


I. Survol de Perl▲
1. Vue d'ensemble▲
1-1. Démarrage▲
Nous pensons que Perl est un langage facile à apprendre et à utiliser, et nous espérons vous en convaincre. L'un des aspects les plus agréables de Perl est que l'on n'a pas besoin d'en écrire beaucoup avant d'exprimer vraiment sa pensée. Dans de nombreux langages de programmation, il faut déclarer les types, les variables et les sous-programmes que l'on va utiliser avant d'écrire la première instruction de code exécutable. C'est une bonne approche pour des problèmes complexes demandant des structures de données complexes ; mais pour beaucoup de problèmes simples, que l'on rencontre tous les jours, il vaut mieux un langage de programmation dans lequel il suffit d'écrire :
print "Salut tout le monde!\n";et où le programme ne fait que cela.
Perl est de ce genre de langage. En fait, cet exemple est un programme complet, et si on le donne à l'interpréteur Perl, il affiche « Salut tout le monde ! » à l'écran.(6) (Le caractère \n produit un saut de ligne en sortie.)
Et voilà. Il n'y a pas non plus grand-chose à écrire après ce que l'on veut dire, d'ailleurs. À l'inverse de nombreux langages, Perl estime que s'arrêter sans prévenir à la fin du programme n'est qu'une façon normale d'en sortir. On peut bien sûr appeler explicitement la fonction exit si on le souhaite, de même que l'on peut déclarer certaines variables ou certains sous-programmes, ou même se forcer à déclarer toutes les variables et tous les sous-programmes. À vous de voir. En Perl, vous êtes libre de faire Ce Qu'il Faut, quelle qu'en soit votre définition.
Il existe d'autres raisons à la facilité d'emploi de Perl, mais il serait inutile de toutes les énumérer ici... car c'est l'objet de ce livre. Le diable est dans les détails, comme disent les Anglo-saxons, mais Perl essaie aussi de vous sortir de l'enfer où vous pouvez vous retrouver plongé. C'est à tous les niveaux que Perl essaye de vous faire arriver à vos fins avec le minimum d'ennuis et le maximum de plaisir. C'est pourquoi tant de programmeurs Perl affichent un sourire béat.
Ce chapitre constitue un survol de Perl, et nous n'essayons pas de le présenter à la partie rationnelle de votre cerveau. Nous n'essayons pas plus d'être complets ou logiques. Ce sera l'objet du prochain chapitre. Les Vulcains, les androïdes ainsi que les humains de cette espèce, peuvent aller directement au chapitre 29, Fonctions, pour avoir toute l'information.
Ce livre présente Perl à l'autre partie de votre cerveau, que vous l'appeliez associative, artistique, passionnée, ou simplement spongieuse. Dans ce but, nous présenterons divers aspects de Perl qui vous en donneront une image aussi claire que celle d'un éléphant pour un aveugle. Allons, nous allons essayer de faire mieux. Il s'agit ici d'un chameau, après tout. Espérons qu'au moins un de ces aspects du langage vous mettra en selle.
1-2. Langages naturels et artificiels▲
Les langages ont d'abord été inventés par les humains, pour les humains. Ce fait a parfois été oublié dans les annales de l'informatique.(7) Perl ayant été conçu (pour ainsi dire) par un linguiste occasionnel, il a été inventé pour fonctionner aussi aisément que le langage naturel. Cela recouvre plusieurs notions, puisque le langage naturel fonctionne simultanément à plusieurs niveaux. Nous pourrions énumérer ici nombre de ces principes linguistiques, mais le plus important est que les choses simples doivent le rester et que les choses complexes ne doivent pas être impossibles. Cela peut sembler évident, mais de nombreux langages informatiques ne remplissent pas ces deux conditions.
Les langages naturels permettent les deux parce que les gens essayent continuellement d'exprimer des choses simples et des choses complexes, ce qui fait que le langage évolue pour gérer les deux. Perl a été conçu avant tout pour évoluer, et c'est ce qui s'est produit. De nombreuses personnes ont contribué à l'évolution de Perl au cours des ans. Nous plaisantons souvent en disant que le chameau est un cheval conçu par un comité, mais si l'on y pense, le chameau est parfaitement adapté à la vie dans le désert. Il a évolué pour devenir relativement autosuffisant. (En revanche, l'évolution de l'odeur du chameau est discutable. Cela vaut pour Perl.)
Quand quelqu'un prononce le mot « linguistique », on pense en général soit à des mots, soit à des phrases. Mais les mots et les phrases ne sont que deux manières pratiques de « morceler » la parole. Ils peuvent tous deux être scindés en unités sémantiques plus petites, ou combinés en unités plus grandes. Et la signification de chaque unité dépend largement du contexte syntaxique, sémantique et pragmatique dans lequel se trouve l'unité. Le langage naturel comporte des mots de diverses sortes, des noms, des verbes, etc. Si je dis « pile » tout seul, il y a de fortes chances pour que vous pensiez qu'il s'agisse d'un nom. Mais je peux l'employer autrement : comme un verbe, comme un adverbe, etc., selon le contexte. Si je pile devant une pile de piles à minuit pile, j'ai intérêt à disposer d'une pile.(8)
De même, Perl évalue les mots de façon différente dans des contextes différents. Nous le verrons plus tard. Souvenez-vous que Perl essaie de comprendre ce que vous dites ; il est à l'écoute. Perl essaie vraiment d'aller jusqu'au bout. Dites ce que vous pensez, et en général, Perl le saisira (à moins d'écrire des choses absurdes, bien sûr ; l'analyseur de Perl comprend le Perl bien mieux que le Français ou le Swahili).
Mais revenons aux noms. Un nom peut désigner un objet précis, ou il peut nommer une classe d'objets générique. La plupart des langages de programmation font cette distinction, sauf que nous appelons valeur une chose précise et variable une chose générique. Une valeur existe quelque part, peu importe où, mais une variable est associée à une ou plusieurs valeurs durant son existence. Ce qui interprète la variable doit garder la trace de cette association. Cet interpréteur peut se trouver dans votre cerveau, ou dans votre ordinateur.
1-2-a. Syntaxe d'une variable▲
Une variable n'est qu'un endroit pratique pour conserver quelque chose, un endroit qui a un nom, ce qui fait que vous pouvez retrouver vos petits quand vous y revenez plus tard. Tout comme dans la vie réelle, il existe de nombreux endroits pour ranger des choses, certains privés et certains publics. Certains lieux sont temporaires et d'autres sont permanents. Les informaticiens adorent parler de « portée » des variables, mais c'est à peu près tout ce qu'ils entendent par là. Perl connaît de nombreux moyens de traiter les problèmes de portée, ce que vous serez ravis d'apprendre le moment venu. (Regardez l'emploi des adjectifs local, my et our dans le chapitre 29, si vous êtes curieux, ou bien regardez Déclarations avec portée dans le chapitre 4, Instructions et déclarations.)
Mais on classifie plus efficacement les variables par le type de données qu'elles peuvent représenter. De même qu'en français, la première distinction se fait entre le singulier et le pluriel. Les chaînes et les nombres sont des bouts de données singulières, alors que les listes de chaînes ou de nombres sont plurielles (et quand nous arriverons à la programmation orientée objet, vous verrez qu'un objet peut paraître singulier de l'extérieur, mais pluriel de l'intérieur, de même qu'une classe d'élèves). Nous appelons scalaire une variable singulière, et tableau une variable plurielle. Comme une chaîne peut être stockée dans une variable scalaire, nous pourrons écrire une version un peu plus longue (et mieux commentée) de notre premier exemple comme ceci :
$phrase = "Salut tout le monde !\n"; # Donner une valeur à une variable.
print $phrase; # Afficher la variable.Remarquez que nous n'avons pas eu à prédéfinir le genre de la variable $phrase. Le caractère $ dit à Perl que phrase est une variable scalaire, c'est-à-dire qu'elle contient une valeur singulière. Une variable tableau, en revanche, commencerait par le caractère @ (on peut remarquer que $ est un « S » stylisé, pour scalaire, alors que @ est un « a » stylisé pour « array » , tableau en anglais).
Perl connaît d'autres types de variables aux noms bizarres comme « hachage », « handle » et « typeglob ». Tout comme les scalaires et les tableaux, ces types de variables sont également précédés par des caractères étranges. Dans un souci d'exhaustivité, voici la liste de tous les caractères étranges que vous pourrez rencontrer :
|
Type |
Car. |
Exemple |
Est un nom pour |
|---|---|---|---|
|
scalaire |
|
|
Une valeur propre (nombre, chaîne). |
|
tableau |
|
|
Une liste de valeurs, indexées par numéro. |
|
hachage |
|
|
Un groupe de valeurs indexées par chaîne. |
|
sous-programme |
|
|
Un bout de code Perl appelable. |
|
typeglob |
|
|
Tout ce qui est appelé truc. |
Pour certains « puristes » des langages, ces caractères étranges sont une raison d'abhorrer Perl. Cette raison est superficielle. Ces caractères procurent de nombreux avantages : les variables peuvent être interpolées dans des chaînes sans syntaxe supplémentaire. Les scripts Perl sont faciles à lire (pour ceux qui ont pris la peine d'apprendre Perl !) parce que les noms se distinguent des verbes, et que de nouveaux verbes peuvent être ajoutés au langage sans abîmer d'autres scripts (nous vous avions dit que Perl était conçu pour évoluer). Et l'analogie avec les noms n'a rien de frivole ; il existe de nombreux précédents dans divers langages naturels qui requièrent des marqueurs de noms grammaticaux. Enfin, c'est notre avis !
1-2-a-i. Singularités▲
D'après notre exemple, on voit que l'on peut assigner une nouvelle valeur à un scalaire avec l'opérateur =, comme dans de nombreux autres langages informatiques. On peut affecter n'importe quelle forme de valeur scalaire à une variable SCALAIRE : entier, nombre à virgule flottante, chaîne, et même des choses ésotériques comme des références à d'autres variables ou à des objets. Il existe de nombreuses façons de générer ces valeurs à assigner.
Comme dans le shell UNIX(9), il est possible d'employer différents mécanismes de protection (quoting) pour fabriquer différents types de valeurs. Les doubles apostrophes font une interpolation de variable(10) et une interprétation de l'antislash, comme en transformant \t en tabulation, \n en saut de ligne, \001 en contrôle-A, etc., dans la tradition de nombreux programmes UNIX, alors que les apostrophes suppriment à la fois l'interpolation et l'interprétation. Et les apostrophes inverses exécutent un programme externe et renvoient la sortie du programme, ce qui fait que l'on peut capturer une ligne unique contenant toutes les lignes de la sortie.
$reponse = 42; # un entier
$pi = 3.14159265; # un nombre "réel"
$avocats = 6.02e23; # notation scientifique
$animal = "Chameau"; # chaîne
$signe = "Mon $animal et moi"; # chaîne avec interpolation
$cout = 'Cela coûte $100'; # chaîne sans interpolation
$pourquoi = $parceque; # une autre variable
$x = $taupes * $avocats; # une expression
$exit = system("vi $x"); # code de retour d'une commande
$cwd = `pwd`; # chaîne générée par une commandeEt même si nous n'avons pas encore vu les valeurs exotiques, nous devons signaler que les scalaires peuvent référencer d'autres types de données incluant les sous-programmes et les objets.
$ary = \@montableau; # référence à un tableau nommé
$hsh = \%monhachage; # référence à un hachage nommé
$sub = \&monsousprog; # référence à un sous-programme
$ary = [1,2,3,4,5]; # référence à un tableau anonyme
$hsh = {Na=>19, Cl=>35}; # référence à un hachage anonyme
$sub = sub { print $pays }; # référence à un sous-programme anonyme
$fido = new Chameau "Amelia"; # référence à un objetLes variables non initialisées se mettent à exister quand le besoin s'en fait sentir. D'après le principe de moindre surprise, elles sont créées avec une valeur nulle, que ce soit "" ou 0. Selon l'endroit où elles sont utilisées, les variables sont automatiquement interprétées comme des chaînes, des nombres ou les valeurs « vrai » et « faux » (communément appelées valeurs booléennes). Les opérateurs attendent certains types de valeurs en paramètres, et nous dirons donc que ces opérateurs « fournissent » ou « procurent » un contexte scalaire à ces paramètres. Nous serons parfois plus spécifiques et dirons qu'il fournit un contexte numérique, un contexte de chaîne ou un contexte booléen à ces paramètres (nous parlerons plus loin du contexte de liste, qui est l'inverse du contexte scalaire). Perl convertit automatiquement les données sous la forme requise par le contexte courant, non sans raison. Par exemple, supposons que nous ayons écrit ceci :
$chameaux = '123';
print $chameaux + 1, "\n";La valeur originelle de $chameaux est une chaîne, mais elle est convertie en un nombre pour y ajouter 1, puis reconvertie en chaîne pour être affichée : "124". Le saut de ligne, représenté par "\n", est également dans un contexte de chaîne, mais puisqu'il est déjà une chaîne, aucune conversion n'est nécessaire. Mais remarquez que nous avons dû employer des apostrophes doubles ; les apostrophes simples (') autour de \n auraient donné une chaîne à deux caractères constituée d'un antislash suivi d'un n, ce qui n'est en rien un saut de ligne.
D'une certaine manière, les apostrophes simples et doubles représentent donc un autre moyen de spécifier le contexte. L'interprétation du contenu d'une chaîne protégée dépend de la forme de protection utilisée. Nous verrons plus loin certains autres opérateurs qui fonctionnent comme des protections de façon syntaxique, mais qui utilisent la chaîne d'une manière spéciale comme pour la correspondance de motifs ou la substitution. Ils fonctionnent tous comme des apostrophes doubles. Le contexte d'apostrophe double est le contexte « interpolatif » de Perl et est fourni par de nombreux opérateurs qui ne ressemblent pas à des guillemets.
De la même manière, une référence se comporte comme telle lorsque vous êtes dans un contexte de « déréférencement », sinon elle agit comme une simple valeur scalaire. Par exemple nous écririons :
Ici nous créons une référence à l'objet Chameau et la plaçons dans la variable $fido. À la ligne suivante nous testons $fido dans un contexte booléen, et nous levons une exception si sa valeur est fausse, ce qui dans ce cas voudrait dire que le constructeur new Chameau a échoué à la création de l'objet Chameau. Mais à la dernière ligne, nous utilisons $fido comme référence pour trouver la méthode seller() appliquée à l'objet référencé par $fido, qui se trouve être un Chameau, et donc Perl cherche la méthode seller() pour l'objet Chameau. Nous reviendrons sur ce sujet. Souvenez-vous juste pour le moment que le contexte est important en Perl, car il sert à lever toute ambiguïté sans faire aucune déclaration, contrairement à beaucoup d'autres langages.
1-2-a-ii. Pluralités▲
Certains types de variables contiennent plusieurs valeurs qui sont logiquement liées entre elles. Perl connaît deux types de variables multivaleurs : les tableaux et les hashes, tables de hachage (ou hachages). Ils se comportent comme des scalaires par de nombreux aspects. Ils se mettent à exister quand le besoin s'en fait sentir et ne contiennent alors rien. Quand on leur assigne une valeur, ils fournissent un contexte de liste du côté droit de l'assignation.
On emploie un tableau quand on veut chercher quelque chose par son numéro. On emploie une table de hachage quand on veut chercher quelque chose par son nom. Ces deux concepts sont complémentaires. On voit souvent des gens utiliser un tableau pour traduire les numéros de mois en noms, et un hachage correspondant pour traduire les noms en numéros (les hachages ne se limitent évidemment pas aux seuls nombres. Par exemple, il est possible d'avoir un hachage qui traduise les noms de mois en nom de pierres porte-bonheur).
Tableaux. Un tableau est une liste ordonnée de scalaires, indicée par la position du scalaire dans la liste. Celle-ci peut contenir des nombres, ou des chaînes, ou un mélange des deux (elle peut aussi contenir des références à d'autres listes ou hachages). Pour assigner une liste de valeurs à un tableau, il suffit de regrouper les variables (par des parenthèses) :
@maison = ("lit", "chaise", "table", "poele");Inversement, si l'on utilise @maison dans un contexte de liste, comme ce que l'on trouve à droite d'une assignation, on obtient la même liste qui a été entrée. On peut donc assigner quatre variables depuis le tableau comme ceci :
($Procuste, $porteurs, $multiplication, $gratter) = @maison;C'est ce que l'on appelle des assignations de liste. Elles se produisent logiquement en parallèle, et il est possible de permuter deux variables en écrivant :
($alpha,$omega) = ($omega,$alpha);Tout comme en C, les tableaux démarrent à zéro ; quand on parle des quatre premiers éléments d'un tableau, leur énumération court de 0 à 3.(11) Les indices de tableaux sont entourés de crochets [comme ceci], et si l'on veut sélectionner un seul élément du tableau, on s'y réfère par $maison[n], où n est l'indice (un de moins que le numéro de l'élément) que l'on désire ; voyez l'exemple ci-dessous. Puisque l'élément considéré est un scalaire, il est toujours précédé d'un $.
Si l'on veut valoriser un seul élément de tableau à la fois, on écrit l'assignation précédente comme suit :
$maison[0] = "lit";
$maison[1] = "chaise";
$maison[2] = "table";
$maison[3] = "poele";Comme les tableaux sont ordonnés, il existe plusieurs opérations utiles s'y rapportant, comme les opérations de pile, push et pop. Une pile n'est après tout qu'une liste ordonnée, avec un début et une fin. Surtout une fin. Perl considère que la fin de la liste est le haut d'une pile (bien que la plupart des programmeurs Perl pensent qu'une liste est horizontale, le haut de la pile étant à droite).
Hachages. Un hachage (hash en anglais) est un ensemble non ordonné de scalaires indexé par une valeur chaîne associée à chaque scalaire. C'est pourquoi les hachages sont souvent appelés « tableaux associatifs ». La principale raison pour laquelle leur appellation a changé est que « tableau associatif » est long à écrire pour les paresseux, et nous en parlons tellement souvent que nous avons décidé de prendre un nom plus bref.(12) Ensuite, le terme « hachage » souligne le fait qu'il s'agit de tables non ordonnées. Elles sont en fait implémentées grâce à un système de recherche dans une table de hachage, ce qui leur donne leur rapidité, rapidité qui reste inchangée quel que soit le nombre de valeurs présentes. On ne peut pas faire de push ou de pop sur un hachage, parce que cela n'a aucun sens. Un hachage n'a ni début ni fin. Les hachages sont néanmoins très puissants et très utiles. Tant que vous ne penserez pas en terme de hachages, vous ne penserez pas en Perl.
Puisque les clefs d'un tableau associatif ne sont pas ordonnées, vous devez fournir la clef aussi bien que sa valeur lorsque celui-ci est rempli. Vous pouvez aussi bien lui affecter une liste comme pour un tableau ordinaire, mais chaque paire d'éléments sera interprétée comme la paire clef/valeur. Les tableaux associatifs utilisent le symbole % pour s'identifier. (Pour mémoire, si vous regardez attentivement le caractère %, vous pouvez voir la clef et sa valeur avec entre deux le /.)
Supposons que nous voulions traduire les abréviations des noms de jours en leurs correspondants complets. Nous pourrions écrire cette assignation de liste :
%longjour = ("Dim", "Dimanche", "Lun", "Lundi", "Mar", "Mardi",
"Mer", "Mercredi", "Jeu", "Jeudi", "Ven",
"Vendredi", "Sam", "Samedi");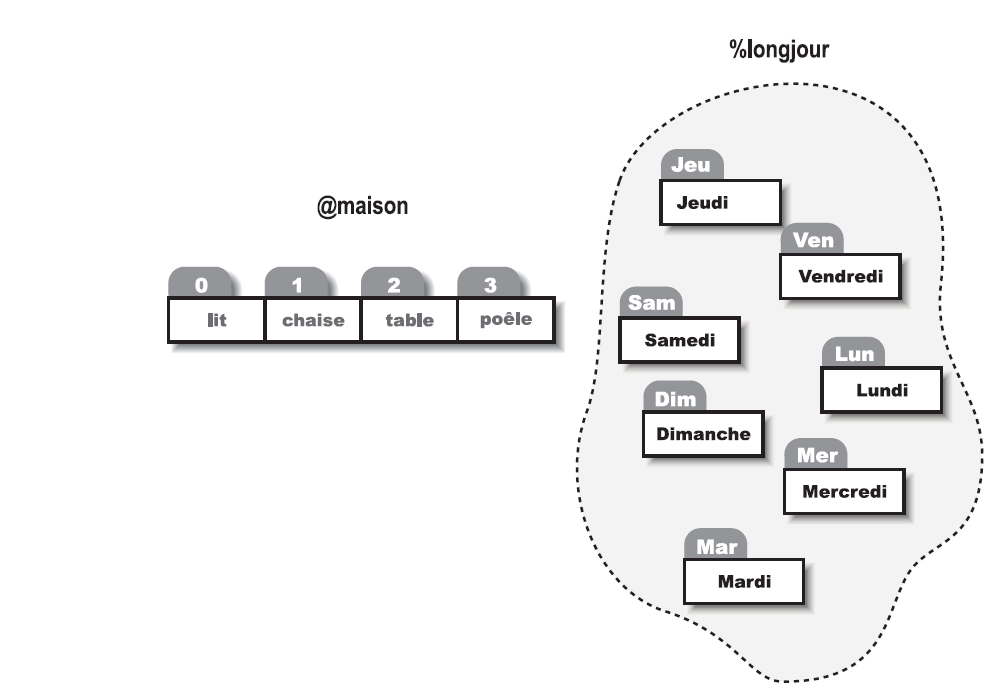
Comme il est parfois difficile de lire un hachage ainsi défini, Perl fournit la séquence => (égal, supérieur) comme alternative à la virgule. Cette syntaxe (associée à un formatage créatif) facilite la distinction entre clefs et valeurs.
%longjour = (
"Dim" => "Dimanche",
"Lun" => "Lundi",
"Mar" => "Mardi",
"Mer" => "Mercredi",
"Jeu" => "Jeudi",
"Ven" => "Vendredi",
"Sam" => "Samedi",
);Il est non seulement possible d'assigner une liste à un hachage, comme nous l'avons fait ci-dessus, mais si l'on emploie un hachage dans un contexte de liste, celui-ci convertira le hachage en une liste de paires clef/valeurs dans un ordre quelconque. La plupart du temps, on se contente d'extraire une liste des seules clefs, grâce à la fonction (bien nommée) keys. Elle est également non ordonnée, mais peut être facilement triée au besoin grâce à la fonction (bien nommée) sort. On peut alors utiliser les clefs ordonnées pour accéder aux valeurs dans un ordre déterminé.
Les hachages n'étant qu'une forme évoluée de tableau, il suffit d'en sélectionner un élément individuel en entourant la clef par des accolades. C'est ainsi que pour trouver la valeur associée à Mer dans le hachage ci-dessus, il faut écrire $longjour{"Mer"}. Remarquez encore une fois qu'il s'agit d'une valeur scalaire et qu'il faut donc écrire $ et non %.
D'un point de vue linguistique, la relation codée dans un hachage est génitive ou possessive, comme les mots « de », « du » ou « d' » en français. La femme d'Adam est Eve, et nous pouvons écrire :
$femme{"Adam"} = "Eve";1-2-a-iii. Complexités▲
La famille des tableaux et des hachages permet de représenter des structures de données simples et élégantes, mais dans la réalité le problème ne se pliera pas toujours à cette simplicité. Il est parfois nécessaire de construire des structures de données non linéaires. Perl nous permet de réaliser ce type de structure d'une manière très simple. Il permet en effet de manipuler de simples scalaires qui se réfèrent à des tableaux. Nous le faisons tous les jours dans le langage courant lorsque nous utilisons un mot par exemple aussi complexe que « gouvernement » pour représenter une entité aussi complexe et inscrutable. (C'est un exemple parmi d'autres.)
Pour développer notre exemple précédent, supposons que nous parlons des femmes de Jacob et Adam. Jacob a eu quatre femmes. Nous pourrions penser l'écrire de cette façon :
$femme{"Jacob"} = ("Léa", "Rachel", "Bilha", "Zilpa"); # MAUVAISMais cette représentation n'est pas bonne, car même les parenthèses ne sont pas assez puissantes pour transformer une liste en scalaire. (Les parenthèses sont utilisées pour le groupage syntaxique et les virgules pour la séparation syntaxique.) Il faut indiquer à Perl que cette liste doit être un scalaire. Les crochets sont parfaitement adaptés à cette fin :
$femme{"Jacob"} = ["Léa", "Rachel", "Bilha", "Zilpa"]; # okCette ligne crée un tableau anonyme et affecte sa référence à l'élément associatif $femme{"Jacob"}. Ainsi nous avons un tableau associatif nommé contenant un tableau anonyme. C'est comme ça que Perl traite les tableaux multidimensionnels et les structures de données imbriquées. Comme avec les types tableaux, on peut aussi affecter des éléments séparés comme ceci :
$femme{"Jacob"}[0] = "Léa";
$femme{"Jacob"}[1] = "Rachel";
$femme{"Jacob"}[2] = "Bilha";
$femme{"Jacob"}[3] = "Zilpa";Comme vous pouvez le voir, cela ressemble beaucoup à un tableau multidimensionnel avec des coordonnées de chaîne puis numérique. Visualisons maintenant une structure de données imbriquées sous forme d'arbre où nous listons aussi tous les fils de chacune des femmes de Jacob. Dans ce cas nous voulons utiliser le tableau associatif dans un contexte scalaire. Pour cela, utilisons les accolades. (La valeur de la clef est un tableau entre crochets. Maintenant nous avons un tableau à l'intérieur d'une association, elle-même association.)
$filsDesFemmesDe{"Jacob"} = {
"Léa" => ["Ruben", "Siméon", "Lévi", "Juda", "Issachar", "Zabulon"],
"Rachel" => ["Joseph", "Benjamin"],
"Bilha" => ["Dan", "Nephtali"],
"Zilpa" => ["Gad", "Aser"],
};Les lignes suivantes sont équivalentes :
$fils_des_femmes_de{"Jacob"}{"Léa"}[0] = "Ruben";
$fils_des_femmes_de{"Jacob"}{"Léa"}[1] = "Siméon";
$fils_des_femmes_de{"Jacob"}{"Léa"}[2] = "Lévi";
$fils_des_femmes_de{"Jacob"}{"Léa"}[3] = "Juda";
$fils_des_femmes_de{"Jacob"}{"Léa"}[4] = "Issachar";
$fils_des_femmes_de{"Jacob"}{"Léa"}[5] = "Zabulon";
$fils_des_femmes_de{"Jacob"}{"Rachel"}[0] = "Joseph";
$fils_des_femmes_de{"Jacob"}{"Rachel"}[1] = "Benjamin";
$fils_des_femmes_de{"Jacob"}{"Bilha"}[0] = "Dan";
$fils_des_femmes_de{"Jacob"}{"Bilha"}[1] = "Nephtali";
$fils_des_femmes_de{"Jacob"}{"Zilpa"}[0] = "Gad";
$fils_des_femmes_de{"Jacob"}{"Zilpa"}[1] = "Aser";On peut constater sur cet exemple que nous avons rajouté une dimension supplémentaire à notre tableau. Perl nous laisse le choix, mais la représentation interne est identique.
Le point important à noter ici est que Perl nous permet de représenter une structure de données complexes comme un simple scalaire. Cette encapsulation nous permet de construire une structure orientée objet. Lorsque nous avions invoqué le constructeur de Chameau comme ceci :
$fido = new Chameau "Amelia";nous avions créé un objet Chameau représenté par le scalaire $fido. Mais la structure intime de l'objet Chameau est plus compliquée. En tant que concepteurs d'objets, nous ne sommes pas concernés par ceci, à moins d'être nous-mêmes les implémenteurs des méthodes de cette classe. Mais, généralement, un objet comme celui-ci serait représenté par un tableau associatif contenant les attributs de Chameau, tels son nom (« Amelia » dans ce cas, et non pas « fido »), le nombre de bosses (ce que nous n'avons pas spécifié, mais il vaut probablement 1, regardez la couverture du livre).
1-2-a-iv. Simplicité▲
Si votre tête ne tourne pas après avoir lu cette dernière section alors vous avez une grosse tête. La plupart des humains sont rebutés par les structures compliquées du type gouvernement ou du type arbre généalogique. Pour cette raison nous disposons dans notre langage parlé d'artifices qui cachent cette complexité sous-jacente. La technique la plus probante est la clôture du champ sémantique, lexicalisation, topicalization en anglais, qui permet de s'accorder sur les termes du langage utilisé. La conséquence immédiate est une meilleure communication. La plupart d'entre nous utilisent cette technique couramment pour basculer d'un contexte sémantique vers un autre lorsque nous changeons simplement de sujet de conversation.
Perl dispose dans sa palette de ce type d'outil. L'un de ceux-ci est fourni par la simple déclaration package. Supposons que notre sujet est le Chameau de Perl. On déclenche le module Chameau par la déclaration :
package Chameau;Tout symbole déclaré ensuite sera préfixé par le nom du module « Chameau:: ». Ainsi si on écrit :
package Chameau;
$fido = &fetch();on écrit en réalité $Chameau::fido et la fonction appelée est &Chameau::fetch, (nous parlerons des verbes plus tard). Si dans le cours du déroulement du code, l'interpréteur rencontre le code suivant :
package Chien;
$fido = &fetch();il ne pourra confondre les noms réels, car $fido est en fait $Chien::fido, et non $Chameau::fido. En informatique cela signifie un espace de nommage. Il n'a pas de limite cardinale. Perl n'en connaît qu'un à la fois. La simplification est le choix libre du programmeur.
Une chose remarquable est que dans :
$fido = new Chameau "Amelia";nous invoquons le verbe &new dans le package Chameau, qui a pour nom plein &Chameau::new. et par
$fido->seller();nous invoquons la routine &Chameau::seller, car $fido pointe sur un Chameau. C'est la programmation objet en perl.
La déclaration package Chameau, marque le début d'un paquetage, ici le paquetage Chameau. Parfois il suffit d'utiliser les noms et les verbes d'un paquetage existant. On utilise alors la déclaration use, qui charge le module dans l'interpréteur. Cela doit s'écrire :
use Chameau;Puis on peut utiliser nos méthodes
$fido = new Chameau "Amelia";Perl est WYSIWYG. Sinon Perl ne connaîtrait pas Chameau.
La chose intéressante ici est qu'il est juste nécessaire de connaître les capacités d'un Chameau. Il suffit de trouver le module sur CPAN :
use Le::Cool::Module;Alors on peut actionner les verbes de ce module dans le champ du sujet.
La lexicalisation Perl, comme dans le langage naturel, donne un nom au champ lexical. Certains modules définissent des ensembles lexicaux et uniquement cela, pour l'interpréteur lui-même. Ces modules spéciaux se nomment pragmas. On verra souvent l'utilisation du pragma strict de cette manière :
Le pragma strict permet d'ajouter une norme pour l'évaluation des termes par Perl. Cette norme oblige à préciser certains aspects comme la portée des variables du code, ce qui est utile dans le développement de grands projets. En effet, Perl est optimisé pour l'écriture de petits modules, mais avec cette directive de compilation il devient possible de gérer des projets importants. On peut en effet l'ajouter à tout moment dans des modules élémentaires, ce qui permet de les faire interagir dans un même champ lexical. (Et autoriser du même coup une approche objet dans le développement de l'application elle-même.)
1-2-b. Verbes▲
Comme tous les langages informatiques impératifs, de nombreux verbes de Perl correspondent à des commandes : elles disent à l'interpréteur de Perl de faire quelque chose. En revanche, comme dans un langage naturel, les significations des verbes de Perl tendent à s'éparpiller dans plusieurs directions selon le contexte. Une instruction commençant par un verbe est en général purement impérative et évaluée entièrement pour ses effets secondaires. Nous appelons souvent ces verbes procédures, surtout quand ils sont définis par l'utilisateur. Un verbe fréquemment rencontré (que vous avez d'ailleurs déjà vu) est la commande print :
print "La femme d'Adam est ", $femme{'Adam'}, ".\n";L'effet secondaire produit la sortie désirée.
Mais il existe d'autres « modes » que le mode impératif. Certains verbes permettent d'interroger l'interpréteur sur certaines valeurs comme dans les conditionnelles comme if. D'autres verbes traduisent leurs paramètres d'entrée en valeurs de retour, tout comme une recette vous indique comment transformer des ingrédients de base en un résultat (peut-être) comestible. Nous appelons souvent ces verbes des fonctions, par déférence envers des générations de mathématiciens qui ne savent pas ce que signifie le mot « fonctionnel » en langage naturel.
Un exemple de fonction interne est l'exponentielle :
$e = exp(1); # 2.718281828459, ou à peu prèsMais Perl ne fait pas de distinction entre les procédures et les fonctions. Les termes seront employés de façon interchangeable. Les verbes sont parfois appelés sous-programmes (subroutines) quand ils sont définis par l'utilisateur, ou opérateurs (s'ils sont prédéfinis). Mais appelez-les comme il vous plaira ; ils renvoient tous une valeur, qu'elle soit ou non significative, que vous pouvez ou non choisir d'ignorer.
Au fur et à mesure que nous avançons, nous verrons d'autres exemples du comportement de Perl qui le font ressembler à un langage naturel. Nous avons déjà insidieusement présenté certaines notions de langage mathématique, comme l'addition et les indices, sans parler de la fonction exponentielle. Perl est aussi un langage de contrôle, un langage d'intégration, un langage de traitement de listes et un langage orienté objet. Entre autres.
Mais Perl est aussi un bon vieux langage informatique. Et c'est ce à quoi nous allons maintenant nous intéresser.
1-3. Un exemple de notation▲
Supposons que vous ayez un ensemble de notes pour chaque membre d'une classe d'élèves. Vous aimeriez une liste combinée de toutes les notes pour chaque étudiant, plus leur moyenne. Vous disposez d'un fichier texte (appelé, quelle imagination, « notes » ) qui ressemble à ceci :
Xavier 25
Samantha 76
Hervé 49
Peter 66
Olivier 92
Thierry 42
Fred 25
Samantha 12
Hervé 0
Corinne 66
etc.Le script ci-dessous rassemble toutes leurs notes, détermine la moyenne de chaque étudiant et les affiche dans l'ordre alphabétique. Ce programme suppose, plutôt naïvement, qu'il n'existe pas deux Corinne dans votre classe. C'est-à-dire que s'il y a un deuxième élément pour Corinne, le programme supposera qu'il s'agit d'une autre note de la première Corinne.
Au fait, les numéros de lignes ne font pas partie du programme, toute ressemblance avec le BASIC mise à part.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
#!/usr/bin/perl
open(NOTES, "notes") or die "Ouverture des notes impossible : $!\n";
while ($ligne = <NOTES>) {
($etudiant, $note) = split(/ /, $ligne);
$notes\{$etudiant\} .= $note . " ";
}
foreach $etudiant (sort keys %notes) {
$scores = 0;
$total = 0;
@notes = split(/ /, $notes{$etudiant});
foreach $note (@notes) {
$total += $note;
$scores++;
}
$moyenne = $total / $scores;
print "$etudiant: $notes{$etudiant}\tMoyenne : $moyenne\n";
}
Ne louchez pas ainsi. Nous devons avouer que si cet exemple illustre beaucoup de ce que nous avons décrit jusqu'à présent, il comprend certaines choses que nous allons maintenant expliquer. Mais si vous regardez un peu dans le vague, vous pouvez commencer à voir apparaître certains motifs intéressants. Vous pouvez vous livrer à toutes les suppositions imaginables, et nous vous dirons plus tard si vous aviez raison.
Nous pourrions vous dire d'essayer de le lancer, mais peut-être ne savez-vous pas comment faire.
1-3-a. Comment faire▲
Bien. Vous devez être en train de vous demander comment lancer un programme Perl. La réponse la plus courte est que vous le donnez au programme interpréteur de Perl, qui s'appelle justement perl (notez le p minuscule). Une réponse plus complète commence comme ceci : Il Existe Plus D'Une Façon De Faire.(13)
La première manière d'invoquer perl (qui fonctionne sur la plupart des systèmes d'exploitation) est d'appeler explicitement perl depuis la ligne de commande.(14) Si vous vous trouvez sur une version d'UNIX et que ce que vous faites est relativement simple, vous pouvez utiliser l'option -e (le % de l'exemple suivant représentant une invite standard de shell, il ne faut pas le taper) :
% perl -e 'print "Salut tout le monde!\n";'Sous d'autres systèmes d'exploitation, il faudra peut-être jouer des apostrophes. Mais le principe de base est le même : vous essayez de rentrer tout ce que Perl doit savoir en 80 colonnes.(15)
Pour les scripts plus longs, vous pouvez utiliser votre éditeur favori (ou un autre) pour écrire vos commandes dans un fichier, puis, si le script s'appelle « gradation », vous entrez :
% perl gradationVous invoquez toujours explicitement l'interpréteur Perl, mais au moins, vous n'avez pas à tout mettre sur la ligne de commande à chaque fois. Et vous n'avez pas à jouer des apostrophes pour plaire au shell.
La façon la plus commode d'invoquer un script est de simplement l'appeler par son nom (ou de cliquer sur son icône), et de laisser le système d'exploitation trouver l'interpréteur tout seul. Sous certains systèmes, il peut exister un moyen d'associer certaines extensions de fichier ou certains répertoires à une application particulière. Sur les systèmes UNIX qui supportent la notation #! (appelée shebang), la première ligne du script peut être magique et dire au système d'exploitation quel programme lancer. Mettez une ligne ressemblant(16) à la ligne 1 de notre exemple dans votre programme :
#!/usr/bin/perlTout ce qu'il vous reste à écrire est maintenant :
% gradationCe qui ne fonctionne évidemment pas parce que vous avez oublié de rendre le script exécutable (voir la page de manuel de chmod (1)(17) et qu'il n'est pas dans votre PATH. Dans ce cas, vous devrez fournir un nom de chemin complet pour que votre système d'exploitation sache comment trouver votre script. Quelque chose comme :
% ../bin/gradationEnfin, si vous avez la malchance de travailler sur un ancien système UNIX qui ne reconnaît pas la ligne magique #!, ou si le chemin vers votre interpréteur est plus long que 32 caractères (une limite interne sur certains systèmes), vous pourrez contourner le problème comme ceci :
#!/bin/sh --# perl, pour arrêter de boucler
eval 'exec /usr/bin/perl -S $0 ${1+"$@"}'
if 0;Certains systèmes d'exploitation peuvent demander une modification de ce qui précède pour gérer, /bin/sh, DCL, COMMAND.COM, ou tout ce qui vous tient lieu d'interpréteur de commandes. Demandez à votre Expert Local.
Tout au long de ce livre, nous nous contenterons d'employer #!/usr/bin/perl pour représenter toutes ces notions et toutes ces notations, mais vous saurez à quoi vous en tenir.
Une astuce : quand vous écrivez un script de test, ne l'appelez pas test. Les systèmes UNIX ont une commande test interne, qui sera exécutée à la place de votre script. Appelez-le plutôt essai.
Une autre astuce : pendant que vous apprenez Perl, et même quand vous croyez savoir ce que vous faites, nous vous suggérons d'utiliser l'option -w, surtout pendant le développement. Cette option active toutes sortes de messages d'avertissement utiles et intéressants (dans le désordre). L'option -w peut être placée sur la ligne « magique », comme ceci :
#!/usr/bin/perl -wMaintenant que vous savez lancer votre programme Perl (à ne pas confondre avec le programme perl), revenons à notre exemple.
1-4. Handles de fichiers▲
À moins qu'il ne s'agisse d'un projet d'IA modélisant un philosophe solipsiste, votre programme a besoin de communiquer avec le monde extérieur. Aux lignes 3 et 4 de notre exemple de notation, on voit le mot NOTES, qui illustre un autre type de données de Perl, le handle de fichier. Un handle de fichier est un nom que l'on donne à un fichier, un périphérique, une socket ou un pipe pour que vous puissiez vous souvenir de ce dont vous parlez, et pour dissimuler certaines complexités, notamment relatives aux tampons. (En interne, les handles de fichiers sont similaires aux streams d'un langage comme C ou C++, ou aux canaux d'E/S du BASIC.)
Les handles de fichiers facilitent la gestion des entrées et des sorties depuis plusieurs sources et vers plusieurs destinations. C'est sa capacité à communiquer avec de nombreux fichiers et de nombreux processus qui fait de Perl un bon langage d'intégration.(18)
On crée un handle de fichier et on l'attache à un fichier par la fonction open. Open prend deux paramètres : le handle de fichier et le nom du fichier auquel on veut l'associer. Perl vous donne aussi quelques handles de fichier prédéfinis (et déjà ouverts). STDIN est le canal d'entrée standard du programme, alors que STDOUT en est le canal de sortie standard. Et STDERR est un canal de sortie supplémentaire pour que votre programme puisse faire des remarques à part pendant qu'il transforme (ou essaye de transformer) votre entrée en sortie.(19)
Comme l'on peut utiliser la fonction open pour créer des handles de fichiers à des fins diverses (entrées, sorties, pipes), vous devrez pouvoir spécifier le comportement que vous désirez. Il suffit d'ajouter des caractères au nom du fichier.
open(SESAME, "nomdefichier"); # lire depuis un fichier existant
open(SESAME, "<nomdefichier "); # (idem, explicitement)
open(SESAME, ">nomdefichier "); # créer un fichier et y écrire
open(SESAME, ">>nomdefichier "); # ajouter à un fichier existant
open(SESAME, "| sortie_de_commande"); # mettre en place un filtre de sortie
open(SESAME, "entrée de commande |"); # mettre en place un filtre d'entréeOn voit que le nom en question est quelconque. Une fois ouvert, le handle de fichier SESAME peut être utilisé pour accéder au fichier, ou au pipe, jusqu'à ce qu'il soit explicitement fermé (avec, on s'en doutait, close(SESAME)), ou si le handle de fichier est attaché à un autre fichier par un autre open sur le même handle.(20)
Une fois le handle de fichier ouvert en entrée (ou si vous désirez utiliser STDIN), vous pouvez lire une ligne grâce à l'opérateur de lecture de ligne, <>. Il est également connu sous le nom d'opérateur diamant en raison de sa forme. L'opérateur diamant entoure le handle de fichier <SESAME> dont on veut lire des lignes.(21) Un exemple utilisant le handle de fichier STDIN pour lire une réponse fournie par l'utilisateur ressemblerait à ceci :
print STDOUT "Entrez un nombre : "; # demander un nombre
$nombre = <STDIN>; # entrer le nombre
print STDOUT "Le nombre est $nombre\n"; # afficher le nombreAvez-vous vu ce que nous venons de vous glisser sous les pieds ? Qu'est-ce que ce STDOUT fait dans ces instructions print ? C'est simplement une des façons possibles d'utiliser un handle de fichier. Un handle de fichier peut être fourni comme premier argument de l'instruction print et, s'il est présent, il indique où est la sortie. Dans ce cas, le handle de fichier est redondant, car la sortie aurait, de toute manière, été STDOUT. De même que STDIN est l'entrée par défaut, STDOUT est la sortie par défaut (nous l'avons enlevé en ligne 18 de l'exemple de notation pour éviter de vous embrouiller).
Nous avons fait autre chose. Si vous essayez l'exemple ci-dessus, vous pouvez voir apparaître une ligne vide supplémentaire. En effet, la lecture n'enlève pas automatiquement le saut de ligne de votre ligne d'entrée (qui serait par exemple « 9\n » ). Au cas où vous voudriez enlever le saut de ligne, Perl fournit les fonctions chop et chomp. chop enlève (et renvoie) le dernier caractère qu'on lui passe sans se poser de question, alors que chomp n'enlève que le marqueur de fin d'enregistrement (en général, « \n ») et renvoie le nombre de caractères enlevés. Cette expression est souvent employée pour lire une seule ligne :
chop($nombre = <STDIN>); # lire le nombre et enlever le saut de lignece qui est identique à
$number = <STDIN>; # lire le nombre
chop($number); # enlever le saut de ligne1-5. Opérateurs▲
Comme nous l'avons laissé entendre plus haut, Perl est également un langage mathématique. C'est vrai à différents niveaux, depuis les opérations logiques au niveau binaire jusqu'aux manipulations de nombres et d'ensembles, de prédicats plus vastes à diverses abstractions. Et comme nous le savons tous depuis que nous avons étudié les mathématiques à l'école, les mathématiciens adorent les symboles étranges. Pire encore, les informaticiens ont inventé leur propre version de ces symboles. Perl en connaît un certain nombre, mais vous pouvez respirer, car la plupart sont directement empruntés au C, au FORTRAN, à sed ou à awk, et seront donc familiers aux utilisateurs de ces langages.
Vous pouvez vous féliciter de connaître plus de termes lexicaux, autant de points d'entrée vers les autres langages.
Les opérateurs internes de Perl peuvent être classés par nombre d'opérandes, en opérateurs unaires, binaires et ternaires. Ils peuvent être classés par opérateurs infixes ou préfixes, mais aussi par le type d'objet avec lesquels ils travaillent, comme les nombres, les chaînes ou les fichiers. Nous vous donnerons plus loin une table de tous les opérateurs, mais en voici quelques-uns par lesquels vous pourrez commencer.
1-5-a. Quelques opérateurs d'arithmétique binaire▲
Les opérateurs arithmétiques font exactement ce que l'on peut attendre d'eux après les avoir étudiés à l'école.
|
Exemple |
Nom |
Résultat |
|---|---|---|
|
|
Addition |
Somme de |
|
|
Multiplication |
Produit de |
|
|
Modulo |
Reste de |
|
|
Puissance |
|
Oui, nous avons bien laissé de côté la soustraction et la division. Mais vous devez pouvoir deviner comment celles-ci fonctionnent. Essayez-les et voyez si vous aviez raison (ou trichez et cherchez dans le chapitre 3, Opérateurs unaires et binaires.) Les opérateurs arithmétiques sont évalués dans l'ordre habituel (c'est-à-dire la puissance avant la multiplication, et la multiplication avant l'addition). Les parenthèses servent à modifier l'ordre.
1-5-b. Opérateurs sur les chaînes▲
Il existe également un opérateur d'« addition » pour les chaînes, qui effectue leur concaténation. Contrairement à d'autres langages qui le confondent avec l'addition arithmétique, Perl définit un opérateur distinct (.) pour cette opération.
$a = 123;
$b = 456;
print $a + $b; # affiche 579
print $a . $b; # affiche 123456Il existe aussi un opérateur de « multiplication » pour les chaînes, également appelée répétition. Il s'agit encore d'un opérateur distinct (x) qui le différencie de la multiplication numérique :
$a = 123;
$b = 3;
print $a * $b; # affiche 369
print $a x $b; # affiche 123123123L'opérateur de répétition est un peu inhabituel en ce qu'il prend une chaîne pour son argument de gauche et un nombre pour celui de droite. Remarquez également comment Perl convertit automatiquement les nombres en chaînes. Tous les nombres ci-dessus pourraient être protégés par des apostrophes doubles avec le même résultat. La conversion interne se serait par contre produite dans le sens inverse (c'est-à-dire de chaînes vers des nombres).
Il faut encore penser à quelques détails. La concaténation de chaînes est également implicite dans l'interpolation qui se produit dans des chaînes entre doubles apostrophes. Quand une liste de valeurs est affichée, les chaînes de caractères sont en fait concaténées. Les trois instructions suivantes produisent donc le même résultat :
print $a . ' est égal à ' . $b . "\n"; # opérateur point
print $a, ' est égal à ', $b, "\n"; # liste
print "$a est égal à $b\n"; # interpolationLe choix de celui qu'il convient d'utiliser ne dépend que de vous.
L'opérateur x peut sembler relativement inutile à première vue, mais il trouve son utilité dans des cas comme celui-ci :
print "-" x $lrgecr, "\n";Ceci trace une ligne à travers l'écran, à supposer que sa largeur soit $lrgecr.
1-5-c. Opérateurs d'affectation▲
Bien qu'il ne s'agisse pas vraiment d'un opérateur mathématique, nous avons déjà employé en de nombreuses occasions l'opérateur d'assignation simple, =. Essayez de vous souvenir que = signifie « est mis à » au lieu de « égale » (il existe aussi un opérateur d'égalité mathématique == qui signifie « égale » , et si vous commencez à réfléchir tout de suite à la différence entre les deux, vous aurez beaucoup moins mal à la tête plus tard. L'opérateur == est comme une fonction qui renvoie une valeur booléenne, alors que = est comme une procédure évaluée dont l'effet est de modifier une variable).
De même que les opérateurs précédents, les opérateurs d'assignation sont des opérateurs binaires infixes, ce qui veut dire qu'ils ont un opérande de chaque côté de l'opérateur. L'opérande de droite peut être n'importe quelle expression, mais celui de gauche doit être une lvalue correcte (ce qui, traduit en bon français, signifie un emplacement de stockage valide, comme une variable ou un élément de tableau). L'opérateur d'assignation le plus courant est l'assignation simple. Il détermine la valeur de l'expression à sa droite, puis met la variable à sa gauche à cette valeur :
$a = $b;
$a = $b + 5;
$a = $a * 3;Remarquez que la dernière assignation se réfère deux fois à la même variable ; une fois pour le calcul et une autre pour l'assignation. Rien d'extraordinaire à cela, mais cette opération est assez commune pour qu'elle connaisse une abréviation (empruntée au C). Si l'on écrit :
lvalue opérateur= expressioncela sera évalué comme si c'était :
lvalue = lvalue opérateur expressionsauf que la lvalue n'est pas calculée deux fois. On ne perçoit de différence que si l'évaluation de la lvalue a un effet secondaire. Mais quand il y a une différence, l'opérateur fait généralement ce que vous vouliez.
On peut, par exemple, écrire :
$a *= 3;ce qui se lit « multiplier $a par 3 et l'affecter à $a ». Presque tous les opérateurs binaires de Perl le permettent, et même certains de ceux qui ne le peuvent pas en C :
$ligne .= "\n"; # Ajouter un saut de ligne à $ligne.
$fill x= 80; # Répéter $fill 80 fois sur elle-même.
$val ||= "2"; # Mettre $val à 2 si ce n'est pas déjà le cas.La ligne 6 de notre exemple(22) de notation contient deux concaténations de chaînes, dont l'une est un opérateur d'affectation. Et la ligne 14 contient un +=.
Quel que soit le type d'opérateur d'affectation utilisé, la valeur finale qui est renvoyée est celle de l'affectation complète(23). Ceci ne surprendra pas les programmeurs C qui le savait déjà en écrivant
$a = $b = $c = 0;pour initialiser à 0 toutes les variables.
Ce qui par contre les surprendra est que l'affectation Perl retourne en lvalue la variable elle-même, de telle sorte qu'il est possible en une instruction de le modifier deux fois, c'est pourquoi nous pouvons écrire :
($temp -= 32) *= 5/9;pour faire la conversion en ligne Fahrenheit vers Celsius. C'est aussi pourquoi nous avons pu écrire plus haut dans ce chapitre :
chop($nombre = <STDIN>);pour que la valeur finale de $nombre soit modifiée par chop. Pour résumer, on peut utiliser cette fonctionnalité chaque fois que l'on veut faire une copie suivie d'une modification de variable.
Ce truc peut être utilisé pour faire deux choses sur la même ligne Perl.
1-5-d. Opérateurs arithmétiques unaires▲
Comme si $variable += 1 n'était pas assez court, Perl emprunte au C un moyen encore plus concis d'incrémenter une variable. Les opérateurs d'autoincrémentation et d'autodécrémentation ajoutent (ou soustraient) un à la valeur de la variable. Ils peuvent être placés avant ou après cette variable, ce qui détermine le moment de leur évaluation.
|
Exemple |
Nom |
Résultat |
|---|---|---|
|
|
Autoincrémentation |
Ajouter 1 à |
|
|
Autodécrémentation |
Soustraire 1 de |
Si l'on place l'un des opérateurs auto avant la variable, il s'agit d'une variable préincrémentée (ou prédécrémentée). Sa valeur sera modifiée avant son référencement. S'il est placé après la variable, il s'agit d'une variable postincrémentée (ou postdécrémentée) et sa valeur est modifiée après son utilisation. Par exemple :
$a = 5; # $a prend la valeur 5
$b = ++$a; # $b prend la valeur incrémentée de $a, soit 6
$c = $a--; # $c prend la valeur 6, puis $a passe à 5La ligne 15 de notre exemple de notation incrémente de un le nombre de notes, afin que nous puissions calculer la moyenne. Nous utilisons un opérateur de postincrémentation ($scores++), mais cela n'a pas d'importance dans ce cas puisque l'expression se trouve dans un contexte vide, ce qui n'est qu'une façon particulière de dire que l'expression n'est évaluée que pour l'effet secondaire de l'incrémentation de la variable. La valeur renvoyée est jetée au panier.(24)
1-5-e. Opérateurs logiques▲
Les opérateurs logiques, que l'on connaît également sous le nom d'opérateurs « court-circuit », permettent au programme de prendre des décisions en fonction de critères multiples sans utiliser les conditionnelles imbriquées. On les appelle court-circuit, car ils arrêtent l'évaluation de leur argument de droite si l'argument de gauche suffit à déterminer la valeur globale.
Perl a en fait deux ensembles d'opérateurs logiques : l'un d'eux, plutôt poussiéreux, emprunté au C, et un superbe ensemble tout neuf d'opérateurs à précédence ultra-basse qui analysent plus comme ce qu'on en attend (mais ils se comportent de la même façon une fois analysés). Perl possède deux ensembles d'opérateurs logiques, l'un dit traditionnel emprunté au C, l'autre avec une précédence encore plus faible venant du BASIC. L'un a la précédence la plus forte des opérateurs du langage, l'autre la plus faible. Souvent les expressions sont équivalentes, c'est une question de préférences. (Pour une comparaison, voir la section And, or, not et xor logiques au chapitre 3.) Bien qu'ils ne sont pas interchangeables, à cause de la précédence, une fois parsés ils s'exécutent avec le même code. La précédence précise l'étendue locale de arguments.
|
Exemple |
Nom |
Résultat |
|---|---|---|
|
|
Et |
|
|
|
Ou |
|
|
|
Non |
Vrai si |
|
|
Et |
|
|
|
Ou |
|
|
|
Non |
Vrai si |
|
|
Ou exclusif |
Vrai si |
Puisque les opérateurs logiques « court-circuitent », ils sont souvent utilisés pour exécuter du code de manière conditionnelle. La ligne suivante (de notre exemple de notation) essaie d'ouvrir le fichier « notes ». Si elle peut ouvrir le fichier, elle saute à la ligne suivante du programme. Dans le cas contraire, elle affiche un message d'erreur et arrête l'exécution.
open(NOTES, "notes") or die "Ouverture du fichier notes impossible: $!\n";Littéralement, « Ouvrir notes ou mourir ! » est encore un exemple de langage naturel, et les opérateurs de court-circuit préservent le f lux visuel. Les actions importantes sont listées en bas à gauche de l'écran et les actions secondaires sont cachées à droite. (La variable $! contient le message d'erreur renvoyé par le système d'exploitation ; voir le chapitre 28, Noms spéciaux.) Bien sûr, ces opérateurs logiques peuvent aussi être employés dans des constructions plus traditionnelles, comme les instructions if et while.
1-5-f. Opérateurs de comparaison▲
Les opérateurs de comparaison, ou relationnels, nous indiquent la relation existant entre deux valeurs scalaires (nombres ou chaînes). Il existe deux ensembles d'opérateurs, dont l'un effectue les comparaisons numériques et l'autre des comparaisons de chaînes. (Dans les deux cas, les arguments seront d'abord transtypés, « contraints », pour prendre le bon type.) Le tableau suivant suppose que $a et $b sont respectivement les arguments de gauche et de droite.
|
Comparaison |
Numérique |
Chaîne |
Valeur de retour |
|---|---|---|---|
|
égal |
|
Vrai si |
|
|
Différent |
|
|
Vrai si |
|
Inférieur à |
|
Vrai si |
|
|
Supérieur à |
|
|
Vrai si |
|
Inférieur ou égal à |
|
|
Vrai si |
|
Supérieur ou égal à |
|
|
Vrai si |
|
Comparaison |
|
|
0 si égal, 1 si |
On peut penser que les deux derniers opérateurs (<=> et cmp) sont entièrement redondants. Vous avez raison. Cependant, ils sont incroyablement utiles dans les sous-programmes de tri (sort).(25)
1-5-g. Opérateurs de tests de fichier▲
Les opérateurs de tests de fichier permettent de tester si certains attributs de fichier sont positionnés avant de faire aveuglément n'importe quoi avec ces fichiers. Par exemple, il vaut mieux s'assurer que le fichier /etc/passwd existe déjà avant de l'ouvrir en création, effaçant ainsi tout ce qui s'y trouvait auparavant.
|
Exemple |
Nom |
Résultat |
|---|---|---|
|
|
Existe |
Vrai si le fichier nommé par |
|
|
Lecture |
Vrai si le fichier nommé par |
|
|
Écriture |
Vrai si le fichier nommé par |
|
|
Répertoire |
Vrai si le fichier nommé par |
|
|
Fichier |
Vrai si le fichier nommé par |
|
|
Fichier texte |
Vrai si le fichier nommé par |
En voici quelques exemples :
-e "/usr/bin/perl" or warn "Perl est mal installé\n";
-f "/boot" and print "Félicitations, nous devons être sous Unix BSD\n";Remarquez qu'un fichier régulier n'est pas la même chose qu'un fichier texte. Les fichiers binaires comme /vmunix sont des fichiers réguliers, mais ne sont pas des fichiers texte. Les fichiers texte sont l'inverse des fichiers binaires, alors que les fichiers réguliers sont l'inverse des fichiers « irréguliers » comme les répertoires et les périphériques.
Il existe beaucoup d'opérateurs de test de fichier, dont un grand nombre n'ont pas été cités. La plupart sont des opérateurs booléens unaires : ils ne prennent qu'un seul opérande, un scalaire qui donne un fichier ou un handle de fichier, et ils renvoient une valeur vraie ou fausse. Quelques-uns renvoient une valeur plus complexe comme la taille du fichier ou son âge, mais vous pourrez les rechercher en temps utile dans la section Opérateurs unaires nommés et de test de fichier au chapitre 3.
1-6. Structures de contrôle▲
Jusqu'ici, et hormis notre programme de notation, tous nos exemples étaient complètement linéaires ; toutes les commandes étaient exécutées dans l'ordre. Nous avons vu quelques exemples d'utilisation des opérateurs court-circuit permettant l'exécution conditionnelle d'une commande. Bien que certains programmes linéaires s'avèrent extrêmement utiles (c'est le cas de beaucoup de scripts CGI), on peut écrire des programmes bien plus puissants grâce aux expressions conditionnelles et aux mécanismes de boucles, que l'on appelle structures de contrôle. Perl peut donc être considéré comme un langage de contrôle.
Mais pour contrôler le cours des choses, il faut être en mesure de décider, et pour décider des choses, il faut distinguer le vrai du faux.
1-6-a. Qu'est-ce que la vérité ?▲
Nous avons déjà parlé de la vérité(26) et nous avons mentionné que certains opérateurs renvoient une valeur vraie ou fausse. Avant de continuer, nous devons expliquer exactement ce que nous entendons par là. Perl ne traite pas tout à fait la vérité comme les autres langages informatiques, mais son comportement prend tout son sens avec un peu d'habitude. (En fait, nous espérons qu'il prendra tout son sens après avoir lu ce qui suit.)
À la base, Perl estime que la vérité est « évidente en soi ». C'est une façon un peu spécieuse de dire que l'on peut évaluer presque n'importe quoi pour connaître sa valeur de vérité. Perl emploie en pratique des définitions de la vérité qui dépendent du type de ce que l'on est en train d'évaluer. Il se trouve qu'il existe beaucoup plus de types de vérité que de types de non-vérité.
La vérité en Perl est toujours évaluée dans un contexte scalaire (sinon, aucun transtypage n'est effectué). Voici donc les règles des divers types de valeurs qu'un scalaire peut contenir :
- Toute chaîne est vraie sauf
""et"0". - Tout nombre est vrai sauf
0. - Toute référence est vraie.
- Toute valeur indéfinie est fausse.
En fait, les deux dernières règles peuvent être dérivées des deux premières. Toute référence (règle 3) pointe vers quelque chose avec une adresse, et donne un nombre ou une chaîne contenant cette adresse, qui n'est jamais nulle. Et toute valeur indéfinie (règle 4) donne 0 ou la chaîne nulle.
Et d'une certaine manière, il est possible de faire dériver la règle 2 de la règle 1 si l'on pose que tout est une chaîne. Encore une fois, aucun transtypage n'est effectué pour évaluer la vérité, mais même si c'était le cas, une valeur numérique de 0 donnerait simplement la chaîne « 0 » et serait fausse. Tout autre nombre donnerait autre chose et serait vrai. Quelques exemples nous permettront de saisir un peu mieux ce que cela implique :
0 # deviendrait la chaîne "0", donc faux
1 # deviendrait la chaîne "1", donc vrai
10 -10 # 10-10 vaut 0, deviendrait la chaîne "0", donc faux
0.00 # devient 0, et donc la chaîne "0", donc faux
"0" # la chaîne "0", donc faux
"" # une chaîne nulle, donc faux
"0.00" # la chaîne "0.00", ni vide, ni vraiment "0", donc vrai
"0.00" + 0 # le nombre 0 (transtypé par +), donc faux
\$a # une référence à $a, donc vrai, même si $a est faux
undef() # une fonction renvoyant la chaîne indéfinie, donc fauxComme nous avons déjà dit que la vérité était évaluée dans un contexte scalaire, on peut se demander quelle serait la valeur d'une liste. En fait, il n'existe pas d'opération renvoyant une liste dans un contexte scalaire. Toutes renvoient une valeur scalaire et il suffit d'appliquer les règles de vérité à ce scalaire. Il n'y a donc pas de problème, tant que l'on sait ce qu'un opérateur donné renvoie dans un contexte scalaire.
1-6-a-i. Les instructions if et unless▲
Nous avons vu plus haut comment un opérateur logique pouvait fonctionner comme un conditionnel. Une forme un peu plus complexe des opérateurs logiques est l'instruction if. Celui-ci évalue une condition de vérité et exécute un bloc si la condition est vraie.
if ($debug_level > 0) {
# Quelque chose ne va pas. Il faut avertir l'utilisateur.
print "Debug: Danger, Arthur Accroc, danger!\n";
print "Debug: La réponse est '54' au lieu de '42'.\n";
}Un bloc consiste en une ou plusieurs instructions regroupées par un ensemble d'accolades. Puisque l'instruction if exécute un bloc, les accolades sont nécessaires par définition. Dans un langage comme le C, on constate une certaine différence. Les accolades sont optionnelles s'il n'y a qu'une ligne de code, ce qui n'est pas le cas en Perl.
Parfois, il ne suffit pas d'exécuter un bloc quand une condition est remplie. On désire également exécuter un autre bloc quand la condition n'est pas remplie. Bien que l'on puisse évidemment employer deux instructions if, l'une étant la négation de l'autre, Perl fournit une solution plus élégante. Après le bloc, if peut prendre une deuxième condition optionnelle, appelée else, qui n'est exécutée que si la conditionnelle est fausse (les vétérans de l'informatique n'en seront pas surpris).
En d'autres occasions, vous pouvez même avoir plus de deux choix possibles. En ce cas, il est possible d'ajouter une conditionnelle elsif pour les autres choix possibles (les vétérans de l'informatique s'étonneront à bon droit de la façon d'écrire « elsif », mais personne ici ne s'en excusera).
if ($city eq "Lille") {
print "Lille est au nord de Paris.\n";
}
elsif ($city eq "Nancy") {
print "Nancy est à l'est de Paris.\n";
}
elsif ($city eq "Bayonne") {
print "Bayonne est au sud-ouest de Paris. Et il y fait plus chaud!\n";
}
else {
print "Je ne sais pas où se trouve $city, désolé.\n";
}Les clauses if et elsif sont calculées chacune à leur tour, jusqu'à ce que l'une d'entre elles soit vraie ou que la condition else soit atteinte. Quand l'une de ces conditions est vraie, son bloc est exécuté et toutes les branches restantes sont sautées. Parfois, on ne veut faire quelque chose que si la condition est fausse, et rien si elle est vraie. Un if vide avec un else n'est pas très propre, et la négation d'un if peut être illisible ; il est dommage d'écrire « faire quelque chose si pas ceci est vrai ». Dans ce cas, on peut utiliser l'instruction unless.
Il n'existe pas de elsunless. Il s'agit là d'une caractéristique.
1-6-b. Constructions itératives (en boucle)▲
Perl possède quatre types principaux d'instructions itératives : while, until, for et foreach. Ces instructions permettent à un programme Perl d'exécuter de façon répétitive le même code pour différentes valeurs.
1-6-b-i. Les instructions while et until▲
Les instructions while et until fonctionnent de la même manière que les instructions if et unless, sauf qu'ils répètent l'exécution du bloc en bouclant. D'abord, la partie conditionnelle d'une instruction est vérifiée. Si la condition est remplie (si elle est vraie pour un while ou fausse pour un until), le bloc de l'instruction est exécuté.
while ($tickets_vendus < 10000) {
$dispo = 10000 -$tickets_vendus;
print "$dispo tickets sont disponibles. Combien en voulez -vous: ";
$achat = <STDIN>;
chomp($achat);
$tickets_vendus += $achat;
}Remarquez que si la condition originelle n'est pas remplie, on ne rentrera jamais dans la boucle. Par exemple, si nous avons déjà vendu 10 000 tickets, nous voulons que la ligne suivante du programme affiche quelque chose comme :
print "Ce spectacle est complet, revenez plus tard.\n";Dans notre exemple de notation, on voit à la ligne 4 :
while ($ligne = <NOTES>) {ce qui assigne la ligne suivante à la variable $ligne, et comme nous l'avons expliqué plus haut, renvoie la valeur de $ligne afin que la condition de l'instruction while puisse évaluer la vérité de $ligne. On peut se demander si Perl obtient un « faux »\ sur les lignes vides et sort prématurément de la boucle. La réponse est non. La raison en est simple, si vous vous reportez à tout ce que nous en avons dit. L'opérateur d'entrée de ligne laisse le saut de ligne à la fin de la chaîne, ce qui fait qu'une ligne vide comporte la valeur « \n ». Et vous savez que « \n » n'est pas une des valeurs canoniques de fausseté. La condition est donc vraie et la boucle continue même pour les lignes vides.
En revanche, quand nous atteignons la fin du fichier, l'opérateur d'entrée de ligne renvoie la valeur indéfinie, qui donne toujours faux. Et la boucle se termine ainsi au moment désiré. Ce programme Perl n'a pas besoin d'un test explicite sur la fonction eof, parce les opérateurs d'entrée sont conçus pour fonctionner sans douleur dans un contexte conditionnel.
En fait, presque tout est conçu pour fonctionner sans douleur dans un contexte conditionnel. Par exemple, un tableau dans un contexte scalaire renvoie sa longueur. On voit donc fréquemment ce genre de choses :
while (@ARGV) {
process(shift @ARGV);
}La boucle sort automatiquement quand @ARGV est épuisé. L'opérateur shift retire un élément de la liste argument à chaque boucle et retourne cet élément. La boucle s'arrête automatiquement lorsque le tableau @ARGV est vide, donc de longueur 0 qui a pour valeur booléenne 0.(27)
1-6-b-ii. L'instruction for▲
Un autre traitement itératif est la boucle for. Une boucle for tourne exactement comme la boucle while, mais paraît très différente (bien qu'elle dise quelque chose aux programmeurs C).
for ($vendu = 0; $vendu < 10000; $vendu += $achat) {
$dispo = 10000 -$vendu;
print "$dispo tickets sont disponibles. Combien en voulez-vous: ";
$achat = <STDIN>;
chomp($achat);
}La boucle for prend trois expressions entre les parenthèses de la boucle : une expression pour initialiser l'état de la variable de boucle, une condition pour tester la variable et une expression pour modifier l'état de la variable. Quand la boucle commence, la variable est initialisée et la condition est vérifiée. Si elle est vraie, le bloc est exécuté. Quand le bloc se termine, l'expression de modification est exécutée, la condition est de nouveau vérifiée et si elle est vraie, le bloc est réexécuté avec les nouvelles valeurs. Tant que la condition reste vraie, le bloc et l'expression de modification continuent à être exécutés. (Notez que seule la valeur de l'expression du milieu est évaluée et mémorisée, les deux autres ne sont utilisées que comme effet de bord, et ne sont pas mémorisées.)
1-6-b-iii. L'instruction foreach▲
La dernière des principales instructions itératives est l'instruction foreach. foreach est utilisée pour exécuter le même code pour chacun des éléments d'un ensemble connu de scalaires, comme un tableau :
foreach $user (@users) {
if (-f "$home{$user}/.nexrc") {
print "$user est un type bien... il utilise un vi qui
comprend Perl!\n";
}
}À la différence des conditionnelles if et while, qui induisent un contexte scalaire dans l'expression, l'instruction foreach induit un contexte de liste dans l'expression entre parenthèses. Ainsi l'expression s'évalue en une liste (même si cette liste ne contient qu'un scalaire). Chaque élément de la liste est tour à tour mis dans la variable de boucle et le bloc de code est exécuté une fois par élément. Remarquez que la variable de boucle devient une référence à l'élément lui-même, et non une copie de l'élément. La modification de cette variable modifie donc le tableau originel.
On trouve beaucoup plus de boucles foreach dans un programme Perl typique que dans des boucles for, car il est très facile en Perl de générer les listes que demande foreach. Une tournure que l'on rencontre fréquemment est une itération bouclant sur les clefs triées d'un hachage :
foreach $clef (sort keys %hash) {Ce qui est exactement le cas de la ligne 9 de notre exemple de notation.
1-6-b-iv. Pour s'en sortir : next et last▲
Les opérateurs next et last permettent de modifier le f lux de votre boucle. Il n'est pas rare de rencontrer un cas spécial ; on peut vouloir le sauter, ou quitter la boucle quand on le rencontre. Par exemple, si l'on gère des comptes UNIX, on peut vouloir sauter les comptes système comme root ou lp. L'opérateur next permet de sauter à la fin de l'itération courante et d'en commencer une nouvelle. L'opérateur last permet de sauter à la fin du bloc comme si la condition du test avait renvoyé faux, par exemple dans le cas où l'on cherche un compte spécifique et que l'on veut quitter aussitôt qu'on l'a trouvé.
foreach $user (@users) {
if ($user eq "root" or $user eq "lp") {
next;
}
if ($user eq "special") {
print "Compte spécial trouvé.\n";
# Traitement
last;
}
}Il est possible de sortir de boucles imbriquées en les étiquetant et en spécifiant celles dont on veut sortir. Les modificateurs d'instruction (une autre forme de conditionnelle dont nous n'avons pas encore parlé) associés à ceci peuvent fournir des sorties de boucles très lisibles, pour autant que le français ou l'anglais soient lisibles :
LIGNE: while ($ligne = <ARTICLE>) {
last LIGNE if $ligne eq "\n"; # arrêt sur la première ligne vide
next LIGNE if /^#/; # sauter les lignes de commentaire
# ici, votre publicité
}Vous devez vous dire, « Une minute, là, qu'est-ce que ce truc bizarre, ^#, entre ces espèces de cure-dents ? Cela ne ressemble pas à du langage naturel. » Vous avez mille fois raison. Il s'agit d'une recherche de correspondance contenant une expression rationnelle (bien qu'elle soit plutôt simple). Et c'est ce dont parle la section suivante. Perl est avant tout un langage de traitement de texte, et les expressions rationnelles sont au cœur de ces fonctionnalités.
1-7. Expressions régulières▲
Les expressions régulières (aussi expressions rationnelles, regexps ou bien RE) sont utilisées par la plupart des processeurs de texte du monde UNIX : grep et findstr, sed et awk, et les éditeurs tels vi et emacs. Une expression régulière est l'écriture concise d'un ensemble de chaînes.(28)
La plupart des autres langages intègrent aussi le traitement des RE, mais aucun d'eux ne le fait à la manière de Perl. Les expressions rationnelles sont employées de plusieurs manières dans Perl. Elles sont utilisées en premier lieu dans des conditionnelles pour déterminer si une chaîne correspond à un motif donné. Quand on voit quelque chose qui ressemble à /machin/, on sait qu'il s'agit d'un opérateur de recherche de correspondance ordinaire.
if (/Windows 95/) { print "Il est temps de faire une mise à jour ?\n" }Ensuite, si l'on peut retrouver des motifs dans une chaîne, on peut les remplacer par quelque chose d'autre. Par exemple, s/machin/bidule/ demande de substituer « bidule » à « machin », si cela est possible. Nous appelons cela l'opérateur de substitution. Une RE peut aussi s'évaluer en un booléen, mais c'est l'effet de bord qui est utilisé la plupart du temps.
s/Windows/Linux/;Enfin, les motifs peuvent non seulement spécifier l'emplacement de quelque chose, mais également les endroits où il ne se trouve pas. L'opérateur split emploie donc une expression rationnelle pour spécifier les emplacements d'où les données sont absentes. Autrement dit, l'expression rationnelle définit les délimiteurs qui séparent les champs de données. Notre exemple de notation en comporte quelques exemples simples. Les lignes 5 et 12 éclatent les chaînes sur le caractère espace pour renvoyer une liste de mots. Mais split permet d'éclater sur tout délimiteur spécifié par une expression rationnelle.
($bon, $brute, $truand) = split(/,/, "vi,emacs,teco");Il existe de nombreux modificateurs utilisables dans chacun de ces contextes pour faire des choses plus exotiques comme l'indifférenciation des majuscules et des minuscules en recherchant des chaînes de caractères, mais ce sont là des détails que nous couvrirons au chapitre suivant.
L'usage le plus simple des expressions rationnelles consiste à rechercher une expression littérale. Dans le cas des éclatements que nous venons de mentionner, nous avons recherché un simple espace. Mais si l'on recherche plusieurs caractères à la fois, ils doivent tous correspondre en séquence. C'est-à-dire que le motif correspond à une sous-chaîne, comme l'on peut s'y attendre. Admettons que nous désirions montrer toutes les lignes d'un fichier HTML représentant des liens vers d'autres fichiers HTML (en excluant les liens FTP). Imaginons que nous travaillions en HTML pour la première fois et que nous soyons donc un peu naïfs. Nous savons que ces liens contiendront toujours la chaîne « http: ». Nous pouvons boucler dans le fichier comme ceci :(29)
Ici, le =~ (opérateur de liaison de motif) indique à Perl qu'il doit rechercher l'expression rationnelle http: dans la variable $ligne. S'il trouve l'expression, l'opérateur renvoie une valeur vraie et le bloc (une commande d'affichage) est exécuté.
Au fait, si l'on n'utilise pas l'opérateur de liaison =~, Perl recherchera un motif par défaut au lieu de $ligne. Ce motif par défaut n'est en fait qu'une variable spéciale qui prend le nom curieux de $_. En fait, de nombreux opérateurs emploient la variable $_ et un expert de la programmation Perl peut écrire ce qui précède comme :
(Hmm, un autre modificateur d'instruction semble être apparu ici. Insidieuses bestioles...)
Tout cela est bien pratique, mais si nous voulons trouver tous les liens, et non les seuls HTTP ? Nous pouvons en donner une liste comme « http: », « ftp: », « mailto: », etc. Mais cette liste peut être longue, et que faire si un nouveau type de lien est ajouté ?
Comme les expressions rationnelles décrivent un ensemble de chaînes, nous pouvons nous contenter de décrire ce que nous cherchons : un certain nombre de caractères alphabétiques suivis d'un deux-points. Dans le dialecte des expressions rationnelles (le regexpais ?), ce serait /[a-zA-Z]+:/, où les crochets définissent une classe de caractères. Les a-z et A-Z représentent tous les caractères alphabétiques (le tiret représentant l'intervalle de caractères entre le caractère de début et celui de fin, inclus). Et le + est un caractère spécial disant « un ou plusieurs exemplaires du machin qui se trouve avant moi ». Il s'agit d'un quantificateur, qui indique combien de fois quelque chose peut être répété. (Les barres obliques ne font pas vraiment partie de l'expression rationnelle, mais plutôt de l'opérateur de correspondance. Elles n'agissent que comme délimiteurs de l'expression rationnelle).
Certaines classes, comme la classe alphabétique, étant fréquemment utilisées, Perl définit des cas spéciaux, qui comprennent :
|
Nom |
Définition ASCII |
Caractère |
|---|---|---|
|
espace |
[ \t\n\r\f] |
\s |
|
Caractère de mot |
[a |
\w |
|
Chiffre (digit) |
[ |
\d |
Remarquez qu'ils ne correspondent qu'à des caractères simples. Un \w recherchera un unique caractère de mot et non un mot complet. (Vous souvenez-vous du quantificateur
+ ? On peut écrire \w+ pour rechercher un mot.) Perl fournit également la négation de ces classes en employant le caractère en majuscule, comme \D pour un caractère qui n'est pas un chiffre.
(Il faut remarquer que \w n'est pas toujours équivalent à [a-zA-Z_0-9]. Certains locales définissent des caractères alphabétiques supplémentaires hors de la séquence ASCII, et \w les respecte.)(30) Certaines langues définissent des caractères alphabétiques au-delà de la séquence ASCII classique. Le code \w les prend en compte. Les récentes versions de Perl connaissent aussi le codage UNICODE avec les propriétés numériques et Perl traite ce codage avec les propriétés en conséquence. (Il considère aussi les idéogrammes comme des caractères \w.)
Il existe une autre classe de caractères très spéciale, que l'on écrit « . », qui recherchera tout caractère.(31) Par exemple, /a./ trouve toute chaîne contenant un « a » qui n'est pas le dernier caractère de la chaîne. Il trouvera donc « at » ou « am », ou même « a+ », mais non « a » puisqu'il n'y a rien après le « a » qui puisse correspondre au point. Comme il cherche le motif n'importe où dans la chaîne, il le trouvera dans « oasis » et dans « chameau », mais non dans « sheba ». Il trouvera le premier « a » de « caravane ». Il pourrait trouver le deuxième, mais il s'arrête après la première correspondance en cherchant de gauche à droite.
1-7-a. Quantificateurs▲
Les caractères et les classes de caractères dont nous avons parlé recherchent des caractères uniques. Nous avons déjà mentionné que l'on pouvait rechercher plusieurs caractères «de mot» avec \w+ pour correspondre à un mot complet. Le + est un de ces quantificateurs, mais il y en a d'autres (tous sont placés après l'élément quantifié).
La forme la plus générale de quantificateur spécifie le nombre minimal et le nombre maximal de fois auquel un élément peut correspondre. Les deux nombres sont mis entre accolades, séparés par une virgule. Par exemple, pour essayer de trouver les numéros de téléphone d'Amérique du Nord, /\d{7,11}/ rechercherait au moins 7 chiffres, mais au plus 11 chiffres. Si un seul chiffre se trouve entre les accolades, il spécifie à la fois le minimum et le maximum ; c'est-à-dire que le nombre spécifie le nombre exact de fois que l'élément peut être répété. (Si l'on y réfléchit, tous les éléments non quantifiés ont un quantificateur implicite {1}.)
Si l'on met le minimum et la virgule en omettant le maximum, ce dernier passe à l'infini. En d'autres termes, le quantificateur indique le nombre minimum de caractères, et tous ceux qu'il trouvera après cela. Par exemple, /\d{7}/ ne trouvera qu'un numéro de téléphone local (d'Amérique du Nord, à sept chiffres), alors que /\d{7,}/ correspondra à tous les numéros de téléphones, même les internationaux (sauf ceux qui comportent moins de 7 chiffres). Il n'existe pas de façon spécifique d'écrire « au plus » un certain nombre de caractères. Il suffit d'écrire, par exemple, /.{0,5}/ pour trouver au plus cinq caractères quelconques.
Certaines combinaisons de minimum et de maximum apparaissant fréquemment, Perl définit des quantificateurs spéciaux. Nous avons déjà vu +, qui est identique à {1,}, c'est-à-dire « au moins une occurrence de l'élément qui précède ». Il existe aussi *, qui est identique à {0,}, ou « zéro occurrence ou plus de l'élément qui précède », et ?, identique à {0,1}, ou « zéro ou une occurrence de l'élément qui précède » (l'élément qui précède est donc optionnel).
Il faut savoir deux ou trois choses concernant la quantification. D'abord, les expressions rationnelles de Perl sont, par défaut, avides. Cela signifie qu'elles essayent de trouver une correspondance tant que l'expression entière correspond toujours. Par exemple, si l'on compare /\d+ à « 1234567890 », cela correspondra à la chaîne entière. Il faut donc spécialement surveiller l'emploi de « . », tout caractère. On trouve souvent une chaîne comme :
larry:JYHtPh0./NJTU:100:10:Larry Wall:/home/larry:/bin/tcshoù on essaye de trouver « larry » avec /.+:/. Cependant, comme les expressions rationnelles sont avides, ce motif correspond à tout ce qui se trouve jusqu'à « /home/larry » inclus. On peut parfois éviter ce comportement en utilisant une négation de classe de caractères, par exemple avec /[\^:]+:/, qui indique de rechercher un ou plusieurs caractères non-deux-points (autant que possible), jusqu'au premier deux-points. C'est le petit chapeau qui inverse le sens de la classe de caractères.(32) L'autre point à surveiller est que les expressions rationnelles essayent de trouver une correspondance dès que possible. Ce point est même plus important que l'avidité. Le balayage se produisant de gauche à droite, cela veut dire que le motif cherchera la correspondance la plus à gauche possible, même s'il existe un autre endroit permettant une correspondance plus longue (les expressions rationnelles sont avides, mais elles voient à court terme). Par exemple, supposons que l'on utilise la commande de substitution s/// sur la chaîne par défaut (à savoir la variable $_), et que l'on veuille enlever une suite de x du milieu de la chaîne. Si l'on écrit :
$_ = "fred xxxxxxx barney";
s/x*//;cela n'aura aucun effet. En effet, le x* (voulant dire zéro caractères « x » ou plus) trouvera le « rien » au début de la chaîne, puisque la chaîne nulle est large de zéro caractères et que l'on trouve une chaîne nulle juste avant le « f » de « fred ».(33)
Encore une chose à savoir. Par défaut, les quantificateurs s'appliquent à un caractère unique les précédant, ce qui fait que /bam{2}/ correspond à « bamm », mais pas à « bambam ». Pour appliquer un quantificateur à plus d'un caractère, utilisez les parenthèses. Il faut employer le motif /(bam){2}/ pour trouver « bambam ».
1-7-b. Correspondance minimale▲
Si l'on ne voulait pas de « correspondances avides » dans les anciennes versions de Perl, il fallait employer la négation d'une classe de caractères (et en fait, on obtenait encore une correspondance avide, bien que restreinte).
Les versions modernes de Perl permettent de forcer une correspondance minimale par l'emploi d'un point d'interrogation après tout quantificateur. Notre recherche de nom d'utilisateur serait alors /.*?:/. Ce .*? essaye alors de correspondre à aussi peu de caractères que possible, au lieu d'autant que possible, et il s'arrête donc au premier deux-points au lieu du dernier.
1-7-c. Pour enfoncer le clou▲
Chaque fois que l'on cherche à faire correspondre un motif, celui-ci essayera partout jusqu'à ce qu'il trouve une correspondance. Une ancre permet de restreindre l'espace de recherche. Une ancre est d'abord quelque chose qui ne correspond à « rien », mais il s'agit là d'un rien d'un type spécial qui dépend de son environnement. On peut aussi l'appeler une règle, une contrainte ou une assertion. Quelle que soit son appellation, elle essaie de faire correspondre quelque chose de longueur zéro, et réussit ou échoue. (En cas d'échec, cela veut surtout dire que le motif ne trouve pas de correspondance de cette façon. Il essaie alors d'une autre manière, s'il en existe.)
La chaîne de caractères spéciale \b correspond à une limite de mot, qui est définie comme le « rien » entre un caractère de mot (\w) et un caractère de non-mot (\W), dans le désordre. (Les caractères qui n'existent pas de part et d'autre de la chaîne sont appelés des caractères de non-mot). Par exemple,
/\bFred\b/correspond à « Le Grand Fred » et à « Fred le Grand » , mais ne correspond pas à « Frederic le Grand » parce que le « de » de Frederic ne contient pas de limite de mot.
Dans une veine similaire, il existe également des ancres pour le début et la fin d'une chaîne. S'il s'agit du premier caractère d'un motif, le chapeau (^) correspond au « rien » au début de la chaîne. Le motif /^Fred/ correspondrait donc à « Frederic le Grand» et non à « Le Grand Fred », alors que /Fred^/ ne correspondrait à aucun des deux (et ne correspondrait d'ailleurs pas à grand-chose). Le signe dollar ($) fonctionne comme le chapeau, mais il correspond au « rien » à la fin de la chaîne au lieu du début.(34)
Vous devez maintenant être en mesure de deviner ce que veut dire :
C'est bien sûr « Aller à la prochaine itération de la boucle LIGNE si cette ligne commence par un caractère # ».
Nous avons dit plus haut que la séquence \d{7,11} coïncide avec un nombre de 7 à 11 chiffres de long ce qui est vrai, mais incomplet : quand cette séquence est utilisée dans une expression comme /\d{7,11}/, ça n'exclue pas d'autres chiffres après les 11 premiers. Donc, le plus souvent, lorsque vous utilisez des quantificateurs, vous utiliserez des ancres de chaque côté.
1-7-d. Références arrière▲
Nous avons déjà mentionné que l'on pouvait employer des parenthèses pour grouper des caractères devant un quantificateur, mais elles peuvent aussi servir à se souvenir de parties de ce qui a été trouvé. Une paire de parenthèses autour d'une partie d'expression rationnelle permet de se souvenir de ce qui a été trouvé pour une utilisation future. Cela ne change pas le motif de recherche, et /\d+ et /(\d+)/ chercheront toujours autant de chiffres que possible, mais dans le dernier cas, ceux-ci seront mémorisés dans une variable spéciale pour être « référencés en arrière » plus tard.
La façon de référencer la partie mémorisée de la chaîne dépend de l'endroit d'où on opère. Dans la même expression rationnelle, on utilise un antislash suivi d'un entier. Il correspond à une paire de parenthèses donnée, déterminée en comptant les parenthèses gauches depuis la gauche du motif, en commençant par un. Par exemple, pour rechercher quelque chose ressemblant à une balise HTML (comme « <B>Gras</B> »), on peut utiliser /<(.*?)>.*?<\/\1>/. On force alors les deux parties du motif à correspondre exactement à la même chaîne de caractères, comme au « B » ci-dessus.
Hormis l'expression rationnelle elle-même, comme dans la partie de remplacement d'une substitution, la variable spéciale est utilisée comme s'il s'agissait d'une variable scalaire normale nommée par l'entier. Donc, si l'on veut échanger les deux premiers mots d'une chaîne, par exemple, on peut employer :
s/(\S+)\s+(\S+)/$2 $1/Le côté droit de la substitution équivaut à une sorte de chaîne protégée par des apostrophes doubles, ce qui explique pourquoi l'on peut y interpoler des variables, y compris des références arrière. Ce concept est puissant : l'interpolation (sous contrôle) est une des raisons pour lesquelles Perl est un bon langage de traitement de texte. Entre autres raisons, on trouve bien entendu les motifs de correspondance. Les expressions rationnelles savent parfaitement extraire des éléments et l'interpolation sert à les rassembler. Peut-être existe-t-il enfin un espoir pour Humpty Dumpty.
1-8. Traitement des listes▲
Nous avons vu plus haut que Perl connaît deux principaux contextes, le contexte scalaire (pour gérer les singularités) et le contexte de liste (pour gérer les pluralités). La plupart des opérateurs traditionnels que nous avons décrits jusqu'ici étaient strictement scalaires dans leur opération. Ils prennent toujours des arguments singuliers (ou des paires d'arguments singuliers pour les opérateurs binaires), et produisent toujours un résultat singulier, même dans un contexte de liste. Donc, si l'on écrit ceci :
@tableau = (1+2,3-4, 5 * 6, 7 / 8);on sait que la liste de droite contient exactement quatre valeurs, car les opérateurs mathématiques ordinaires produisent toujours des valeurs scalaires, même dans le contexte de liste fourni par l'assignation à un tableau.
Cependant, d'autres opérateurs Perl peuvent produire soit un scalaire, soit une liste, selon le contexte. Ils « savent » si vous attendez d'eux un scalaire ou une liste. Mais comment pouvez-vous le savoir ? C'est en fait très simple une fois que vous vous êtes familiarisés avec quelques concepts clefs.
Premièrement, le contexte de liste doit être fourni par quelque chose dans l'« environnement ». Dans l'exemple ci-dessus, c'est l'assignation de liste qui le fournit. Nous avons vu ci-avant que la liste dans l'instruction de boucle foreach fournit le contexte de liste. L'opérateur print aussi. Il est possible de tous les identifier d'un coup.
Si vous regardez les nombreuses représentations syntaxiques des opérateurs dans le reste de ce livre, divers opérateurs sont définis pour prendre une LISTE en argument. Ce sont les opérateurs qui fournissent un contexte de liste. Tout au long de ce livre, LISTE est employé comme le terme technique signifiant « une construction syntaxique fournissant un contexte de liste ». Par exemple, si l'on regarde sort, on trouve le résumé de syntaxe suivant :
sort LISTECe qui veut dire que sort procure un contexte de liste à ses arguments.
Deuxièmement, à la compilation, tout opérateur qui prend une LISTE fournit un contexte de liste à chaque élément syntaxique de cette LISTE. Chaque opérateur ou entité de haut niveau de la LISTE sait qu'il est censé fournir la meilleure liste possible. Cela signifie que si l'on écrit :
sort @mecs, @nanas, autres();@mecs, @nanas et autres() savent tous qu'ils sont censés fournir une valeur de liste. Enfin, à l'exécution, chacun de ces éléments de LISTE fournit sa liste, puis (ceci est important) toutes les listes isolées sont rassemblées, bout à bout, en une liste unique. Et cette liste unique, unidimensionnelle, est ce qui est finalement donné à la fonction qui voulait une LISTE. Si donc @mecs contient (Fred, Barney), @nanas contient (Wilma, Betty), et que la fonction autre() renvoie la liste à un seul élément (Dino), la LISTE que voit sort devient :
(Fred,Barney,Wilma,Betty,Dino)et sort renvoie la liste :
(Barney,Betty,Dino,Fred,Wilma)Certains opérateurs produisent des listes (comme keys), certains les consomment (comme print) et d'autres les transforment en d'autres listes (comme sort). Les opérateurs de cette dernière catégorie sont considérés comme des filtres ; mais contrairement au shell, le flux de données s'effectue de droite vers la gauche, puisque les opérateurs de liste agissent sur les éléments qui sont passés à leur droite. On peut empiler plusieurs opérateurs de liste à la fois :
print reverse sort map {lc} keys %hash;Toutes les clefs de %hash sont prises et renvoyées à la fonction map, qui met chacune d'entre elles en minuscules par l'opérateur lc, et les passe à la fonction sort qui les trie et les repasse à la fonction reverse, qui renverse l'ordre des éléments de la liste, qui les passe enfin à la fonction print, qui les affiche.
C'est, on le voit, beaucoup plus facile à décrire en Perl qu'en français.
Nous ne pouvons lister tous les exemples où l'utilisation de la structure de liste produit un code plus naturel à lire. Mais revenons sur les RE un moment. Dans un contexte de liste, toutes les coïncidences sont mémorisées dans les éléments successifs de la liste. Cherchons, par exemple, toutes les chaînes de la forme « 12:59:59 am ». On peut le faire comme ceci :
($hour, $min, $sec, $ampm) = /(\d+):(\d+):(\d+) *(\w+)/;Ce qui est une façon pratique d'instancier plusieurs variables en même temps. On peut aussi écrire :
@hmsa = /(\d+):(\d+):(\d+) *(\w+)/;et mettre ces 4 valeurs dans un tableau. Étrangement, par la séparation de l'action entre les RE et les expressions Perl, le contexte de liste augmente les possibilités du langage. Nous ne le voyons pas, mais Perl est un véritable langage orthogonal en plus d'être diagonal. Allez, on fait une pause !
1-9. Ce que vous ne savez pas ne vous fera pas (trop) de mal▲
Enfin, permettez-nous de revenir encore une fois au concept de Perl en tant que langage naturel. Les usagers d'un langage naturel ont le droit d'avoir des niveaux d'aptitude différents, de parler différents sous-ensembles de ce langage, d'apprendre au fur et à mesure et, en général, de l'utiliser avant d'en connaître tous les arcanes. Vous ne connaissez pas tout de Perl, tout comme vous ne connaissez pas tout du français. Mais ceci est Officiellement OK dans la culture Perl. Vous pouvez employer utilement Perl même si nous ne vous avons pas encore appris à écrire vos propres sous-programmes. Nous avons à peine commencé à expliquer que Perl pouvait être vu comme un langage de gestion système, ou comme un langage de prototypage rapide, ou comme un langage réseau, ou comme un langage orienté objet. Nous pourrions écrire des chapitres entiers sur ces sujets (et à vrai dire, c'est déjà le cas).
Mais au bout du compte, vous devrez créer votre propre vision de Perl. C'est votre privilège, en tant qu'artiste, de vous infliger à vous-même la douleur de la créativité. Nous pouvons vous apprendre notre façon de peindre, mais nous ne pouvons pas vous apprendre votre façon. TMTOWTDI : il existe plus d'une façon de faire.
Amusez-vous comme il convient.
