous ne faites que remplacer l'une des références à l'intérieur du typeglob :
*sym = \$frodon;
*sym = \@sam;
*sym = \%merry;
*sym = \&pippin;D'un autre point de vue, le typeglob lui-même peut être considéré comme une espèce de hachage, incluant des entrées pour les différents types de variables. Dans ce cas, les clefs sont fixées, puisqu'un typeglob contient exactement un scalaire, un tableau, un hachage, et ainsi de suite. Mais vous pouvez extraire les références individuelles, comme ceci :
*pkg::sym{SCALAR} # pareil que \$pkg::sym
*pkg::sym{ARRAY} # pareil que \@pkg::sym
*pkg::sym{HASH} # pareil que \%pkg::sym
*pkg::sym{CODE} # pareil que \&pkg::sym
*pkg::sym{GLOB} # pareil que \*pkg::sym
*pkg::sym{IO} # handle de fichier/rép interne, pas d'équivalent direct
*pkg::sym{NAME} # "sym" (pas une référence)
*pkg::sym{PACKAGE} # "pkg" (pas une référence)Vous pouvez dire *foo{PACKAGE} et *foo{NAME} pour déterminer de quel nom et et de quel paquetage provient l'entrée *foo d'une table de symboles. Ceci peut être utile dans une fonction à laquelle des typeglobs sont passés en paramètres :
sub identifier_typeglob {
my $glob = shift;
print 'Vous m\'avez donné ', *{$glob}{PACKAGE}, '::', *{$glob}{NAME}, "\n"
}
identifier_typeglob(*foo);
identifier_typeglob(*bar::glarch);Ceci affiche :
Vous m'avez donné main::foo
Vous m'avez donné bar::glarchLa notation *foo{TRUC} peut être utilisée pour obtenir des références aux éléments individuels de *foo. Voir pour plus de détails la section Références de table de symboles, chapitre 8.
Cette syntaxe est principalement utilisée pour accéder au handle de fichier ou de répertoire interne, car les autres références internes sont déjà accessibles d'autres façons. (L'ancien *foo{FILEHANDLE} reste supporté et signifie *foo{IO}, mais ne laissez pas son nom vous faire croire qu'il peut distinguer entre des handles de fichier et de répertoire.) Nous avons pensé généraliser cela parce que quelque part, c'est joli. Quelque part. Vous n'avez probablement pas à vous souvenir de tout cela sauf si vous avez l'intention d'écrire un autre débogueur de Perl.
10-2. Autochargement▲
Normalement, vous ne pouvez pas appeler une fonction non définie. Cependant, s'il y a une fonction nommée AUTOLOAD dans le paquetage de la fonction non définie (ou dans le cas d'une méthode d'objet, dans le paquetage de l'une quelconque des classes de base de l'objet), alors la fonction AUTOLOAD est appelée avec les mêmes paramètres qui seraient passés à la fonction d'origine. Vous pouvez définir la fonction AUTOLOAD pour qu'elle retourne des valeurs exactement comme une fonction normale, ou vous pouvez définir la fonction qui n'existait pas et ensuite l'appeler comme si elle avait existé tout du long.
Le nom pleinement qualifié de la fonction d'origine apparaît magiquement dans la variable globale au paquetage $AUTOLOAD, dans le même paquetage que la fonction AUTOLOAD. Voici un exemple simple qui vous avertit gentiment lors des appels de fonctions non définies, au lieu d'arrêter le programme.
sub AUTOLOAD {
our $AUTOLOAD;
warn "la tentative d'appeler $AUTOLOAD a échoué.\n";
}
blarg(10); # notre $AUTOLOAD aura la valeur to main::blarg
print "Encore vivant!\n"Ou vous pouvez retourner une valeur pour le compte de la fonction non définie :
sub AUTOLOAD {
our $AUTOLOAD;
return "Je vois $AUTOLOAD(@_)\n";
}
print blarg(20); # affiche: Je vois main::blarg(20)Votre fonction AUTOLOAD pourrait charger une définition de la fonction non définie en utilisant eval ou require, ou utiliser l'astuce d'affectation au glob discutée précédemment, puis exécuter cette fonction en utilisant une forme spéciale du goto qui peut effacer le « stack frame » de la fonction sans laisser de trace. Ici nous définissons la fonction en affectant une fermeture au glob :
sub AUTOLOAD {
my $nom = our $AUTOLOAD;
*$AUTOLOAD = sub { print "Je vois $nom(@_)\n" };
goto &$AUTOLOAD; # Redémarrer la nouvelle fonction
}
blarg(30); # affiche : je vois main::blarg(30)
glarb(40); # affiche : je vois main::glarb(40)
blarg(50); # affiche : je vois main::blarg(50)Le module standard AutoSplit est utilisé par les créateurs de modules pour les aider à diviser leurs modules en plusieurs fichiers (avec des noms de fichier se terminant avec .al), chacun contenant une fonction. Les fichiers sont placés dans le répertoire auto/ de la bibliothèque Perl de votre système, après quoi les fichiers peuvent être autochargés par le module standard AutoLoader.
Une approche similaire est utilisée par le module SelfLoader, mis à part qu'il autocharge des fonctions à partir de la zone DATA du fichier lui-même, ce qui est moins efficace à certains égards, et plus efficace à d'autres. L'autochargement de fonctions Perl par AutoLoader et SelfLoader est analogue au chargement dynamique de fonctions C compilées par DynaLoader, mais l'autochargement est fait avec la granularité d'un appel de fonction, alors que le chargement dynamique est fait avec la granularité d'un module entier, et liera en général un grand nombre de fonctions C ou C++ à la fois. (Notez que beaucoup de programmeurs Perl se débrouillent très bien sans les modules AutoSplit, AutoLoader, SelfLoader, or DynaLoader. Il faut juste que vous sachiez qu'ils sont là, au cas où vous ne pourriez pas vous débrouiller sans eux.)
On peut s'amuser avec des fonctions AUTOLOAD qui servent d'emballage pour d'autres interfaces. Par exemple, faisons semblant qu'une fonction qui n'est pas définie doive juste appeler system avec ses paramètres. Tout ce que vous auriez à faire est ceci :
sub AUTOLOAD {
my $programme = our $AUTOLOAD;
$programme =~ s/.*:://; # enlever le nom du paquetage
system($programme, @_);
}(Félicitations, vous venez d'implémenter une forme rudimentaire du module Shell qui vient en standard avec Perl.) Vous pouvez appeler votre autochargeur (sur Unix) ainsi :
date();
who('am', 'i');
ls('-l');
echo("Ga bu zo meu...");En fait, si vous prédéclarez les fonctions que vous voulez appeler de cette façon, vous pouvez procéder comme si elles étaient préconstruites dans le langage et omettre les parenthèses lors de l'appel :
11. Modules▲
Le module est l'unité fondamentale de réutilisation de Perl. À bien le regarder, un module n'est qu'un paquetage défini dans un fichier de même nom (avec .pm à la fin). Dans ce chapitre, nous allons explorer comment utiliser les modules des autres et créer les siens.
Perl inclut en standard un grand nombre de modules, que vous pouvez trouver dans le répertoire lib de votre distribution Perl. Beaucoup de ces modules sont décrits au chapitre 32, Modules standards, et au chapitre 31, Modules de pragmas. Tous les modules standard ont aussi une documentation détaillée en ligne, qui peut (scandale !) être plus à jour que ce livre. Essayez la commande perldoc si votre commande man ne fonctionne pas.
Le Comprehensive Perl Archive Network (CPAN) contient un dépôt de modules alimenté par la communauté Perl mondiale, et est présenté au chapitre 22, CPAN. Voir aussi http://www.cpan.org.
11-1. Utilisation des modules▲
Il y a deux sortes de modules : traditionnel et orienté objet. Les modules traditionnels définissent des fonctions et des variables destinées à être importées et utilisées par un programme qui y fait appel. Les modules orientés objet fonctionnent comme des définitions de classe auxquelles on accède par des appels de méthodes, décrites au chapitre 12, Objets. Certains modules font les deux.
Les modules Perl sont habituellement inclus dans votre programme en écrivant :
use MODULE LISTE;ou simplement :
use MODULE;MODULE doit être un identificateur qui nomme le paquetage et le fichier du module. (Les descriptions de syntaxe ne sont données ici qu'à titre indicatif, car la syntaxe complète de l'instruction use est détaillée au chapitre 29, Fonctions.)
L'instruction use précharge MODULE au moment de la compilation, puis importe les symboles que vous avez demandés pour qu'ils soient disponibles pour le reste de la compilation. Si vous ne fournissez pas une LISTE des symboles que vous voulez, les symboles nommés dans le tableau @EXPORT interne au module sont utilisés — en supposant que vous utilisez le module Exporter, décrit plus loin dans ce chapitre sous « Espace privé de module et Exporter ». (Si vous fournissez une LISTE, tous vos symboles doivent être mentionnés, soit dans le tableau @EXPORT, soit dans le tableau @EXPORT_OK, faute de quoi une erreur en résultera.)
Puisque les modules utilisent Exporter pour importer des symboles dans le paquetage courant, vous pouvez utiliser les symboles d'un module sans les qualifier avec le nom du paquetage :
use Fred; # Si Fred.pm contient @EXPORT = qw(pierrafeu)
pierrafeu(); # ...ceci appelle Fred::pierrafeu()Tous les fichiers de module Perl ont l'extension .pm. Ceci (ainsi que les doubles apostrophes) est pris en compte par use ainsi que par require afin que vous n'ayez pas à écrire "MODULE.pm". Cette convention permet de différencier les nouveaux modules des bibliothèques .pl et .ph utilisées dans d'anciennes versions de Perl. Elle définit aussi MODULE comme nom officiel de module, ce qui aide l'analyseur dans certaines situations ambiguës. Tout double deux-points dans le nom de module est traduit comme le séparateur de répertoires de votre système, de sorte que si votre module a pour nom Rouge::Bleu::Vert, Perl pourrait le chercher sous Rouge/Bleu/Vert.pm.
Perl ira chercher vos modules dans tous les répertoires listés dans le tableau @INC. Comme use charge les modules au moment de la compilation, toutes modifications au tableau @INC doivent aussi survenir au moment de la compilation. Vous pouvez faire cela avec le pragma lib, décrit au chapitre 31 ou avec un bloc BEGIN. Une fois qu'un module est inclus, un couple clef/valeur sera ajouté au hachage %INC. La clef sera le nom de fichier du module (Rouge/Bleu/Vert.pm dans notre exemple) et la valeur sera le chemin complet, qui pourrait être quelque chose comme C:/perl/site/lib/Rouge/Bleu/Vert.pm pour un fichier convenablement installé sur un système Windows.
Les noms de module doivent commencer avec une lettre majuscule, sauf s'ils fonctionnent comme pragmas. Les pragmas sont essentiellement des directives de compilation (des conseils pour le compilateur), donc nous réservons les noms de pragma en minuscules pour un usage ultérieur.
Lorsque vous utilisez un module avec use, tout le code du module est exécuté, tout comme il le serait avec un require ordinaire. S'il vous est égal que le module soit pris en compte à la compilation ou à l'exécution, vous pouvez juste dire :
require MODULE;Cependant, en général on préfère use plutôt que require, car il recherche les modules à la compilation, donc vous découvrez les erreurs éventuelles plus tôt. Ces deux instructions font presque la même chose :
Elles diffèrent néanmoins de deux façons. Dans la première instruction, require traduit tout double deux-points en séparateur de répertoire de votre système, tout comme le fait use. La deuxième instruction ne fait pas de traduction, vous obligeant à spécifier explicitement le chemin de votre module, ce qui est moins portable. L'autre différence est que le premier require indique au compilateur que les expressions utilisant la notation objet indirecte avec « MODULE » (comme $ob = purgeMODULE) sont des appels de méthode, pas des appels de fonction. (Si, ça peut réellement faire une différence, s'il y a une définition purge dans votre module qui entre en conflit avec une autre.)
Comme la déclaration use et la déclaration apparentée no impliquent un bloc BEGIN, le compilateur charge le module (et exécute son éventuel code d'initialisation) dès qu'il rencontre cette déclaration, avant de compiler le reste du fichier. C'est ainsi que les pragmas peuvent modifier le comportement du compilateur, et que les modules peuvent déclarer des fonctions qui sont par la suite visibles comme opérateurs de liste pour le reste de la compilation. Ceci ne marchera pas si vous utilisez un require à la place d'un use. La seule raison d'utiliser un require est d'avoir deux modules dont chacun nécessite une fonction de l'autre. (Et nous ne sommes pas sûrs que ce soit une bonne raison.)
Les modules Perl chargent toujours un fichier .pm, mais ce fichier peut à son tour charger des fichiers associés, comme des bibliothèques C ou C++ liées dynamiquement, ou des définitions de fonction Perl autochargées. Dans ce cas, les complications supplémentaires seront entièrement invisibles pour l'utilisateur du module. C'est la responsabilité du fichier .pm de charger (ou de s'arranger pour autocharger) toute fonctionnalité supplémentaire. Il se trouve que le module POSIX fait du chargement dynamique et de l'autochargement, mais l'utilisateur peut simplement dire :
pour avoir accès à toutes les fonctions et variables exportées.
11-2. Création de modules▲
Précédemment, nous avons dit qu'un module a deux façons de mettre son interface à la disposition de votre programme : en exportant des symboles ou en permettant des appels de fonction. Nous vous montrerons un exemple de la première technique ici ; la deuxième technique est utilisée pour les modules orientés objet, et est décrite dans le prochain chapitre. (Les modules orientés objet ne devraient rien exporter, car les méthodes objet ont pour principe que Perl les trouve automatiquement à votre place en se basant sur le type de l'objet.)
Pour construire un module appelé Bestiaire, créez un fichier appelé Bestiaire.pm qui ressemble à ceci :
package Bestiaire;
require Exporter;
our @ISA = qw(Exporter);
our @EXPORT = qw(dromadaire); # Symboles à exporter par défaut
our @EXPORT_OK = qw($poids); # Symboles à exporter à la demande
our $VERSION = 1.00; # Numéro de version
### Mettez vos variables et vos fonctions ici
sub dromadaire { print "Chameau à une seule bosse" }
$poids = 1024;
1;Maintenant un programme peut dire use Bestiaire pour pouvoir accéder à la fonction dromadaire (mais pas à la variable $poids), et use Bestiaire qw(dromadaire $poids) pour accéder à la fois à la fonction et à la variable.
Vous pouvez également créer des modules qui chargent dynamiquement du code écrit en C. Voir le chapitre 21, Mécanismes internes et accès externes, pour plus de détails.
11-2-a. Espace privé de module et Exporter▲
Perl ne patrouille pas automatiquement le long de frontières entre le privé et le public dans ses modules — contrairement à des langages comme C++, Java et Ada, Perl n'est pas obsédé par le droit à la vie privée. Un module Perl préfèrerait que vous restiez hors de son salon parce que vous n'y avez pas été invité, pas parce qu'il a un fusil.
Le module et son utilisateur ont un contrat, dont une partie se base sur la loi coutumière, et dont l'autre est écrite. Une partie du contrat de loi coutumière est qu'un module doit s'abstenir de modifier tout espace de noms qu'on ne lui a pas demandé de modifier. Le contrat écrit du module (c'est-à-dire la documentation) peut prendre d'autres dispositions. Mais vous savez sans doute, après avoir lu le contrat, que quand vous dites use RedefinirLeMonde vous redéfinissez le monde, et vous êtes prêt à en risquer les conséquences. La façon la plus commune de redéfinir des mondes est d'utiliser le module Exporter. Comme nous le verrons plus loin dans ce chapitre, vous pouvez même redéfinir des fonctions Perl de base avec ce module.
Lorsque vous faites appel à un module avec use, le module met habituellement certaines fonctions et variables à la disposition de votre programme, ou plus précisément du paquetage courant de votre programme. Cet acte d'exportation de symboles du module (et donc d'importation dans votre programme) est parfois appelé pollution de votre espace de noms. La plupart des modules utilisent Exporter pour faire cela. C'est pourquoi la plupart des modules disent quelque chose comme ceci vers le début :
Ces deux lignes font hériter au module de la classe Exporter. L'héritage est décrit au prochain chapitre, mais tout ce que vous avez besoin de savoir c'est que notre module Bestiaire peut maintenant exporter des symboles dans d'autres paquetages avec des lignes comme celle-ci :
our @EXPORT = qw($chameau %loup belier); # Exporter par défaut
our @EXPORT_OK = qw(leopard @lama $emeu); # Exporter à la demande
our %EXPORT_TAGS = ( # Exporter en groupe
camelides => [qw($chameau @lama)],
bestiaux => [qw(belier $chameau %loup)],
);Du point de vue du module qui exporte, le tableau @EXPORT contient les noms de variables et de fonctions à exporter par défaut : ce qu'obtient votre programme lorsqu'il dit use Bestiaire. Les variables et les fonctions dans @EXPORT_OK ne sont exportées que lorsque le programme en fait explicitement la demande dans l'instruction use. Enfin, les couples clef/valeur dans %EXPORT_TAGS permettent au programme d'inclure des groupes de symboles spécifiques, listés dans @EXPORT et @EXPORT_OK.
Du point de vue du module qui importe, l'instruction use spécifie la liste des symboles à importer, un groupe nommé %EXPORT_TAGS, un motif de symboles, ou rien du tout, auquel cas les symboles dans @EXPORT seront importés du module dans votre programme.
Vous pouvez inclure l'une quelconque de ces instructions pour importer des symboles du module Bestiaire :
use Bestiaire; # Importer les symboles de @EXPORT
use Bestiaire (); # Ne rien importer
use Bestiaire qw(belier @lama); # Importer la fonction belier et le tableau @lama
use Bestiaire qw(:camelides); # Importer $chameau et @lama
use Bestiaire qw(:DEFAULT); # Importer les symboles de @EXPORT
use Bestiaire qw(/am/); # Importer $chameau et @lama
use Bestiaire qw(/^\$/); # Importer tous les scalaires
use Bestiaire qw(:bestiaux !belier); # Importer bestiaux, mais exclure belier
use Bestiaire qw(:bestiaux !:camelides); # Importer bestiaux, mais pas camelidesOmettre un symbole des listes d'exportation (ou le supprimer explicitement de la liste d'import avec le point d'exclamation) ne le rend pas inaccessible pour le programme qui utilise le module. Le programme pourra toujours accéder au contenu du paquetage du module en le qualifiant avec le nom du paquetage, par exemple %Bestiaire::gecko. (Comme les variables lexicales n'appartiennent pas au paquetage, l'espace privé est possible : voir Méthodes privées au chapitre suivant.)
Vous pouvez dire BEGIN { $Exporter::Verbose=1 } pour voir comment sont gérées les spécifications et pour voir ce qui est réellement importé dans votre paquetage.
Exporter est lui-même un module Perl, et si cela vous intéresse vous pouvez voir les astuces typeglob qui sont utilisées pour exporter des symboles d'un paquetage à un autre. À l'intérieur du module Exporter, la fonction essentielle, appelée import, crée les alias nécessaires pour qu'un symbole d'un paquetage soit visible dans un autre paquetage. En fait, l'instruction use BestiaireLISTE est précisément équivalente à :
Cela veut dire que vos modules ne sont pas obligés d'utiliser Exporter. Un module peut faire ce qui lui plaît, puisque use ne fait qu'appeler la méthode import du module, et vous pouvez définir cette méthode pour qu'elle fasse ce que vous voulez.
11-2-a-i. Exporter sans utiliser la méthode import de Exporter▲
Le module Exporter définit une méthode appelée export_to_level pour les situations où vous ne pouvez pas directement appeler la méthode import de Exporter. La méthode export_to_level est invoquée comme ceci :
MODULE->export_to_level($ou_exporter, @quoi_exporter);L'entier $ou_exporter indique à quelle hauteur dans la pile d'appel exporter vos symboles, et le tableau $quoi_exporter liste les symboles à exporter (habituellement @_).
Par exemple, supposons que notre Bestiaire contienne sa propre fonction import :
package Bestiaire;
@ISA = qw(Exporter);
@EXPORT_OK = qw ($zoo);
sub import {
$Bestiaire::zoo = "ménagerie";
}La présence de cette fonction import empêche d'hériter de la fonction import de Exporter. Si vous vouliez qu'après avoir affecté à $Bestiaire::zoo, la fonction import de Bestiaire se comporte exactement comme la fonction import de Exporter, vous la définiriez de la façon suivante :
Ceci exporte des symboles vers le paquetage situé un niveau « au-dessus » du paquetage courant, c'est-à-dire vers tout programme ou module qui utilise Bestiaire.
11-2-a-ii. Vérification de version▲
Si votre module définit une variable $VERSION, un programme qui utilise votre module peut s'assurer que le module est suffisamment récent. Par exemple :
use Bestiaire 3.14; # Le Bestiaire doit être de version 3.14 ou plus
use Bestiaire v1.0.4; # Le Bestiaire doit être de version 1.0.4 ou plusCes instructions sont converties en appels à Bestiaire->require_version, dont hérite ensuite votre module.
11-2-a-iii. Gestion de symboles inconnus▲
Dans certaines situations, vous voudrez peut-être empêcher l'exportation de certains symboles. Typiquement, c'est le cas de certains modules qui ont des fonctions ou des constantes qui n'ont pas de sens sur certains systèmes. Vous pouvez empêcher Exporter d'exporter ces symboles en les plaçant dans le tableau @EXPORT_FAIL.
Si un programme tente d'importer l'un de ces symboles, Exporter permet au module de gérer la situation avant de produire une erreur. Il le fait en appelant une méthode export_fail avec une liste des symboles qui ont échoué, que vous pouvez définir ainsi (en supposant que votre module utilise le module Carp):
sub export_fail {
my $class = shift;
carp "Désolé, ces symboles ne sont pas disponibles : @_";
return @_;
}Exporter fournit une méthode export_fail par défaut, qui retourne simplement la liste inchangée et fait échouer le use en levant une exception pour chaque symbole. Si export_fail retourne une liste vide, aucune erreur n'est enregistrée et tous les symboles demandés sont exportés.
11-2-a-iv. Fonctions de gestion des étiquettes▲
Comme les symboles listés dans %EXPORT_TAGS doivent également apparaître, soit dans @EXPORT, soit dans @EXPORT_OK, Exporter fournit deux fonctions qui vous permettent d'ajouter ces ensembles de symboles étiquetés.
%EXPORT_TAGS = (foo => [qw(aa bb cc)], bar => [qw(aa cc dd)]);
Exporter::export_tags('foo'); # ajouter aa, bb et cc à @EXPORT
Exporter::export_ok_tags('bar'); # ajouter aa, cc et dd à @EXPORT_OKC'est une erreur de spécifier des noms qui ne sont pas des étiquettes.
11-3. Supplanter des fonctions internes▲
De nombreuses fonctions internes peuvent être supplantées, bien que (comme pour faire des trous dans vos murs) vous ne devriez faire cela que rarement et pour de bonnes raisons. Typiquement, ce serait fait par un paquetage qui tente d'émuler des fonctions internes manquantes sur un système autre qu'Unix. (Ne confondez pas supplanter avec surcharger, qui ajoute des significations orientées objet supplémentaires aux opérateurs internes, mais ne supplante pas grand-chose. Le module overload dans le chapitre 13, Surcharge, donne plus de détails sur ce sujet.)
On ne peut supplanter qu'en important le nom d'un module ; la prédéclaration ordinaire ne suffit pas. Pour être parfaitement francs, c'est l'affectation d'une référence de code à un typeglob qui permet à Perl de supplanter, comme dans *open = \&myopen. De plus, l'affectation doit survenir dans un autre paquetage ; ceci rend intentionnellement difficile de supplanter accidentellement par alias de typeglob. Malgré tout, si vous voulez vraiment supplanter vous-même, ne désespérez pas, car le pragma subs vous permet de prédéclarer des fonctions avec la syntaxe d'importation, et ces noms supplantent alors ceux qui existent en interne :
En général, les modules ne doivent pas exporter des noms internes comme open ou chdir comme partie de leur liste @EXPORT par défaut, puisque ces noms pourraient se glisser dans l'espace de noms de quelqu'un d'autre et en changer le contenu de façon inattendue. Si au lieu de cela le module inclut le nom dans la liste @EXPORT_OK, les importateurs seront obligés de demander explicitement que le nom interne soit supplanté, évitant ainsi les surprises.
La version d'origine des fonctions internes est toujours accessible via le pseudo-paquetage CORE. En conséquence, CORE::chdir sera toujours la version compilée d'origine dans Perl, même si le mot-clef chdir a été supplanté.
Enfin, presque toujours. Le mécanisme décrit ci-dessus pour supplanter les fonctions internes est restreint, très délibérément, au paquetage qui fait la demande d'importation. Mais il existe un mécanisme plus radical que vous pouvez utiliser lorsque vous souhaitez supplanter une fonction interne partout, sans prendre en compte les frontières d'espaces de noms. Ceci est accompli en définissant la fonction dans le pseudo-paquetage CORE::GLOBAL. Voyez ci-dessous un exemple qui supplante l'opérateur glob avec quelque chose qui comprend les expressions rationnelles. (Notez que cet exemple n'implémente pas tout ce qui est nécessaire pour supplanter proprement le glob interne de Perl, qui se comporte différemment selon qu'il apparaît dans un contexte scalaire ou un contexte de liste. En vérité, de nombreuses fonctions internes de Perl ont de tels comportements sensibles au contexte, et toute fonction visant à les correctement supplanter une fonction interne doit gérer adéquatement ces comportements. Pour voir un exemple complètement fonctionnel où glob est supplanté, étudiez le module File::Glob inclus avec Perl.) En tout cas, voici la version antisociale :
*CORE::GLOBAL::glob = sub {
my $motif = shift;
my @trouve;
local *D;
if (opendir D, '.') {
@trouve = grep /$motif/, readdir D;
closedir D;
}
return @trouve;
}
package Quelconque;
print <^[a-z_]+\.pm\$>; # montrer tous les pragmas dans le répertoire courantEn supplantant glob globalement, ceci impose un nouveau (et subversif) comportement pour l'opérateur glob dans tous les espaces de noms, sans la connaissance ou la coopération des modules propriétaires de ces espaces de noms. Bien sûr, s'il faut faire cela, il faut le faire avec la plus extrême prudence. Et probablement il ne faut pas le faire.
Nous supplantons avec le principe suivant : c'est sympa d'être important, mais c'est plus important d'être sympa.
12. Objets▲
Pour commencer, vous devez comprendre les paquetages et les modules ; voir le chapitre 10, Paquetages, et le chapitre 11, Modules. Vous devez aussi connaître les références et les structures de données ; voir le chapitre 8, Références, et le chapitre 9, Structures de données. Comme il est utile de s'y connaître un peu en programmation orientée objet, nous vous donnerons un petit cours de vocabulaire orienté objet dans la section suivante.
12-1. Bref rappel de vocabulaire orienté objet▲
Un objet est une structure de données munie d'une collection de comportements. Nous dirons parfois qu'un objet agit directement sur la base de comportements, allant parfois jusqu'à l'anthropomorphisme. Par exemple, nous dirons qu'un rectangle « sait » comment s'afficher à l'écran ou qu'il « sait » comment calculer sa propre surface.
Un objet exhibe des comportements en étant une instance d'une classe. La classe définit des méthodes : des comportements qui s'appliquent à la classe et à ses instances. Lorsqu'il faut faire la distinction, nous appelons méthode d'instance une méthode qui ne s'applique qu'à un objet donné et méthode de classe une méthode qui s'applique à la classe dans son entier. Mais ce n'est qu'une convention : pour Perl, une méthode n'est qu'une méthode qui ne se distingue que par le type de son premier argument.
Vous pouvez considérer qu'une méthode d'instance est une action exécutée par un objet donné, comme l'action de s'afficher, de se copier ou de modifier une ou plusieurs de ses propriétés (« affecter Anduril au nom de cette épée »). Les méthodes de classe peuvent exécuter des opérations sur un ensemble d'objets (« afficher toutes les épées ») ou fournir d'autres opérations qui ne dépendent pas d'un objet particulier (« à partir de maintenant, à chaque fois qu'une nouvelle épée est forgée, enregistrer dans cette base de données le nom de son propriétaire »). Les méthodes qui produisent des instances (ou objets) d'une classe sont appelées constructeurs (« créer une épée incrustée de pierres précieuses et avec une inscription secrète »). Celles-ci sont en général des méthodes de classe (« fais-moi une nouvelle épée »), mais elles peuvent aussi être des méthodes d'instance (« fais-moi une copie exacte de cette épée-ci »).
Une classe peut hériter des méthodes de classes parentes, appelées aussi classes de base ou surclasses. Dans ce cas, on l'appelle classe dérivée ou sous-classe. (Brouillant un peu les cartes, certains livres entendent par « classe de base » la surclasse « racine », mais ce n'est pas ce que nous voulons dire.) Lorsque vous invoquez une méthode dont la définition ne se trouve pas dans la classe, Perl consulte automatiquement les classes parentes pour chercher une définition. Par exemple, une classe « épée » pourrait hériter sa méthode attaquer d'une classe générique « arme d'estoc et de taille ». Les classes parentes peuvent elles-mêmes avoir des classes parentes, et Perl examinera également ces classes si besoin est. La classe « arme d'estoc et de taille » peut à son tour hériter la méthode attaquer d'une classe encore plus générique « arme ».
Lorsque la méthode attaquer est invoquée sur un objet, le comportement résultant peut varier, selon que l'objet est une épée ou une flèche. Il se peut qu'il n'y ait aucune différence, ce qui serait le cas si les épées et les flèches héritaient leur comportement d'attaque de la classe arme générique. Mais s'il y avait une différence de comportement, le mécanisme d'acheminement de méthode sélectionnerait toujours la méthode attaquer la plus appropriée pour le type d'objet donné. Cette propriété fort utile de sélection du comportement le plus approprié pour un type donné d'objet s'appelle le polymorphisme. C'est une façon importante de ne se soucier de rien.
Vous devez vous soucier des entrailles de vos objets lorsque vous implémentez une classe, mais lorsque vous utilisez une classe (avec use), vous devriez traiter vos objets comme des « boîtes noires ». Vous ne voyez pas ce qu'il y a à l'intérieur, vous n'avez pas besoin de savoir comment ça marche, et vous interagissez avec la boîte sur ses termes : par les méthodes fournies par la classe. C'est comme la télécommande de votre téléviseur : même si vous savez ce qui se passe dedans, vous ne devriez pas sans bonne raison trifouiller dans ses entrailles.
Perl vous permet de scruter l'intérieur d'un objet de l'extérieur de la classe lorsque vous en avez besoin. Mais de faire ainsi enfreint l'encapsulation, le principe qui sépare l'interface publique (comment un objet doit être utilisé) de l'implémentation (comment l'objet fonctionne en réalité). Perl ne fournit pas un dispositif d'interface explicite, mis à part le contrat implicite entre le concepteur et l'utilisateur. L'un et l'autre sont censés être raisonnables et respectueux : l'utilisateur en ne dépendant que de l'interface documentée, le concepteur en préservant cette interface.
Perl ne vous impose pas un style de programmation particulier, et ne partage pas l'obsession avec la vie privée d'autres langages de programmation orientée objet. Néanmoins Perl a l'obsession de la liberté, et l'une de vos libertés en tant que programmeur Perl est le droit de choisir si vous voulez beaucoup ou peu de vie privée. En fait, Perl permet un espace privé plus restrictif encore que C++. C'est-à-dire qu'il n'y a rien que Perl vous empêche de faire, et en particulier il ne vous empêche pas de vous empêcher vous-même, si ce genre de choses vous intéresse. Les sections Méthodes privées et Utilisation de fermetures pour objets privés de ce chapitre vous montrent comment vous pouvez augmenter votre dose de discipline.
Reconnaissons qu'il y a beaucoup plus à dire sur les objets, et beaucoup de façons d'en apprendre plus sur la conception orientée objet. Mais ce n'est pas notre propos. Continuons donc.
12-2. Le système objet de Perl▲
Perl ne fournit pas de syntaxe objet particulière pour définir les objets, les classes ou les méthodes. Au lieu de cela, il réutilise des constructions existantes pour implémenter ces trois notions.(112)
Voici quelques définitions simples que vous trouverez peut-être rassurantes :
Un objet n'est qu'une référence... enfin, un référent.
- Comme une référence permet de représenter une collection de données avec un seul scalaire, il ne devrait pas être surprenant qu'on utilise les références pour tous les objets. Pour être précis, un objet n'est pas la référence elle-même, mais plutôt le référent sur lequel pointe la référence. Toutefois cette distinction est souvent brouillée par les programmeurs Perl, et comme nous trouvons que c'est une jolie métonymie, nous la perpétuons ici lorsque cela nous arrange(113).
Une classe n'est qu'un paquetage.
- Un paquetage agit comme une classe en utilisant les fonctions du paquetage pour exécuter les méthodes de la classe et en utilisant les variables du paquetage pour contenir les données globales de la classe. Souvent, on utilise un module pour contenir une ou plusieurs classes.
Une méthode n'est qu'une fonction.
- Vous déclarez simplement des fonctions dans le paquetage que vous utilisez comme classe ; celles-ci seront ensuite utilisées comme méthodes de la classe. L'invocation de méthode, une nouvelle façon d'appeler une fonction, ajoute un paramètre supplémentaire : l'objet ou le paquetage utilisé pour invoquer la méthode.
12-3. Invocation de méthode▲
Si vous aviez à réduire toute la programmation orientée objet à une notion essentielle, ce serait l'abstraction. C'est le fil conducteur de tous ces mots ronflants qu'aiment employer les enthousiastes OO, comme le polymorphisme, l'héritage et l'encapsulation. Nous croyons en ces mots savants, mais nous les traiterons du point de vue pratique de ce que signifie invoquer des méthodes. Les méthodes sont au cœur des systèmes objet parce qu'elles fournissent la couche d'abstraction nécessaire à l'implémentation de ces termes savants. Au lieu d'accéder directement à une donnée résidant dans un objet, vous invoquez une méthode d'instance. Au lieu d'appeler directement une fonction dans un paquetage, vous invoquez une méthode de classe. En interposant un niveau d'indirection entre l'utilisation d'une classe et son implémentation, le concepteur de programme reste libre de bricoler le fonctionnement interne de la classe, sans grand risque d'invalider des programmes qui l'utilisent.
Perl permet deux formes syntaxiques différentes pour invoquer les méthodes. L'une utilise le style familier que vous avez déjà vu ailleurs en Perl, et la seconde est une forme que vous aurez peut-être déjà rencontrée dans d'autres langages de programmation. Quelle que soit la forme d'invocation de méthode utilisée, un paramètre initial supplémentaire est passé à la fonction servant de méthode. Si une classe est utilisée pour invoquer la méthode, ce paramètre sera le nom de la classe. Si un objet est utilisé pour invoquer la méthode, ce paramètre sera la référence à l'objet. Quel que soit ce paramètre, nous l'appellerons invoquant de la méthode. Pour une méthode de classe, l'invoquant est le nom d'un paquetage. Pour une méthode d'instance, l'invoquant est la référence qui spécifie un objet.
En d'autres termes, l'invoquant est ce avec quoi la méthode a été invoquée. Certains livres OO l'appellent l'agent ou l'acteur de la méthode. D'un point de vue grammatical, l'invoquant n'est ni le sujet de l'action ni son destinataire. Il est plutôt comme un objet indirect, le bénéficiaire au nom duquel l'action est exécutée — tout comme le mot « moi » dans la commande « Forge-moi une épée ! ». Sémantiquement vous pouvez voir l'invoquant comme ce qui invoque ou ce qui est invoqué, selon ce qui correspond mieux à votre appareil mental. Nous n'allons pas vous dire comment penser. (Pas sur ce sujet-là, en tout cas.)
La plupart des méthodes sont invoquées explicitement, mais des méthodes peuvent aussi être invoquées implicitement lorsqu'elles sont déclenchées par un destructeur d'objet, un opérateur surchargé ou une variable liée. Ce ne sont pas à proprement parler des appels de fonction ordinaires, mais plutôt des invocations de méthode déclenchées automatiquement par Perl au nom de l'objet. Les destructeurs sont décrits plus loin dans ce chapitre, la surcharge est décrite dans le chapitre 13, Surcharge, et les variables liées sont décrites dans le chapitre 14, Variables liées.
Les méthodes et les fonctions normales diffèrent par le moment auquel leur paquetage est résolu — c'est-à-dire, le moment où Perl décide quel code doit être exécuté pour la méthode ou la fonction. Le paquetage d'une fonction est résolu à la compilation, avant que le programme ne commence à s'exécuter.(114) Au contraire, le paquetage d'une méthode n'est résolu que lorsqu'elle est effectivement invoquée. (Les prototypes sont vérifiés à la compilation, c'est pourquoi les fonctions normales peuvent les utiliser, mais les méthodes ne le peuvent pas.)
La raison pour laquelle le paquetage d'une méthode ne peut pas être résolu plus tôt est relativement évidente : le paquetage est déterminé par la classe de l'invoquant, et l'invoquant n'est pas connu tant que la méthode n'a réellement été invoquée. Au cœur de l'OO est cette simple chaîne logique : si on connaît l'invoquant, on connaît la classe de l'invoquant ; si on connaît la classe, on connaît l'héritage de la classe ; si on connaît l'héritage de la classe, on connaît la fonction à appeler.
La logique de l'abstraction a un coût. À cause de la résolution tardive des méthodes, une solution orientée objet en Perl risque de s'exécuter plus lentement que la solution non-OO correspondante. Pour certaines des techniques sophistiquées décrites plus loin, elle pourrait être beaucoup plus lente. Toutefois, la solution de beaucoup de problèmes n'est pas de travailler plus vite, mais de travailler plus intelligemment. C'est là que brille l'OO.
12-3-a. Invocation de méthode avec l'opérateur flèche▲
Nous avons indiqué qu'il existe deux styles d'invocation de méthode. Le premier style se présente comme ceci :
INVOQUANT->METHODE(LISTE)
INVOQUANT->METHODEPour des raisons évidentes, ce style est habituellement appelé la forme f lèche d'invocation. (Ne confondez pas -> avec =>, la flèche « à deux coups » utilisée comme virgule de luxe.) Les parenthèses sont exigées s'il y a des paramètres. Lorsqu'elle est exécutée, l'invocation commence par trouver la fonction déterminée conjointement par la classe de l'INVOQUANT et par le nom de la METHODE, lui passant INVOQUANT comme premier paramètre.
Lorsque INVOQUANT est une référence, nous disons que METHODE est invoquée comme méthode d'instance, et lorsque INVOQUANT est un nom de paquetage, nous disons que METHODE est invoquée comme méthode de classe. Il n'y a en réalité aucune différence entre les deux, mis à part que le nom de paquetage est plus clairement associé à la classe elle-même qu'avec les objets de la classe. Vous allez devoir nous faire confiance lorsque nous disons que les objets connaissent leur classe. Nous vous dirons bientôt comment associer un objet à un nom de classe, mais vous pouvez utiliser les objets sans savoir cela.
Par exemple, pour construire un objet avec la méthode de classe invoquer puis invoquer la méthode d'instance dire sur l'objet résultant, vous pourriez dire ceci :
$mage = Magicien->invoquer("Gandalf"); # méthode de classe
$mage->dire("ami"); # méthode d'instanceLes méthodes invoquer et dire sont définies par la classe Magicien ---ou par une des classes dont elle hérite. Mais ne vous inquiétez pas de cela. Ne vous mêlez pas des affaires de Magiciens.
Comme l'opérateur flèche est associatif vers la gauche (voir le chapitre 3, Opérateurs unaires et binaires), vous pouvez même combiner les deux instructions :
Magicien->invoquer("Gandalf")->dire("ami");Parfois vous souhaiterez invoquer une méthode sans connaître son nom par avance. Vous pouvez utiliser la forme flèche d'invocation et remplacer le nom de méthode avec une simple variable scalaire :
$methode = "invoquer";
$mage = Magicien->$methode("Gandalf"); # Invoquer Magicien->invoquer
$voyager = $compagnon eq "Grispoil" ? "monter" : "marcher";
$mage->$voyager("sept lieues"); # Invoquer $mage->monter ou
# $mage->marcherBien que vous utilisiez le nom d'une méthode pour l'invoquer indirectement, cet usage n'est pas interdit par use strict 'refs', car tous les appels de méthode sont en fait recherchés par symbole au moment où ils sont résolus.
Dans notre exemple, nous stockons le nom d'une fonction dans $voyager, mais vous pourriez aussi stocker une référence de fonction. Ceci contourne l'algorithme de recherche de méthode, mais parfois c'est exactement ce que vous voulez faire. Voir la section Méthodes privées et la discussion de la méthode can dans la section UNIVERSAL : la classe ancêtre ultime. Pour créer une référence à la méthode spécifique d'appel pour une instance spécifique, voir la section Fermetures dans le chapitre 8.
12-3-b. Invocation de méthode avec des objets indirects▲
Le second style d'invocation de méthode se présente comme ceci :
y
METHODE INVOQUANT (LISTE)
METHODE INVOQUANT LISTE
METHODE INVOQUANTLes parenthèses autour de LISTE sont optionnelles ; si elles sont omises, la méthode se comporte comme un opérateur de liste. Vous pouvez donc avoir des instructions comme les suivantes, toutes utilisant ce style d'appel de méthode :
$mage = invoquer Magicien "Gandalf";
$nemesis = invoquer Balrog demeure => "Moria", arme => "fouet";
deplacer $nemesis "pont";
dire $mage "Tu ne peux pas passer";
briser $baton; # il est plus sûr d'utiliser : briser $baton ()La syntaxe d'opérateur de liste devrait vous être familière, car c'est le même style qu'on utilise pour passer des handles de fichiers à print ou à printf :
print STDERR "au secours !!!\n";Elle est également similaire à des phrases en français comme « Donner (à) Gollum le trésor », donc nous l'appelons la forme avec objet indirect. L'invoquant est attendu dans la case d'objet indirect. Lorsqu'il est fait mention de passer quelque chose à une fonction interne comme system ou exec dans sa « case d'objet indirect », cela veut dire que vous fournissez ce paramètre supplémentaire et dépourvu de virgule au même endroit que vous le feriez si vous invoquiez une méthode avec la syntaxe d'objet indirect.
La forme avec objet indirect vous permet même de spécifier que l'INVOQUANT soit un BLOC évaluable comme objet (référence) ou comme classe (paquetage). Ce qui vous permet de combiner deux invocations en une instruction ainsi :
dire { invoquer Magicien "Gandalf" } "ami";12-3-c. Pièges syntaxiques avec les objets indirects▲
Une syntaxe sera souvent plus lisible que l'autre. La syntaxe d'objet indirect est moins lourde, mais souffre de plusieurs sortes d'ambiguïté syntaxique. La première est que la partie LISTE d'une invocation avec objet indirect est analysée de la même façon que tout autre opérateur de liste. Ainsi, les parenthèses de :
enchanter $epee ($points + 2) * $cout;sont censées entourer tous les paramètres, quel que soit ce qui suit. Cela équivaut à :
($epee->enchanter($points + 2)) * $cout;Cela ne fait probablement pas ce que vous pensez : enchanter n'est appelée qu'avec $points + 2, et la valeur de retour de la méthode est ensuite multipliée par $cout. Comme avec d'autres opérateurs de liste, vous devez faire attention à la précédence de && et de || par rapport à and et à or.
Par exemple ceci :
appeler $epee $ancien_nom || "Glamdring"; # ne pas utiliser "or" ici !devient comme prévu :
$epee->appeler($ancien_nom || "Glamdring");mais ceci :
dire $mage "ami" && entrer(); # il aurait fallu "and" ici !devient le douteux :
$mage->dire("ami" && entrer());qui pourrait être corrigé en récrivant avec une des formes équivalentes :
entrer() if $mage->dire("ami");
$mage->dire("ami") && entrer();
dire $mage "ami" and entrer();Le deuxième ennui syntaxique de la forme avec objet indirect est que l'INVOQUANT ne peut être qu'un nom, une variable scalaire non indicée ou un bloc.(115) Dès que l'analyseur voit une de ces choses, il a son INVOQUANT, donc il commence à chercher sa LISTE. Ainsi ces invocations :
deplacer $groupe->{CHEF}; # probablement faux !
deplacer $cavaliers[$i]; # probablement faux !sont en fait analysées comme celles-ci :
$groupe->deplacer->{CHEF};
$cavaliers->deplacer([$i]);au lieu de ce que vous vouliez sans doute :
$groupe->{CHEF}->deplacer;
$cavaliers[$i]->deplacer;L'analyseur ne regarde qu'un petit peu vers l'avant pour trouver l'invoquant d'un objet indirect, pas même aussi loin qu'il ne regarderait dans le cas d'un opérateur unaire. Cette bizarrerie n'a pas lieu avec la première forme syntaxique, donc vous souhaiterez peut-être faire de la f lèche votre arme de choix.
Même en français il peut se poser un problème similaire. Pensez à l'instruction : « Envoyez-moi par la poste la lettre pour que je la lise ». Si vous analysez cette phrase trop vite, vous finirez par envoyer quelqu'un, et non pas une lettre, par la poste. Comme Perl, le français a parfois deux syntaxes différentes pour décrire un agent : « Envoyez-moi la lettre » et « Envoyez la lettre à moi ». Parfois la forme plus longue est plus claire et plus naturelle, et parfois c'est le contraire. Au moins en Perl, vous êtes obligé d'utiliser des accolades autour d'un objet indirect complexe.
12-3-d. Classes à paquetage explicite▲
La dernière ambiguïté syntaxique du style d'invocation de méthode avec objet indirect est qu'elle peut ne pas du tout être analysée comme appel de méthode, parce que le paquetage courant peut contenir une fonction ayant le même nom que la méthode. Lorsque vous utilisez une méthode de classe avec un nom de paquetage littéral comme invoquant, il y a moyen de résoudre cette ambiguïté tout en gardant la syntaxe d'objet indirect : explicitez le nom de paquetage en y ajoutant un double deux-points.
$obj = methode CLASSE::; # imposer "CLASSE"->methodeCeci est important, car la notation courante :
$obj = new CLASSE; # pourrait ne pas être analysé comme méthodene se comportera pas toujours correctement si le paquetage courant comporte une fonction nommée new ou CLASSE. Même si prudemment vous utilisez la forme avec flèche au lieu de la forme avec objet indirect pour invoquer des méthodes, ceci peut, rarement, rester un problème. Au prix d'un peu plus de ponctuation, la notation CLASSE:: garantit comment Perl analysera votre invocation de méthode. Dans les exemples suivants, les deux premiers ne sont pas toujours analysés de la même façon, mais les deux derniers le sont :
$obj = new AnneauElfique; # pourrait être new("AnneauElfique")
# ou même new(AnneauElfique())
$obj = AnneauElfique->new; # pourrait être AnneauElfique()->new()
$obj = new AnneauElfique::; # toujours "AnneauElfique"->new()
$obj = AnneauElfique::->new; # toujours "AnneauElfique"->new()Cette notation de paquetage explicite peut être enjolivée avec un peu d'alignement :
$obj = new AnneauElfique::
nom => "Narya",
proprietaire => "Gandalf",
domaine => "feu",
pierre => "rubis";Néanmoins, vous vous exclamerez peut-être « Qu'il est laid ! » en voyant ce double deux-points, donc nous vous dirons que vous pouvez presque toujours vous en sortir avec un simple nom de classe, à deux conditions. Premièrement, qu'il n'y ait pas de fonction avec le même nom que la classe. (Si vous observez la convention que les noms de fonction comme new commencent avec une lettre minuscule, et que les noms de classe comme AnneauElfique commencent avec une majuscule, ceci ne posera jamais de problème.) Deuxièmement, que la classe soit chargée avec l'une des instructions suivantes :
Chacune de ces déclarations assure que Perl sait que AnneauElfique est un nom de module, ce qui oblige tout nom simple comme new avant le nom de classe AnneauElfique à être interprété comme un appel de méthode, même s'il se trouve que vous avez vous-même déclaré une fonction new dans le paquetage courant. On ne rencontre habituellement de problème avec les objets indirects que si l'on entasse plusieurs classes dans un même fichier, auquel cas Perl ne sait pas forcément qu'un paquetage spécifique était censé être un nom de classe. Ceux qui nomment des fonctions avec des noms qui ressemblent à NomsDeModule finissent également par le regretter un jour ou l'autre.
12-4. Construction d'objet▲
Tout objet est une référence, mais toute référence n'est pas un objet. Une référence ne fonctionnera comme objet que si son référent est marqué spécialement pour dire à Perl à quel paquetage il appartient. On appelle consacrer (du sens anglais de la fonction bless) l'acte de marquer un référent avec le nom d'un paquetage — et donc de sa classe, puisqu'une classe n'est qu'un paquetage. Vous pouvez considérer que consacrer une référence la transforme en objet, bien qu'il soit plus précis de dire que cela transforme la référence en référence à un objet.
La fonction bless prend un ou deux paramètres. Le premier paramètre est une référence et le deuxième est le paquetage avec lequel est consacré le référent. Si le deuxième paramètre est omis, c'est le paquetage courant qui est utilisé.
$obj = { }; # Obtenir une référence à un hachage anonyme.
bless($obj); # Consacrer le hachage avec le paquetage courant.
bless($obj, "Bestiau"); # Consacrer le hachage avec la classe Bestiau.Ici nous avons utilisé une référence à un hachage anonyme, ce que les gens utilisent habituellement comme structure de données pour leurs objets. Les hachages sont après tout extrêmement flexibles. Mais permettez-nous de souligner que vous pouvez consacrer une référence à toute chose à laquelle vous pouvez faire une référence en Perl, comme les scalaires, les tableaux, les fonctions et les typeglobs. Vous pouvez même consacrer une référence au hachage de la table de symboles d'un paquetage si vous trouvez une bonne raison de le faire. (Ou même si vous n'en trouvez pas.) L'orientation objet de Perl est entièrement distincte de la structure des données.
Une fois que le référent est consacré, l'appel de la fonction interne ref sur sa référence retourne le nom de la classe consacrée au lieu du type de base, comme HASH. Si vous voulez le type de base, utilisez la fonction reftype du module attributes. Voir use attributes dans le chapitre 31, Modules de pragmas.
Voilà comment créer un objet. Prenez simplement une référence à quelque chose, donnez-lui une classe en la consacrant avec un paquetage, et vous avez terminé. C'est tout ce que vous avez à faire si vous créez une classe minimale. Si vous utilisez une classe, vous avez encore moins à faire, car l'auteur de la classe aura caché le bless à l'intérieur d'une fonction nommée constructeur, qui crée et retourne des instances de la classe. Comme bless retourne son premier paramètre, un constructeur typique peut être aussi simple que ceci :
Ou, pour être un peu plus explicite :
package Bestiau;
sub engendrer {
my $self = {}; # Référence à un hachage anonyme vide
bless $self, "Bestiau"; # Faire de ce hachage un objet Bestiau
return $self; # Retourner le Bestiau nouvellement créée
}Muni de cette définition, voici comment on pourrait créer un objet Bestiau :
$animal = Bestiau->engendrer;12-4-a. Constructeurs héritables▲
Comme toutes les méthodes, un constructeur n'est qu'une fonction, mais nous ne l'appelons pas fonction. Nous l'invoquons toujours comme méthode — ici une méthode de classe, car l'invoquant est un nom de paquetage. Les invocations de méthode diffèrent des appels de fonctions normales de deux façons. Premièrement, elles reçoivent un paramètre supplémentaire, comme indiqué précédemment. Deuxièmement, elles obéissent à l'héritage, permettant ainsi à une classe d'utiliser les méthodes d'une autre.
Nous décrirons plus rigoureusement la mécanique sous-jacente de l'héritage dans la section suivante, mais pour l'instant, quelques exemples simples de ses effets devraient vous permettre de créer vos constructeurs. Par exemple, supposons que nous avons une classe Araignee qui hérite des méthodes de la classe Bestiau. En particulier, supposons que la classe Araignee ne possède pas sa propre méthode engendrer. On obtient les correspondances suivantes :
|
Appel de méthode |
Appel de fonction résultant |
|---|---|
|
Bestiau |
Bestiau::engendrer( |
|
Araignee |
Bestiau::engendrer( |
La fonction appelée est la même dans les deux cas, mais le paramètre est différent. Notez que notre constructeur engendrer ne prêtait aucune attention à son paramètre, ce qui signifie que notre objet Araignee était incorrectement consacré avec la classe Bestiau. Un meilleur constructeur fournirait le nom du paquetage (passé comme premier paramètre) à bless :
sub engendrer {
my $classe = shift; # Enregistrer le nom de paquetage
my $self = { };
bless($self, $classe); # Consacrer la référence avec ce paquetage
return $self;
}Maintenant vous pourriez utiliser la même fonction pour les deux cas :
$vermine = Bestiau->engendrer;
$shelob = Araignee->engendrer;Et chaque objet serait de la classe appropriée. Ceci fonctionne même indirectement, par exemple :
$type = "Araignee";
$shelob = $type->engendrer; # pareil que "Araignee"->engendrerCela reste une méthode de classe, pas une méthode d'instance, parce que son invoquant contient une chaîne et non une référence.
Si $type était un objet au lieu d'un nom de classe, la définition de constructeur ci-dessus ne fonctionnerait pas, car bless nécessite un nom de classe. Mais pour beaucoup de classes, il est intéressant d'utiliser un objet existant comme modèle pour la création d'un nouvel objet. Dans ces cas, vous pouvez définir vos constructeurs de façon à ce qu'ils fonctionnent à la fois avec des objets ou avec des noms de classe :
12-4-b. Initialiseurs▲
La majorité des objets gèrent des informations internes qui sont indirectement manipulées par les méthodes de l'objet. Tous nos constructeurs jusqu'à maintenant ont créé des hachages vides, mais il n'y a pas de raison de les laisser vides. Par exemple, un constructeur pourrait accepter des paramètres supplémentaires à ranger dans le hachage comme couples clef/valeur. Les livres OO appellent souvent de telles données propriétés, attributs, accesseurs, données membres, données d'instance ou variables d'instance. La section Gestion des données d'instance plus loin dans ce chapitre donne plus de détails sur les attributs.
Imaginez une classe Cheval avec des attributs d'instance comme « nom » et « couleur » :
$monture = Cheval->new(nom => "Grispoil", couleur => "blanc");Si l'objet est implémenté comme référence à un hachage, les couples clef/valeur peuvent être interpolés directement dans le hachage une fois que l'invoquant est supprimé de la liste des paramètres :
sub new {
my $invoquant = shift;
my $classe = ref($invoquant) || $invoquant;
my $self = { @_ }; # Les paramètres restants deviennent des attributs
bless($self, $classe); # Transformer en objet
return $self;
}Cette fois-ci nous avons utilisé une méthode appelée new comme constructeur de la classe, ce qui pourrait bien donner aux programmeurs C++ l'impression de savoir ce qui se passe. Mais Perl ne considère pas « new » comme étant quelque chose de spécial ; vous pouvez nommer vos constructeurs comme vous voulez. Toute méthode qui crée et retourne un objet est de fait un constructeur. En général, nous vous recommandons de donner à vos constructeurs des noms qui correspondent au contexte du problème que vous résolvez. Par exemple, les constructeurs du module Tk ont le même nom que le widget qu'ils créent. Dans le module DBI, un constructeur nommé connect retourne un objet handle de base de données, et un autre constructeur nommé prepare est invoqué comme méthode d'instance et retourne un objet handle de statement. Mais s'il n'y a pas de nom de constructeur qui convienne au contexte, new n'est peut-être pas un mauvais choix. Cela dit, ce n'est peut-être pas une si mauvaise chose de choisir au hasard un nom pour obliger les gens à lire le contrat d'interface (c'est-à-dire la documentation de la classe) avant d'utiliser ses constructeurs.
Vous pouvez aussi configurer votre constructeur avec des couples clef/valeur par défaut, que l'utilisateur peut supplanter en les passant comme paramètres :
sub new {
my $invoquant = shift;
my $classe = ref($invoquant) || $invoquant;
my $self = {
couleur => "bai",
pattes => 4,
proprietaire => undef,
@_, # Supplanter les attributs précédents
};
return bless $self, $classe;
}
$ed = Cheval->new; # Un cheval bai à 4 pattes
$etalon = Cheval->new(couleur => "noir"); # Un cheval noir à 4 pattesCe constructeur de Cheval ne prête pas attention aux attributs existants de son invoquant lorsqu'il est utilisé comme méthode d'instance. Vous pourriez créer un deuxième constructeur conçu pour être appelé comme méthode d'instance, et s'il était conçu correctement, vous pourriez utiliser les valeurs de l'objet invoquant comme valeurs par défaut du nouvel objet :
$monture = Cheval->new(couleur => "gris");
$poulain = $monture->clone(proprietaire => "EquuGen Guild, Ltd.");
sub clone {
my $modele = shift;
my $self = $modele->new(%$modele, @_);
return $self; # Déjà consacré par ->new
}(Vous auriez également pu intégrer cette fonction directement dans new, mais alors le nom ne correspondrait plus tout à fait à son rôle.)
Remarquez comment, même dans le constructeur clone, nous ne codons pas en dur le nom de la classe Cheval. Ainsi l'objet d'origine invoque sa méthode new, quelle qu'elle soit. Si nous avions écrit cela Cheval->new au lieu de $modele->new, la classe n'aurait pas facilité l'héritage par une classe Zebre ou une classe Licorne. Il serait dommage de cloner Pégase et de se retrouver avec un vulgaire bidet.
Cependant, parfois vous avez le problème contraire : au lieu de partager un même constructeur entre plusieurs classes, vous essayez de faire partager l'objet d'une même classe entre plusieurs constructeurs. Cela se passe à chaque fois qu'un constructeur veut appeler le constructeur d'une classe de base pour faire une partie du travail de construction. Perl ne fait pas de construction hiérarchique à votre place. C'est-à-dire que Perl n'appelle pas automatiquement les constructeurs (ou les destructeurs) des classes de base de la classe en question, donc votre constructeur devra faire cela lui-même et ensuite rajouter tout autre attribut dont a besoin la classe dérivée. Donc la situation est similaire à la méthode clone, sauf qu'au lieu de copier un objet existant vers un nouvel objet, vous voulez appeler le constructeur de votre classe de base et ensuite transformer le nouvel objet de base en votre nouvel objet dérivé.
12-5. Héritage de classe▲
Comme pour le reste du système objet de Perl, l'héritage d'une classe par une autre ne nécessite l'ajout au langage d'aucune syntaxe particulière. Lorsque vous invoquez une méthode pour laquelle Perl ne trouve pas de fonction dans le paquetage de l'invoquant, le tableau @ISA(116) de ce paquetage est examiné. C'est ainsi que Perl implémente l'héritage : chaque élément du tableau @ISA d'un paquetage donné contient le nom d'un autre paquetage, dans lequel est faite une recherche lorsque manquent des méthodes. Par exemple, ce qui suit fait de la classe Cheval une sous-classe de la classe Bestiau. (Nous déclarons @ISA avec our parce qu'il doit être une variable de paquetage, pas une variable lexicale déclarée avec my.)
Vous devriez maintenant pouvoir utiliser un objet ou une classe Cheval partout où Bestiau était utilisé. Si votre classe réussit ce test de sous-classe vide, vous savez que Bestiau est une classe de base correcte, apte à l'héritage.
Supposons que vous avez un objet Cheval dans $monture et que vous invoquez une méthode deplacer dessus :
$monture->deplacer(10);Comme $monture est un Cheval, le premier choix de Perl pour cette méthode est la fonction Cheval::deplacer. S'il n'y en a pas, au lieu de lever une exception à l'exécution, Perl consulte d'abord le premier élément du tableau @Cheval::ISA, qui lui indique de chercher Bestiau::deplacer dans le paquetage Bestiau. Si cette fonction n'est pas trouvée non plus, et que Bestiau a son propre tableau @Bestiau::ISA, alors lui aussi sera consulté pour trouver le nom d'un paquetage ancestral qui puisse fournir une méthode deplacer, et ainsi de suite en remontant la hiérarchie d'héritage jusqu'à ce que l'on tombe sur un paquetage sans un @ISA.
La situation que nous venons de décrire est l'héritage simple, dans lequel chaque classe n'a qu'un seul parent. Perl permet aussi l'héritage multiple : il suffit d'ajouter d'autres paquetages à l'@ISA de la classe. Ce type d'héritage fonctionne davantage comme une structure de données en arbre, car chaque paquetage peut avoir plus d'un parent immédiat. Certaines personnes trouvent cela plus sexy.
Lorsque vous invoquez une méthode nom_meth sur un invoquant de type nom_classe, Perl essaie six façons différentes de trouver une fonction à utiliser :
- D'abord, Perl cherche une fonction nommée nom_classe::nom_meth dans le paquetage de l'invoquant. Si cela échoue, l'héritage entre en jeu, et nous passons à la deuxième étape.
- Ensuite, Perl cherche une méthode héritée de classes de base en cherchant dans tous les paquetages parent listés dans
@nom_classe::ISA une fonction parent::nom_meth. La recherche se fait de gauche à droite, récursivement, et en cherchant en profondeur d'abord (depth-first). La récursivité garantit que l'on recherche dans les classes grand-parent, arrière-grand-parent, arrière-arrière-grand-parent et ainsi de suite. - Si cela échoue, Perl cherche une fonction nommée UNIVERSAL::nom_meth.
- À ce stade, Perl abandonne nom_meth et commence à chercher un AUTOLOAD. D'abord, il cherche une fonction nommée nom_classe::AUTOLOAD.
- S'il n'en trouve pas, Perl cherche dans toutes les classes parent listées dans
@nom_classe::ISA une fonction parent::AUTOLOAD . La recherche est à nouveau de gauche à droite, récursive, et en profondeur d'abord. - Pour finir, Perl cherche une fonction nommée UNIVERSAL::AUTOLOAD.
Perl s'arrête à la première tentative réussie et invoque cette fonction. Si aucune fonction n'est trouvée, une exception est levée, que vous verrez fréquemment :
Can't locate object method "nom_meth" via package "nom_classe"Si vous avez compilé une version Perl de débogage avec l'option -DDEBUGGING de votre compilateur C, en utilisant l'option -Do de Perl, vous pouvez le regarder passer par chacune de ces étapes lorsqu'il résout une invocation de méthode.
Nous détaillerons le mécanisme d'héritage au fur et à mesure dans ce qui suit.
12-5-a. Héritage avec @ISA▲
Si @ISA contient plusieurs noms de paquetage, les paquetages sont tous parcourus de gauche à droite. La recherche se fait en profondeur d'abord, donc si vous avez une classe Mule configurée pour l'héritage de la façon suivante :
Perl cherche les méthodes manquantes de Mule d'abord dans Cheval (et dans tous ses ancêtres, comme Bestiau) avant de continuer à chercher dans Ane et ses ancêtres.
Si une méthode manquante est trouvée dans la classe de base, pour plus d'efficacité, Perl place cet emplacement en interne dans un cache dans la classe courante, pour qu'il n'ait pas à chercher aussi loin la prochaine fois qu'il doit trouver cette méthode. Modifier @ISA ou définir de nouvelles méthodes invalide le cache et oblige Perl à faire la recherche de nouveau.
Lorsque Perl cherche une méthode, il s'assure que vous n'avez pas créé de hiérarchie d'héritage circulaire. Ceci pourrait se produire si deux classes héritaient l'une de l'autre, même indirectement par d'autres classes. Essayer d'être votre propre grand-père est trop paradoxal, même pour Perl, donc la tentative lève une exception. Toutefois, Perl ne considère pas comme une erreur d'hériter de plusieurs classes partageant de mêmes ancêtres, ce qui fait penser à un mariage entre cousins. Simplement, votre hiérarchie d'héritage ne ressemble plus à un arbre et commence à ressembler à un graphe acyclique orienté. Ceci ne dérange pas Perl — tant que le graphe est réellement acyclique.
Lorsque vous initialisez @ISA, l'affectation se produit normalement à l'exécution, donc sauf si vous prenez des précautions, le code dans un bloc BEGIN, CHECK ou INIT ne pourra pas utiliser la hiérarchie d'héritage. Le pragma use base est une précaution (ou commodité) qui vous permet d'utiliser des classes avec require et les ajoute à @ISA à la compilation. Voici comment vous pourriez l'utiliser :
Ceci est un raccourci de :
sauf que use base prend aussi en compte toute déclaration use fields.
Il arrive que les gens s'étonnent que l'inclusion d'une classe dans @ISA n'effectue pas le require correspondant à votre place. C'est parce que le système de classes de Perl est largement séparé du système de modules. Un fichier peut contenir plusieurs classes (puisqu'elles ne sont que des paquetages), et un paquetage peut être mentionné dans plusieurs fichiers. Mais dans la situation la plus courante, dans laquelle un paquetage et une classe et un module et un fichier deviennent assez interchangeables si vous plissez suffisamment les yeux, le pragma use base fournit une syntaxe déclarative qui établit l'héritage, charge les fichiers de module, et gère les déclarations de champs de classe de base. C'est une de ces diagonales commodes que nous mentionnons souvent.
Voir pour plus de détails les descriptions de use base et de use fields au chapitre 31.
12-5-b. Accès aux méthodes supplantées▲
Lorsqu'une classe définit une méthode, cette fonction supplante les méthodes de même nom dans toutes les classes de base. Imaginons que vous avez un objet Mule (dérivé de la classe Cheval et de la classe Ane), et que vous décidez d'invoquer la méthode procreer de votre objet. Bien que les classes parentes aient leurs propres méthodes procreer, le concepteur de la classe Mule les a supplantées en fournissant à la classe Mule sa propre méthode procreer. Cela veut dire que le croisement suivant risque de ne pas être productif :
$etalon = Cheval->new(sexe => "male");
$molly = Mule->new(sexe => "femelle");
$poulain = $molly->procreer($etalon);Supposons maintenant que par le miracle de l'ingénierie génétique, vous trouvez un moyen de contourner le problème bien connu de stérilité de la mule, donc vous souhaitez passer outre la méthode Mule::procreer non viable. Vous pourriez appeler votre méthode comme une fonction ordinaire, en s'assurant de passer explicitement l'invoquant :
$poulain = Cheval::procreer($molly, $etalon);Toutefois ceci contourne l'héritage, ce qui est presque toujours la mauvaise chose à faire.
Il est parfaitement imaginable que la fonction Cheval::procreer n'existe pas, car Cheval et Ane dérivent ce comportement d'un parent commun nommé Equide. Si, d'un autre côté, vous voulez que Perl commence à chercher une méthode dans une classe donnée, utilisez simplement l'invocation de méthode ordinaire, mais qualifiez le nom de méthode avec la classe :
$poulain = $molly->Cheval::procreer($etalon);Parfois vous voudrez qu'une méthode dans une classe dérivée serve d'emballage pour une méthode dans une classe de base. La méthode de la classe dérivée peut elle-même appeler la méthode dans la classe de base, ajoutant ses propres actions avant ou après cette invocation. Vous pourriez utiliser la notation ci-dessus pour spécifier dans quelle classe commencer la recherche. Mais dans la plupart des cas de méthodes supplantées, vous voudrez probablement éviter de savoir ou de spécifier quelle classe parente appartient à la méthode supplantée que vous voulez exécuter.
C'est là que la pseudo-classe SUPER est très utile. Elle vous permet d'invoquer une méthode supplantée de classe de base sans avoir à spécifier quelle classe a défini cette méthode.(117) La fonction suivante consulte le tableau @ISA du paquetage courant sans vous faire spécifier de nom de classe :
package Mule;
our @ISA = qw(Cheval Ane);
sub coup_de_pied {
my $self = shift;
print "La mule donne un coup de pied !\n";
$self->SUPER::coup_de_pied(@_);
}Le pseudo-paquetage n'a un sens que lorsqu'il est utilisé à l'intérieur d'une méthode. Bien que celui qui implémente une classe peut faire usage de SUPER dans son propre code, quelqu'un qui ne fait qu'utiliser les objets de la classe ne le peut pas.
SUPER ne fonctionne pas toujours comme vous le voudriez dans le cas d'un héritage multiple. Comme vous pourriez vous y attendre, il parcourt @ISA exactement comme le fait le mécanisme d'héritage normal : de gauche à droite, récursivement, et en profondeur d'abord. Si Cheval et Ane avaient chacun une méthode dire, et que vous préfériez la méthode d'Ane, vous auriez à nommer explicitement la classe parente :
Des manières plus élaborées de traiter les situations avec héritage multiple peuvent être créées avec la méthode UNIVERSAL::can décrite dans la section suivante. Vous pouvez aussi récupérer le module Class::Multimethods de CPAN, qui fournit de nombreuses solutions sophistiquées, dont une qui trouve la méthode la plus proche au lieu de celle située le plus à gauche.
Chaque bout de code Perl sait dans quel paquetage il se trouve, d'après la dernière instruction package. Une méthode SUPER ne consulte le @ISA que du paquetage dans lequel l'appel à SUPER a été compilé. Il ne se soucie pas de la classe de l'invoquant, ni du paquetage de la fonction appelée. Ceci peut causer des problèmes si vous tentez de définir des méthodes dans une autre classe simplement en jouant sur le nom de méthode :
Malheureusement, ceci invoque la surclasse d'Oiseau, pas celle de Libellule. Pour faire ce que vous essayez de faire, vous devez aussi explicitement passer dans le paquetage approprié pour la compilation de SUPER :
package Oiseau;
use Libellule;
{
package Libellule;
sub bombarder { shift->SUPER::bombarder(@_) }
}Comme l'indique cet exemple, il n'est jamais nécessaire de modifier un fichier de module pour simplement ajouter des méthodes à une classe existante. Puisqu'une classe n'est qu'un paquetage, et qu'une méthode n'est qu'une fonction, tout ce que vous devez faire c'est définir une fonction dans ce paquetage comme nous l'avons fait ici, et la classe possède soudainement une nouvelle méthode. L'héritage n'est pas nécessaire. Seul compte le paquetage, et comme les paquetages sont globaux, on peut accéder à tout paquetage de n'importe où dans le programme. (Vous a-t-on informé que nous allions installer une baignoire dans votre salon la semaine prochaine ?)
12-5-c. UNIVERSAL : la classe ancêtre ultime▲
Si aucune définition de méthode de nom correspondant n'est trouvée après avoir recherché dans la classe de l'invoquant et récursivement dans toutes ses classes ancêtres, une dernière recherche de méthode de ce nom est faite dans la classe spéciale prédéfinie nommée UNIVERSAL. Ce paquetage n'apparaît jamais dans un @ISA, mais il est toujours consulté lorsque la recherche dans @ISA échoue. Vous pouvez voir UNIVERSAL comme l'ancêtre ultime dont dérivent implicitement toutes les classes.
Les méthodes prédéfinies suivantes sont disponibles dans la classe UNIVERSAL, et donc dans toutes les classes. Elles fonctionnent toutes qu'elles soient invoquées comme méthodes de classe ou comme méthodes d'objet.
INVOQUANT->isa(CLASSE)
- La méthode isa retourne vrai si la classe d'INVOQUANT est CLASSE ou une classe héritant de CLASSE. À la place d'un nom de paquetage, CLASSE peut aussi être un des types internes, comme « HASH » ou « ARRAY ». (Mais la détermination du type exact n'est pas bon signe pour l'encapsulation et le polymorphisme. Vous devriez dépendre de l'acheminement de méthode pour vous donner la bonne méthode.)
use FileHandle;
if (FileHandle->isa("Exporter")) {
print "FileHandle est un Exporter.\n";
}
$fh = FileHandle->new();
if ($fh->isa("IO::Handle")) {
print "\$fh est un objet en rapport avec IO.\n";
}
if ($fh->isa("GLOB")) {
print "\$fh est en fait une référence à un GLOB.\n";
}INVOQUANT->can(METHODE)
- La méthode can retourne une référence à la fonction qui serait appelée si METHODE était appliquée à INVOQUANT. Si une telle fonction n'est pas trouvée, can retourne
undef.
if ($invoquant->can("copier")) {
print "Notre invoquant peut copier.\n";
}- Ceci pourrait être utilisé pour n'invoquer une méthode que si elle existe :
$obj->grogner if $obj->can("grogner");- Avec l'héritage multiple, ceci permet à une méthode d'invoquer toutes les méthodes de classe de base supplantées, et non pas seulement celle la plus à gauche :
sub grogner {
my $self = shift;
print "Grognement: @_\n";
my %vues;
for my $parent (@ISA) {
if (my $code = $parent->can("grogner")) {
$self->$code(@_) unless $vues{$code}++;
}
}
}- Nous utilisons le hachage
%vuespour nous souvenir des fonctions déjà appelées. Ceci pourrait se produire si plusieurs classes parentes avaient un ancêtre commun. - Les méthodes qui déclencheraient un AUTOLOAD (décrit dans la section suivante) ne seront pas correctement signalées sauf si le paquetage a déclaré (mais pas défini) les fonctions qu'il souhaite voir autocharger.
INVOQUANT->VERSION(REQUIS)
- La méthode VERSION retourne le numéro de version de la classe d'INVOQUANT, tel qu'il a été enregistré dans la variable
$VERSIONdu paquetage. Si le paramètre REQUIS est fourni, elle vérifie que la version courante n'est pas plus petite que REQUIS, et lève une exception si elle l'est. C'est la méthode qu'invoque use pour déterminer si un module est suffisamment récent.
use Thread 1.0; # appelle Thread->VERSION(1.0)
print "Exécute la version ", Thread->VERSION, " de Thread.\n";- Vous pouvez fournir votre propre méthode VERSION pour supplanter la méthode dans UNIVERSAL. Néanmoins, ceci obligera aussi toute classe dérivée de votre classe à utiliser la méthode supplantée. Si vous ne souhaitez pas que cela se produise, vous devriez concevoir votre méthode de telle sorte qu'elle délègue à UNIVERSAL les requêtes de version des autres classes.
Les méthodes dans UNIVERSAL sont des fonctions internes de Perl, que vous pouvez appeler si vous les qualifiez et leur passez deux paramètres, comme dans UNIVERSAL::isa($obj_form, "HASH"). (Mais ceci n'est pas vraiment conseillé puisque can a normalement la réponse que vous cherchez vraiment.)
Vous êtes libre d'ajouter vos propres méthodes à la classe UNIVERSAL. (Vous devez être très prudent, évidemment ; vous pourriez vraiment gâcher les choses pour quelqu'un qui s'attend à ne pas trouver le nom de méthode que vous définissez, peut-être pour qu'il puisse l'autocharger d'un autre endroit.) Ici nous créons une méthode copier que les objets d'une classe quelconque peuvent utiliser s'ils ne l'ont pas définie eux-mêmes. (Elle échoue de façon spectaculaire si elle est invoquée pour une classe au lieu d'un objet.)
use Data::Dumper;
use Carp;
sub UNIVERSAL::copier {
my $self = shift;
if (ref $self) {
return eval Dumper($self); # pas de ref de CODE
} else {
confess "UNIVERSAL::copier ne peut pas copier la classe $self";
}
}Cette utilisation de Data::Dumper ne fonctionne pas si l'objet contient des références aux fonctions, car elle ne peuvent pas être reproduites correctement. Même si le source était disponible, les liens lexicaux seraient perdus.
12-5-d. Autochargement de méthode▲
Normalement, lorsque vous appelez une fonction non définie dans un paquetage qui définit une fonction AUTOLOAD, la fonction AUTOLOAD est appelée au lieu de lever une exception (voir la section Autochargement au chapitre 10). Avec les méthodes, ceci fonctionne un peu différemment. Si la recherche de méthode normale (dans la classe, dans ses ancêtres, et finalement dans UNIVERSAL) échoue, la même séquence est de nouveau exécutée, en cherchant cette fois une fonction AUTOLOAD. Si elle est trouvée, cette fonction est appelée comme méthode, en affectant à la variable $AUTOLOAD du paquetage le nom complet de la fonction au nom de laquelle a été appelé AUTOLOAD.
Vous devez être un peu prudent lorsque vous autochargez des méthodes. Premièrement, la fonction AUTOLOAD doit retourner immédiatement si elle est appelée au nom d'une méthode nommée DESTROY, sauf si votre but était de simuler DESTROY, qui en Perl a une signification spéciale décrite dans la section Destructeurs d'instance plus loin dans ce chapitre.
Deuxièmement, si une classe fournit un filet de sûreté AUTOLOAD, vous ne pourrez pas utiliser UNIVERSAL::can sur un nom de méthode pour vérifier si l'on peut l'invoquer. Vous devez vérifier AUTOLOAD séparément :
if ($obj->can("nom_meth") || $obj->can("AUTOLOAD")) {
$obj->nom_meth();
}Finalement, avec l'héritage multiple, si une classe hérite de deux classes ou plus, chacune ayant un AUTOLOAD, seul celui le plus à gauche sera jamais déclenché, puisque Perl s'arrête dès qu'il trouve le premier AUTOLOAD.
Ces deux dernières tracasseries sont facilement contournées en déclarant les fonctions dans le paquetage dont le AUTOLOAD est censé gérer ces méthodes. Vous pouvez faire ceci, soit avec des déclarations individuelles :
soit avec le pragma use subs, qui est plus commode si vous avez de nombreuses méthodes à déclarer :
Même si vous n'avez que déclaré ces fonctions sans les définir, c'est assez pour que le système pense qu'elles sont réelles. Elles apparaissent dans la vérification avec UNIVERSAL::can, et plus important encore, elles apparaissent dans l'étape 2 de recherche de méthode, qui n'ira jamais jusqu'à l'étape 3 et encore moins la 4.
« Mais, mais, » vous vous exclamez, « elles invoquent AUTOLOAD, non ? » Eh bien oui, elles finissent par le faire, mais le mécanisme est différent. Ayant trouvé le bout de méthode grâce à l'étape 2, Perl essaie de l'appeler. Lorsqu'il découvre que la méthode n'est pas tout ce qu'elle aurait pu être, la recherche de méthode AUTOLOAD démarre de nouveau, mais cette fois-ci, elle démarre dans la classe contenant le bout de méthode, ce qui restreint la recherche de méthode à la classe et à ses ancêtres (et à UNIVERSAL). Voilà comment Perl trouve le bon AUTOLOAD à exécuter et ignore les AUTOLOAD de la mauvaise partie de l'arbre généalogique.
12-5-e. Méthodes privées▲
Il existe un moyen d'invoquer une méthode de telle façon que Perl ignore complètement l'héritage. Si au lieu d'utiliser un nom de méthode littéral, vous spécifiez une simple variable scalaire contenant une référence à la fonction, alors la fonction est appelée immédiatement. Dans la précédente description de UNIVERSAL->can, le dernier exemple invoque toutes les méthodes supplantées en utilisant la référence à la fonction, pas son nom.
Un aspect intrigant de ce comportement est qu'il peut être utilisé pour implémenter des appels de méthode privée. Si vous mettez la classe dans un module, vous pouvez utiliser la portée lexicale du fichier pour faire un espace privé. Premièrement, stockez une fonction anonyme dans une variable lexicale dont la portée est le fichier :
Plus loin dans ce fichier, vous pouvez utiliser la variable comme si elle contenait un nom de variable. La fermeture sera appelée directement, sans prendre l'héritage en considération. Comme pour toute autre méthode, l'invoquant est passé en paramètre supplémentaire.
sub frapper {
my $self = shift;
if ($self->{frappe}++ > 5) {
$self->$porte_secrete();
}
}Ceci permet aux fonctions appartenant à un fichier (les méthodes de classe) d'invoquer une méthode à laquelle tout code hors de leur portée lexicale ne peut accéder.
12-6. Destructeurs d'instance▲
Comme pour tout autre référent en Perl, lorsque la dernière référence à un objet disparaît, sa mémoire est implicitement recyclée. Avec un objet, vous avez la possibilité de prendre la main juste au moment où ceci est près de se passer en définissant une fonction DESTROY dans le paquetage de la classe. Cette méthode est déclenchée automatiquement au moment approprié, avec l'objet prêt à être recyclé comme unique paramètre.
Les destructeurs sont rarement nécessaires en Perl, parce que la mémoire est gérée automatiquement pour vous. Cependant, la mémoire mise à part, certains objets peuvent avoir des informations d'état dont vous pouvez souhaiter vous occuper, comme des handles de fichier ou des connexions à une base de données.
package NotifierCourrier;
sub DESTROY {
my $self = shift;
my $fh = $self->{handle_courrier};
my $id = $self->{nom};
print $fh "\n$id s'en va à " . localtime() . "\n";
close $fh; # fermer la connexion au système de courrier
}De même que Perl n'utilise qu'une unique méthode pour construire un objet même lorsque la classe du constructeur hérite d'une ou plusieurs autres classes, Perl n'utilise aussi qu'une unique méthode DESTROY par objet détruit quel que soit l'héritage. En d'autres termes, Perl ne fait pas de la destruction hiérarchique à votre place. Si votre classe supplante le destructeur d'une surclasse, alors votre méthode DESTROY devra peut-être invoquer la méthode DESTROY d'une classe de base :
sub DESTROY {
my $self = shift;
# voir s'il y a un destructeur supplanté...
$self->SUPER::DESTROY if $self->can("SUPER::DESTROY");
# faites vos choses maintenant, avant ou après
}Ceci ne s'applique qu'aux classes héritées ; un objet qui est simplement contenu dans l'objet courant — comme, par exemple, une valeur dans un hachage — sera libéré et détruit automatiquement. C'est une raison pour laquelle l'appartenance par simple agrégation (parfois appelée relation « has-a » ou « possède-un ») est souvent plus propre et plus claire que l'héritage (une relation « est-un »). En d'autres termes, il suffit parfois de stocker un objet directement à l'intérieur d'un autre au lieu d'employer l'héritage, qui peut inutilement ajouter de la complexité. Parfois lorsque des utilisateurs se tournent vers l'héritage multiple, l'héritage simple peut suffire.
Il est possible, mais rarement nécessaire, d'appeler DESTROY explicitement. Cela peut même être dangereux, car l'exécution du destructeur plus d'une fois sur un même objet pourrait s'avérer désagréable.
12-6-a. Ramasse-miettes avec les méthodes DESTROY▲
Comme nous l'avons décrit dans la section Ramasse-miettes, références circulaires et références faibles du chapitre 8, une variable qui fait référence à elle-même n'est libérée que quand le programme (ou l'interpréteur intégré) est sur le point de se terminer (il en est de même pour plusieurs variables qui se font référence indirectement entre elles). Si vous voulez récupérer la mémoire plus tôt, vous devez normalement annuler explicitement la référence ou l'affaiblir avec le module WeakRef de CPAN.
Avec les objets, une autre solution est de créer une classe conteneur qui contient un pointeur à la structure de données autoréférentielle. Définissez une méthode DESTROY pour la classe de l'objet conteneur qui annule manuellement les boucles dans la structure autoréférentielle. Vous trouverez un exemple de ceci dans le chapitre 13 du Perl en action dans la recette 13.13, Gérer les structures de données circulaires.
Lorsqu'un interpréteur se termine, tous ses objets sont détruits, ce qui est important pour les applications Perl multithreadées ou intégrés dans un autre logiciel. Les objets sont presque toujours détruits lors d'une étape distincte, avant les références ordinaires. Ceci afin d'empêcher les méthodes DESTROY d'utiliser des références qui ont elles-mêmes été détruites. (Et aussi parce que les références ordinaires ne sont soumises au ramasse-miettes que dans les interpréteurs intégrés, puisque terminer un processus est une façon très rapide de récupérer les références. Mais terminer n'exécutera pas les destructeurs d'objet, donc Perl le fait d'abord.)
12-7. Gestion des données d'instance▲
La plupart des classes créent des objets qui ne sont essentiellement que des structures de données avec plusieurs champs de données internes (ou variables d'instance) avec des méthodes pour les manipuler.
Les classes Perl héritent de méthodes, pas de données, mais tant que tout accès à l'objet se fait par des appels de méthode, tout se passe très bien. Si vous voulez l'héritage de données, vous devez le réaliser par l'héritage de méthodes. Généralement, ceci n'est pas nécessaire en Perl, car la plupart des classes stockent les attributs de leur objet dans un hachage anonyme. Les données d'instance de l'objet sont contenues dans ce hachage, qui constitue son propre petit espace de noms dans lequel peut tailler toute classe faisant quelque chose avec l'objet. Par exemple, si vous voulez qu'un objet appelé $ville possède un champ nommé altitude, vous pouvez y accéder simplement avec $ville>{altitude}. Aucune déclaration n'est nécessaire. Mais les méthodes d'emballage ont leur utilité.
Supposons que vous voulez implémenter un objet Personne. Vous décidez d'avoir un champ appelé « nom », que par curieuse coïncidence vous stockez sous la clef nom dans le hachage anonyme qui servira d'objet. Pour profiter de l'encapsulation, les utilisateurs nécessitent des méthodes qui permettent d'accéder à cette variable d'instance sans lever le voile de l'abstraction.
Par exemple, vous pourriez créer une paire d'accesseurs :
sub recuperer_nom {
my $self = shift;
return $self->{nom};
}
sub affecter_nom {
my $self = shift;
$self->{nom} = shift;
}ce qui permet le code suivant :
$lui = Person->new();
$lui->affecter_nom("Frodon");
$lui->affecter_nom( ucfirst($lui->recuperer_nom) );Vous pourriez même combiner les deux méthodes :
Ce qui permettrait le code suivant :
$lui = Person->new();
$lui->nom("Frodon");
$lui->nom( ucfirst($lui->nom) );L'avantage d'écrire une fonction différente pour chaque variable d'instance (qui pour notre classe Personne pourrait être nom, âge, taille et ainsi de suite) est d'être direct, évident et flexible. Le désavantage est que chaque fois que vous voulez une nouvelle classe, vous finissez par définir une ou deux méthodes identiques par variable d'instance. Au début, ceci n'est pas gênant, et vous êtes libre de le faire si vous le souhaitez. Mais si vous préférez la commodité à la flexibilité, vous préférerez peut-être une des techniques décrites dans les sections suivantes.
Notez que nous ferons varier l'implémentation et non l'interface. Si les utilisateurs de votre classe respectent l'encapsulation, vous pourrez passer de manière transparente d'une implémentation à l'autre sans que les utilisateurs le remarquent. (Les membres de la famille de votre arbre d'héritage ne seront peut-être pas aussi tolérants, puisqu'ils vous connaissent beaucoup mieux que ne vous connaissent des étrangers.) Si vos utilisateurs ont pris l'habitude de mettre leur nez ou leurs mains dans les affaires privées de votre classe, le désastre inévitable est de leur faute et ne vous concerne pas. Tout ce que vous pouvez faire c'est respecter votre partie du contrat en gardant la même interface. Essayer d'obliger tout le monde à ne jamais rien faire de mal prendra tout votre temps et toute votre énergie — et en fin de compte échouera de toute façon.
Il est plus difficile de s'occuper des membres de la famille. Si une sous-classe supplante l'accesseur d'attribut d'une surclasse, doit-elle ou non accéder au même champ dans le hachage ? Les deux approches sont défendables, selon la nature de l'attribut. Pour être plus sûr dans le cas général, chaque accesseur peut préfixer le nom de champ de hachage avec son propre nom de classe, de telle façon que la sous-classe et la surclasse puissent chacune avoir leur propre version. Plusieurs des exemples ci-dessous, dont le module Class::Struct, utilisent cette stratégie « résistante aux sous-classes ». Vous verrez des accesseurs qui ressemblent à ceci :
sub nom {
my $self = shift;
my $champ = __PACKAGE__ . "::nom";
if (@_) { $self->{$champ} = shift }
return $self->{$champ};
}Dans chacun des exemples suivants, nous créons une classe Personne simple avec les champs nom, race, et surnoms, chacun avec une interface identique, mais une implémentation complètement différente. Nous n'allons pas vous dire laquelle nous préférons, car nous les préférons toutes, selon l'occasion. Et tous les goûts sont dans la nature. Certains préfèrent le ragoût de lapin, d'autres le poisson.
12-7-a. Déclarations de champ avec use fields▲
Un objet n'est pas obligatoirement implémenté avec un hachage anonyme. N'importe quelle référence suffira. Par exemple, si vous utilisiez un tableau anonyme, vous pourriez définir un constructeur comme ceci :
sub new {
my $invoquant = shift;
my $classe = ref($invoquant) || $invoquant;
return bless [], $classe;
}et des accesseurs comme ceci :
sub nom {
my $self = shift;
if (@_) { $self->[0] = shift }
return $self->[0];
}
sub race {
my $self = shift;
if (@_) { $self->[1] = shift }
return $self->[1];
}
sub surnoms {
my $self = shift;
if (@_) { $self->[2] = shift }
return $self->[2];
}Les tableaux sont un peu plus rapides d'accès que les hachages et occupent un peu moins de mémoire, mais ils ne sont pas terriblement commodes à utiliser. Vous devez tenir compte des numéros d'index (pas juste dans votre classe, mais aussi dans votre surclasse), qui doivent d'une façon ou d'un autre indiquer quelles parties du tableau utilise votre classe. Sinon, vous pourriez réutiliser une case.
Le pragma use fields traite tous ces points :
Ce pragma ne vous crée pas les méthodes accesseurs, mais il dépend de magie interne (appelée pseudo-hachages) pour faire quelque chose de similaire. (Vous souhaiterez peut-être tout de même emballer les champs dans des accesseurs, comme nous le faisons dans l'exemple suivant.) Les pseudo-hachages sont des références de tableau que vous pouvez utiliser comme des hachages parce qu'ils sont associés avec un tableau qui met les clefs en correspondance avec les index. Le pragma use fields vous met en place cette table de correspondance, déclarant effectivement quels champs sont valides pour l'objet Personne ; ceci les fait prendre en compte par le compilateur Perl. Si vous déclarez le type de votre variable objet (comme avec my Personne $self dans l'exemple suivant), le compilateur est suffisamment intelligent pour optimiser l'accès aux champs avec des simples accès par tableau. De façon peut-être plus importante, il fait à la compilation de la validation de type pour les noms de champ (c'est en quelque sorte une validation de typographie contre les fautes de frappe). (Voir la section Pseudo-hachages au chapitre 8.)
Un constructeur et des exemples d'accesseurs ressembleraient à ceci :
package Personne;
use fields qw(nom race surnoms);
sub new {
my $type = shift;
my Personne $self = fields::new(ref $type || $type);
$self->{nom} = "pas de nom";
$self->{race} = "inconnue";
$self->{surnoms} = [];
return $self;
}
sub nom {
my Personne $self = shift;
$self->{nom} = shift if @_;
return $self->{nom};
}
sub race {
my Personne $self = shift;
$self->{race} = shift if @_;
return $self->{race};
}
sub surnoms {
my Personne $self = shift;
$self->{surnoms} = shift if @_;
return $self->{surnoms};
}
1;Si vous écrivez incorrectement l'une des clefs littérales utilisées pour accéder au pseudohachage, vous n'aurez pas à attendre l'exécution pour vous en rendre compte. Le compilateur sait à quel type $self est censé faire référence (parce que vous le lui avez dit), donc il peut vérifier que le code n'accède qu'à des champs réellement existants dans les objets Personne. S'il arrive que vos doigts s'emballent et que vous tentez d'accéder à un champ inexistant (comme $self->{mon}), le compilateur peut tout de suite signaler cette erreur et ne laissera jamais exécuter par l'interpréteur le programme erroné.
Il reste un peu de redite dans la déclaration de méthodes pour accéder aux variables d'instance, donc vous souhaiterez peut-être encore automatiser la création de méthodes accesseur simples avec l'une des techniques ci-dessous. Toutefois, comme ces techniques utilisent toutes une forme d'indirection ou une autre, vous perdrez l'avantage de la vérification à la compilation de fautes de frappe pour les accès typés lexicalement aux hachages. Il vous restera néanmoins les (légères) économies de temps et d'espace.
Si vous décidez d'utiliser un pseudo-hachage pour implémenter votre classe, toute classe qui en hérite doit prendre en compte cette implémentation sous-jacente. Si un objet est implémenté avec un pseudo-hachage, tous les membres de la hiérarchie d'héritage doivent utiliser les déclarations use base et use fields. Par exemple :
Ceci fait du module Magicien une sous-classe de la classe Personne, et charge le fichier Personne.pm. Ceci déclare également trois nouveaux champs dans cette classe, qui s'ajoutent à ceux de Personne. Ainsi lorsque vous écrirez :
my Magicien $mage = fields::new("Magicien");vous aurez un objet pseudo-hachage avec accès aux champs des deux classes :
$mage->nom("Gandalf");
$mage->couleur("Gris");Puisque toutes les sous-classes doivent savoir qu'elles utilisent une implémentation de pseudo-hachage, elles doivent utiliser la notation directe de pseudo-hachage pour des raisons d'efficacité et de validation des types :
$mage->{nom} = "Gandalf";
$mage->{couleur} = "Gris";Toutefois, si vous voulez garder des implémentations interchangeables, les utilisateurs extérieurs de votre classe doivent utiliser les méthodes accesseurs.
Bien que use base ne permette que l'héritage simple, ceci est rarement une contrainte sévère. Voir les descriptions de use base et de use fields au chapitre 31.
12-7-b. Génération de classes avec Class::Struct▲
Le module standard Class::Struct exporte une fonction appelée struct. Celle-ci crée tout ce qu'il vous faut pour commencer l'écriture d'une classe entière. Elle génère un constructeur appelé new, ainsi que des méthodes accesseurs pour chacun des champs (variables d'instance) nommés dans cette structure.
Par exemple, si vous mettez la classe dans un fichier Personne.pm :
package Personne;
use Class::Struct;
struct Personne => { # créer la définition d'une "Personne"
nom => '$', # le champ nom est un scalaire
race => '$', # le champ race est aussi un scalaire
surnoms => '@', # mais le champ surnoms est une réf de tableau
};
1;Alors vous pourriez utiliser le module de cette façon :
use Personne;
my $mage = Personne->new();
$mage->nom("Gandalf");
$mage->race("Istar");
$mage->surnoms( ["Mithrandir", "Olorin", "Incanus"] );Le module Class::Struct a créé ces quatre méthodes. Comme il respecte le principe « résistant aux sous-classes » de toujours préfixer le nom du champ avec le nom de la classe, il permet aussi sans conflit à une sous-classe d'avoir son propre champ séparé de même nom qu'un champ de la classe de base. Cela veut dire qu'il utilise ici « Personne::nom » au lieu du simple « nom » comme clef de hachage pour cette variable d'instance.
Les champs d'une déclaration struct ne sont pas obligatoirement des types Perl de base. Ils peuvent aussi spécifier d'autres classes, mais les classes créées avec struct fonctionnent le mieux, car la fonction fait des présuppositions sur le comportement des classes qui ne sont pas généralement vraies de toutes les classes. Par exemple, la méthode new de la classe appropriée est invoquée pour initialiser le champ, mais beaucoup de classes ont des constructeurs nommés différemment.
Voir la description de Class::Struct au chapitre 32, Modules standards, et sa documentation en ligne pour plus d'information. Beaucoup de modules standard utilisent Class::Struct pour implémenter leurs classes, dont notamment User::pwent et Net::hostent. La lecture de leur code peut s'avérer instructive.
12-7-c. Génération d'accesseurs par autochargement▲
Comme nous l'avons mentionné précédemment, lorsque vous invoquez une méthode inexistante, Perl cherche une méthode AUTOLOAD de deux façons différentes, selon que vous ayez déclaré la méthode ou non. Vous pouvez utiliser cette propriété pour donner accès aux données d'instance de l'objet sans définir une fonction différente pour chaque variable d'instance. Dans la fonction AUTOLOAD, le nom de la méthode réellement invoquée peut être déterminé à partir de la variable $AUTOLOAD. Examinons le code suivant :
use Personne;
$lui = Personne->new;
$lui->nom("Aragorn");
$lui->race("Homme");
$lui->surnoms( ["Grands-Pas", "Estel", "Elessar"] );
printf "La race de %s est : %s.\n", $lui->nom, $lui->race;
print "Ses surnoms sont : ", join(", ", @{$lui->surnoms}), ".\n";Comme précédemment, cette classe Personne implémente une structure de données avec trois champs : nom, race, et surnoms :
package Personne;
use Carp;
my %Fields = (
"Personne::nom" => "pas de nom",
"Personne::race" => "inconnue",
"Personne::surnoms" => [],
);
# Cette déclaration nous assure d'obtenir notre propre autochargeur
use subs qw(nom race surnoms);
sub new {
my $invoquant = shift;
my $classe = ref($invoquant) || $invoquant;
my $self = { %Fields, @_ }; # cloner comme Class::Struct
bless $self, $classe;
return $self;
}
sub AUTOLOAD {
my $self = shift;
# ne gérer que les méthodes d'instance, pas les méthodes de classe
croak "$self n'est pas un objet" unless ref($self);
my $nom = our $AUTOLOAD;
return if $nom =~ /::DESTROY$/;
unless (exists $self->{$nom}) {
croak "impossible d'accéder au champ '$nom' dans $self";
}
if (@_) { return $self->{$nom} = shift }
else { return $self->{$nom} }
}Comme vous le voyez, il n'y a aucune mention de méthodes nommées nom, race ou surnoms. La fonction AUTOLOAD prend tout cela en charge. Lorsque quelqu'un utilise $lui->nom("Aragorn"), la fonction AUTOLOAD est appelée avec la valeur « Personne::nom » affectée à $AUTOLOAD. Commodément, le nom qualifié est exactement sous la forme nécessaire pour accéder au champ du hachage de l'objet. Ainsi si vous utilisez cette classe à l'intérieur d'une hiérarchie de classes, vous n'entrerez pas en conflit avec l'utilisation du même nom dans d'autres classes.
12-7-d. Génération d'accesseurs par fermetures▲
La plupart des méthodes accesseurs font essentiellement la même chose : elles ne font que récupérer ou stocker une valeur dans une variable d'instance. En Perl, la façon la plus naturelle de créer une famille de fonctions quasiment identiques est de boucler autour d'une fermeture. Mais une fermeture est une fonction anonyme, et une méthode, pour qu'elle puisse être appelée par nom, doit être une fonction nommée dans la table de symboles du paquetage de la classe. Ceci n'est pas un problème — il suffit d'affecter la référence à la fermeture à un typeglob de nom approprié.
package Personne;
sub new {
my $invoquant = shift;
my $self = bless({}, ref $invoquant || $invoquant);
$self->init();
return $self;
}
sub init {
my $self = shift;
$self->nom("pas de nom");
$self->race("inconnue");
$self->surnoms([]);
}
for my $champ (qw(nom race surnoms)) {
my $slot = __PACKAGE__ . "::$champ";
no strict "refs"; # Pour que fonctionne la réf symbolique au typeglob
*$slot = sub {
my $self = shift;
$self->{$champ} = shift if @_;
return $self->{$champ};
};
}Les fermetures sont la façon « fait main » la plus propre de créer une multitude de méthodes accesseurs pour vos données d'instance. C'est une méthode efficace à la fois pour l'ordinateur et pour vous. Non seulement tous les accesseurs partagent le même bout de code (ils ne nécessitent que leur propre emplacement lexical), mais plus tard si vous décidez d'ajouter un autre attribut, les changements requis sont minimaux : il suffit d'ajouter un mot de plus à la liste de la boucle for, et peut-être quelque chose à la méthode init.
12-7-e. Utilisation de fermetures pour objets privés▲
Jusqu'ici, ces techniques de gestion de données d'instance n'ont proposé aucun mécanisme pour les « protéger » d'accès externes. Toute personne en dehors de la classe peut ouvrir la boîte noire de l'objet et fouiner dedans — si elle n'a pas peur d'annuler la garantie. Imposer un espace privé obligatoire tend à mettre des bâtons dans les roues de personnes qui essaient simplement de faire leur travail. Perl part du principe qu'il est mieux d'encapsuler ses données avec un écriteau sur lequel il est écrit :
EN CAS D'INCENDIE
BRISER LA GLACEVous devez si possible respecter l'encapsulation, tout en gardant un accès aisé au contenu en cas d'urgence, comme pour le débogage.
Mais si vous souhaitez imposer un espace privé, Perl ne va pas vous en empêcher. Perl fournit des briques de base de bas niveau dont vous pouvez faire usage pour entourer votre classe et ses objets d'un bouclier impénétrable d'espace privé — un bouclier en fait plus fort que celui dont on dispose dans de nombreux langages orientés objet. Les portées lexicales et les variables lexicales qu'ils contiennent en sont les éléments principaux, et les fermetures y jouent un rôle essentiel.
Dans la section Méthodes privées, nous avons vu comment une classe peut utiliser les fermetures pour implémenter des méthodes qui sont invisibles à l'extérieur du fichier de module. Plus loin nous verrons des méthodes accesseurs qui régulent des données de classe si privées que même le reste de la classe n'y a pas un accès illimité. Ces techniques restent des utilisations assez traditionnelles des fermetures. L'approche véritablement intéressante est d'utiliser une fermeture pour l'objet lui-même. Les variables d'instance de l'objet sont verrouillées à l'intérieur d'une portée à laquelle seul l'objet — c'est-à-dire, la fermeture — a librement accès. Ceci est une forme très forte d'encapsulation ; elle empêche non seulement toute altération de l'extérieur, mais aussi d'autres méthodes de la même classe doivent utiliser les méthodes d'accès appropriées pour accéder aux données d'instance de l'objet.
Voici un exemple de comment cela pourrait fonctionner. Nous utiliserons des fermetures à la fois pour les objets eux-mêmes et pour les accesseurs générés :
package Personne;
sub new {
my $invoquant = shift;
my $classe = ref($invoquant) || $invoquant;
my $donnees = {
NOM => "pas de nom",
RACE => "inconnue",
SURNOMS => [],
};
my $self = sub {
my $champ = shift;
############################################
### METTRE LES VERIFICATIONS D'ACCES ICI ###
############################################
if (@_) { $donnees->{$champ} = shift }
return $donnees->{$champ};
};
bless($self, $classe);
return $self;
}
# générer les noms de méthodes
for my $champ (qw(nom race surnoms)) {
no strict "refs"; # pour l'accès à la table de symboles
*$champ = sub {
my $self = shift;
return $self->(uc $champ, @_);
};
}L'objet créé et retourné par la méthode new n'est plus un hachage, comme c'était le cas des autres constructeurs que nous avons vus. C'est une fermeture avec accès unique aux données des attributs stockés dans le hachage référencé par $donnees. Une fois l'appel au constructeur terminé, l'accès à $donnees (et donc aux attributs) ne se fait plus que par la fermeture.
Dans un appel comme $lui->nom("Bombadil"), l'objet invoquant stocké dans $self est la fermeture consacrée et retournée par le constructeur. On ne peut pas faire grand-chose avec une fermeture sinon l'appeler, donc c'est ce que nous faisons avec $self->(uc $champ, @_). Ne vous laissez pas tromper par la flèche : ceci n'est qu'un appel de fonction indirect, pas une invocation de méthode. Le paramètre initial est la chaîne « nom », et d'autres paramètres peuvent être passés à sa suite.(118) Une fois qu'on s'exécute à l'intérieur de la fermeture, la référence de hachage dans $donnees est à nouveau accessible. La fermeture est alors libre de permettre ou d'interdire l'accès à ce qui lui plaît.
Personne en dehors de l'objet fermeture n'a d'accès direct à ces données d'instance extrêmement privées, pas même les autres méthodes de la classe. Elles pourraient essayer d'appeler la fermeture de la même façon que le font les méthodes générées par la boucle for, définissant éventuellement une variable d'instance dont la classe n'aurait jamais entendu parler. Mais cette approche est aisément bloquée en insérant divers bouts de code dans le constructeur à l'endroit du commentaire sur les vérifications d'accès. D'abord, nous avons besoin d'un préambule commun :
use Carp;
local $Carp::CarpLevel = 1; # Afficher des messages croak courts
my ($pack_appelant, $fichier_appelant) = caller();Ensuite nous faisons chacune des vérifications. La première s'assure que le nom d'attribut existe :
croak "Pas de champ valide '$champ' dans l'object"
unless exists $donnees->{$champ};Celle-ci ne permet l'accès qu'aux appelants du même fichier :
carp "Accès direct interdit aux fichiers étrangers"
unless $fichier_appelant eq __FILE__;Celle-ci ne permet l'accès qu'aux appelants du même paquetage :
carp "Accès direct interdit au paquetage étranger ${pack_appelant}::"
unless $pack_appelant eq __PACKAGE__;Et celle-ci ne permet l'accès qu'aux appelants dont la classe hérite de la nôtre :
carp "Accès direct interdit à la classe inconnue ${pack_appelant}::"
unless $pack_appelant->isa(__PACKAGE__);Toutes ces vérifications ne font qu'empêcher l'accès direct. Les utilisateurs d'une classe qui, poliment, n'emploient que les méthodes de classes prévues ne souffrent pas d'une telle restriction. Perl vous donne les outils pour être aussi maniaque que vous le souhaitez. Heureusement, peu de gens souhaitent être vraiment maniaques.
Mais certaines personnes devraient l'être. C'est bien d'être maniaque lorsqu'on écrit un logiciel de calculateur de vol. Si vous voulez être ou devriez être une telle personne, et que vous préférez utiliser du code fonctionnel au lieu de tout réinventer vous-même, jetez un coup d'œil sur CPAN au module Tie::SecureHash de Damian Conway. Il implémente des hachages restreints qui permettent des maniaqueries publiques, protégées ou privées. Damian a aussi écrit un module encore plus ambitieux, Class::Contract, qui impose un régime d'ingénierie logicielle formelle au système objet flexible de Perl. La liste des fonctionnalités de ce module ressemble à la liste de contrôle d'un livre écrit par un professeur d'ingénierie logicielle(119), avec notamment l'encapsulation obligatoire, l'héritage statique, et la vérification de conditions de conception par contrat pour le Perl orienté objet, avec une syntaxe déclarative pour les définitions d'attribut, de méthode, de constructeur, et de destructeur, à la fois au niveau de l'objet et de la classe, et des préalables, des post-conditions, et des invariants de classe. Ouf !
12-7-f. Nouvelles astuces▲
Depuis la version 5.6 de Perl, vous pouvez aussi déclarer une méthode pour indiquer qu'elle retourne une lvalue. Ceci se fait avec l'attribut de fonction lvalue (à ne pas confondre avec les attributs d'objet). Cette fonctionnalité expérimentale vous permet de traiter une méthode comme quelque chose qui apparaîtrait du côté gauche d'un signe égal :
package Bestiau;
sub new {
my $classe = shift;
my $self = { petits => 0, @_ }; # Supplanter la valeur par défaut.
bless $self, $classe;
}
sub petits : lvalue { # Nous affecterons à petits() plus loin.
my $self = shift;
$self->{petits};
}
package main;
$vermine = Bestiau->new(petits => 4);
$vermine->petits *= 2; # Affecter à $vermine->petits !
$vermine->petits =~ s/(.)/$1$1/; # Modifier $vermine->petits sur place !
print $vermine->petits; # Nous avons maintenant 88 petits.Ceci vous laisse faire semblant que $vermine->petits est une variable tout en respectant l'encapsulation. Voir la section L'attribut lvalue du chapitre 6, Sous-programmes.
Si vous exécutez une version de Perl avec threads et que vous voulez vous assurer qu'un seul thread n'appelle une méthode donnée pour un objet, vous pouvez faire cela avec les attributs locked et method :
Lorsqu'un thread invoque la méthode petits pour un objet, Perl verrouille l'objet avant exécution, empêchant d'autres threads de faire la même chose. Voir la section Les attibuts locked et method du chapitre 6.
12-8. Gestion des données de classe▲
Nous avons examiné plusieurs approches pour accéder aux données associées à un objet. Mais parfois vous voulez un état commun partagé par tous les objets d'une classe. Au lieu d'être seulement un attribut d'une instance de la classe, ces variables sont globales pour la classe entière, quelle que soit l'instance de classe (l'objet) que vous utilisez pour y accéder. (Les programmeurs C++ les appelleraient des membres statiques de la classe.) Voici des situations où ces variables de classe seraient commodes :
- Pour compter au fur et à mesure tous les objets créés, ou tous les objets en cours d'utilisation.
- Pour garder la liste de tous les objets, liste que vous pouvez parcourir.
- Pour stocker le nom ou le descripteur d'un fichier log utilisé par une méthode de débogage de toute la classe.
- Pour recenser des données accumulées, comme la somme totale de liquide distribuée en une journée par tous les distributeurs de billets d'un réseau.
- Pour suivre le dernier objet créé par une classe ou l'objet le plus utilisé.
- Pour gérer un cache des objets en mémoire qui ont déjà été reconstitués à partir d'une mémoire persistante.
- Pour fournir une table associative inversée permettant de trouver un objet à partir de la valeur de l'un de ses attributs.
Il reste à décider où stocker l'état de ces attributs partagés. Perl n'a pas de mécanisme syntaxique particulier pour déclarer les attributs de classe, pas plus qu'il n'en a pour les attributs d'instance. Perl fournit au développeur un large ensemble de fonctionnalités puissantes, mais flexibles qui peuvent être adaptées habilement aux exigences particulières d'une situation. Vous pouvez donc sélectionner le mécanisme qui correspond le mieux à la situation donnée au lieu de devoir vivre avec les choix de conception de quelqu'un d'autre. Ou alors, vous pouvez vivre avec les choix de conception que quelqu'un d'autre a empaqueté et mis sur CPAN. Comme toujours, il y a plus d'une façon de le faire, TMTOWTDI.
Comme pour tout ce qui a trait à une classe, on ne doit pas accéder directement aux données de classe, particulièrement de l'extérieur de l'implémentation de la classe elle-même. Ce n'est guère respecter l'encapsulation que de soigneusement créer des méthodes accesseurs pour les variables d'instance, mais ensuite d'inviter le public à tripoter directement vos variables de classe, en affectant par exemple $UneClasse::Debug = 1. Pour établir une barrière bien claire entre interface et implémentation, vous pouvez, pour manipuler les données de classe, créer des méthodes accesseurs similaires à celles que vous employez pour les données d'instance.
Imaginons que nous voulions connaître à tout moment le compte de la population mondiale des objets Bestiau. Nous rangeons ce nombre dans une variable de paquetage, mais nous fournissons une méthode appelée population pour que les utilisateurs de la classe n'aient pas à connaître son implémentation.
Bestiau->population() # Accès par le nom de classe
$gollum->population() # Accès par l'instanceComme en Perl une classe n'est qu'un paquetage, une variable de paquetage est l'endroit le plus naturel pour ranger une donnée de classe. Voici une implémentation simple d'une telle classe. La méthode population ne tient pas compte de son invoquant et ne fait que retourner la valeur courante de la variable de paquetage $Population. (Certains programmeurs aiment commencer leurs variables globales par une majuscule.)
package Bestiau;
our $Population = 0;
sub population { return $Population; }
sub DESTROY { $Population-- }
sub engendrer {
my $invoquant = shift;
my $classe = ref($invoquant) || $invoquant;
$Population++;
return bless { nom => shift || "anon" }, $classe;
}
sub nom {
my $self = shift;
$self->{nom} = shift if @_;
return $self->{nom};
}Si vous voulez créer des méthodes de données de classe qui fonctionnent comme les accesseurs de données d'instance, faites ceci :
our $Deboguage = 0; # donnée de classe
sub debug {
shift; # on ignore intentionnellement l'invoquant
$Deboguage = shift if @_;
return $Deboguage;
}Maintenant vous pouvez spécifier le niveau de débogage global avec la classe ou avec l'une quelconque de ses instances.
Comme $Deboguage est une variable de paquetage, elle est globalement accessible. Mais si vous changez la variable our en variable my, seul peut la voir le code situé à sa suite dans le fichier. Vous pouvez en faire encore plus — vous pouvez même restreindre l'accès aux attributs de classe au reste de la classe elle-même. Emballez la déclaration de va
{
my $Deboguage = 0; # donnée de classe à portée lexicale
sub debug {
shift; # on ignore intentionnellement l'invoquant
$Deboguage = shift if @_;
return $Deboguage;
}
}Maintenant personne n'a le droit de lire ou d'écrire les attributs de classe sans utiliser la méthode accesseur, puisque seule cette fonction est dans la même portée que la variable et y a accès.
Si une classe dérivée hérite de ces accesseurs de classe, ils accèdent tout de même aux données d'origine, que ces variables soient déclarées avec our ou avec my. Les données ne sont pas relatives au paquetage. Vous pouvez considérer que les accesseurs s'exécutent dans la classe où ils ont été définis à l'origine, pas dans la classe qui les invoque.
Pour certaines données de classe, cette approche fonctionne correctement, mais pour d'autres non. Supposons que nous créions une sous-classe Ouargue de Bestiau. Si nous voulons garder séparées nos populations, Ouargue ne peut hériter de la méthode population de Bestiau, car cette méthode telle qu'elle est écrite retourne la valeur de $Bestiau::Population.
Il vous faudra décider selon le cas de l'utilité de rendre les attributs de classe relatifs au paquetage. Si vous voulez des attributs relatifs au paquetage, utilisez la classe de l'invoquant pour situer le paquetage contenant les données de classe :
sub debug {
my $invoquant = shift;
my $classe = ref($invoquant) || $invoquant;
my $nom_var = $classe . "::Deboguage";
no strict "refs"; # pour accéder symboliquement
#aux données de paquetage
$$nom_var = shift if @_;
return $$nom_var;
}Nous annulons temporairement le pragma strict références, car sans cela nous ne pourrions pas utiliser le nom symbolique qualifié de la variable globale de paquetage. Ceci est parfaitement raisonnable : puisque toutes les variables de paquetage se trouvent par définition dans la table de symboles du paquetage, il n'y a pas de mal à y accéder par la table de symboles de ce paquetage.
Une autre approche consiste à rendre disponible tout ce dont a besoin un objet — y compris ses données globales de classe — par l'objet (ou passé en tant que paramètre). Pour ce faire, vous aurez souvent à créer un constructeur spécifique pour chaque classe ou au moins une fonction d'initialisation spécifique à appeler par le constructeur. Dans le constructeur ou l'initialiseur, vous stockez des références aux données de classe directement dans l'objet lui-même, pour ne pas devoir les chercher plus tard. Les méthodes accesseurs utilisent l'objet pour trouver une référence aux données.
Au lieu de mettre la complexité de la recherche des données de classe dans chaque méthode, laissez simplement dire par l'objet à la méthode où se situent les données. Cette approche ne fonctionne bien que lorsque les méthodes d'accès aux données de classe sont invoquées comme méthodes d'instance, car les données de classe pourraient être dans des variables lexicales inaccessibles à partir du nom d'un paquetage.
De quelque façon que l'on s'y prenne, les données de classes relatives à un paquetage sont toujours un peu incommodes. C'est vraiment plus propre si, lorsque vous héritez d'une méthode d'accès à une donnée de classe, vous héritez aussi de la donnée d'état à laquelle elle accède. Voir la page man perltootc pour de nombreuses approches plus élaborées de la gestion des données de classe.
12-9. Résumé▲
C'est à peu près tout ce qu'il y a à savoir, sauf tout le reste. Maintenant vous n'avez plus qu'à aller acheter un livre sur la méthodologie de la conception orientée objet et vous cogner le front avec durant six mois environ.
13. Surcharge▲
Les objets sont chics, mais parfois ils sont juste un peu trop chics. Parfois l'on préférerait qu'ils se comportent un peu moins comme des objets et un peu plus comme des types de données ordinaires. Mais voilà le hic : les objets sont des référents représentés par des références, et celles-ci ne sont guère utiles sauf comme références. Vous ne pouvez pas ajouter des références, ou les afficher, ou leur appliquer (utilement) la plupart des opérateurs prédéfinis de Perl. La seule chose que vous puissiez faire c'est les déréférencer. Donc vous finissez par écrire beaucoup d'invocations de méthode explicites, comme ceci :
print $objet->comme_chaine;
$nouvel_objet = $sujet->ajouter($objet);De telles références explicites sont en général une bonne chose ; vous ne devez jamais confondre vos références avec vos référents, sauf quand vous voulez les confondre. C'est le cas qui se présente ici. Si vous concevez votre classe avec la surcharge, vous pouvez faire comme si les références n'étaient pas là et dire simplement :
print $objet;
$nouvel_objet = $sujet + $objet;Lorsque vous surchargez l'un des opérateurs prédéfinis de Perl, vous définissez comment il se comporte lorsqu'il est appliqué aux objets d'une classe donnée. Un certain nombre de modules Perl standard utilisent la surcharge, comme Math::BigInt, qui vous permet de créer des objets Math::BigInt se comportant comme des entiers ordinaires, mais sans limite de taille. Vous pouvez les ajouter avec +, les diviser avec /, les comparer avec <=>, et les afficher avec print.
Notez que la surcharge diffère de l'autochargement, qui charge à la demande une fonction manquante. Il faut également distinguer entre surcharger et supplanter, qui masque une fonction avec une autre. La surcharge ne cache rien ; elle ajoute un sens à une opération qui n'aurait pas de sens sur une simple référence.
13-1. Le pragma overload▲
Le pragma use overload implémente la surcharge d'opérateur. Vous lui fournissez une liste de couples clef/valeur d'opérateurs et de leur comportement associé :
package MaClasse;
use overload '+' => \&mon_addition, # réf de code
'<' => "inferieur_a", # méthode nommée
'abs' => sub { return @_ }; # fonction anonymeMaintenant lorsque vous ajoutez deux objets MaClasse, la fonction mon_addition est appelée pour créer le résultat.
Lorsque vous comparez deux objets MaClasse avec l'opérateur <, Perl remarque que le comportement est spécifié par une chaîne et interprète la chaîne comme le nom d'une méthode et non comme un simple nom de fonction. Dans l'exemple ci-dessus, la méthode inferieur_a pourrait être fournie par le paquetage MaClasse lui-même ou héritée d'une classe de base de MaClasse, mais la fonction mon_addition doit être fournie dans le paquetage courant. La fonction anonyme pour abs est fournie encore plus directement. De quelque manière que ces fonctions soient fournies, nous les appellerons des handlers.
Dans le cas des opérateurs unaires (ceux qui ne prennent qu'un seul opérande, comme abs), le handler spécifié pour une classe est invoqué à chaque fois que l'opérateur est appliqué à un objet de cette classe.
Dans le cas des opérateurs binaires comme + ou <, le handler est invoqué lorsque le premier opérande est un objet de la classe ou lorsque le deuxième opérande est un objet de la classe et le premier opérande n'a pas de comportement de surcharge. C'est pour que vous puissiez dire soit :
$objet + 6soit :
6 + $objetsans avoir à vous soucier de l'ordre des opérandes. (Dans le deuxième cas, les opérandes seront permutés lorsqu'ils seront passés au handler.) Si notre expression était :
$animal + $legumeet $animal et $legume étaient des objets de classes différentes, chacune utilisant la surcharge, c'est le comportement de surcharge de $animal qui serait déclenché. (Nous espérons que l'animal aime les légumes.)
Il n'y a qu'un seul opérateur trinaire (ternaire) en Perl, ?:, et vous ne pouvez pas le surcharger. Heureusement.
13-2. Handlers de surcharge▲
Lorsqu'un opérateur surchargé s'exécute, le handler correspondant est invoqué avec trois paramètres. Les deux premiers paramètres sont les deux opérandes. Si l'opérateur n'utilise qu'un opérande, le deuxième paramètre est undef.
Le troisième paramètre indique si les deux premiers paramètres sont permutés. Même selon les règles de l'arithmétique ordinaire, certaines opérations ne se soucient pas de l'ordre de leurs paramètres, comme l'addition et la multiplication, alors que d'autres si, comme la soustraction ou la division.(120) Considérez la différence entre :
$objet - 6et :
6 -$objetSi les deux premiers paramètres d'un handler ont été permutés, le troisième paramètre sera vrai. Sinon, le troisième paramètre sera faux, auquel cas on fera aussi une distinction plus fine : si le handler a été déclenché par un autre handler en rapport avec l'affectation (si par exemple += appelle + pour déterminer comment faire une addition), alors le troisième paramètre n'est pas simplement faux, mais undef. Cette distinction permet certaines optimisations.
Par exemple, voici une classe qui vous permet de manipuler un intervalle borné d'entiers. Elle surcharge à la fois + et - de manière à contraindre le résultat de l'addition ou de la soustraction d'objets à être une valeur dans l'intervalle de 0 à 255 :
package OctetBorne;
use overload '+' => \&ajouter_borne,
'-' => \&soustraire_borne;
sub new {
my $classe = shift;
my $valeur = shift;
return bless \$valeur => $classe;
}
sub ajouter_borne {
my ($x, $y) = @_;
my ($valeur) = ref($x) ? $$x : $x;
$valeur += ref($y) ? $$y : $y;
$valeur = 255 if $valeur > 255;
$valeur = 0 if $valeur < 0;
return bless \$valeur => ref($x);
}
sub soustraire_borne {
my ($x, $y, $swap) = @_;
my ($valeur) = (ref $x) ? $$x : $x;
$valeur -= (ref $y) ? $$y : $y;
if ($swap) { $valeur = -$valeur }
$valeur = 255 if $valeur > 255;
$valeur = 0 if $valeur < 0;
return bless \$valeur => ref($x);
}
package main;
$octet1 = OctetBorne->new(200);
$octet2 = OctetBorne->new(100);
$octet3 = $octet1 + $octet2; # 255
$octet4 = $octet1 - $octet2; # 100
$octet5 = 150 - $octet2; # 50Vous noterez que chacune des fonctions est ici par nécessité un constructeur, donc chacune s'assure de consacrer (avec bless) son nouvel objet dans la classe courante, quelle qu'elle soit ; nous supposons que la classe peut être héritée. Nous supposons aussi que si $y est une référence, c'est une référence à un objet de notre propre type. Au lieu de tester ref($y), nous pourrions appeler $y->isa("OctetBorne"), si nous voulions être plus complet (et exécuter plus lentement).
13-3. Opérateurs surchargeables▲
Vous ne pouvez surcharger que certains opérateurs, qui sont listés dans le tableau 13-1. Les opérateurs sont également listés dans le hachage %overload::ops mis à disposition lorsque vous employez use overload, bien que la catégorisation y soit légèrement différente.
|
Catégorie |
Opérateurs |
|---|---|
|
Conversion |
|
|
Arithmétique |
|
|
Logique |
|
|
Sur les bits |
|
|
Affectation |
|
|
Comparaison |
|
|
Mathématique |
|
|
Itératif |
|
|
Déréférence |
|
|
Pseudo |
nomethod fallback |
Notez que neg, bool, nomethod et fallback ne sont pas réellement des opérateurs Perl. Les cinq opérateurs de déréférence, "" et 0+ ne ressemblent sans doute pas non plus à des opérateurs. Néanmoins tous sont des clefs valides de la liste de paramètres que vous fournissez à use overload. Ceci n'est pas vraiment un problème. Nous allons vous révéler un petit secret : c'est un petit mensonge de dire que le pragma overload surcharge les opérateurs. Il surcharge les opérations sous-jacentes, qu'elles soient invoquées explicitement par leurs opérateurs « officiels » ou implicitement par un opérateur apparenté. (Les pseudo-opérateurs mentionnés ci-dessus ne peuvent être invoqués qu'implicitement.) En d'autres termes, la surcharge ne se produit pas au niveau syntaxique, mais au niveau sémantique. Le but n'est pas d'avoir l'air bien, mais de faire ce qui est bien. Vous pouvez généraliser.
Notez aussi que = ne surcharge pas l'opérateur d'affectation de Perl, comme vous pourriez le croire. Cela ne serait pas la bonne chose à faire. Nous verrons cela plus tard.
Commençons par traiter les opérateurs de conversion, non parce qu'ils sont les plus évidents (ils ne le sont pas), mais parce qu'ils sont les plus utiles. De nombreuses classes ne surchargent que la conversion en chaîne, spécifiée par la clef "". (Oui, ce sont vraiment deux doubles apostrophes à la suite.)
Opérateurs de conversion : "" , 0+ , bool
- Ces trois clefs vous permettent de fournir à Perl des comportements pour les conversions automatiques en chaîne, en nombre et en valeur booléenne, respectivement.
- La conversion en chaîne ou stringification a lieu lorsqu'une variable non-chaîne est utilisée en tant que chaîne. C'est ce qui se passe lorsque vous convertissez une variable en chaîne par affichage, par interpolation, par concaténation ou même en l'utilisant comme clef de hachage. C'est la conversion en chaîne qui fait que vous voyez quelque chose comme SCALAR(
0xba5fe0) lorsque vous essayez d'afficher un objet avecprint. - La conversion en nombre ou numification a lieu lorsqu'une variable non numérique est convertie en nombre dans un contexte numérique comme une expression mathématique, un indice de tableau, ou même un opérande de .., l'opérateur d'intervalle.
- Enfin, bien que personne ici n'ose tout à fait appeler cela boolification, vous pouvez définir comment un objet doit être interprété en contexte booléen (comme if, unless, while, for,
and,or,&&,||,?:, ou dans le bloc d'une expressiongrep) en créant un handler de bool. - Si vous avez défini l'un des trois opérateurs de conversion, les deux autres peuvent être autogénérés (nous expliquerons l'autogénération plus loin). Vos handlers peuvent retourner la valeur qu'ils veulent. Notez que si l'opération qui a déclenché la conversion est également surchargée, cette dernière surcharge aura lieu immédiatement après.
- Voici une démonstration de
""qui invoque le handler comme_chaine d'un objet au moment de la conversion en chaîne. N'oubliez pas de délimiter les doubles apostrophes :
package Personne;
use overload q("") => \&comme_chaine;
sub new {
my $classe = shift;
return bless { @_ } => $classe;
}
sub comme_chaine {
my $self = shift;
my ($clef, $valeur, $resultat);
while (($clef, $valeur) = each %$self) {
$resultat .= "$clef => $valeur\n";
}
return $resultat;
}
$obj = Personne->new(taille => 72, poids => 165, yeux => "marron");
print $obj;- Au lieu de quelque chose comme Personne
=HASH(0xba1350), ceci affiche (dans l'ordre du hachage) :
poids => 165
taille => 72
yeux => marron- (Nous espérons sincèrement que cette personne n'a pas été mesurée en kilos et en centimètres.)
Opérateurs arithmétiques : + , - , * , / , % , ** , x , . , neg
- Ceux-ci devraient tous vous êtres familiers, sauf neg, qui est une clef spéciale de surcharge du moins unaire : le
-de-123. La distinction entre les clefs neg et-vous permet de spécifier des comportements différents pour le moins unaire et pour le moins binaire, plus connu sous le nom de soustraction. - Si vous surchargez,
-mais pas neg, et qu'ensuite vous utilisez le moins unaire, Perl vous émulera un handler de neg. Ceci est appelé autogénération, et se produit lorsque certains opérateurs peuvent raisonnablement être déduits d'autres opérateurs (en supposant que les opérateurs surchargés auront le même rapport que les opérateurs ordinaires). Comme le moins unaire peut être exprimé en fonction du moins binaire (ainsi-123équivaut à0-123), Perl ne vous oblige pas à surcharger neg lorsque-suffit. (Bien sûr, si vous avez arbitrairement spécifié que le moins binaire divise le second paramètre par le premier, le moins unaire sera une excellente manière de lever une exception de division par zéro.) - La concaténation avec l'opérateur . peut être autogénérée à partir du handler de conversion de chaîne (voir
""ci-dessus).
Opérateur logique : !
- Si un handler pour
!n'est pas spécifié, il peut être autogénéré à partir du handler de bool,"", ou0+. Si vous surchargez l'opérateur!, l'opérateurnotdéclenchera aussi le comportement que vous avez spécifié. (Vous souvenez-vous de notre petit secret ?) - Vous serez peut-être surpris par l'absence des autres opérateurs logiques, mais ils ne peuvent pas pour la plupart être surchargés, car ils font un court-circuit. Ce sont en réalité des opérateurs de flot de contrôle qui doivent être capables de retarder l'évaluation de certains de leurs paramètres. C'est aussi la raison pour laquelle l'opérateur
?: n'est pas surchargeable.
Opérateurs sur les bits : & , | , ~ , ^ , << , >>
- L'opérateur
~est un opérateur unaire ; tous les autres sont binaires. Voici comment nous pourrions surcharger>>pour faire quelque chose commechop:
package DecaleChaine;
use overload
'>>' => \&decale_droite,
'""' => sub { ${ $_[0] } };
sub new {
my $classe = shift;
my $valeur = shift;
return bless \$valeur => $classe;
}
sub decale_droite {
my ($x, $y) = @_;
my $valeur = $$x;
substr($valeur, -$y) = "";
return bless \$valeur => ref($x);
}
$chameau = DecaleChaine->new("Chameau");
$belier = $chameau >> 2;
print $belier; # ChameOpérateurs d'affectation : += , -= , *= , /= , %= , **= , x= , .= , <<= , >>= , ++ , -
- Ces opérateurs d'affectation peuvent changer la valeur de leurs paramètres ou les laisser inchangés. Le résultat n'est affecté à l'opérateur de gauche que si la nouvelle valeur diffère de l'ancienne. Ceci permet d'utiliser le même handler à la fois pour
+=et pour+. Bien que ce soit permis, ceci est rarement recommandé, puisque d'après la sémantique décrite plus loin dans la section Lorsqu'un handler de surcharge fait défaut (nomethod et fallback), Perl invoquera de toute façon le handler de+, en supposant que+=n'ait pas été surchargé directement. - La concaténation (.
=) peut être autogénérée avec la conversion de chaîne, suivie de la concaténation de chaînes ordinaire. Les opérateurs++et-peuvent être autogénérés à partir de+et de-(ou de+=et de-=). - Il est attendu des handlers implémentant
++et-qu'ils mutent (altèrent) leur paramètre. Si vous vouliez que l'autodécrémentation fonctionne pour les lettres comme pour les nombres, vous pourriez le faire avec un handler comme ceci :
package DecMagique;
use overload
q(--) => \&decrementer,
q("") => sub { ${ $_[0] } };
sub new {
my $classe = shift;
my $valeur = shift;
bless \$valeur => $classe;
}
sub decrementer {
my @chaine = reverse split(//, ${ $_[0] } );
my $i;
for ($i = 0; $i < @chaine; $i++ ) {
last unless $chaine[$i] =~ /a/i;
$chaine[$i] = chr( ord($chaine[$i]) + 25 );
}
$chaine[$i] = chr( ord($chaine[$i]) - 1 );
my $resultat = join('', reverse @chaine);
$_[0] = bless \$resultat => ref($_[0]);
}
package main;
for $normal (qw/perl NZ Pa/) {
$magique = DecMagique->new($normal);
$magique--;
print "$normal devient $magique\n";
}- Ce qui affiche :
perl devient perk
NZ devient NY
Pa devient Oz- inversant précisément l'opérateur magique d'auto-incrémentation de Perl. L'opération
++$apeut être autogénérée avec$a+=1ou avec$a=$a+1, et$a-avec$a-=1ou$a=$a-1. Cependant, cela ne déclenche pas le comportement de copie d'un vrai opérateur++. Voir Le constructeur de copie (=) plus loin dans ce chapitre.
Opérateurs de comparaison : == , < , <= , > , >= , != , <=> , lt , le , gt , ge , eq , ne , cmp
- Si
<=>est surchargé, il peut servir pour autogénérer les comportements des opérateurs suivants :<,<=,>,>=,==, et!=. De manière similaire, sicmpest surchargé, il peut servir pour autogénérer les comportements des opérateurs suivants : lt,le,gt,ge, eq, andne. - Notez que la surcharge de
cmpne vous permettra pas de trier les objets aussi facilement que vous le souhaiteriez, car ce sont les versions converties en chaînes des objets qui seront comparées, et non les objets eux-mêmes. Si votre but était de comparer les objets eux-mêmes, vous auriez aussi à surcharger"".
Fonctions mathématiques : atan2 , cos , sin , exp , abs , log , sqrt
- Si
absn'est pas disponible, il peut être autogénéré à partir de<ou de<=>en combinaison avec le moins unaire ou avec la soustraction. Un opérateur-surchargé peut servir à autogénérer les handlers manquants du moins unaire ou de la fonctionabs, qui peuvent aussi être surchargés séparément. (Oui, nous savons queabsressemble à une fonction, alors que le moins unaire ressemble à un opérateur, mais ils ne sont pas si différents que cela en ce qui concerne Perl.)
Opérateur itératif : <>
- Le handler de
<>peut être déclenché en utilisant la fonction readline (lorsqu'elle lit dans un fichier, comme dans while (<FH>)) ou la fonctionglob(lorsqu'elle sert à faire un glob de fichiers, comme dans@files=<*.*>).
package TirageHeureux;
use overload
'<>' => sub {
my $self = shift;
return splice @$self, rand @$self, 1;
};
sub new {
my $classe = shift;
return bless [@_] => $classe;
}
package main;
$loto = new TirageHeureux 1 .. 49;
for (qw(1er 2eme 3eme 4eme 5eme 6eme)) {
$numero_chanceux = <$loto>;
print "Le $_ numéro chanceux est : $numero_chanceux\n";
}
$numero_chanceux = <$loto>;
print "\nEt le numéro complémentaire est : $numero_chanceux\n";- En France, ceci affiche :
The 1er numéro chanceux est : 14
The 2eme numéro chanceux est : 29
The 3eme numéro chanceux est : 45
The 4eme numéro chanceux est : 23
The 5eme numéro chanceux est : 9
The 6eme numéro chanceux est : 25
Et le numéro complémentaire est : 8- et vous rapporte 98 450 870 F.
Opérateurs de déréférencement : ${} , @{} , %{} , &{} , *{}
- Les tentatives de déréférencement d'une référence de scalaire, de tableau, de hachage, de fonction, ou de glob peuvent être interceptées en surchargeant ces cinq symboles.
- La documentation Perl en ligne de overload montre comment vous pouvez utiliser ces opérateurs pour simuler vos propres pseudo-hachages. Voici un exemple plus simple qui implémente un objet avec un tableau anonyme, mais permet de le référencer comme un hachage. N'essayez pas de le traiter comme un vrai hachage ; vous ne pourrez pas utiliser
deletepour supprimer des couples clef/valeur de l'objet. Si vous voulez combiner les notations de tableau et de hachage, utilisez un vrai pseudo-hachage (si l'on peut dire).
package PsychoHachage;
use overload '%{}' => \&comme_hachage;
sub comme_hachage {
my ($x) = shift;
return { @$x };
}
sub new {
my $classe = shift;
return bless [ @_ ] => $classe;
}
$bestiau = new PsychoHachage( taille => 72, poids => 365, type => "chameau" );
print $bestiau->{poids}; # affiche 365- Voyez aussi le chapitre 14, Variables liées, pour un mécanisme qui vous permet de redéfinir les opérations de base sur les hachages, les tableaux, et les scalaires.
Lorsque vous surchargez un opérateur, essayez de ne pas créer des objets avec des références sur eux-mêmes. Par exemple,
Ceci revient à chercher des ennuis, car si vous dites $animal += $legume, le résultat fera de $animal une référence à un tableau consacré dont le premier élément est $animal. Ceci est une référence circulaire, ce qui veut dire que si vous détruisez $animal, sa mémoire ne sera libérée que lorsque se termine votre processus (ou votre interpréteur). Voir Ramasse-miettes, références circulaires et références faibles au chapitre 8, Références.
13-4. Le constructeur de copie (=)▲
Bien qu'il ressemble à un opérateur ordinaire, = a une signification spéciale et légèrement non intuitive en tant que clef de surcharge. Il ne surcharge pas l'opérateur d'affectation de Perl. Il ne le peut pas, car cet opérateur doit être réservé pour l'affectation des références, sinon plus rien ne fonctionne.
Le handler de = est utilisé dans des situations où un opérateur de mutation (comme ++, -- ou l'un des opérateurs d'affectation) est appliqué à une référence qui partage son objet avec une autre référence. Le handler de = vous permet d'intercepter l'opérateur de mutation et de copier l'objet vous-même de telle façon que la copie seule soit mutée (altérée). Sans cela, vous écraseriez l'objet d'origine.
$copie = $origine; # ne copie que la référence
++$copie; # modifie l'objet partagé sous-jacentC'est ici qu'il faut faire bien attention. Supposons que $origine soit une référence à un objet. Pour faire en sorte que ++$copie ne modifie que $copie et non $origine, on commence par faire une copie de $copie et l'on affecte à $copie une référence à ce nouvel objet. Cette opération n'a lieu que lorsque ++$copie est exécuté, donc $copie est identique à $origine avant l'incrémentation — mais pas après. En d'autres termes, c'est le ++ qui reconnaît la nécessité de faire une copie et qui appelle votre constructeur de copie.
La nécessité de faire une copie n'est reconnue que par les opérateurs de mutations comme ++ ou +=, ou par nomethod, décrit plus loin. Si l'opération est autogénérée avec +, comme dans :
$copie = $origine;
$copie = $copie + 1;alors il n'y a pas de copie, car + ne sait pas qu'il est utilisé comme opérateur de mutation.
Si l'exécution d'un opérateur de mutation nécessite le constructeur de copie, mais qu'un handler pour = n'est pas spécifié, il peut être autogénéré comme copie de chaîne tant que l'objet reste un simple scalaire et non quelque chose de plus compliqué.
Par exemple, le code réellement exécuté lors de la séquence :
$copie = $origine;
...
++$copie;pourrait ressembler à quelque chose comme ceci :
$copie = $origine;
...
$copie = $copie->clone(undef, "");
$copie->incr(undef, "");Dans cet exemple $origine fait référence à un objet surchargé, ++ est surchargé avec \&incr, et = est surchargé avec \&clone.
Un comportement similaire est déclenché par $copie = $origine++, ce qui est interprété comme $copie = $origine; ++$origine.
13-5. Lorsqu'un handler de surcharge fait défaut (nomethod et fallback)▲
Si vous appliquez un opérateur non surchargé à un objet, Perl tente d'abord d'autogénérer un comportement à partir d'autres opérateurs surchargés en utilisant les règles décrites ci-dessus. Si cela échoue, Perl cherche un comportement de surcharge de nomethod et l'utilise s'il est disponible. Ce handler joue le même rôle pour les opérateurs que joue la fonction AUTOLOAD pour les fonctions : c'est ce que vous faites lorsque vous ne savez pas quoi faire d'autre.
Si elle est employée, la clef nomethod doit être suivie d'une référence à un handler prenant quatre paramètres (et non trois comme pour tous les autres handlers). Les trois premiers paramètres ne diffèrent pas de ceux des autres handlers ; le quatrième est une chaîne correspondante à l'opérateur dont le handler fait défaut. Ceci joue le même rôle que la variable $AUTOLOAD pour les fonctions AUTOLOAD.
Si Perl doit chercher un handler de, nomethod mais n'en trouve pas, une exception est levée.
Si vous voulez empêcher l'autogénération, ou si vous voulez qu'une tentative d'autogénération infructueuse ne produise aucune surcharge, vous pouvez définir la clef spéciale de surcharge fallback. Celle-ci comporte trois états :
undef
- Si fallback n'est pas définie, ou si
undeflui est explicitement affecté, la séquence d'événements de surcharge n'est pas modifiée : Perl cherche les handlers, tente l'autogénération, et finit par invoquer le handler de nomethod. Si cela échoue une exception est levée.
faux
- Si l'on affecte à fallback une valeur définie, mais fausse (comme
0), Perl ne tente jamais d'autogénération. Il appellera le handler de nomethod s'il existe, mais lèvera une exception dans le cas contraire.
vrai
- Ceci est presque le même comportement que pour
undef, mais aucune exception n'est levée si un handler approprié ne peut être synthétisé par autogénération. Au lieu de cela, Perl retourne au comportement non surchargé de cet opérateur, comme si la classe ne contenait aucun pragma use overload.
13-6. Surcharge de constantes▲
Vous pouvez modifier la façon dont Perl interprète les constantes avec overload::constant, qui est le plus utilement placé dans la méthode import d'un paquetage. (Si vous faites cela, vous devriez normalement invoquer overload::remove_constant dans la méthode unimport du paquetage pour que le paquetage puisse tout nettoyer lui-même lorsque vous le lui demandez.)
Les fonctions overload::constant et overload::remove_constant prennent chacune comme paramètre une liste de couples clef/valeur. Les clefs doivent être parmi les suivantes : integer, float, binary, q, et qr. Chaque valeur doit être le nom d'une fonction, une fonction anonyme ou une référence de code qui traitera les constantes.
sub import { overload::constant ( integer => \&entier_handler,
float => \&decimal_handler,
binary => \&base_handler,
q => \&chaine_handler,
qr => \®ex_handler ) }Les handlers que vous spécifiez pour integer et float sont invoqués à chaque fois que l'analyseur lexical de Perl traite un nombre constant. Ceci est indépendant du pragma use constant ; de simples instructions comme :
$annee = cube(12) + 1; # entier
$pi = 3.14159265358979; # nombre décimaldéclencheront le handler spécifié.
La clef binary vous permet d'intercepter des constantes binaires, octales et hexadécimales. q traite les chaînes entre apostrophes (dont les chaînes introduites avec q) et les sous-chaînes constantes contenues dans les chaînes citées avec qq et qx et les documents ici même. Pour finir, qr traite les parties constantes contenues dans les expressions régulières, comme il est mentionné à la fin du chapitre 5, Recherche de motif.
Le handler prend trois paramètres. Le premier paramètre est la constante d'origine, sous la forme fournie à Perl. Le deuxième paramètre contient la constante une fois qu'elle est interprétée par Perl ; par exemple, 123_456 apparaîtra comme 123456.
Le troisième paramètre n'est défini que pour les chaînes traitées par les handlers de q et de qr et aura pour valeur qq, q, s ou tr selon l'utilisation de la chaîne. qq signifie que la chaîne provient d'un contexte interpolé, comme les doubles apostrophes, les apostrophes inverses, une correspondance m// ou le motif d'une substitution s///. q signifie que la chaîne provient d'un contexte non interpolé, s signifie que la constante est la chaîne de remplacement d'une substitution s///, et tr signifie qu'elle est un composant d'une expression tr/// ou y///.
Le handler doit retourner un scalaire, qui sera utilisé à la place de la constante. Souvent, ce scalaire sera une référence à un objet surchargé, mais rien ne vous empêche de faire quelque chose de plus pervers :
package Doubleur; # Un module à placer dans Doubleur.pm
use overload;
sub import { overload::constant ( integer => \&handler,
float => \&handler ) }
sub handler {
my ($orig, $interp, $contexte) = @_;
return $interp * 2; # doubler toutes les constantes
}
1;Notez que handler est partagé par les deux clefs, ce qui fonctionne correctement dans ce cas. Maintenant quand vous dites :
use Doubleur;
$ennuis = 123; # ennuis est maintenant 246
$danger = 3.21; # danger est maintenant 6.42vous redéfinissez le monde.
Si vous interceptez les chaînes constantes, il est conseillé de fournir également un opérateur de concaténation (« . »), puisqu'une expression interpolée comme "ab$cd!!" n'est qu'un raccourci pour l'expression plus longue 'ab' . $cd . '!!'. De façon similaire, on considère les nombres négatifs comme les négations de constantes positives, donc vous devez fournir un handler pour neg lorsque vous interceptez des entiers ou des nombres décimaux. (Il n'y avait pas besoin de faire cela ci-dessus, car nous retournons des nombres, et non des références d'objets surchargés.)
Notez que overload::constant ne se propage pas à l'intérieur d'un eval compilé au moment de l'exécution, ce qui est soit un bogue soit une fonctionnalité selon votre point de vue.
13-7. Fonctions publiques de surcharge▲
Depuis la version 5.6 de Perl, le pragma use overload fournit les fonctions suivantes à usage public :
overload::StrVal(OBJ)
- Cette fonction retourne la valeur de chaîne que retournerait OBJ en l'absence de la surcharge de la conversion en chaîne (
"").
overload::Overloaded(OBJ)
- Cette fonction retourne vrai si OBJ est sujet à la surcharge d'un opérateur quel qu'il soit, et faux s'il ne l'est pas.
overload::Method(OBJ , OPERATEUR)
- Cette fonction retourne une référence au code qui implémente la surcharge de OPERATEUR lorsqu'il opère sur OBJ, ou
undefsi une telle surcharge n'existe pas.
13-8. Héritage et surcharge▲
L'héritage interagit avec la surcharge de deux façons. La première a lieu lorsqu'un handler est nommé en tant que chaîne au lieu d'être spécifié comme référence de code ou comme fonction anonyme. Lorsqu'il est nommé en tant que chaîne le handler est interprété comme une méthode, et peut donc être hérité de surclasse.
La deuxième interaction entre l'héritage et la surcharge provient du fait que toute classe dérivée d'une classe surchargée est elle-même sujette à cette surcharge. En d'autres termes, la surcharge est elle-même héritée. L'ensemble des handlers d'une classe est l'union des handlers de tous les ancêtres de cette classe, récursivement. Si un handler peut être trouvé dans plusieurs ancêtres différents, le choix du handler à utiliser est régi par les règles habituelles d'héritage de méthode. Par exemple, si la classe Alpha hérite des classes Beta et Gamma dans cet ordre, et que la classe Beta surcharge + avec \&Beta::fonction_plus, mais que la classe Gamma surcharge + avec la chaîne "methode_plus", alors c'est Beta::fonction_plus qui sera appelée lorsque vous appliquez + à un objet Alpha.
Comme la valeur de la clef fallback n'est pas un handler, son héritage n'est pas régi par les règles ci-dessus. Dans l'implémentation actuelle, on utilise la valeur de fallback du premier ancêtre surchargé, mais ceci est accidentel et sujet à modification sans préavis (enfin, sans trop de préavis).
13-9. Surcharge à l'exécution▲
Comme les instructions use sont exécutées à la compilation, la seule façon de modifier la surcharge à l'exécution est :
eval " use overload '+' => \&mon_addition ";Vous pouvez aussi dire :
eval " no overload '+', '--', '<=' ";bien que l'emploi de ces formules à l'exécution soit douteux.
13-10. Surcharge de diagnostics▲
Si votre Perl est compilé avec -DDEBUGGING, vous pouvez voir les messages de diagnostics de surcharge lorsque vous exécutez un programme avec l'option -Do ou son équivalent. Vous pouvez aussi déduire quelles opérations sont surchargées en utilisant la commande m du débogueur interne de Perl.
Si maintenant vous vous sentez un peu surchargé, le chapitre suivant vous permettra peut-être de lier un peu la sauce.
14. Variables liées▲
Certaines activités humaines nécessitent un déguisement. Parfois l'intention est de tromper, mais le plus souvent il s'agit de communiquer quelque chose de vrai à un niveau plus profond. Souvent, par exemple, quelqu'un qui vous fait passer un entretien d'embauche s'attend à ce que vous portiez une cravate pour signifier que vous souhaitez sérieusement vous intégrer, même si vous savez tous les deux que vous ne porterez jamais de cravate au travail. C'est curieux lorsqu'on y pense : nouer un morceau de tissu autour de son cou peut magiquement vous obtenir un emploi. Dans la culture Perl, l'opérateur de liaison tie(121) joue un rôle similaire : il vous permet de créer une variable apparemment normale qui, derrière son déguisement, est en fait un objet Perl à part entière dont on peut s'attendre qu'elle ait sa propre personnalité intéressante. C'est juste un drôle de bout de magie, comme tirer Bugs Bunny d'un chapeau.
Formulé autrement, les drôles de caractères $, @, % ou * devant un nom de variable en disent long à Perl et à ses programmeurs — ils sous-entendent chacun un ensemble spécifique de comportements caractéristiques. Vous pouvez déformer ces comportements de diverses manières utiles avec tie en associant la variable à une classe qui implémente un nouvel ensemble de comportements. Par exemple, vous pouvez créer un hachage Perl ordinaire et le lier avec tie à une classe qui transforme le hachage en base de données, de sorte que quand vous lisez des valeurs du hachage, Perl va par magie chercher les données dans un fichier de données externe, et que quand vous affectez des valeurs au hachage, Perl stocke par magie les données dans le même fichier. Ici, « par magie » signifie « en effectuant de manière transparente quelque chose de très compliqué ». Vous connaissez le vieux dicton : toute technologie suffisamment avancée est indiscernable d'un script Perl. (Sérieusement, les gens qui jouent avec les tripes de Perl utilisent magique comme terme technique désignant toute sémantique supplémentaire attachée à des variables telles que %ENV ou %SIG. Les variables liées n'en sont qu'une extension.)
Perl possède déjà les fonctions internes dbmopen et dbmclose, qui lient magiquement des variables de hachage à des bases de données, mais ces fonctions datent du temps où Perl n'avait pas l'opérateur tie. Maintenant, tie fournit un mécanisme plus général. En fait, Perl lui-même implémente dbmopen et dbmclose à l'aide de tie.
Vous pouvez lier avec tie un scalaire, un tableau, un hachage ou un handle de fichier (via son typeglob) à toute classe qui fournit les méthodes nommées de manière appropriée pour intercepter et simuler un accès normal à ces variables. La première de ces méthodes est invoquée au moment de la liaison elle-même : le fait de lier une variable invoque toujours un constructeur, qui retourne en cas de succès un objet que Perl stocke à l'abri des regards, caché à l'intérieur de la variable « normale ». Vous pouvez toujours récupérer cet objet plus tard en appliquant la fonction tied à la variable normale :
tie VARIABLE, NOM_CLASSE, LISTE; # relie VARIABLE à NOM_CLASSE
$objet = tied VARIABLE;Ces deux lignes sont équivalentes à :
$objet = tie VARIABLE, NOM_CLASSE, LISTE;Une fois qu'elle est liée, vous pouvez traiter la variable normale normalement, mais chaque accès invoque automatiquement une méthode de l'objet sous-jacent ; toute la complexité de la classe est cachée derrière ces appels de méthodes. Si plus tard vous voulez rompre l'association entre la variable et la classe, vous pouvez délier la variable avec untie :
untie VARIABLE;Vous pouvez presque considérer tie comme une espèce de bless bizarre, à ceci près qu'il consacre une simple variable au lieu d'une référence à un objet. Il peut aussi prendre des paramètres supplémentaires, à l'instar d'un constructeur — ce qui n'est pas terriblement surprenant, dans la mesure où il invoque un constructeur en interne, dont le nom dépend du type de la variable que vous liez : TIESCALAR, TIEARRAY, TIEHASH ou TIEHANDLE.(122) Ces constructeurs sont invoqués en tant que méthodes de classe, avec NOM_CLASSE comme invoquant, plus tout paramètre additionnel que vous donnez dans LISTE. (La VARIABLE n'est pas passée au constructeur.)
Ces quatre constructeurs retournent chacun un objet de la façon habituelle. Ni les constructeurs, ni les autres méthodes de la classe ne se soucient vraiment de savoir s'ils ont été invoqués par tie, puisque vous pouvez toujours les invoquer directement si vous le souhaitez. En un sens, toute la magie se situe dans tie et non dans la classe implémentant le tie. La classe n'est en ce qui la concerne qu'une classe ordinaire avec des drôles de noms de méthode. (En effet, certains modules liés fournissent des méthodes supplémentaires qui ne sont pas visibles par la variable liée ; ces méthodes doivent être appelées explicitement comme vous le feriez pour toute autre méthode d'objet. De telles méthodes supplémentaires pourraient fournir des services comme le verrouillage de fichiers, la protection de transactions, ou toute autre chose que pourrait faire une méthode d'instance.)
Ainsi ces constructeurs consacrent (avec bless) et retournent une référence d'objet comme le ferait tout autre constructeur. Cette référence ne doit pas forcément référencer le même type de variable que celle qui est liée ; elle doit simplement être consacrée afin que la variable liée puisse retrouver le chemin de votre classe en cas de besoin. Par exemple, notre long exemple de TIEARRAY utilise un objet basé sur un hachage afin qu'il puisse commodément contenir des informations supplémentaires sur le tableau qu'il émule.
La fonction tie n'exécutera pas à votre place de use ou de require — vous devez le faire vous-même explicitement, avant d'appeler le tie. (Cela dit, pour des raisons de compatibilité descendante, la fonction dbmopen tentera de faire un use de l'une ou l'autre implémentation DBM. Mais vous pouvez l'empêcher de choisir en faisant un use explicite, du moment que le module que vous spécifiez figure dans la liste des modules que peut choisir dbmopen. Voir la doc en ligne du module AnyDBM_File pour une explication plus complète.)
Les méthodes appelées par une variable liée ont un nom prédéterminé comme FETCH (récupérer) et STORE (stocker), puisqu'elles sont invoquées implicitement (c'est-à-dire déclenchées par des événements spécifiques) de l'intérieur de la machinerie de Perl. Ces noms sont en MAJUSCULES, suivant la convention courante pour les fonctions appelées implicitement. (D'autres noms spéciaux qui suivent cette convention sont BEGIN, CHECK, INIT, END, DESTROY et AUTOLOAD, sans parler de UNIVERSAL->VERSION. En fait, presque toutes les variables prédéfinies et les handles de fichiers de Perl sont en majuscules : STDIN, SUPER, CORE, CORE::GLOBAL, DATA, @EXPORT, @INC, @ISA, @ARGV et %ENV. Bien entendu, les opérateurs internes et les pragmas, à l'extrême opposé, n'ont pas du tout de majuscules.)
La première chose que nous traiterons est extrêmement simple : comment lier une variable scalaire.
14-1. Liaison de scalaire▲
Afin d'implémenter un scalaire lié, une classe doit définir les méthodes suivantes : TIESCALAR, FETCH et STORE (et éventuellement DESTROY). Lorsque vous liez une variable scalaire avec tie, Perl appelle TIESCALAR. Lorsque vous consultez la variable liée, il appelle FETCH, et lorsque vous affectez une valeur à la variable, il appelle STORE. Si vous avez gardé en main l'objet retourné par le tie initial (ou si vous le récupérez plus tard avec tied), vous pouvez accéder vous-même à l'objet sous-jacent — ceci ne déclenche ni FETCH ni STORE. En tant qu'objet, il n'est pas du tout magique, et tout à fait objectif.
S'il existe une méthode DESTROY, Perl l'invoque lorsque disparaît la dernière référence à l'objet lié, comme pour tout autre objet. Cela se produit lorsque votre programme se termine ou lorsque vous appelez untie, ce qui élimine la référence utilisée par tie. Cependant, untie n'élimine pas les références existantes que vous pourriez avoir stockées ailleurs ; DESTROY est reporté jusqu'à ce que ces références aient également disparu.
Les paquetages Tie::Scalar et Tie::StdScalar, situés tous les deux dans le module Tie::Scalar, fournissent des définitions de classe de base simples si vous ne souhaitez pas définir toutes ces méthodes vous-même. Tie::Scalar fournit des méthodes élémentaires qui ne font quasiment rien, et Tie::StdScalar fournit des méthodes qui font se comporter un scalaire lié comme un scalaire Perl ordinaire. (Ce qui semble particulièrement inutile, mais parfois vous voulez juste un léger emballage autour de la sémantique de scalaire ordinaire, par exemple pour compter le nombre de fois qu'une variable donnée est affectée.)
Avant de vous montrer un exemple recherché et une description complète de toute la mécanique, voici juste un avant-goût pour vous mettre en appétit — et pour vous montrer à quel point c'est facile. Voici un programme complet :
#!/usr/bin/perl
package Centime;
sub TIESCALAR { bless \my $self, shift }
sub STORE { ${ $_[0] } = $_[1] } # faire l'action par défaut
sub FETCH { sprintf "%.02f", ${ my $self = shift } } # valeur arrondie
package main;
tie $francs, "Centime";
$francs = 45.00;
$francs *= 1.0715; # taxe
$francs *= 1.0715; # et double taxe !
print "Ce sera $francs francs, s'il vous plaît.\n";À l'exécution, le programme affiche :
Ce sera 51.67 francs, s'il vous plaît.Pour voir la différence, mettez l'appel à tie en commentaire. Vous obtiendrez :
Ce sera 51.66505125 francs, s'il vous plaît.Reconnaissons que cela représente beaucoup d'efforts juste pour arrondir des nombres.
14-1-a. Méthodes de liaison de scalaire▲
Maintenant que vous avez vu un échantillon de ce qui va venir, développons une classe de liaison de scalaire plus recherchée. Au lieu d'utiliser un paquetage prêt à l'emploi pour la classe de base (et étant donné que les scalaires sont si simples), nous examinerons tour à tour chacune des quatre méthodes en construisant une classe exemple nommée FichierScalaire. Les scalaires liés à cette classe contiennent des chaînes ordinaires, et chaque variable de ce type est implicitement associée au fichier dans lequel la chaîne est stockée. (Vous pourriez nommer vos variables de manière à vous rappeler à quel fichier vous faites référence.) Les variables sont liées à la classe de la manière suivante :
use FichierScalaire; # charger FichierScalaire.pm
tie $chameau, "FichierScalaire", "/tmp/camel.ide";Une fois la variable liée, son contenu d'origine est écrasé, et la connexion interne entre la variable et son objet supplante la sémantique normale de la variable. Lorsque vous demandez la valeur de $chameau, elle lit le contenu de /tmp/camel.ide, et lorsque vous affectez une valeur à $chameau, elle écrit le nouveau contenu dans /tmp/camel.ide, écrasant tout occupant précédent.
La liaison est faite sur la variable et non sur sa valeur, donc la nature liée d'une variable n'est pas préservée par l'affectation. Par exemple, supposons que vous copiiez une variable liée :
$dromadaire = $chameau;Au lieu de lire la valeur comme à l'ordinaire dans la variable scalaire $chameau, Perl invoque la méthode FETCH de l'objet associé sous-jacent. C'est comme si vous aviez écrit ceci :
$dromadaire = (tied $chameau)->FETCH():Ou si vous retenez l'objet retourné par tie, vous pouvez utiliser cette référence directement, comme dans le code exemple suivant :
$cide = tie $chameau, "FichierScalaire", "/tmp/camel.ide";
$dromadaire = $chameau; # par l'interface implicite
$dromadaire = $cide->FETCH(); # pareil, mais explicitementSi la classe fournit des méthodes autres que TIESCALAR, FETCH, STORE, et DESTROY, vous pouvez utiliser $cide pour les invoquer manuellement. Toutefois, ordinairement on s'occupe de ses propres affaires et on laisse l'objet sous-jacent tranquille, ce qui explique qu'on utilise rarement la valeur de retour de tie. Vous pouvez toujours récupérer l'objet avec tied si vous en avez besoin plus tard (par exemple, si la classe documente d'autres méthodes dont vous avez besoin). Ne pas utiliser l'objet retourné élimine aussi certains types d'erreurs, ce que nous traiterons plus loin.
Voici le préambule de notre classe, que nous mettrons dans FichierScalaire.pm :
package FichierScalaire;
use Carp; # Transmettre gentiment les messages d'erreur.
use strict; # S'imposer un peu de discipline.
use warnings; # Activer les avertissements de portée lexicale.
use warnings::register; # Permettre à l'utilisateur de dire
# "use warnings 'FichierScalaire'".
my $compteur = 0; # Compteur interne de FichierScalaires liés.Le module standard Carp exporte les fonctions carp, croak, et confess, que nous utiliserons dans le code plus loin. Comme d'habitude, voir le chapitre 32, Modules standards, ou la doc en ligne pour plus de détails sur Carp.
Les méthodes suivantes sont définies par la classe :
NOM_CLASSE->TIESCALAR(LISTE)
- La méthode TIESCALAR de la classe est déclenchée lorsque vous liez une variable avec
tie. La LISTE en option contient les paramètres nécessaires pour initialiser l'objet correctement. (Dans notre exemple, il n'y a qu'un seul paramètre : le nom du fichier.) La méthode doit retourner un objet, mais celui-ci n'est pas nécessairement une référence à un scalaire. Mais il l'est dans notre exemple.
sub TIESCALAR { # dans FichierScalaire.pm
my $classe = shift;
my $nom_fichier = shift;
$compteur++; # Une lexicale visible dans le fichier,
# privée pour la classe
return bless \$nom_fichier, $classe;
}- Comme il n'y a pas d'équivalent scalaire des compositeurs de tableau et de hachage anonymes [] et
{}, nous consacrons simplement le référent de la variable lexicale, qui devient de fait anonyme dès la sortie de la portée lexicale du nom. Ceci fonctionne bien (vous pourriez faire de même avec les tableaux et les hachages) tant que la variable est réellement lexicale. Si vous tentiez cette astuce avec une variable globale, vous pourriez croire vous en sortir jusqu'à ce que vous tentiez de créer un autre camel.ide. Ne soyez pas tenté d'écrire quelque chose comme ceci :
sub TIESCALAR { bless \$_[1], $_[0] } # FAUX, pourrait référencer
# une variable globale- Un constructeur écrit de manière plus robuste pourrait vérifier que le fichier est accessible. Nous vérifions d'abord que le fichier est lisible, comme nous ne souhaitons pas écraser la variable existante. (En d'autres termes, il ne faut pas supposer que l'utilisateur commence par écrire dans le fichier. Il pourrait garder précieusement son ancien fichier camel.ide produit par une exécution antérieure du programme.) Si nous ne pouvons pas ouvrir ou créer le fichier spécifié, nous indiquons l'erreur gentiment en retournant
undefet en affichant en option un avertissement avec carp. (Au lieu de cela nous pourrions moins gentiment faire un croak — c'est une affaire de goût.) Nous utilisons le pragma warnings pour déterminer si l'utilisateur s'intéresse ou non à notre avertissement :
sub TIESCALAR { # dans FichierScalaire.pm
my $classe = shift;
my $nom_fichier = shift;
my $hf;
if (open $hf, "<", $nom_fichier or
open $hf, ">", $nom_fichier)
{
close $hf;
$compteur++;
return bless \$nom_fichier, $classe;
}
carp "Impossible de lier $nom_fichier: $!" if warnings::enabled();
return;
}- Étant donné un tel constructeur, nous pouvons à présent associer le scalaire
$chaineau fichier camel.ide :
tie ($chaine, "FichierScalaire", "camel.ide") or die;- (Nous faisons encore des suppositions que nous ne devrions pas faire. Dans une version en production, nous n'ouvririons probablement qu'une fois le fichier, en retenant le handle de fichier ainsi que le fichier pour la durée de la liaison, et en gardant tout ce temps un verrouillage exclusif sur le handle à l'aide de
flock. Sans cela nous risquons des situations de concurrence (race conditions) — voir Gestion des problèmes de synchronisation dans le chapitre 23, Sécurité.)
SELF->FETCH
- Cette méthode est invoquée à chaque fois que vous accédez à une variable liée (c'est-à-dire, que vous la lisez). Elle ne prend pas de paramètre hormis l'objet lié à la variable. Dans notre exemple, cet objet contient le nom de fichier :
sub FETCH {
my $self = shift;
confess "Je ne suis pas une méthode de classe" unless ref $self;
return unless open my $hf, $$self;
read($hf, my $valeur, -s $hf); # NB: n'utilisez pas -s avec
# les tubes !
return $valeur;
}- Cette fois nous avons décidé d'exploser (lever une exception) si FETCH reçoit autre chose qu'une référence. (Soit elle était invoquée comme méthode de classe, soit quelqu'un l'a appelée par erreur en tant que fonction.) Nous n'avons pas d'autre moyen de retourner une erreur, donc c'est probablement la réaction appropriée. En fait, Perl aurait de toute façon levé une exception dès que nous aurions tenté de déréférencer
$self; nous sommes simplement polis en utilisant confess pour déverser une trace arrière complète de la pile sur l'écran de l'utilisateur. (Si l'on peut considérer cela poli.) - Nous pouvons maintenant voir le contenu de camel.ide lorsque nous disons :
tie($chaine, "FichierScalaire", "camel.ide");
print $chaine;SELF->STORE(VALEUR)
- Cette méthode est exécutée lorsqu'une valeur est affectée à la variable liée. Le premier paramètre, SELF, est comme toujours l'objet associé à la variable ; VALEUR est ce qui est affecté à la variable. (Nous utilisons le terme « affecté » au sens large — toute opération qui modifie la variable peut appeler STORE.)
sub STORE {
my($self,$valeur) = @_;
ref $self or confess "pas une méthode de classe";
open my $hf, ">", $$self or croak "impossible d'écraser $$self: $!";
syswrite($hf, $valeur) == length $valeur
or croak "impossible d'écrire dans $$self: $!";
close $hf or croak "impossible de fermer $$self: $!";
return $valeur;
}- Après avoir « affecté » la nouvelle valeur, nous la retournons — car c'est ce que fait l'affectation. Si l'affectation n'a pas réussi, nous affichons l'erreur avec croak. Parmi les causes éventuelles d'échec : nous n'avions pas la permission d'écrire dans le fichier associé, ou le disque s'est rempli, ou des malins génies ont infesté le contrôleur de disque. Parfois vous contrôlez la magie, et parfois c'est elle qui vous contrôle.
- Nous pouvons maintenant écrire dans camel.ide en disant ceci :
tie($chaine, "FichierScalaire", "camel.ide");
$chaine = "Voici la première ligne de camel.ide\n";
$chaine .= "Et voici une deuxième ligne, rajoutée automatiquement.\n";SELF->DESTROY
- Cette méthode est déclenchée lorsque l'objet associé à la variable liée est sur le point d'être recyclé par le ramasse-miettes, au cas où il devrait faire quelque chose de spécial pour nettoyer autour de lui. Comme pour les autres classes, cette méthode est rarement nécessaire, puisque Perl vous libère automatiquement la mémoire de l'objet moribond. Ici, nous définissons une méthode DESTROY qui décrémente notre compteur de fichiers liés :
- Nous pourrions alors aussi fournir une méthode de classe supplémentaire pour récupérer la valeur courante du compteur. À vrai dire, elle ignore si elle est appelée comme méthode de classe ou d'objet, mais vous n'avez plus d'objet après le DESTROY, non ?
sub count {
# my $invoquant = shift;
$compteur;
}- Vous pouvez l'appeler comme méthode de classe à tout moment comme ceci :
if (FichierScalaire->count) {
warn "Il reste des FichierScalaires liés quelque part...\n";
}C'est à peu près tout ce qu'il y a à faire. À vrai dire, c'est plus que tout ce qu'il y a à faire, puisque nous avons fait quelques choses gentilles pour être complets, robustes, et esthétiques (ou pas). Il est certainement possible de faire des classes TIESCALAR plus simples.
14-1-b. Variables compteur magiques▲
Voici une classe Tie::Counter simple, inspirée du module CPAN de même nom. Les variables liées à cette classe s'incrémentent de 1 à chaque fois qu'elles sont utilisées. Par exemple :
tie my $compte "Tie::Counter", 100;
@tableau = qw /Rouge Vert Bleu/;
for my $couleur (@tableau) { # Affiche :
print " $compteur $couleur\n"; # 100 Rouge
} # 101 Vert
# 102 BleuLe constructeur prend en option un paramètre supplémentaire spécifiant la valeur initiale du compteur, par défaut 0. L'affectation au compteur lui donne une nouvelle valeur. Voici la classe :
package Tie::Counter;
sub FETCH { ++ ${ $_[0] } }
sub STORE { ${ $_[0] } = $_[1] }
sub TIESCALAR {
my ($classe, $valeur) = @_;
$valeur = 0 unless defined $valeur;
bless \$valeur => $classe;
}
1; # nécessaire dans un moduleVous voyez comme c'est court ? Nul besoin de beaucoup de code pour assembler une classe comme celle-ci.
14-1-c. Bannir $_ par magie▲
Cette classe de liaison curieusement exotique permet d'interdire les emplois non localisés de $_. Au lieu d'intégrer un module avec use, qui invoque la méthode import de la classe, ce module doit être chargé avec no pour appeler la méthode unimport rarement utilisée. L'utilisateur dit :
no Souligne;Alors toutes les utilisations de $_ comme variable globale non localisée lèvent une exception.
Voici une suite de tests pour le module :
#!/usr/bin/perl
no Souligne;
@tests = (
"Affectation" => sub { $_ = "Mal" },
"Lecture" => sub { print },
"Comparaison" => sub { $x = /mauvais/ },
"Chop" => sub { chop },
"Test fichier" => sub { -x },
"Emboîté" => sub { for (1..3) { print } },
);
while ( ($nom, $code) = splice(@tests, 0, 2) ) {
print "Tester $nom : ";
eval { &$code };
print $@ ? "détecté" : " raté !";
print "\n";
}qui affiche ce qui suit :
Tester Affectation : détecté
Tester Lecture : détecté
Tester Comparaison : détecté
Tester Chop : détecté
Tester Test fichier : détecté
Tester Emboîté : 123 raté !Ce dernier est « raté » parce qu'il est localisé correctement par la boucle for et donc sûr d'accès.
Voici le module curieusement exotique Souligne lui-même. (Avons-nous mentionné qu'il est curieusement exotique ?) Il fonctionne, car la magie liée est de fait cachée par un local. Le module fait le tie dans son propre code d'initialisation pour le cas où il serait appelé par un require.
package Souligne;
use Carp;
sub TIESCALAR { bless \my $toto => shift }
sub FETCH { croak 'Accès en lecture à $_ interdit' }
sub STORE { croak 'Accès en écriture à $_ interdit' }
sub unimport { tie($_, __PACKAGE__) }
sub import { untie $_ }
tie($_, __PACKAGE__) unless tied $_;
1;Il est difficile de mêler de manière utile dans votre programme des appels à use et à no pour cette classe, car ils se produisent tous à la compilation, et non à l'exécution. Vous pourriez appeler Souligne->import et Souligne->unimport directement, comme le font use et no. Mais normalement, pour vous permettre d'utiliser $_ librement, vous lui appliqueriez simplement local, ce qui est tout l'intérêt de la manipulation.
14-2. Liaison de tableau▲
Une classe qui implémente un tableau lié doit définir au moins les méthodes TIEARRAY, FETCH, et STORE. Il y a aussi beaucoup de méthodes optionnelles : la méthode DESTROY omniprésente, bien entendu, mais aussi les méthodes STORESIZE et FETCHSIZE, qui donnent accès à $#tableau et à scalar(@tableau). De plus, CLEAR est déclenchée lorsque Perl doit vider un tableau, et EXTEND lorsque Perl aurait par avance alloué plus de mémoire pour un vrai tableau.
Vous pouvez aussi définir les méthodes POP, PUSH, SHIFT, UNSHIFT, SPLICE, DELETE, et EXISTS si vous voulez que les fonctions Perl correspondantes fonctionnent avec le tableau lié. La classe Tie::Array peut servir de classe de base pour implémenter les cinq premières de ces fonctions à partir de FETCH et de 0TORE. (L'implémentation par défaut dans Tie::Array de DELETE et de EXISTS appelle simplement croak.) Tant que vous définissez FETCH et STORE, le type de structure de données contenu par votre objet n'a pas d'importance.
D'un autre côté, la classe de base Tie::StdArray (définie dans le module standard Tie::Array module) fournit des méthodes par défaut qui supposent que l'objet contient un tableau ordinaire. Voici une simple classe de liaison de tableau qui en fait usage. Parce qu'elle utilise Tie::StdArray comme classe de base, seules sont à définir les méthodes qui doivent être traitées d'une manière non standard.
#!/usr/bin/perl
package TableauHorloge;
use Tie::Array;
our @ISA = 'Tie::StdArray';
sub FETCH {
my($self,$emplacement) = @_;
$self->[ $emplacement % 12 ];
}
sub STORE {
my($self,$emplacement,$valeur) = @_;
$self->[ $emplacement % 12 ] = $valeur;
}
package main;
tie my @tableau, 'TableauHorloge';
@tableau = ( "a" ... "z" );
print "@tableau\n";Lorsqu'il est exécuté, le programme affiche "yzopqrstuvwx". Cette classe implémente un tableau ne comportant que douze cases, comme les heures du cadran d'une horloge, numérotées de 0 à 11. Si vous demandez le 15e élément du tableau, vous obtenez en réalité le 3e. Vous pouvez voir la classe comme une aide pour les gens qui n'ont pas appris à lire l'heure sur une horloge à 24 heures.
14-2-a. Méthodes de liaison de tableau▲
C'était la méthode simple. Voyons maintenant les menus détails. Pour illustrer notre propos, nous implémenterons un tableau de taille limitée à la création. Si vous tentez d'accéder à quelque chose au-delà de cette limite, une exception est levée. Par exemple :
use TableauLimite;
tie @tableau, "TableauLimite", 2;
$tableau[0] = "bon";
$tableau[1] = "bien";
$tableau[2] = "super";
$tableau[3] = "oula"; # Interdit : affiche un message d'erreurLe code en préambule de cette classe est le suivant :
Pour éviter de devoir définir SPLICE plus tard, nous l'hériterons de la classe Tie::Array :
NOM_CLASSE->TIEARRAY(LISTE)
- En tant que constructeur de la classe, TIEARRAY doit retourner une référence consacrée qui émulera le tableau lié.
- Dans cet exemple, juste pour vous montrer que vous ne devez pas nécessairement retourner une référence de tableau, nous choisissons de représenter notre objet avec une référence de hachage. Un hachage fonctionne bien comme type générique d'enregistrement : la valeur de la clef « LIMITE » du hachage stocke la limite maximale autorisée, et sa valeur « DONNEES » contient les données réelles. Si quelqu'un à l'extérieur de la classe tente de déréférencer l'objet retourné (en pensant sans doute qu'il s'agit d'une référence à un tableau), une exception est levée.
sub TIEARRAY {
my $classe = shift;
my $limite = shift;
confess "usage: tie(\@tableau, 'TableauLimite', index_max)"
if @_ || $limite =~ /\D/;
return bless { LIMITE => $limite, DONNEES => [] }, $classe;
}- Maintenant nous pouvons dire :
tie(@tableau, "TableauLimite", 3); # l'index maximum autorisé est 3- pour nous assurer que le tableau n'aura jamais plus de quatre éléments. À chaque fois qu'un élément du tableau est consulté ou enregistré, FETCH ou STORE sera appelée tout comme elle l'était pour les scalaires, mais avec l'index en paramètre supplémentaire.
SELF->FETCH(INDEX)
- Cette méthode est exécutée à chaque fois que l'on accède à un élément du tableau lié. Elle prend un paramètre après l'objet : l'index de la valeur que nous tentons de récupérer.
sub FETCH {
my ($self, $index) = @_;
if ($index > $self->{LIMITE}) {
confess "Dépassement de limite du tableau :
$index > $self->{LIMITE}";
}
return $self->{DONNEES}[$index];
}SELF->STORE(INDEX,VALEUR)
- Cette méthode est invoquée à chaque fois que l'on affecte une valeur à un élément du tableau. Elle prend deux paramètres après l'objet : l'index de la case où nous tentons de stocker quelque chose et la valeur que nous tentons d'y mettre.
sub STORE {
my($self, $index, $valeur) = @_;
if ($index > $self->{LIMITE} ) {
confess "Dépassement de limite du tableau :
$index > $self->{LIMITE}";
}
return $self->{DONNEES}[$index] = $valeur;
}SELF->DESTROY
- Perl appelle cette méthode lorsque la variable liée doit être détruite et sa mémoire récupérée. Ceci n'est presque jamais utile dans un langage avec un ramasse-miettes, donc cette fois-ci nous la laissons de côté.
SELF->FETCHSIZE
- La méthode FETCHSIZE devrait retourner le nombre total d'éléments dans le tableau lié associé à SELF. C'est l'équivalent de
scalar(@tableau), qui est habituellement égal à$#tableau+1.
SELF->STORESIZE(NOMBRE)
- Cette méthode spécifie le NOMBRE total d'éléments dans le tableau lié associé à SELF. Si le tableau rétrécit, vous devez supprimer les éléments au-delà de NOMBRE. Si le tableau grandit, vous devez vous assurer que les nouvelles positions sont indéfinies. Dans notre classe TableauLimite, nous empêchons aussi que le tableau ne grandisse au-delà de la limite spécifiée initialement.
sub STORESIZE {
my ($self, $nombre) = @_;
if ($nombre > $self->{LIMITE}) {
confess "Dépassement de limite du tableau :
$nombre > $self->{LIMITE}";
}
$#{$self->{DONNEES}} = $nombre;
}SELF->EXTEND(NOMBRE)
- Perl se sert de la méthode EXTEND pour indiquer que le tableau risque d'augmenter pour accommoder NOMBRE éléments. Ainsi vous pouvez tout de suite allouer la mémoire en un gros morceau au lieu de l'allouer plus tard et petit à petit avec de nombreux appels successifs. Comme notre TableauLimite possède une taille limite fixe, nous ne définissons pas cette méthode.
SELF->EXISTS(INDEX)
- Cette méthode vérifie l'existence dans le tableau lié de l'élément situé à la position INDEX. Pour notre TableauLimite, nous ne faisons qu'employer la fonction interne
existsde Perl après avoir vérifié qu'il ne s'agit pas d'une tentative de regarder au-delà de la limite supérieure fixée.
sub EXISTS {
my ($self, $index) = @_;
if ($index > $self->{LIMITE}) {
confess "Dépassement de limite du tableau :
$index > $self->{LIMITE}";
}
exists $self->{DONNEES}[$index];
}SELF->DELETE(INDEX)
- La méthode DELETE supprime l'élément à la position INDEX du tableau lié SELF. Dans notre classe TableauLimite, la méthode est presque identique à EXISTS, mais ceci n'est pas toujours le cas.
sub DELETE {
my ($self, $index) = @_;
print STDERR "suppression !\n";
if ($index > $self->{LIMITE}) {
confess "Dépassement de limite du tableau :
$index > $self->{LIMITE}";
}
delete $self->{DONNEES}[$index];
}SELF->CLEAR
- Cette méthode est appelée lorsque le tableau doit être vidé. Cela se produit lorsqu'on affecte une liste de nouvelles valeurs (ou une liste vide) au tableau, mais pas lorsqu'il est soumis à la fonction
undef. Comme un TableauLimite vidé satisfait toujours la limite supérieure, nous n'avons rien à vérifier ici.
- Si vous affectez une liste au tableau, CLEAR sera déclenchée mais ne verra pas les valeurs de la liste. Donc si vous passez outre la limite supérieure ainsi :
tie(@tableau, "TableauLimite", 2);
@tableau = (1, 2, 3, 4);- la méthode CLEAR retournera quand même avec succès. L'exception ne sera levée que lors du STORE qui suit. L'affectation déclenche un CLEAR et quatre STORE.
SELF->PUSH(LISTE)
- Cette méthode ajoute les éléments de LISTE à la fin du tableau. Voici à quoi elle pourrait ressembler pour notre classe TableauLimite :
sub PUSH {
my $self = shift;
if (@_ + $#{$self->{DONNEES}} > $self->{LIMITE}) {
confess "Tentative d'ajouter trop d'éléments";
}
push @{$self->{DONNEES}}, @_;
}SELF->UNSHIFT(LISTE)
- Cette méthode insère les éléments de LISTE au début du tableau. Dans notre classe TableauLimite, la fonction ressemblerait à PUSH.
SELF->POP
- La méthode POP enlève le dernier élément du tableau et le retourne. Pour TableauLimite, c'est une ligne :
SELF->SHIFT
- La méthode SHIFT enlève le premier élément de la liste et le retourne. Pour TableauLimite, c'est similaire à POP.
SELF->SPLICE(POSITION,LONGUEUR,LISTE)
- Cette méthode vous permet d'épisser (splice) le tableau SELF. Pour imiter la fonction interne
splicede Perl, POSITION devrait être en option et zéro par défaut, et compter en arrière à partir de la fin du tableau s'il est négatif. LONGUEUR devrait également être en option, et par défaut la longueur du reste du tableau. LISTE peut être vide. Si elle imite correctement la fonction interne, la méthode retournera une liste des LONGUEUR éléments à partir de POSITION (c'est-à-dire la liste des éléments devant être remplacés par LISTE). - Comme l'épissage est une opération assez complexe, nous ne la définirons pas du tout ; nous ne ferons qu'utiliser la fonction SPLICE du module Tie::Array dont nous disposons sans rien faire en héritant de Tie::Array. De cette manière nous définissons SPLICE en fonction d'autres méthodes de TableauLimite, et donc la vérification de limites aura tout de même lieu.
Ceci complète notre classe TableauLimite. Elle ne fait que légèrement déformer la sémantique des tableaux. Mais nous pouvons faire mieux, et plus court.
14-2-b. Commodité de notation▲
Une des choses bien avec les variables c'est qu'elles interpolent. Une des choses moins bien avec les fonctions c'est qu'elles ne le font pas. Vous pouvez utiliser un tableau lié pour faire une fonction qui peut être interpolée. Supposons que vous vouliez interpoler des nombres aléatoires dans une chaîne. Vous pouvez juste dire :
#!/usr/bin/perl
package InterpAleat;
sub TIEARRAY { bless \my $self };
sub FETCH { int rand $_[1] };
package main;
tie @rand, "InterpAleat";
for (1,10,100,1000) {
print "Un entier aléatoire plus petit que $_ serait $rand[$_]\n";
}
$rand[32] = 5; # Cela va-t-il reformater notre disque système ?Lorsqu'il est exécuté, ce programme affiche :
Un entier aléatoire plus petit que 1 serait 0
Un entier aléatoire plus petit que 10 serait 5
Un entier aléatoire plus petit que 100 serait 81
Un entier aléatoire plus petit que 1000 serait 765
Can't locate object method "STORE" via package "InterpAleat" at foo line 11.Comme vous le voyez, ce n'est pas si grave de ne pas avoir implémenté STORE. Cela explose simplement de façon normale.
14-3. Liaison de hachage▲
Une classe qui implémente un hachage lié doit définir huit méthodes. TIEHASH construit de nouveaux objets. FETCH et STORE donnent accès aux couples clef/valeur. EXISTS indique si une clef est présente ou non dans le hachage, et DELETE supprime une clef et sa valeur associée.(123) CLEAR vide le hachage en supprimant tous les couples clef/valeur. FIRSTKEY et NEXTKEY itèrent sur les couples clef/valeur lorsque vous appelez keys, values ou each. Et comme d'habitude, si vous voulez exécuter des actions spécifiques lorsque l'objet est désalloué, vous pouvez définir une méthode DESTROY. (Si ceci vous semble un grand nombre de méthodes, vous n'avez pas lu avec attention la section précédente sur les tableaux. En tout cas, n'hésitez pas à hériter de méthodes par défaut du module standard Tie::Hash, en ne redéfinissant que les méthodes intéressantes. Ici aussi, Tie::StdHash s'attend à ce que l'implémentation soit aussi un hachage.)
Par exemple, supposons que vous vouliez créer un hachage pour lequel, à chaque fois que vous affectez une valeur à une clef, au lieu d'écraser la valeur d'origine, la nouvelle valeur soit ajoutée à la fin d'un tableau de valeurs existantes. Comme cela lorsque vous dites :
$h{$c} = "un";
$h{$c} = "deux";Cela fait en réalité :
push @{ $h{$c} }, "un";
push @{ $h{$c} }, "deux";Cela n'est pas une idée très compliquée, donc vous devriez pouvoir employer un module assez simple, ce que vous pouvez faire en utilisant Tie::StdHash comme classe de base. Voici une classe Tie::HachageRajout qui fait précisément cela :
package Tie::HachageRajout;
use Tie::Hash;
our @ISA = ("Tie::StdHash");
sub STORE {
my ($self, $clef, $valeur) = @_;
push @{$self->{$clef}}, $valeur;
}
1;14-3-a. Méthodes de liaison de hachage▲
Voici un exemple intéressant de classe de liaison de hachage : elle vous donne un hachage qui représente les « fichiers point » d'un utilisateur (c'est-à-dire les fichiers dont le nom commence avec un point, ce qui est une convention de nommage des fichiers de configuration sous Unix). Vous indexez dans le hachage avec le nom du fichier (sans le point) et vous récupérez le contenu du fichier point. Par exemple :
use FichiersPoint;
tie %dot, "FichiersPoint";
if ( $point{profile} =~ /MANPATH/ or
$point{login} =~ /MANPATH/ or
$point{cshrc} =~ /MANPATH/ ) {
print "il semble que vous spécifiez votre MANPATH\n";
}Voici une autre manière d'utiliser notre classe liée :
# Le troisième paramètre est le nom de l'utilisateur
# dont nous examinerons les fichiers point.
tie %lui, "FichiersPoint", "daemon";
foreach $f (keys %lui) {
printf "le fichier point %s de daemon est de taille %d\n", $f,
length $lui{$f};
}Dans notre exemple FichiersPoint nous implémentons le hachage avec un hachage ordinaire comportant plusieurs champs importants, dont seul le champ {CONTENU} contient ce que voit l'utilisateur comme son hachage. Voici les vrais champs de l'objet :
|
Champ |
Contenu |
|---|---|
|
UTILISATEUR |
Celui dont l'objet représente les fichiers point. |
|
REPERTOIRE |
Où se situent ces fichiers point. |
|
ECRASER |
Si l'on a le droit de modifier ou d'écraser ces fichiers point. |
|
CONTENU |
Le hachage de couples nom de fichier point et contenu. |
Voici le début de FichiersPoint.pm :
package FichiersPoint;
use Carp;
sub quietaisje { (caller(1))[3] . "()" }
my $DEBOGUAGE = 0;
sub deboguage { $DEBOGUAGE = @_ ? shift : 1 }Dans notre exemple, nous voulons pouvoir déclencher l'affichage de messages de débogage pendant le développement de la classe, d'où l'utilité de $DEBOGUAGE. Nous gardons aussi sous la main en interne une fonction pratique pour afficher les avertissements : quietaisje retourne le nom de la fonction ayant appelé la fonction courante (la fonction « grand-mère » de quietaisje).
Voici les méthodes pour le hachage lié FichiersPoint :
NOM_CLASSE->TIEHASH(LISTE)
- Voici le constructeur de FichiersPoint :
sub TIEHASH {
my $self = shift;
my $utilisateur = shift || $>;
my $rep_point = shift || "";
croak "usage: @{[ &quietaisje ]} [UTILISATEUR [REP_POINT]]" if @_;
$utilisateur = getpwuid($utilisateur) if $utilisateur =~ /^\d+$/;
my $rep = (getpwnam($utilisateur))[7]
or croak "@{ [&quietaisje] }: pas d'utilisateur $utilisateur";
$rep .= "/$rep_point" if $rep_point;
my $noeud = {
UTILISATEUR => $utilisateur,
REPERTOIRE => $rep,
CONTENU => {},
ECRASER => 0,
};
opendir REP, $rep
or croak "@{[&quietaisje]}: impossible d'ouvrir $rep: $!";
for my $point ( grep /^\./ && -f "$rep/$_", readdir(REP)) {
$point =~ s/^\.//;
$noeud->{CONTENU}{$point} = undef;
}
closedir REP;
return bless $noeud, $self;
}- Cela vaut sans doute la peine de mentionner que si vous allez appliquer des tests de fichier sur les valeurs retournées par le
readdirci-dessus, vous avez intérêt à les préfixer avec le répertoire concerné (comme nous le faisons). Sans quoi, en l'absence d'unchdir, vous risqueriez de ne pas tester le bon fichier.
SELF->FETCH(CLEF)
- Cette méthode implémente la lecture d'un élément du hachage lié. Elle prend un paramètre après l'objet : la clef dont nous tentons de récupérer la valeur. Cette clef est une chaîne, et vous pouvez faire ce que vous voulez avec (qui soit cohérent avec sa nature de chaîne).
Voici le fetch de notre exemple FichiersPoint :
sub FETCH {
carp &quietaisje if $DEBOGUAGE;
my $self = shift;
my $point = shift;
my $rep = $self->{REPERTOIRE};
my $fichier = "$rep/.$point";
unless (exists $self->{CONTENU}->{$point} || -f $fichier) {
carp "@{[&quietaisje]}: pas de fichier $point" if $DEBOGUAGE;
return undef;
}
# Implémenter un cache.
if (defined $self->{CONTENU}->{$point}) {
return $self->{CONTENU}->{$point};
} else {
return $self->{CONTENU}->{$point} = `cat $rep/.$point`;
}
}- Nous avons un peu triché en exécutant la commande Unix cat(1), mais il serait plus portable (et plus efficace) d'ouvrir le fichier nous-mêmes. D'un autre côté, comme les fichiers point sont un concept unixien, nous ne sommes pas tellement concernés. Ou nous ne devrions pas l'être. Ou quelque chose comme ça...
SELF->STORE(CLEF,VALEUR)
- Cette méthode fait ce qu'il faut lorsqu'un élément du hachage lié est modifié (écrit). Elle prend deux paramètres après l'objet : la clef sous laquelle nous stockons la nouvelle valeur, et la valeur elle-même.
- Dans notre exemple FichiersPoint, nous ne permettons pas à un utilisateur d'écrire un fichier sans d'abord invoquer la méthode ecraser sur l'objet d'origine retourné par
tie:
sub STORE {
carp &quietaisje if $DEBOGUAGE;
my $self = shift;
my $point = shift;
my $valeur = shift;
my $fichier = $self->{REPERTOIRE} . "/.$point";
croak "@{[&quietaisje]}: $fichier non écrasable"
unless $self->{ECRASER};
open(F, "> $fichier") or croak "impossible d'ouvrir $fichier: $!";
print F $valeur;
close(F);
}- Si quelqu'un souhaite écraser quelque chose, il peut dire :
$ob = tie %points_daemon, "daemon";
$ob->ecraser(1);
$points_daemon{signature} = "Un vrai démon\n";- Mais il pourrait également modifier
{ECRASER}à l'aide detied:
tie %points_daemon, "FichiersPoint", "daemon";
tied(%points_daemon)->ecraser(1);- ou en une instruction :
(tie %points_daemon, "FichiersPoint", "daemon")->ecraser(1);- La méthode ecraser est simplement :
SELF->DELETE(CLEF)
- Cette méthode traite les tentatives de suppression d'un élément du hachage. Si votre hachage émulé utilise quelque part un vrai hachage, vous pouvez simplement appeler le vrai
delete. De nouveau, nous prenons la précaution de vérifier que l'utilisateur souhaite réellement écraser des fichiers :
sub DELETE {
carp &quietaisje if $DEBOGUAGE;
my $self = shift;
my $point = shift;
my $fichier = $self->{REPERTOIRE} . "/.$point";
croak "@{[&quietaisje]}: ne supprime pas le fichier $fichier"
unless $self->{ECRASER};
delete $self->{CONTENU}->{$point};
unlink $fichier or carp "@{[&quietaisje]}: impossible de supprimer $fichier: $!";
}SELF->CLEAR
- Cette méthode est exécutée lorsque le hachage entier doit être vidé, habituellement en lui affectant la liste vide. Dans notre exemple, cela supprimerait tous les fichiers point de l'utilisateur ! C'est une chose tellement dangereuse que nous exigerons que ECRASER soit supérieur à 1 avant que cela ne puisse se produire :
sub CLEAR {
carp &quietaisje if $DEBOGUAGE;
my $self = shift;
croak "@{[&quietaisje]}: ne supprime pas tous les fichiers point
de $self->{UTILISATEUR}"
unless $self->{ECRASER} > 1;
for my $point ( keys %{$self->{CONTENU}}) {
$self->DELETE($point);
}
}SELF->EXISTS(CLEF)
- Cette méthode est exécutée lorsque l'utilisateur invoque la fonction
existssur un hachage donné. Dans notre exemple, nous examinons le hachage{CONTENU}pour trouver la réponse :
sub EXISTS {
carp &quietaisje if $DEBOGUAGE;
my $self = shift;
my $point = shift;
return exists $self->{CONTENU}->{$point};
}SELF->FIRSTKEY
- Cette méthode est appelée lorsque l'utilisateur commence à itérer sur le hachage, comme lors d'un appel à
keys,valuesoueach. En appelantkeysdans un contexte scalaire, nous réinitialisons son état interne pour nous assurer que le prochaineachutilisé dans l'instruction return obtiendra bien la première clef.
sub FIRSTKEY {
carp &quietaisje if $DEBOGUAGE;
my $self = shift;
my $temp = keys %{$self->{CONTENU}};
return scalar each %{$self->{CONTENU}};
}SELF->NEXTKEY(CLEF_PRECEDENTE)
- Cette méthode est l'itérateur d'une fonction
keys,valuesoueach. CLEF_PRECEDENTE est la dernière clef à laquelle on a accédé, ce que sait fournir Perl. Ceci est utile si la méthode NEXTKEY doit connaître l'état précédent pour calculer l'état suivant. - Dans notre exemple, nous utilisons un vrai hachage pour représenter les données du hachage lié, à ceci près que ce hachage est stocké dans le champ CONTENU du hachage plutôt que dans le hachage lui-même. Donc nous pouvons compter sur l'opérateur
eachde Perl :
sub NEXTKEY {
carp &quietaisje if $DEBOGUAGE;
my $self = shift;
return scalar each %{ $self->{CONTENU} }
}SELF->DESTROY
- Cette méthode est déclenchée lorsque l'objet du hachage lié est sur le point d'être désalloué. Elle n'est vraiment utile que pour le débogage et le nettoyage. En voici une version très simple :
Maintenant que nous vous avons donné toutes ces méthodes, voici un exercice à faire à la maison : reprendre tout par le début, trouver les endroits où nous avons interpolé @{[&quietaisje]}, et les remplacer par un simple scalaire lié nommé $quietaisje qui fait la même chose.
14-4. Liaison de handle de fichier▲
Une classe qui implémente un handle de fichier lié doit définir les méthodes suivantes : TIEHANDLE, et l'une au moins de PRINT, PRINTF, WRITE, READLINE, GETC, ou READ. La classe peut également fournir une méthode DESTROY, et la définition des méthodes BINMODE, OPEN, CLOSE, EOF, FILENO, SEEK, TELL, READ et WRITE permet au handle de fichier lié d'émuler les fonctions internes Perl correspondantes. (Enfin, ce n'est pas tout à fait vrai : WRITE correspond à syswrite et n'a rien à voir avec la fonction Perl interne write, qui fait de l'affichage à l'aide de déclarations format.)
Les handles de fichier liés sont particulièrement utiles lorsque Perl est intégré dans un autre programme (comme Apache ou vi) et que l'affichage par STDOUT ou STDERR doit être redirigé de manière spéciale.
Mais il n'est en fait même pas nécessaire que les handles de fichier soient liés à un fichier. Vous pouvez utiliser des instructions de sortie pour construire une structure de données en mémoire, et des instructions d'entrée pour la récupérer. Voici une manière simple d'inverser une série d'instructions print et printf sans inverser chaque ligne :
package InversePrint;
use strict;
sub TIEHANDLE {
my $classe = shift;
bless [], $classe;
}
sub PRINT {
my $self = shift;
push @$self, join '', @_;
}
sub PRINTF {
my $self = shift;
my $fmt = shift;
push @$self, sprintf $fmt, @_;
}
sub READLINE {
my $self = shift;
pop @$self;
}
package main;
my $m = "--MORE--\n";
tie *INV, "InversePrint";
# Faire des print et des printf.
print INV "Le juge blond est soudainement très malade.$m";
printf INV <<"END", int rand 10000000;
Portez %d vieux whiskys
au juge blond qui fume !
END
print INV <<"END";
Portez ce vieux whisky
au juge blond qui fume.
END
# Maintenant on lit à partir du même handle.
print while <INV>;Ceci affiche :
Portez ce vieux whisky
au juge blond qui fume.
Portez 7387770 vieux whiskys
au juge blond qui fume !
Le juge blond est soudainement très malade.--MORE--14-4-a. Méthodes de liaison de handle de fichier▲
Pour notre exemple détaillé, nous créerons un handle de fichier qui met en majuscules les chaînes qui lui sont soumises. Pour nous amuser un peu, nous ferons commencer le fichier avec <CRIER> lorsqu'il est ouvert, et nous le fermerons avec </CRIER> lorsqu'il est fermé. Comme ça nous pourrons divaguer en XML bien formé.
Voici le début du fichier Crier.pm qui implémente la classe :
Listons à présent les définitions de méthode de Crier.pm.
NOM_CLASSE->TIEHANDLE(LISTE)
- Ceci est le constructeur de la classe, qui comme d'habitude doit retourner une référence consacrée :
sub TIEHANDLE {
my $classe = shift;
my $forme = shift;
open my $self, $forme, @_ or croak "impossible d'ouvrir $forme@_: $!";
if ($forme =~ />/) {
print $self "<CRIER>\n";
$$self->{ECRITURE} = 1; # Se souvenir d'écrire la balise
#de fin
}
return bless $self, $classe; # $self est une référence de glob
}- Ici, nous ouvrons un nouveau handle de fichier selon le mode et le nom de fichier passés à l'opérateur
tie, nous écrivons<CRIER>dans le fichier, et nous retournons une référence consacrée. Il se passe beaucoup de choses dans cette instructionopen, mais nous indiquerons simplement que, en plus de l'idiome habituel « open or die », le my$selfpasse un scalaire non défini àopen, qui sait comment l'autovivifier en un typeglob. Sa nature de typeglob est également intéressante, car le typeglob contient non seulement le véritable objet entrée/sortie du fichier, mais aussi diverses autres structures de données pratiques, comme un scalaire ($$$self), un tableau (@$$self), et un hachage (%$$self). (Nous ne mentionnerons pas la fonction,&$$self.) - La
$formeest un paramètre indiquant soit le nom de fichier, soit le mode. Si c'est un nom de fichier,@_est vide, donc cela se comporte comme un open à deux paramètres. Autrement,$formeest le mode pour les paramètres restants. - Après l'ouverture, nous faisons un test pour déterminer si nous devons écrire la balise ouvrante, auquel cas nous le faisons. Et immédiatement nous utilisons une de ces structures de données susmentionnées. Ce
$$self->{ECRITURE}est un exemple d'utilisation du glob pour stocker une information intéressante. Dans ce cas, nous retenons si nous avons écrit la balise ouvrante afin de savoir si nous devons écrire la balise fermante correspondante. Nous utilisons le hachage%$$self, donc nous pouvons donner au champ un nom compréhensible. Nous aurions pu utiliser le scalaire$$$self, mais une telle utilisation ne se documenterait pas elle-même. (Ou elle ne ferait que se documenter elle-même, selon votre point de vue.)
SELF->PRINT(LISTE)
- Cette méthode implémente le
printsur le handle lié. La LISTE contient ce qui a été passé àprint. Notre méthode ci-dessous met en majuscules chaque élément de la LISTE :
SELF->READLINE
- Cette méthode fournit les données lorsque le handle de fichier est lu avec l'opérateur angle (
<HF>) ou avec readline. La méthode doit retournerundeflorsqu'il n'y a plus de données.
- Ici, nous faisons simplement return
<$self>pour que la méthode se comporte correctement selon qu'elle est appelée en contexte scalaire ou en contexte de liste.
SELF->GETC
- Cette méthode s'exécute à chaque fois qu'est appelée
getcsur le handle de fichier lié.
- Comme plusieurs des méthodes dans notre classe Crier, la méthode GETC ne fait qu'appeler sa fonction interne Perl correspondante et retourner le résultat.
SELF->OPEN(LISTE)
- Notre méthode TIEHANDLE ouvre elle-même le fichier, mais un programme qui utilise la classe Crier et appelle ensuite
opendéclenche cette méthode.
sub OPEN {
my $self = shift;
my $forme = shift;
my $nom = "$forme@_";
$self->CLOSE;
open($self, $forme, @_) or croak "impossible de rouvrir $nom: $!";
if ($forme =~ />/) {
print $self "<CRIER>\n" or croak "impossible de commencer le print: $!";
$$self->{ECRITURE} = 1; # Se souvenir d'écrire la balise de fin
}
else {
$$self->{ECRITURE} = 0; # Se souvenir de ne pas écrire
# la balise de fin
}
return 1;
}- Nous invoquons notre propre méthode CLOSE pour fermer le fichier explicitement au cas où l'utilisateur ne se serait pas soucié de le faire lui-même. Ensuite nous ouvrons un nouveau fichier avec le nom de fichier spécifié dans le
open, et nous crions dedans.
SELF->CLOSE
- Cette méthode gère les requêtes de fermeture du handle. Ici, nous faisons un
seekjusqu'à la fin du fichier et, s'il réussit, nous affichons</CRIER>avant d'appeler lecloseinterne de Perl.
sub CLOSE {
my $self = shift;
if ($$self->{ECRITURE}) {
$self->SEEK(0, 2) or return;
$self->PRINT("</CRIER>\n") or return;
}
return close $self;
}SELF->SEEK(LISTE)
- Lorsque vous faites un
seeksur un handle de fichier lié, la méthode SEEK est appelée.
sub SEEK {
my $self = shift;
my ($position, $depart) = @_;
return seek($self, $position, $depart);
}SELF->TELL
- Cette méthode est invoquée lorsque
tellest appelée sur le handle de fichier lié.
SELF->PRINTF(LISTE)
- Cette méthode est exécutée lorsque
printfest appelée sur le handle de fichier lié. La LISTE contient le format et les éléments à afficher.
sub PRINTF {
my $self = shift;
my $format = shift;
return $self->PRINT(sprintf $format, @_);
}- Ici, nous employons
sprintfpour produire la chaîne formatée et nous la passons à PRINT pour la mise en majuscules. Mais rien ne vous oblige à utiliser la fonction internesprintf. Vous pourriez interpréter les codes pour-cent à votre manière.
SELF->READ(LISTE)
- Cette méthode répond lorsque le handle est lu avec
readousysread. Notez que nous modifions le premier paramètre de LISTE « sur place », imitant commentreadpeut remplir le scalaire fourni comme deuxième paramètre.
sub READ {
my ($self, undef, $taille, $position) = @_;
my $ref_tampon = \$_[1];
return read($self, $$ref_tampon, $taille, $position);
}SELF->WRITE(LISTE)
- Cette méthode est invoquée lorsqu'on écrit au handle avec
syswrite. Ici, nous mettons en majuscules la chaîne écrite.
sub WRITE {
my $self = shift;
my $chaine = uc(shift);
my $taille = shift || length $chaine;
my $position = shift || 0;
return syswrite $self, $chaine, $taille, $position;
}SELF->EOF
- Cette méthode retourne une valeur booléenne lorsque l'état fin-de-fichier du handle de fichier lié à la classe Crier est testé avec
eof.
SELF->BINMODE(DISC)
- Cette méthode indique la discipline entrée/sortie qui doit être utilisée sur le handle de fichier. Si rien n'est spécifié, elle met le handle de fichier en mode binaire (la discipline :raw), pour les systèmes de fichiers qui distinguent entre les fichiers texte et les fichiers binaires.
sub BINMODE {
my $self = shift;
my $disc = shift || ":raw";
return binmode $self, $disc;
}- Voilà comment vous l'écririez, mais elle est en fait inutilisable dans notre cas, car
opena déjà écrit sur le handle. Donc nous devrions probablement lui faire dire :
sub BINMODE { croak("Trop tard pour utiliser binmode") }SELF->FILENO
- Cette méthode doit retourner le descripteur de fichier (
fileno) associé au handle de fichier par le système d'exploitation.
SELF->DESTROY
Comme pour les autres types de liaison, cette méthode est déclenchée lorsque l'objet lié est sur le point d'être détruit. Ceci est utile pour permettre à l'objet de faire du nettoyage. Ici, nous nous assurons que le fichier est fermé, au cas où le programme aurait oublié d'appeler close. Nous pourrions simplement dire close $self, mais il est préférable d'invoquer la méthode CLOSE de la classe. De cette manière si le concepteur de la classe décide de modifier la façon dont les fichiers sont fermés, cette méthode DESTROY n'a pas à être modifiée.
sub DESTROY {
my $self = shift;
$self->CLOSE; # Fermer le fichier avec la méthode CLOSE de Crier
}Voici une démonstration de notre classe Crier :
#!/usr/bin/perl
use Crier;
tie(*FOO, Crier::, ">nom_fichier");
print FOO "bonjour\n"; # Affiche BONJOUR.
seek FOO, 0, 0; # Repart du début.
@lines = <FOO>; # Appelle la méthode READLINE.
close FOO; # Ferme le fichier explicitement.
open(FOO, "+<", "nom_fichier"); # Rouvre FOO, appelant OPEN.
seek(FOO, 8, 0); # Saute "<CRIER>\n".
sysread(FOO, $tampon, 7); # Lit 7 octets de FOO dans $tampon.
print "trouvé $tampon\n"; # Devrait afficher "BONJOUR".
seek(FOO, -7, 1); # Recule par-dessus "bonjour".
syswrite(FOO, "ciao!\n", 6); # Ecrit 6 octets dans FOO.
untie(*FOO); # Appelle la méthode CLOSE implicitement.Après l'exécution de ceci, le fichier contient :
<CRIER>
CIAO!
</CRIER>Voici d'autres choses étranges et merveilleuses à faire avec le glob interne. Nous employons le même hachage que précédemment, mais avec les nouvelles clefs CHEMIN_FICHIER et DEBOGUAGE. D'abord nous installons une surcharge de conversion en chaîne pour que l'affichage de nos objets révèle le nom de fichier (voir le chapitre 13, Surcharge):
# Ceci est vraiment trop génial !
use overload q("") => sub { $_[0]->chemin_fichier };
# Ceci doit être mis dans chaque fonction que vous voulez tracer.
sub trace {
my $self = shift;
local $Carp::CarpLevel = 1;
Carp::cluck("\nméthode magique trace") if $self->deboguage;
}
# Handler de surcharge pour afficher le chemin d'accès au fichier.
sub chemin_fichier {
my $self = shift;
confess "je ne suis pas une méthode de classe" unless ref $self;
$$self->{CHEMIN_FICHIER} = shift if @_;
return $$self->{CHEMIN_FICHIER};
}
# Deux modes.
sub deboguage {
my $self = shift;
my $var = ref $self ? \$$self->{DEBOGUAGE} : \our $Deboguage;
$$var = shift if @_;
return ref $self ? $$self->{DEBOGUAGE} || $Deboguage : $Deboguage;
}Ensuite nous appelons trace à l'entrée de toutes nos méthodes ordinaires, comme ceci :
Nous stockons le chemin d'accès du fichier dans les méthodes TIEHANDLE et OPEN :
sub TIEHANDLE {
my $classe = shift;
my $forme = shift;
my $nom = "$forme@_"; # NOUVEAU
open my $self, $forme, @_ or croak "impossible d'ouvrir $nom : $!";
if ($forme =~ />/) {
print $self "<CRIER>\n";
$$self->{ECRITURE} = 1; # Se souvenir d'écrire la balise de fin
}
bless $self, $classe; # $self est une référence de glob
$self->chemin_fichier($nom); # NOUVEAU
return $self;
}
sub OPEN { $_[0]->trace; # NOUVEAU
my $self = shift;
my $forme = shift;
my $nom = "$forme@_";
$self->CLOSE;
open($self, $forme, @_) or croak "impossible de rouvrir $nom : $!";
$self->chemin_fichier($nom); # NOUVEAU
if ($forme =~ />/) {
print $self "<CRIER>\n" or croak "impossible de commencer le print : $!";
$$self->{ECRITURE} = 1; # Se souvenir d'écrire la balise de fin
}
else {
$$self->{ECRITURE} = 0; # Se souvenir de ne pas écrire la
# balise de fin
}
return 1;
}Il faut aussi appeler $self->deboguage(1) quelque part pour démarrer le débogage. Lorsque nous faisons cela, tous les appels à Carp::cluck produiront des messages informatifs. En voici un que nous obtenons pendant la réouverture ci-dessus. Il nous situe à trois niveaux de profondeur d'appels de méthode, alors que nous fermons l'ancien fichier en préparation pour l'ouverture du nouveau :
méthode magique trace at foo line 87
Crier::SEEK('>nom_fichier', '>nom_fichier', 0, 2) called at foo line 81
Crier::CLOSE('>nom_fichier') called at foo line 65
Crier::OPEN('>nom_fichier', '+<', 'nom_fichier') called at foo line 14114-4-b. Handles de fichier originaux▲
Vous pouvez lier un même handle de fichier à l'entrée et à la sortie d'un tube (pipe) à deux bouts. Supposons que vous vouliez exécuter le programme bc(1) (calculateur à précision arbitraire) de cette manière :
use Tie::Open2;
tie *CALC, 'Tie::Open2', "bc -l";
$somme = 2;
for (1 .. 7) {
print CALC "$somme * $somme\n";
$somme = <CALC>;
print "$_: $somme";
chomp $somme;
}
close CALC;Vous vous attendriez à ce qu'il affiche ceci :
1: 4
2: 16
3: 256
4: 65536
5: 4294967296
6: 18446744073709551616
7: 340282366920938463463374607431768211456Vous auriez raison de vous attendre à cela si vous aviez le programme bc(1) sur votre ordinateur, et si vous aviez défini Tie::Open2 de la manière suivante. Cette fois-ci nous utiliserons un tableau consacré comme objet interne. Il contient nos deux handles de fichier pour la lecture et pour l'écriture. (La tâche difficile d'ouverture d'un tube à deux bouts est faite par IPC::Open2 ; nous ne faisons que la partie amusante.)
package Tie::Open2;
use strict;
use Carp;
use Tie::Handle; # ne pas hériter de ceci !
use IPC::Open2;
sub TIEHANDLE {
my ($classe, @cmd) = @_;
no warnings 'once';
my @paire_hf = \do { local(*LECTURE, *ECRITURE) };
bless $_, 'Tie::StdHandle' for @paire_hf;
bless(\@paire_hf => $classe)->OPEN(@cmd) || die;
return \@paire_hf;
}
sub OPEN {
my ($self, @cmd) = @_;
$self->CLOSE if grep {defined} @{ $self->FILENO };
open2(@$self, @cmd);
}
sub FILENO {
my $self = shift;
[ map { fileno $self->[$_] } 0,1 ];
}
for my $meth_sortie ( qw(PRINT PRINTF WRITE) ) {
no strict 'refs';
*$meth_sortie = sub {
my $self = shift;
$self->[1]->$meth_sortie(@_);
};
}
for my $meth_entree ( qw(READ READLINE GETC) ) {
no strict 'refs';
*$meth_entree = sub {
my $self = shift;
$self->[0]->$meth_entree(@_);
};
}
for my $meth_double ( qw(BINMODE CLOSE EOF)) {
no strict 'refs';
*$meth_double = sub {
my $self = shift;
$self->[0]->$meth_double(@_) && $self->[1]->$meth_double(@_);
};
}
for my $meth_morte ( qw(SEEK TELL)) {
no strict 'refs';
*$meth_morte = sub {
croak("impossible d'appliquer $meth_morte à un tube");
};
}
1;Les quatre dernières boucles sont incroyablement chouettes, à notre avis. Pour une explication de ce qui se passe, voir la section Fermetures comme modèles de fonctions au chapitre 8.
Voici un ensemble de classes encore plus bizarres. Les noms de paquetages devraient vous donner une idée de ce qu'elles font :
use strict;
package Tie::DevNull;
sub TIEHANDLE {
my $classe = shift;
my $hf = local *HF;
bless \$hf, $classe;
}
for (qw(READ READLINE GETC PRINT PRINTF WRITE)) {
no strict 'refs';
*$_ = sub { return };
}
package Tie::DevAleatoire;
sub READLINE { rand() . "\n"; }
sub TIEHANDLE {
my $classe = shift;
my $hf = local *HF;
bless \$hf, $classe;
}
sub FETCH { rand() }
sub TIESCALAR {
my $classe = shift;
bless \my $self, $classe;
}
package Tie::Tee;
sub TIEHANDLE {
my $classe = shift;
my @handles;
for my $chemin (@_) {
open(my $hf, ">$chemin") || die "impossible d'écrire $chemin";
push @handles, $hf;
}
bless \@handles, $classe;
}
sub PRINT {
my $self = shift;
my $ok = 0;
for my $hf (@$self) {
$ok += print $hf @_;
}
return $ok == @$self;
}La classe Tie::Tee émule le programme standard Unix tee(1) qui envoie un f lux en sortie vers plusieurs différentes destinations. La classe Tie::DevNull émule le périphérique nul /dev/null des systèmes Unix. La classe Tie::DevRandom produit des nombres aléatoires soit comme handle, soit comme scalaire, selon que vous appelez TIEHANDLE ou TIESCALAR ! Voici comment vous les appelez :
package main;
tie *DISPERSE, "Tie::Tee", qw(tmp1 - tmp2 >tmp3 tmp4);
tie *ALEATOIRE, "Tie::DevAleatoire";
tie *NULL, "Tie::DevNull";
tie my $alea, "Tie::DevAleatoire";
for my $i (1..10) {
my $ligne = <ALEATOIRE>;
chomp $ligne;
for my $hf (*NULL, *DISPERSE) {
print $hf "$i: $ligne $alea\n";
}
}Ce qui produit quelque chose comme ceci sur votre écran :
1: 0.124115571686165 0.20872819474074
2: 0.156618299751194 0.678171662366353
3: 0.799749050426126 0.300184963960792
4: 0.599474551447884 0.213935286029916
5: 0.700232143543861 0.800773751296671
6: 0.201203608274334 0.0654303290639575
7: 0.605381294683365 0.718162304090487
8: 0.452976481105495 0.574026269121667
9: 0.736819876983848 0.391737610662044
10: 0.518606540417331 0.381805078272308Mais ce n'est pas tout ! Le programme a écrit sur votre écran à cause du - dans le tie de *DISPERSE ci-dessus. Mais cette ligne lui a également dit de créer les fichiers tmp1, tmp2, et tmp4, et d'ajouter à la fin de tmp3. (Nous avons aussi écrit au handle de fichier *NULL dans la boucle, mais bien sûr cela n'est apparu nulle part d'intéressant, à moins que vous vous intéressiez aux trous noirs.)
14-5. Un piège subtil du déliement▲
Si vous avez l'intention de vous servir de l'objet retourné par tie ou par tied, et que la classe définit un destructeur, il y a un piège subtil contre lequel vous devez vous protéger. Examinez cet exemple (tordu, avouons-le) d'une classe qui utilise un fichier pour tenir un log de toutes les valeurs affectées à un scalaire :
package Souvenir;
sub TIESCALAR {
my $classe = shift;
my $nom_fichier = shift;
open(my $handle, ">", $nom_fichier)
or die "Impossible d'ouvrir $nom_fichier: $!\n";
print $handle "Le Début\n";
bless {HF => $handle, VALEUR => 0}, $classe;
}
sub FETCH {
my $self = shift;
return $self->{VALEUR};
}
sub STORE {
my $self = shift;
my $valeur = shift;
my $handle = $self->{HF};
print $handle "$valeur\n";
$self->{VALEUR} = $valeur;
}
sub DESTROY {
my $self = shift;
my $handle = $self->{HF};
print $handle "La Fin\n";
close $handle;
}
1;Voici un exemple qui se sert de notre classe Souvenir :
use strict;
use Souvenir;
my $fred;
tie $fred, "Souvenir", "chameau.log";
$fred = 1;
$fred = 4;
$fred = 5;
untie $fred;
system "cat chameau.log";Voici ce qu'il affiche lorsqu'il est exécuté :
Le Début
1
4
5
La FinJusqu'ici tout va bien. Rajoutons une méthode supplémentaire à la classe Souvenir qui permet les commentaires dans le fichier — disons, quelque chose comme ceci :
sub commenter {
my $self = shift;
my $message = shift;
print { $self->{HF} } $handle $message, "\n";
}Et voici l'exemple précédent, modifié pour utiliser la méthode commenter :
use strict;
use Souvenir;
my ($fred, $x);
$x = tie $fred, "Souvenir", "chameau.log";
$fred = 1;
$fred = 4;
commenter $x "change...";
$fred = 5;
untie $fred;
system "cat chameau.log";Maintenant le fichier risque d'être vide ou incomplet, ce qui n'est probablement pas ce que vous souhaitiez faire. Voici pourquoi. Lier une variable l'associe à l'objet retourné par le constructeur. Cet objet n'a normalement qu'une référence : celle cachée derrière la variable liée. Appeler « untie » rompt l'association et élimine cette référence. Comme il ne reste pas de référence à l'objet, la méthode DESTROY est déclenchée.
Cependant, dans l'exemple ci-dessus nous avons stocké dans $x une deuxième référence à l'objet lié. Cela veut dire qu'il reste une référence valide à l'objet après le untie. DESTROY n'est pas déclenchée, et le fichier n'est ni enregistré, ni fermé. C'est pour cela que rien n'est sorti : le tampon du handle de fichier était encore en mémoire. Il n'atteindra le disque qu'à la sortie du programme.
Pour détecter ceci, vous pourriez utiliser l'option de ligne de commande -w ou inclure le pragma use warnings "untie" dans la portée lexicale courante. L'une ou l'autre technique décèlerait un appel à untie pendant qu'il reste des références à l'objet lié. Dans ce cas, Perl affiche cet avertissement :
untie attempted while 1 inner references still existPour faire marcher correctement le programme et faire taire l'avertissement, éliminez les références supplémentaires à l'objet lié avant d'appeler untie. Vous pouvez le faire explicitement :
undef $x;
untie $fred;Souvent vous pouvez résoudre le problème en vous assurant simplement que vos variables quittent leur portée au bon moment.
14-6. Modules de liaison sur CPAN▲
Avant de devenir tout inspiré à l'idée d'écrire votre propre module de liaison, vous devriez vérifier que quelqu'un ne l'a pas déjà fait. Il y a beaucoup de modules de liaison sur CPAN, et il y en a des nouveaux tous les jours. (Enfin, chaque mois, en tout cas.) Le tableau 14-1 en liste quelques-unes.
|
Module |
Description |
|---|---|
|
GnuPG::Tie::Encrypt |
Lie une interface de handle de fichier avec GNU Privacy Guard. |
|
IO::WrapTie |
Emballe les objets liés avec une interface IO::Handle. |
|
MLDBM |
Stocke de manière transparente des données complexes, pas juste de simples chaînes, dans un fichier DBM. Net::NISplusTied Lie des hachages à des tables NIS+. |
|
Tie::Cache::LRU |
Implémente un cache utilisant l'algorithme « Least Recently Used » (moins récemment utilisé). |
|
Tie::Const |
Fournit des scalaires et des hachages constants. |
|
Tie::Counter |
Enchante une variable scalaire pour qu'elle s'incrémente à chaque fois qu'on y accède. |
|
Tie::CPHash |
Implémente un hachage insensible à la casse, mais qui préserve la casse. |
|
Tie::DB_FileLock |
Fournit un accès verrouillé aux bases de données Berkeley DB 1.x. |
|
Tie::DBI |
Lie des hachages aux bases de données relationnelles DBI. |
|
Tie::DB_Lock |
Lie des hachages aux bases de données avec des verrouillages exclusifs et partagés. |
|
Tie::Dict |
Lie un hachage à un serveur dict RPC. |
|
Tie::Dir |
Lie un hachage pour lire des répertoires. |
|
Tie::DirHandle |
Lie des handles de répertoire. |
|
Tie::FileLRUCache |
Implémente un cache LRU léger, basé sur le système de fichiers. |
|
Tie::FlipFlop |
Implémente une liaison qui alterne entre deux valeurs. |
|
Tie::HashDefaults |
Permet à un hachage d'avoir des valeurs par défaut. |
|
Tie::HashHistory |
Garde l'historique de toutes les modifications d'un hachage. |
|
Tie::IxHash |
Fournit à Perl des tableaux associatifs ordonnés. |
|
Tie::LDAP |
Implémente une interface à une base de données LDAP. |
|
Tie::Persistent |
Fournit des structures de données persistantes via tie. |
|
Tie::Pick |
Choisit (et supprime) aléatoirement un élément d'un ensemble. |
|
Tie::RDBM |
Lie des hachages aux bases de données relationnelles. |
|
Tie::SecureHash |
Permet l'encapsulation avec les espaces de noms. |
|
Tie::STDERR |
Envoie la sortie de votre STDERR à un autre processus tel qu'un système d'envoi de courrier. |
|
Tie::Syslog |
Lie un handle de fichier pour automatiquement enregistrer sa sortie avec syslog. |
|
Tie::TextDir |
Lie un répertoire de fichiers. |
|
Tie::TransactHash |
Modifie un hachage par transactions sans changer l'ordre pendant la transaction. |
|
Tie::VecArray |
Donne à un vecteur de bits une interface de tableau. |
|
Tie::Watch |
Place des témoins sur les variables Perl. |
|
Win32::TieRegistry |
Fournit des manières faciles et puissantes de manipuler la base de registres de Microsoft Windows. |
